
Assets

Kubernetes Node Non-Graceful Shutdown and Remediation: Insights from Dell Technologies

Tue, 12 Dec 2023 18:16:57 -0000
|Read Time: 0 minutes
Introduction
Kubernetes has become a pivotal technology in managing containerized applications, but it's not without its challenges, particularly when dealing with Stateful Apps and non-graceful shutdown scenarios. This article delves into the intricacies of handling such situations, drawing insights from Dell Technologies' expertise and more importantly, how to enable it.
Understanding Graceful vs. Non-Graceful Node Shutdowns in Kubernetes
A 'graceful' node shutdown in Kubernetes is an orchestrated process. When kubelet detects a node shutdown event, it terminates the pods on that node properly, releasing resources before the actual shutdown. This orderly process allows critical pods to be terminated after regular pods, ensuring an application continues operating as long as possible. This process is vital for maintaining high availability and resilience in applications.
However, issues arise with a non-graceful shutdown, like a hard stop or node crash. In such cases, kubelet fails to detect a clean shutdown event. This leads to Kubernetes marking the node ‘NotReady', and Pods in a Stateful Set can remain stuck in 'Terminating' mode indefinitely!
Kubernetes adopts a cautious approach in these scenarios since it cannot ascertain if the issue is a total node failure, a kubelet problem, or a network glitch. This distinction is critical, especially for stateful apps, where rescheduling amidst active data writing could lead to severe data corruption.
Role of Dell's Container Storage Module (CSM) for Resiliency
Dell's CSM for Resiliency plays a crucial role in automating decision-making in these complex scenarios, aiming to minimize manual intervention and maximize uptime. The module's functionality is highlighted through a typical workflow:
- Consider a pod with two mounted volumes, annotated for protection with CSM resiliency.
- Upon an abrupt node power-off, the Kubernetes API detects the failure, marking the node as 'Not Ready'.
- The podmon controller of CSM Resiliency then interrogates the storage array, querying its status regarding the node and volumes.
- Depending on its findings and a set heuristic, the module determines whether it's safe to reschedule the pod.
- If rescheduling is deemed safe, the module quickly fences off access for the failed node, removes the volume attachment, and force-deletes the pod, enabling Kubernetes to reschedule it efficiently.
The following tutorial allow to test the functionality live: https://dell.github.io/csm-docs/docs/interactive-tutorials/
How to enable the module ?
To take advantage of the CSM resiliency you need two things:
- Enable it for your driver, for example with PowerFlex
- With the CSM wizard, just check the resiliency box
- With the Operator just set enable: true in the section .spec.modules.name['resiliency']
- With the helm chart set enable: true in the section .csi-vxflexos.podmon
- Then protect you application by adding the magic label podmon.dellemc.com/driver: csi-vxflexos
Conclusion:
Managing non-graceful shutdowns in Kubernetes, particularly for stateful applications, is a complex but essential aspect of ensuring system resilience and data integrity.
Tools like Dell's CSM for Resiliency are instrumental in navigating these challenges, offering automated, intelligent solutions that keep applications running smoothly even in the face of unexpected failures.
Sources
Stay informed of the latest updates of Dell CSM eco-system by subscribing to:
* The Dell CSM Github repository
* Our DevOps & Automation Youtube playlist
* The Slack

Driving Innovation with the Dell Validated Platform for Red Hat OpenShift and IBM Instana
Wed, 14 Dec 2022 21:20:39 -0000
|Read Time: 0 minutes
“There is no innovation and creativity without failure. Period.” – Brené Brown
In the Information Technology field today, it seems like it’s impossible to go five minutes without someone using some variation of the word innovate. We are constantly told we need to innovate to stay competitive and remain relevant. I don’t want to spend time arguing the importance of innovation, because if you’re reading this then you probably already understand its importance.
What I do want to focus on is the role that failure plays in innovation. One of the biggest barriers to innovation is the fear of failure. We have all experienced some level of failure in our lives, and the costly mistakes can be particularly memorable. To create a culture that fosters innovation, we need to create an environment that reduces the costs associated with failure – these can be financial costs, time costs, or reputation costs. This is why one of the core tenets of modern application architecture is “fail fast”. Put simply, it means to identify mistakes quickly and adjust. The idea is that a flawed process or assumption will cost more to fix the longer it is present in the system. With traditional waterfall processes, that flaw could be present and undetected for months during the development process, and in some cases, even make it through to production.
While the benefits of fail fast can be easy to see, implementing it can be a bit harder. It involves streamlining not just the development process, but also the build process, the release process, and having proper instrumentation all the way through from dev to production. This last part, instrumentation, is the focus of this article. Instrumentation means monitoring a system to allow the operators to:
- See current state
- Identify application performance
- Detect when something is not operating as expected
While the need for instrumentation has always been present, developers are often faced with difficult timelines and the first feature areas that tend to be cut are testing and instrumentation. This can help in the short term, but it often ends up costing more down the road, both financially and in the end-user experience.
IBM Instana is a tool that provides observability of complete systems, with support for over 250 different technologies. This means that you can deploy Instana into the environment and start seeing valuable information without requiring any code changes. If you are supporting web-based applications, you can also take things further by including basic script references in the code to gain insights from client statistics as well.
Announcing Support for Instana on the Dell Validated Platform for Red Hat OpenShift
Installing IBM Instana into the Dell Validated Platform for Red Hat OpenShift can be done by Operator, Helm Chart, or YAML File.
The simplest way is to use the Operator. This consists of the following steps:
- Create the instana-agent project
- Set the policy permissions for the instana-agent service account
- Install the Operator
- Apply the Operator Configuration using a custom resource YAML file
You can configure IBM Instana to point to IBM’s cloud endpoint. Or for high security environments, you can choose to connect to a private IBM Instana endpoint hosted internally.

Figure 1. Infrastructure view of the OpenShift Cluster
Once configured, the IBM Instana agent starts sending data to the endpoint for analysis. The graphical view in Figure 1 shows the overall health of the Kubernetes cluster, and the node on which each resource is located. The resources in a normal state are gray: any resource requiring attention would appear in a different color.
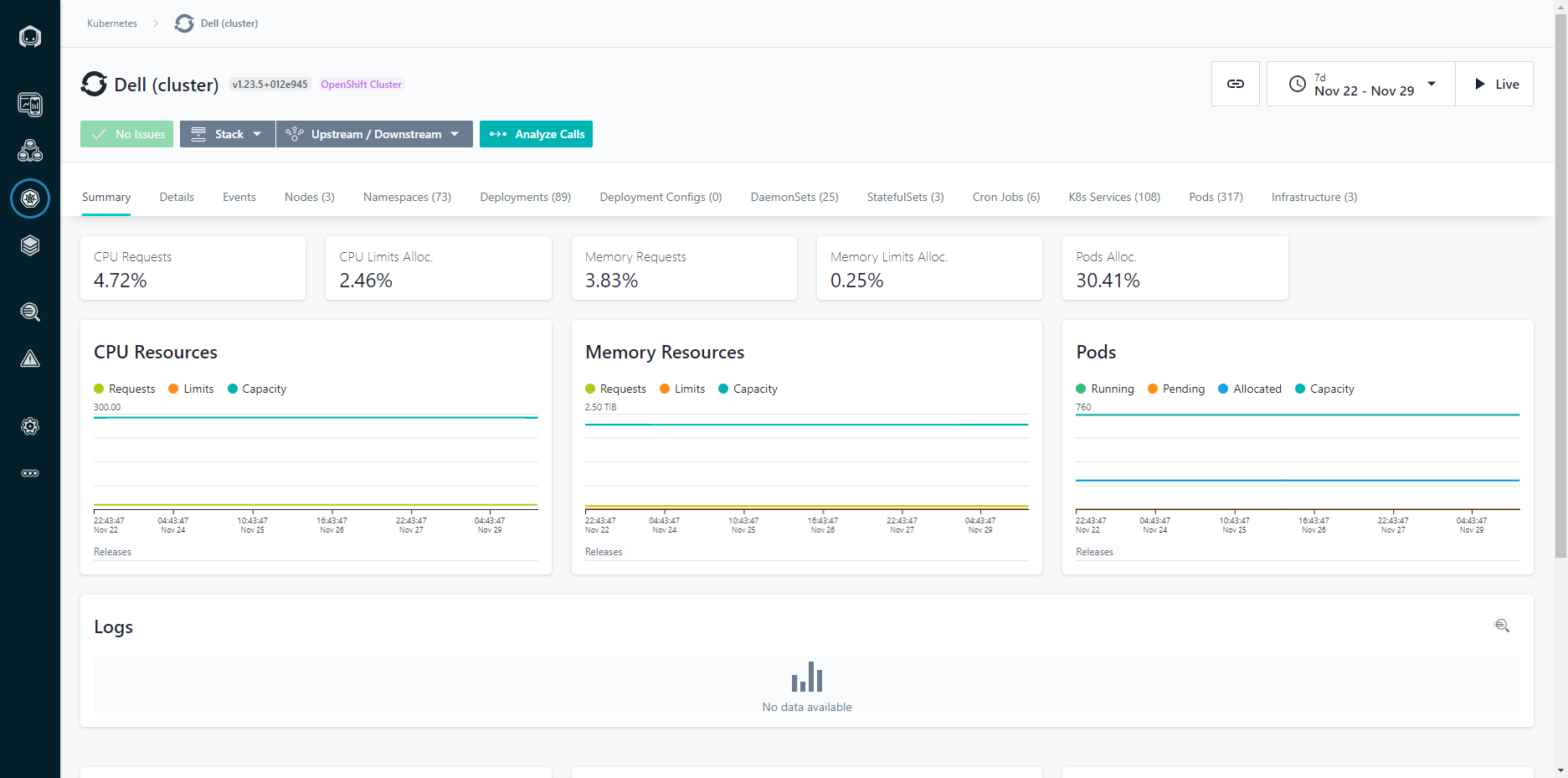
Figure 2: Cluster View
We can also see the metrics across the cluster, including CPU and Memory statistics. The charts are kept in time sync, so if you highlight a given area or narrow the time period, all of the charts remain in the same context. This makes it easy to identify correlations between different metrics and events.
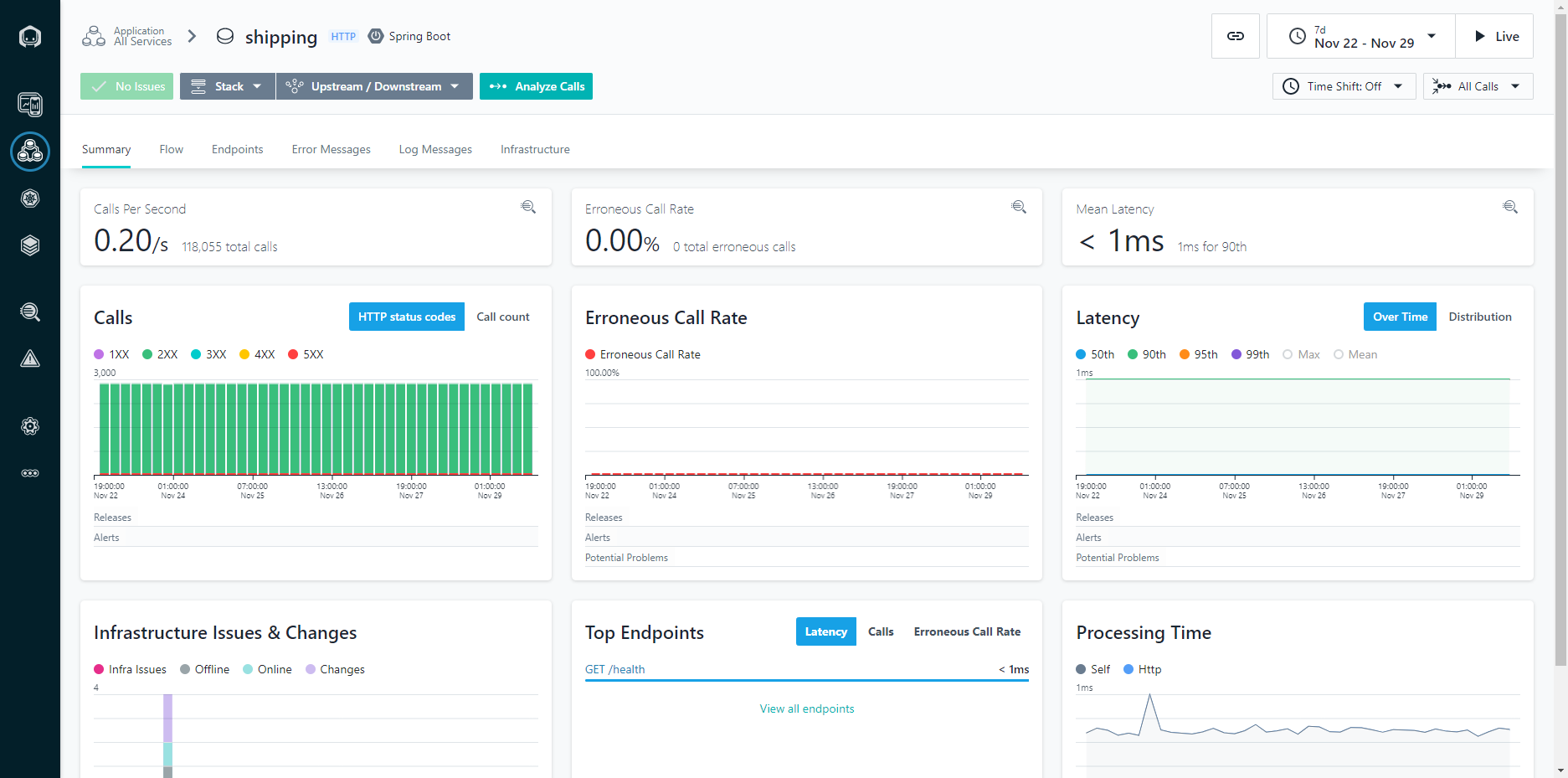
Figure 3: Application Calls View
Looking at the application calls allows you to see how a given application is performing over time. Being able to narrow down to a one second granularity means that you can actually follow individual calls through the system and see things like the parameters passed in the call. This can be incredibly helpful for troubleshooting intermittent application issues.
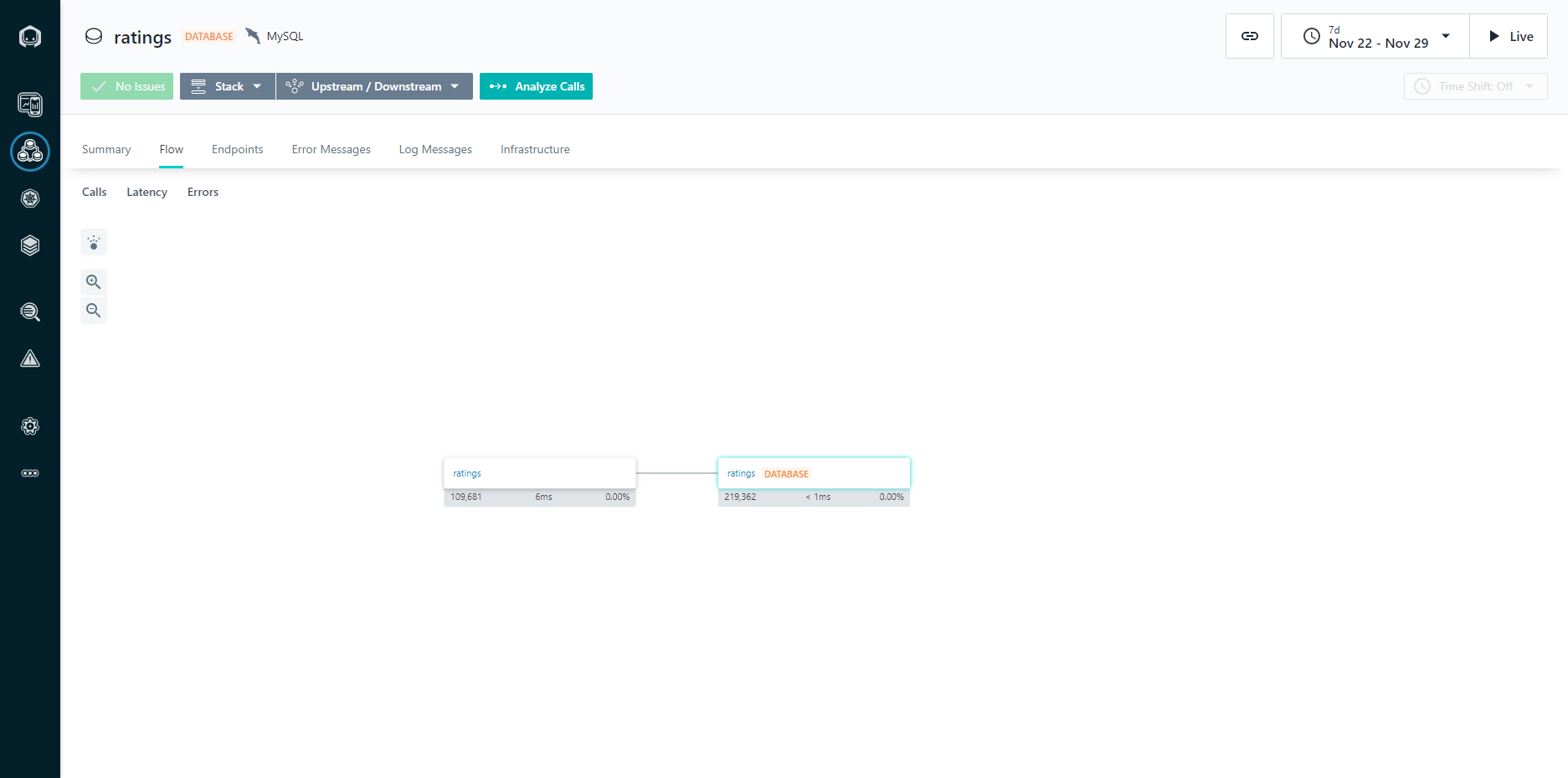
Figure 4: Application Dependencies View
The dependencies view gives you a graphical representation of all the components within a system and how they relate to each other, in a dependency diagram. This is critically important in modern application design because as you implement a larger number of more focused services, often created by different DevOps teams, it can be difficult to keep track of what services are being composed together.
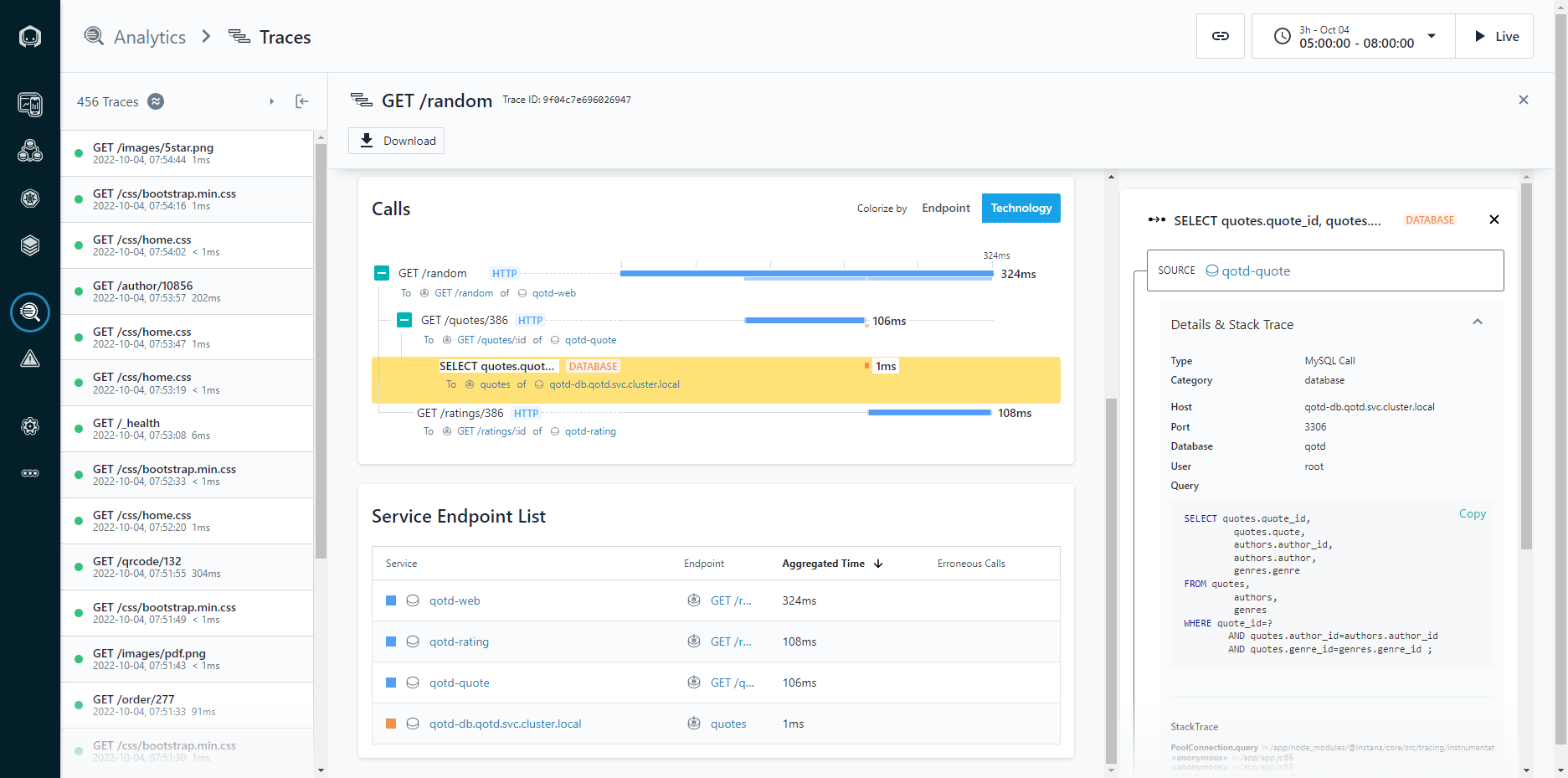
Figure 5: Application Stack Traces
The application stack trace allows you to walk the stack of an application to see what calls were made, and how much time each call took to complete. Knowing that a page load took five seconds can help indicate a problem, but being able to walk the stack and identify that 4.8 seconds was spent running a database query (and exactly what query that was) means that you can spend less time troubleshooting, because you already know exactly what needs to be fixed.
For more information about the Dell Validated Platform for Red Hat OpenShift, see our launch announcement: Accelerate DevOps and Cloud Native Apps with the Dell Validated Platform for Red Hat OpenShift | Dell Technologies Info Hub.
Author: Michael Wells, PowerFlex Engineering Technologist
Twitter: @SqlTechMike
LinkedIn

Accelerate DevOps and Cloud Native Apps with the Dell Validated Platform for Red Hat OpenShift
Thu, 15 Sep 2022 13:28:43 -0000
|Read Time: 0 minutes
Today we announce the release of the Dell Validated Platform for Red Hat OpenShift. This platform has been jointly validated by Red Hat and Dell, and is an evolution of the design referenced in the white paper “Red Hat OpenShift 4.6 with CSI PowerFlex 1.3.0 Deployment on Dell EMC PowerFlex Family”.
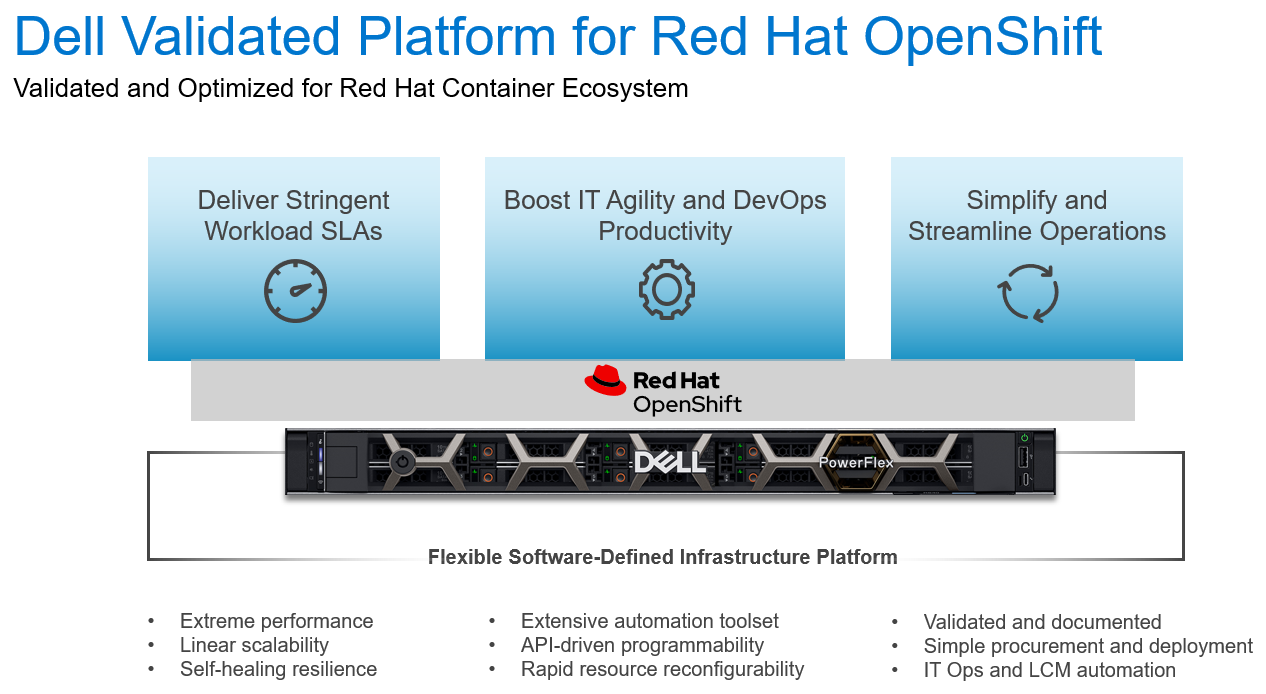
Figure 1: The Dell Validated Platform for Red Hat OpenShift
The world is moving faster and with that comes the struggle to not just maintain, but to streamline processes and accelerate deliverables. We are no longer in the age of semi-annual or quarterly releases, as some industries need multiple releases a day to meet their goals. To accomplish this requires a mix of technology and processes … enter the world of containers. Containerization is not a new technology, but in recent years it has picked up a tremendous amount of steam. It is no longer just a fringe technology reserved for those on the bleeding edge; it has become mainstream and is being used by organizations large and small. However, technology alone will not solve everything. To be successful your processes must change with the technology – this is where DevOps comes in. DevOps is a different approach to Information Technology; it involves a blending of resources usually separated into different teams with different reporting structures and often different goals. It systematically looks to eliminate process bottlenecks and applies automation to help organizations move faster than they ever thought possible. DevOps is not a single process, but a methodology that can be challenging to implement.
Why Red Hat OpenShift?
Red Hat OpenShift is an enterprise-grade container orchestration and management platform based on Kubernetes. While many organizations understand the value of moving to containerization, and are familiar with the name Kubernetes, most don’t have a full grasp of what Kubernetes is and what it isn’t. OpenShift uses their own Kubernetes distribution, and layers on top critical enterprise features like:
- Built-in underlying hardware management and scaling, integrated with Dell iDRAC
- Multi-Cluster deployment, management, and shift-left security enforcement
- Developer Experience – CI/CD, GitOps, Pipelines, Logging, Monitoring, and Observability
- Integrated Networking including ServiceMesh and multi-cluster networking
- Integrated Web Console with distinct Admin and Developer views
- Automated Platform Updates and Upgrades
- Multiple workload options – containers, virtual machines, and serverless
- Operators for extending and managing additional capabilities
All these capabilities mean that you have a full container platform with a rigorously tested and certified toolchain that can accelerate your development, and reduce the costs associated with maintenance and downtime. This is what has made OpenShift the number 1 container platform in the market.

Figure 2: Realizing business value from a hybrid strategy - Source: IDC White Paper, sponsored by Red Hat, "The Business Value of Red Hat OpenShift", doc # US47539121, February 2021.
Meeting the performance needs
Scalable container platforms like Red Hat OpenShift work best when paired with a fast, scalable infrastructure platform, and this is why OpenShift, and Dell PowerFlex are the perfect team. With PowerFlex, organizations can have a single software-defined platform for all their workloads, from bare metal, to virtualized, to containerized. All on a blazing-fast infrastructure that can scale to thousands of nodes. Not to mention the API-driven architecture of PowerFlex fits perfectly in a methodology centered on automation. To help jumpstart customers on their automation journey we have already created robust infrastructure and DevOps automation through our extensive tooling that includes:
- Dell Container Storage Modules (CSM)/Container Storage Interface (CSI) Plugins
- Ansible Modules
- AppSync Integration
Being software-defined means that PowerFlex can deliver linear performance by being able to balance data across all nodes. This ensures that you can spread the work out over the cluster to scale well beyond the limits of the individual hardware components. This also allows PowerFlex to be incredibly resilient, capable of seamlessly recovering from individual component or node failures.
Putting it all together
Introducing the Dell Validated Platform for Red Hat OpenShift, the latest collaboration in the long 22-year partnership between Red Hat and Dell. This platform brings together the power of Red Hat OpenShift with the flexibility and performance of Dell PowerFlex into a single package.
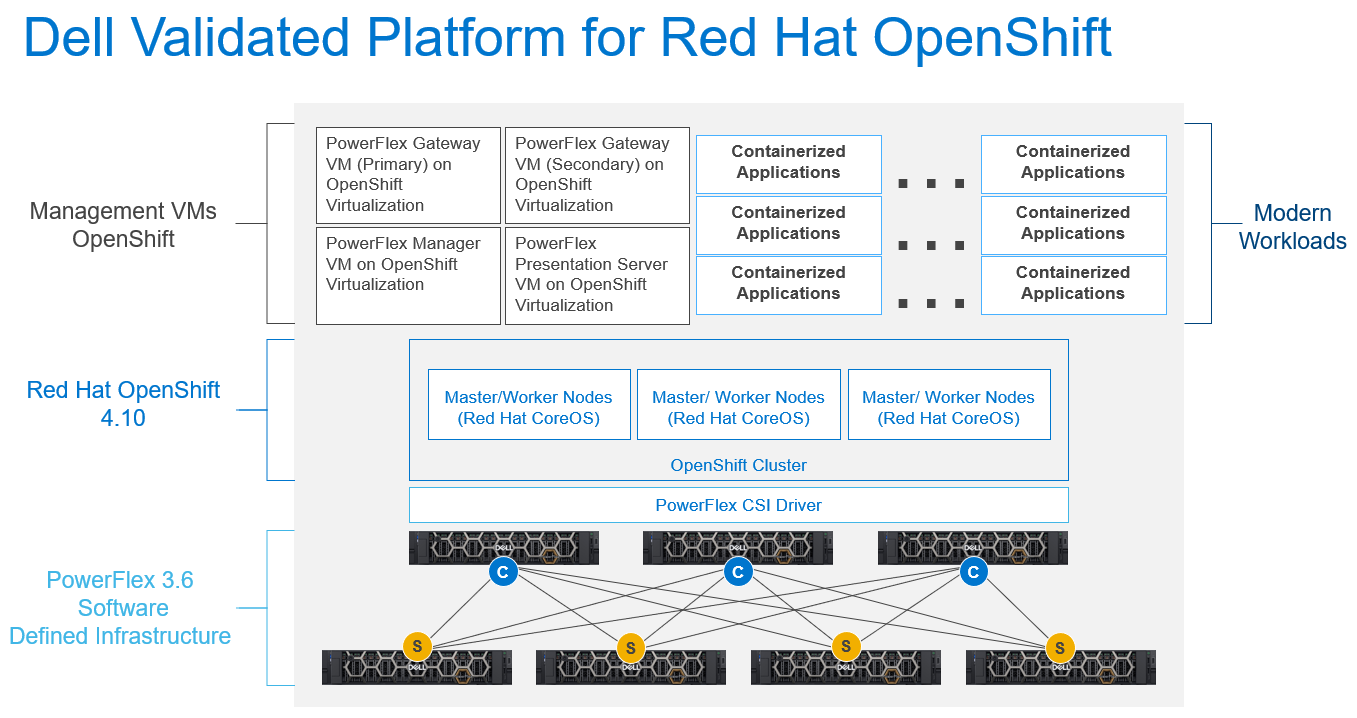
Figure 3: The Dell Validated Platform for Red Hat OpenShift Architecture
This platform uses PowerFlex in a 2-tier architecture to give you optimal performance, and the ability to scale storage and compute independently, up to thousands of nodes. We are also taking advantage of Red Hat capabilities to run PowerFlex Manager and its accompanying services in OpenShift Virtualization to make efficient use of compute nodes and minimize the required hardware footprint.
The combined platform gives you the ability to become more agile and increase productivity through the extensive automation already available, along with the documented APIs to extend that automation or create your own.
This platform has been fully validated by both Dell and Red Hat, so you can run it with confidence. We have also streamlined the ordering process, so the entire platform can be acquired directly from Dell, including the Red Hat software and subscriptions. All of this is implemented using Dell’s ProDeploy services to ensure that the platform is implemented optimally and gets you up and running faster. This means you can start realizing the value of the platform faster, while reducing risk.
If you are interested in getting more information about the Dell Validated Platform for Red Hat OpenShift please contact your Dell representative.
Authors:
Michael Wells, PowerFlex Engineering Technologist
Twitter: @SqlTechMike
LinkedIn
Rhys Oxenham, Director, Customer & Field Engagement