




Artificial Intelligence for IT operations (AIOps) in PowerScale Performance Prediction
Tue, 06 Sep 2022 18:14:53 -0000
|Read Time: 0 minutes
AI is a fancy and hot topic in recent years. A common question from our customers is ‘How can AI help the day-to-day operation and management of PowerScale?’ It’s a very interesting question, because although AI can help realize so many possibilities, we still don’t have that many implementations of it in IT infrastructure.
But, we finally have something that is very inspiring. Here is what we have achieved as proof of concept in our lab with the support of AI Dynamics, a professional AI platform company.
Challenges for IT operations and opportunities for AIOps
With the increase in complexity of IT infrastructure comes the increase in the amount of data produced by these systems, Real-time performance logs, usage reports, audits, and other metadata can add up to gigabytes or terabytes a day. It is a big challenge for the IT department to analyze this data and to extract proactive predictions, such as IT infrastructure performance issues and their bottlenecks.
AIOps is the methodology to address these challenges. The term ‘AIOps’ refers to the use of artificial intelligence (AI), specifically machine learning (ML) techniques, to ingest, analyze, and learn from large volumes of data from every corner of the IT environment. The goal of AIOps is to allow IT departments to manage their assets and tackle performance challenges proactively, in real-time (or better), before they become system-wide issues.
PowerScale key performance prediction using AIOps
Overview
In this solution, we identify NFS latency as the PowerScale performance indicator that customers would like to see predictive reporting about. The goal of the AI model is to study historical system activity and predict the NFS latency at five-minute intervals for four hours in the future. A traditional software system can use these predictions to alert users of a potential performance bottleneck based on the user’s specified latency threshold level and spike duration. In the future, AI models can be built that help diagnose the source of these issues so that both an alert and a best-recommended solution can be reported to the user.
The whole training process involves the following three steps (I’ll explain the details in the following sections):
- Data preparation – to get the raw data and extract the useful features as the input for training and validation
- Training the model – to pick up a proper AI architecture and tune the parameters for accuracy
- Model validation – to validate the AI model based on the data set obtained from the training
Data preparation
The raw performance data is collected through Dell Secure Remote Services (SRS) from 12 different all-flash PowerScale clusters from an electronic design automation (EDA) customer each week. We identify and extract 26 performance key metrics from the raw data, most of which are logged and updated every five minutes. AI Dynamics NeoPulse is used to extract some additional fields (such as the day of the week and time of day from the UNIX timestamp fields) to allow the model to make better predictions. Each week new data was collected from the PowerScale cluster to increase the size of the training dataset and to improve the AI model. During every training run, we also withheld 10% of the data, which we used to test the AI model in the testing phase. This is separate from the 10% of training data withheld for validation.
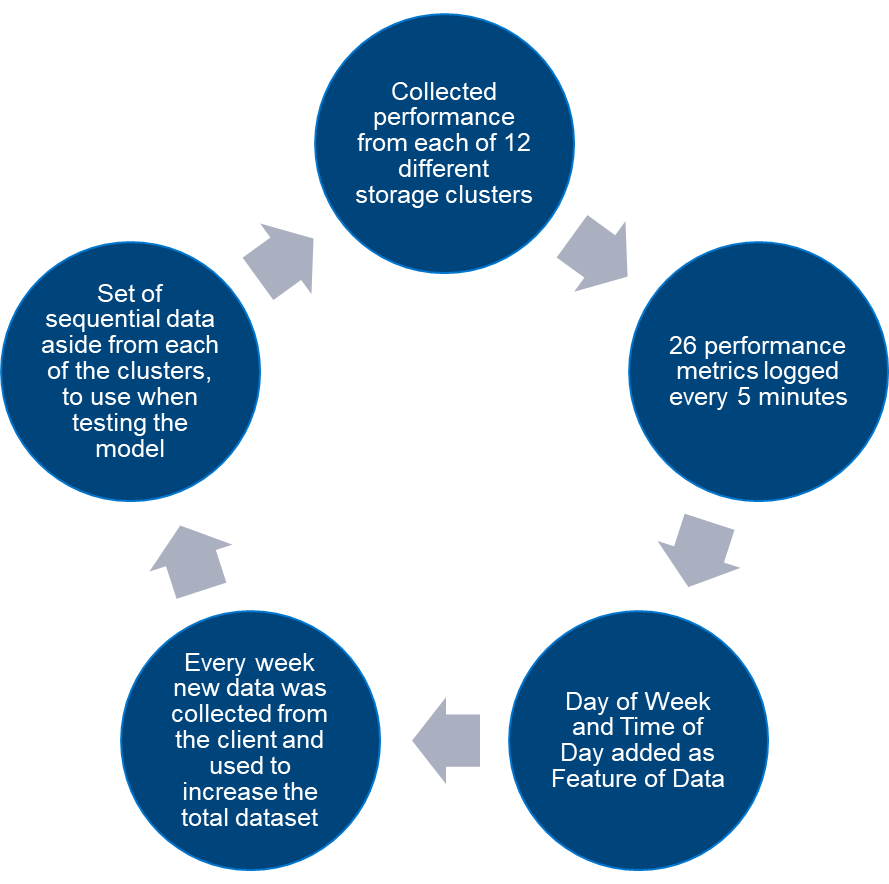
Figure 1. Data preparation process
Training the model
Over a period of two months, more than 50 different AI models were trained using a variety of different time series architectures, varying model architecture parameters, hyperparameters, and data engineering techniques to maximize performance, without overfitting to existing data. When these training pipelines were created in NeoPulse, they could easily be reused as new data arrived from the client each week, to rerun training and testing in order to quantify the performance of the model.
At the end of the two-month period, we had built a model that could predict whether this one performance metric (NFS3 latency) would be above a threshold of 10ms, correctly for 70% of each one of the next 48 five-minute intervals (four hours total).
Model validation
In the data preparation phase, we withheld 10% of the total data set to be used for AI model validation and testing. With the current AI model, end-users can easily configure the threshold of the latency as they want. In this case, we validated the model at 10ms and 15ms thresholds latency. The model can correctly identify over 70% of 10ms latency spikes and 60% of 15ms latency spikes over the entire ensuing four-hour period.

Figure 2. Model Validation
Results
In this solution, we used NFS latency from PowerScale as the indicator to be predicted. The AI model uses the performance data from the previous four hours to predict the trends and spikes of NFS latency in the next four hours. If the software identifies a five-minute period when a >10ms latency spike would occur more than 70% of the time, it will trigger a configurable alert to the user.
The following diagram shows an example. At 8:55 a.m., the AI model predicts the NFS latency from 8:55 a.m. to 12:55 p.m., based on the input of performance data from 4:55 a.m. to 8:55 a.m. The AI model makes predictions for each five-minute period over the prediction duration. The model predicts a few isolated spikes in latency, with a large consecutive cluster of high latency between around 12 p.m. and 12:55 p.m. A software system can use this prediction to alert the user about the expected increase in latency, giving them over three hours to get ahead of the problem and reduce the server load. In the graph, the dotted line shows the AI model’s prediction, whereas the solid line shows actual performance.
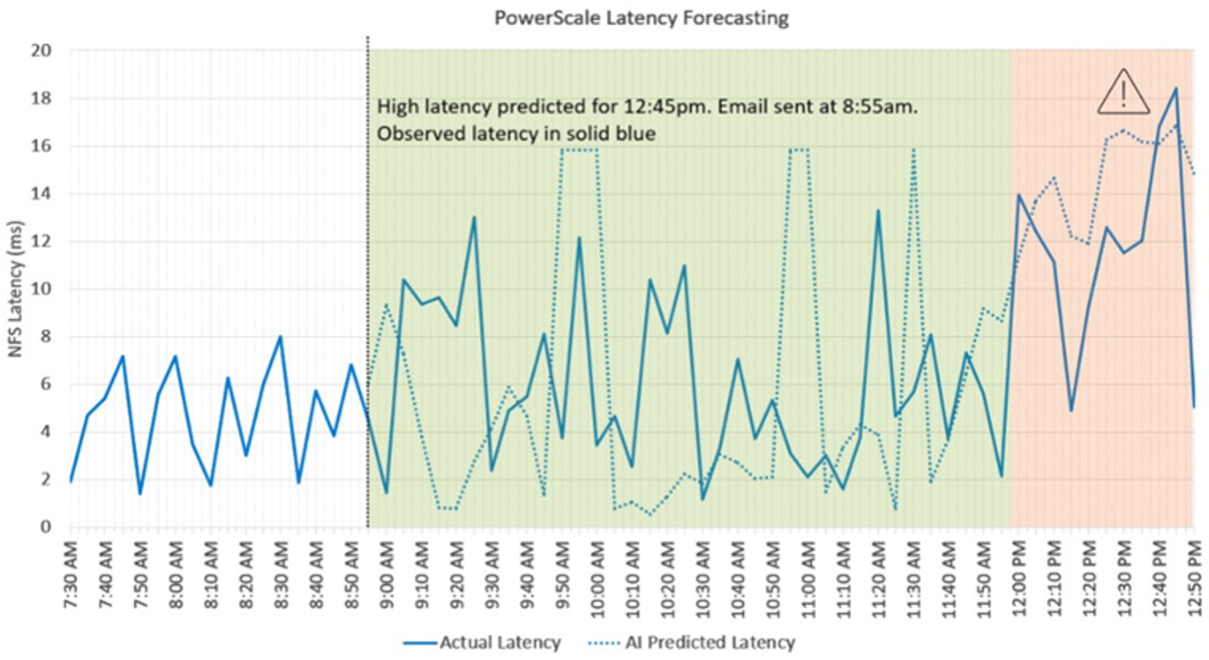
Figure 3. Dell PowerScale NFS Latency Forecasting
To sum up, the solution achieved the following:
- By using the previous four hours of PowerScale performance data, the solution can forecast the next four hours of any specified metric.
- For NFS3 latency, the solution was benchmarked as correctly identifying periods when latency would be above 10ms 70% of the time.
- The data and model training pipelines created for this task can easily be adapted to predict other performance metrics, such as NFS throughput spikes, SMB latency spikes, and so on.
- The AI learns to improve its predictions week by week as it adapts to each customer’s nuanced usage patterns, creating customized models for each customer’s idiosyncratic workload profiles.
Conclusion
AIOps introduces the intelligence needed to manage the complexity of modern IT environments. The NeoPulse platform from AI Dynamics makes AIOps easy to implement. In an all-flash configuration of Dell PowerScale clusters, performance is one of the key considerations. Hundreds and thousands of performance logs are generated every day and it is very easy for AIOps to consume the existing logs and provide insight into potential performance bottlenecks. Dell servers with GPUs are great platforms for performing training and inference, for not just this model but for any other new AI challenge the company wishes to tackle, across dozens of problem types.
For additional details about our testing, see the white paper Key Performance Prediction using Artificial Intelligence for IT operations (AIOps).
Author: Vincent Shen