




Transactional Database Performance Boosted with Intel® Optane™ DC Persistent Memory
Download PDFSummary
An efficient transactional database running large amounts of information requires heavy-duty hardware performance that can support an optimized workload output. Dell EMC PowerEdge R740xd servers configured with Intel® Optane™ DC Persistent Memory were able to execute more transactions per minute than configurations with NAND flash NVMe drives or SATA SSDs.
The Advantage of Application Direct Mode
Intel® Optane™ DC Persistent Memory Modules (DCPMMs) have two different modes with unique advantages; Application Direct mode and Memory mode. Application Direct mode allows for OS and applications to register DCPMMs as persistent memory, while Memory mode allows for increased memory capacity over traditional DIMMs. This technical brief will focus on the advantages of using Application Direct mode.
 Figure 1: The 8Rx4 PC4-2666V DCPMM has a DRAM form factor but functions as both a memory and storage technology
Figure 1: The 8Rx4 PC4-2666V DCPMM has a DRAM form factor but functions as both a memory and storage technology
DCPMMs working in Application Direct mode can drive change in the following ways:
- Memory persistence is enabled; In-memory data will remain intact throughout power cycles
- Memory is read as storage; Operations can be directly performed on storage class memory instead of having to go through the time- consuming file system and storage system software layers
- Memory capacity increase; DCPMMs increase memory capacity over traditional DIMMS by roughly 50%, therefore increasing the overall capacity.
Testing was conducted to quantify the value of Microsoft SQL2019 by comparing the performances measured while running DCPMM, NVMe and SATA drive configurations.
The Testing Conditions
A Dell EMC PowerEdge R740xd server ran four storage configurations to compare performance readings:
- 12 Intel D3-S4510 SATA SSDs (capacity of 1.92 TB each)
- 2 Intel P4610 NVMe SSDs (capacity of 1.6 TB each)
- 4 Intel P4610 NVMe SSDs (capacity of 1.6 TB each)
- 12 Intel 8Rx4 PC4-2666V DCPMMs (capacity of 256 GB each)
NVMe SSDs did not exceed four drives because the processor had reached full utilization at four and bottlenecked performance for additional drives. VMware vSphere ESXi™ software was chosen to use the DCPMMs in App Direct mode (as this recognizes the new technology and allows its persistence capabilities). vPMEM mode was chosen to give the OS and applications access to persistence. A TPC-C like workload was derived to simulate a database application that mimics a company with warehouses, parts, orders and customers, with the benchmark reporting performance in transactions per minute.
Each storage configuration ran the number of workloads required to achieve full storage saturation while fully utilizing the CPU. Tests were run and recorded three times with each test running for a total of 45 minutes, while only the last 15 minutes of each run was recorded as the system was at a steady-state. Results were then averaged and compared as transactions per minute (TPM).
The Proof of Concept
Intel® Optane™ DCPMMs showed significant performance gains compared to other storage devices, with
11.3x the TPM of 12 SATA SSDs, 2.2x the TPM of 2 NVMe drives and 1.7x the TPM of 4 NVMe drives. See Figure 2 below for graphical test results:
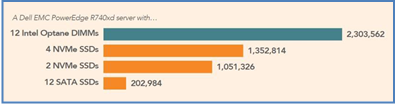
Figure 2: Median TPMs for each storage configuration
The Future Impact of App Direct Mode
The test results validate that using DCPMMs can bring newfound value to the server market that is worth investing in. With persistence and bus lane speeds boosting performance, DCPMMs were proven capable of running 1.7x greater TPMs when compared to four NVMe SSDs and 11.2x greater TPMs when compared to twelve SATA SSDs. MSFT SQL 2019 is a fitting first entry to evangelize the value of DCPMMs, and as the next data decade unfolds, so will more opportunities to push the standards of server technology.
To read the full whitepaper publications, please access the below links:
https://principledtechnologies.com/Dell/PowerEdge-R740xd-Intel-Optane-science-1019.pdf
https://principledtechnologies.com/Dell/PowerEdge-R740xd-Intel-Optane-1019.pdf
Related Documents

Powering Kafka with Kubernetes and Dell PowerEdge Servers with Intel® Processors
Mon, 29 Jan 2024 23:33:38 -0000
|Read Time: 0 minutes
Kafka with Kubernetes
At the top of this webpage are 3 PDF files outlining test results and reference configurations for Dell PowerEdge servers using both the 3rd Generation Intel® Xeon® processors and 4th Generation Intel Xeon processors. All testing was conducted in Dell Labs by Intel and Dell Engineers in October and November of 2023.
- “Dell DfD Kafka ICX” – highlights the recommended configurations for Dell PowerEdge servers using 3rd generation Intel® Xeon® processors.
- “Dell DfD Kafka SPR” – highlights the recommended configurations for Dell PowerEdge servers using 4th generation Intel® Xeon® processors.
- “Dell DfD Kafka Kubernetes Test Report” – Highlights the results of performance testing on both configurations with comparisons that demonstrate the performance differences between them.
Solution Overview
The Apache® Software Foundation developed Kafka as an Open Source solution to provide distributed event store and stream processing capabilities. Apache Kafka uses a publish-subscribe model to enable efficient data sharing across multiple applications. Applications can publish messages to a pool of message brokers, which subsequently distribute the data to multiple subscriber applications in real time.
Kafka is often deployed for mission-critical applications and streaming analytics along with other use cases. These types of workloads require leading-edge performance which places significant demand on hardware.
There are five major APIs in Kafka[i]:
- Producer API – Permits an application to publish streams of records.
- Consumer API – Permits an application to subscribe to topics and process streams of records.
- Connect API – performs the reusable producer and consumer APIs that can link the topics to the existing applications.
- Streams API – This API converts the input streams to output and produces the result.
- Admin API – Used to manage Kafka topics, brokers, and other Kafka objects.
Kafka with Dell PowerEdge and Intel processor benefits
The introduction of new server technologies allows customers to deploy solutions using the newly introduced functionality, but it can also provide an opportunity for them to review their current infrastructure and determine if the new technology might increase performance and efficiency. Dell and Intel recently conducted testing of Kafka performance in a Kubernetes environment and measured the performance of two different compression engines on the new Dell PowerEdge R760 with 4th generation Intel® Xeon® Scalable processors and compared the results to the same solution running on the previous generation R750 with 3rd generation Intel® Xeon® Scalable processors to determine if customers could benefit from a transition.
Some of the key changes incorporated into 4th generation Intel® Xeon® Scalable processors include:
- Quick Assist Technology (QAT) to accelerate data compression and encryption.
- Support for 4800 MT/s DDR5 memory
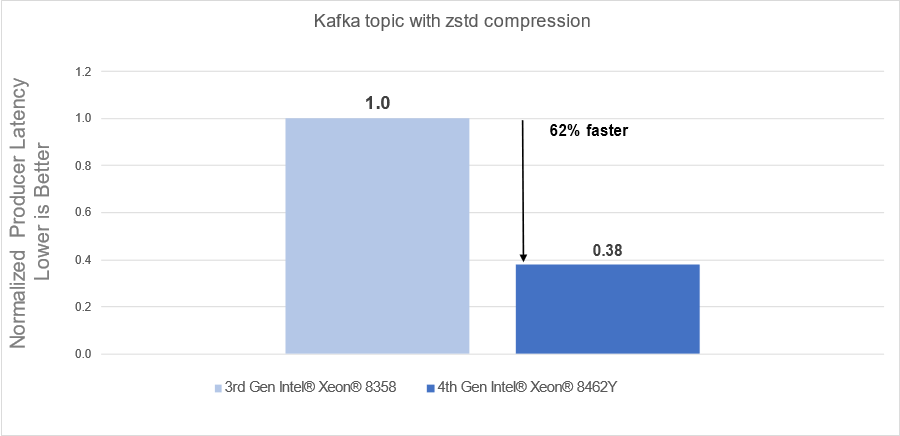
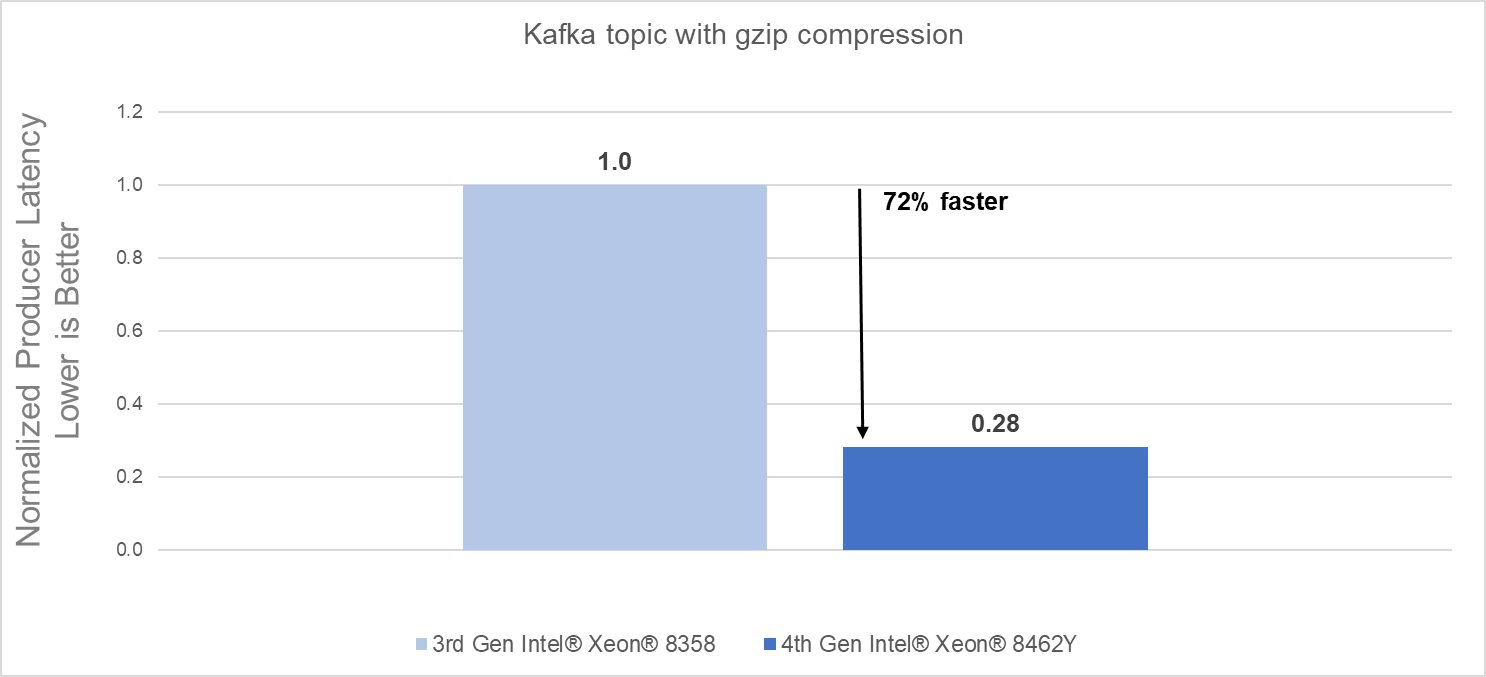
Raw performance: As noted in the report, our tests showed a 72% producers’ latency decrease with gzip compression and a 62% producers’ latency decrease with zstd compression.
Conclusion
Choosing the right combination of Server and Processor can increase performance and reduce time, allowing customers to react faster and process more data. As this testing demonstrated, the Dell PowerEdge R760 with 4th Generation Intel® Xeon® CPUs significantly outperformed the previous generation.
- The Dell PowerEdge R760 with 4th Generation Intel® Xeon® Scalable processors delivered:
- 62% faster processing using zstd compression
- 72% faster procession using gzip compression
- 4th Generation Intel® Xeon® Scalable processors benefits are the results of:
- Innovative CPU microarchitecture providing a performance boost
- Introduction of DDR5 memory support
[i] https://en.wikipedia.org/wiki/Apache_Kafka

Yellowbrick- An efficient Cloud Data Warehouse powered by Dell Technologies
Mon, 29 Jan 2024 23:20:57 -0000
|Read Time: 0 minutes
In the current economic climate, CIOs are rethinking their cloud strategy. They face challenges on several fronts - the need to continue innovating and driving growth while reducing the cost of cloud data programs and bringing tangible value. As cloud economics practices mature, private cloud and hybrid cloud are regaining strategic impetus. Organizations need the flexibility to manage data in private cloud, public cloud, co-lo, and at the edge. Yellowbrick delivers on this “Your Data Anywhere” vision.
Alongside new data management approaches such as data lakes, SQL based Data Warehouse technologies continue to prove their value as the primary business interface, with data lake vendors rushing to emulate their capabilities.
With Dell Technologies’ this solution is designed and optimized to provide an elastic data management platform for SQL analytics at any scale.
Business Challenges and Benefits
Yellowbrick data warehouse meets these challenges with a unique architecture designed to maximize efficiency with hardened security and simplified management. Yellowbrick delivers everything you would expect from a modern high-performance SQL cloud data warehouse.
It comes with cloud SaaS simplicity and elasticity with performance perfected through years of delivering value to customers in weeks and months and bills natively to exploit the power agility of the cloud.
Yellowbrick uniquely combines its MPP database software, and highly engineered systems design, with an agile elastic modern Kubernetes-based architecture that delivers high efficiency and maximizes performance in every deployment scenario.
Yellowbrick is engineered for maximum efficiency and price performance, supporting thousands of concurrent users on 1/5 of the cloud resources compare with competitors, maximizing data value with the simplicity and familiarity of SQL but with a unique pricing model that alleviates concerns over unpredictable cost overruns.
Who is Yellowbrick?
The Yellowbrick Data Warehouse is an elastic massively parallel processing (MPP) SQL database that runs on-premises, in the cloud, and at the network edge, it was designed for the most demanding batch real time and ad hoc and mixed workloads and can run complex queries at up to petabyte scale with guaranteed sub second response times. Yellowbrick is proven, providing business critical services at many large global enterprises with thousands of concurrent users. It is available on AWS, Azure, and Google Cloud as well as on-premises.
| SQL Analytics for The Masses Cost-effectively supporting thousands of concurrent users running hundreds of concurrent ad-hoc queries, Yellowbrick leapfrogs competitors while still providing full elasticity with separate storage and compute. |
| Meet Mission-Critical Service Levels Intelligent workload management dynamically optimizes resources to ensure SLAs are consistently met without the need to scale out and spend more. |
| Ultimate Control of Data Security Yellowbrick’s data warehouse runs in your own cloud VPC or on-premises behind your firewall, allowing you to meet data sovereignty and governance requirements and pay for your own infrastructure. |
| Engineered for Extreme Efficiency and Performance Get answers faster with our Direct Data Path architecture. Yellowbrick runs mixed ad-hoc ETL, OLAP, and real-time streaming workloads delivering the maximum benefit from any underlying infrastructure platform. |
| Easy to Do Business With Optimize your costs with flexible on-demand or fixed subscription – Yellowbrick is invested in your success, not in emptying your wallet. Our NPS of 82 is a testament to our customer partnership model and support excellence. |





Figure 1 The Yellowbrick Advantage
Yellowbrick Overview
Designed to run complex mixed workloads and support ad-hoc SQL while computing correct answers on any schema, Yellowbrick offers massive scalability and supports vast numbers of concurrent users. This means our clients gain deeper, more meaningful insights into their customers more quickly than ever before possible, setting us apart from other cloud data warehouses (CDWs).
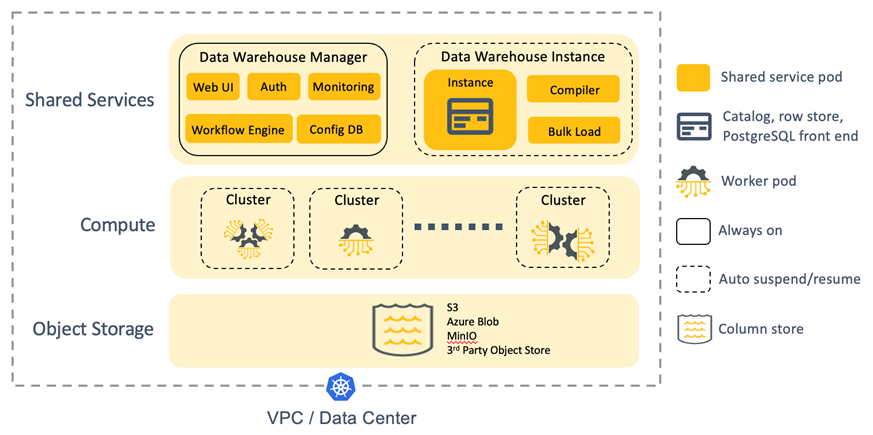
Figure 2 Yellowbrick Architecture
In an industry-first, full SQL-driven elasticity with separate storage and compute is available within your own cloud account as well as on-premises. Compute resources – elastic, virtual compute clusters (VCCs) – are created, resized, and dropped on-demand through SQL, and cache data persisted on shared cloud object storage. For example, ad-hoc users can be routed to one cluster, business-critical users to a second cluster, and more clusters created and dropped on demand for ETL processing.
Each data warehouse instance runs independently of one another. There is no single point of failure or metadata shared across instances. Global outages – when deployed with replication across multiple public clouds and/or on-premises – are impossible.
Yellowbrick is secure by default with no external network access to your database instance. Encryption of data at rest is standard with keys you manage. Columnar encryption, granular role-based access control, column masking, OAuth2, Active Directory, and Kerberos authentication are built in. Integrations with best-in-class enterprise data protection solutions secure PII data. Enterprise-class high availability, backups for data retention, and asynchronous replication for disaster recovery are standard. Management capabilities, Vantage offers significant value for your investment.
Yellowbrick powered by Dell Technologies
Yellowbrick and Dell share solutions that address a variety of data analytic use cases:
- Mission-critical Reporting and BI
- Data Warehouse modernization and consolidation
- Data-intensive B2B Apps and Data Monetization
- Hybrid Cloud Big Data Analytics
- Unified features store for data science and AI
- Multi-PB scale relational data lake
Symphony Retail AI
Symphony RetailAI serves the ever-changing consumer goods industry. That means they need to transfer terabytes of raw data to their 700 TB data warehouse and quickly convert it into easily digestible information for their consumers. Development and test, departmental data marts, self-service analytic workspaces for data scientists and developers, and edge/IoT computing.
TEOCO powered by Dell Technologies
TEOCO (The Employee-Owned Company) is a leading provider of telecom industry analytics and optimization solutions. The company provides intelligence about revenue assurance, network quality, and customer experience to more than 300 providers and customers. In addition to managing mountains of data for their clients, TEOCO also develops algorithms to transform raw data into actionable insights.
With these game-changing responsibilities in mind, TEOCO constantly strives to improve data warehouse innovation.
Some of the use cases <insert use case introduction>
Catalina Marketing powered by Dell Technologies
Catalina Marketing is the industry leader in consumer intelligence as well as in targeted instore and digital media. The company delivers an annual $6.1 billion in consumer value by pairing its exceptional analytics and insights with the richest buyer-history database in the world. To fulfill its mission, Catalina processes terabytes of data, transforming it into meaningful results so companies can optimize media planning to increase consumer engagement.
Catalina’s complex extract, transform, and load (ETL) processes required nightly conversions to produce data sets for querying and reporting. Plus, Catalina’s team of about 100 data scientists used advanced analytics and data-mining tools to perform large, ad hoc queries for a variety of customers.
Luis Velez, data engineering manager at Catalina explained that before Yellowbrick “It was an unsustainable environment in which we were not able to finish our data loads because we had 15 to 20 queries running at any given time.” “Every day, it was getting a little bit worse.” “Sometimes queries took hours, and other times they were simply killed so ETL processes could run,” says Aaron Augustine, executive director of data science at Catalina.
To achieve optimal results, Catalina incorporated Yellowbrick into its system, dividing the computing workload in half between the two platforms. Netezza would handle data processing, while Yellowbrick supported the consumption of processed data. During a three-week Proof of Technology (POT) exercise, Catalina found Yellowbrick’s single 10U, 30-node system performed 182X better than their current system. Catalina switched immediately.
The Enterprise Data Warehouse is powered by the Dell PowerEdge R660 server, together with Dell PowerSwitch networking and ECS storage featuring capacity, performance, and operational simplicity.
Dell Infrastructure Components
The following Dell components provide the foundation for the Yellowbrick private cloud solution.

Figure 3 Dell Yellowbrick Solution
Dell PowerEdge R660 Server is the ideal dual-socket 1U rack server based on Intel’s fourth-generation Xeon Scalable “Sapphire Rapids” processors for dense scale-out data center computing applications. Benefiting from the flexibility of 2.5” or 3.5” drives, the performance of NVMe, and embedded intelligence, it ensures optimized application performance in a secure platform.
The server is designed with a cyber-resilient architecture, integrating security deep into every phase in the life cycle. It has intelligent automation with integrated change management capabilities for update planning and seamless and zero-touch configuration. And it has built-in telemetry streaming, thermal management, and RESTful APIs with Redfish that offer streamlined visibility and control for better server management.
Dell ECS Storage is an enterprise-grade, cloud-scale, object storage platform that provides comprehensive protocol support for unstructured object and file workloads on a single modern storage platform. Either the ECS EX500 or EX5000 may be used depending on capacity requirements.
Dell PowerSwitch Networking switches are based on open standards to free the data center from outdated, proprietary approaches: They support future ready networking technology that helps you improve network performance, lower network management costs and complexity, and adopt new innovations in networking.
Why Dell Technologies
The technology required for data management and enterprise analytics is evolving quickly, and companies may not have experts on staff or who have the time to design, deploy, and manage solution stacks at the pace required. Dell Technologies has been a leader in the Big Data and advanced analytics space for more than a decade, with proven products, solutions, and expertise. Dell Technologies has teams of application and infrastructure experts dedicated to staying on the cutting edge, testing new technologies, and tuning solutions for your applications to help you keep pace with this constantly evolving landscape.
Dell Technologies is building a broad ecosystem of partners in the data space to bring the necessary experts, resources, and capabilities to our customers and accelerate their data strategy. We believe customers should be able to innovate using data irrespective of where it resides across on-premises, public cloud and edge. By partnering with Teradata, an industry leader in enterprise data management and analytics, we are creating optimized solutions for our customers.
Dell Technologies uniquely provides an extensive portfolio of technologies to deliver the advanced infrastructure that underpins successful data implementations. With years of experience and an ecosystem of curated technology and service partners, Dell Technologies provides innovative solutions, servers, networking, storage, workstations, and services that reduce complexity and enable you to capitalize on a universe of data.
Conclusion
Whether you want to expand your existing capabilities or get started with your first project, Yellowbrick powered by Dell Technologies offers XYZ. For more information about the solutions, please contact the Dell Technologies Teradata Solutions team by email.
Your company needs all tools and technologies working in concert to achieve success. Fast, effective systems that complement time management practices are crucial to making the most out of every employee hour. High-level data collection and processing that provides rich, detailed analytics can ensure your marketing campaigns strategically target your ideal customers and encourage conversion. To top it off, you need affordable products that meet your criteria and then some. After switching to Yellowbrick, our customers have seen dramatic gains in efficiency:
- Streamlined processes.
- Faster query times.
- Minimized data turnaround time.
- Richer, more accurate data.
- Increased customer growth.
- Affordable pricing with fixed-rate subscriptions for any deployment.
- No hidden fees or quotas.
- Predictable and reliable performance.
- Compatible with other components and applications.
- Highly capable system portability and accessibility.
- Innovative solutions.
- Little to no performance tuning.
- Ability to support a multitude of concurrent users.
Enjoy quick, easy, and supportive migration
At Yellowbrick, we are ready to provide you with simple, swift migration services. We complete most migrations in weeks, not months. Our 15-day proof of concept performance and operational testing period allows you to confirm that Yellowbrick is the right fit for your company. During this time, we will work closely with you to understand the requirements and scope a POC in your data center or in the cloud—whichever you prefer. We will set up a test instance, migrate your data, and integrate all necessary applications.
Since Yellowbrick is based on PostgreSQL, the world’s most advanced open-source database, and natively supports stored procedures, it works out of the box quickly. Our data solutions are also compatible with common industry tools, such as Tableau, MicroStrategy, SAS, and Microsoft Power BI, as well as Python and R programming languages. Coupled with one day of setup and one week of testing, your team can hit the ground running almost immediately.
Additionally, our broad partner network can help plan your transition, understand your data flows, and manage cutover with purpose-built tools and consulting services, so you can migrate from any platform.
Additional Resources
For more information, please see the following resources: