




Code Llama – How Meta Can an Open Source Coding Assistant Get?


Introduction
The past few years have been an exciting adventure in the field of AI, as increasingly sophisticated AI models continue to be developed to analyze and comprehend vast amounts of data. From predicting protein structures to charting the neural anatomy of a fruit fly to creating optimized math operations that accelerate supercomputers, AI has achieved impressive feats across varied disciplines. Large language models (LLMs) are no exception. Although producing human-like language garners attention, large language models were also created for code generation. By training on massive code datasets, these systems can write code by forecasting the next token in a sequence.
Companies like Google, Microsoft, OpenAI, and Anthropic are developing commercial LLMs for coding such as Codex, GitHub Copilot, and Claude. In contrast to closed systems, Meta has opened up its AI coding tool Code Llama, an AI coding assistant that aims to boost software developer productivity. It is released under a permissive license for both commercial and research use. Code Llama is an LLM capable of generating code and natural language descriptions of code from both code snippets and user-engineered prompts to automate repetitive coding tasks and enhance developer workflows. The open-source release allows the wider tech community to build upon Meta’s foundational model in natural language processing and code intelligence. For more information about the release, see Meta’s blog Introducing Code Llama, an AI Tool for Coding.
Code Llama is a promising new AI assistant for programmers. It can autocomplete code, search through codebases, summarize code, translate between languages, and even fix issues. This impressive range of functions makes Code Llama seem almost magical—like a programmer's dream come true! With coding assistants like Code Llama building applications could become far easier. Instead of writing every line of code, we may one day be able to describe what we want the program to do in a natural language prompt and the model can generate the necessary code for us. This workflow of the future could allow programmers to focus on the high-level logic and architecture of applications, without getting bogged down in implementation details.
Getting up and running with Code Llama was straightforward and fast. Meta released a 7 B, 13 B, and 34 B version of the model including instruction models that were trained with fill-in-the-middle (FIM) capability. This allows the models to insert into existing code, perform code completion, and accept natural language prompts. Using a Dell PowerEdge R740XD equipped with a single Nvidia A100 40GB GPU experimented with the smaller 7 billion parameter model, CodeLlama-Instruct-7 B. We used our Rattler Cluster in the HPC AI Innovation Lab to take advantage of PowerEdge XE8545 servers each equipped with four Nvidia A100 40 GB GPUs for the larger 34 billion parameter model (CodeLlama-Instruct-34 B). The examples provided by Meta were running a few minutes after downloading the model files and we began experimenting with natural language prompts to generate code. By engineering the prompts in a strategic manner, we aimed to produce the scaffolding for a web service wrapping the Code Llama model with an API that could be accessed over the web.
Accept user input from command line
The examples provided in example_instructions.py must be edited manually to add wanted user prompts. To make Code Llama a bit easier to use, we copied example_instructions.py into test_instructions.py and added the ability to send in a prompt from the command line.
The full file with changes:
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
from typing import Optional
import fire
from llama import Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
content:str,
temperature: float = 0.2,
top_p: float = 0.95,
max_seq_len: int = 512,
max_batch_size: int = 8,
max_gen_len: Optional[int] = None,
):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
instructions = [
[
{
"role": "user",
"content": content,
}
]
]
results = generator.chat_completion(
instructions, # type: ignore
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for instruction, result in zip(instructions, results):
for msg in instruction:
print(f"{msg['role'].capitalize()}: {msg['content']}\n")
print(
f"> {result['generation']['role'].capitalize()}: {result['generation']['content']}"
)
print("\n==================================\n")
if __name__ == "__main__":
fire.Fire(main)
It is possible to run the standard torchrun command with a --content option to pass in the prompt. Rather than evaluating the model on complex tasks, we started with simple coding challenges. To test the model, we designed a few experiments involving straightforward coding prompts posing basic programming problems. The manual process of directly prompting the model allows us to evaluate the strengths and weaknesses in generating code with this model.
Our first prompt: “Show an example of recursion in Python”
Command:
torchrun test_instructions.py \ --nproc_per_node 1 \ --ckpt_dir CodeLlama-7b-Instruct/ \ --tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \ --max_seq_len 512 \ --max_batch_size 1 \ --content "Show an example of recursion in Python"
Output:
> Assistant: Sure! Here's an example of recursion in Python: ``` def factorial(n): if n == 0: return 1 else: return n * factorial(n-1) ``` In this example, the `factorial` function takes an integer `n` as input and returns its factorial. The function calls itself with the argument `n-1` until the base case is reached, where `n` is equal to 0. The base case returns 1, and the recursive calls return the factorial of `n-1`. The final result is the product of `n` and the factorial of `n-1`. Here's an example of how the function would work for different values of `n`: * `factorial(5)` would call `factorial(4)`, which would call `factorial(3)`, which would call `factorial(2)`, which would call `factorial(1)`, which would return 1. The final result would be 5! = 120. * `factorial(0)` would return 1. * `factorial(-1)` would raise a `ValueError` because negative numbers are not allowed. Recursion can be a powerful tool for solving problems that have a recursive structure, but it can also be difficult to understand and debug. It's important to use recursion judiciously and to make sure that it's the best approach for the problem you're trying to solve. ==================================
The model not only generates example code, but it also explains how the code works through examples. By providing both code snippets and clarifying descriptions, the model enables a deeper understanding of the functionality. Users can both see concrete implementations and learn the rationale behind them. Now that we have made it easier to provide a prompt to the model, let’s build an API endpoint by prompting Code Llama to build its own server.
Create An API endpoint for Code Llama
RESTful APIs are a popular way to build backend services that can be consumed by various applications over a network with tools such as curl. However, instead of manually coding this, we asked Code Llama to write the code for its own REST server.
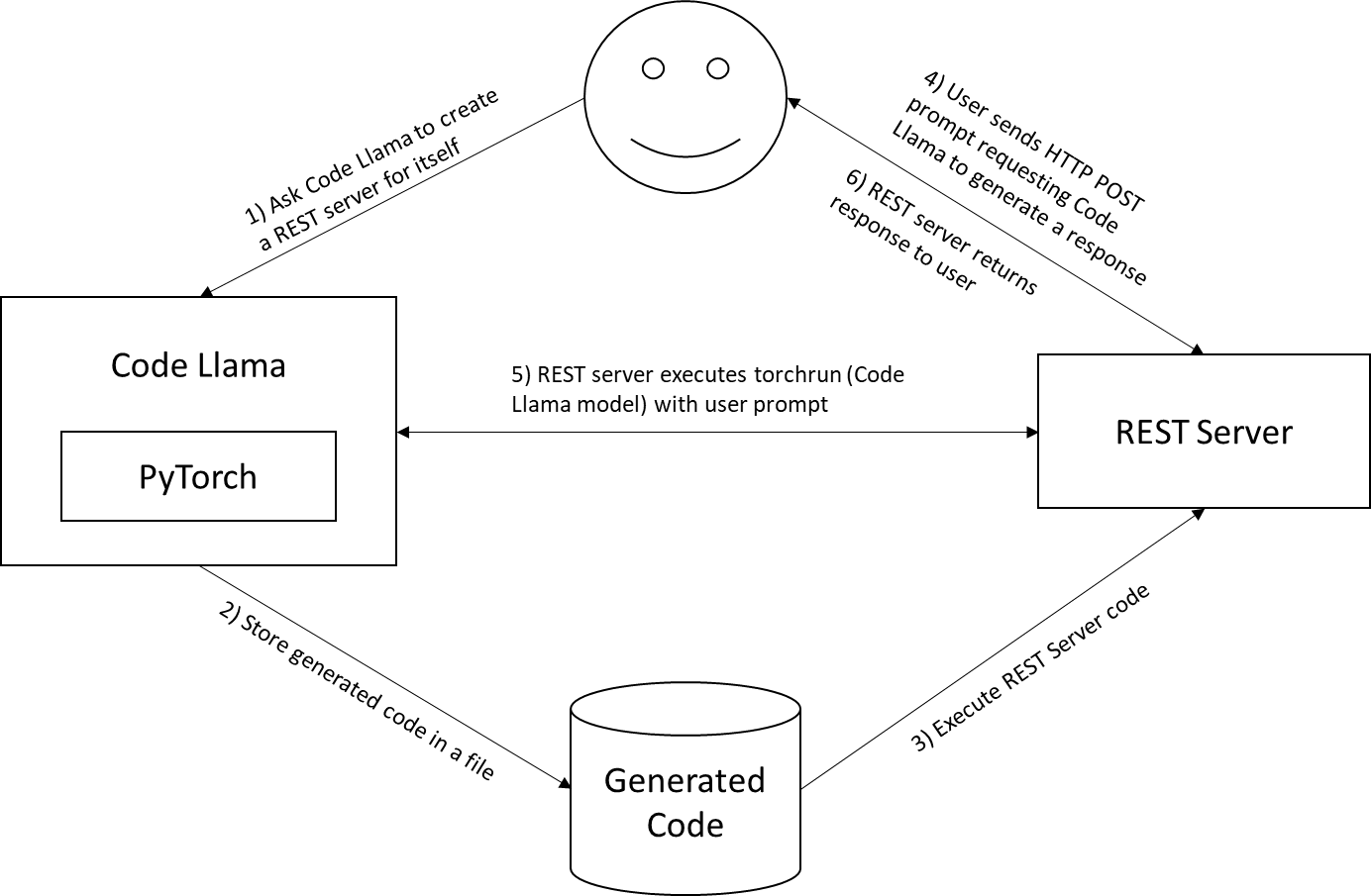
Our process for using Code Llama to produce a web service of itself:
- Step 1: Ask Code Llama to create a REST server for itself
- Step 2: Store the generated code in a file
- Step 3: Run the REST app on same GPU enabled server
- Step 4: Send prompts using HTTP POST requests to Code Llama service on the local host
- Step 5: REST server runs torchrun command with user prompt
- Step 6: REST server returns response to user
We needed to add some context to the prompt for Code Llama to generate the correct code, as the engineered prompt is a bit more complex and includes how to call torchrun with the correct parameters:
torchrun \ --nproc_per_node 1 \ test_instructions.py \ --ckpt_dir CodeLlama-7b-Instruct/ \ --tokenizer_path CodeLlama-7b-Instruct/tokenizer.model\ --max_seq_len 512 \ --max_batch_size 1 \ --content "Create a REST server in Python with a POST /codellama URL, expect a JSON payload with a 'content' field, use a subprocess.run(['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content], stdout=subprocess.PIPE) and return stdout from subprocess.run"
All torchrun command line options, except for --content, are defined by Code Llama itself. Let’s break down what our engineered prompt is requesting:
- “Create a REST server in Python” – No framework was defined; Code Llama chose Flask
- “with a POST /codellama URL” – Expect to receive HTTP POSTS to the /codellama URL
- “expect a JSON payload with a ‘content’ field” – Expect a ‘content’ key in the POST JSON. This holds the user prompt.
- “use a subprocess.run(…)” – This is where we tell Code Llama how to call itself
- “return stdout from subprocess.run” – Return any text that Code Llama produces over HTTP
The resulting output:
> Assistant: Here is an example of how you can create a REST server in Python with a POST /codellama URL that expects a JSON payload with a 'content' field, and uses a subprocess.run command to run the torchrun command with the specified arguments:
```
import json
import subprocess
from flask import Flask, request
app = Flask(__name__)
@app.route('/codellama', methods=['POST'])
def codellama():
if request.method == 'POST':
data = request.get_json()
content = data['content']
args = ['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content]
result = subprocess.run(args, stdout=subprocess.PIPE)
return result.stdout
else:
return 'Invalid request'
if __name__ == '__main__':
app.run(debug=True)
```
This code defines a Flask application with a single route, '/codellama', that handles POST requests. The route expects a JSON payload with a 'content' field, and uses the subprocess.run command to run the torchrun command with the specified arguments. The result of the
==================================We clipped the Code Llama generated code and pasted it into server.py:
import json
import subprocess
from flask import Flask, request
app = Flask(__name__)
@app.route('/codellama', methods=['POST'])
def codellama():
if request.method == 'POST':
data = request.get_json()
content = data['content']
args = ['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content]
result = subprocess.run(args, stdout=subprocess.PIPE)
return result.stdout
else:
return 'Invalid request'
if __name__ == '__main__':
app.run(debug=True)After running the code:
python server.py
… the REST-like server will be running and waiting for commands.
Using curl, we can send commands over the network to Code Llama now:
curl -X POST -H "Content-Type: application/json" -d '{"content": " Show an example of recursion in Python"}' http://localhost:5000/codellama… and will receive a result like:
> Assistant: Sure! Here's an example of recursion in Python: ``` def factorial(n): if n == 0: return 1 else: return n * factorial(n-1) ``` In this example, the `factorial` function takes an integer `n` as input and returns its factorial. The function calls itself with the argument `n-1` until the base case is reached, where `n` is equal to 0. The base case returns 1, and the recursive calls return the factorial of `n-1`. The final result is the product of `n` and the factorial of `n-1`. Here's an example of how the function would work for different values of `n`: * `factorial(5)` would call `factorial(4)`, which would call `factorial(3)`, which would call `factorial(2)`, which would call `factorial(1)`, which would return 1. The final result would be 5! = 120. * `factorial(0)` would return 1. * `factorial(-1)` would raise a `ValueError` because negative numbers are not allowed Recursion can be a powerful tool for solving problems that have a recursive structure, but it can also be difficult to understand and debug. It's important to use recursion judiciously and to make sure that it's the best approach for the problem you're trying to solve. ==================================
Conclusion
The capabilities of AI and LLMs continue to rapidly evolve. What we find most compelling about an open source model like Code Llama is the potential for customization and data privacy. Unlike closed, proprietary models, companies can run Code Llama on their own servers and fine-tune it using internal code examples and data. This allows enforcement of coding styles and best practices while keeping code and data private. Rather than relying on external sources and APIs, teams can query a customized expert trained on their unique data in their own data center. Whatever your use cases, we found standing up an instance of Code Llama using Dell servers accelerated with Nvidia GPUs a simple and powerful solution that enables an exciting innovation for development teams and enterprises alike.
AI coding assistants such as Code Llama have the potential to transform software development in the future. By automating routine coding tasks, these tools could save developers significant time that can be better spent on higher-level system design and logic. With the ability to check for errors and inconsistencies, AI coders may also contribute to improved code quality and reduced technical debt. However, our experiments reaffirm that generative AI is still prone to limitations like producing low-quality or non-functional code. Now that we have a local API endpoint for Code Llama, we plan to conduct more thorough testing to further evaluate its capabilities and limitations. We encourage developers to try out Code Llama themselves using the resources we provided here. Getting experience with this open-sourced model is a great way to start exploring the possibilities of AI for code generation while contributing to its ongoing improvement.