
Overcoming the underperformance of Open RAN systems
Overcoming the underperformance of Open RAN systems
-
A traditional RAN architecture consists of the following:
- A radio base station (that is, the visible tower structure)
- A baseband unit (BBU), typically housed in a small building
With the advent of 4G and network virtualization, vRAN solutions began to appear. These vRAN solutions disaggregated the BBU functionality—the distributed unit (DU), centralized unit (CU), and radio unit (RU)—into virtualized, software-based modules. These modules could be deployed on commercial off-the-shelf (COTS) hardware rather than a traditional bundled appliance. While disaggregation and virtualization made BBUs less expensive to deploy and easier to scale, the performance of COTS hardware (which featured a general-purpose design) failed to match the performance of purpose-built BBU appliances.
The goal of vRAN and Open RAN solutions is to achieve (and ultimately exceed) cost and performance parity with the traditional RAN systems they aim to displace. Until now, this has been challenging because of the underperformance of the virtualized Distributed Unit (vDU) function on COTS servers. The vDU plays an essential role in vRAN and Open RAN systems, including the upper Layer 1 (data transmission) and Layer 2 (network transmission) processing. Traditional BBUs feature highly optimized hardware designed to support Layer 1 and Layer 2 processing for RAN workloads. Because COTS hardware (such as Intel-based servers) is not natively optimized for RAN workloads, they tend to have lower performance characteristics under certain workload conditions. The performance gap between traditional BBU appliances and vRAN/Open RAN solutions is one of the main barriers to widespread 5G RAN adoption.
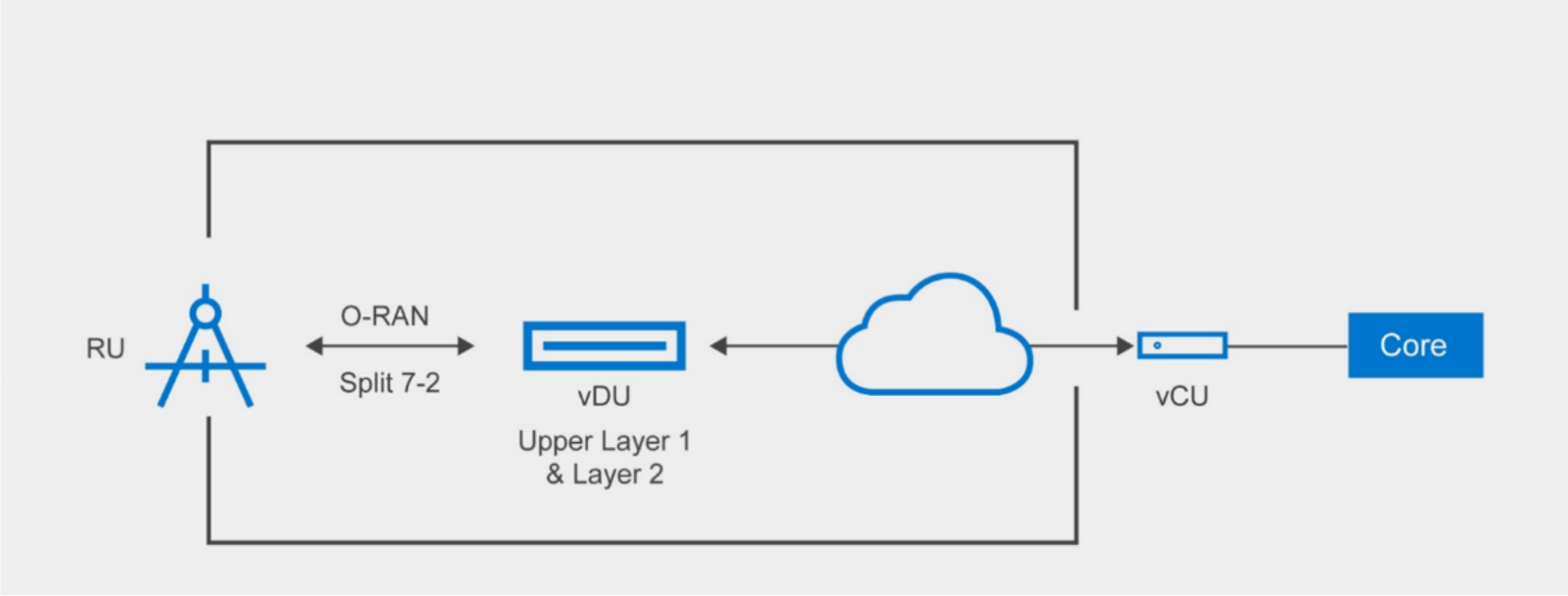
Figure 1. vDU in Open RAN deployments
Until now, Layer 1 processing has been the Achilles’ heel of vRAN and Open RAN systems. In a standard Open RAN Split 7.2 architecture, Layer 1 processing is split into upper and lower layers. The RU handles lower Layer 1 processing, while the vDU does the upper Layer 1 processing (see Figure 1). Today, most vDUs use a “look-aside” method to shift a subset of Layer 1 operations—mainly the Forward Error Correction (FEC) processing—to a standard PCIe accelerator card. This “look-aside” method results in back-and-forth communications for Layer 1 processing between the accelerator card and the central processing unit (CPU). This helps performance but does not solve the performance gap versus traditional RAN systems.