
Data services
Data services
-
Standard object and file methods are used to access ECS storage services. For S3, Atmos and Swift, RESTful APIs over HTTP are used for access. For Content Addressable Storage (CAS), a proprietary access method/SDK is used. ECS natively supports all the NFSv3 procedures except for LINK. ECS buckets can now be accessed by S3a.
ECS provides multi-protocol access where data ingested through one protocol can be accessed through others. This means that data can be ingested through S3 and modified through NFSv3 or Swift, or vice versa. There are some exceptions to multi-protocol access due to protocol semantics and representations of protocol design. The following table highlights the access methods and which protocols interoperate.
Table 1. ECS supported data services and protocol interoperability
Protocol
Supported
Interoperability
Object
S3
Additional capabilities like Byte Range Updates and Rich ACLS
NFS, Swift, S3a
Atmos
Version 2.0
NFS (path-based objects only and not object ID style based)
Swift
V2 APIs and Swift and Keystone v3 Authentication
NFS, S3
CAS
SDK v3.1.544 or later
N/A
File
NFS
NFSv3
S3, Swift, Atmos (path-based objects only and not object ID style based)
Data services, which are also referred to as head services, are responsible for taking client requests, extracting required information, and passing it to the storage engine for further processing. All head services are combined to a single process, dataheadsvc, running inside the infrastructure layer. This process is further encapsulated within a Docker container named object-main that runs on every node within ECS. Infrastructure covers Docker in more detail. ECS protocol service port requirements, such as port 9020 for S3 communication, are available in the latest ECS Security Configuration Guide.
Object
ECS supports S3, Atmos, Swift, and CAS APIs for object access. Except for CAS, objects or data are written, retrieved, updated, and deleted using HTTP or HTTPS calls of GET, POST, PUT, DELETE, and HEAD. For CAS, standard TCP communication and specific access methods and calls are used.
ECS provides a facility for metadata search for objects using a rich query language. This is a powerful feature of ECS that allows S3 object clients to search for objects within buckets using system and custom metadata. While search is possible using any metadata, by searching on metadata that has been specifically configured to be indexed in a bucket, ECS can return queries quicker, especially for buckets with billions of objects.
Metadata search with tokenization allows the customer to use metadata search to search for objects that have a specific metadata value within an array of metadata values. The method must be chosen when the bucket is created. It can be included as an option when creating the bucket through the S3 create bucket API, and include the header x-emc-metadata-search-tokens: true in the request.
Up to thirty user-defined metadata fields can be indexed per bucket. Metadata is specified at the time of bucket creation. Metadata search feature can be enabled on buckets with server-side encryption enabled; however, any indexed user metadata attribute used as a search key will not be encrypted.
Note: There is a performance impact when writing data in buckets configured to index metadata. The impact to operations increases as the number of indexed fields increases. Impact to performance needs careful consideration on choosing if to index metadata in a bucket, and if so, how many indexes to maintain.
For CAS objects, CAS query API provides similar ability to search for objects based on metadata that is maintained for CAS objects which does not need to be enabled explicitly.
For more information about about ECS APIs and APIs for metadata search, see the latest ECS Data Access Guide. For Atmos and S3 SDKs refer to the GitHub site Dell Data Services SDK or Dell ECS. For CAS refer to the Centera Community site. Access to numerous examples, resources, and assistance for developers can be found in the ECS Community.
Client applications such as S3 Browser and Cyberduck provide a way to quickly test or access data stored in ECS. ECS Test Drive is freely provided by Dell which allows access to a public facing ECS system for testing and development purposes. After registering for ECS Test Drive, REST endpoints are provided with user credentials for each of the object protocols. Anyone can use ECS Test drive to test their S3 API application.
Note: Only the number of metadata that can be indexed per bucket is limited to thirty in ECS. There is no limitation to the total number of custom metadata stored per object, only the number indexed for fast lookup.
Hadoop S3A support
ECS supports the Hadoop S3A client for storing Hadoop data. S3A is an open source connector for Hadoop, based on the official Amazon Web Services (AWS) SDK. It was created to address storage scaling and cost problems that many Hadoop admin were having with HDFS. Hadoop S3A connects Hadoop clusters to any S3 compatible object store whether in the public, hybrid, or on-premises cloud.
Note: S3A support is available on Hadoop 3.1.1.
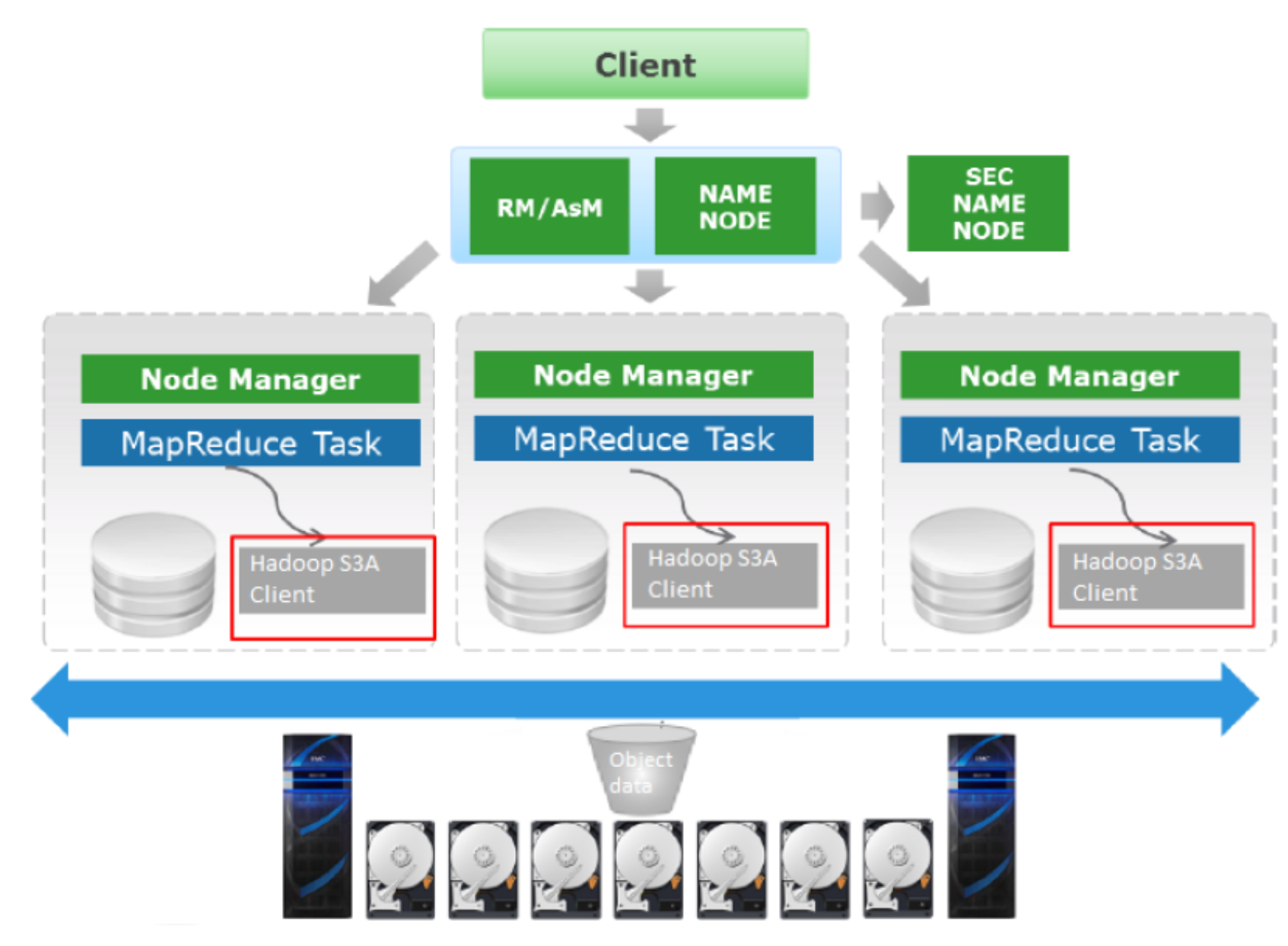
Figure 4. Hadoop and ECS architecture
As shown in the preceding figure, when the Hadoop cluster is set up on traditional HDFS, its S3A configuration points to the ECS Object data to do all the HDFS activity. On each Hadoop HDFS node, any traditional Hadoop component would use the Hadoop’s S3A client to perform the HDFS activity.
Hadoop configuration analysis using ECS Service Console
The ECS Service Console (SC) can read and interpret your Hadoop configuration parameters with respect to connections to ECS for S3A. Also, SC provides a function, Get_Hadoop_Config that reads the Hadoop cluster configuration and checks S3A settings for typos, errors, and values. Contact ECS support team for assistance with installing ECS SC.
Privacera implementation with Hadoop S3A
Privacera is a third-party vendor that has implemented a Hadoop client-side agent and integration with Ambari for S3 (AWS and ECS) granular security. Although Privacera supports Cloudera Distribution of Hadoop (CDH), Cloudera (another third-party vendor) does not support Privacera on CDH.
Note: CDH users must use ECS IAM security services. If you want secure access to S3A without using ECS IAM, contact the support team.
See the latest ECS Data Access Guide for more information about S3A support.
Hadoop S3A security
ECS IAM allows the Hadoop administrator to setup access policies to control access to S3A Hadoop data. Once the access policies are defined, there are two user access options for Hadoop administrators to configure:
- IAM Users/Groups
- Create IAM groups that attach to policies
- Create IAM users that are members of an IAM group
- SAML Assertions (Federated Users)
- Create IAM roles that attach to policies
- Configure CrossTrustRelationship between Identity Provider (AD FS) and ECS that map AD groups to IAM roles
ECS admin and Hadoop admin need to work together to pre-define appropriate policies. The fictional examples that follow outline three types of Hadoop users that we will create policies for. They are:
- Hadoop Administrator - do all operations, except create bucket and delete bucket
- Hadoop Power User - do all operations except create bucket, delete bucket and delete objects
- Hadoop Read Only User - only list and read objects
For more information about ECS IAM, see ECS IAM.
NFS
ECS includes native file support with NFSv3. The main features for the NFSv3 file data service include:
- Global namespace - File access from any node at any site.
- Global locking - In NFSv3 locking is advisory only. ECS supports compliant client implementations that allow for shared and exclusive, range-based and mandatory locks.
- Multiprotocol access - Access to data using different protocol methods.
NFS exports, permissions and user group mappings are created using the WebUI or API. NFSv3 compliant clients mount exports using namespace and bucket names. Here is a sample command to mount a bucket:
mount –t nfs –o vers=3 s3.dell.com:/namespace/bucket
To achieve client transparency during a node failure, a load balancer is recommended for this workflow.
ECS has tightly integrated the other NFS server implementations, such as lockmgr, statd, nfsd, and mountd, hence, these services are not dependent on the infrastructure layer (host operating system) to manage. NFSv3 support has the following features:
- No design limits on the number of files or directories.
- File write size can be up to 16TB.
- Ability to scale across up to 8 sites with a single global namespace/export.
- Support for Kerberos and AUTH_SYS authentication.
NFS file services process NFS requests coming from clients; however, data is stored as objects within ECS. An NFS file handle is mapped to an object id. Since the file is basically mapped to an object, NFS has features like the object data service, including:
- Quota management at the bucket level.
- Encryption at the object level.
- Write-Once-Read-Many (WORM) to the bucket level.
- WORM is implemented using Auto Commit period during new bucket creation.
- WORM is only applicable to non-compliant buckets.
Connectors and gateways
Several third-party software products can access ECS object storage. Independent software vendors (ISVs) such as Panzura, Ctera, and Syncplicity create a layer of services that offer client access to ECS object storage using traditional protocols such as SMB/CIFS, NFS, and iSCSI. Organizations can also access or upload data to ECS storage with the following Dell products:
- PowerScale [BJ2][ZJ3]CloudPools - Policy-based tiering of data to ECS from PowerScale.
- Data Domain Cloud Tier - Automated native tiering of deduplicated data to ECS from Data Domain for long-term retention. Data Domain Cloud Tier provides a secure and cost-effective solution to encrypt data in the cloud with a reduced storage footprint and network bandwidth.
- GeoDrive - ECS stub-based storage service for Microsoft® Windows® desktops and servers.