
DellNLP text correction steps
DellNLP text correction steps
-
Step 1. Expansion and correction of contractions
The concordance analysis of a large amount of Dell Technologies text data helped identify mappings for contraction expansions. This analysis also used trained word embeddings to identify terms like “doesn” instead of “doesn’t,” for example.
The first operation that DellNLP performs on text is expansion of contractions. This is based on the simple but efficient use of compiled regular expressions. Any contractions found in the input text are corrected or expanded with the aid of derived mappings, as shown in the following figure.
The current mapping list consists of 270 contractions similar to this sample list.

Figure 6. Contraction mappings
Input Text
cx reported autoshut down issue wih the the optiaio.
I’ve instructuced to reboot lap top
Output Text
cx reported autoshut down issue wih the the optiaio.
I have instructuced to reboot lap top
Step 2. Dell Technology terminology expansion and correction
To address Dell-specific terms within text, a mapping was leveraged and constructed with the aid of concordance analysis to expand frequently used abbreviations by support agents.
The default mapping list includes more than 900 Dell Technology terms with an option to augment these mappings depending on project requirements. DellNLP also supports custom language packs that can be installed separately.
A sample of Dell Technology terminology expansion and correction mapping is shown in the following figure:

Figure 7. Dell Technologies abbreviations and acronyms mapping
The following table illustrates the application of these mappings:
Input Text
cx reported autoshut down issue wih the the optiaio.
I have instructuced to reboot lap top
Output Text
customer reported autoshut down issue wih the the optiaio.
I have instructuced to reboot lap top
Steps 3 and 4. Compounding and decompounding
Exploratory data analysis revealed that some support agents pay less attention to the proper use of spaces between words or proper word segmentation due to time pressure. In these steps, the algorithm determines the appropriate placement of spaces between words in a sentence.
By leveraging the collated bigram and unigram frequency information, the probability of segmenting or amalgamating given terms is computed. For example, given the term “lap top,” the algorithm determines whether the typical usage is “laptop” or “lap top.” Next, depending on the probability of segmenting the word, these modules either break the term into several terms (as in the bigram dictionary) or amalgamate it into a single term (as in the unigram dictionary).
The following illustrates the application of these corrections:
Input Text
customer reported autoshut down issue wih the the optiaio.
I have instructuced to reboot lap top
Output Text
customer reported auto shut down issue wih the the optiaio.
I have instructuced to reboot laptop
Step 5. Individual term correction
This algorithm is the most complex component of the project and includes a novel, newly created word-embedding-based spelling correction algorithm. Here given an incorrect term, we use spelling corrections by four different algorithms independently and select the term suggested by the majority of the algorithms as the final correction. The details of the algorithm are given below:
- After carrying out Steps 1-4, the algorithm consumes each term as a separate token and analyzes each token for a possible non-word.
- Next, three separate functions available through SymSpell are employed for obtaining possible syntactic corrections for the non-word.
- In parallel, the custom word-embedding-based spelling correction algorithm is also executed. The latter suggestion is primarily used to semantically validate the SymSpell syntactic suggestions.
- Finally, a simple decision tree determines the final term correction. This decision tree mainly implements a voting mechanism where, if suggestions by multiple independent methods agree on the same correction, it will be used as the final term correction.
The algorithm also segments terms if previous bigram or unigram analysis failed to do the correction. Empirical results show that this novel algorithm minimized false positives but increases recall, including the detection of true misspellings, in Dell Technologies text. The following figure illustrates the novel term correction process:
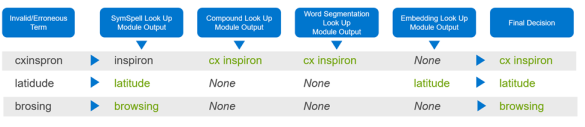
Figure 8. Individual term correction by different modules
The invention of the word-embedding-based spelling correction method, which determines semantically accurate spelling correction for a given term, uses fuzzy matching techniques and meta-phone features of the terms under analysis.
The following table illustrates the outcome of this step:
Input Text
customer reported auto shut down issue wih the the optiaio.
I have instructuced to reboot laptop
Output Text
customer reported auto shut down issue with the the opti aio.
I have instructed to reboot laptop
Step 6. Dell Terminology expansion and correction
As a result of individual term correction, some terms may need to be segmented that did not get resolved during the compounding and decompounding stages. An example of this is “optiaio” in the figure below. Terms like this undergo the same terminology mapping as described in Step 2.
The following table illustrates the outcome of this step:
Input Text
customer reported auto shut down issue with the the opti aio.
I have instructed to reboot laptop
Output Text
customer reported auto shut down issue with the the optiplex all in one.
I have instructed to reboot laptop
Step 7. Repetitive phrase deletion
Exploratory data analysis showed that repetitive phrases are a common issue in Dell Technologies text. These repetitions may occur due to database augmentations, by appending or inserting data into same table, for example.
Since repetitive phrases usually add little value in semantic parsing, the repeated phrases are removed in text using simple but effective regular expression technique.
The following table illustrates the outcome of this step:
Input Text
customer reported auto shut down issue with the the optiplex all in one.
I have instructed to reboot laptop
Output Text
customer reported auto shut down issue with the optiplex all in one.
I have instructed to reboot laptop
The following figure shows how DellNLP handles individual cases as implemented in a notebook.

Figure 9. DellNLP auto-correct function
Optimizations
As highlighted in the preceding figure, the auto-correct algorithm performs several complex operations to detect and correct various issues found in Dell Technologies text. The initial implementation of DellNLP primarily focused on accuracy and less on performance, yet due to the increasing demand for use in real-time applications, there was a focus on identifying algorithmic optimizations.
The optimizations included comprehensive time complexity analysis of individual functions, including profiling of each function. Appropriate steps were then taken to optimize code performance, including optimizing O(n2) operations into O(n), the use of appropriate data structures, and more.
The above steps failed to reach desired performance targets (for example, 200-400ms for processing an average sentence, including API call time, which was longer than desired), the algorithm was redesigned as a Cython implementation. This redesign resulted in a more than 50 percent faster performance, outperforming existing Python pre-processing algorithms in terms of speed within some projects.
The current implementation in production is the Cython-based DellNLP implementation. Subsequent optimizations focused on code maintainability, such as identifying and implementing key unit test cases, linting (with 10/10 rating), and PEP8 formatting of code.
Systematic derivation of language resources
Several language resources were collated and built for this project, such as unigram and bigram dictionaries. As a first step to the systematic derivation, textual data was collected and a text corpus was compiled, primarily containing text logged by Dell Technologies support agents and service providers. The collected data was later used for training FastText-based word embeddings due to its ability to provide embeddings for even out-of-vocabulary data.
Next steps involved identification of Dell Technologies terminology using the trained word-embeddings to retrieve semantically similar terms. For example, if the given term was “cx,” similar ones such as “cust”, “customer”, “cst” are retrieved.
A list of unique words found in the textual corpus was also derived. This list originally contained more than 198,000 terms, but any terms found within an English dictionary were filtered out, at about 80,000 words. Only 28,248 words were common between the Dell Technologies unique word list and English dictionary. The rest of the entries contained of Dell Technologies-specific terms, multilingual entries, and erroneous or misspelt terms.
These 170,000 entries could be further segregated into Es, Pt, It, De, Fr language terms and short terms with just two to three letters. The remaining entries (~132,000) consisted mainly of terms with genuine spelling mistakes, specific to Dell Technologies, person names, place names, erroneous compounds, and some transliterated terms. The following figure outlines term analysis.

Figure 10. Dictionary construction - term analysis
Identifying Dell Technologies-specific terms meant reviewing ~132,000 terms to construct a custom dictionary. After filtering out less frequently occurring terms, the rest were manually reviewed to identify legitimate terms including acronyms, abbreviations, and products to be included. The following figure shows a sample of the word review process.
Figure 11. Manual analysis of unique words
Concordance analysis and word-embeddings were used to examine the usage of words in context, as shown in the figure below:

Figure 12. Concordance analysis of the term "weve"
These steps resulted in the following:
- A Dell Technologies dictionary containing more than 83,000 Dell Technologies-specific terms
- A word-embeddings model
- A bigrams dictionary with more than 303,000 words
These systematically derived resources are leveraged in algorithms and models and are consistently being updating, with new Language Packs released as necessary. This ensures that model predictions are updated to reflect any changes or new patterns in the data.