




Azure Stack HCI Stretch Clustering: because automatic disaster recovery matters
If history has taught us anything, it’s that disasters are always around the corner and tend to appear in any shape or form when they’re least expected.
To overcome these circumstances, we need the appropriate tools and technologies that can guarantee resuming operations back to normal in a secure, automatic, and timely manner.
Traditional disaster recovery (DR) processes are often complex and require a significant infrastructure investment. They are also labor intensive and prone to human error.
Since December 2020, the situation has changed. Thanks to the new release of Microsoft Azure Stack HCI, version 20H2, we can leverage the new Azure Stack HCI stretched cluster feature on Dell EMC Integrated System for Microsoft Azure Stack HCI (Azure Stack HCI).
The integrated system is based on our flexible AX nodes family as the foundation, and combines Dell Technologies full stack life cycle management with the Microsoft Azure Stack HCI operating system.
It is important to note that this technology is only available for the integrated system offering under the certified Azure Stack HCI catalog.
Azure Stack HCI stretch clustering provides an easy and automatic solution (no human interaction if desired) that assures transparent failovers of disaster-impacted production workloads to a safe secondary site.
It can also be leveraged to perform planned operations (such as entire site migration, or disaster avoidance) that, until now, required labor intensive and error prone human effort for execution.
Stretch clustering is one type of Storage Replica configuration. It allows customers to split a single cluster between two locations—rooms, buildings, cities, or regions. It provides synchronous or asynchronous replication of Storage Spaces Direct volumes to provide automatic VM failover if a site disaster occurs.
There are two different topologies:
- Active-Passive: All the applications and workloads run on the primary (preferred) site while the infrastructure at the secondary site remains idle until a failover occurs.
- Active-Active: There are active applications in both sites at any given time and replication occurs bidirectionally from either site. This setup tends to be a more efficient use of an organization’s investment in infrastructure because resources in both sites are being used.
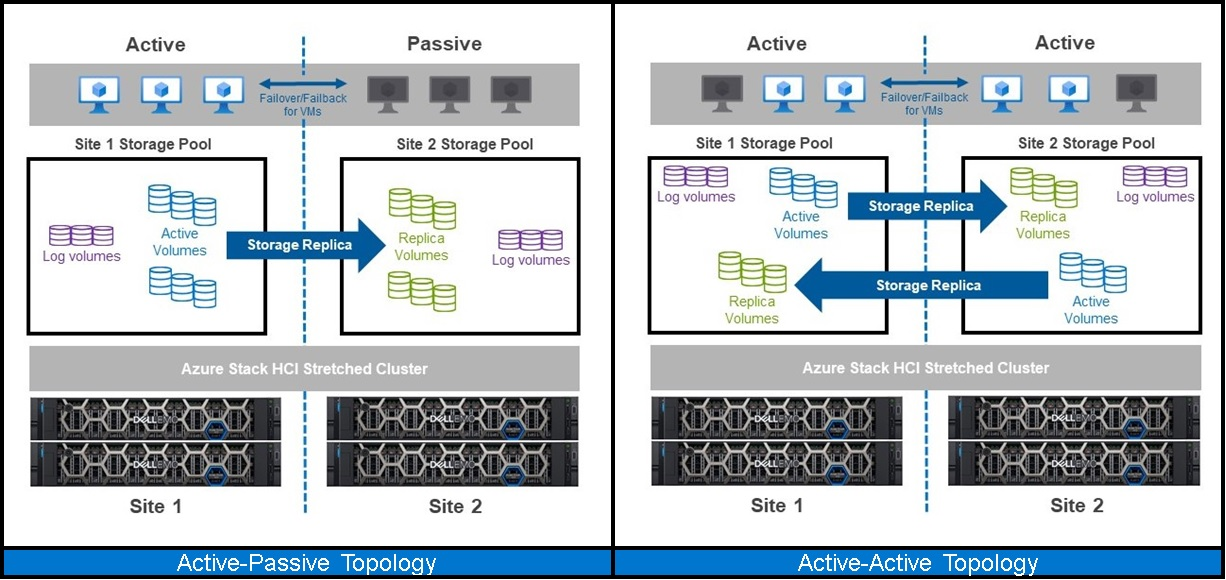
Azure Stack HCI stretch clustering topologies: Active-Passive and Active-Active
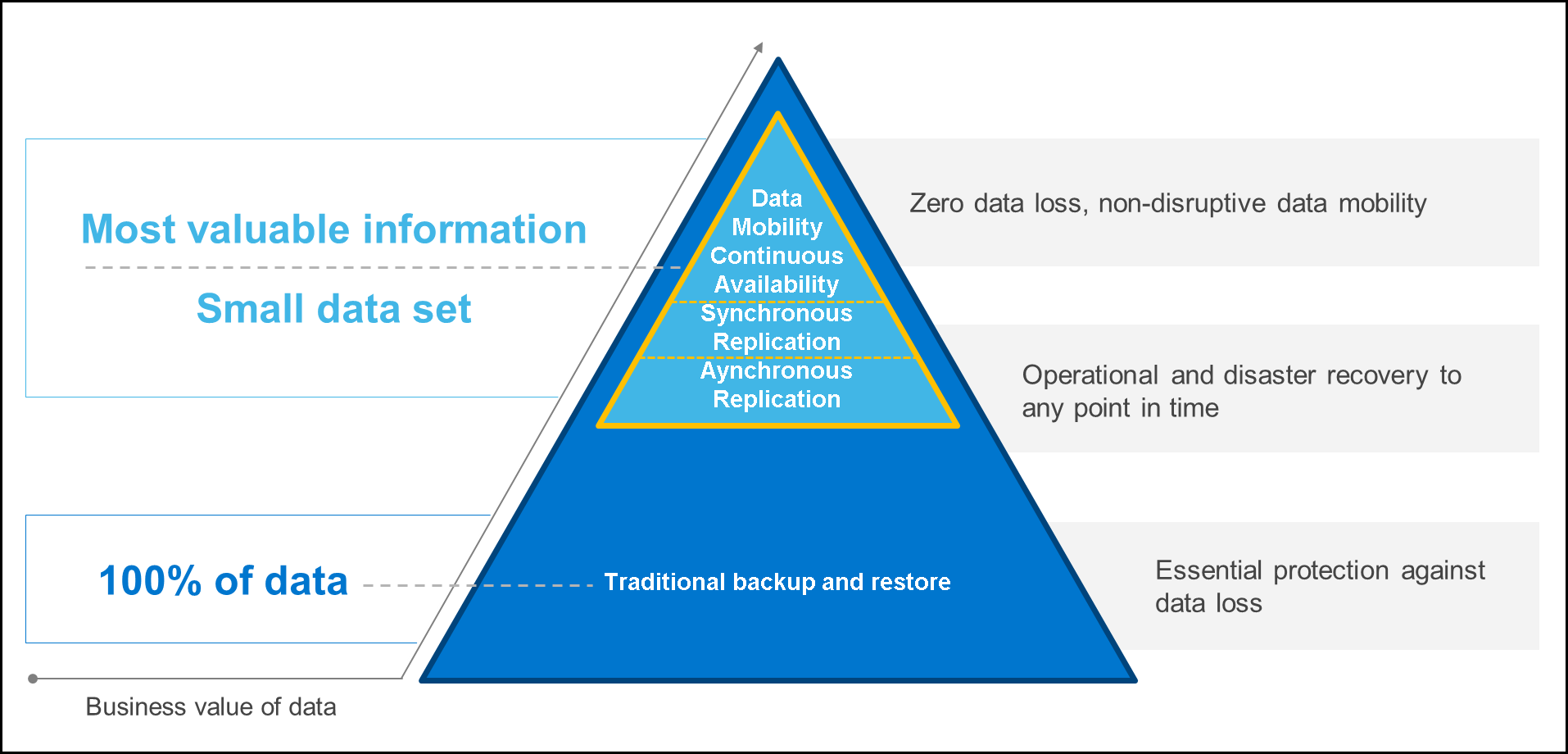
To be truly cost-effective, the best data protection strategies incorporate a combination of different technologies (deduplicated backup, archive, data replication, business continuity, and workload mobility) to deliver the right level of data protection for each business application.
The following diagram highlights the fact that just a reduced data set holds the most valuable information. This is the sweet spot for stretch clustering.
For a real-life experience, our Dell Technologies experts put Azure Stack HCI stretched clustering to the test in the following lab setup:
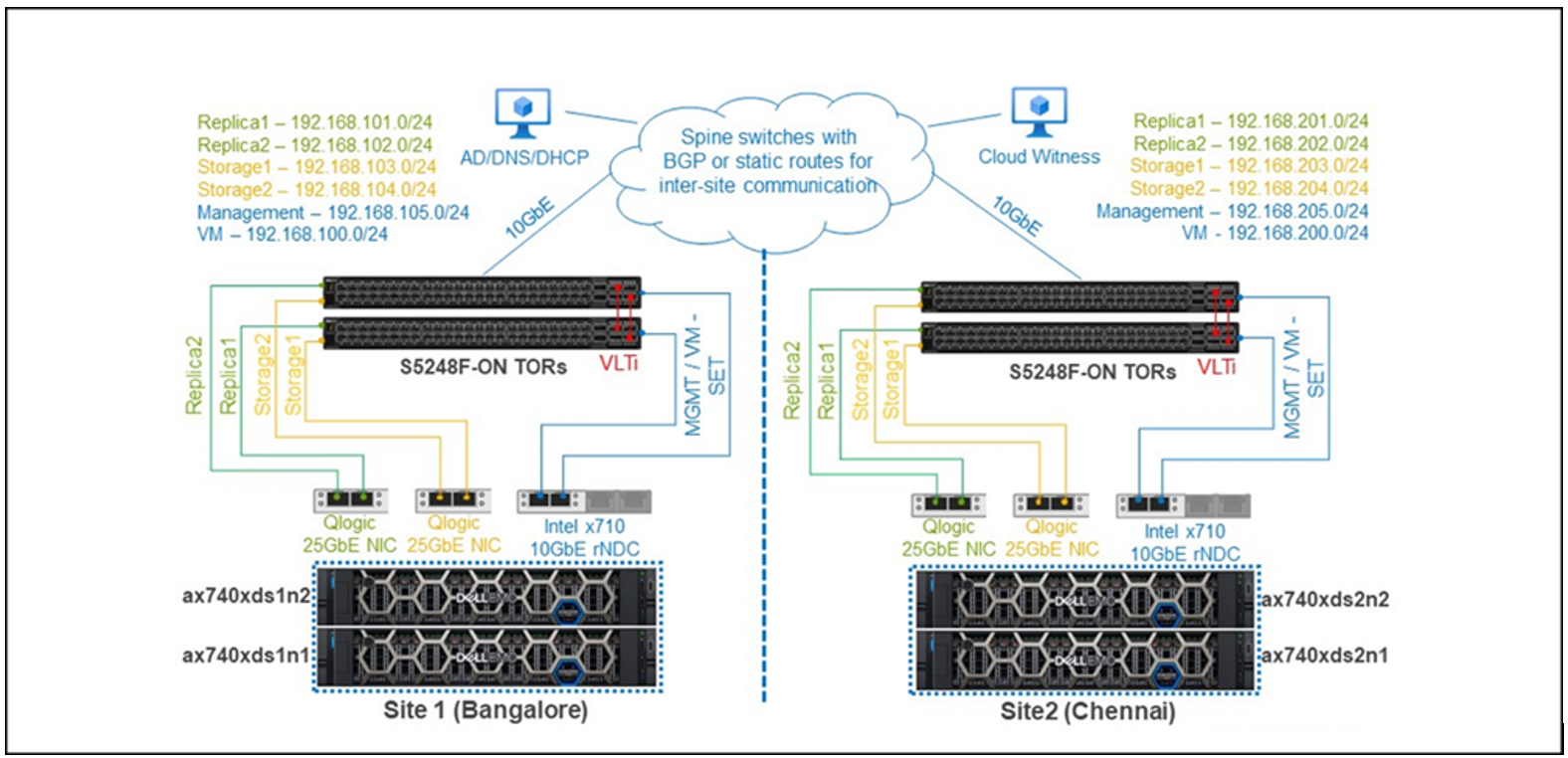
Test lab cluster network topology
Note these key considerations regarding the lab network architecture:
- The Storage Replica, management, and VM networks in each site were unique Layer 3 subnets. In Active Directory, we configured two sites—Bangalore (Site 1) and Chennai (Site 2)—based on these IP subnets so that the correct sites appeared in Failover Cluster Manager on configuration of the stretched cluster. No additional manual configuration of the cluster fault domains was required.
- Average latency between the two sites was less than 5 milliseconds, required for synchronous replication.
- Cluster nodes could reach a file share witness within the 200-millisecond maximum roundtrip latency requirement.
- The subnets in both sites could reach Active Directory, DNS, and DHCP servers.
- Software-defined networking (SDN) on a multisite cluster is not currently supported and was not used for this testing.
For all the details, see this white paper: Adding Flexibility to DR Plans with Stretch Clustering for Azure Stack HCI.
In this blog though, I only want to focus on summarizing the results we obtained in our labs for the following four scenarios:
- Scenario 1: Unplanned node failure
- Scenario 2: Unplanned site failure
- Scenario 3: Planned failover
- Scenario 4: Life cycle management
Scenario | Event | Simulated failure or maintenance event | Stretched Cluster expected response | Stretched Cluster actual response |
1 | Unplanned node failure | Node 1 in Site 1 power-down | Impacted VMs should failover to another local node | In around 5 minutes, all 10 VMs in Node 1 Site 1 fully restarted in Node 2 Site 1.
This is expected behavior since Site 1 has been configured as preferred site; otherwise, the active volume could have been moved to Site 2, and the VMs would have been restarted on a cluster node in Site 2. |
2 | Outage in Site 1 | Simultaneous power-down of Nodes 1 and 2 in site 1 | Impacted VMs should failover to nodes on the secondary site | In 25 minutes, all VMs were restarted, and the included web application was fully responsive.
The volumes owned by the nodes in Site 2 remained online throughout this failure scenario.
The replica volumes remained offline until Site 1 was restored to full health. Once Site 1 was back online, synchronous replication began again from the source volumes in Site 2 to their destination replica partners in Site 1. |
3 | Planned failover | Switch Direction operation on a volume from Windows Admin Center | Selected VMs and workloads should transparently move to secondary site | Within 0 to 3 mins, the application hosted by the affected VMs was reachable without service interruption (time depends on whether IP reassignment is required).
First, the owner node for the volumes changed to Node 2 in Site 2, and owner node for the replica volumes changed to Node 2 in Site 1. No service interruption. At this time, the test VM was running in Site 1, but its virtual disk that resided on the volume was running in Site 2. Performance problems can result because I/O is traversing the replication links across sites. After approximately 10 minutes, a Live Migration of the test VM would occur automatically (if not manually initiated earlier) so that the VM would be on the same node as its virtual disk. |
4 | Lifecycle management | Update all nodes in the cluster by using Single-click Full Stack Cluster Aware Updating (CAU) in Windows Admin Center | Stretched cluster and CAU should work seamlessly together to provide full stack cluster update without service interruption and local only workload mobility for the Live Migrated VMs | The total process of applying the operating system and firmware updates to the stretched cluster took approximately 3 hours, and the process had no application impact.
Each node was drained, and its VMs were live migrated to the other node in the same site. The intersite links between Site 1 and Site 2 were never used during update operations. In addition, the process required only a single reboot per node. This behavior was consistent throughout the update of all the nodes in the stretched cluster. |
To sum up, Azure Stack HCI Stretch Clustering has been shown to work as expected under difficult circumstances. It can easily be leveraged to cover a wide range of data protection scenarios, such as:
- restoring your organization's IT within minutes after an unplanned event
- transparently moving running workloads between sites to avoid incoming disasters or other planned operations
- automatically failing over VMs and workloads of individual failed nodes
This technology may make the difference for businesses to automatically stand up after disaster strikes, a total game changer in the automatic disaster recovery landscape.
Thank you for your time reading this blog and don’t forget to check out the full white paper!!!