
Sizing
Sizing
-
To better understand the sizing recommendations, consider the following key concepts in cnvrg.io:
- Each workspace, such as an interactive Jupyter notebook, runs as a Kubernetes pod that is based on a compute template.
- A compute template has a predefined set of resources, including CPU, memory, and GPU resources.
- The pods run on Kubernetes worker nodes in a Kubernetes cluster.
- The Kubernetes cluster is referred to as a compute resource.
In this section, we first provide recommendations for creating compute templates that can be used for various AI workloads and use cases. Then, we provide sizing recommendations for different types of worker nodes. Finally, we provide sizing recommendations for the deployment.
The following figure shows the workspaces running on worker nodes using recommended compute templates. In the rest of this section, we describe the sizing of CPU- and GPU-based templates and worker nodes.
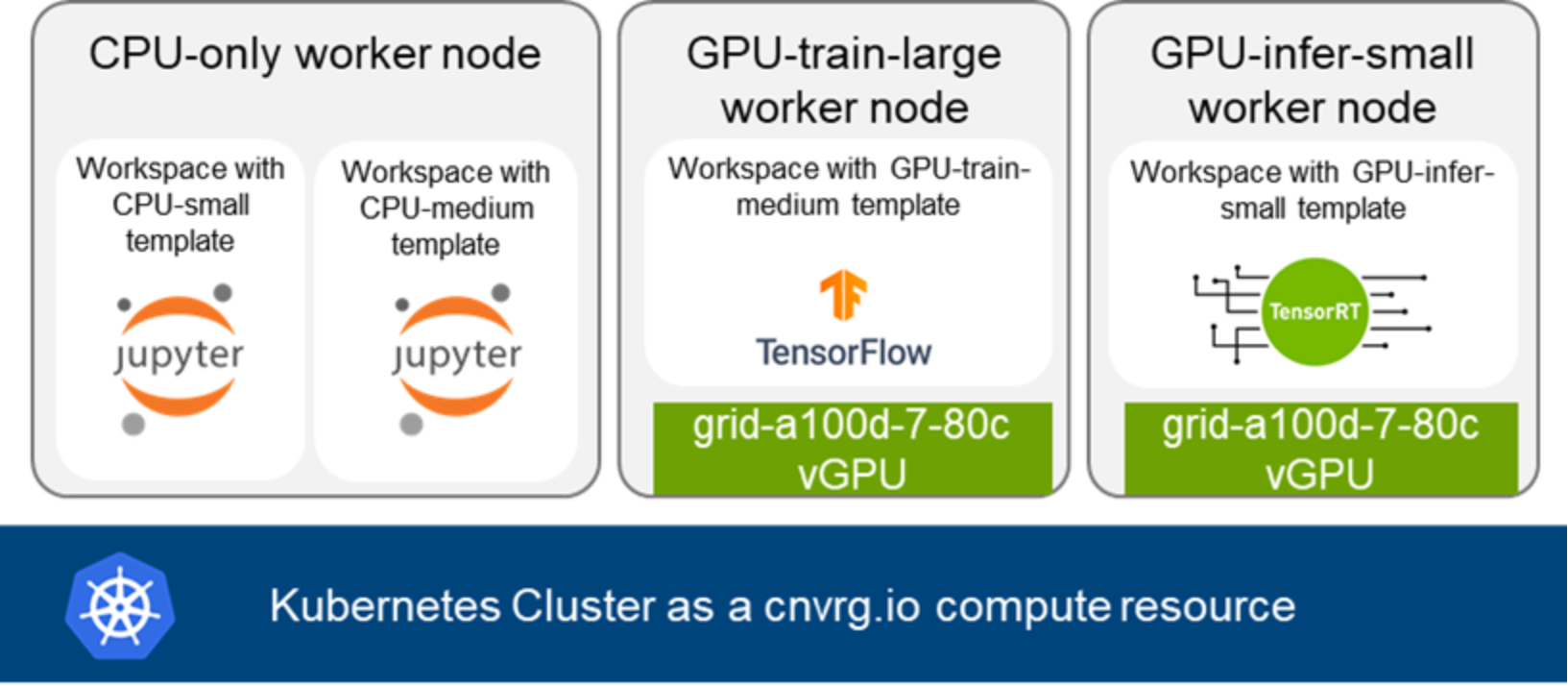
Figure 2. Worker nodes, compute templates, and compute resource in cnvrg.io
Recommended compute templates
The following table shows the recommended compute templates that can be created in cnvrg.io, including the GPU profile associated with each template:
Table 2. Recommended compute templates
Number of CPU cores
Memory (in GB)
Number of GPUs
Associated GPU profile for A100 80 GB
CPU-small
4
8
0
None
CPU-medium
8
16
0
None
16
32
0
None
GPU-train-medium
16
64
1
grid_a100d-3-40c
GPU-train-large
32
64
1
grid_a100d-7-80c
GPU-infer-small
8
16
1
grid_a100d-1-10c
GPU-infer-medium
8
16
1
grid_a100d-2-20c
Note: cnvrg.io deployments come with a default CPU template which has one CPU core and 1 GB memory.
cnvrg.io supports MIG partitions. When deploying cnvrg.io on bare metal Kubernetes, these profiles can be selected when creating the compute template. When deploying on Tanzu Kubernetes clusters, worker nodes can be deployed with these profiles, and templates can be associated with them by using node labels, as explained in Pod affinity to worker nodes.
Each compute template can be used for a specific set of workloads or use cases. Our recommended compute templates are categorized into three workload categories:
- CPU Workload templates (including CPU-small, CPU-medium, and CPU-large) can be used for exploratory data analysis and classical machine algorithms that do not require GPU acceleration. For example, these templates are used by data scientists working on problems related to Classification (Logistic Regression, SVM, Decision Trees, XGBoost Classifier, and so on) Regression (Linear Regression, XGBoost Regressor, SGD Regressor) or Clustering (K-Means, DBSCAN, and so on) using the scikit-learn library. The number of CPUs and memory differentiate each template in this workload category. The templates with more CPUs provide the ability to parallelize expensive operations using multiple CPUs, achieving a high degree of parallelization.
- GPU Train Workload templates (including GPU-train-medium and GPU-train-large) can be useful for building and training deep learning (DL) models. Some of the DL problem types include Image Classification, Image Segmentation, Object Detection, Speech Recognition, NLP, and Recommendation. Choosing between a smaller GPU profile and a large GPU profile depends on the model size/parameter count, batch size, and allowable training time. In general, larger GPU profiles provide higher throughput and can support large models such as BERT (NLP), Mask R-CNN (Object Detection), DLRM (Recommendation), and so on. If the model is small, the full computing capacity of the A100 GPUs cannot be used resulting in GPU resource waste. Using the medium template in this case provides a way to maximize the benefits of the GPU such as training a ResNet50 model (Image Classification), SSD (Object Detection), and so on.
- GPU Inference Workload templates (including GPU-infer-small and GPU-infer-medium) can be useful for inference tasks. Inference tasks can be categorized based on the latency requirements. The smaller template (GPU-infer-small) can be used for online inference in which predictions are generated in real time. The medium template (GPU-infer-medium) can be used for batch inference to generate predictions on a large batch of data in which the latency can be high.
Sizing recommendation for cnvrg.io deployment
You must consider several factors for sizing a cnvrg.io deployment, such as cnvrg.io application requirements, the number of projects and workspaces, the type of workspaces, the number of concurrent users, and the number of active tasks. With its modular and microservices-based design, a cnvrg.io deployment can easily be scaled depending on resource use. NVIDIA MIG capability also enables effective partitioning of GPUs for various use cases and increases GPU utilization.
We recommend three sizing deployments for our validated design. The total CPU, memory, and GPU resources for each deployment can be calculated from the number of jobs and configuration of templates that they use. The storage recommendation includes storage required for both cnvrg.io control plane and user data. It is assumed that this storage is shared across all the worker nodes.
The recommended deployments include:
- Minimum production deployment—This deployment is the minimum deployment for a production-ready deployment and is recommended for organizations that are starting their AI journey. It can support up to ten projects and workspaces that perform classic ML or statistical modeling. This deployment assumes that these use cases do not require GPU acceleration and therefore, do not contain GPU worker nodes described in Table 3. You do not need to create GPU-based compute templates that are listed in Table 2 in this deployment.
- Mainstream deployment—This deployment is recommended for organizations that want to kickstart AI projects that might require GPU acceleration. It can support four projects that require GPU acceleration for training and can host four models for inference. It can also support a few projects and workspaces that use CPU only.
- High-performance deployment—This deployment is recommended for organizations that want to train and deploy AI models at scale. It can support up to 20 active projects that require GPU acceleration for training and can similarly number of models for inference. It can also support several projects and workspaces that use CPU only.
Table 3. Recommended sizing for the validated design
Deployment
Number of AI workloads or tasks in cnvrg.io
Total resource requirements
Recommended storage
Minimum production
- 4 CPU-only workloads (training and inference)
- 60 CPU cores
- 150 GB Memory
2 TB
Mainstream
- 4 CPU-only workloads (training and inference)
- 4 GPU training workloads
- 4 GPU inference workloads
- 160 CPU cores
- 600 GB Memory
- 6 A100 GPUs
5 TB
High performance
- 16 CPU-only workloads (training and inference)
- 10 GPU training workloads
- 10 GPU inference workloads
- 388 CPU cores
- 1.2 TB Memory
- 16 A100 GPUs
Greater than 5 TB, depending on the use case and datasets