




The AMD MI100 GPU on the PowerEdge R7525 Will Accelerate HPC and ML Workloads
Download PDFMon, 16 Jan 2023 13:44:22 -0000
|Read Time: 0 minutes
Summary
AMD will be releasing their next-gen GPU, the MI100, in December 2020. This new technology targets to accelerate HPC and ML workloads across various industries. This DfD will discuss the performance metrics and general improvements to the MI100 GPU with the intention of educating customers on how they can best utilize the technology to accelerate their own needs and goals.
PowerEdge Support and Performance
The AMD Instinct MI100 GPU will be best powered by the PowerEdge R7525, which can currently support 3 MI100s. The R7525 with MI100 is the only platform with PCIe Gen4 capability, making it ideal for HPC workloads. Both the MI100 GPUs and Rome processors have a large number of cores, making them a great fit for related computing workloads like AI/ML/DL. Furthermore, using the PE R7525 to power MI100 GPUs will offer increased memory bandwidth from the support of up to eight memory channels. Overall, customers can expect great SP performance and leading TCO from the AMD MI100.
Multiple benchmarks were performed and observed with MI100 GPUs populated in a PowerEdge R7525 server. The first is the LAMMPS benchmark, which measures the performance and scalability of parallel molecular dynamic simulations. Figure 1 below shows very fast atom- timesteps per second across four datasets that scale mostly linearly as the number of populated MI100 GPUs increase from one to three.
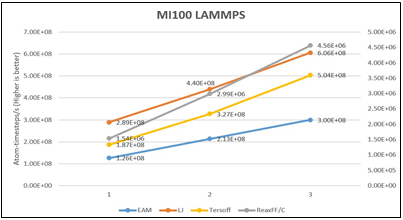
Figure 1 – LAMMPS benchmark performance for 1, 2 and 3 GPUs on four datasets
Figure 2 below highlights the results of the NAMD benchmark; a parallel molecular dynamics system designed to stress the performance and scaling aspects of the MI100 on the R7525. Because NAMD 3.0 does not scale beyond one GPU, three replica simulations were launched on the same server, one on each GPU, in parallel. The ns/day metric represents the number of MD instances that can be completed in a day (higher is better). Additionally, we observe how this data scales across all datasets.
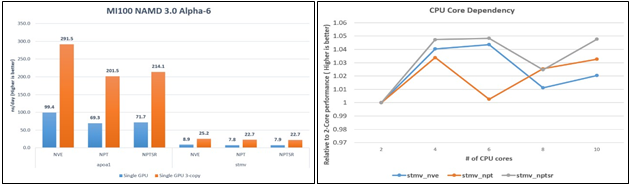
Figure 2 – NAMD benchmark performance Figure 3 – CPU core dependency on NAMD
Lastly, the NAMD CPU Core Dependency line graph in Figure 3 shows the relative performance differences (shown as a multiplier) for a range of CPU cores. We see that for the STMV dataset, the MI100 exhibited an optimum configuration of four CPU cores per GPU.
User Implementation Use Cases
HPC Workloads – Scientific computing simulations are typically so complex that FP64 double-precision models are required to translate the mathematics into accurate numeric models. The AMD Instinct™ MI100 is the first GPU to break the 11TF computing barrier (FP64) at 11.3TFLOPs. When these high speeds are coupled with the high bandwidth memory and I/O capabilities offered, the AMD MI100 GPU powered by the Dell EMC PowerEdge R7525 allows for a giant leap in computing performance; perfect for HPC workloads.
AI Workloads – Artificial Intelligence applications typically require FP32 single-precision models to determine high level features from raw input. The AMD Instinct™ MI100 boasts 3.5x the FP32 performance compared to the previous-gen MI50, and nearly a 7x boost for FP16 performance compared to the MI50. Additionally, new matrix core technology offers superior performance for a full range of mixed precision operations (including BF16, INT4, INT8, FP16, FP32 and FP32 matrices) that provides the capability to work with large models and enhance memory-bound operation performance for all AI system requirements.
Price/Performance – The MI100 GPU has positioned itself for optimal price/performance over maximum performance. Although pricing is volatile, at the time of entry to market the MI100 GPU has a leading price per performance for FP64 and FP16 models when compared to competitors. This increase in price per performance will appeal to price-sensitive customers.
MI100 Specifications
At the heart of AMDs Instinct MI100 GPU is the 1st Gen CDNA (Compute DNA) ‘Arcturus’ architecture, which focuses on computing improvements for HPC and AI server workloads. The number of compute units has effectively double over the previous generation MI50 from 60 to 120. Similarly, the number of stream processors has doubled from 3840 to 7680, allowing for significant increases of FP64 and FP32 performance. At a peak of 11.5 TFLOPS, the FP64 precision model has gained up to a 75% performance increase over the previous MI50. FP32/FP16 precision models have gained a ~70% performance increase. Furthermore, the MI100 supports 32GB of high-bandwidth memory (HBM2) that enables up to 1.2TB/s memory bandwidth. This is 1.23x higher memory bandwidth over the MI50. See Figure 4 for full details:

Figure 4 – Official MI100 specifications pulled from the AMD website
New Feature Sets
In addition to the product specification improvements noted above, the AMD MI100 introduces several key new features that will further accelerate HPC and AI workloads:
- New Matrix Core Technology
- FP32 Matrix Core for nearly 3.5x faster HPC & AI workloads vs AMD prior gen
- FP16 Matrix Core for nearly 7x faster AI workloads vs AMD prior gen
- Support for newer ML operators like bfloat16
- Enhanced RAS for consistent performance & uptime while offering remote manageability capabilities
- AMD ROCm™ Open ecosystem maximizes developer flexibility and productivity
Conclusion
The AMD MI100 GPU offers significant performance improvements over the prior-gen MI50, as well as new feature sets that were designed to accelerate HPC and ML workloads. The PowerEdge R7525 configured with MI100 GPUs will be enabled to utilize these new capabilities working in concert with other system components to yield best performance.
For additional information on the MI100, please refer to the Dell Technologies blog HPC Application Performance on Dell EMC PowerEdge R7525 Servers with the AMD MI100 Accelerator
Related Documents

Efficient Machine Learning Inference on Dell EMC PowerEdge R7525 and R7515 Servers using NVIDIA GPUs
Tue, 17 Jan 2023 00:28:16 -0000
|Read Time: 0 minutes
Summary
Dell EMC™ participated in the MLPerf™ Consortium v0.7 result submissions for machine learning. This DfD presents results for two AMD PowerEdge™ server platforms - the R7515 and R7525. The results show that Dell EMC with AMD processor-based servers when paired with various NVIDIA GPUs offer industry-leading inference performance capability and flexibility required to match the compute requirements for AI workloads.
MLPerf Inference Benchmarks
The MLPerf (https://mlperf.org) Inference is a benchmark suite for measuring how fast Machine Learning (ML) and Deep Learning (DL) systems can process inputs and produce results using a trained model. The benchmarks belong to a very diversified set of ML use cases that are popular in the industry and provide a need for competitive hardware to perform ML-specific tasks. Hence, good performance under these benchmarks signifies a hardware setup that is well optimized for real world ML inferencing use cases. The second iteration of the suite (v0.7) has evolved to represent relevant industry use cases in the datacenter and edge. Users can compare overall system performance in AI use cases of natural language processing, medical imaging, recommendation systems and speech recognition as well as different use cases in computer vision.
MLPerf Inference v0.7
The MLPerf inference benchmark measures how fast a system can perform ML inference using a trained model with new data in a variety of deployment scenarios, see below Table 1 with the list of seven mature models included in the official v0.7 release:
Model | Reference Application | Dataset |
resnet50-v1.5 | vision / classification and detection | ImageNet (224x224) |
ssd-mobilenet 300x300 | vision / classification and detection | COCO (300x300) |
ssd-resnet34 1200x1200 | vision / classification and detection | COCO (1200x1200) |
bert | language | squad-1.1 |
dlrm | recommendation | Criteo Terabyte |
3d-unet | vision/medical imaging | BraTS 2019 |
rnnt | speech recognition | OpenSLR LibriSpeech Corpus |
The above models serve in a variety of critical inference applications or use cases known as “scenarios”. Each scenario requires different metrics, demonstrating production environment performance in real practice. MLPerf Inference consists of four evaluation scenarios: single-stream, multi-stream, server, and offline. See Table 2 below:
Scenario | Sample Use Case | Metrics |
SingleStream | Cell phone augmented reality | Latency in milliseconds |
MultiStream | Multiple camera driving assistance | Number of streams |
Server | Translation site | QPS |
Offline | Photo sorting | Inputs/second |
Executing Inference Workloads on Dell EMC PowerEdge
The PowerEdge™ R7515 and R7525 coupled with NVIDIA GPus were chosen for inference performance benchmarking because they support the precisions and capabilities required for demanding nference workloads.
Dell EMC PowerEdge™ R7515
The Dell EMC PowerEdge R7515 is a 2U, AMD-powered server that supports a single 2nd generation AMD EPYC (ROME) processor with up to 64 cores in a single socket. With 8x memory channels, it also features 16x memory module slots for a potential of 2TB using 128GB memory modules in all 16 slots. Also supported are 3-Dimensional Stack DIMMs, or 3-DS DIMMs.
SATA, SAS and NVMe drives are supported on this chassis. There are some storage options to choose from depending on the workload. Chassis configurations include:
- 8 x 3.5-inch hot plug SATA/SAS drives (HDD)
- 12 x 3.5-inch hot plug SATA/SAS drives (HDD)
- 24 x 2.5-inch hot plug SATA/SAS/NVMe drives
The R7515 is a general-purpose platform capable of handling demanding workloads and applications, such as data warehouses, ecommerce, databases, and high-performance computing (HPC). Also, the server provides extraordinary storage capacity options, making it well-suited for data-intensive applications without sacrificing I/O performance. The R7515 benchmark configuration used in testing can be seen in Table 3.
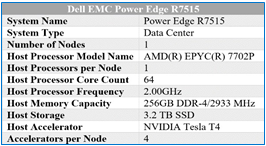
Table 3 – R7515 benchmarking configuration
Dell EMC PowerEdge™ R7525
The The Dell EMC PowerEdge R7525 is a 2-socket, 2U rack-based server that is designed to run complex workloads using highly scalable memory, I/O capacity, and network options. The system is based on the 2nd Gen AMD EPYC processor (up to 64 cores), has up to 32 DIMMs, PCI Express (PCIe) 4.0-enabled expansion slots, and supports up to three double wide 300W or six single wide 75W accelerators.
SATA, SAS and NVMe drives are supported on this chassis. There are some storage options to choose from depending on the workload. Storage configurations include:
- Front Bays
- Up to 24 x 2.5” NVMe
- Up to 16 x 2.5” SAS/SATA (SSD/HDD) and NVMe
- Up to 12 x 3.5” SAS/SATA (HDD)
- Up to 2 x 2.5” SAS/SATA/NVMe (HDD/SSD)
- Rear Bays
- Up to 2 x 2.5” SAS/SATA/NVMe (HDD/SSD)
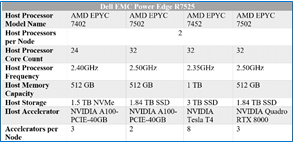
Table 4 – R7525 benchmarking configuration
The R7525 is a highly adaptable and powerful platform capable of handling a variety of demanding workloads while also providing flexibility. The R7525 benchmark configuration used in testing can be seen in Table 4.
NVIDIA Technologies Used for Efficient Inference
NVIDIA® Tesla T4
The NVIDIA Tesla T4, based on NVIDIA’s Turing™ architecture is one of the most widely used AI inference accelerators. The Tesla T4 features NVIDIA Turing Tensor cores which enables it to accelerate all types of neural networks for images, speech, translation, and recommender systems, to name a few. Tesla T4 is supported by a wide variety of precisions and accelerates all major DL & ML frameworks, including TensorFlow, PyTorch, MXNet, Chainer, and Caffe2.
For more details on NVIDIA Tesla T4, please refer to https://www.nvidia.com/en-us/data-center/tesla-t4/
NVIDIA® Quadro RTX8000
NVIDIA® Quadro® RTX™ 8000, powered by the NVIDIA Turing™ architecture and the NVIDIA RTX platform, combines unparalleled performance and memory capacity to deliver the world’s most powerful graphics card solution for professional workflows. With 48 GB of GDDR6 memory, the NVIDIA Quadro RTX 8000 is designed to work with memory intensive workloads that create complex models, build massive architectural datasets and visualize immense data science workloads.
For more details on NVIDIA® Quadro® RTX™ 8000, please refer to https://www.nvidia.com/en-us/design- visualization/quadro/rtx-8000/
NVIDIA® A100-PCIE
The NVIDIA A100 Tensor Core GPU is the flagship product of the NVIDIA data center platform for deep learning, HPC, and data analytics. The platform accelerates over 700 HPC applications and every major deep learning framework. It’s available everywhere, from desktops to servers to cloud services, delivering both dramatic performance gains and cost-saving opportunities.
For more details, please refer to https://www.nvidia.com/en-us/data-center/a100/
NVIDIA Inference Software Stack for GPUs
At its core, NVIDIA TensorRTTM is a C++ library designed to optimize deep learning inference performance on systems which contains NVIDIA GPUs, and supports models that are trained in most of the major deep learning frameworks including, but not limited to, TensorFlow, Caffe, PyTorch, MXNet. After the neural network is trained, TensorRT enables the network to be compressed, optimized and deployed as a runtime without the overhead of a framework. It supports FP32, FP16 and INT8 precisions. To optimize the model, TensorRT builds an inference engine out of the trained model by analyzing the layers of the model and eliminating layers whose output is not used, or combining operations to perform faster calculations. The result of all these optimizations is improved latency, throughput and efficiency. TensorRT is available on NVIDIA NGC.
MLPerf v0.7 Performance Results and Key Takeaways
Figures 1 and 2 below show the inference capabilities of the PowerEdge R7515 and PowerEdge R7525 configured with different NVIDIA GPUs. Each bar graph indicates the relative performance of inference operations completed meeting certain latency constraints. Therefore, the higher the bar graph is, the higher the inference capability of the platform. Details on the different scenarios used in MLPerf inference tests (server and offline) are available at the MLPerf website. Offline scenario represents use cases where inference is done as a batch job (using AI for photo sorting), while server scenario represents an interactive inference operation (translation app). The relative performance of the different servers are plotted below to show the inference capabilities and flexibility that can be achieved using these platforms:
Offline Performance
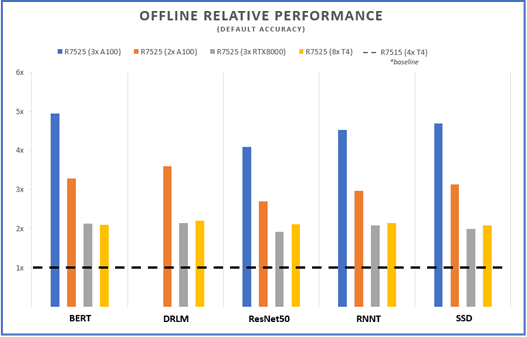
Figure 1 – Offline scenario relative performance for five different benchmarks and four different server configs, using the R7515 (4 xT4) as a baseline
Server Performance
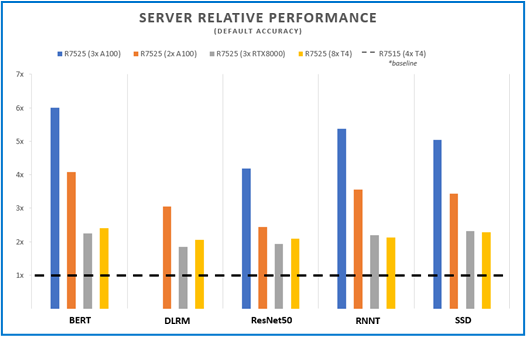
Figure 2 – Server scenario relative performance for five different benchmarks and four different server configs, using the R7515 (4 xT4) as a baseline
The R7515 and R7525 offers configuration flexibility to address inference performance and datacenter requirements around power and costs. Inference applications can be deployed on AMD single socket system without compromising accelerator support, storage and I/O capacities or on double socket systems with configurations that support higher capabilities. Both platforms support PCIe Gen4 links for latest GPU offerings like the A100 and also upcoming Radeon Instinct MI100 GPUs from AMD that are PCIe Gen 4 capable.
The Dell PowerEdge platforms offer a variety of PCIe riser options that enable support for multiple low- profile (up to 8 T4) or up to 3 full height double wide GPU accelerators (RTX or A100). Customers can choose the GPU model and number of GPUs based on the workload requirements and to fit their datacenter power and density needs. Figure 3 shows a relative compare of the GPUs used in the MLPerf study from a performance, power, price and memory point of view. The specs for the different GPUs supported on Dell platforms and server recommendations are covered in previous DfDs (link to the 2 papers)
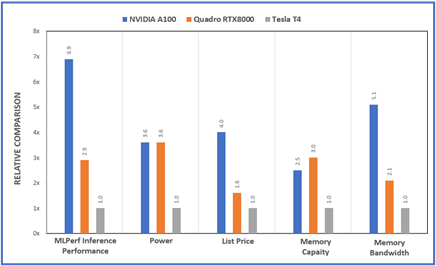
Figure 3 – Relative comparisons between the A100, RTX800 and T4 GPUs for various metrics
Conclusion
As demonstrated by MLPerf performance, Inference workloads executed on Dell EMC PowerEdge R7515 and Dell EMC PowerEdge R7525 performed well in a wide range of benchmark scenarios. . These results can server a guide to help identify the configuration that matches your inference requirements.

Using NVMe Namespaces to Increase Performance in a Dell PowerEdge R7525 Server

Mon, 16 Jan 2023 23:10:15 -0000
|Read Time: 0 minutes
Summary
This document summarizes how NVMe namespaces can be used to increase performance in Dell PowerEdge R7525 servers using KIOXIA CM6 Series NVMe enterprise SSDs.
All performance and characteristics discussed are based on performance testing conducted in KIOXIA America, Inc. application labs.
Results are accurate as of September 1, 2022
Introduction
A key goal of IT administrators is to deliver fast storage device performance to end- users in support of the many applications and workloads they require. With this objective, many data center infrastructures have either transitioned to, or are transitioning to, NVMe storage devices, given the very fast read and write capabilities they possess. Selecting the right NVMe SSD for a specific application workload or for many application workloads is not always a simple process because user requirements can vary depending on the virtual machines (VMs) and containers for which they are deployed. User needs can also dynamically change due to workload complexities and other aspects of evolving application requirements. Given these volatilities, it can be very expensive to replace NVMe SSDs to meet the varied application workload requirements.
To achieve even higher write performance from already speedy PCIe® 4.0 enterprise SSDs, using NVMe namespaces is a viable solution. Using namespaces can also deliver additional benefits such as better utilization of a drive’s unused capacity and increased performance of random write workloads. The mantra, ‘don’t let stranded, unused capacity go to waste when random performance can be maximized,’ is a focus of this performance brief.
Random write SSD performance effect on I/O blender workloads
The term ‘I/O blender’ refers to a mix of different workloads originating from a single application or multiple applications on a physical server within bare-metal systems or virtualized / containerized environments. VMs and containers are typically the originators of I/O blender workloads.
When an abundance of applications run simultaneously in VMs or containers, both sequential and random data input/output (I/O) streams are sent to SSDs. Any sequential I/O that exists at that point is typically mixed in with all of the other I/O streams and essentially becomes random read/write workloads. As multiple servers and applications process these workloads and move data at the same time, the SSD activity changes from just sequential or random read/write workloads into a large mix of random read/write I/Os - the I/O blender effect.
As almost all workloads become random mixed, an increase in random write performance can have a large impact on the I/O blender effect in virtualized and containerized environments.
The I/O blender effect can come into play at any time where multiple VMs and/or containers run on a system. Even if a server is deployed for a single application, the I/O written to the drive can still be highly mixed with respect to I/O size and randomness. Today’s workload paradigm is to use servers for multiple applications, not just for a single application. This is why most modern servers are deployed for virtualized or containerized environments. It is in these modern infrastructures where the mix of virtualized and containerized workloads creates the I/O blender effect, and is therefore applicable to almost every server that ships today. Supporting details include a description of the test criteria, the set-up and associated test procedures, a visual representation of the test results, and a test analysis.
Addressing the I/O blender effect
Under mixed workloads, some I/O processes that typically would have been sequential in isolation become random. This can increase SSD read/write activity, as well as latency (or the ability to access stored data). One method used to address the I/O blender effect involves allocating more SSD capacity for overprovisioning (OP).
Overprovisioning
Overprovisioning means that an SSD has more flash memory than its specified user capacity, also known as the OP pool. The SSD controller uses the additional capacity to perform various background functions (transparent to the host) such as flash translation layer (FTL) management, wear leveling, and garbage collection (GC). GC, in particular, reclaims unused storage space which is very important for large write operations.
The OP pool is also very important for random write operations. The more random the data patterns are, the more it allows the extra OP to provide space for the controller to place new data for proper wear leveling and reduce write amplification (while handling data deletions and clean up in the background). In a data center, SSDs are rarely used for only one workload pattern. Even if the server is dedicated to a single application, other types of data can be written to a drive, such as logs or peripheral data that may be contrary to the server’s application workload. As a result, almost all SSDs perform random workloads. The more write-intensive the workload is, the more OP is needed on the SSD to maintain maximum performance and efficiency
Namespaces
Namespaces divide an NVMe SSD into logically separate and individually addressable storage spaces where each namespace has its own I/O queue. Namespaces appear as a separate SSD to the connected host that interacts with them as it would with local or shared NVMe targets. They function similarly to a partition, but at the hardware level as a separate device. Namespaces are developed at the controller level and have the included benefit of dedicated I/O queues that may provide improved Quality of Service (QoS) at a more granular level.
With the latest firmware release of KIOXIA CM6 Series PCIe 4.0 enterprise NVMe SSDs, flash memory that is not provisioned for a namespace is added back into the OP pool, which in turn, enables higher write performance for mixed workloads. To validate this methodology, testing was performed using a CM6 Series 3.84 terabyte1 (TB), 1 Drive Write Per Day2 (DWPD) SSD, provisioned with smaller namespaces (equivalent to a CM6 Series 3.2TB 3DWPD model). As large OP pools impact performance, CM6 Series SSDs can be set to a specific performance or capacity metric desired by the end user. By using namespaces and reducing capacity, a 1DWPD CM6 Series SSD can perform comparably in write performance to a 3DWPD CM6 Series SSD, as demonstrated by the test results.
1 Definition of capacity - KIOXIA Corporation defines a kilobyte (KB) as 1,000 bytes, a megabyte (MB) as 1,000,000 bytes, a gigabyte (GB) as 1,000,000,000 bytes and a terabyte (TB) as 1,000,000,000,000 bytes. A computer operating system, however, reports storage capacity using powers of 2 for the definition of 1Gbit = 230 bits = 1,073,741,824 bits, 1GB = 230 bytes = 1,073,741,824 bytes and 1TB = 240 bytes = 1,099,511,627,776 bytes and therefore shows less storage capacity. Available storage capacity (including examples of various media files) will vary based on file size, formatting, settings, software and operating system, and/or pre-installed software applications, or media content. Actual formatted capacity may vary.
2 Drive Write(s) per Day: One full drive write per day means the drive can be written and re-written to full capacity once a day, every day, for the specified lifetime. Actual results may vary due to system configuration, usage, and other factors.
Testing Methodology
To validate the performance comparison, benchmark tests were conducted by KIOXIA in a lab environment that compared the performance of three CM6 Series SSD configurations in a PowerEdge server with namespace sizes across the classic four-corner performance tests and three random mixed-use tests. This included a CM6 Series SSD with
3.84TB capacity, 1DWPD and 3.84TB namespace size, a CM6 Series SSD with 3.84TB capacity, 1DWPD and a namespace adjustment to a smaller 3.20TB size, and a CM6 Series SSD with 3.20TB capacity, 3DWPD and 3.20TB namespace size to which to compare the smaller namespace adjustment.
The seven performance tests were run through Flexible I/O (FIO) software3 which is a tool that provides a broad spectrum of workload tests with results that deliver the actual raw performance of the drive itself. This included 100% sequential read/write throughput tests, 100% random read/write IOPS tests, and three mixed random IOPS tests (70%/30%, 50%/50% and 30%/70% read/write ratios). These ratios were selected as follows:
- 70%R / 30%W: represents a typical VM workload
- 50%R / 50%W: represents a common database workload
- 30%R / 70%W: represents a write-intensive workload (common with log servers)
In addition to these seven tests, 100% random write IOPS tests were performed on varying namespace capacity sizes to illustrate the random write performance gain that extra capacity in the OP pool provides. The additional namespace capacities tested included a CM6 Series SSD with 3.84TB capacity, 1DWPD and two namespace adjustments (2.56TB and 3.52TB).
A description of the test criteria, set-up, execution procedures, results and analysis are presented. The test results represent the probable outcomes that three different namespace sizes and associated capacity reductions have on four- corner performance and read/write mixes (70%/30%, 50%/50% and 30%/70%). There are additional 100% random write test results of four different namespace sizes when running raw FIO workloads with a CM6 Series 3.84TB, 1DWPD SSD and equipment as outlined below.
Test Criteria:
The hardware and software equipment used for the seven performance tests included:
- Dell PowerEdge R7525 Server: One (1) dual socket server with two (2) AMD EPYC 7552 processors, featuring 48 processing cores, 2.2 GHz frequency, and 256 gigabytes1 (GB) of DDR4
- Operating System: CentOS v8.4.2105 (Kernel 4.18.0-305.12.1.el8_4.x86_64)
- Application: FIO v3.19
- Test Software: Synthetic tests run through FIO v3.19 test software
- Storage Devices (Table 1):
- One (1) KIOXIA CM6 Series PCIe 4.0 enterprise NVMe SSD with 3.84 TB capacity (1DWPD)
- One (1) KIOXIA CM6 Series PCIe 4.0 enterprise NVMe SSD with 3.2 TB capacity (3DWPD)
3 Flexible I/O (FIO) is a free and open source disk I/O tool used both for benchmark and stress/hardware verification. The software displays a variety of I/O performance results, including complete I/O latencies and percentiles.
Set-up & Test Procedures
Set-up: The test system was configured using the hardware and software equipment outlined above. The server was configured with a CentOS v8.4 operating system and FIO v3.19 test software.
Tests Conducted
Test | Measurement | Block Size |
100% Sequential Read | Throughput | 128 kilobytes1 (KB) |
100% Sequential Write | Throughput | 128KB |
100% Random Read | IOPS | 4KB |
100% Random Write | IOPS | 4KB |
70%R/30%W Random | IOPS | 4KB |
50%R/50%W Random | IOPS | 4KB |
30%R/70%W Random | IOPS | 4KB |
Test Configurations
Product | Focus | SSD Type | Capacity Size | Namespace Size |
CM6 Series | Read-intensive | Sanitize Instant Erase4 (SIE) | 3.84TB | 3.84TB |
CM6 Series | Read-intensive | SIE | 3.84TB | 3.52TB |
CM6 Series | Read-intensive | SIE | 3.84TB | 3.20TB |
CM6 Series | Read-intensive | SIE | 3.84TB | 2.56TB |
CM6 Series | Mixed-use | SIE | 3.20TB | 3.20TB |
Note: The SIE drives used for testing have no performance differences versus CM6 Series Self-Encrypting Drives5 (SEDs) or those without encryption, and their selection was based on test equipment availability at the time of testing.
Utilizing FIO software, the first set of seven tests were run on a CM6 Series SSD with 3.84TB capacity, 1DWPD and
3.84TB namespace size. The results were recorded.
The second set of seven FIO tests were then run on the same CM6 Series SSD, except that the namespace size was changed to 3.2TB to represent the namespace size of the third SSD to be tested against - the 3DWPD CM6 Series SSD with 3.2TB capacity, 3DWPD and 3.2TB namespace size. The results for these tests were recorded.
The third set of seven FIO tests were then run on the CM6 Series SSD with 3.2TB capacity, 3DWPD and 3.2TB namespace size, and the performance that the CM6 Series SSD (3.84TB capacity, 1DWPD, 3.84TB namespace size) is trying to achieve. The results for these tests were recorded.
4 Sanitize Instant Erase (SIE) drives are compatible with the Sanitize device feature set, which is the standard prescribed by NVM Express, Inc. It was first introduced in the NVMe v1.3 specification and improved in the NVMe v1.4 specification, and by the T10 (SAS) and T13 (SATA) committees of the American National Standards Institute (ANSI).
5 Self-Encrypting Drives (SEDs) encrypt/decrypt data written to and retrieved from them via a password-protected alphanumeric key (continuously encrypting and decrypting data).
Additionally, a 100% random write FIO test was run on the CM6 Series SSD, except that the namespace size was changed to 2.56TB. The results for this test were recorded. A second 100% random write FIO test was run on the CM6 Series SSD with the namespace size changed to 3.52TB. The results for this test were also recorded.
The steps and commands used to change the respective namespace sizes include:
Step 1: Delete the namespace that currently resides on the SSD:
(1) sudo nvme detach-ns /dev/nvme1 –n 1 ; (2) sudo nvme delete-ns /dev/nvme1 –n 1
Step 2: Create a 3.84 TB namespace and attach it sudo nvme create-ns /dev/nvme1
-s 7501476528
-c 7501476528 -b 512
sudo nvme attach-ns /dev/nvme1 -n1 -c1 | Create a 3.52 TB namespace and attach it* sudo nvme create-ns /dev/nvme1
-s 6875000000
-c 6875000000 -b 512
sudo nvme attach-ns /dev/nvme1 -n1 -c1 | Create a 3.2 TB namespace and attach it* sudo nvme create-ns /dev/nvme1
-s 6251233968
-c 6251233968 -b 512
sudo nvme attach-ns /dev/nvme1 -n1 -c1 | Create a 2.56 TB namespace and attach it* sudo nvme create-ns /dev/nvme1
-s 5000000000
-c 5000000000 -b 512
sudo nvme attach-ns /dev/nvme1 -n1 -c1 |
*The additional namespaces were tested by repeating Steps 1 and 2, but replacing the namespace parameter value so that the sectors match the desired namespace capacity6.
Test Results
The objective of these seven FIO tests was to demonstrate that a 1DWPD CM6 Series SSD can perform comparably in write performance to a 3DWPD CM6 Series SSD by using NVMe namespaces and reducing capacity. The throughput (in megabytes per second or MB/s) and random performance (in input/output operations per second or IOPS) were recorded.
Sequential Read/Write Operations: Read and write data of a specific size that is ordered one after the other from a Logical Block Address (LBA).
Random Read/Write/Mixed Operations: Read and write data of a specific size that is ordered randomly from an LBA.
Snapshot of Results:
Performance Test | 1st Test Run: 3.84TB Capacity 3.84TB Namespace Size | 2nd Test Run: 3.84TB Capacity 3.20TB Namespace Size | 3rd Test Run: 3.20TB Capacity 3.20TB Namespace Size |
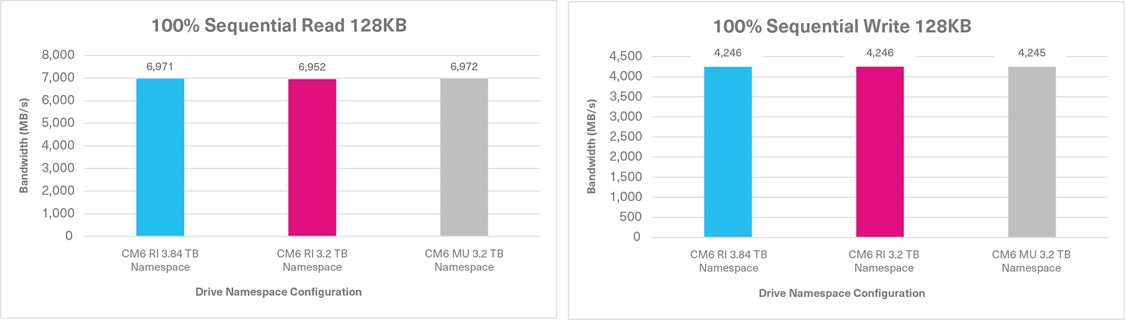
100% Sequential Read Sustained, 128KB, QD16 | 6,971 MB/s | 6,952 MB/s | 6,972 MB/s |
100% Sequential Write Sustained, 128KB, QD16 | 4,246 MB/s | 4,246 MB/s | 4,245 MB/s |
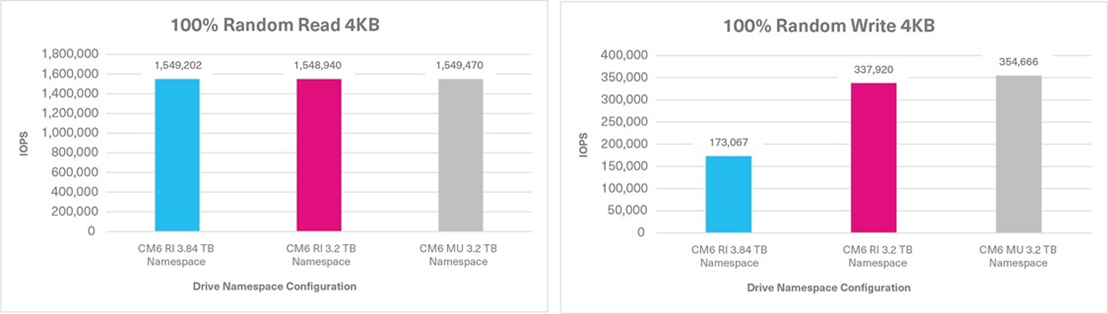
100% Random Read Sustained, 4KB, QD32 | 1,549,202 IOPS | 1,548,940 IOPS | 1,549,470 IOPS |
6 To determine the number of sectors required for any size namespace, divide the required namespace size by the logical sector size. Using 2.56 TB as an example, 2.56 TB = 2.56 x 10^12B. Because many SSDs typically have a 512B logical sector size, divide (2.56 x 10^12B) by 512B, which equals 5,000,000,000 sectors.
100% Random Write Sustained, 4KB, QD32 | 173,067 IOPS | 337,920 IOPS | 354,666 IOPS |
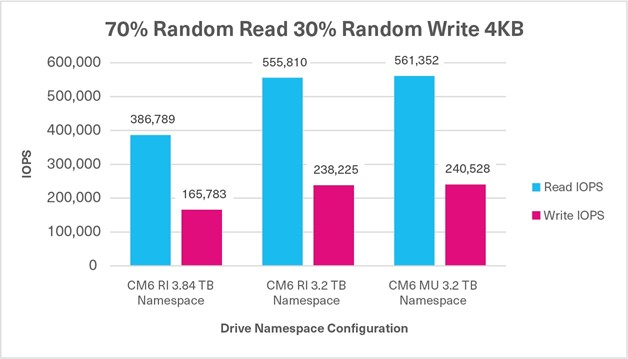
70%/30% Random Mixed Sustained, 4KB, QD32 | 386,789 IOPS (R) +165,783 IOPS (W) 552,572 IOPS | 555,810 IOPS (R) +238,225 IOPS (W) 794,035 IOPS | 561,352 IOPS (R) +240,528 IOPS (W) 801,880 IOPS |
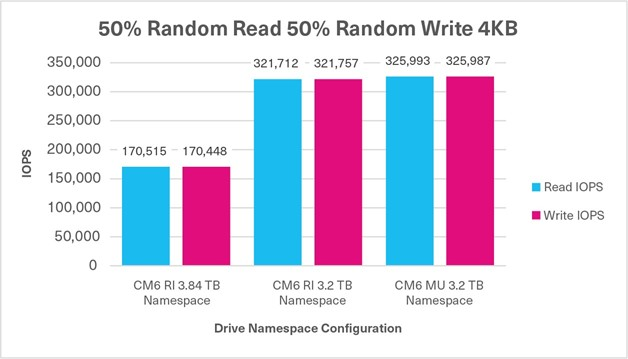
50%/50% Random Mixed Sustained, 4KB, QD32 | 170,515 IOPS (R) +170,448 IOPS (W) 340,963 IOPS | 321,712 IOPS (R) +321,757 IOPS (W) 643,469 IOPS | 325,993 IOPS (R) +325,987 IOPS (W) 651,980 IOPS |
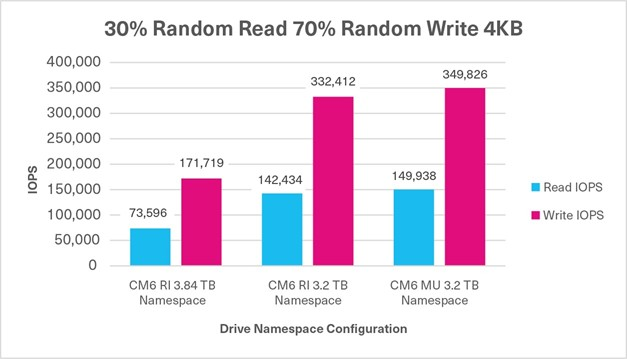
30%/70% Random Mixed Sustained, 4KB, QD32 | 73,596 IOPS (R) +171,719 IOPS (W) 245,315 IOPS | 142,434 IOPS (R) +332,412 IOPS (W) 474,846 IOPS | 149,938 IOPS (R) +349,826 IOPS (W) 499,764 IOPS |
Tests 1 & 2: 100% Sequential Read / Write
Tests 3 & 4: 100% Random Read / Write
Test 5: Mixed Random - 70% Read / 30% Write
Test 6: Mixed Random - 50% Read / 50% Write
Test 7: Mixed Random - 30% Read / 70% Write
Additional Test: 100% Random Write Using 4 Namespace Sizes
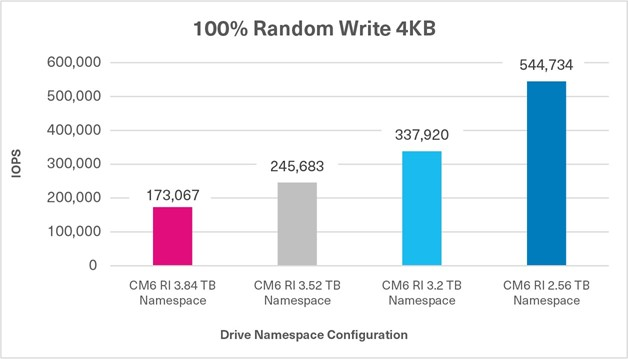
The objective of these 100% random write FIO tests was to demonstrate the increase in random write performance when using NVMe namespaces of different sizes, and reducing capacity. The random performance was recorded in IOPS.
Test Analysis
When a read or write operation is either 100% sequential or random, the performance differences between the three CM6 Series configurations were negligible based on the four FIO tests. However, when the three mixed FIO workloads were tested, the CM6 Series enabled the flash memory that was not provisioned for a namespace to be added back into the OP pool, and demonstrated higher write performance. Therefore, when provisioned with smaller namespaces, in conjunction with reducing the capacity requirements, the 3.84TB capacity, 1DWPD drive performed comparably to a 3.2TB capacity, 3DWPD drive as demonstrated by the test results. Though the 3.84TB capacity / 3.84TB CM6 Series SSD did not perform exactly to the CM6 Series 3.2TB capacity / 3.2TB namespace size SSD, the performance results were very close.
Also evident is a significant increase in the random write performance based on the allocated capacity given to a namespace, with the remaining unallocated capacity going into the OP pool courtesy of KIOXIA firmware. This enables users to have finer control over the capacity allocation for each application in conjunction with the write performance required from that presented storage namespace to the application.
ASSESSMENT: If a user requires higher write performance from their CM6 Series PCIe 4.0 enterprise NVMe SSD, using NVMe namespaces can achieve this objective.
Summary
Namespaces can be used to manage NVMe SSDs by setting the random write performance level to the desired requirement, as long as IT administration (or the user) is willing to give up some capacity. With the reality that today’s workloads are very mixed, the ability to adjust the random performance means that these mixed and I/O blender effect workloads can get maximum performance simply by giving up already unused capacity. Don’t let stranded, unused capacity go to waste when the random performance workload can be maximized!
If longer drive life is the desired objective, then using smaller namespaces to increase the OP pool is a very effective method to manage drives. Enabling these drives to be available for other applications and workloads maximizes the use of the resource as well as its life. However, the use of smaller namespaces to increase drive performance of 100% random write operations and mixed random workloads will show substantial benefit.
Additional CM6 Series SSD information is available here.
Trademarks
AMD EPYC is a trademark of Advanced Micro Devices, Inc. CentOS is a trademark of Red Hat, Inc. in the United States and other countries. Dell, Dell and PowerEdge are either registered trademarks or trademarks of Dell Inc. NVMe is a registered trademark of NVM Express, Inc. PCIe is a registered trademark of PCI-SIG. All other company names, product names and service names may be trademarks or registered trademarks of their respective companies.
Disclaimers
Information in this performance brief, including product specifications, tested content, and assessments are current and believed to be accurate as of the date that the document was published, but is subject to change without prior notice.
Technical and application information contained here is subject to the most recent applicable product specifications.