




MLPerf™ v1.1 Inference on Virtualized and Multi-Instance GPUs

Introduction
Graphics Processing Units (GPUs) provide exceptional acceleration to power modern Artificial Intelligence (AI) and Deep Learning (DL) workloads. GPU resource allocation and isolation are some of the key components that data scientists working in a shared environment use to run their DL experiments effectively. The need for this allocation and isolation becomes apparent when a single user uses only a small percentage of the GPU, resulting in underutilized resources. Due to the complexity of the design and architecture, maximizing the use of GPU resources in shared environments has been a challenge. The introduction of Multi-Instance GPU (MIG) capabilities in the NVIDIA Ampere GPU architecture provides a way to partition NVIDIA A100 GPUs and allow complete isolation between GPU instances. The Dell Validated Design showcases the benefits of virtualization for AI workloads and MIG performance analysis. This design uses the most recent version of VMware vSphere along with the NVIDIA AI Enterprise suite on Dell PowerEdge servers and VxRail Hyperconverged Infrastructure (HCI). Also, the architecture incorporates Dell PowerScale storage that supplies the required analytical performance and parallelism at scale to feed the most data-hungry AI algorithms reliably.
In this blog, we examine some key concepts, setup, and MLPerf Inference v1.1 performance characterization for VMs hosted on Dell PowerEdge R750xa servers configured with MIG profiles on NVIDIA A100 80 GB GPUs. We compare the inference results for the ResNet50 and Bidirectional Encoder Representations from Transformers (BERT) models.
Key Concepts
Key concepts include:
- Multi-Instance GPU (MIG)—MIG capability is an innovative technology released with the NVIDIA A100 GPU that enables partitioning of the A100 GPU up to seven instances or independent MIG devices. Each MIG device operates in parallel and is equipped with its own memory, cache, and streaming multiprocessors.
In the following figure, each block shows a possible MIG device configuration in a single A100 80 GB GPU:
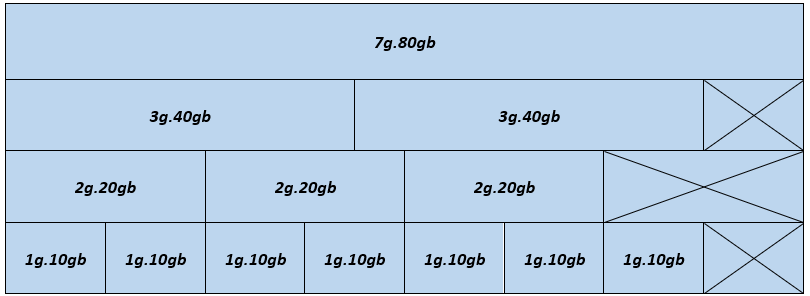
Figure 1- MIG device configuration - A100 80 GB GPU
The figure illustrates the physical location of GPU instances after they have been instantiated on the GPU. Because GPU instances are generated and destroyed at various locations, fragmentation might occur. The physical location of one GPU instance influences whether more GPU instances can be formed next to it.
Supported profiles for the A100 80GB GPU include:
- 1g.10gb
- 2g.20gb
- 3g.40gb
- 4g.40gb
- 7g.80gb
In Figure 1, a valid combination is constructed by beginning with an instance profile on the left and progressing to the right, ensuring that no two profiles overlap vertically. For detailed information about NVIDIA MIG profiles, see the NVIDIA Multi-Instance GPU User Guide.
- MLPERF—MLCommons™ is a consortium of leading researchers in AI from academia, research labs, and industry. Its mission is to "develop fair and useful benchmarks" that provide unbiased evaluations of training and inference performance for hardware, software, and services—all under controlled conditions. The foundation for MLCommons began with the MLPerf benchmark in 2018, which rapidly scaled as a set of industry metrics to measure machine learning performance and promote transparency of machine learning techniques. To stay current with industry trends, MLPerf is always evolving, conducting new tests, and adding new workloads that represent the state of the art in AI.
Setup for MLPerf Inference
A system under test consists of an ESXi host that can be operated from vSphere.
System details
The following table provides the system details.
Table 1: System details
Server | Dell PowerEdge R750xa (NVIDIA-Certified System) |
Processor | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz |
GPU | 4 x NVIDIA A100 PCIe (PCI Express) 80 GB |
Network adapter | Mellanox ConnectX-6 Dual Port 100 GbE |
Storage | Dell PowerScale |
ESXi version | 7.0.3 |
BIOS version | 1.1.3 |
GPU driver version | 470.82.01 |
CUDA version | 11.4 |
System configuration for MLPerf Inference
The configuration for MLPerf Inference on a virtualized environment requires the following steps:
- Boot the host with ESXi (see Installing ESXi on the management hosts), install the NVIDIA bootbank driver, enable MIG, and restart the host.
- Create a virtual machine (VM) on the ESXi host with EFI boot mode (see Using GPUs with Virtual Machines on vSphere – Part 2: VMDirectPath I/O) and add the following advanced configuration settings:
pciPassthru.use64bitMMIO: TRUE pciPassthru.allowP2P: TRUE pciPassthru.64bitMMIOSizeGB: 64
- Change the VM settings and add a new PCIe device with a MIG profile (see Using GPUs with Virtual Machines on vSphere – Part 3: Installing the NVIDIA Virtual GPU Technology).
- Boot the Linux-based operating system and run the following steps in the VM.
- Install Docker, CMake (see Installing CMake), the build-essentials package, and CURL
- Download and install the NVIDIA MIG driver (grid driver).
- Install the nvidia-docker repository (see NVIDIA Container Toolkit Installation Guide) for running nvidia-containers.
- Configure the nvidia-grid service to use the vGPU setting on the VM (see Using GPUs with Virtual Machines on vSphere – Part 3: Installing the NVIDIA Virtual GPU Technology) and update the licenses.
- Run the following command to verify that the setup is successful:
nvidia-smi
Note: Each VM consists of 32 vCPUs and 64 GB memory.
MLPerf Inference configuration for MIG
When the system has been configured, configure MLPerf v1.1 on the MIG VMs. To run the MLPerf Inference benchmarks on a MIG-enabled system under test, do the following:
- Add MIG details in the inference configuration file:
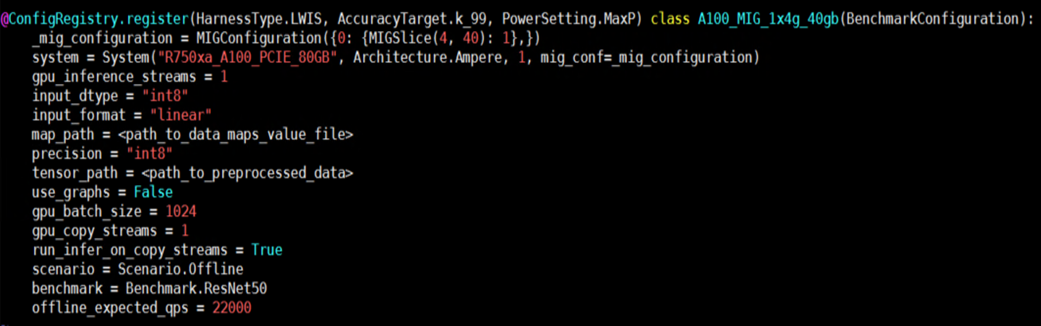 Figure 2- Example configuration for running inferences using MIG enabled VMs
Figure 2- Example configuration for running inferences using MIG enabled VMs - Add valid MIG specifications to the system variable in the system_list.py file.
 Figure 3- Example system entry with MIG profiles
Figure 3- Example system entry with MIG profiles
These steps complete the system setup, which is followed by building the image, generating engines, and running the benchmark. For detailed instructions, see our previous blog about running MLPerf v1.1 on bare metal systems.
MLPerf v1.1 Benchmarking
Benchmarking scenarios
We assessed inference latency and throughput for ResNet50 and BERT models using MLPerf Inference v1.1. The scenarios in the following table identify the number of VMs and corresponding MIG profiles used in performance tests. The total number of tests for each scenario is 57. The results are averaged based on three runs.
Note: We used MLPerf Inference v1.1 for benchmarking but the results shown in this blog are not part of the official MLPerf submissions.
Table 2: Scenarios configuration
Scenario | MIG profiles | Total VMs |
1 | MIG nvidia-7-80c | 1 |
2 | MIG nvidia-4-40c | 1 |
3 | MIG nvidia-3-40c | 1 |
4 | MIG nvidia-2-20c | 1 |
5 | MIG nvidia-1-10c | 1 |
6 | MIG nvidia-4-40c + nvidia-2-20c + nvidia-1-10c | 3 |
7 | MIG nvidia-2-20c + nvidia-2-20c + nvidia-2-20c + nvidia-1-10c | 4 |
8 | MIG nvidia-1-10c* 7 | 7 |
ResNet50
ResNet50 (see Deep Residual Learning for Image Recognition) is a widely used deep convolutional neural network for various computer vision applications. This neural network can address the disappearing gradients problem by allowing gradients to traverse the network's layers using the concept of skip connections. The following figure shows an example configuration for ResNet50 inference:
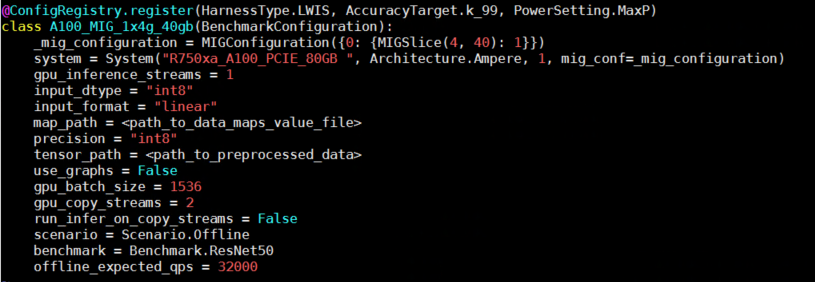
Figure 4- Configuration for running inference using Resnet50 model
The following figure shows ResNet50 inference performance based on the scenarios in Table 2: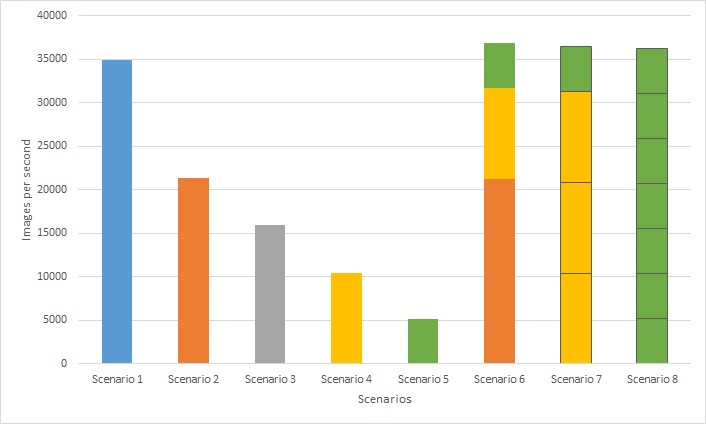
Figure 5- ResNet50 Performance throughput of MLPerf Inference v1.1 across various VMs with MIG profiles
Multiple data scientists can use all the available GPU resources while running their individual workloads on separate instances, improving overall system throughput. This result is clearly seen on Scenarios 6 through 8, which contain multiple instances, compared to Scenario 1 which consists of a single instance with the largest MIG profile for A100 80 GB. Scenario 6 achieves the highest overall system throughput (5.77 percent improvement) compared to Scenario 1. Also, Scenario 8 shows seven VMs equipped with individual GPU instances that can be built for up to seven data scientists who can fine-tune their ResNet50 base models.
BERT
BERT (see BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding) is a state-of-the-art language representational model. BERT is essentially a stack of Transformer encoders. It is suitable for neural machine translation, question answering, sentiment analysis, and text summarization, all of which require a working knowledge of the target language.
BERT is trained in two stages:
- Pretrain—During which the model acquires language and context understanding
- Fine-tuning—During which the model acquires task-specific knowledge such as querying and response.
The following figure shows an example configuration for BERT inference:
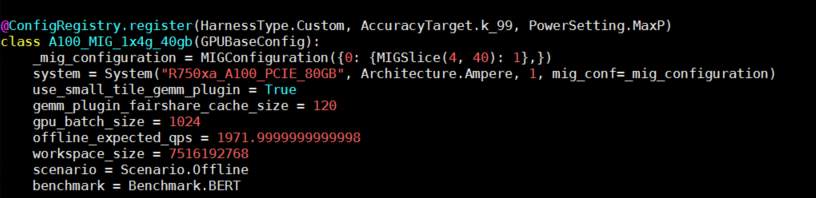
Figure 6- Configuration for running inference using BERT model
The following figure shows BERT inference performance based on scenarios in Table 2:
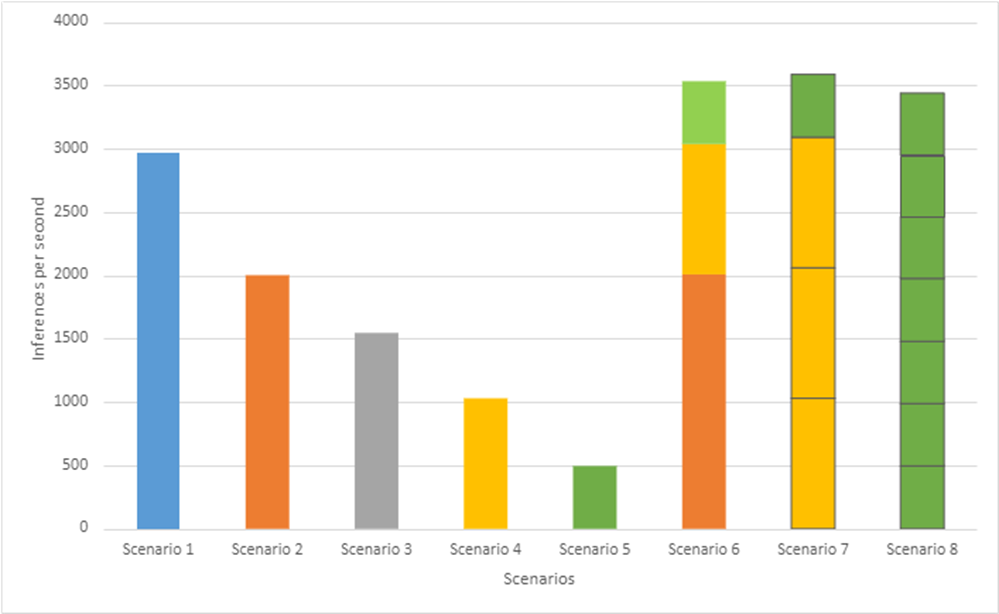 Figure 7- BERT Performance throughput of MLPerf Inference v1.1 across various VMs with MIG profiles
Figure 7- BERT Performance throughput of MLPerf Inference v1.1 across various VMs with MIG profiles
Like Resnet50 Inference performance, we clearly see that Scenarios 6 through 8, which contain multiple instances, perform better compared to Scenario 1. Particularly, Scenario 7 achieves the highest overall system throughput (21 percent improvement) compared to Scenario 1 while achieving 99.9 percent accuracy target. Also, Scenario 8 shows seven VMs equipped with individual GPU instances that can be built for up to seven data scientists who want to fine-tune their BERT base models.
Conclusion
In this blog, we describe how to install and configure MLPerf Inference v1.1 on Dell PowerEdge 750xa servers using a VMware-virtualized infrastructure and NVIDIA A100 GPUs. Furthermore, we examine the performance of single- and multi-MIG profiles running on the A100 GPU. If your ML workload is primarily inferencing-focused and response time is not an issue, enabling MIG on the A100 GPU can ensure complete GPU use with maximum throughput. Developers can use VMs with an independent GPU compute allocated to them. Also, in cases where the largest MIG profiles are used, performance is comparable to bare metal systems. Inference results from ResNet50 and BERT models demonstrate that overall system performance using either the whole GPU or multiple VMs with MIG instances hosted on an R750xa system with VMware ESXi and NVIDIA A100 GPUs performed well and produced valid results for MLPerf Inference v1.1. In both the cases, the average throughput and latency are equal. This result confirms that MIG provides predictable latency and throughput independent of other processes operating on the MIG instances on the GPU.
There is a MIG limitation for GPU profiling on the VMs. Due to the shared nature of the hardware performance across all MIG devices, only one GPU profiling session can run on a VM; parallel GPU profiling sessions on a single VM are not possible.