



Unveiling the Power of the PowerEdge XE9680 Server on the GPT-J Model from MLPerf™ Inference
Tue, 16 Jan 2024 18:30:32 -0000
|Read Time: 0 minutes
Abstract
For the first time, the latest release of the MLPerf™ inference v3.1 benchmark includes the GPT-J model to represent large language model (LLM) performance on different systems. As a key player in the MLPerf consortium since version 0.7, Dell Technologies is back with exciting updates about the recent submission for the GPT-J model in MLPerf Inference v3.1. In this blog, we break down what these new numbers mean and present the improvements that Dell Technologies achieved with the Dell PowerEdge XE9680 server.
MLPerf inference v3.1
MLPerf inference is a standardized test for machine learning (ML) systems, allowing users to compare performance across different types of computer hardware. The test helps determine how well models, such as GPT-J, perform on various machines. Previous blogs provide a detailed MLPerf inference introduction. For in-depth details, see Introduction to MLPerf inference v1.0 Performance with Dell Servers. For step-by-step instructions for running the benchmark, see Running the MLPerf inference v1.0 Benchmark on Dell Systems. Inference version v3.1 is the seventh inference submission in which Dell Technologies has participated. The submission shows the latest system performance for different deep learning (DL) tasks and models.
Dell PowerEdge XE9680 server
The PowerEdge XE9680 server is Dell’s latest two-socket, 6U air-cooled rack server that is designed for training and inference for the most demanding ML and DL large models.

Figure 1. Dell PowerEdge XE9680 server
Key system features include:
- Two 4th Gen Intel Xeon Scalable Processors
- Up to 32 DDR5 DIMM slots
- Eight NVIDIA HGX H100 SXM 80 GB GPUs
- Up to 10 PCIe Gen5 slots to support the latest Gen5 PCIe devices and networking, enabling flexible networking design
- Up to eight U.2 SAS4/SATA SSDs (with fPERC12)/ NVMe drives (PSB direct) or up to 16 E3.S NVMe drives (PSB direct)
- A design to train and inference the most demanding ML and DL large models and run compute-intensive HPC workloads
The following figure shows a single NVIDIA H100 SXM GPU:

Figure 2. NVIDIA H100 SXM GPU
GPT-J model for inference
Language models take tokens as input and predict the probability of the next token or tokens. This method is widely used for essay generation, code development, language translation, summarization, and even understanding genetic sequences. The GPT-J model in MLPerf inference v3.1 has 6 B parameters and performs text summarization tasks on the CNN-DailyMail dataset. The model has 28 transformer layers, and a sequence length of 2048 tokens.
Performance updates
The official MLPerf inference v3.1 results for all Dell systems are published on https://mlcommons.org/benchmarks/inference-datacenter/. The PowerEdge XE9680 system ID is ID 3.1-0069.
After submitting the GPT-J model, we applied the latest firmware updates to the PowerEdge XE9680 server. The following figure shows that performance improved as a result:
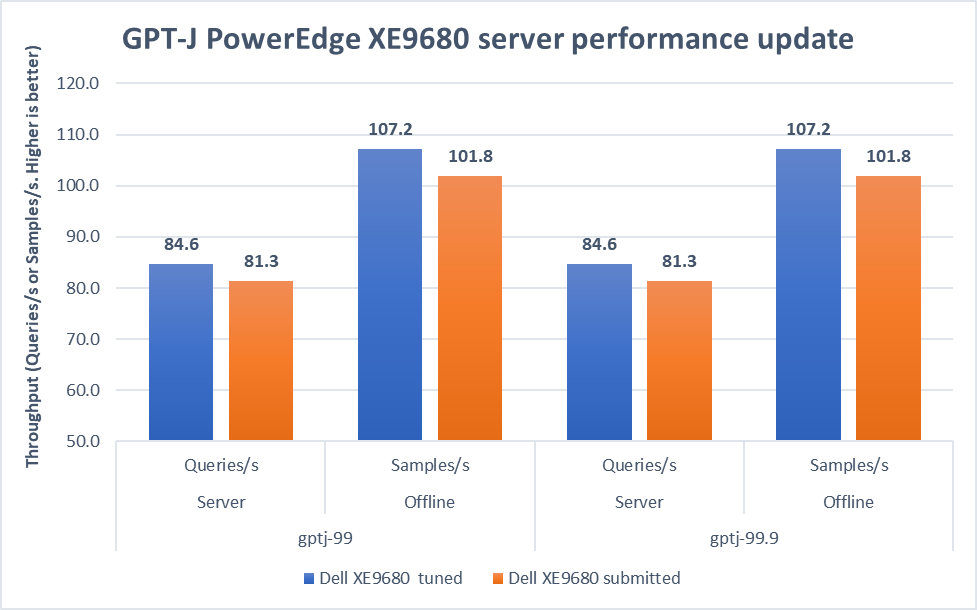
Figure 3. Improvement of the PowerEdge XE9680 server on GPT-J Datacenter 99 and 99.9, Server and Offline scenarios [1]
In both 99 and 99.9 Server scenarios, the performance increased from 81.3 to an impressive 84.6. This 4.1 percent difference showcases the server's capability under randomly fed inquires in the MLPerf-defined latency restriction. In the Offline scenarios, the performance saw a notable 5.3 percent boost from 101.8 to 107.2. These results mean that the server is even more efficient and capable of handling batch-based LLM workloads.
Note: For PowerEdge XE9680 server configuration details, see https://github.com/mlcommons/inference_results_v3.1/blob/main/closed/Dell/systems/XE9680_H100_SXM_80GBx8_TRT.json
Conclusion
This blog focuses on the updates of the GPT-J model in the v3.1 submission, continuing the journey of Dell’s experience with MLPerf inference. We highlighted the improvements made to the PowerEdge XE9680 server, showing Dell's commitment to pushing the limits of ML benchmarks. As technology evolves, Dell Technologies remains a leader, constantly innovating and delivering standout results.
[1] Unverified MLPerf® v3.1 Inference Closed GPT-J. Result not verified by MLCommons Association.
The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.