
Apache Cassandra architecture
Apache Cassandra architecture
-
DataStax Enterprise deployments rely on the node-based ring architecture of Apache Cassandra, which provides resilience, data integrity, and linear scalability.
In a typical Apache Cassandra deployment, each node consists of the Cassandra software running on a commodity physical server, such as a Dell EMC PowerEdge server with Intel Xeon processors. Apache Cassandra nodes can also run in virtual machines (VMs) or Docker containers based on Linux, either on premises or on cloud platforms. Each node runs the same Java-based Cassandra software and is configured through a single configuration file. Clusters can consist of any combination of on-premises physical servers or VMs and cloud resources.
Apache Cassandra clusters are organized into three logical categories:
- Nodes—A node is a physical server, VM, or container that runs an instance of Apache Cassandra.
- Racks—A rack is a set of Apache Cassandra nodes that are near to one another. For example, an on-premises deployment might contain multiple Apache Cassandra nodes in multiple racks within a single data center. In cloud deployments, a rack can refer to multiple instances of Apache Cassandra running in the same availability zone.
- Data centers—A data center is a collection of Apache Cassandra racks. In an on-premises deployment, these racks reside in the same data center and use the same data center network. In a cloud deployment, a data center typically refers to a cloud region.
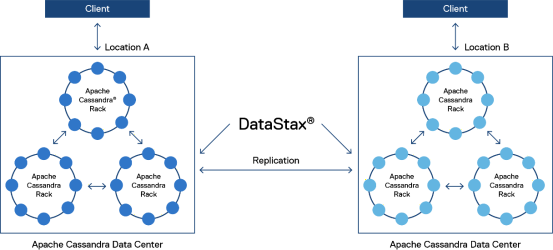
Apache Cassandra organizes data using a ring topology. When data is written to a database, Apache Cassandra creates a token that determines in which nodes the data will reside. Apache Cassandra stores data redundantly across racks and data centers to ensure data availability if nodes become unavailable.Figure 2. Overview of a DataStax Enterprise deployment across multiple data centers; clients can connect to any node within any cluster, while DataStax Enterprise OpsCenter manages all clusters and nodes
When a user or application queries an Apache Cassandra database through client software, the client connects to any node within the cluster. The node to which the client connects then becomes the coordinator node for that query. A coordinator node interacts with other nodes to collect query results, and then it returns the result to the client.