
Elastic Stack overview
Elastic Stack overview
-
This section provides a brief overview of Elastic Stack and the components that reside in the stack. To learn more about Elastic Stack, see Elastic Docs library.
ELK stack components
Before 2015, Elastic Stack was known as the ELK Stack. ELK is an acronym for a group of three free and open-source products: Elasticsearch, Logstash, and Kibana:
- Elasticsearch is the heart of Elastic Stack and is a search and analytics engine that can work with all types of structured, semi structured, and unstructured data.
- Logstash is a server-side data processing pipeline that can ingest and transform data from various sources simultaneously, and then stash the data away in a destination like Elasticsearch.
- Kibana is a data analytics and visualization platform that allows users to see data in ways that help them to understand the data. Kibana can visualize the data in graphs and charts like line graphs, histograms, heat maps, and pie charts.
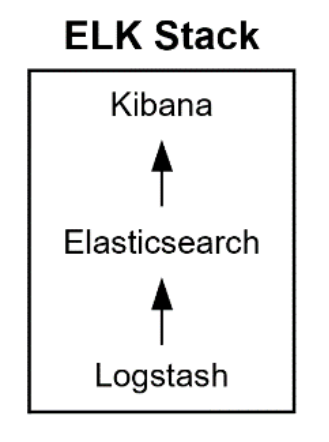
Figure 5. ELK Stack
Elastic Stack components
Since 2015, a fourth product called Beats (lightweight open-platform data shipper agents) was added to the ELK stack and began a new evolution of the ELK stack. Adding Beats to the ELK stack is the reason the stack is now called Elastic Stack.
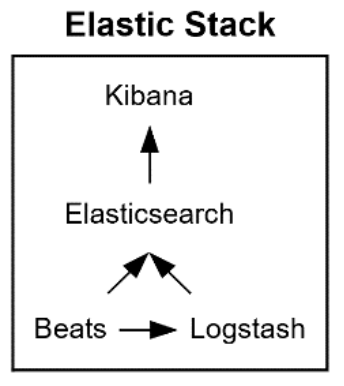
Figure 6. Elastic Stack
In 2016, with the release of Elastic Stack 5.0.0, X-Pack was released which was a replacement for the stand-alone plug-ins Shield, Marvel, Watcher, Graph, and Reporting.
X-Pack further augments Elastic Stack’s capabilities. Also, a newly added management UI was introduced in Kibana for X-Pack.Elastic Stack has grown and matured over the years and is now sometimes referred to as an Insight Engine. Gartner defines Insight Engines as data engines that “apply relevancy methods to describe, discover, organize and analyze data.” In 2021, Gartner added Elastic to the Magic Quadrant for Insight Engines.
Elasticsearch
Elasticsearch is at the heart of Elastic Stack and is a distributed open-source analytics, full-text and RESTful search engine that is used to store and search copious amounts of data. Elasticsearch is often used for search capabilities by applications and users for an increasing number of use cases. The distributed capability of Elasticsearch, when configured, provides fault tolerance and enables high scalability through a collection of servers clustered together and is referred to the Elasticsearch cluster. Each server in the cluster is referred to as a node and contains the entirety of the data.
The search function and capabilities can be basic or complex like search capabilities found in Internet search engines. Elasticsearch can query, analyze, and aggregate structured data, textual and numeric, which can be used to generate charts and graphs. Elasticsearch can also process semistructured and unstructured data in the same manner.
Elasticsearch also provides the functionality of document stores or document-oriented databases. Elasticsearch documents are stored in JSON format, and with a query DSL, any document can be found. In Elasticsearch, there are several terms used to describe the logical data structures and are sometimes compared to logical data structures from relational database theory:
Table 4. Elasticsearch and Relational database terms
Elasticsearch
Relational database
Index
Database
Type
Table
Document
Row
Fields
Columns
Indexes are where data (documents) are stored. The number of indexes defined in an Elasticsearch cluster depends on business requirements. There can be one or multiple indexes in an Elasticsearch cluster. Indexes are typically made up of one or multiple shards.
Document sharding is also possible with Elasticsearch. A use case for shards is when processing large amounts of data increases elapsed times. Sharding in this case can increase the read/write throughput, reducing elapsed times. Shards, considered indexes themselves, are portions of an index and separate data horizontally across clustered nodes.
There are two types of shards: primary or replica. Primary shards are mainly responsible for operations involving indexes (creating, reindexing, delete indexes), but they can also be used for reads. Replica shards are responsible for throughput and providing high availability.
Mappings control how JSON documents and fields are processed. Mappings can have an impact on the amount data stored on disk and query performance. Mappings can inform Elasticsearch many different things, such as but not limited to:
- If the documents are structured or unstructured
- If fields (and how many fields) should be indexed
- The type of data in the fields
- Data patterns that describe the data content of fields
Elasticsearch cluster and node roles
An Elasticsearch cluster consists of one or multiple nodes. A node is a single running instance of Elasticsearch. For simplicity, the discussion in this paper focuses on running a single node on a single physical server. However, running multiple nodes on a single or multiple physical servers is also possible. See Elastic documentation for more information.
When Elasticsearch starts, an elastic cluster is started. Regardless of the number of nodes in the cluster, all nodes know about the other nodes. Communication between nodes is through the transport layer.
Each node in the cluster assumes one or multiple node roles. If node roles are not explicitly set for a node, the node is assigned all roles. The following roles are available:
- master: Master nodes control the cluster. For resiliency and high availability, a minimum of three master nodes are needed. Only one master node is active at a time.
- data: Data nodes are the data repository for Elasticsearch. The nodes can be classified for different tiers of data storage: frozen, cold, warm, and hot data. The data stored in the tiers can remain indefinitely or can move between data tiers by configuring index lifecycle management (ILM) policies. To learn more about data tiers and ILM, see the following documentation: Data tiers and ILM: Manage the index lifecycle.
- data_content: data_content nodes generally hold items with values that remain relatively constant over time and have long retention requirements. data_content allows the data to remain in the same tier as it ages.
- data_hot: This tier of data is for hot data. data_hot is the entry point for all time-series data ingested into Elasticsearch, and is the repository of most-recent searched time series data.
- data_warm: This role is for warm data. Data that is less frequently queried can move to this tier. Data_warm nodes generally do not need the same compute power as data_content or data_hot nodes.
- data_cold: data_cold nodes are used for time-series data that is queried less frequently than data_warm nodes. These nodes are generally optimized for lower storage costs rather than search speed.
- data_frozen: When data is rarely searched, it can be moved to a node with the data_frozen role. Data remains in data_frozen nodes for the rest of its life.
- ingest: Ingest nodes are used to transform and enrich data before indexing
- ml: ml are machine learning nodes.
- remote_cluster_client: This role allows the node to connect to remote clusters.
- transform: Transformations are processed on nodes with this role.
At a minimum, every cluster requires the master and data (or data_content and data_hot) roles. See Node for more information about role definitions and helpful tips to select the number of nodes and role type for the environment. Multiple nodes for some roles may be necessary if the cluster grows and contains heavy data transformations and machine learning tasks. For example, separating master, data, transformation, and machine learning nodes may help with performance and provide more flexible and possible scaling options.
Adoption of Elasticsearch
enlyft.com reports that 36,655 companies use Elasticsearch. Stackshare.io also reports that many organizations use Elasticsearch. According to enlyft.com, smaller companies often use Elasticsearch. However, larger sized companies use Elasticsearch too. Several sources indicated that Accenture, Adobe, Facebook, Firefox, Fujitsu, LinkedIn, Netflix, Quora, Slack, Stack Exchange, Stack Overflow, Tripwire, Uber, Udemy, Wikimedia, and Yelp use Elasticsearch. Starting in 2015, Wikimedia has made available weekly dumps of indexes for each wiki. The current weekly dumps can be found here. A discussion of how to load Elasticsearch with the dumps is found here.
Logstash
Logstash is a free and open-source pipeline that collects data from multiple sources and in many formats. After collecting data, Logstash processes the data and forwards events and log messages along with the data to a stash—in this case, to Elasticsearch. Logstash is a server-side data collector and processor in Elastic Stack and provides greater flexibility in terms of processing and transforming events than what Elasticsearch ingest nodes can do. Logstash, with its rich feature set and over 200 available plugins, can be considered a data ETL tool for Elasticsearch. If a wanted plug-in does not exist, a powerful API is available to develop the plug-in.
An advanced use case for Logstash is that Logstash, along with the grok plug-in, can dynamically transform unstructured to structured data. While another use case can be the deciphering of geo coordinates from IP addresses. Logstash’s wide variety of output types provide the data to be routed where it is needed. Data transformation possibilities and use cases are too many to enumerate.
Logstash uses a persistent queue feature with the main goal of avoiding data loss during abnormal failures. The use of the persistent queue feature gives Logstash the ability to provide what it calls the At-Least-Once delivery guarantee. At-Least-Once delivery guarantees that upon a failure, any unacknowledged event will be replayed once Logstash is restarted. The persistent queue also provides Logstash with the ability to take in small load spikes without holding up connections and using an external queue layer.
Kibana
Kibana is an open-source web interface that interacts with Elasticsearch and is the analytics and visualization plug-in used by Elastic Stack. Kibana provides the user with several different ways to view and analyze the data. Some options include: charts, graphs, tables, and maps. The data that Kibana presents is from real-time Elasticsearch queries. Kibana can also apply machine learning, when enabled with X-Pack, to data to learn data behavior and trends. The advanced machine learning of Kibana can detect data anomalies as soon as possible.
Beats
Beats are free, lightweight open-platform data shipper agents. There are different types of Beats data shippers, each designed to collect specific data and for a specific purpose. Of the available Beats agents, Filebeats and Metricbeats are the most used data shippers. Beats can be installed on a stand-alone or multipurpose server, from which the data shippers will fetch and send data directly to Elasticsearch or to Logstash (see Figure 6). Beats also provide integrated default dashboards that can be configured in Kibana to visualize the data.
Beats packages data using the open-source ECS specification and should be sufficient for most use cases. However, if additional data transformation and parsing is needed before storing in Elasticsearch, Beats can forward data to Logstash.
Two Beats data shippers are discussed below. For the full list of Beats provided by Elastic, see Beats: Data Shippers for Elasticsearch.
Filebeat
Filebeat, a lightweight data shipper, can collect an assortment of files, including log files, and send the file content to Elasticsearch or to Logstash. Once data are in Elasticsearch, Kibana can be used to analyze and visually present findings.
Filebeat provides modules for common log files. The modules reduce the amount of effort and simplify the process of getting logs in to Elasticsearch, including how to process a multiline log entry. The modules are well suited for simple use cases as there is no additional configuration needed.
Two commonly monitored logs are web access and error logs. Web access logs can be mined to determine how long a web server took to process each request. If response times spike, it could be an indication that an infrastructure issue has occurred. Web error logs can be mined to detect faulty code that passed through testing without being detected. Application logs can also be mined for specific needs. Filebeat provides many modules for various applications including: Apache web server, Elasticsearch, Iptables, Kibana, Logstash, MongoDB, MSSQL, MySQL, Oracle, and Linux system. For a full list of Filebeat modules, see Filebeat Reference.
When processing a file, Filebeats remembers its current location within the file. If an interruption occurs, Filebeats resumes from its last known location within the file.
The data shipping protocol used by Filebeats incorporates a backpressure scheme. Should either Elasticsearch or Logstash be overwhelmed with other processing while Filebeats is sending data, Filebeats will be notified to slow down. When there is no more congestion, Filebeat will pick up speed in shipping data to its original pace.
Metricbeat
Metricbeat is designed to collect system level metrics like CPU and memory usage, or to collect service type metrics like which services are running on the system. Metricbeat can also monitor specific processes or components within an application.
When configuring Metricbeat, Metricbeat can be instructed to create and configure a default dashboard automatically in Kibana. This default dashboard could be considered a template dashboard and can be customized. Since Metricbeat does not communicate with Kibana, this default dashboard is configured in Kibana by way of Kibana storing its configuration data in Elasticsearch. Kibana refers to this configuration information in Elasticsearch to create the necessary dashboard for Metricbeat.
Once Metricbeat is configured in Kibana, Kibana can present visualizations of how a system or application is performing. Alerts can be configured in Kibana to instruct Kibana to send notification when specific thresholds have been reached. For example, Kibana can send notification when CPU or memory usage thresholds have been reached.
Metricbeat can monitor various services or applications through its internal modules. Some examples of Metricbeat modules are: Apache, Elasticsearch, Kibana, Linux, Logstash, MongoDB, Oracle, and System. For a complete list of Metricbeat modules, see Metricbeat Modules.
Other Elastic Stack components
More free or subscription-based Elastic products and components are available to add to and enhance the Elastic Stack experience. Some examples are:
Elastic Enterprise Search is a set of specialized tools and APIs that assist the user in building solutions and is part of Elasticsearch. The tools provide analytics to monitor performance and provide ways to adjust data scale and relevance. For more information, see Elastic Enterprise Search.
Elastic Observability monitors and becomes more aware of and understand distributed data within a stack. Elastic Observability can also collapse data silos and bring data together in a unified solution. For more information, see Elastic Observability.
Elastic Fleet Agent is a single unified agent that resides on each host where data needs to be collected. The agent can get the data into the Elastic stack more easily through the centralized management of the unified Elastic Agent. For more information, see Fleet and Elastic Agent Guide.
Application Performance Monitoring (APM) accelerates the development of and improves application code. APM can be used to quickly determine root cause issues and gain deeper visibility into correlated data. For more information, see Application Performance Monitoring (APM).
Elastic security can be enhanced with Security Information Event Monitory (SIEM) and security analytics for the modern Security Operation Center (SOC). Elastic security detects, investigates, and responds to security threats. SIEM can also increase host visibility and control. Elastic security also provides endpoint security and prevents ransomware and malware, detects advanced threats, and arms responders with vital context. For more information, see Elastic Security.
Elastic Stack use cases
Elastic Stack can be used in a vast range of simple to complex use cases. A use case could be as simple as basic log or system monitoring and analysis and extends to whatever the imagination can conceive. Elastic Stack can be used for, but is not limited to, logging, data transformation, searching, data analysis, machine learning, and event monitoring. Here are two simple use cases:
Resource monitoring
System resource statistics can be ingested and analyzed to determine if resource consumption is reaching a threshold. If thresholds are reached, it could be an indication that the business has outgrown the current environment or that something has gone wrong. In either case, necessary steps could be taken to avoid performance issues from overcommitted resources. This type of use case can extend to other type of objects. Two examples of additional objects are applications and specific processes.
Log management
Logs, whether system logs like /var/log or application logs, can be monitored for anomalies or specific events. The data could be pushed to Elasticsearch from either Logstash or Beats. Once the data are in Elasticsearch, the data can be queried and analyzed. Kibana can be used to present the analysis in graphical form giving the user a better understanding of the anomalies or events.