




Silicon Diversity: Deploy GenAI on the PowerEdge XE9680 with AMD Instinct MI300X Accelerators
Wed, 08 May 2024 18:14:35 -0000
|Read Time: 0 minutes
| Entering the Era of Choice in AI: Putting Dell™ PowerEdge™ XE9680 Server with AMD Instinct™ MI300X Accelerators to the Test by Fine-tuning and Deploying Llama 2 70B Chat Model.
In this blog, Scalers AI™ will show you how to fine-tune large language models (LLMs), deploy 70B parameter models, and run a chatbot on the Dell™ PowerEdge™ XE9680 Server equipped with AMD Instinct™ MI300X Accelerators.
With the release of the AMD Instinct MI300X Accelerator, we are now entering an era of choice for leading AI Accelerators that power today’s generative AI solutions. Dell has paired the accelerators with its flagship PowerEdge XE9680 server for high performance AI applications. To put this leadership combination to the test, Scalers AI™ received early access and developed a fine-tuning stack with industry leading open-source components and deployed the Llama 2 70B Chat Model with FP16 precision in an enterprise chatbot scenario. In doing so, Scalers AI™ uncovered three critical value drivers:
- Deployed the Llama 2 70B parameter model on a single AMD Instinct MI300X Accelerator on the Dell PowerEdge XE9680 Server.
- Deployed eight concurrent instances of the model by utilizing all eight available AMD Instinct MI300X Accelerators on the Dell PowerEdge XE9680 Server.
- Fine-tuned the Llama 2 70B parameter model with FP16 precision on one Dell PowerEdge XE9680 Server with eight AMD Instinct MI300X accelerators.

This showcases industry leading total cost of ownership value for enterprises looking to fine-tune state of the art large language models with their own proprietary data, and deploy them on a single Dell PowerEdge XE9680 server equipped with AMD Instinct MI300X Accelerators.
 | “The PowerEdge XE9680 paired with AMD Instinct MI300X Accelerators delivers industry leading capability for fine-tuning and deploying eight concurrent instances of the Llama 2 70B FP16 model on a single server.”
| “The PowerEdge XE9680 paired with AMD Instinct MI300X Accelerators delivers industry leading capability for fine-tuning and deploying eight concurrent instances of the Llama 2 70B FP16 model on a single server.”
- Chetan Gadgil, CTO, Scalers AI
| To recreate, start with Dell PowerEdge XE9680 Server configurations as such.
OS: Ubuntu 22.04.4 LTS
Kernel version: 5.15.0-94-generic
Docker Version: Docker version 25.0.3, build 4debf41
ROCm™ version: 6.0.2
Server: Dell™ PowerEdge™ XE9680
GPU: 8x AMD Instinct™ MI300X Accelerators
| Setup Steps
- Install the AMD ROCm™ driver, libraries, and tools. Follow the detailed installation instructions for your Linux based platform.
To ensure these installations are successful, check the GPU info using rocm-smi.
- Clone the vLLM GitHub repository for 0.3.2 version as below:
git clone -b v0.3.2 https://github.com/vllm-project/vllm.git |
- Build the Docker container from the Dockerfile.rocm file inside the cloned vLLM repository.
cd vllm sudo docker build -f Dockerfile.rocm -t vllm-rocm:latest . |
- Use the command below to start the vLLM ROCm docker container and open the container shell.
sudo docker run -it \ --name vllm \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --shm-size 16G \ --group-add=video \ --workdir=/ \ vllm-rocm:latest bash |
- Request access to Llama 2 70B Chat Model from Llama 2 models from Meta and HuggingFace. Once the request is approved, log in to the Hugging Face CLI and enter your HuggingFace access token when prompted:
huggingface-cli login |
Part 1.0: Let’s start by showcasing how you can run the Llama 2 70B Chat Model on one AMD Instinct MI300X Accelerator on the PowerEdge XE9680 server. Previously we would use two cutting edge GPUs to complete this task. 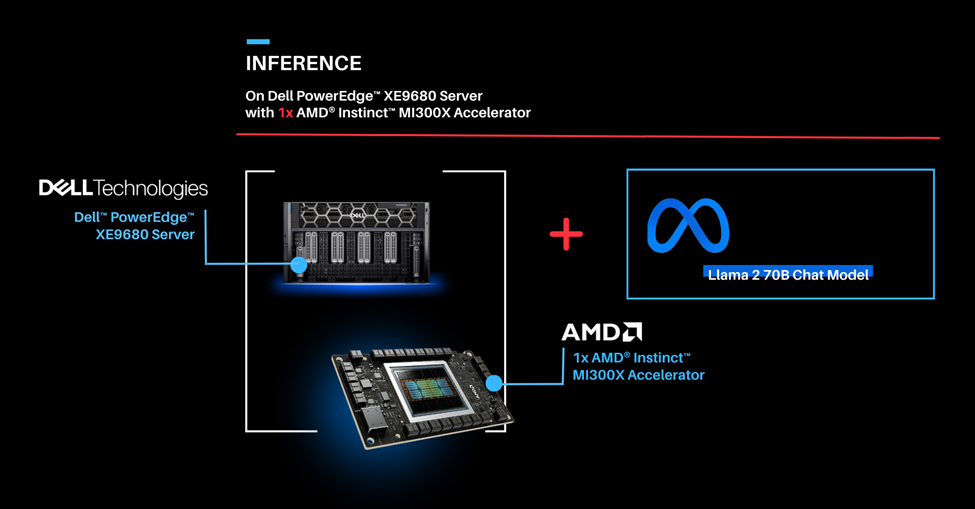
| Deploying Llama 2 70B Chat Model with vLLM 0.3.2 on a single AMD Instinct MI300X Accelerator with Dell PowerEdge XE9680 Server.
| Run vLLM Serving with Llama 2 70B Chat Model.
- Start the vLLM server for Llama 2 70B Chat model with FP16 precision loaded on a single AMD Instinct MI300X Accelerator.
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-70b-chat-hf --dtype float16 --tensor-parallel-size 1 |
- Execute the following curl request to verify if vLLM is successfully serving the model at the chat completion endpoint.
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-2-70b-chat-hf", "max_tokens":256, "temperature":1.0, "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Describe AMD ROCm in 180 words."} ]
}' |
The response should look as follows.
{"id":"cmpl-42f932f6081e45fa8ce7a7212cb19adb","object":"chat.completion","created":1150766,"model":"meta-llama/Llama-2-70b-chat-hf","choices":[{"index":0,"message":{"role":"assistant","content":" AMD ROCm (Radeon Open Compute MTV) is an open-source software platform developed by AMD for high-performance computing and deep learning applications. It allows developers to tap into the massive parallel processing power of AMD Radeon GPUs, providing faster performance and more efficient use of computational resources. ROCm supports a variety of popular deep learning frameworks, including TensorFlow, PyTorch, and Caffe, and is designed to work seamlessly with AMD's GPU-accelerated hardware. ROCm offers features such as low-level hardware control, GPU Virtualization, and support for multi-GPU configurations, making it an ideal choice for demanding workloads like artificial intelligence, scientific simulations, and data analysis. With ROCm, developers can take full advantage of AMD's GPU capabilities and achieve faster time-to-market and better performance for their applications."},"finish_reason":"stop"}],"usage":{"prompt_tokens":42,"total_tokens":237,"completion_tokens":195}} |
Part 1.1: Now that we have deployed the Llama 2 70B Chat Model on one AMD Instinct MI300X Accelerator on the Dell PowerEdge XE9680 server, let’s create a chatbot.
| Running Gradio Chatbot with Llama 2 70B Chat Model

This Gradio chatbot works by sending the user input query received through the user interface to the Llama 2 70B Chat Model being served using vLLM. The vLLM server is compatible with the OpenAI Chat API hence the request is sent in the OpenAI Chat API compatible format. The model generates the response based on the request which is sent back to the client. This response is displayed on the Gradio chatbot user interface.
| Deploying Gradio Chatbot
- If not already done, follow the instructions in the Setup Steps section to install the AMD ROCm driver, libraries, and tools, clone the vLLM repository, build and start the vLLM ROCm Docker container, and request access to the Llama 2 Models from Meta.
- Install the prerequisites for running the chatbot.
pip3 install -U pip pip3 install openai==1.13.3 gradio==4.20.1 |
- Log in to the Hugging Face CLI and enter your HuggingFace access token when prompted:
huggingface-cli login |
- Start the vLLM server for Llama 2 70B Chat model with data type FP16 on one AMD Instinct MI300X Accelerator.
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-70b-chat-hf --dtype float16 |
- Run the gradio_openai_chatbot_webserver.py from the /app/vllm/examples directory within the container with the default configurations.
cd /app/vllm/examples python3 gradio_openai_chatbot_webserver.py --model meta-llama/Llama-2-70b-chat-hf |
The Gradio chatbot will be running on the port 8001 and can be accessed using the URL http://localhost:8001. The query passed to the chatbot is “How does AMD ROCm contribute to enhancing the performance and efficiency of enterprise AI workflows?” The output conversation with the chatbot is shown below:

- To observe the GPU utilization, use the rocm-smi command as shown below.

- Use the command below to access various vLLM serving metrics through the /metrics endpoint.
curl http://127.0.0.1:8000/metrics |
The output should look as follows.
# HELP exceptions_total_counter Total number of requested which generated an exception # TYPE exceptions_total_counter counter # HELP requests_total_counter Total number of requests received # TYPE requests_total_counter counter requests_total_counter{method="POST",path="/v1/chat/completions"} 1 # HELP responses_total_counter Total number of responses sent # TYPE responses_total_counter counter responses_total_counter{method="POST",path="/v1/chat/completions"} 1 # HELP status_codes_counter Total number of response status codes # TYPE status_codes_counter counter status_codes_counter{method="POST",path="/v1/chat/completions",status_code="200"} 1 # HELP vllm:avg_generation_throughput_toks_per_s Average generation throughput in tokens/s. # TYPE vllm:avg_generation_throughput_toks_per_s gauge vllm:avg_generation_throughput_toks_per_s{model_name="meta-llama/Llama-2-70b-chat-hf"} 4.222076684555402 # HELP vllm:avg_prompt_throughput_toks_per_s Average prefill throughput in tokens/s. # TYPE vllm:avg_prompt_throughput_toks_per_s gauge vllm:avg_prompt_throughput_toks_per_s{model_name="meta-llama/Llama-2-70b-chat-hf"} 0.0 ... # HELP vllm:prompt_tokens_total Number of prefill tokens processed. # TYPE vllm:prompt_tokens_total counter vllm:prompt_tokens_total{model_name="meta-llama/Llama-2-70b-chat-hf"} 44 ... vllm:time_per_output_token_seconds_count{model_name="meta-llama/Llama-2-70b-chat-hf"} 136.0 vllm:time_per_output_token_seconds_sum{model_name="meta-llama/Llama-2-70b-chat-hf"} 32.18783768080175 ... vllm:time_to_first_token_seconds_count{model_name="meta-llama/Llama-2-70b-chat-hf"} 1.0 vllm:time_to_first_token_seconds_sum{model_name="meta-llama/Llama-2-70b-chat-hf"} 0.2660619909875095 |
Part 2: Now that we have deployed the Llama 2 70B Chat Model on a single GPU, let’s take full advantage of the Dell PowerEdge XE9680 server and deploy eight concurrent instances of the Llama 2 70B Chat Model with FP16 precision. To handle more simultaneous users and generate higher throughput, the 8x AMD Instinct MI300X Accelerators can be leveraged to deploy 8 vLLM serving deployments in parallel.
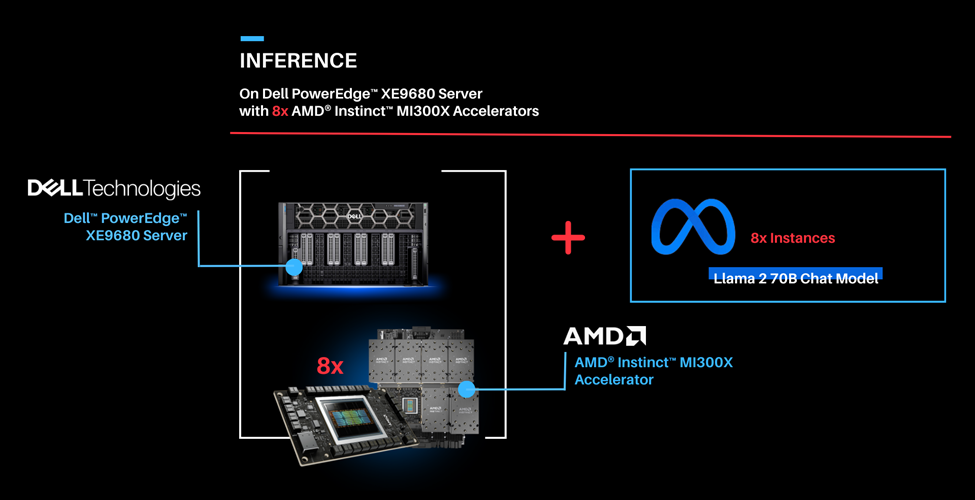
| Serving Llama 2 70B Chat model with FP16 precision using vLLM 0.3.2 on 8x AMD Instinct MI300X Accelerators with the PowerEdge XE9680 Server.
To enable the multi GPU vLLM deployment, we use a Kubernetes based stack. The stack consists of a Kubernetes Deployment with 8 vLLM serving replicas and a Kubernetes Service to expose all vLLM serving replicas through a single endpoint. The Kubernetes Service utilizes a round robin based strategy to distribute the requests across the vLLM serving replicas.
| Prerequisites
- Any Kubernetes distribution on the server.
- AMD GPU device plugins for Kubernetes setup on the installed Kubernetes distribution.
- A Kubernetes secret that grants access to the container registry, facilitating Kubernetes deployment.
| Deploying the multi vLLM serving on 8x AMD Instinct MI300X Accelerators.
- If not already done, follow the instructions in the Setup Steps section to install the AMD ROCm driver, libraries, and tools, clone the vLLM repository, build the vLLM ROCm Docker container, and request access to the Llama 2 Models from Meta. Push the built vllm-rocm:latest image to the container registry of your choice.
- Create a deployment yaml file “multi-vllm.yaml” based on the sample provided below.
# vllm deployment apiVersion: apps/v1 kind: Deployment metadata: name: vllm-serving namespace: default labels: app: vllm-serving spec: selector: matchLabels: app: vllm-serving replicas: 8 template: metadata: labels: app: vllm-serving spec: containers: - name: vllm image: container-registry/vllm-rocm:latest # update the container registry name args: [ "python3", "-m", "vllm.entrypoints.openai.api_server", "--model", "meta-llama/Llama-2-70b-chat-hf" ] env: - name: HUGGING_FACE_HUB_TOKEN value: "" # add your huggingface token with Llama 2 models access resources: requests: cpu: 15 memory: 150G amd.com/gpu: 1 # each replica is allocated 1 GPU limits: cpu: 15 memory: 150G amd.com/gpu: 1 imagePullSecrets: - name: cr-login # kubernetes container registry secret --- # nodeport service with round robin load balancing apiVersion: v1 kind: Service metadata: name: vllm-serving-service namespace: default spec: selector: app: vllm-serving type: NodePort ports: - name: vllm-endpoint port: 8000 targetPort: 8000 nodePort: 30800 # the external port endpoint to access the serving |
- Deploy the multi vLLM serving using the deployment configuration with kubectl. This will deploy eight replicas of vLLM serving using the Llama 2 70B Chat model with FP16 precision.
kubectl apply -f multi-vllm.yaml |
- Execute the following curl request to verify whether the model is being successfully served at the chat completion endpoint at port 30800.
curl http://localhost:30800/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-2-70b-chat-hf", "max_tokens":256, "temperature":1.0, "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Describe AMD ROCm in 180 words."} ]
}' |
The response should look as follows:
{"id":"cmpl-42f932f6081e45fa8ce7dnjmcf769ab","object":"chat.completion","created":1150766,"model":"meta-llama/Llama-2-70b-chat-hf","choices":[{"index":0,"message":{"role":"assistant","content":" AMD ROCm (Radeon Open Compute MTV) is an open-source software platform developed by AMD for high-performance computing and deep learning applications. It allows developers to tap into the massive parallel processing power of AMD Radeon GPUs, providing faster performance and more efficient use of computational resources. ROCm supports a variety of popular deep learning frameworks, including TensorFlow, PyTorch, and Caffe, and is designed to work seamlessly with AMD's GPU-accelerated hardware. ROCm offers features such as low-level hardware control, GPU Virtualization, and support for multi-GPU configurations, making it an ideal choice for demanding workloads like artificial intelligence, scientific simulations, and data analysis. With ROCm, developers can take full advantage of AMD's GPU capabilities and achieve faster time-to-market and better performance for their applications."},"finish_reason":"stop"}],"usage":{"prompt_tokens":42,"total_tokens":237,"completion_tokens":195}} |
- We used load testing tools similar to Apache Bench to simulate concurrent user requests to the serving endpoint. The screenshot below showcases the output of rocm-smi while Apache Bench is running 2048 concurrent requests.

Part 3: Now that we have deployed the Llama 2 70B Chat model on both one GPU and eight concurrent GPUs, let's try fine-tuning Llama 2 70B Chat with Hugging Face Accelerate.
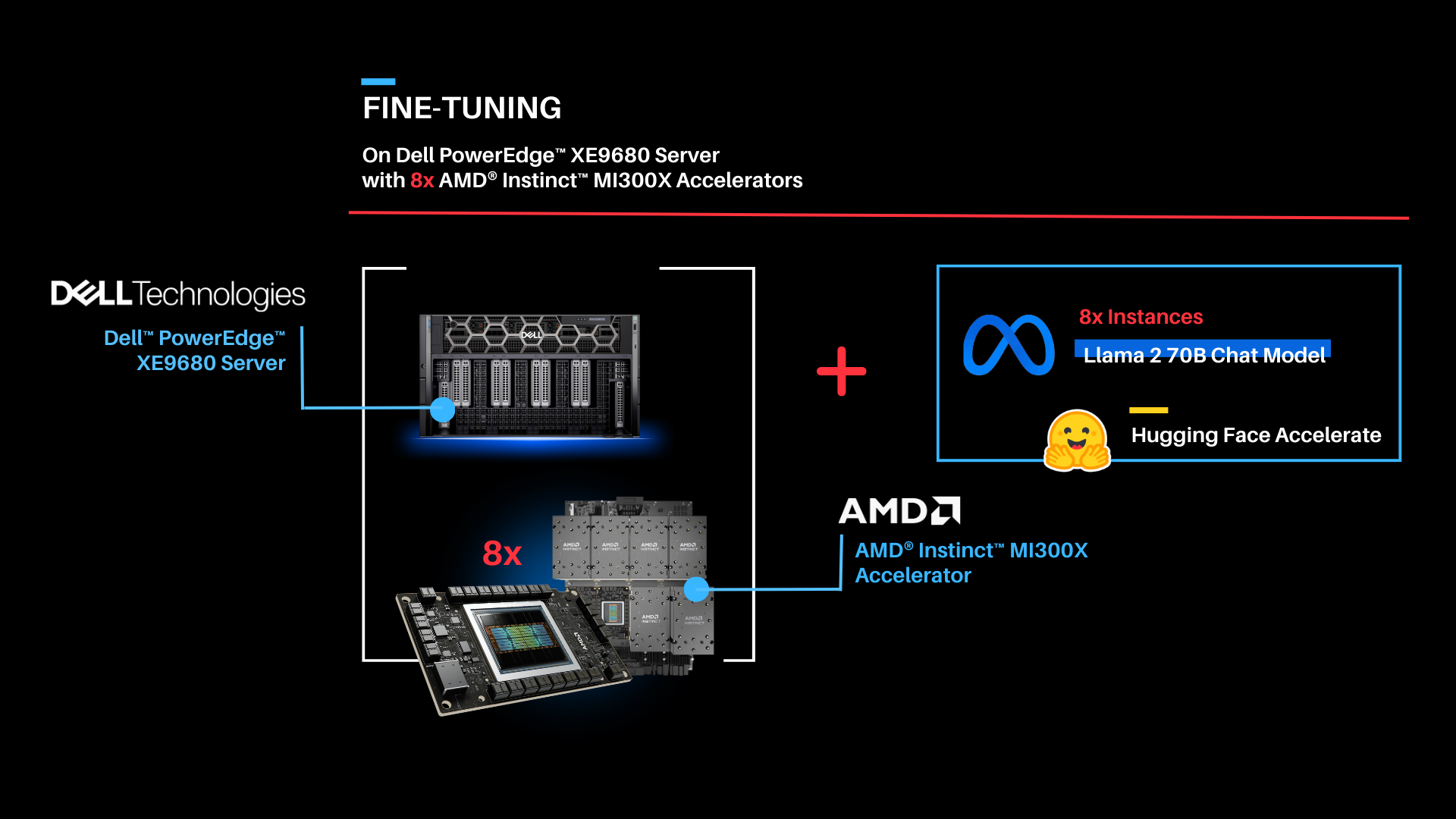
| Fine-tuning
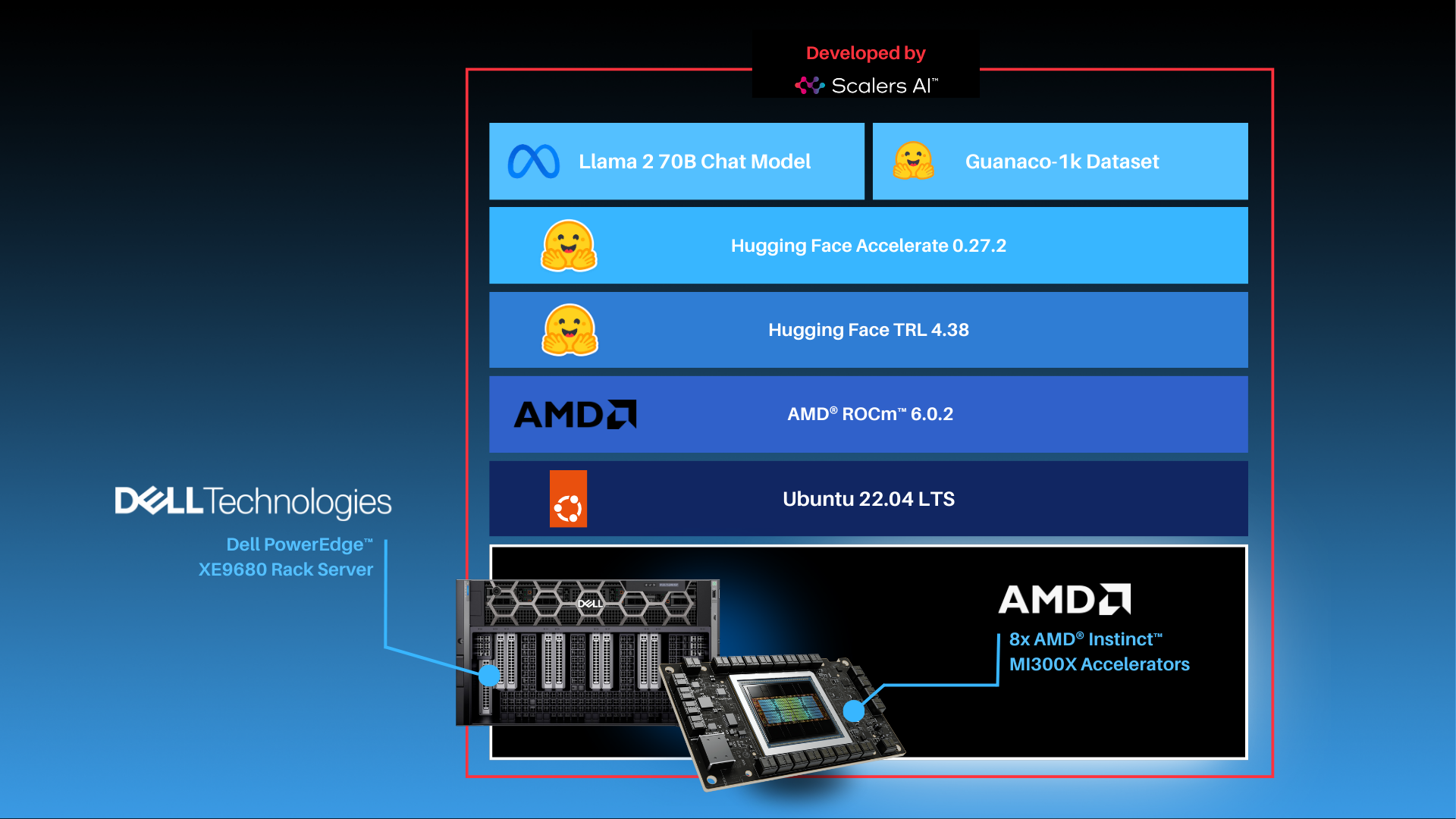
As shown above, the fine-tuning software stack begins with the AMD ROCm PyTorch image serving as the base, offering a tailored PyTorch library for optimal fine-tuning. Leveraging the Hugging Face Transformers library alongside Hugging Face Accelerate, facilitates multi-GPU fine-tuning capabilities. The Llama 2 70B Chat model will be fine-tuned with FP16 precision, utilizing the Guanaco-1k dataset from Hugging Face on eight AMD Instinct MI300X Accelerators.
In this scenario, we will perform full parameter fine-tuning of the Llama 2 70B Chat Model. While you can also implement fine-tuning using optimized techniques such as Low-Rank Adaptation of Large Language Models (LoRA) on accelerators with smaller memory footprints, performance tradeoffs exist on specific complex objectives. These nuances are addressed by full parameter fine-tuning methods, which generally require accelerators that support significant memory requirements.
| Fine-tuning Llama 2 70B Chat on 8x AMD Instinct MI300X Accelerators.
Fine-tune the Llama 2 70B Chat Model with FP16 precision for question and answer tasks by utilizing the mlabonne/guanaco-llama2-1k dataset on the 8X AMD Instinct MI300X Accelerators.
- If not already done, install the AMD ROCm driver, libraries, and tools and request access to the Llama 2 Models from Meta following the instructions in the Setup Steps section.
- Start the fine-tuning docker container with the AMD ROCm PyTorch base image.
The below command opens a shell within the docker container.
sudo docker run -it \ --name fine-tuning \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --shm-size 16G \ --group-add=video \ --workdir=/ \ rocm/pytorch:rocm6.0.2_ubuntu22.04_py3.10_pytorch_2.1.2 bash |
- Install the necessary Python prerequisites.
pip3 install -U pip pip3 install transformers==4.38.2 trl==0.7.11 datasets==2.18.0 |
- Log in to Hugging Face CLI and enter your HuggingFace access token when prompted.
huggingface-cli login |
- Import the required Python packages.
from datasets import load_dataset from transformers import ( AutoModelForCausalLM, AutoTokenizer, TrainingArguments, pipeline ) from trl import SFTTrainer |
- Load the Llama 2 70B Chat Model and the mlabonne/guanaco-llama2-1k dataset from Hugging Face.
# load the model and tokenizer base_model_name = "meta-llama/Llama-2-70b-chat-hf"
# tokenizer parameters llama_tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True) llama_tokenizer.pad_token = llama_tokenizer.eos_token llama_tokenizer.padding_side = "right"
# load the based model base_model = AutoModelForCausalLM.from_pretrained( base_model_name, device_map="auto", ) base_model.config.use_cache = False base_model.config.pretraining_tp = 1
# load the dataset from huggingface dataset_name = "mlabonne/guanaco-llama2-1k" training_data = load_dataset(dataset_name, split="train") |
- Define fine-tuning configurations and start fine-tuning for 1 epoch. The fine tuned model will be saved in finetuned_llama2_70b directory.
# fine tuning parameters train_params = TrainingArguments( output_dir="./runs", num_train_epochs=1, # fine tuning for 1 epochs per_device_train_batch_size=8 # setting per GPU batch size )
# define the trainer fine_tuning = SFTTrainer( model=base_model, train_dataset=training_data, dataset_text_field="text", tokenizer=llama_tokenizer, args=train_params, max_seq_length=512 )
# start the fine tuning run fine_tuning.train()
# save the fine tuned model fine_tuning.model.save_pretrained("finetuned_llama2_70b") print("Fine-tuning completed") |
- Use the `rocm-smi` command to observe GPU utilization while fine-tuning.

| Summary

Dell PowerEdge XE9680 Server equipped with AMD Instinct MI300X Accelerators offers enterprises industry leading infrastructure to create custom AI solutions using their proprietary data. In this blog, we showcased how enterprises deploying applied AI can take advantage of this solution in three critical use cases:
- Deploying the entire 70B parameter model on a single AMD Instinct MI300X Accelerator in Dell PowerEdge XE9680 Server
- Deploying eight concurrent instances of the model, each running on one of eight AMD Instinct MI300X accelerators on the Dell PowerEdge XE9680 Server
- Fine-tuning the 70B parameter model with FP16 precision on one PowerEdge XE9680 with all eight AMD Instinct MI300X accelerators
Scalers AI is excited to see continued advancements from Dell, AMD, and Hugging Face on hardware and software optimizations in the future.
| Additional Criteria for IT Decision Makers
| What is fine-tuning, and why is it critical for enterprises?
Fine-tuning enables enterprises to develop custom models with their proprietary data by leveraging the knowledge already encoded in pre-trained models. As a result, fine-tuning requires less labeled data and time for training compared to training a model from scratch, making it a more efficient approach for achieving competitive performance, particularly in the quantity of computational resources used and training time.
| Why is memory footprint critical for LLMs?
Large language models often have enormous numbers of parameters, leading to significant memory requirements. When working with LLMs, it is essential to ensure that the GPU has sufficient memory to store these parameters so that the model can run efficiently. In addition to model parameters, large language models require substantial memory to store input data, intermediate activations, and gradients during training or inference, and insufficient memory can lead to data loss or performance degradation.
| Why is the Dell PowerEdge XE9680 Server with AMD Instinct MI300X Accelerators well-suited for LLMs?
Designed especially for AI tasks, Dell PowerEdge XE9680 Server is a robust data-processing server equipped with eight AMD Instinct MI300X accelerators, making it well-suited for AI-workloads, especially for those involving training, fine-tuning, and conducting inference with LLMs. AMD Instinct MI300X Accelerator is a high-performance AI accelerator intended to operate in groups of eight within AMD’s generative AI platform.
Running inference, specifically with a Large Language Model (LLM), requires approximately 1.2 times the memory occupied by the model on a GPU. In FP16 precision, the model memory requirement can be estimated as 2 bytes per parameter multiplied by the number of model parameters. For example, the Llama 2 70B model with FP16 precision requires a minimum of 168 GB of GPU memory to run inference.
With 192 GB of GPU memory, a single AMD Instinct MI300X Accelerator can host an entire Llama 2 70B parameter model for inference. It is optimized for LLMs and can deliver up to 10.4 Petaflops of performance (BF16/FP16) with 1.5TB of total HBM3 memory for a group of eight accelerators.
Copyright © 2024 Scalers AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. AMD, Instinct™, ROCm™, and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other product names are the trademarks of their respective owners.
***DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.
Related Documents

Delivering Choice for Enterprise AI: Multi-Node Fine-Tuning on Dell PowerEdge XE9680 with AMD Instinct MI300X
Wed, 15 May 2024 21:26:35 -0000
|Read Time: 0 minutes
In this blog, Scalers AI and Dell have partnered to show you how to use domain-specific data to fine-tune the Llama 3 8B Model with BF16 precision on a distributed system of Dell PowerEdge XE9680 Servers equipped with AMD Instinct MI300X Accelerators.

| Introduction
Large language models (LLMs) have been a significant breakthrough in AI and demonstrated remarkable capabilities in understanding and generating human-like text across a wide range of domains. The first step in approaching an LLM-assisted AI solution is generally pre-training, during which an untrained model learns to anticipate the next token in a given sequence using information acquired from various massive datasets, followed by fine-tuning, which involves adapting the pre-trained model for a domain specific task by updating a task-specific layer on top.
Fine-tuning, however, still requires a lot of time, computation, and RAM. One approach to reducing computation time is distributed fine-tuning, which allows computational resources to be more efficiently utilized by parallelizing the fine-tuning process across multiple GPUs or devices. Scalers AI showcased various industry-leading capabilities of Dell PowerEdge XE9680 Servers paired with AMD Instinct MI300X Accelerators on a distributed fine-tuning task by uncovering these key value drivers:
- Developed a distributed finetuning software stack on the flagship Dell PowerEdge XE9680 Server equipped with eight AMD Instinct MI300X Accelerators.
- Fine-tuned Llama 3 8B with BF16 precision using the PubMedQA medical dataset on two Dell PowerEdge XE9680 Servers each equipped with AMD Instinct MI300X Accelerators.
- Deployed fine-tuned model in an enterprise chatbot scenario & conducted side by side tests with Llama 3 8B.
- Released distributed fine-tuning stack with support for Dell PowerEdge XE9680 Servers equipped with AMD Instinct MI300X Accelerators and NVIDIA H100 Tensor Core GPUs to offer enterprise choice.
| The Software Stack
This solution stack leverages Dell PowerEdge Rack Servers, coupled with Broadcom Ethernet NICs for providing high-speed inter-node communications needed for distributed computing as well as Kubernetes for scaling. Each Dell PowerEdge server contains AI accelerators, specifically AMD Instinct Accelerators to enhance LLM fine-tuning.
The architecture diagram provided below illustrates the configuration of two Dell PowerEdge XE9680 servers with eight AMD Instinct MI300X accelerators each.
Leveraging Dell PowerEdge, Dell PowerSwitch, and high-speed Broadcom Ethernet Network adaptors, the software platform integrates Kubernetes (K3S), Ray, Hugging Face Accelerate, Microsoft DeepSpeed, with other AI libraries and drivers including AMD ROCm™ and PyTorch.
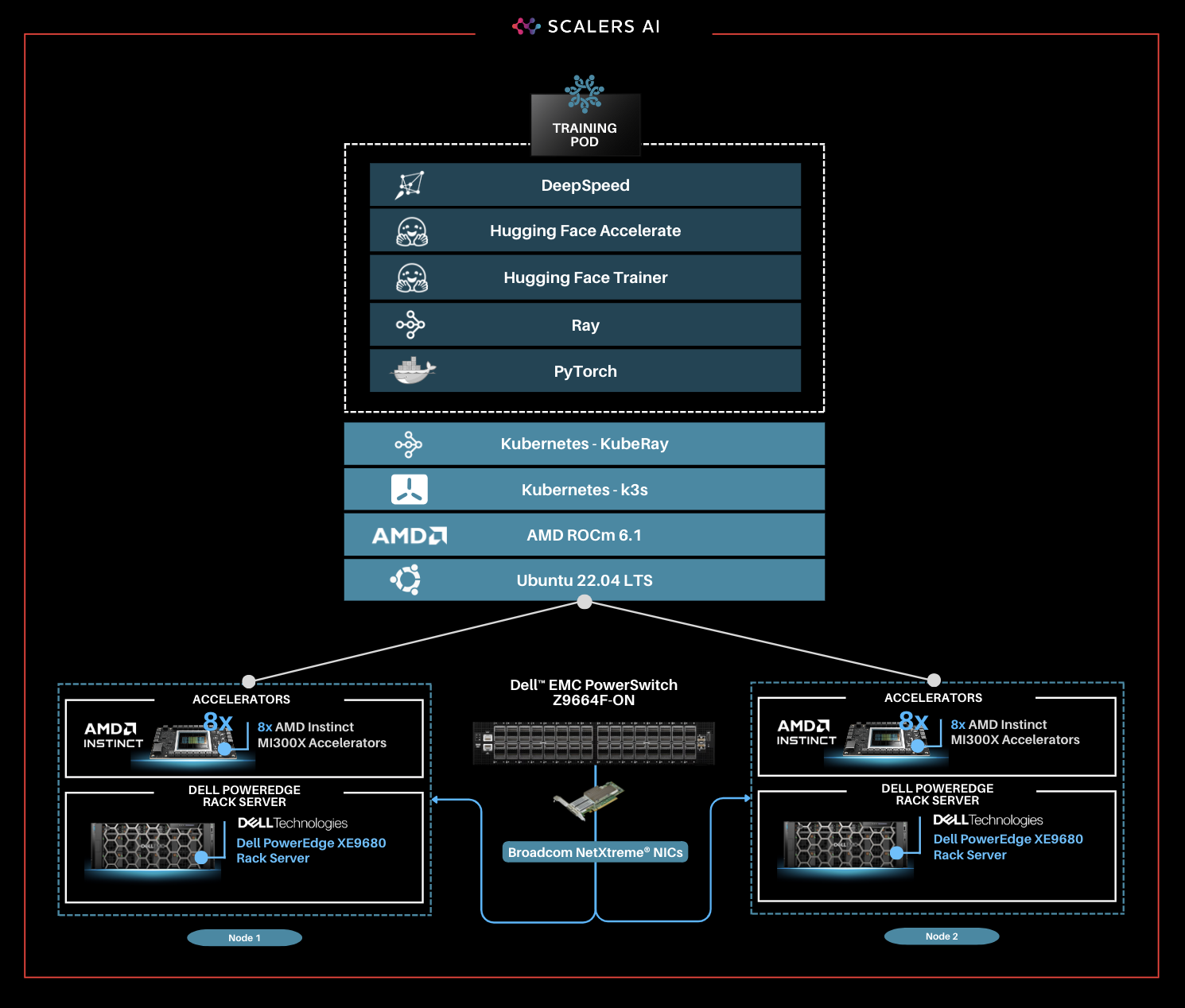
| Step-by-Step Guide
Step 1. Set up the distributed cluster.
Follow the k3s setup and introduce additional parameters for the k3s installation script. This involves configuring flannel, the networking fabric for kubernetes, with a user-selected specified network interface and utilizing the "host-gw" backend for networking. Then, Helm, the package manager for Kubernetes, will be used, and AMD plugins will be incorporated to grant access to AMD Instinct MI300X GPUs for the cluster pods.
Step 2. Install KubeRay and configure Ray Cluster.
The next steps include installing Kuberay, a Kubernetes operator, using Helm. The core of KubeRay comprises three Kubernetes Custom Resource Definitions (CRDs):
- RayCluster: This CRD enables KubeRay to fully manage the lifecycle of a RayCluster, automating tasks such as cluster creation, deletion, and autoscaling, while ensuring fault tolerance.
- RayJob: KubeRay streamlines job submission by automatically creating a RayCluster when needed. Users can configure RayJob to initiate job deletion once the task is completed, enhancing operational efficiency.
- RayService: RayService is made up of two parts: a RayCluster and a Ray Serve deployment graph. RayService offers zero-downtime upgrades for RayCluster and high availability.
helm repo add kuberay https://ray-project.github.io/kuberay-helm/ helm install kuberay-operator kuberay/kuberay-operator --version 1.0.0 |
This RayCluster consists of a head node followed by 1 worker node. In a YAML file, the head node is configured to run Ray with specified parameters, including the dashboard host and the number of GPUs, as shown in the excerpt below. Here, the worker node is under the name "gpu-group”.
... headGroupSpec: rayStartParams: dashboard-host: "0.0.0.0" # setting num-gpus on the rayStartParams enables # head node to be used as a worker node num-gpus: "8" ... |
The Kubernetes service is also defined to expose the Ray dashboard port for the head node. The deployment of the Ray cluster, as defined in a YAML file, will be executed using kubectl.
kubectl apply -f cluster.yml |
Step 3. Fine-tune Llama 3 8B Model with BF16 Precision.
You can either create your own dataset or select one from HuggingFace. The dataset must be available as a single json file with the specified format below.
{"question":"Is pentraxin 3 reduced in bipolar disorder?", "context":"Immunologic abnormalities have been found in bipolar disorder but pentraxin 3, a marker of innate immunity, has not been studied in this population.", "answer":"Individuals with bipolar disorder have low levels of pentraxin 3 which may reflect impaired innate immunity."}
Jobs will be submitted to the Ray Cluster through the Ray Python SDK utilizing the Python script, job.py, provided below.
# job.py
from ray.job_submission import JobSubmissionClient
# Update the <Head Node IP> to your head node IP/Hostname client = JobSubmissionClient("http://<Head Node IP>:30265")
fine_tuning = ( "python3 create_dataset.py \ --dataset_path /train/dataset.json \ --prompt_type 5 \ --test_split 0.2 ;" "python3 train.py \ --num-devices 16 \ # Number of GPUs available --batch-size-per-device 12 \ --model-name meta-llama/Meta-Llama-3-8B-Instruct \ # model name --output-dir /train/ \ --hf-token <HuggingFace Token> " ) submission_id = client.submit_job(entrypoint=fine_tuning,)
print("Use the following command to follow this Job's logs:") print(f"ray job logs '{submission_id}' --address http://<Head Node IP>:30265 --follow") |
This script initializes the JobSubmissionClient with the head node IP address, and sets parameters such as prompt_type, which determines how each question-answer datapoint is formatted when inputted into the model, as well as batch size and number of devices for training. It then submits the job with these set parameter definitions.
The initial phase involves generating a fine-tuning dataset, which will be stored in a specified format. Configurations such as the prompt used and the ratio of training to testing data can be added. During the second phase, we will proceed with fine-tuning the model. For this fine-tuning, configurations such as the number of GPUs to be utilized, batch size for each GPU, the model name as available on HuggingFace, HuggingFace API Token, and the number of epochs to fine-tune can all be specified.
Finally, in the third phase, we can start fine-tuning the model.
python3 job.py |
The fine-tuning jobs can be monitored using Ray CLI and Ray Dashboard.
- Using Ray CLI:
- Retrieve submission ID for the desired job.
- Use the command below to track job logs.
ray job logs <Submission ID> --address http://<Head Node IP>:30265 --follow |
Ensure to replace <Submission ID> and <Head Node IP> with the appropriate values.
- Using Ray Dashboard:
- To check the status of fine-tuning jobs, simply visit the Jobs page on your Ray Dashboard at <Head Node IP>:30265 and select the specific job from the list.
The reference code for this solution can be found here.
| Industry Specific Medical Use Case
Following the fine-tuning process, it is essential to assess the model’s performance on a specific use-case.
This solution uses the PubMedQA medical dataset to fine-tune a Llama 3 8B model on BF16 precision for our evaluation. The process was conducted on a distributed setup, utilizing a batch size of 12 per device, with training performed over 25 epochs. Both the base model and fine-tuned model are deployed in the Scalers AI enterprise chatbot to compare performance. The example below prompts the chatbot with a question from the MedMCQA dataset available on Hugging Face, for which the correct answer is “a.”

As shown on the left, the response generated by the base Llama 3 8B model is unstructured and vague, and returns an incorrect answer. On the other hand, the fine-tuned model returns the correct answer and also generates a thorough and detailed response to the instruction while demonstrating an understanding of the specific subject matter, in this case medical knowledge, relevant to the instruction.
| Enterprise Choice in Industry Leading Accelerators
To deliver enterprise choice, this distributed fine-tuning software stack supports both AMD Instinct MI300X Accelerators as well as NVIDIA H100 Tensor Core GPUs. Below, we show a visualization of the unified software and hardware stacks, running seamlessly with the Dell PowerEdge XE9680 Server.
“Scalers AI is thrilled to offer choice in distributed fine-tuning across both leading AI GPUs in the industry on the flagship PowerEdge XE9680.” -CEO at Scalers AI |
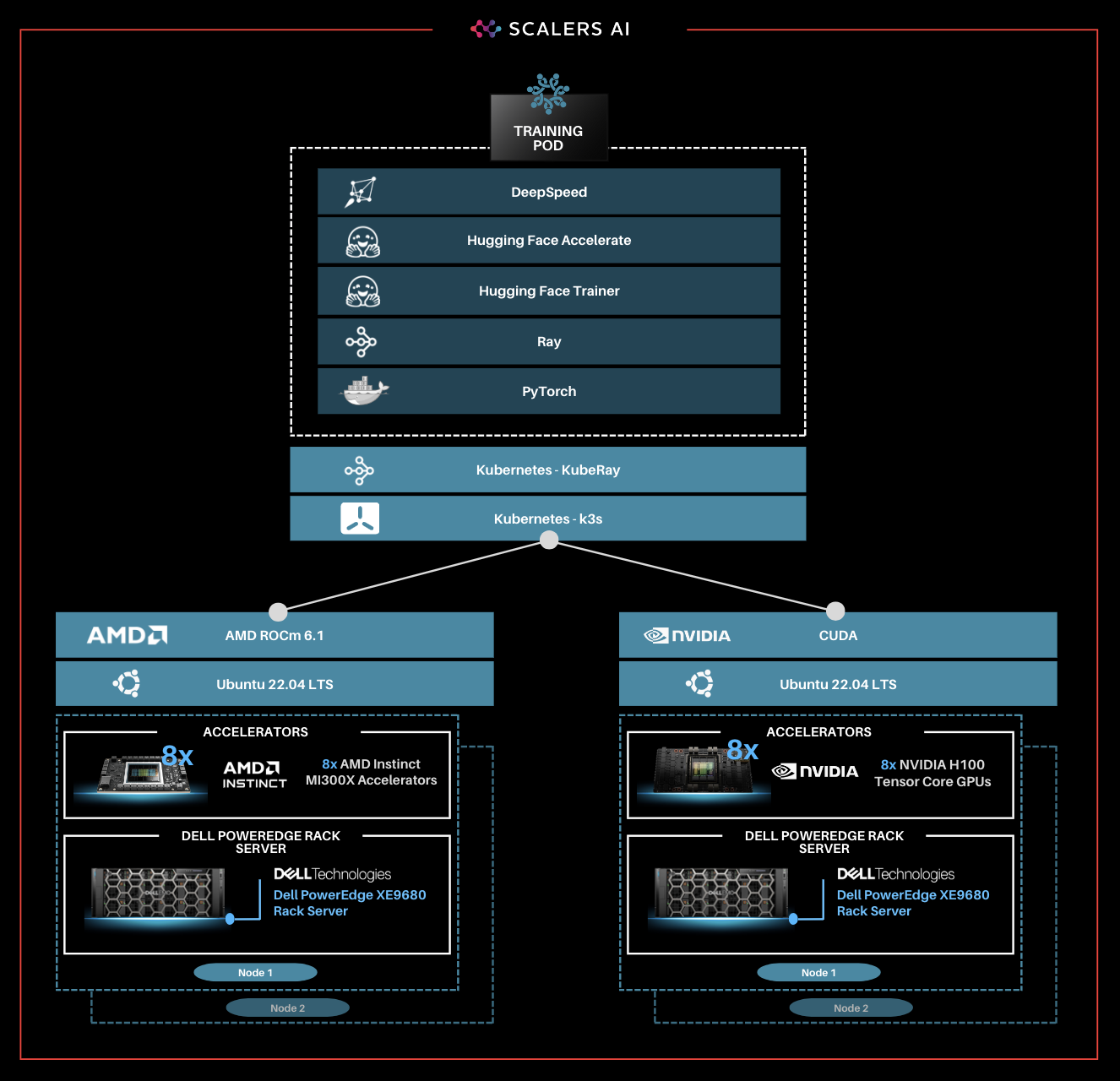
| Summary
Dell PowerEdge XE9680 Server, featuring AMD Instinct MI300X Accelerators, provides enterprises with cutting-edge infrastructure for creating industry-specific AI solutions using their own proprietary data. In this blog, we showcased how enterprises deploying applied AI can take advantage of this unified AI ecosystem by delivering the following critical solutions:
- Developed a distributed finetuning software stack on the flagship Dell PowerEdge XE9680 Server equipped with eight AMD Instinct MI300X Accelerators.
- Fine-tuned Llama 3 8B with BF16 precision using the PubMedQA medical dataset on two Dell PowerEdge XE9680 Servers each equipped with eight AMD Instinct MI300X Accelerators.
- Deployed fine-tuned model in an enterprise chatbot scenario & conducted side by side tests with Llama 3 8B.
- Released distributed fine-tuning stack with support for Dell PowerEdge XE9680 Servers equipped with AMD Instinct MI300X Accelerators and NVIDIA H100 Tensor Core GPUs to offer enterprise choice.
Scalers AI is excited to see continued advancements from Dell and AMD on hardware and software optimizations in the future, including an upcoming RAG (retrieval augmented generation) offering running on the Dell PowerEdge XE9680 Server with AMD Instinct MI300X Accelerators at Dell Tech World ‘24.
| References
AMD products: AMD Library, https://library.amd.com/account/dashboard/
Nvidia images: Nvidia.com
Copyright © 2024 Scalers AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. AMD, Instinct™, ROCm™, and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other product names are the trademarks of their respective owners.
***DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.

PowerEdge XE9680 Rack Integration
Mon, 29 Apr 2024 16:12:31 -0000
|Read Time: 0 minutes
Introduction
Proper server rack integration is crucial for a data center's efficient and reliable operation. Optimizing space, power, and cooling can reduce downtime, simplify fleet management, improve serviceability, and lower overall costs. However, successful server rack integration requires careful planning, attention to detail, and expertise in server hardware, networking, and system administration.
This paper focuses on the critical aspects of deploying the PowerEdge XE9680 server in your data center. It describes key factors such as selecting the appropriate rack type, sizing the rack to meet current and future needs, installing and configuring the server hardware and related components, and ensuring proper power and cooling.
At Dell Technologies, we understand the importance of meeting our customers where they are. Whether you require full-service rack integration and deployment services or expert advice, we are committed to providing the support you need to achieve your goals. By leveraging our expertise and resources, you can be confident in your ability to implement the server rack integration that meets your unique needs and requirements.
The PowerEdge XE9680
The Dell PowerEdge XE9680 is a high-performance server designed to deliver exceptional performance for machine learning workloads, AI inferencing, and high-performance computing. Table 1 lists key specifications to consider when installing it in a rack.
Table 1. Server specifications
Feature | Technical Specifications |
Form Factor | 6U Rack Server |
Dimensions and Weight | Height — 263.2 mm / 10.36 inches Width — 482.0 mm / 18.98 inches Depth — 1008.77 mm / 39.72 inches with bezel — 995 mm / 39.17 inches without bezel —1075 mm /42.32 inches with Cable Management Arm (CMA) Weight —107 kg / 236 lbs. |
Cooling Options | Air Cooling |
XE9680 rack integration – critical factors
Server operating environment
The American Society of Heating, Refrigerating, and Air-Conditioning Engineers (ASHRAE) data center specifications focus on temperature and humidity control, optimized air distribution, airflow management, air quality, and energy efficiency. Key recommendations include maintaining appropriate temperature and humidity ranges, implementing hot aisle/cold aisle configurations and containment systems, managing airflow effectively, ensuring high indoor air quality, and adopting energy-efficient technologies.
The Dell PowerEdge XE9680 complies with the A2 Class ASHRAE specifications in Table 2.
Table 2. Operating environment specifications
Product Operation | Product Power Off | |||||
Dry-Bulb Temp, °C | Humidity Range, Noncondensing | Max Dew Point, °C | Max Elevation, meters | Max. Rate of Change, °C/hour | Dry-Bulb Temp, °C | Relative Humidity, % |
10-35
| –12°C DP and 8% rh to 21°C DP and 80% rh | 21 | 3050 | 20 | 5 to 45 | 8 to 80 |
Note: The maximum operating temperature is derated by 1°C per 300m above 900m in altitude.
For optimal performance and reliability, it is recommended to operate within the defined specification ranges. While it is possible to operate at the edge of these ranges, Dell does not recommend continuous operation under such conditions due to potential impacts on performance and reliability.
Cabinet recommendations
When choosing a cabinet, it is important to consider factors such as size, ventilation, cable management, and security. The right cabinet should provide ample space for equipment, efficient airflow to prevent overheating, organized cable routing, and robust physical protection for valuable server hardware. Careful consideration of these factors ensures optimal performance, reliability, and ease of maintenance for your server infrastructure. We recommend the following cabinet specifications for optimal XE9680 installation:
- Minimum width of 600mm / 23.62 inches
- Minimum depth of 1200mm / 47.24 inches
- 42 or 48RU height
- Rear cable management support
- Support for rear facing horizontal or vertical PDUs
- To accommodate the depth of server and IO cables, it may be necessary to utilize cabinet extensions depending on cabinet vendor
- Side panels for single cabinets
Rack and stack
Installing servers in a rack is a crucial aspect of server management. Proper placement within the rack ensures efficient use of space, ease of access, and optimal airflow. Each server should be securely mounted in the rack, taking into account factors such as weight distribution and cable management. Strategic placement allows for better cooling, reducing the risk of overheating, and prolonging the lifespan of the equipment. Additionally, thoughtful placement enables easy maintenance, troubleshooting, and scalability as the server environment evolves. By giving careful consideration to the placement of servers in a rack, you can create a well-organized and functional setup that maximizes performance and minimizes downtime. We recommend the following:
- The PowerEdge XE9680 has a maximum chassis weight of 107kg/236 lbs. It is recommended to install the first XE9680 server in the 1RU location, and to install any additional servers directly above it. This configuration helps maintain a low center of gravity, reducing the risk of cabinet tipping.
- For ease of assembly and seismic bracket installation, we recommend starting at the 3RU position when using seismic hardware. It is important for customers to adhere to local building codes, and to ensure that all necessary facility accommodations are in place and that the seismic brackets are correctly installed.
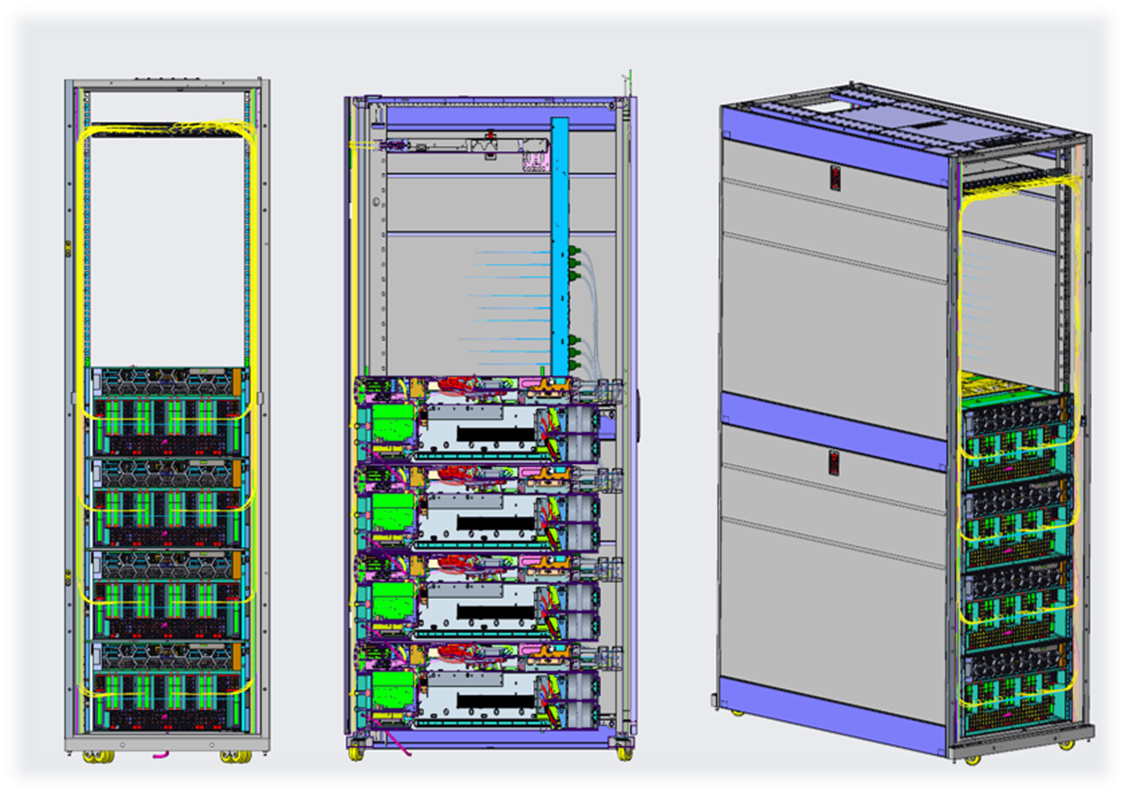
Figure 1. 4x PowerEdge XE9680 servers in a rack
Power distribution recommendations
The PowerEdge XE9680, equipped with H100 GPUs, has an approximate maximum power draw of 11.5kW. It comes with six 2800W Mixed Mode power supply units (PSUs) that feature a C22 input socket.
The XE9680 currently supports 5+1 fault-tolerant redundancy (FTR). (An additional 3+3 FTR configuration will be introduced in the Fall of 2023.) It is important to note that in 3+3 mode, system performance may throttle upon power supply failure to prevent overloading the remaining power supplies.
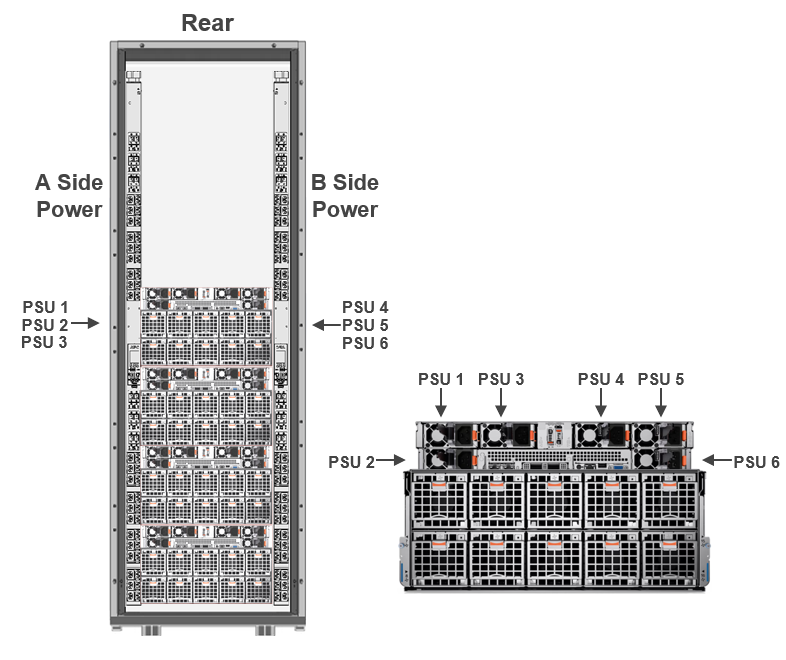 Figure 2. PowerEdge XE9680 with PDU
Figure 2. PowerEdge XE9680 with PDU
For the XE9680, we recommend the following PDU specifications:
- Vertical or horizontal PDUs
- One circuit breaker per power supply
- C19 receptacles
Table 3. PDU specifications
PDU Input Voltage | XE9680s Per Cabinet | PDUs Per Cabinet | Circuit Breakers Per PDU (Min) | Single PDU Requirement (Min) |
208V | 2 | 2 | 6 | 60A (48A Rated) 17.3kW |
208V | 2 | 4 | 3 | 30A (24A Rated) 8.6kW |
208V | 4 | 2 | 12 | 100A (80A Rated) 28.8kW |
208V | 4 | 4 | 6 | 60A (48A Rated) 17.3kW |
400/415V | 2 | 2 | 6 | |
400/415V | 2 | 4 | 3 | 20A (16A Rated) 11.1kW@400 / 11.5kW@415V |
400/415V | 4 | 2 | 12 | |
400/415V | 4 | 4 | 6 |
Note: Single PDU Power Requirement = Input Voltage * Current Rating * 1.73.
The factor of 1.73 (the square root of 3) is used to account for three-phase power systems commonly used in data centers and industrial settings. By multiplying the input voltage, current rating, and 1.73, you can determine the power capacity needed for a single PDU to adequately support the connected equipment. This calculation helps ensure that the PDU can handle the power load and prevent overloading or electrical issues.
Optimal thermal management for performance and reliability
Thermal management is important in data centers to ensure equipment reliability, optimize performance, improve energy efficiency, prolong equipment lifespan, and reduce environmental impact. By maintaining appropriate temperature levels, data centers can achieve a balance between operational reliability, energy efficiency, and cost-effectiveness.
Dell Technologies recommends the following best practices for thermal management:
- Ensure a cold aisle inlet airflow of 1200 CFM.
- If additional equipment is rear-facing, consider using 1 or 2 RU ducts.
- Use filler panels for all open front U spaces.
- For stand-alone racks, install cabinet side panels to optimize airflow.
The XE9680 is engineered to operate efficiently within ambient temperature conditions of up to 35°C. Although it is technically capable of functioning in such environments, maintaining lower temperatures is highly recommended to ensure the device's optimal performance and reliability. By operating the XE9680 in a cooler environment, the risk of overheating and potential performance degradation can be mitigated, resulting in a more stable and reliable operation overall.

Cabinet cable management
Proper cable management in a server rack improves organization, airflow, accessibility, safety, and scalability. It enhances the reliability, performance, and maintainability of the entire IT infrastructure.
The PowerEdge XE9680 supports Ethernet and InfiniBand network adaptors, which are installed at the front of the server for easy access in cold aisles. To ensure proper cable management, the chosen cabinet solution should provide a minimum clearance of 93.12mm from the face of the network adaptor to the cabinet door. This clearance is necessary to accommodate the bend radius of a typical DAC (Direct Attach Cable) cable (see Figure 3).
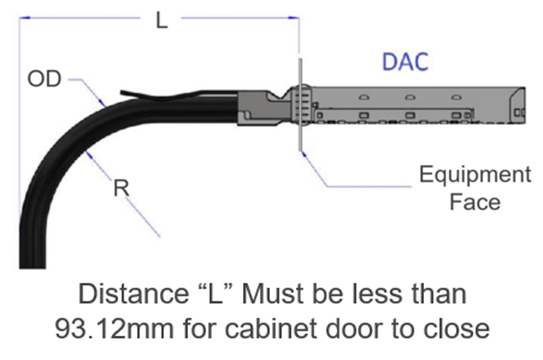
Figure 3. DAC clearance recommendations
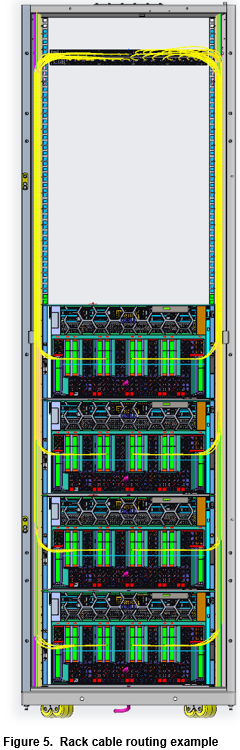 The maximum cable length in the figure 6 is 2.07 meters or 81.49 inches.
The maximum cable length in the figure 6 is 2.07 meters or 81.49 inches.
With adjacent racks, it is possible to improve cable management by removing the inner side panels. This alteration provides an open space along the sides of the racks, allowing cables to be conveniently routed between adjacent racks. By eliminating the inner side panels, technicians or IT professionals gain unobstructed access to the interconnecting cables, making it simpler to establish and maintain organized cabling infrastructure.
The following two figures show power cables routed through the optional cable management arm (CMA). The CMA can be mounted to either side of the sliding server rails.

Figure 4. Power cables in cable arm
Network switch
AI server network switches play a crucial role in supporting high-performance and data-intensive artificial intelligence workloads. These switches handle the demanding requirements of AI applications, providing high bandwidth, low latency, and efficient data transfer. They facilitate seamless communication and data exchange between AI servers, to ensure optimal performance and to minimize bottlenecks.
Installing a switch in a rack for servers is vital for establishing a robust and efficient network infrastructure, enabling seamless communication, centralized management, scalability, and optimal performance for the server environment.
The network switch may require offsetting within the rack to accommodate the bend radius of specific networking cables. To achieve this, a bracket can be utilized to push the network switch towards the rear of the rack, creating space for the necessary cable bend radius while ensuring proper installation of the front door. The accompanying images demonstrate the process of using the bracket to adjust the network switch position within the rack. This allows for optimal cable management and ensures the smooth operation of the network infrastructure.
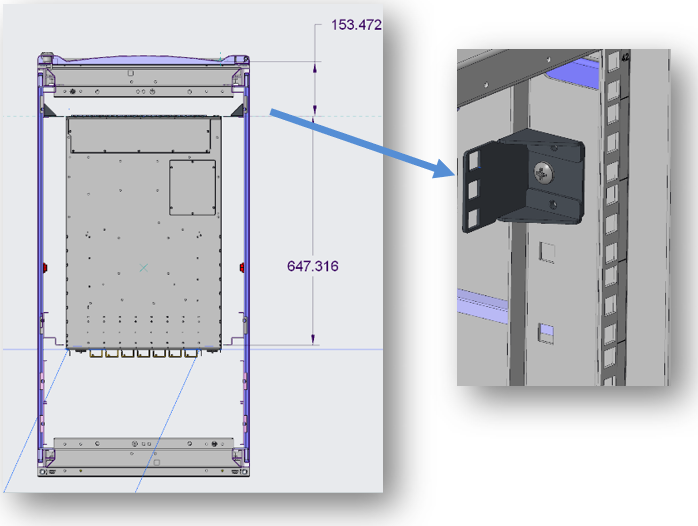
Figure 6. Switch offset brackets
Enterprise Infrastructure Planning Tool (EIPT)
The Dell Enterprise Infrastructure Planning Tool (EIPT) helps IT professionals, plan and tune their computer and infrastructure equipment for maximum efficiency. Offering a wide range of configuration flexibility and environmental inputs, this can help right size your IT environment. EIPT is a model driven tool supporting many products and configurations for infrastructure sizing purposes. EIPT models are based on hardware measurements with operating conditions representative of typical use cases. Workloads can impact the power consumption greatly. For example, the same percent CPU utilization and different workloads can lead to widely different power consumption. It is not possible to cover all the workload, environmental, and customer data center factors in a model and provide a percent accuracy figure with any degree of confidence. With that said, Dell Technologies would anticipate (NOT guarantee or claim) a potential for some variation. Customers are always advised to confirm EIPT estimates with actual measurements under their own actual workloads.
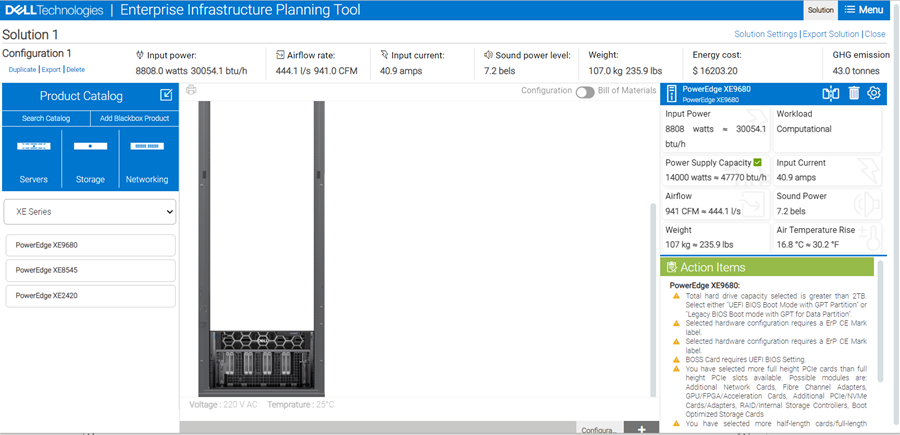
Figure 7. Dell EIPT tool
Dell Deployment Services
Leading edge technologies bring implementation challenges that can be reduced or eliminated with Dell Rack Integration Services. We have the experience and expertise to engineer, integrate, and install your Dell storage, server, or networking solution. Our proven integration methodology will take you step by step from a plan to a ready-to-use solution:
- Project management
- Solutioning and rack layout engineering
- Physical integration and validation
- Logistics and installation
Contact your account manager and go to Custom deployment services to learn more.