




XR8000 – Unique Sled Design
Download PDFFri, 03 Mar 2023 19:57:26 -0000
|Read Time: 0 minutes
Summary
The Dell PowerEdge XR8000 is a compact multi-node server designed for the edge and telecom. This DfD describes the unique form factor with chassis and sleds for the deployment of the XR8000.
Overview
The Dell PowerEdge XR8000 is a rugged multi-node edge server with Intel 4th Gen Intel® Xeon® Scalable processors MCC SKU stack. This short-depth sled-based server, purpose-built for telco at the edge, is configurable, environmentally agile, and RAN optimized. It is optimized to operate in Class 1 (-5C to 55C) environments and –20C to 65C for select configurations, provides a short depth of 430 mm from the front I/O wall to the rear wall, and is front-accessible.
Available in a unique sled-based chassis form factor, the 2U chassis supports 1U and 2U half-width sleds. It is an open and reusable chassis as opposed to fixed monolithic chassis. The entire sled can be replaced without removing the chassis and power, which simplifies serviceability and maintenance. Customers who need additional storage or PCIe expansion can choose the 2U sled, with options for compute, accelerators, or GPUs.
Each sled includes iDRAC for management, a CPU, memory, storage, networking, PCIe expansion (2U sled), and cooling.
The reversible airflow chassis
XR8000 offers a reverse airflow design for use in front accessed chassis configurations. It provides a front-accessible, multi-node sled-based rackable chassis (430mm depth). It offers dual 60 mm PSUs for reverse airflow, with the following options:
- -48VDC options: 800W, 1100W, 1400W
- 100 to 240VAC options: 1400W, 1800W

Assuming redundant PSUs for each server, there would be between four and eight PSUs for equivalent compute capacity, and between four and eight additional power cables. This consolidation of PSUs and cables not only reduces the cost of the installation (due to fewer PSUs), it also reduces the cabling, clutter, and Power Distribution Unit (PDU) ports used in the installation.
The sleds
The compute sleds offer common features such as:
- Power and management connector(s) to the chassis manager
- Pull handle(s) and a mechanical lock for attachment to the chassis (for example, spring clips)
- Side rails to aid insertion and stability in the chassis
- Ventilation holes and baffles as appropriate for cooling
- Intrusion detection for sled insertion/removal linked to iDRAC
The XR8000 provides two sled options:
- 1U sled: The 1U Compute Sled adds support for one x16 FHHL (Full Height Half Length) Slot (PCIe Gen5).

Figure 1. XR8610t
- 2U Sled: The 2U Compute Sled builds upon the foundation of the 1U Sled and adds support for an additional two x16 FHHL slots (Gen 5)

Figure 2. XR8620t
These slots can support GPUs*, SFP, DPUs, SoC Accelerators, and other NIC Options.
*More details will be available at RTS, planned for May 2023.
The chassis with sleds
Various configurations are available:
1. 1X4U - This option includes 4x1U compute sleds and PSUs:

2. 2x1U + 1x2U - This option includes 2x1U and 1x2U compute sleds and PSUs:

3. 2x2U - This option includes 2x2U compute sleds and PSUs:

The PowerEdge XR8000 offers various form factor options based on different workloads:
- General purpose far edge 2U half-width: 3 x16 FHHL (Gen 5)
- Dense Compute Optimized 1U half-width: 1 x16 FHHL (Gen 5)
You can create any of these compute node configurations to support a broad range of workloads in one chassis.
Ease of deployment
The XR8000 offers a front servicing (cold aisle) chassis, which allows it to be deployed with all cables connected to the front. This simplifies cable management and allows the server to be installed in areas where space is limited and access to the front and back of the chassis is not possible. Also, the sleds are designed to be easily field replaceable by non-IT personnel. Whether it is located at the top of the roof or in any other difficult environment, XR8000 has a dense form factor with a Class 1 temperature range (-5 to +55°C) with some configurations reaching –20C to 65C and is tested for NEBS Level 3 compliance.
Improved IT maintainance
The XR8000 multi-node server enables IT administrators to deploy compact, redundant server solutions. For example, two sleds can be configured identically and installed in the same chassis. One acts as the primary, and the other is the secondary, or backup. If the primary server goes down, the secondary server steps in to minimize or eliminate downtime. This redundant server configuration is also a great way for administrators to manage software updates seamlessly. For example, administrators can deploy the secondary server while performing maintenance, updates, or development work on the primary server.
Scalability and flexibility
XR8000 with its unique form factor and multiple deployment options provides flexibility to start with a single node and scales up to four independent nodes as needed. Depending on the needs of various workloads, deployment options can change.
The same sleds can work in either the flexible or rack mount chassis based on space constraints or user requirements.
Conclusion
XR8000 provides a streamlined approach for various edge and telecom deployment options based on different use cases. It provides a solution to the challenge of deploying small form factors at the edge, with industry-standard rugged tests (NEBS), providing a compact solution for scalability and flexibility in a temperature range of -20 to +65°C for select configurations.
Related Documents

Are Rugged Compact Platforms Ready for Edge AI?
Thu, 14 Mar 2024 16:47:06 -0000
|Read Time: 0 minutes
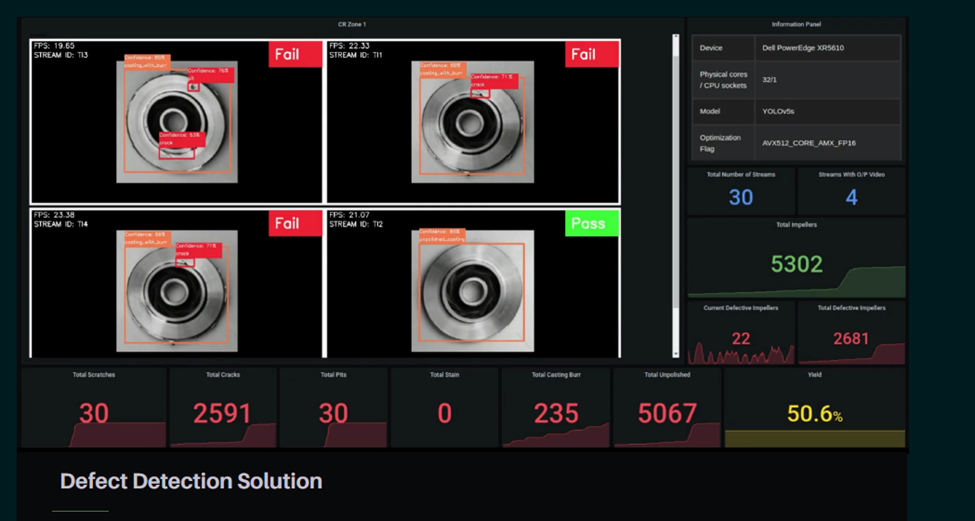
Scalers AI™ tested the Impellers Defect Inspection at the Edge on the Dell PowerEdge XR5610 server. Impellers are rotating components used in various industrial processes, including fluid handling in pumps and fans. Quality inspection of impellers is crucial to ensure their reliable performance and durability.
Dell™ PowerEdge™XR5610 Server supports 50 simultaneous streams running AI defect detection in a single CPU config with Dell™PowerEdge™ XR Portfolio offering scalability to 4CPUs at a near-linear scale. 1.4x Gen on Gen Performance Improvement Using Intel® Deep Learning Boost and Intel® OpenVINO™ Smart Factory Solution | Defect Detection Solution.
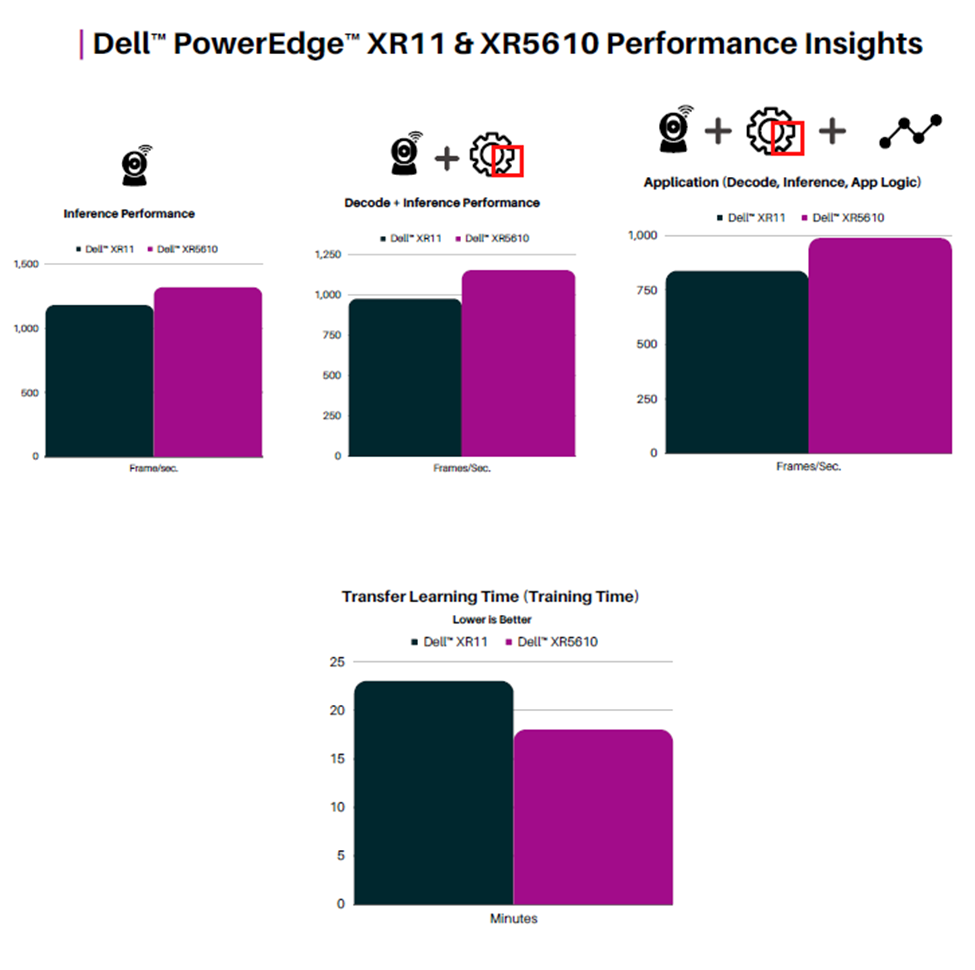
Dell™ PowerEdge™ XR 5610 servers, equipped with fourth Gen Intel® Xeon® scalable processors, are well suited to handle Edge AI applications with both AI inference and training at the Edge. The rugged form factor, extended temp, and scalability to four sockets enable compute to be deployed in the physical world closer to the point of data creation, allowing for near-real-time insights.
Fast-track development with access to the solution code:
Contact your Dell™ representative or Scalers AI™ at contact@scalers.ai for access. Save hundreds of hours of development with the solution code. As part of this effort, ScalersAI™ is making the solution code available.

Next Generation Dell PowerEdge XR7620 Server Machine Learning (ML) Performance
Fri, 03 Mar 2023 19:57:26 -0000
|Read Time: 0 minutes
Summary
Dell Technologies has recently announced the launch of next-generation Dell PowerEdge servers that deliver advanced performance and energy efficient design.
This Direct from Development (DfD) tech note describes the new capabilities you can expect from the next-generation Dell PowerEdge servers powered by Intel 4th Gen Intel® Xeon® Scalable processors MCC SKU stack. This document covers the test and results for ML performance of Dell’s next generation PowerEdge XR 7620 using the industry standard MLPerf Inference v2.1 benchmarking suite. XR7620 has target workloads in manufacturing, retail, defense, and telecom - all key workloads requiring AI/ML inferencing capabilities at the edge.
With up to 2x300W accelerator cards for GPUs to handle your most demanding edge workloads, XR7620 provides a 45% faster image classification workload as compared to the previous generation Dell XR 12 server with just one 300W GPU accelerator for the ML/AI scenarios at the enterprise edge. The combination of low latency and high processing power allows for faster and more efficient analysis of data, enabling organizations to make real-time decisions for more opportunities.
Edge computing
Edge computing, in a nutshell, brings computing power close to the source of the data. As the Internet of Things (IoT) endpoints and other devices generate more and more time-sensitive data, edge computing becomes increasingly important. Machine Learning (ML) and Artificial Intelligence (AI) applications are particularly suitable for edge computing deployments. The environmental conditions for edge computing are typically vastly different than those at centralized data centers. Edge computing sites might, at best, consist of little more than a telecommunications closet with minimal or no HVAC. Rugged, purpose-built, compact, and accelerated edge servers are therefore ideal for such deployments. The Dell PowerEdge XR7620 server checks all of those boxes. It is a high-performance, high-capacity server for the most demanding workloads, certified to operate in rugged, dusty environments ranging from -5C to 55C (23F to 131F), all within a short-depth 450mm (from ear-to-rack) form factor.
MLPerf Inference workload summary
MLPerf is a multi-faceted benchmark suite that benchmarks different workload types and different processing scenarios. There are five workloads and three processing scenarios. The workloads are:
- Image classification
- Object detection
- Medical image segmentation
- Speech-to-text
- Language processing
The scenarios are single-stream (SS), multi-stream (MS), and Offline.
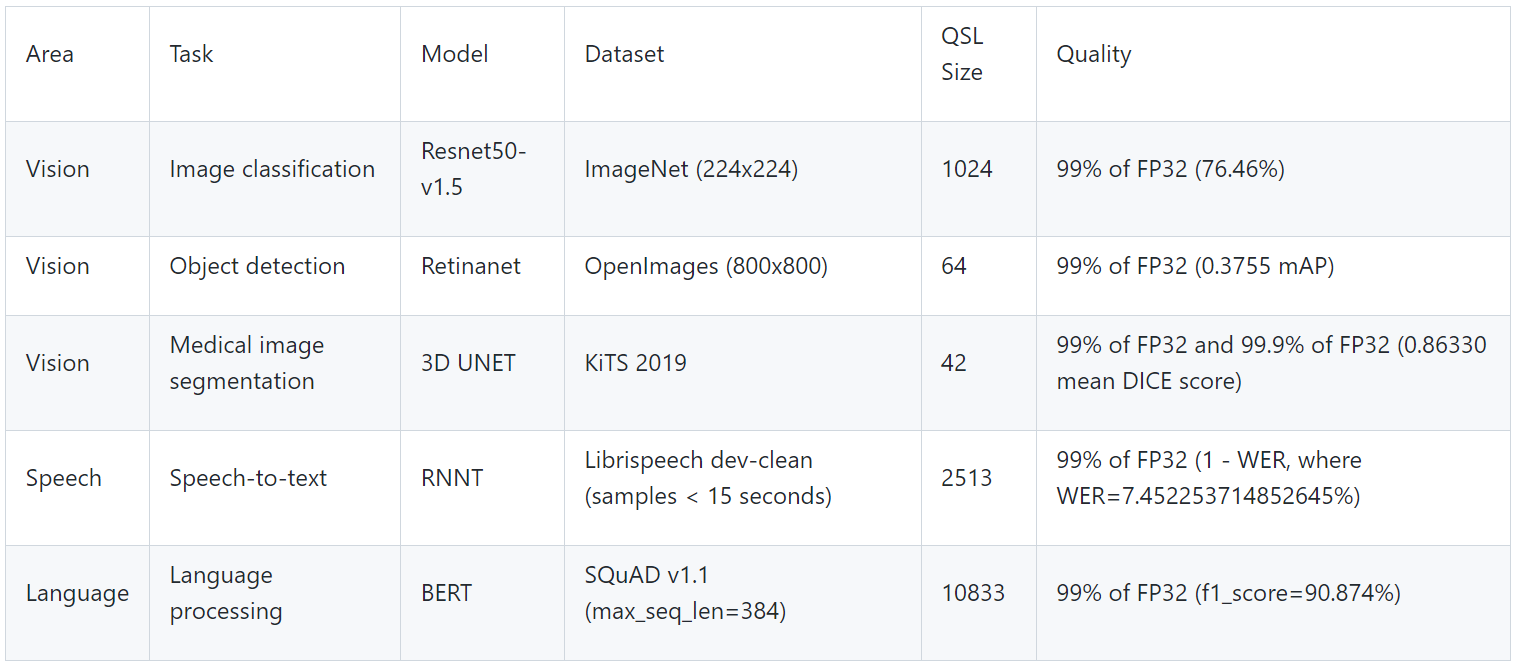
The tasks are self-explanatory and are listed in the following table below, along with the dataset used, the ML model used, and descriptions. The single-stream tests reported results at the 90th percentile; multi-stream tests reported results at the 99th percentile.
Table 1. MLPerf Inference benchmark scenarios
Scenario | Performance metric | Example use cases |
Single-stream | 90% percentile latency | Google voice search: Waits until the query is asked and returns the search results. |
Offline | Measured throughput | Batch processing aka Offline processing. Google photos identifies pictures, tags people, and generates an album with specific people and locations/events Offline. |
Multi-stream | 99% percentile latency | Example 1: Multicamera monitoring and quick decisions. MultiStream is more like a CCTV backend system that processes multiple real-time streams on identifying suspicious behaviors. Example 2: Self driving cameras merge all multiple camera inputs and make drive decisions in real time. |
Table 2. MLPerf EdgeSuite for inferencing benchmarks
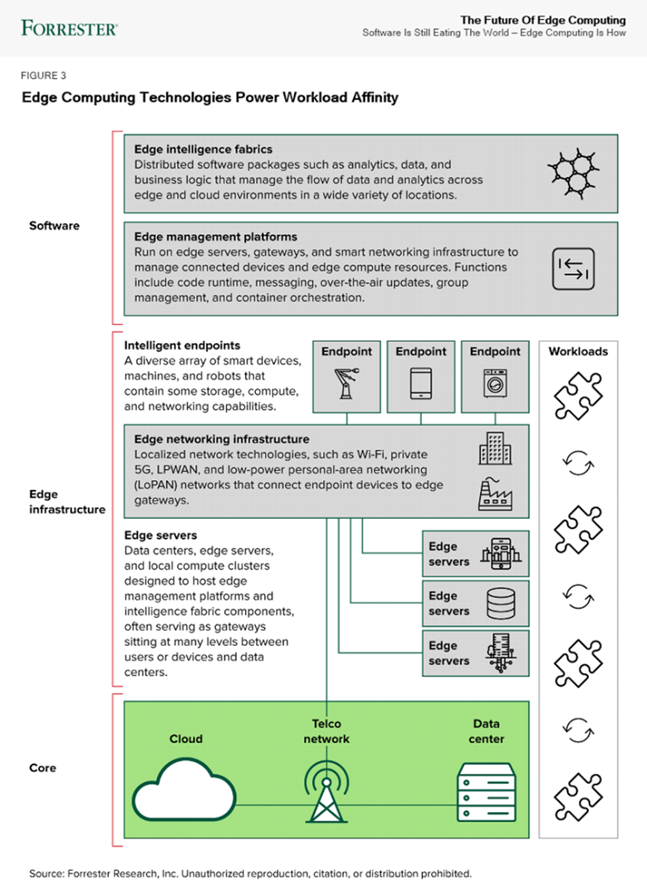
Industry reports about the future of edge computing
According to Forrester’s report (“Five technology elements make workload affinity possible across the four business scenarios”), most systems today are designed to run software in a single place. This creates performance limitations as conditions change, such as when more sensors are installed in a factory, as more people gather for an event, or as cameras receive more video feed. Workload affinity is the concept of using distributed applications to deploy software automatically where it runs best: in a data center, in the cloud, or across a growing set of connected assets. Innovative AI/ML, analytics, IoT, and container solutions enable new applications, deployment options, and software design strategies. In the future, systems will choose where to run software across a spectrum of possible locations, depending on the needs of the moment.
ML/AI inference performance
Table 3. Dell PowerEdge XR7620 key specifications
MLPerf system suite type | Edge |
Operating System | CentOS 8.2.2004 |
CPU | 4th Gen Intel® Xeon® Scalable processors MCC SKU |
Memory | 512GB |
GPU | NVIDIA A2 |
GPU Count | 1 |
Networking | 1x ConnectX-5 IB EDR 100Gb/Sec |
Software Stack | TensorRT 8.4.2 CUDA 11.6 cuDNN 8.4.1 Driver 510.73.08 DALI 0.31.0 |

Figure 1. Dell PowerEdge XR7620: 2U 2S
Table 4. NVIDIA GPUs Tested:
Brand | GPU | GPU memory | Max power consumption | Form factor | 2-way bridge | Recommended workloads |
PCIe Adapter Form Factor | ||||||
NVIDIA | A2 | 16 GB GDDR6 | 60W | SW, HHHL or FHHL | n/a | AI Inferencing, Edge, VDI |
NVIDIA | A30 | 24 GB HBM2 | 165W | DW, FHFL | Y | AI Inferencing, AI Training |
NVIDIA | A100 | 80 GB HBM2e | 300W | DW, FHFL | Y, Y | AI Training, HPC, AI Inferencing |
The edge server offloads the image processing to the GPU. And just as servers have different price/performance levels to suit different requirements, so do GPUs. XR7620 supports up to 2xDW 300W GPUs or 4xSW 150W GPUs, part of the constantly evolving scalability and flexibility offered by the Dell PowerEdge server portfolio. In comparison, the previous gen XR11 could support up to 2xSW GPUs.
Edge server vs data center server comparison[1]
When testing with NVIDIA A100 GPU for the Offline scenario, the Dell XR7620 delivered a performance with less than 1% difference, as compared to the prior generation Dell PowerEdge rack server. The XR7620 edge server with a depth of 430mm is capable of providing similar performance for an AI inferencing scenario as a rack server. See Figure 2.
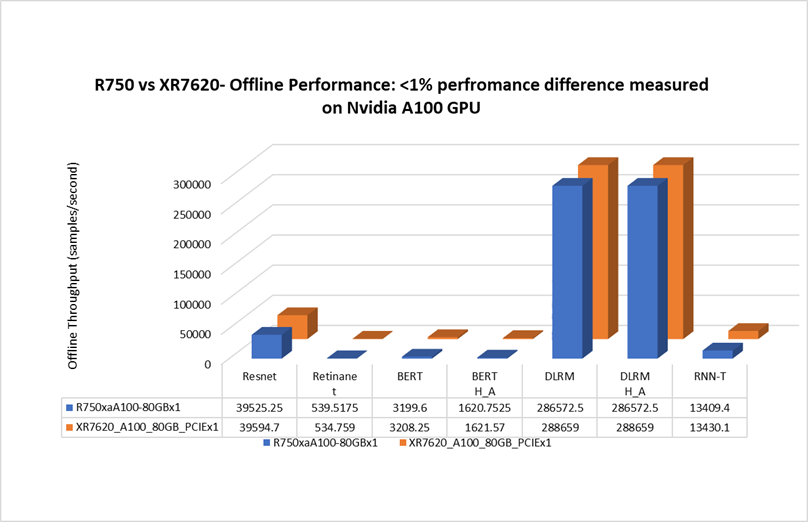
Figure 2. Rack vs edge server MLPerf Offline performance
XR7620 performance with NVIDIA A2 GPU
XR7620 was also tested with NVIDIA A2 GPU for the entire range of MLPerf workloads in the Offline scenario. For the results, see Figure 3.
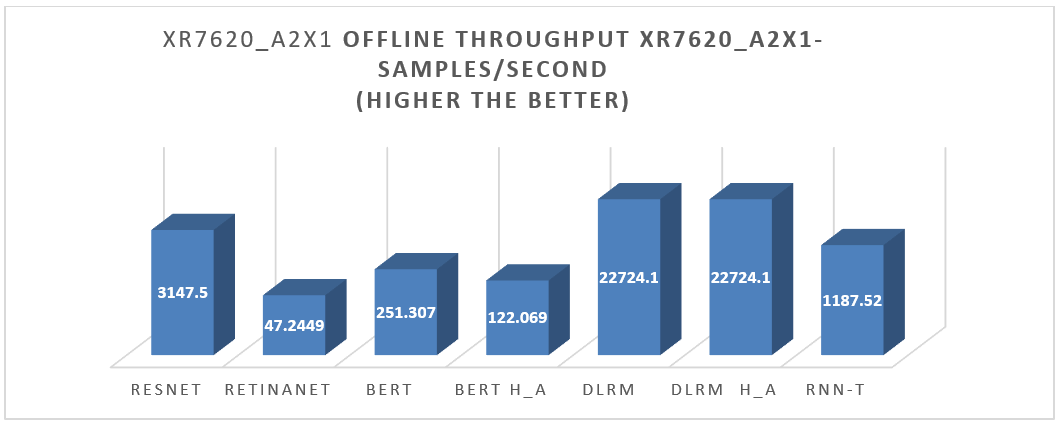
Figure 3. XR7620 Offline performance results
XR7620 was also tested with NVIDIA A2 GPU for the entire range of MLPerf workloads in the Single Stream scenario. See Figure 4.
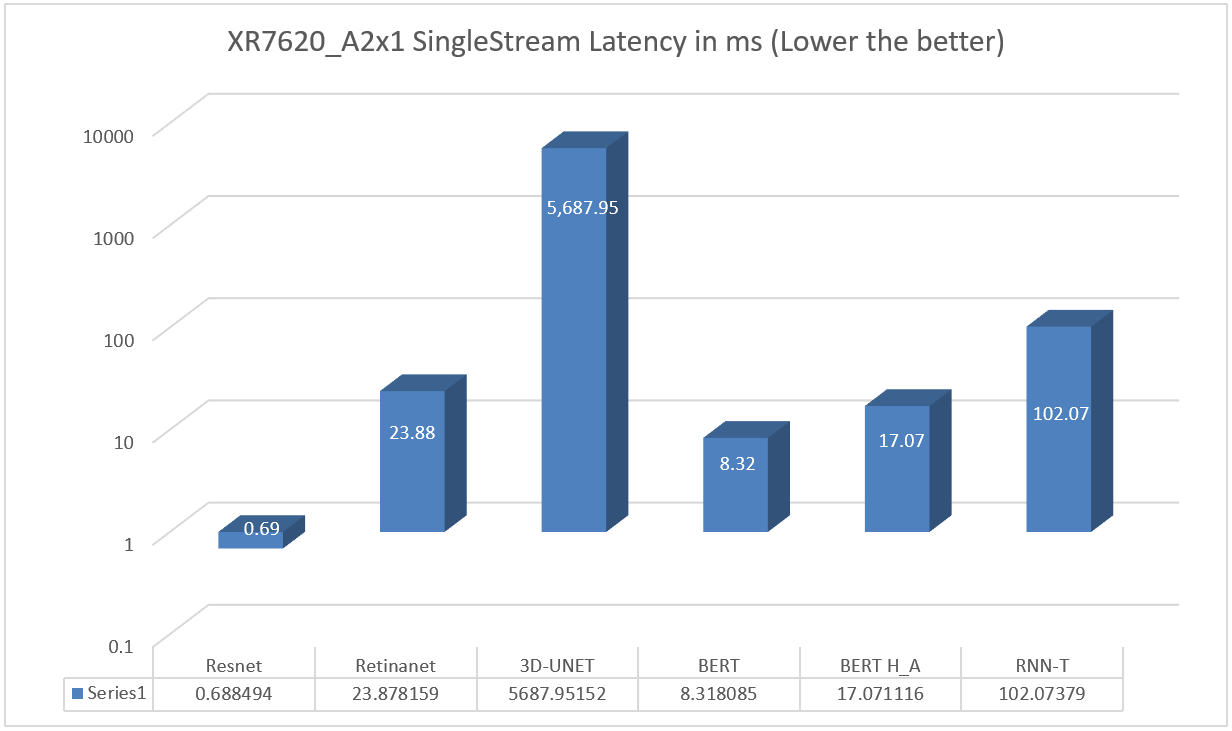
Figure 4. XR7620 Single Stream Performance results
XR7620 was also tested with NVIDIA A30 GPU for the entire range of MLPerf workloads in the Offline Scenario. See Figure 5.
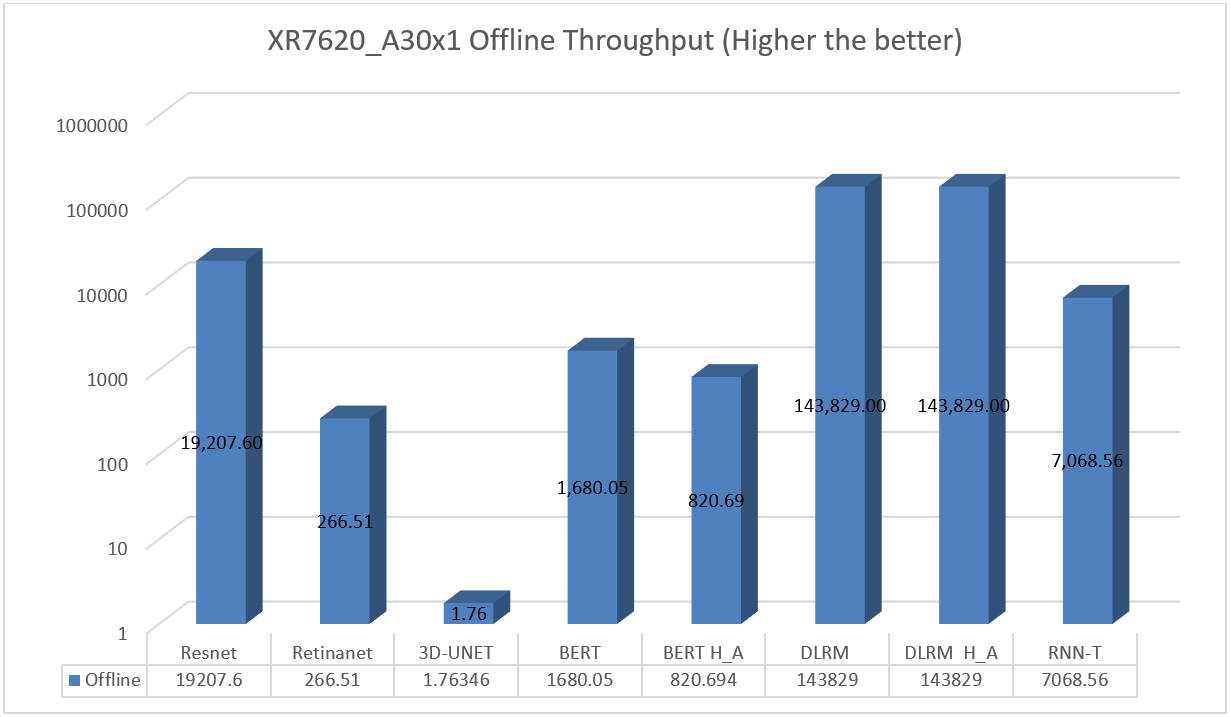
Figure 5. XR7620 Offline Performance results on A30 GPU
XR7620 was also tested with NVIDIA A30 GPU for the entire range of MLPerf workloads in the Single Scenario. See Figure 6.
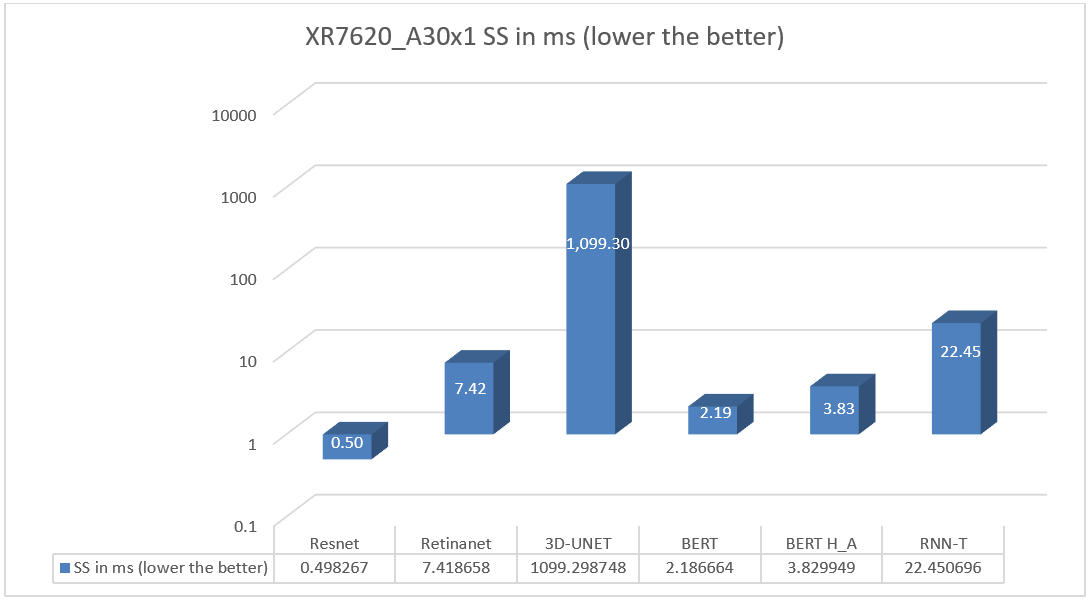
Figure 6. XR7620 SS Performance results on A30 GPU
In some scenarios, next generation Dell PowerEdge servers showed improvement over previous generations, due to the integration of the latest technologies such as PCIe Gen 5.
Speech to text
The Dell XR7620 delivered better throughput by 16%, as compared to the prior generation Dell server. See Figure 7
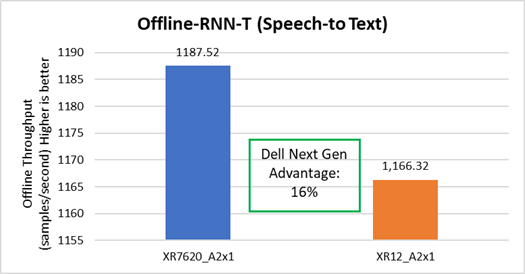
Figure 7. Offline Speech to Text performance improvement on XR7620
Image Classification
The Dell XR7620 delivered better latency by 45%, as compared to the prior generation Dell server. See Figure 8.
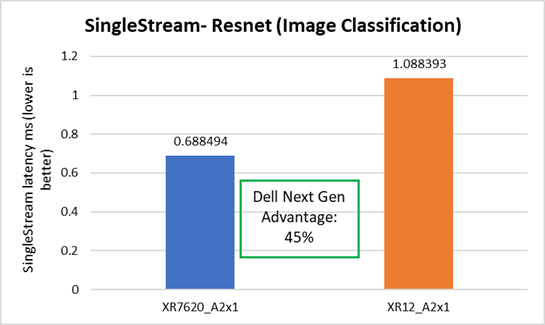
Figure 8. SS Image Classification performance improvement on XR7620
Conclusion
The Dell XR portfolio continues to provide a streamlined approach for various edge and telecom deployment options based on various use cases. It provides a solution to the challenge of small form factors at the edge with industry-standard rugged certifications (NEBS), with a compact solution for scalability and flexibility in a temperature range of -5 to +55°C. The MLPerf results provide a real-life scenario on edge inferencing for servers on AI inferencing. Based on the results in this document, Dell servers continue to provide a complete solution.
References
Notes:
- Based on testing conducted in Dell Cloud and Emerging Technology lab, January 2023. Results to be submitted to MLPerf in Q2,FY24.
- Unverified MLPerf v2.1 Inference. Results not verified by MLCommons Association. MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
[1] Based on testing conducted in Dell Cloud and Emerging Technology lab, January 2023.