




Dell ObjectScale Data Path Overview Part I
Wed, 10 Jan 2024 16:13:45 -0000
|Read Time: 0 minutes
Dell ObjectScale is the next evolution of object storage from Dell Technologies. ObjectScale is scale-out, high-performance containerized object storage built for the toughest applications and workloads, from generative AI to analytics and more. ObjectScale features a containerized architecture built on the principles of microservices to promote resiliency and flexibility. It is a branch of Dell ECS’s codebase and has been re-platformed to utilize the native orchestration capabilities of Kubernetes—scheduling, load-balancing, self-healing, resource optimization, and so on.
This blog will focus solely on the data path of ObjectScale. Please refer to the ObjectScale overview and architecture documentation to learn more about ObjectScale.
Before we introduce the data path, let’s first review chunks, metadata, and B+ tree . If you are already familiar with these concepts, please refer to the Dell ObjectScale Data Path Overview Part II, which will introduce data protection and dataflow.
Chunks
A chunk is a logical container that ObjectScale uses to store all types of data, including object data, custom client provided metadata, and system metadata. Chunks contain 128 MB of data consisting of one or more objects, as shown in the following figure.
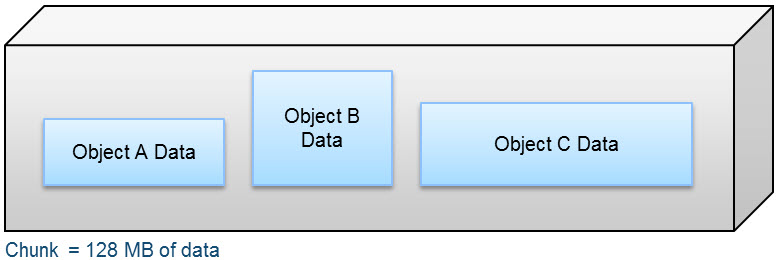
Figure 1. Composition of a chunk
An object created within ObjectScale includes writing data and metadata. Metadata encompasses journal chunks and btree chunks. Data chunks have either inline coding or triple mirror plus in-place erasure coding protection depending on the size of the object data, and the btree or journal chunks which store the metadata have triple mirror protection. For more information, please refer to the Dell ObjectScale Data Path Overview Part II.
Metadata
Metadata provides information about one or more aspects of the data, including system metadata like owner, creation date, size, and custom metadata. An example of customer metadata could be client=Dell, event=DellWorld, and ID=123.
Both system metadata and custom metadata are stored in B+ tree and journal chunks.
Data management
ObjectScale maintains the metadata that tracks data locations and transaction history in logical tables and journals.
The tables hold key-value pairs to store information relating to the objects. A hash function is used to do fast lookups of values associated with a key. These key-value pairs are stored in a B+ tree for fast indexing of data locations. In addition, to further enhance query performance of these logical tables, ObjectScale implements a two-level log-structured merge (LSM) tree. Thus, there are two tree-like structures in which a smaller tree is in memory (memory table) and the main B+ tree resides on disk. A lookup of key-value pairs first queries the memory table, and if the value is not memory, it looks in the main B+ tree on disk.
Transaction history is recorded in journal logs which are written to disks. The journals track the index transactions not yet committed to the B+ tree. After the transaction is logged into a journal, the memory table is updated. After a set period of time or when the table in memory becomes full, the table is merged, sorted, or dumped to the B+ tree on disk. A checkpoint is then recorded in the journal.
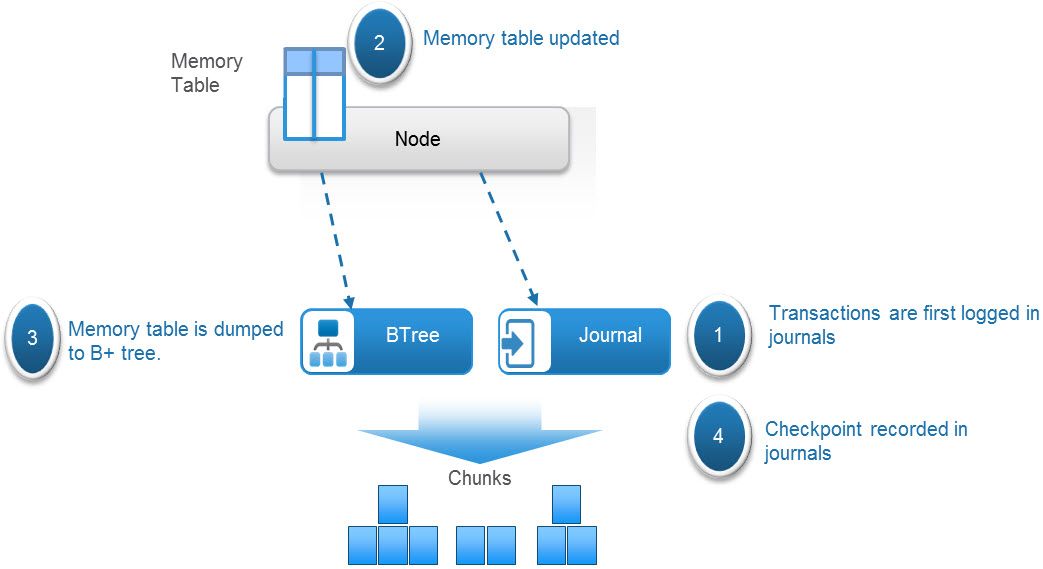
Figure 2. Metadata management process in ObjectScale
ObjectScale uses several different tables, which can get quite large. To optimize the performance of table lookups, each table is divided into partitions that are distributed across the nodes. The node where the partition is written then becomes the owner or authority of that partition or section of the table.
One such table is a chunk table, which tracks the physical location of chunk fragments and replica copies on disk. The following table shows a sample of a partition of the chunk table. Each chunk identifies its physical location by listing the disk within the node, the file within the disk, the offset within that file, and the length of the data. Chunk ID C1 is erasure coded, and chunk ID C2 is triple mirrored, as shown in table 1.
Table 1. Sample chunk table partition
Chunk ID | Chunk location |
C1 | Node1:Disk1:File1:offset1:length Node2:Disk1:File1:offset1:length Node3:Disk1:File1:offset1:length Node4:Disk1:File1:offset1:length Node5:Disk1:File1:offset1:length Node6:Disk1:File1:offset1:length Node7:Disk1:File1:offset1:length Node8:Disk1:File1:offset1:length Node1:Disk2:File1:offset1:length Node2:Disk2:File1:offset1:length Node3:Disk2:File1:offset1:length Node4:Disk2:File1:offset1:length Node5:Disk2:File1:offset1:length Node6:Disk2:File1:offset1:length Node7:Disk2:File1:offset1:length Node8:Disk2:File1:offset1:length |
C2 | Node1:Disk3:File1:offset1:length Node2:Disk3:File1:offset1:length Node3:Disk3:File1:offset1:length |
Another example is an object table, which is used for object name to chunk mapping. The following table shows an example of a partition of an object table that lists the chunk or chunks and shows where an object resides in the chunk or chunks.
Table 2. Sample object table
Object name | Chunk ID |
ImgA | C1:offset:length |
FileA | C4:offset:length C6:offset:length |
A service called Atlas, which runs on all nodes, maintains the mapping of table partition owners. The following table shows an example of a portion of an atlas mapping table.
Table 3. Sample Atlas mapping table
Table ID | Table partition owner |
Table 0 P1 | Node 1 |
Table 0 P2 | Node 2 |
We will cover ObjectScale data protection and workflow in the Dell ObjectScale Data Path Overview Part II.
Resources
The following Dell Technologies documentation provides additional information related to this blog. Access to these documents depends on an individual’s login credentials. For access to a document, contact a Dell Technologies representative.
Author: Jarvis Zhu
Related Blog Posts

Dell ObjectScale Data Path Overview Part II
Wed, 10 Jan 2024 16:14:05 -0000
|Read Time: 0 minutes
This blog is a continuation of the Dell ObjectScale Data Path Overview Part I. Here, I will cover data protection and dataflow. If you haven’t already, feel free to check out the Dell ObjectScale Data Path Overview Part I to get some basic knowledge about chunks, metadata, and the B+ tree.
Data protection methods
An object created within ObjectScale includes writing data and metadata. ObjectScale metadata includes journal chunks and btree chunks. Each is written to a different logical chunk that will contain ~128 MB of data from one or more objects. ObjectScale uses a combination of triple mirroring and erasure coding to protect the data.
- Triple mirroring ensures that three copies of data are written, protecting against two node failures.
- Erasure coding provides enhanced data protection from disk and node failures, using the Reed Solomon erasure coding scheme which breaks up chunks into data and coding fragments that are equally distributed across nodes.
- ObjectScale uses 12+4 erasure coding. That means a chunk is broken into 12 data segments and another 4 coding (parity) segments.
Depending on the size and type of data, data is written using one of the data protection methods shown in the following table.
Table 1. Data protection methods based on data type and size
Type of data | Data protection method used |
Journal chunks/ Btree chunks | Triple mirroring |
Object data <128 MB | Triple mirroring plus in-place erasure coding |
Object data >=128 MB | Inline erasure coding |
Note: In the ObjectScale appliance (XF960) with NVMe architecture, the object data will have inline erasure coding when >=44MB. In this blog, we will talk about 128MB chunk as default.
Triple mirroring
The triple-mirror write method applies to the ObjectScale journal and Btree chunks, of which ObjectScale creates three replica copies. Each replica copy is written to a single disk on different nodes. This method protects the chunk data against two-node or two-disk failures.
Triple mirroring plus in-place erasure coding
This write method is applicable to the data from any object that is less than 128 MB in size.
As an object is created, it is written as follows:
- One copy is written in fragments that are spread across different nodes and disks.
- A second replica copy of the chunk is written to a single disk on a node.
- A third replica copy of the chunk is written to a single disk on a different node.
- Other objects are written to the same chunk until it contains ~128 MB of data. The erasure coding scheme calculates coding (parity) fragments for the chunk and writes these fragments to different disks.
- The second and third replica copies are deleted from disk.
- After this sequence is complete, the chunk is protected by erasure coding.
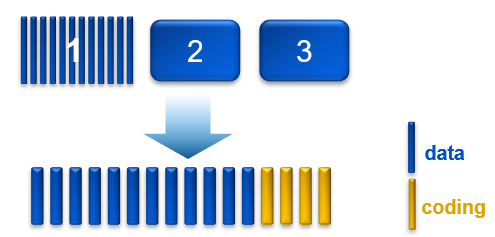
Figure 1. Process of triple mirroring plus in-place erasure coding
Inline erasure coding
This write method is applicable to the data from any object that is 128 MB or larger. Objects are broken up into 128 MB chunks. The Reed Solomon erasure coding scheme calculates coding (parity) fragments for each chunk. Each fragment is written to different disks across the nodes.
Any remaining portion of an object that is less than 128 MB is written using the triple mirroring plus in-place erasure coding scheme. As an example, if an object is 150 MB, 128 MB is written using inline erasure coding. The remaining 22 MB is written using triple mirroring plus in-place erasure coding.
Checksums
Checksums are done per write-unit, up to 2 MB. During write operations, the checksum is calculated in memory and then written to disk. On reads, data is read along with the checksum. The checksum is then calculated in memory from the data read and compared with the checksum stored in disk to determine data integrity. Additionally, the storage engine runs a consistency checker periodically in the background and does checksum verification over the entire dataset.
Data flow
ObjectScale was designed as a distributed architecture and includes a built-in load balancer (Metallb by default) that chooses the node in a cluster that will respond to a read or write request.
The following figure and steps provide a high-level overview of a write dataflow.
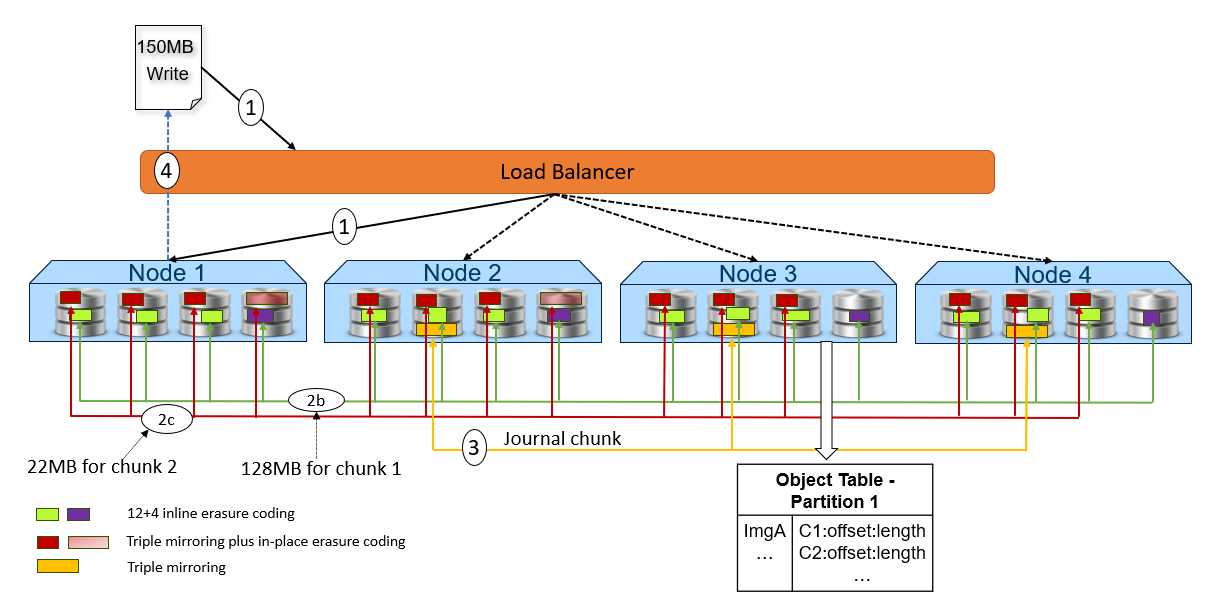
Figure 2. High-level overview of a write dataflow
- A write object request is received. In this example, Node 1 processes the request.
- Depending on the size of the object, the data is written to one or more chunks. Each chunk is protected using advanced data protection schemes such as triple mirroring plus in-place erasure coding and inline erasure coding. Before writing the data to disk, ObjectScale runs a checksum function and stores the result.
- In this example, the object size is 150MB and will be divided into 128MB as chunk 1 and 22MB as chunk 2.
- For the chunk 1 with 128MB size, it uses the inline erasure coding scheme (12+4).
- For the chunk 2 with 22MB size, it uses the triple mirroring plus in-place erasure coding scheme.
- After the object data is written successfully, the object metadata will be stored. In this example, Node 3 owns the partition of the object table in which this object belongs. As owner, Node 3 writes the object name and chunk ID to this partition of the object table’s journal logs. Journal logs are triple mirrored, so Node 3 sends replica copies to three different nodes in parallel—Node 2, Node 3, and Node 4 in this example.
- Acknowledgment is sent to the client.
- In a background process, the memory table is updated.
The following figure and steps provide a high-level overview of a read dataflow.
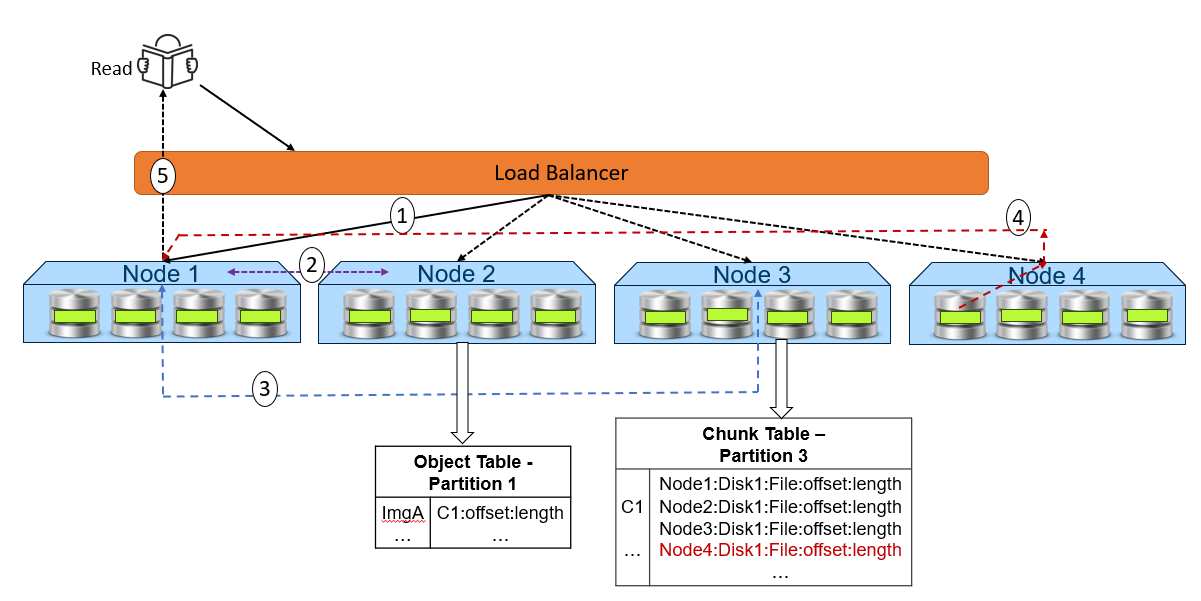
Figure 3. High-level overview of a read dataflow
- A read request is received for ImgA. In this example, Node 1 processes the request.
- Node 1 requests the chunk information from Node 2 (object table partition owner for ImgA).
- Knowing that ImgA is in C1 at a particular offset and length, Node 1 requests the chunk’s physical location from Node 3 (chunk table partition owner for C1).
- Now that Node 1 knows the physical location of ImgA, it requests that data from the node or nodes that contain the data fragment or fragments of that file. In this example, the location is Node 4 Disk 1. Then, Node 4 performs a byte offset read and returns the data to Node 1.
- Node 1 validates the checksum together with the data payload and returns the data to the requesting client.
Note: In step 4, for NVMe architecture like ObjectScale appliance, each node can directly read data from the other node. This architecture contrasts with a hard-drive architecture in which each node can only read its own data store and then transfer to the request node.
Resources
The following Dell Technologies documentation provides additional information related to this blog. Access to these documents depends on an individual’s login credentials. For access to a document, contact a Dell Technologies representative.
Author: Jarvis Zhu

Announcing the Dell ObjectScale Appliance!
Tue, 21 Nov 2023 20:14:23 -0000
|Read Time: 0 minutes
‘A major element fueling the ascent of object storage is the emergence of all-flash object storage and organizations’ growing recognition of the value “fast object” can provide them. All-flash object storage is clearly playing a key role in providing the modern infrastructure necessary to support these new initiatives.‘
This assertion is verified by a report produced by Scott Sinclair of ESG research.
Our latest ObjectScale release features the XF960, an enterprise-class, scale-out, high-performance, all-flash storage system built for the toughest applications and workloads. The XF960 hardware stack includes the server, switch, rack-mount equipment, and appropriate power cables, all optimized to run the ObjectScale software. It is built on Dell Technologies’ PowerEdge R760 server (new 16th generation).
We’re taking the ObjectScale experience to the next level by providing the latest software innovation as a fully integrated, turnkey solution.

Built with NVMe disks on Dell PowerEdge R760 servers, capacity for the ObjectScale appliance begins at 2.95PB raw capacity and scales up to 11.79PB raw capacity per rack to support the most data-intensive workloads, such as AI, machine learning, IoT, and real-time analytics applications.
ObjectScale appliance configurations include:
- 2U form factor
- Dual Intel processor with 32 cores per processor
- 256GB memory
- 30TB with 24*NVMe TLC drives
- Dual mirrored boot drives
- Network:
- 100Gb Back-end switches (Dell provided)
- 25Gb Front-end switches (customer-provided and supported)
Note: The ObjectScale appliance supports a minimum of 4 node deployment and max 16 nodes in a single rack cluster.
Two major performance enhancements with ObjectScale 1.3 and XF960 enable application development teams and data science teams to innovate even faster:
- 16G PowerEdge server performance with full-stack NVMe connectivity. The XF960 embraces the NVMe over TCP protocol for its blazing fast 100Gb backend network, accelerating node-to-node communication and unlocking the true potential of the all-flash system’s throughput rate, especially in large-scale deployments.
- We introduce shared memory in the NVMe IO path of the datahead service in the ObjectScale appliance running software version 1.3 to increase S3 throughput performance.
The ObjectScale appliance offers self-encrypting drives (SEDs), NVMe SSDs that transparently encrypt all on-disk data using an internal key and a drive access password. This encryption protects the system from data theft when a drive is removed. ObjectScale now only supports Secure Enterprise Key Manager (SKEM) in the iDRAC.
The ObjectScale appliance supports encryption for:
- Boot Drive
- Data Drive (providing better hardware deployment performance compared to software based D@RE)
- Software based D@RE (enabled at a system or bucket level)
The ObjectScale appliance supports hardware monitoring by leveraging the iDRAC from servers. It can be enabled and disabled from the UI or API directly. The alerts include a detailed description of the issue with Severity type, Reason, and Impacted resource.
The following workflow summarizes how the hardware monitoring works:
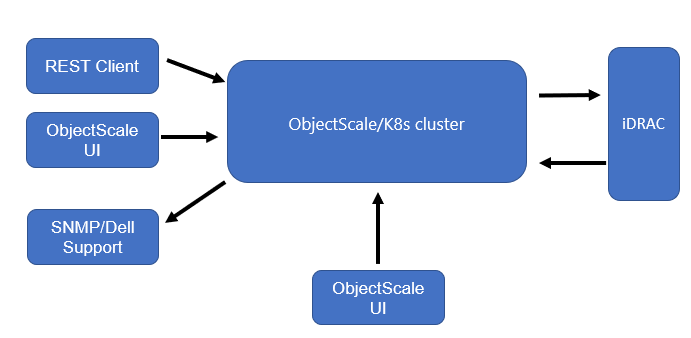
- UI or REST clients issue calls to manage hardware alerts.
- ObjectScale enables hardware alerts.
- iDRAC publishes alerts to the event listener and K8s events.
- The event is finally delivered to SNMP and Dell Support.
- ObjectScale pulls alerts every 60 seconds that display in the UI.
The ObjectScale appliance is deployed with the latest ObjectScale 1.3 software bundle package. For more information about Dell ObjectScale 1.3, see the latest Dell ObjectScale: Overview and Architecture white paper.
Conclusion
The Dell ObjectScale appliance gives organizations flexibility in deploying and managing enterprise-grade object storage. ObjectScale is a distributed system that has a layered architecture: every function is built as an independent layer, which provides horizontal scalability across all nodes and enables high availability. The ObjectScale software provides optimum protection, geo-replication, greater availability, and secure data access.
Resources
The following Dell Technologies documentation provides additional information about Dell ObjectScale. Access to these documents depends on an individual’s login credentials. For access to a document, contact a Dell Technologies representative.
- ObjectScale and ECS white papers:
- Dell Support resources:
Author: Jarvis Zhu