
The challenges of distributed data
The challenges of distributed data
-
While a microservices architecture can help transform legacy applications into modern, scalable applications, another challenge of application modernization is designing a distributed database model that can span data centers, provide high availability, and deliver high-performance data processing capabilities.
Apache Hadoop, a scalable data-storage and analytics system, provides a model for storing and processing large, distributed datasets. The architecture of Apache Hadoop is distributed, meaning that data is distributed across multiple nodes. These clusters of Apache Hadoop nodes can be in a single data center, or they can span multiple data centers.
While Apache Hadoop paved the way for large-scale analytics across large, distributed datasets, it is better suited for batch processing than for real-time analysis of unstructured data. NoSQL databases, such as Apache Cassandra, fill the gap for real-time storage and analysis of high-velocity unstructured, semistructured, and structured data.
Like Apache Hadoop, NoSQL databases can scale horizontally to provide fast read/write access to various datatypes. Apache Hadoop and NoSQL databases differ in that Apache Hadoop is not intended to be a database-management system (DBMS); rather, it is designed to store and analyze massive amounts of unstructured data. NoSQL databases share the same ability as Apache Hadoop to store and analyze large, distributed datasets. Additionally, NoSQL databases are also designed to store and analyze unstructured, semistructured, and structured data.
The flexibility and variety of NoSQL databases and data models provide an answer to the inherent limitations of relational databases. Data models designed for relational databases have historically contained rigid schemas. While these rigid schemas have served enterprises well for decades, new data sources are pushing the limits of relational database designs. Data sources can now generate data with various structures that do not follow any specification, data model, or organization. Examples of unstructured data include raw sensor data from IoT devices and hand-written patient information created by medical professionals. Semistructured data typically contains tags or markers within the data that identify information, but the data does not comply with a specific relational database schema. Examples of semistructured data include Extensible Markup Language (XML) or JavaScript Object Notation (JSON) documents and email messages.
To avoid the limitations of relational databases, structured and unstructured data must be modeled differently when using a NoSQL database. NoSQL data models include:
- Key-value store—This data model is one of the simplest NoSQL data models. A key-value database stores data as a set of key-value pairs, where the key is a unique identifier. Data within a key-value store can be easily partitioned to allow horizontal scaling. For example, web applications can use key-value stores to manage session information. The key in this example identifies the user, while the values can be user information, user preferences, discounts, or promotions.
- Wide-column store—This data model is similar to relational databases in that data is stored in rows, with each row of data consisting of columns. In a relational database, each column is rigidly defined and maintained across each row of data. For example, in an industrial or manufacturing scenario, a row of data from an IoT refrigeration sensor might contain the sensor’s device ID, the time, the date, and the temperature. Wide-column stores differ in that each row of data can contain a different number of columns, different column names, and different column datatypes than other rows in the same table. Using the IoT refrigeration sensor example, a wide-column store might store the device ID, temperature, and humidity data from a warehouse refrigeration sensor on one row. The data from another device that monitors refrigeration on a truck might include device ID, temperature, humidity, latitude, longitude, and speed on the next row. The wide-column store can capture rows of information from both devices in the same table, even though the columns vary.
- Document store—A document store is designed to store documents that are typically formatted as JSON documents. Like other NoSQL data models, a document store does not adhere to a defined schema. Rather, the structure is internal to the document itself. For example, a health sciences research system can use a document store to consolidate patient data and doctor consultation notes from an electronic health records (EHR) system. Data scientist can then query these records to discover health trends within the consultation notes and correlate them with various patient attributes.
- Graph databases—This data model uses graph structures to represent relationships. Graph databases are ideal for capturing relationships between different data artifacts. For example, financial institutions can use graph databases to analyze the relationships between people, bank accounts, and transactions to discover fraudulent behavior.
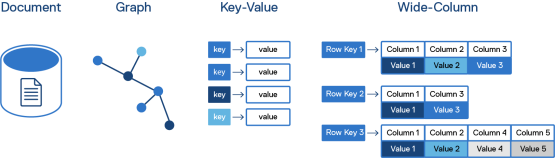
Figure 1. Four NoSQL database models
Enterprises with unstructured, semistructured, and structured data can now rely on NoSQL databases to enable modern microservices-enabled applications that meet the needs of diverse organizations and customers with many different data models.