

Assets

Developing Digital Twin 3D Models on Dell PowerEdge R760xa with NVIDIA Omniverse virtualized platform

Tue, 14 May 2024 15:16:38 -0000
|Read Time: 0 minutes
Related publications
This blog is part two of the blog series Dell Technologies PowerEdge R760xa with NVIDIA Omniverse:
- Part One: Deploy Virtualized NVIDIA Omniverse Environment with Dell PowerEdge R760xa and NVIDIA L40 GPUs
- Part Three: Synthetic Data Generation with Dell PowerEdge R760xa and NVIDIA Omniverse Platform
The following related technical white paper is also available:
A Digital Twin Journey: Computer Vision AI Model Enhancement with Dell Technologies Integrated Solutions & NVIDIA Omniverse
Introduction
Digital Twins are physically accurate virtual replicas of assets, processes, or environments. Digital Twins are becoming increasingly popular with organizations looking to benefit from timely, and better decision making. Having a digitized virtual twin of real-world resources might, for example, enable businesses to identify and prevent costly mistakes or anomalies before they occur.
The Digital Twin paradigm can be applied to a lot of real-world scenarios, both big and small!
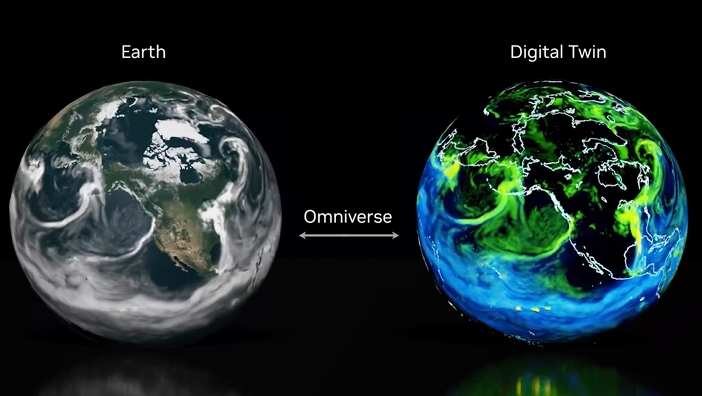 Figure 1: Real-time weather twin
Figure 1: Real-time weather twin
See Building Digital Twins of the Earth in Omniverse.
The Technical Challenge
Implementation of Digital Twin is a complex undertaking made all the more challenging by the fact there is no “one size fits all” approach.
 Figure 2: Example attributes of a real-time synchronized 3D Digital Twin
Figure 2: Example attributes of a real-time synchronized 3D Digital Twin
See 5 Steps to Get Started with Digital Twins.
This article describes how Dell Technologies PowerEdge R760xa servers, in conjunction with the NVIDIA Omniverse platform, can be used in the development of physically accurate Digital Twin 3D workflows.
Omniverse
NVIDIA Omniverse is a platform of APIs, SDKs, and services that enable developers to easily integrate Universal Scene Description (OpenUSD) and RTX rendering technologies into existing software tools and simulation workflows for building AI systems and 3D Digital Twin use cases.
The Omniverse ecosystem is designed from the ground up to enable development of new tools and workflows from scratch with customizable sample foundation application templates or SDKs that are easy to modify.
Laying the foundation for Digital Twin environments
 Figure 3: Virtualized Omniverse stack on Dell PowerEdge 760xa server
Figure 3: Virtualized Omniverse stack on Dell PowerEdge 760xa server

 Figure 4: Front and top view of the Dell PowerEdge 760xa server
Figure 4: Front and top view of the Dell PowerEdge 760xa server
For a sample configuration, refer to the Dell PowerEdge R760xa Technical Guide.
The PowerEdge R760xa server is positioned to meet the diverse needs of Digital Twin requirements such as 3D modelling, physics simulations, image rendering, computer vision, robotics, edge computing, AI training, and inferencing.
Taking the first steps into the Omniverse
Step One: Launcher is your gateway to the Omniverse
Launcher is an easy access GUI for enabling and learning about the Omniverse platform.
In Launcher, click the Exchange tab to download, install, and update Omniverse Apps and Connectors. Connectors extend the capabilities of Omniverse to integrate with a wide range of applications and services such as CAD, GIS, and VR.
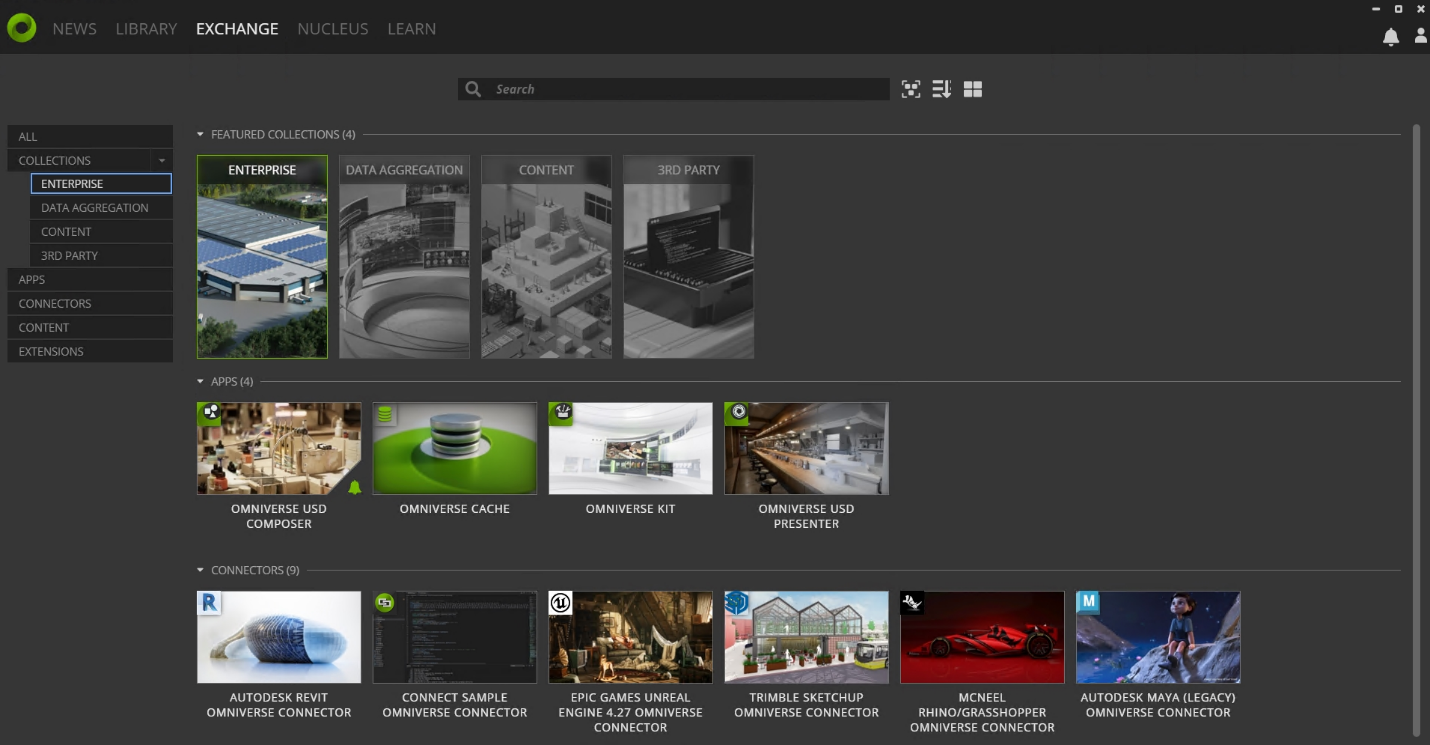 Figure 5: Launcher Exchange tab
Figure 5: Launcher Exchange tab
Step Two:
USD Composer is a foundation app template built using NVIDIA Omniverse Kit. It takes advantage of the advanced 3D workflow capabilities of OpenUSD such as layers, variants, instancing, and animation caches. USD Composer lets you develop and compose physically accurate 3D scenes.
Note: See figure 7 depicting Assembly line scene generated with USD Composer.
Building 3D Scenes
For organizations looking to make more insightful and timely decisions by simulating their real-world resources—such as production lines, warehouse/factory designs, and computer vision AI anomaly detection capabilities—the generation of highly accurate 3D models that mirror real-world physics is crucial.
SimReady Assets
It’s not enough just to have 3D models that contain virtual assets that are visually accurate. For simulations to be insightful, 3D assets must also represent their real-world counterparts as closely as possible. NVIDIA is working to create a new 3D standard specification called SimReady assets. These assets are building blocks for virtual worlds.
Simulation platforms, such as Omniverse, can leverage SimReady assets (information and metadata) to make scenario modelling far more useful for research and training of a particular product or ecosystem.
See figures 6 and 7 below depicting the development of a basic automotive assembly line scene with both visual and SimReady assets.
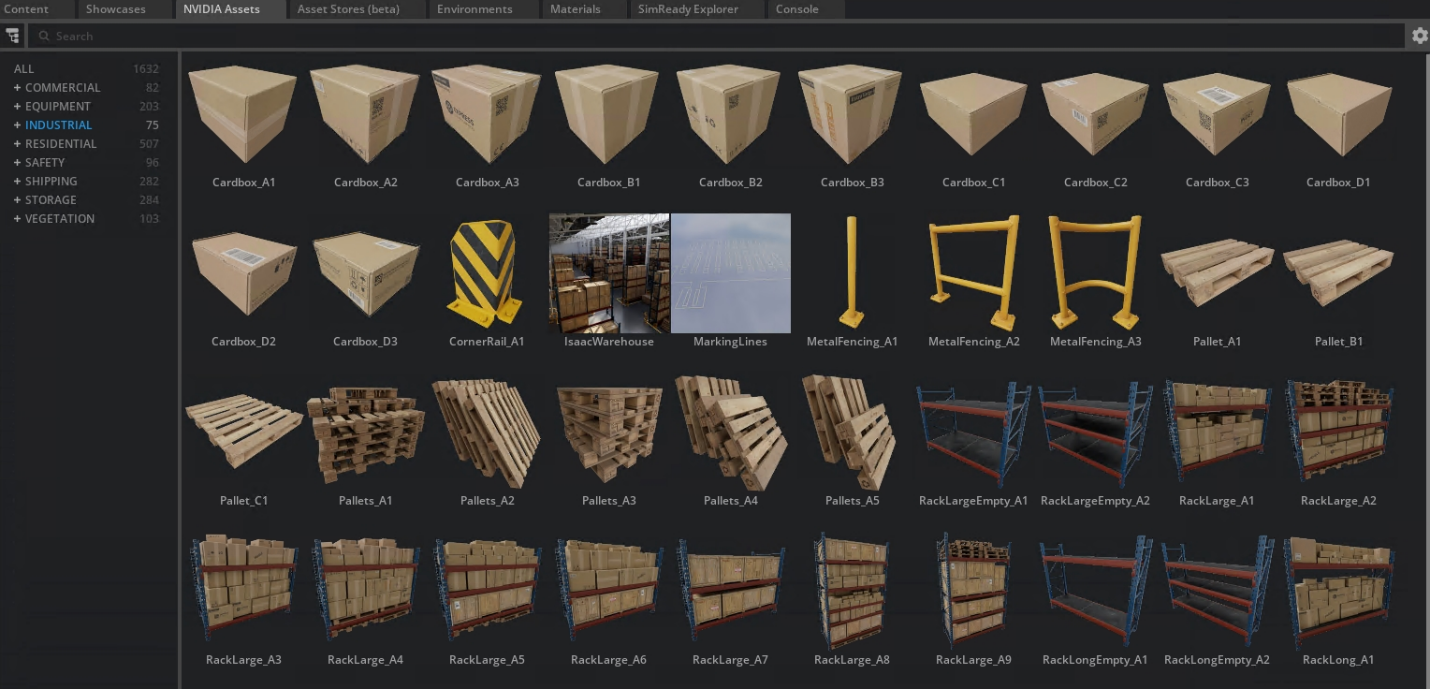 Figure 6: Example Omniverse assets catalog
Figure 6: Example Omniverse assets catalog
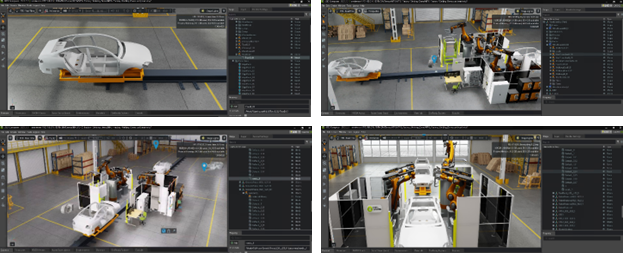 Figure 7: 3D assembly line scenes rendered from various perspectives
Figure 7: 3D assembly line scenes rendered from various perspectives
 Figure 8: Rendered close-up of an assembly line scene
Figure 8: Rendered close-up of an assembly line scene
The NVIDIA Omniverse RTX Renderer is a powerful rendering technology offering real-time and offline rendering capabilities.
RTX - Real-Time mode allows rendering more geometry than traditional rasterization methods while maintaining high fidelity. It is suitable for real-time applications.
In RTX - Interactive (Path Tracing) mode, the renderer uses a path tracing-based algorithm to achieve photorealistic results. This mode is ideal for scenarios where quality takes precedence over real-time performance with 4k or lower resolution. The balance of quality and performance depends on the given use case.
Performance and flexibility
The NVIDIA-SMI command-line utility (figure 9) shows an example of multi-GPU resource utilization (four physical L40 GPUs) on a Dell PowerEdge 760xa server and virtualized Omniverse instance.
Number of GPUs | Purpose |
2 | RTX rendering |
1 | 3D scene simulation |
1 | Training computer vision model |
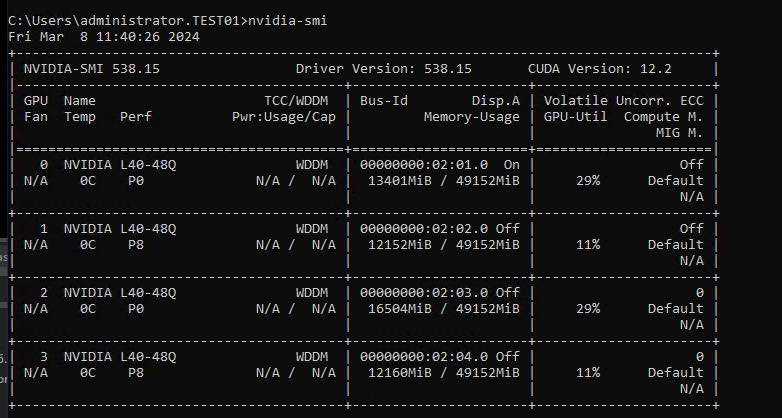 Figure 9: Utilization of four L40 GPUs on a Dell PowerEdge 760xa server
Figure 9: Utilization of four L40 GPUs on a Dell PowerEdge 760xa server
Conclusion
There is no single implementation approach for Digital Twins due to their diverse and complex nature. Requirements might evolve as development takes place, so flexibility is a key consideration when embarking on a Digital Twin venture.
Omniverse Enterprise is architected with interoperability in mind. Based on OpenUSD, the platform fundamentally transforms complex 3D workflows. You can easily connect your 3D product pipelines and unlock full design-fidelity visualization of your 3D datasets using purpose-built connector plugins for the most common 3D applications and data types.
The compatibility and collaboration capabilities of NVIDIA Omniverse and the flexibility and computational power of Dell Technologies PowerEdge Servers combine to enable a strong foundation for the development/use of Digital Twin workflows.
References
Virtual Workstation Interactive Collaboration with NVIDIA Omniverse

Synthetic Data Generation with Dell PowerEdge R760xa and NVIDIA Omniverse Platform
Tue, 14 May 2024 15:08:48 -0000
|Read Time: 0 minutes
Related publications
This blog is part three of the blog series Dell Technologies PowerEdge R760xa with NVIDIA Omniverse:
- Part One: Deploy Virtualized NVIDIA Omniverse Environment with Dell PowerEdge R760xa and NVIDIA L40 GPUs
- Part Two: Developing Digital Twin 3D Models on Dell PowerEdge R760xa with NVIDIA Omniverse virtualized platform
Synthetic Data Generation
Synthetic Data Generation (SDG) is the process of generating data for model development using analysis and tools to represent the patterns, relationships, and characteristics of real-world data.
The collection, curation, and annotation of real-world data is inherently time-consuming, expensive and may not be feasible in many circumstances. Synthetic data on the other hand might prove a suitable alternative, either in its own right or in conjunction with existing real-word data. Synthetic data has the added benefit of less risk of infringing on privacy or exposing sensitive information while providing data diversity.
Types of Synthetic data and use cases:
Synthetic text: Artificially generated text, such as text used to train language models.
Synthetic media: Artificially generated sound, image, and video, such as media used to train autonomous vehicles or computer vision models.
Synthetic tabular data: Artificially generated structured data (such as, spreadsheets and databases).
Synthetic data/datasets are increasingly being used to train AI algorithms and perform real-world modeling.
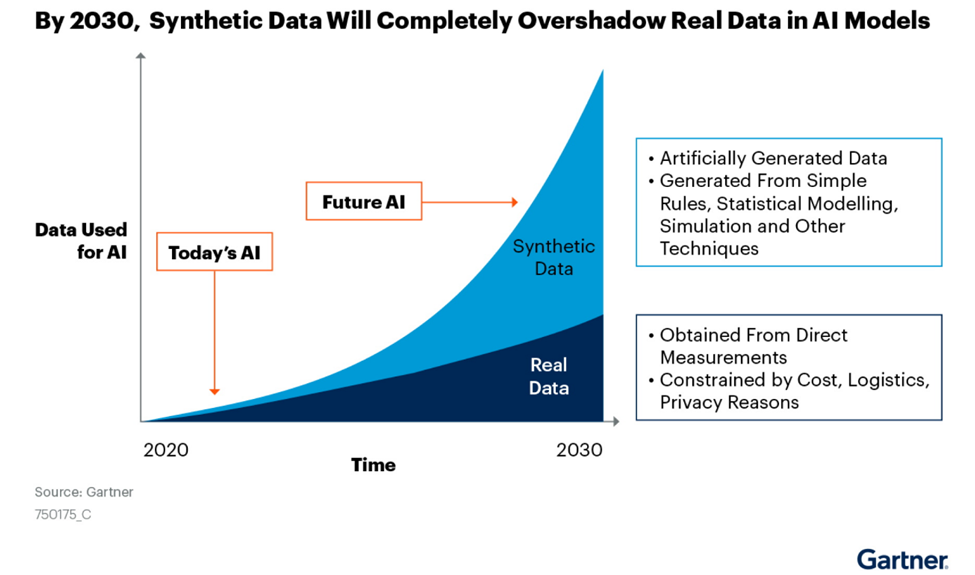 Figure 1: Gartner Synthetic Data forecast. Source www.gartner.com
Figure 1: Gartner Synthetic Data forecast. Source www.gartner.com
Gartner predicts that by 2030, most AI modeling data will be artificially generated by rules, statistical models, simulations, or other techniques.
Part one of this blog series discussed how to deploy a virtual instance of NVIDIAs Omniverse platform with Part two highlighting how 3D scenes that are built with Omniverse SimReady assets can be used in the development of physically accurate Digital Twin 3D workflows.
This article, Part 3, is the final installment in the series and describes how NVIDIA Omniverse™ Isaac Sim with SimReady Assets can produce photorealistic, physically accurate simulations and synthetic data, which can subsequently be used for AI training and integrated into Digital Twin development workflows.
Omniverse Isaac Sim and TAO Toolkit
Isaac Sim is an extensible robotics simulation toolkit for the NVIDIA Omniverse™ platform. With Isaac Sim, developers can train and optimize AI robots for a wide variety of tasks. It provides the tools and workflows needed to create physically accurate simulations and synthetic datasets.
Note: Isaac Sim exposes as a set of extensions (Omniverse Replicator) to provide synthetic data generation capabilities.
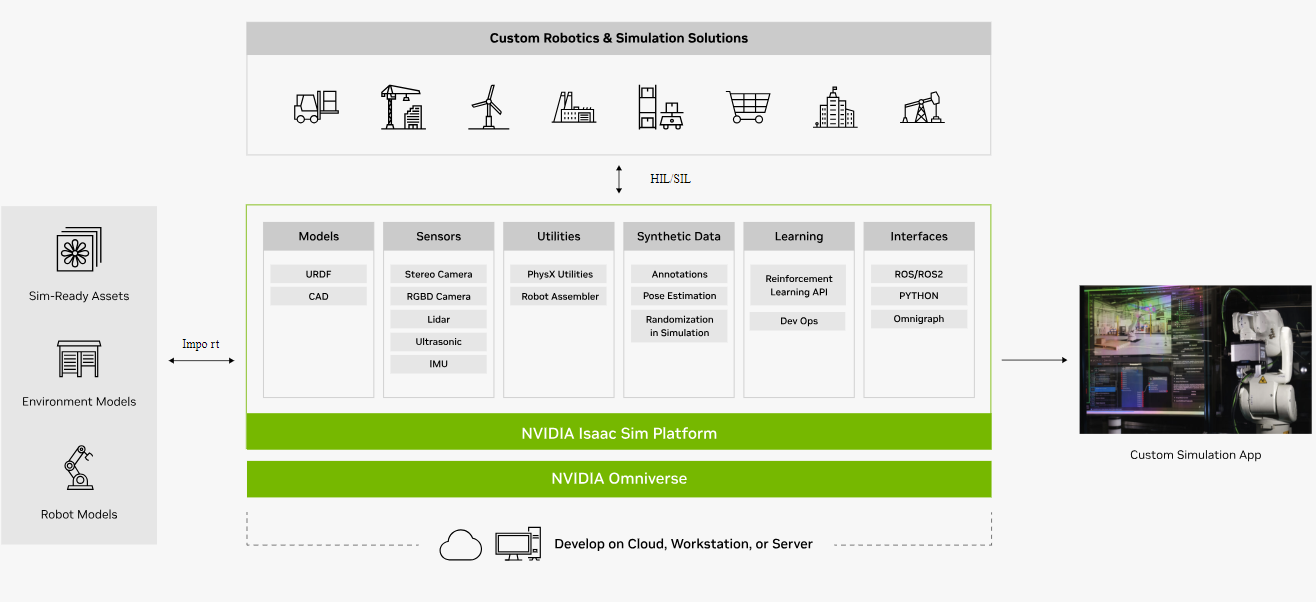 Figure 2: NVIDIA Isaac Sim Stack
Figure 2: NVIDIA Isaac Sim Stack
SimReady 3D assets and SDG are designed to be used in concert to create and randomize a variety of scenarios to meet specific training goals and do it safely as a virtual simulation. Unlike real-world datasets that must be manually annotated before use, SDG data annotated using semantic labeling can be used directly to train AI models.
NVIDIA TAO Toolkit is used for model training and inferencing. The TAO Toolkit is a powerful open-source AI toolkit that is designed to simplify the process of creating highly accurate, customized computer vision AI models. It leverages transfer learning, enabling the adaption of existing AI models for specific data. Built with TensorFlow and PyTorch, it streamlines the model training process.
TAO is part of NVIDIA AI Enterprise, an enterprise-ready AI software platform with security, stability, manageability, and support.
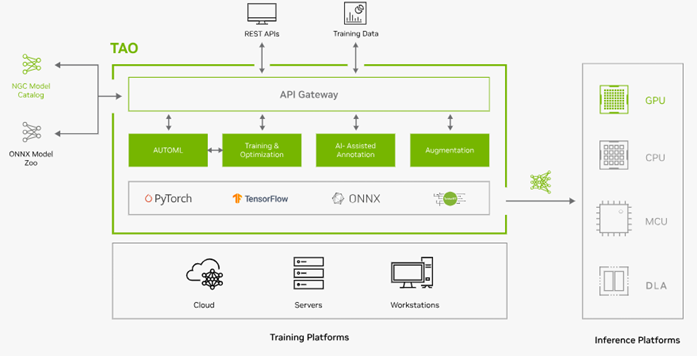 Figure 3: TAO overview
Figure 3: TAO overview
TAO supports most popular computer vision tasks such as:
- Image Classification
- Object Detection
- Semantic Segmentation
- Optical character recognition (OCR)
Synthetic Image Data Generation on Dell Technologies PowerEdge R760xa servers
This article concentrates on leveraging Dell PowerEdge R760xa servers with 4x L40 GPUs, a virtualized instance of NVIDIAs Omniverse Enterprise with Isaac Sim to synthetically generate a dataset of suitable images that can be used to train Computer Vision object detection AI models.
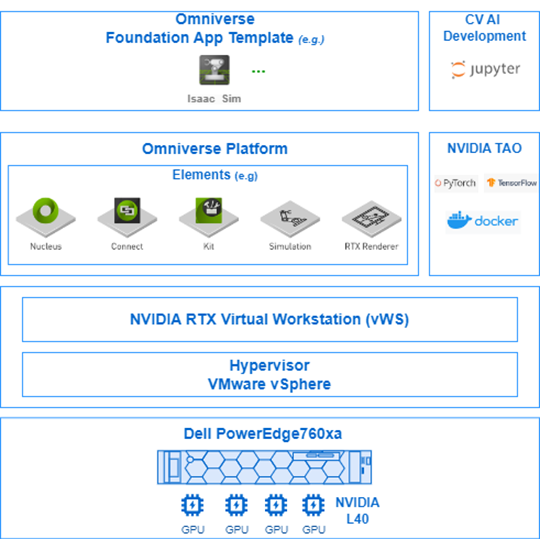 Figure 4: Virtualized Omniverse stack on Dell PowerEdge 760xa server with 4x L40 GPUs
Figure 4: Virtualized Omniverse stack on Dell PowerEdge 760xa server with 4x L40 GPUs
Enhance Computer Vision Model Capabilities with Synthetically Generated Data
The following example explores the generation of synthetic data and how it can be used to train a Computer Vision AI model to detect “Pallet Jack” objects within a warehouse setting for logistics planning.
 Figure 5: Synthetic & Real Images of “Pallet Jack” objects within a warehouse scene
Figure 5: Synthetic & Real Images of “Pallet Jack” objects within a warehouse scene
High Level Steps:
- Isaac Sim configuration
- Load warehouse scene & SimReady Assets
- Scenario Simulation
- Generate synthetic 3D image data
- Train CV object detection AI model with synthetic data
- Test AI Model Inference performance on real-world images
The following NVIDIA documentation provides a repository of collateral material (information, scripts, notebooks, and so forth) focused on:
- Isaac Sim configurations
- Synthetic Image Data Generation techniques
- Pre-Trained Computer Vision AI models
Isaac Sim Configuration
Several python scripts are included to configure and run 3D simulations with Isaac Sim. The resulting SDG output consists of ~ 5,000 high quality annotated images of “Pallet Jack” objects within a warehouse scene.
Synthetic Image Data Generation techniques
One factor to consider when generating synthetic image data is diversity. Similar or repetitive images from the synthetic domain/scene will likely not help to improve AI model accuracy. Suitable domain randomization techniques that vary image generation maybe required, such as:
- Scene distraction (multiple objects, occlusions),
- Scene composition (lighting, reflective surfaces, textures).
See Figure 6 & 7.
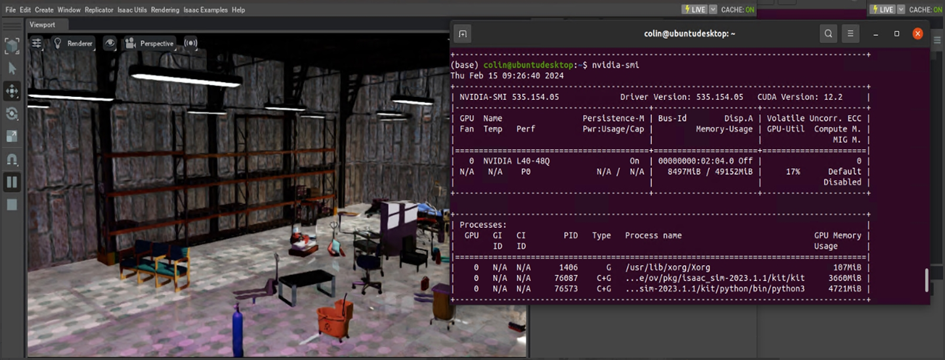 Figure 6: Isaac Sim simulation (multi object scene with occlusions) & GPU utilization snapshot
Figure 6: Isaac Sim simulation (multi object scene with occlusions) & GPU utilization snapshot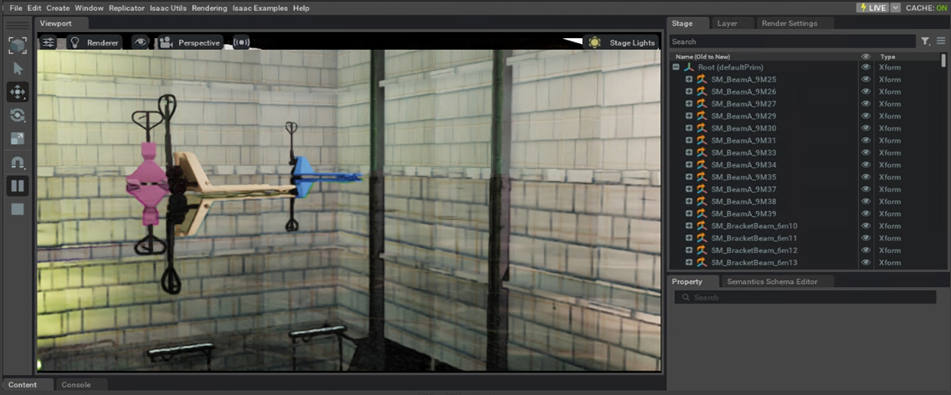 Figure 7: Isaac Sim simulation (reflective materials)
Figure 7: Isaac Sim simulation (reflective materials)
Data diversity techniques will likely vary on a use case or scene basis, for example indoor vs outdoor scenes may require different approaches before satisfactory data is generated.
Pre-Trained Computer Vision AI models
A sample Jupyter notebook from the following (Omniverse repository) uses the TAO Toolkit from NVIDIA to download a pre-trained computer vision AI (DetectNet_v2/resnet18) model, which is then trained on the previously generated synthetic images.
Figure 8 shows computer vision AI model validation on synthetic images.
 Figure 8: Object detection training validation with synthetic Data
Figure 8: Object detection training validation with synthetic Data
Finally, the synthetically trained computer vision AI object detection model is evaluated on real-world “pallet-jack” images during inferencing to assess the performance and accuracy obtained.
The example in Figure 9 shows computer vision object detection of “pallet-jacks” in real-world images
 Figure 9: Object detection Inferencing on Real-World Images
Figure 9: Object detection Inferencing on Real-World Images
Note: See Logistic Objects in Context (LOCO) dataset containing real-world images within logistics settings.
Conclusion
Synthetic data is playing an increasingly important role in enhancing the capabilities of AI models. Synthetic data used either on its own or in augmenting existing datasets may be used to address certain shortcomings and impediments of real datasets in the training of AI models such as: insufficient data, diversity, privacy, rare scenarios, and cost of curation.
NVIDIA’s Omniverse Platform in conjunction with the Isaac Sim application enables 3D scenario modeling and simulation with corresponding synthetic data image generation which can then be used to train AI and or integrated into 3D data pipelines such as Digital Twins.
In this three-part blog series Dell Technologies PowerEdge 760xa with NVIDIA Omniverse Enterprise Platform, we explored,
- Virtual deployment,
- Build/simulating high fidelity and physically accurate 3D models
- Synthetic Data Generation
- Training computer vision AI model with synthetic data
For further information see Dell Technologies Technical White Paper: A Digital Twin Journey: Computer Vision AI Model Enhancement with Dell Technologies Integrated Solutions & NVIDIA Omniverse
References
Virtual Workstation Interactive Collaboration with NVIDIA Omniverse
Applying Digital Twin and AMR Technologies for Industrial Manufacturing