




Accelerating Distributed Training in a Multinode Virtualized Environment

Introduction
In the age of deep learning (DL), with complex models, it is vital to have a system that allows faster distributed training. Depending on the application, some DL models require more frequent retraining and fine-tuning of the hyperparameters to be deployed in the production environment. It is important to understand the best practices to improve multinode distributed training performance.
Networking is critical in a distributed training setup as there are numerous gradients exchanged between the nodes. The complexity increases as we increase the number of nodes. In the past, we have seen the benefits of using:
- Direct Memory Access (DMA), which enables a device to access host memory without the intervention of CPUs
- Remote Direct Memory Access (RDMA), which enables access to memory on a remote machine without interrupting the CPU processes on that system
This blog examines performance when direct communication is established between the GPUs in multinode training experiments run on Dell PowerEdge servers with NVIDIA GPUs and VMware vSphere.
GPUDirect RDMA
Introduced as part of Kepler class GPUs and CUDA 5.0, GPUDirect RDMA enables a direct communication path between NVIDIA GPUs and third-party devices such as network interfaces. By establishing direct communication between the GPUs, we can eliminate the critical bottleneck where data needs to be moved into the host system memory before it can be sent over the network, as shown in the following figure:
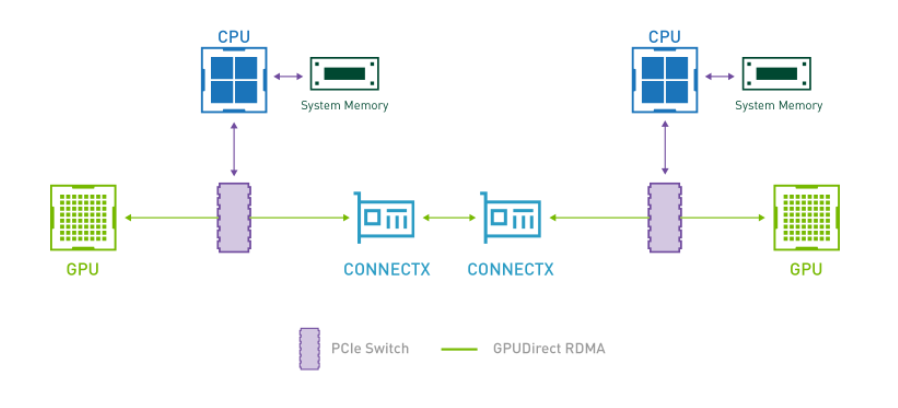
Figure 1: Direct Communication – GPUDirect RDMA
For more information, see:
System details
The following table provides the system details:
Table 1: System details
Component | Details |
Server | Dell PowerEdge R750xa (NVIDIA-Certified System) |
Processor | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz |
GPU | 4 x NVIDIA A100 PCIe |
Network adapters | Mellanox ConnectX-6 Dual port 100 GbE and 25 GbE |
Storage | Dell PowerScale |
ESXi version | 7.0.3 |
BIOS version | 1.1.3 |
GPU driver version | 470.82.01 |
CUDA Version | 11.4 |
Setup
The setup for multinode training in a virtualized environment is outlined in our previous blog.
At a high level, after Address Translation Services (ATS) is enabled on VMware ESXi, the VMs, and ConnectX-6 NIC:
- Enable mapping between logical and physical ports.
- Create a Docker container with Mellanox OFED drivers, Open MPI Library, and NVIDIA-optimized TensorFlow.
- Set up a keyless SSH login between VMs
Performance evaluation
For evaluation, we use tf_cnn_benchmarks using the ResNet50 model and synthetic data with a local batch size of 1024. Each VM is configured with 32 vCPUs, 64 GB of memory, and one NVIDIA A100 PCIE 80 GB GPU. The experiments are performed by using a data parallelism approach in a distributed training setup, scaling up to four nodes. The results are based on averaging three experiment runs. Single-node experiments are only for comparison as there is no internode communication.
Note: Use the ibdev2netdev utility to display the installed Mellanox ConnectX-6 card along with the mapping of ports. In the following figures, ON and OFF indicate if the mapping is enabled between logical and physical ports.
The following figure shows performance when scaling up to four nodes using Mellanox ConnectX-6 Dual Port 100 GbE. It is clear that the throughput increases significantly when the mapping is enabled (ON), providing direct communication between NVIDIA GPUs. The two-node experiments show an improvement in throughput of 18.7 percent while the four node experiments improve throughput by 26.7 percent.
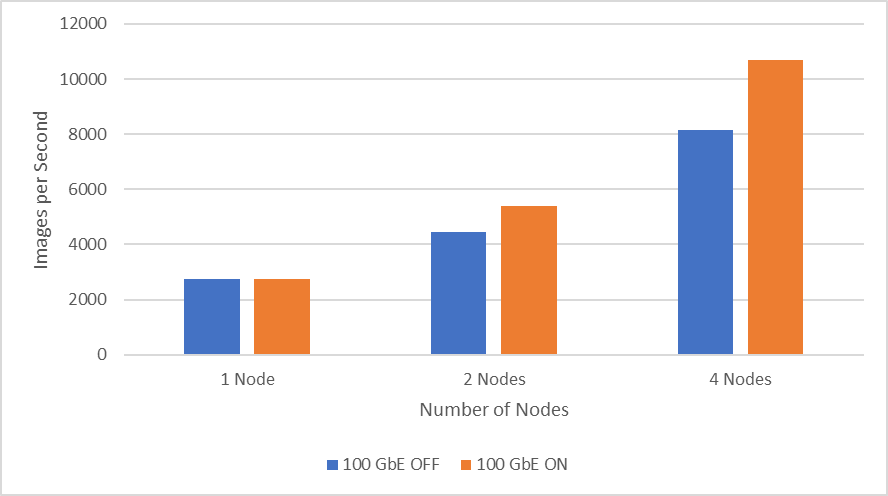
Figure 2: 100 GbE network performance
The following figure shows the scaling performance comparison between Mellanox ConnectX-6 Dual Port 100 GbE and Mellanox ConnectX-6 Dual Port 25 GbE while performing distributed training of the ResNet50 model. Using 100 GbE, two-node experiment results show an improved throughput of six percent while four-node experiments show an improved performance of 11.6 percent compared to 25 GbE.
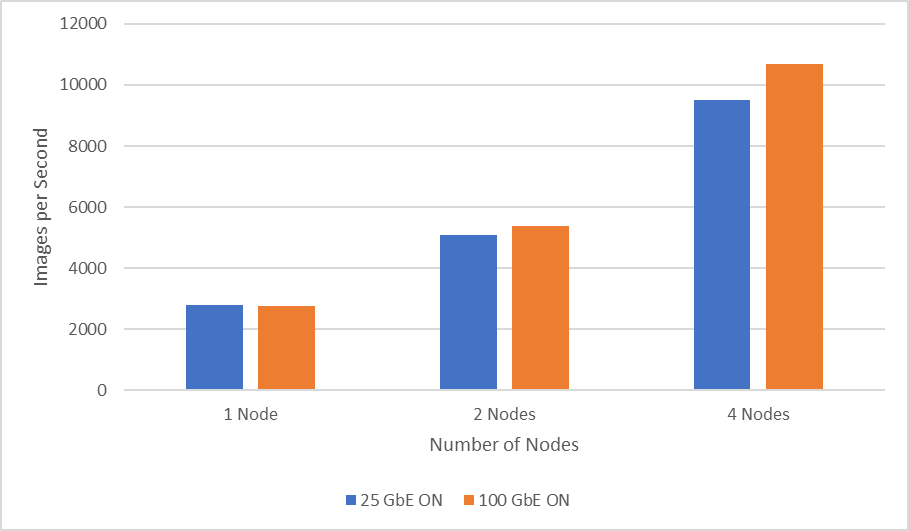
Figure 3: 25 GbE compared to 100 GbE network performance
Conclusion
In this blog, we considered GPUDirect RDMA and a few required steps to setup multinode experiments in the virtualized environment. The results showed that scaling to a larger number of nodes boosts throughput significantly when establishing direct communication between GPUs in a distributed training setup. The blog also showcased the performance comparison between Mellanox ConnectX-6 Dual Port 100 GbE and 25 GbE network adapters used for distributed training of a ResNet50 model.