
Sentiment analysis with NLP
Sentiment analysis with NLP
-
NLP is one of the key use cases supported by H2O Driverless AI. The H2O Driverless AI platform can support both stand-alone text and text with other column types as predictive features. TensorFlow-based and PyTorch Transformer Architectures (for example, BERT) are used for feature engineering and model building. H2O.ai has also validated this use case and made results available in their documentation.
We used a classic example of sentiment analysis of tweets using the US Airline Sentiment dataset. The sentiment of each tweet was labeled in advance and our model was used to label new tweets.
The following table shows some samples from the dataset:
Table 2. Example rows in dataset
Tweet
Sentiment
@<Airline1> it was amazing, and arrived an hour early. You're too good to me.
Positive
@<Airline2> hey me and my family have questions on a trip to Disney world that we are doing in April. Please follow me so I could dm you guys
Neutral
@<Airline2>thank you for not even coming with a solution. Great service I might say...as a TrueBlue member I am totally dissatisfied...thanks
Negative
The following table describes the hardware and software of the two configurations used for validating this design. The software versions were the latest during the time of validation. Newer versions might be available after the publication of this white paper and are fully supported:
Table 3. Validation setup
Category
Components in VMware vSphere with Tanzu
Components in Symworld Cloud Native Platform
3 x PowerEdge R750xa servers, each with 2 x NVIDIA A100 80 GB GPUs
4 x R7525 each with 2 x NVIDIA A100 80 GB
Virtualization and container orchestration
VMware vSphere 7.0U3 and VMware vSphere with Tanzu
Symworld Cloud Native Platform (version 5.3.11-217)
AI Enterprise software
NVIDIA AI Enterprise (version 1.1)
NVIDIA GPU Operator (version 1.11.1)
Storage
vSAN
Symworld Cloud Native Storage
Network switches
- Dell S5248F-ON (for workload and management)
- Dell S4148T-ON OOB
- Dell S5248F-ON (for workload and management)
- Dell S4148T-ON OOB
AutoML platform
- Driverless AI (1.10.2)
- Enterprise Steam (1.8.12)
- Driverless AI (1.10.2)
- Enterprise Steam (1.8.12)
H2O Driverless AI instance configuration
Number of CPUs: 16
Number of GPUs: 1
Memory: 64 GB
Storage: 512 GB
Number of CPUs: 16
Number of GPUs: 1
Memory: 64 GB
Storage: 512 GB
[1] The validated use case does not fully utilize the cluster. The listed servers are the minimum number of servers recommended in a cluster.
Data ingestion—The US Airline Sentiment dataset is available in Kaggle. We uploaded the dataset to the H2O Driverless AI local repository.
Data preparation—Using H2O Driverless AI, we split the dataset into training, validation, and test sets. We used the tweets in the ‘text’ column and the sentiment (positive, negative, or neutral) in the ‘airline_sentiment’ column for this demonstration. Because we did not want to use other columns in the dataset, we clicked Dropped Cols, and then excluded everything. We also used the visualization feature for a better understanding of the dataset, as shown in the following figure:
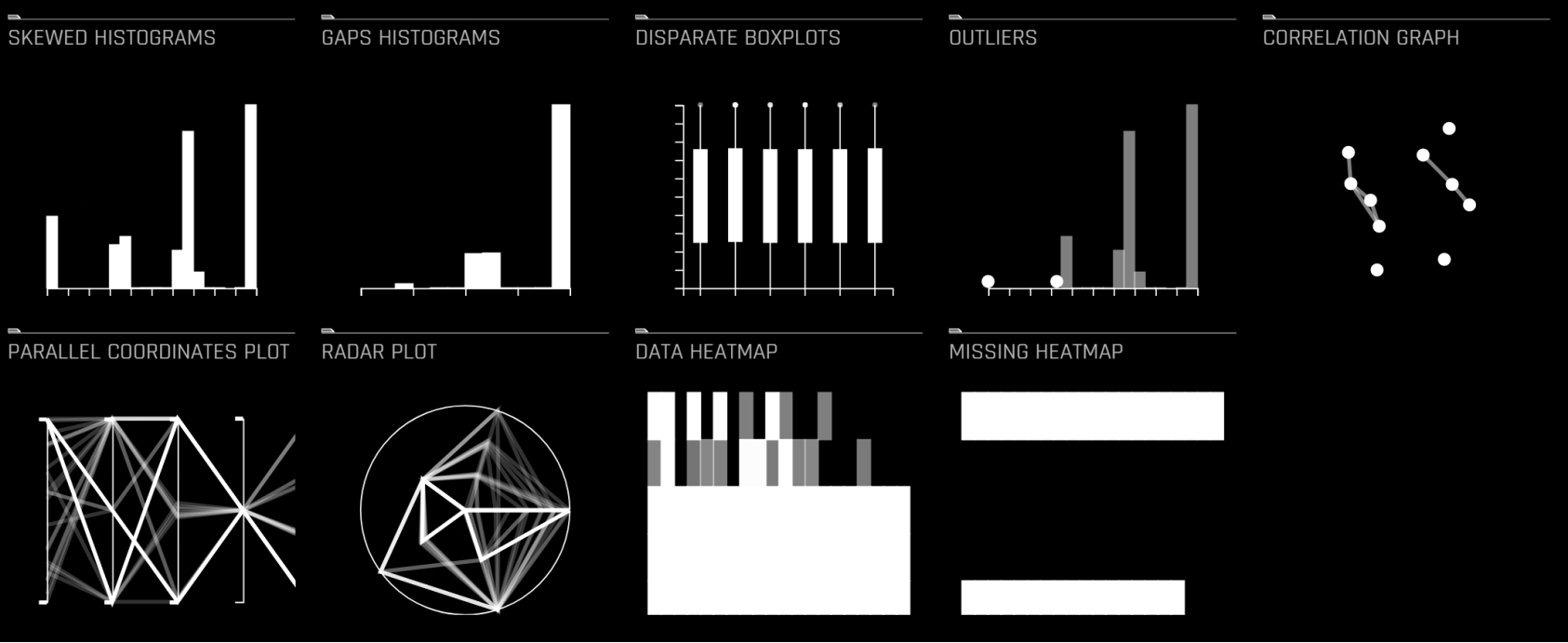
Figure 6. Data visualization options in H2O Driverless AI
Model Building—We configured the experiment using the settings shown in the following figure and then ran the experiment. Text features were automatically generated and evaluated during the feature engineering process. Some features such as TextCNN rely on TensorFlow models can be accelerated through GPUs. We verified the use of GPUs using the nvidia-smi command.
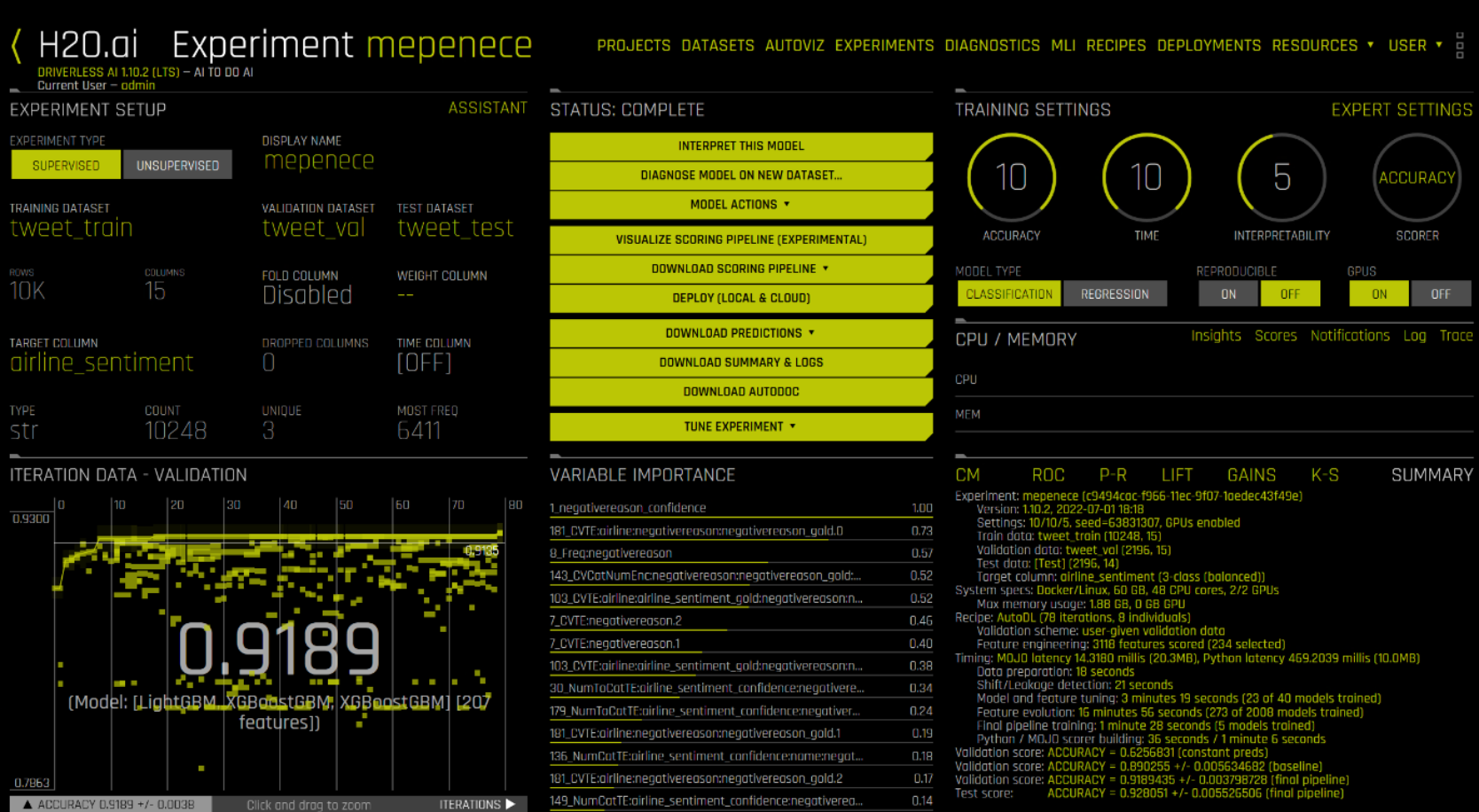
Figure 7. Completed experiment for sentiment analysis
Productization—When the experiment is completed, you can make new predictions and download the scoring pipeline as with any other H2O Driverless AI experiments. The model is then pushed to production and made available for prediction through a REST end point. We downloaded the MOJO Scoring Pipeline and built a container for it. The instructions for building the container are available in H2O’s GitHub.
We used the following Dockerfile to build the container:
FROM ubuntu:18.04
# Install necessary dependencies ls -al
RUN apt-get update && \
apt-get -y install --no-install-recommends \
build-essential \
ca-certificates \
openjdk-11-jdk \
&& rm -rf /var/lib/apt/lists/*
# Install H2O.ai Inference server
RUN mkdir -p /opt/H2O
WORKDIR /opt/H2O
COPY /opt/H2O/DAI-Mojo2-RestServer-1.0.jar ./
COPY H2OaiRestServer.properties ./
COPY license.sig ./
COPY pipeline.mojo ./
COPY goRestServerStart.sh ./
Run /bin/sh -c 'chmod a+x goRestServerStart.sh'
ENTRYPOINT ["/bin/sh","./goRestServerStart.sh"]
We then built a Kubernetes service to deploy the container. Using the external IP address configured for the service, we can access the REST end point. We tested the end point with the following curl command and received the following output:
$ curl -X POST -d '{"fields": ["text"], "rows": [["@Airlines You are horrible. Really bad food"]]}' http://<external-ip>/model/score -H "Content-Type: application/json”
{"id":"92fcc278-e8e5-11ec-9e4d-06f524030811","fields":["airline_sentiment.negative","airline_sentiment.neutral","airline_sentiment.positive"],"score":[["0.14810233","0.13797826","0.7139194"]]}