



The First MLPerf Inference v2.1 Performance Result on AMD EPYC™ CPU-Based PowerEdge Servers
Thu, 08 Sep 2022 17:00:38 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies, AMD, and Deci AI recently submitted results to MLPerf Inference v2.1 in the open division. This blog showcases our first successful three-way submission and describes how the software and hardware of each party was best used to achieve optimal performance for the MLPerf BERT-Large model.
Introduction
MLCommons™ is a consortium of companies whose mission is to accelerate machine learning innovation to benefit everyone. The organization focuses on benchmarking to enable the display of fair performance measurements and makes datasets open and available, since models in the benchmarks are only as good as the data. It also shares best practices to initiate standardization of sharing and communication among machine learning stakeholders.
The MLPerf Inference v2.1 submission falls under the benchmarking road map for MLCommons. Submissions made to the closed division warrant an equitable comparison of hardware platforms and software frameworks. The submissions must use the same model and optimizer as the reference implementation. Additionally, no retraining is permitted in the closed division. On the other hand, the open division promotes faster models and optimizers as it allows benchmark implementations that use a different model for the same task. Any machine learning approach is permitted if it meets the target quality. Results submitted to the open division showcase exciting technologies that are being developed.
This blog highlights an offline submission made in the open division BERT 99.9 category for the natural language processing (NLP) task. The goal of the submission was to maximize throughput while keeping the accuracy within a 0.1 percent margin of error from the baseline accuracy, which is 90.874 F1 (Stanford Question Answering Dataset (SQuAD)).
Dell PowerEdge R7525 Server Powered with AMD EPYC™ processors
Since MLPerf benchmarking results are a showcase of the joint performance of both the software and underlying hardware, Deci AI’s optimized BERT-Large model, known as DeciBERT-Large, was run using ONNXRT on the Dell PowerEdge R7525 rack server populated with two 64-core AMD EPYC 7773X processors.
The PowerEdge R7525 rack server is a highly scalable and adaptable two-socket 2U rack server that delivers powerful performance and flexible configurations. It is ideal for traditional and emerging workloads and applications that include flash software-defined storage (SDS), virtual desktop infrastructure (VDI), and data analytics (DA) workloads. As this blog’s MLPerf submission shows, the PowerEdge R7525 rack server is also well suited for AI workloads such as deep learning inference.
The PowerEdge R7525 server is an excellent server choice for several reasons. Some of the high-level specifications to meet performance demands include up to 24 directly connected NVMe drives that support all flash AF8 vSAN Ready Nodes. The 4 TB of memory and two AMD EPYC processors enable optimal performance. Also, the PowerEdge R7525 server has maximized IOPS, storage, and memory configurations enabled by up to eight PCIe Gen4 slots. Furthermore, AMD Instinct™ MI100 and MI200 series accelerators and other double-width GPUs can provide additional levels of acceleration.
AMD EPYC processors with AMD 3D V-Cache™ Technology were launched in March 2022. This innovative new lineup of server-class AMD EPYC processors was positioned for accelerating technical computing workloads, including computational fluid dynamics (CFD), electronic design automation (EDA), and finite element analysis (FEA).
With this joint MLPerf submission, a first for AMD EPYC processors with AMD 3D V-Cache Technology, AMD demonstrates the applicability of the new AMD EPYC processors and their extra L3 cache for deep learning inference workloads.
Deci AI DeciBERT-Large Model Comparisons and Metrics
Deci AI used their proprietary AutoNAC™ (Automated Neural Architecture Construction) Engine to generate an optimized BERT-Large model, called DeciBERT-Large, tuned specifically for the underlying PowerEdge R7525 server and two 64-core AMD EPYC 7773X processors. The Deci AI algorithm reduces the reference BERT-Large model size by nearly three times, from 340 million parameters in the standard BERT-Large model down to 115 million parameters, while achieving compelling performance and accuracy.
From a memory capacity perspective, the parameter count reduction also contributes to similarly significant space savings with the DeciBERT-Large model. The ONNX DeciBERT-Large model size is 378 MB in FP32 and 95 MB in INT8 compared to 1.4 GB of the reference BERT-Large model implementation from MLCommons.
By pairing the optimized, smaller DeciBERT-Large model with the extended L3 cache capacity of the AMD EPYC processors with 3D V-Cache, more of the model can be stored in the cache at a time. This method of leveraging the additional L3 cache enables near compute and lower latency memory accesses compared to DRAM.
The following tables highlight the data points collected by Deci AI on the PowerEdge R7525 server with two AMD EPYC 7773X processors. The application of the Deci AI AutoNAC algorithm to generate the DeciBERT-Large model highlights a 6.33 times improvement in FP32 performance and a 6.64 times improvement in INT8 performance, while achieving an INT8 F1 score of 91.08, which is higher than the F1 score of 90.07 of the reference BERT-Large implementation in INT8.
Table 1: BERT-Large comparisons – FP32
F1 accuracy on SQuAD (FP32) | Parameter count | Model size | Throughput (QPS) ONNX runtime FP32 | |
BERT-Large | 90.87 | 340 million | 1.4 GB | 12 |
DeciBERT-Large | 91.08 | 115 million | 378 MB or 0.378 GB | 76 |
Deci Gains | 0.21 better F1 accuracy | 66.2% improvement | 73% size reduction | 6.33 times throughput improvement |
Table 2: BERT-Large comparisons – INT8
F1 accuracy on SQuAD (INT8) | Parameter count | Model size | Throughput (QPS) ONNX runtime INT8 | |
BERT-Large | 90.07 | 340 million | 1.4 GB
| 18 |
DeciBERT-Large | 91.08 | 115 million | 95 MB or 0.095 GB | 116 |
Deci Gains | 1.01 better F1 accuracy | 66.2% improvement | 93.2% size reduction | 6.44 times throughput improvement |
The following figure shows that Deci AI’s implementations of the BERT-Large models compiled with ONNXRT are critical in enabling competitive performance in both FP32 and INT8 precisions:
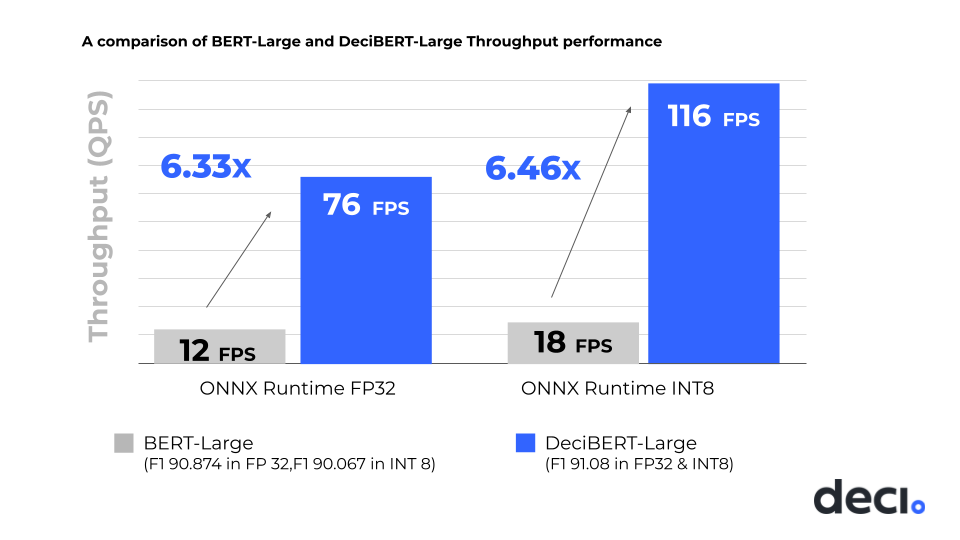
Figure 1: Performance comparison between the reference BERT-Large model implementation and Deci AI’s optimized DeciBERT-Large model
FP32 is commonly used for running deep learning models as it is the default floating datatype in programming languages. It consists of 32 bits of ones and zeros, of which the first bit is the sign bit, representing whether the value is positive. The next eight bits are the exponent of the number, and the last 23 bits are the fraction or mantissa of the number. FP32, or floating point 32, uses nine bits for range and 23 bits for accuracy. The dynamic range of FP32, or the quantity of representable numbers using this datatype, reaches nearly four billion values.
INT8 has become a popular datatype for deep learning inference. Since INT8 has fewer bits and a smaller dynamic range (256 values compared to the four billion values representable by FP32), INT8 compute requirements are considerably reduced compared to FP32. Typically, latencies are lower and throughputs are higher when using INT8 models compared to FP32 models. However, the increased throughput and lower latency tends to come at the cost of accuracy degradation.
Most MLPerf BERT-Large submissions in the 99.9 percent accuracy category use 32-bit or 16-bit quantization because 8-bit quantization is lossy and typically reduces model accuracy below the 99.9 percent threshold. For example, while applying INT8 quantization to the baseline BERT-Large model is an option that accelerates throughput from 12 FPS to 18 FPS, it no longer meets the MLPerf 99.9 percent accuracy constraints.
Deci AI AutoNac Engine and Optimization
The Deci AI AutoNAC engine guarantees that the model designed meets the accuracy requirements set by MLPerf and pursues the most performant variation of the specific model within those constraints, allowing INT8 quantization to be leveraged for the submission.
The Deci AI AutoNAC engine begins by generating a dynamic search space that accounts for parameters such as the baseline accuracy, inference performance targets, underlying hardware, compilers, and quantization, among others. A fast and accurate multiconstraints search algorithm is initiated and creates a new model architecture that delivers the highest performance given the defined constraints.
From a computation time perspective, the AutoNAC search process is approximately three times longer than standard training, depending on the task. For example, training the DeciBert model to perform the SQuAD NLP task requires approximately 60 GPU hours. The search for this DeciBERT model required approximately 180 GPU hours, and the computation involved was parallelized. Therefore, the computation of AutoNAC is commercially affordable for almost any organization.
In summary, Deci AI generated a model using AutoNAC that was specifically designed to deliver optimal performance within the MLPerf constraints when running on a Dell server with AMD EPYC processors with 3D V-Cache.
The following figure shows the AutoNAC optimization process:
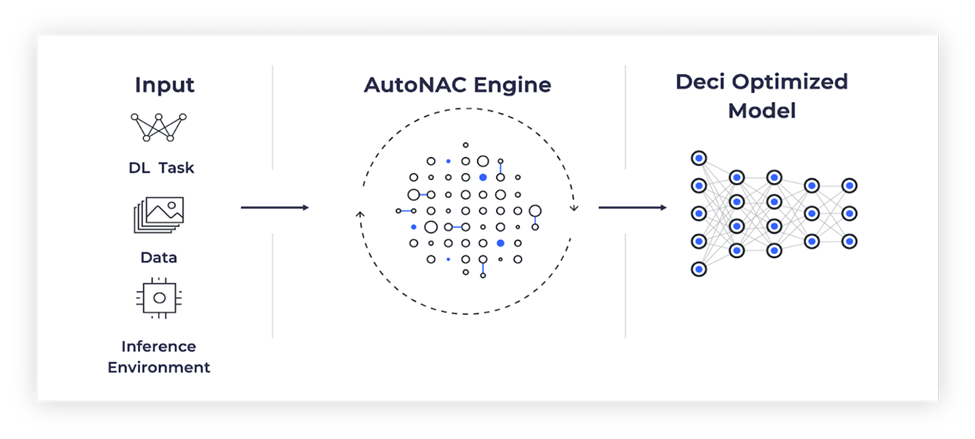
Figure 2: Deci AI’s AutoNac process
Conclusion
The Deci AI AutoNAC engine generates optimized deep learning inference models that meet customer accuracy and dataset requirements while maximizing performance. The increased performance, combined with the significant reduction in parameter count and memory size, positions Deci AI optimized models as highly efficient for a range of applications. The DeciBERT-Large model is an optimized version of the state-of-the-art BERT-Large model for NLP applications. Applying that to real-world scenarios, call centers are examples of customers that can take advantage of deep learning insights in the areas of sentiment analysis, live transcription and translation, and question answering. The DeciBERT-Large model, as developed for MLPerf v2.1 by Deci AI, can be easily tuned for a call center’s own dataset and application, and deployed in production today to improve performance, shorten time to insights, and enable the deployment of smaller optimized models with reduced compute requirements, which becomes particularly beneficial in power or cost constrained environments.
Related Blog Posts
Unveiling the Power of the PowerEdge XE9680 Server on the GPT-J Model from MLPerf™ Inference
Tue, 16 Jan 2024 18:30:32 -0000
|Read Time: 0 minutes
Abstract
For the first time, the latest release of the MLPerf™ inference v3.1 benchmark includes the GPT-J model to represent large language model (LLM) performance on different systems. As a key player in the MLPerf consortium since version 0.7, Dell Technologies is back with exciting updates about the recent submission for the GPT-J model in MLPerf Inference v3.1. In this blog, we break down what these new numbers mean and present the improvements that Dell Technologies achieved with the Dell PowerEdge XE9680 server.
MLPerf inference v3.1
MLPerf inference is a standardized test for machine learning (ML) systems, allowing users to compare performance across different types of computer hardware. The test helps determine how well models, such as GPT-J, perform on various machines. Previous blogs provide a detailed MLPerf inference introduction. For in-depth details, see Introduction to MLPerf inference v1.0 Performance with Dell Servers. For step-by-step instructions for running the benchmark, see Running the MLPerf inference v1.0 Benchmark on Dell Systems. Inference version v3.1 is the seventh inference submission in which Dell Technologies has participated. The submission shows the latest system performance for different deep learning (DL) tasks and models.
Dell PowerEdge XE9680 server
The PowerEdge XE9680 server is Dell’s latest two-socket, 6U air-cooled rack server that is designed for training and inference for the most demanding ML and DL large models.

Figure 1. Dell PowerEdge XE9680 server
Key system features include:
- Two 4th Gen Intel Xeon Scalable Processors
- Up to 32 DDR5 DIMM slots
- Eight NVIDIA HGX H100 SXM 80 GB GPUs
- Up to 10 PCIe Gen5 slots to support the latest Gen5 PCIe devices and networking, enabling flexible networking design
- Up to eight U.2 SAS4/SATA SSDs (with fPERC12)/ NVMe drives (PSB direct) or up to 16 E3.S NVMe drives (PSB direct)
- A design to train and inference the most demanding ML and DL large models and run compute-intensive HPC workloads
The following figure shows a single NVIDIA H100 SXM GPU:

Figure 2. NVIDIA H100 SXM GPU
GPT-J model for inference
Language models take tokens as input and predict the probability of the next token or tokens. This method is widely used for essay generation, code development, language translation, summarization, and even understanding genetic sequences. The GPT-J model in MLPerf inference v3.1 has 6 B parameters and performs text summarization tasks on the CNN-DailyMail dataset. The model has 28 transformer layers, and a sequence length of 2048 tokens.
Performance updates
The official MLPerf inference v3.1 results for all Dell systems are published on https://mlcommons.org/benchmarks/inference-datacenter/. The PowerEdge XE9680 system ID is ID 3.1-0069.
After submitting the GPT-J model, we applied the latest firmware updates to the PowerEdge XE9680 server. The following figure shows that performance improved as a result:
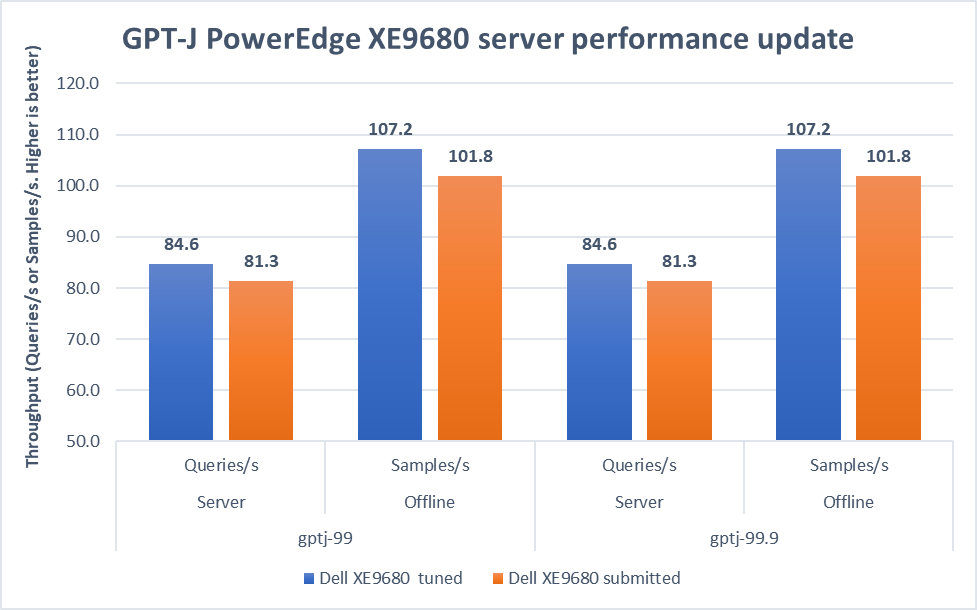
Figure 3. Improvement of the PowerEdge XE9680 server on GPT-J Datacenter 99 and 99.9, Server and Offline scenarios [1]
In both 99 and 99.9 Server scenarios, the performance increased from 81.3 to an impressive 84.6. This 4.1 percent difference showcases the server's capability under randomly fed inquires in the MLPerf-defined latency restriction. In the Offline scenarios, the performance saw a notable 5.3 percent boost from 101.8 to 107.2. These results mean that the server is even more efficient and capable of handling batch-based LLM workloads.
Note: For PowerEdge XE9680 server configuration details, see https://github.com/mlcommons/inference_results_v3.1/blob/main/closed/Dell/systems/XE9680_H100_SXM_80GBx8_TRT.json
Conclusion
This blog focuses on the updates of the GPT-J model in the v3.1 submission, continuing the journey of Dell’s experience with MLPerf inference. We highlighted the improvements made to the PowerEdge XE9680 server, showing Dell's commitment to pushing the limits of ML benchmarks. As technology evolves, Dell Technologies remains a leader, constantly innovating and delivering standout results.
[1] Unverified MLPerf® v3.1 Inference Closed GPT-J. Result not verified by MLCommons Association.
The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
Comparison of Top Accelerators from Dell Technologies’ MLPerf™ Inference v3.0 Submission
Fri, 21 Apr 2023 21:43:39 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to MLPerfTM Inference v3.0 in the closed division. This blog highlights the NVIDIA H100 PCIe GPU and compares the results to the NVIDIA A100 PCIe GPU with the PCIe form factor held constant.
Introduction
MLPerf Inference v3.0 submission falls under the benchmarking pillar of the MLCommonsTM consortium with the objective to make fair comparisons across server configurations. Submissions that are made to the closed division warrant an equitable comparison of the systems.
This blog highlights the closed division submissions Dell Technologies made with the NVIDIA A100 GPU using the PCIe (peripheral component interconnect express) form factor. The PCIe form factor is an interfacing standard for connecting various high-speed components in hardware such as a computer or a server. Servers include a certain number of PCIe slots in which to insert GPUs or other additional cards. Note that there are different physical configurations for the slots to indicate the number of lanes for data to travel to and from the PCIe card. The NVIDIA H100 GPU is truly the latest and greatest GPU with NVIDIA AI Enterprise included; it is a dual-slot air cooled PCIe generation 5.0 GPU. This GPU runs at a memory bandwidth speed of over 2,000 megabits per second and up to seven Multi-Instance GPUs at 10 gigabytes each. The NVIDIA A100 80 GB GPU is a dual-slot PCIe generation 4.0 GPU that runs at a memory bandwidth speed of over 2,000 megabits per second.
NVIDIA H100 PCIe GPU and NVIDIA A100 PCIe GPU comparison
In addition to making a submission with the NVIDIA A100 GPU, Dell Technologies made a submission with the NVIDIA H100 GPU. To make a fair comparison, the systems were identical and the PCIe form factor was held constant.
Platform | Dell PowerEdge R750xa (4x A100-PCIe-80GB, TensorRT) | Dell PowerEdge R750xa (4x H100-PCIe-80GB, TensorRT) |
Round | V3.0 | |
MLPerf System ID | R750xa_A100_PCIe_80GBx4_TRT | R750xa_H100_PCIe_80GBx4_TRT |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
Memory | 1 TB | 1 TB |
GPU | NVIDIA A100-PCIe-80GB | NVIDIA H100-PCIe-80GB |
GPU form factor | PCIe | |
GPU memory configuration | HBM2e | |
GPU count | 4 | |
Software stack | TensorRT 8.6 CUDA 12.0 cuDNN 8.8.0 Driver 525.85.12 DALI 1.17.0 | TensorRT 8.6 CUDA 12.0 cuDNN 8.8.0 Driver 525.60.13 DALI 1.17.0 |
Table 1: Software stack of submissions made on NVIDIA A100 PCIe and NVIDIA H100 PCIe GPUs for MLPerf Inference v3.0 on the Dell PowerEdge R750xa server
In the following figure, the per card numbers are normalized over the NVIDIA A100 GPU results to show a readable comparison of the GPUs on the same system. Across object detection, medical image segmentation, and speech to text and natural language processing, the latest NVIDIA H100 GPU outperforms its predecessor in all categories. Note the outstanding performance of the Dell PowerEdge R750xa server with NVIDIA H100 GPUs with the BERT benchmark in the high accuracy mode. With the advancements in generative artificial intelligence, the Dell PowerEdge R750xa server is a versatile, reliable, and high performing platform.
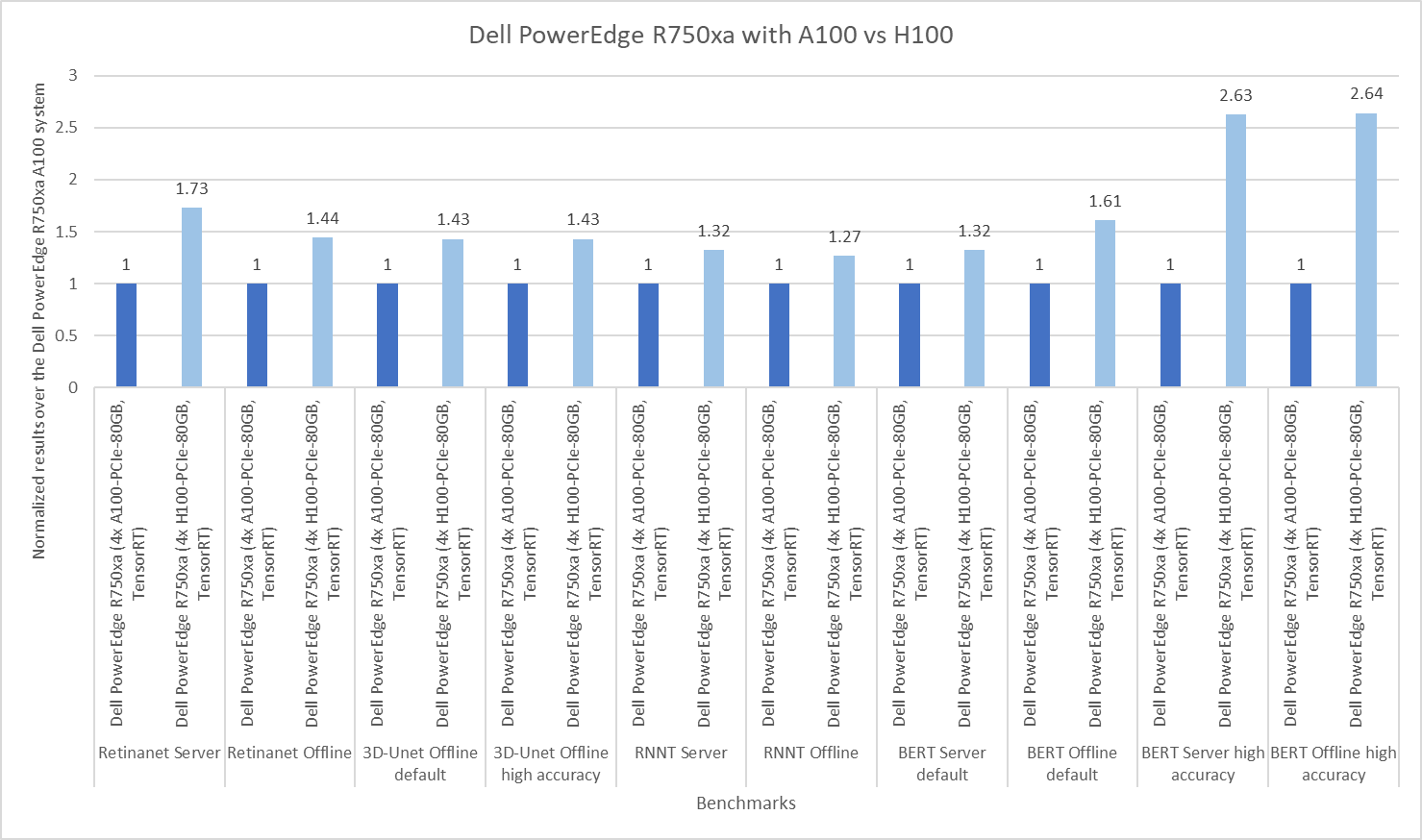
Figure 1: Normalized per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs on the Dell PowerEdge R750xa server
The following figures show absolute numbers for a comparison of the NVIDIA H100 and NVIDIA A100 GPUs.

Figure 2: Per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs for RetinaNet on the PowerEdge R750xa server
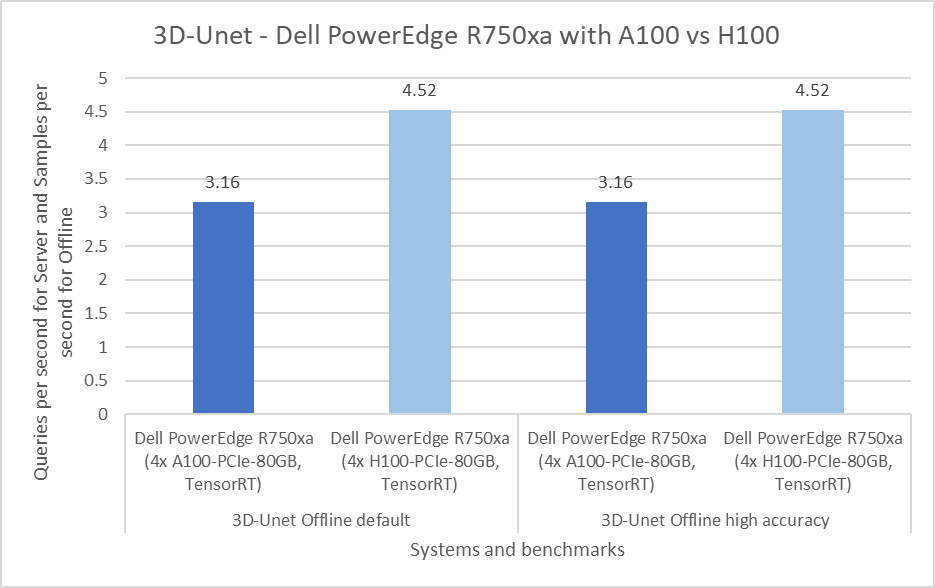
Figure 3: Per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs for 3D-Unet on the PowerEdge R750xa server

Figure 4: Per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs for RNNT on the PowerEdge R750xa server
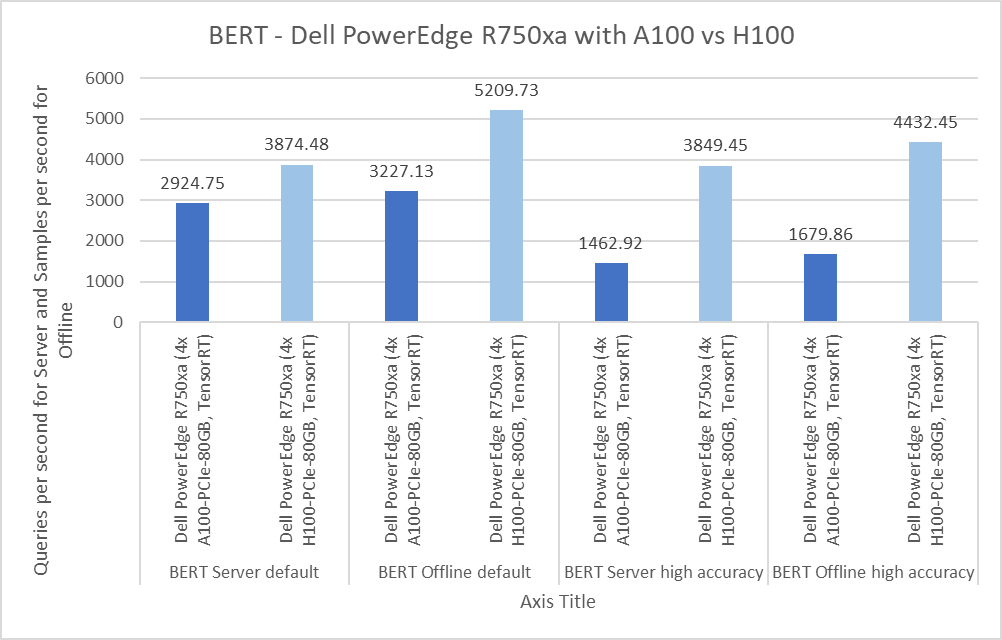
Figure 5: Per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs for BERT on the PowerEdge R750xa server
These results can be found on the MLCommons website.
Submissions made with the NVIDIA A100 PCIe GPU
In this round of submissions, Dell Technologies submitted results on the PowerEdge R750xa server packaged with four NVIDIA A100 80 GB PCIe GPUs. In previous rounds, the PowerEdge R750xa server showed outstanding performance across all the benchmarks. For a deeper dive of a previous round's submission, check out our blog from MLPerf Inference v2.0. From the previous round of MLPerf Inference v2.1 submissions, Dell Technologies submitted results on an identical system. However, across the two rounds of submissions, the main difference is the upgrades in the software stack, as described in the following table:
Platform | Dell PowerEdge R750xa (4x A100-PCIe-80GB, TensorRT) | Dell PowerEdge R750xa (4x A100-PCIe-80GB, TensorRT) |
Round | V3.0 | V2.1 |
MLPerf System ID | R750xa_A100_PCIe_80GBx4_TRT | |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
Memory | 512 GB | |
GPU | NVIDIA A100-PCIe-80GB | |
GPU form factor | PCIe | |
GPU memory configuration | HBM2e | |
GPU count | 4 | |
Software stack | TensorRT 8.6 CUDA 12.0 cuDNN 8.8.0 Driver 525.85.12 DALI 1.17.0 | TensorRT 8.4.2 CUDA 11.6 cuDNN 8.4.1 Driver 510.39.01 DALI 0.31.0 |
Table 2: Software stack for submissions made on the NVIDIA A100 PCIe GPU in MLPerf Inference v3.0 and v2.1
Comparison of PowerEdge R750xa NVIDIA A100 results from Inference v3.0 and v2.1
Object detection
The RetinaNet benchmark falls under the object detection category and uses the OpenImages dataset. The results from Inference v3.0 show a less than 0.05 percent difference in the Server scenario and a 21.53 percent difference in the Offline scenario. A potential reason for this result might be NVIDIA’s optimizations, as outlined in their technical blog.

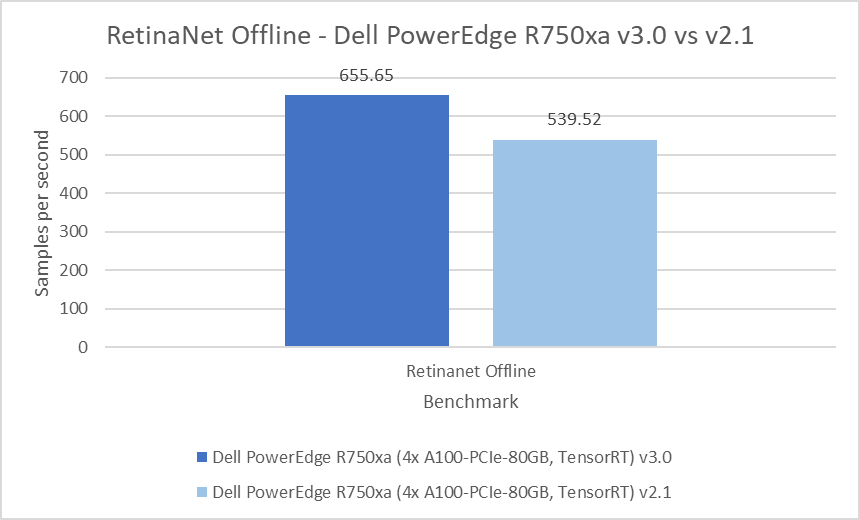
Figure 6: RetinaNet Server and Offline results on the PowerEdge R750xa server from Inference v3.0 and Inference v2.1
Medical image segmentation
The 3D-Unet benchmark performs the KiTS 2019 kidney tumor segmentation task. Across the two rounds of submission, the PowerEdge R750xa server performed consistently well with a 0.3 percent difference in both the default and high accuracy modes.
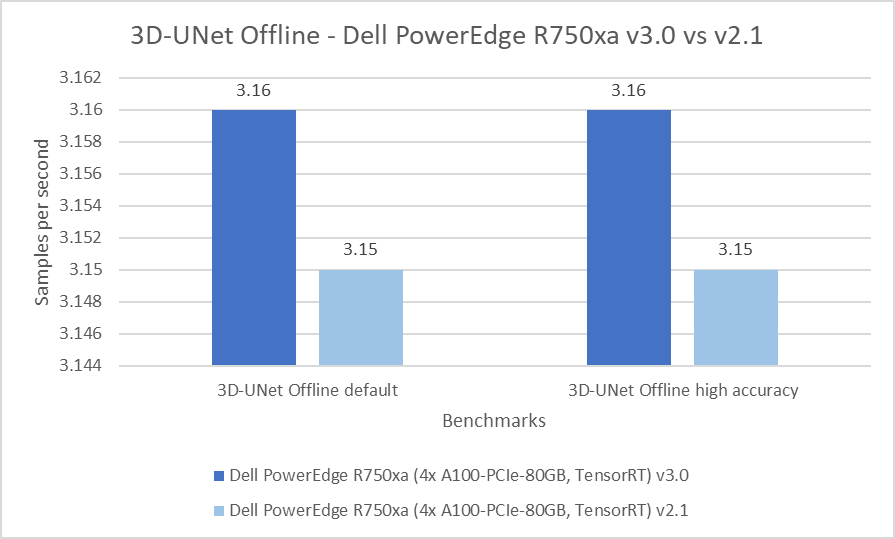
Figure 7: 3D-UNet Offline results on the PowerEdge R750xa server from Inference v3.0 and v2.1
Speech to text
The Recurrent Neural Network Transducers (RNNT) model falls under the speech recognition category. This benchmark accepts raw audio samples and produces the corresponding character transcription. In the Server scenario, the results are within a 2.25 percent difference and 0.41 percent difference in the Offline scenario.

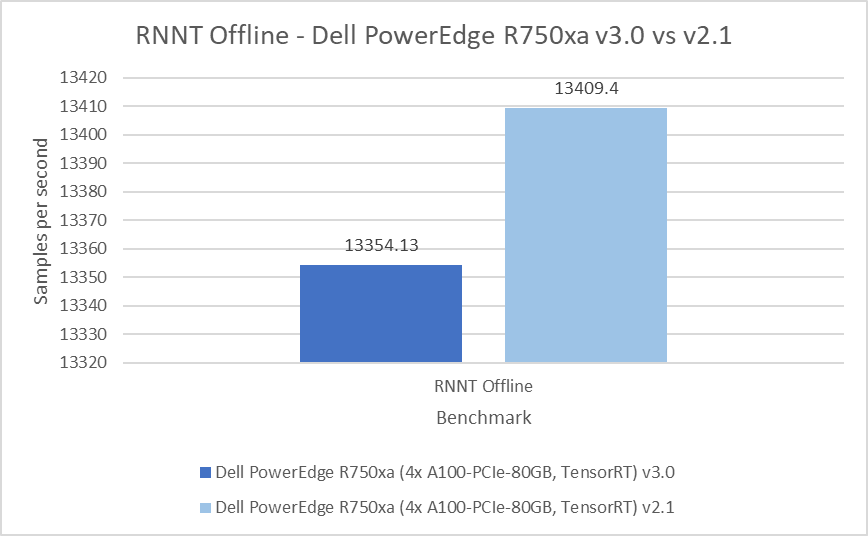
Figure 8: RNNT Server and Offline results on the Dell PowerEdge R750xa server from Inference v3.0 and v2.1
Natural language processing
Bidirectional Encoder Representation from Transformers (BERT) is a state-of-the-art language representational model for Natural Language Processing applications. This benchmark performs the SQuAD question answering task. The BERT benchmark consists of default and high accuracy modes for the Offline and Server scenarios. For the Server scenarios, the default mode results are within a 1.69 percent range and 3.12 percent range for the high accuracy mode. For the Offline scenarios, a similar behavior is noticeable in which the default mode results are within a 0.86 percent range and 3.65 percent range in the high accuracy mode.

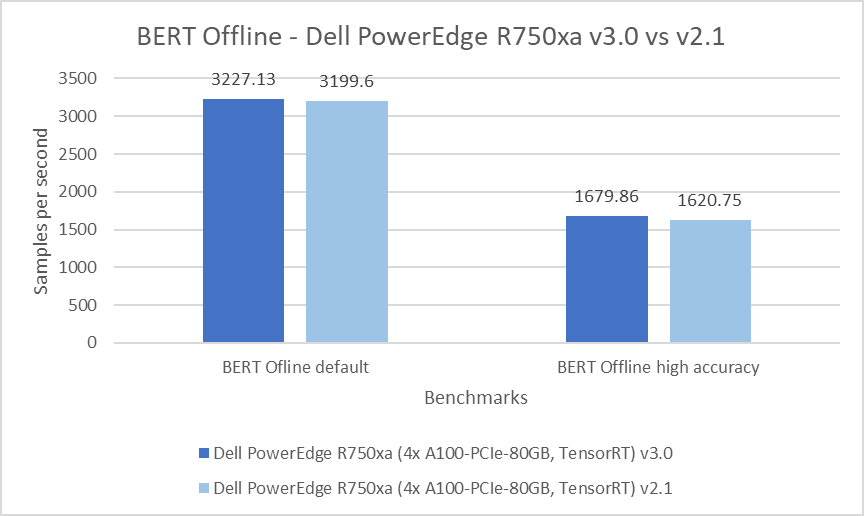
Figure 9: BERT Server and Offline results on the PowerEdge R750xa server from Inference v3.0 and v2.1
Conclusion
Across the various rounds of submissions to the MLPerf Inference benchmark suite, the PowerEdge R750xa server has been a consistent top performer for any machine learning tasks ranging from object detection, medical image segmentation, speech to text and natural language processing. The PowerEdge R750xa server continues to be an excellent server choice for machine learning inference workloads. Customers can take advantage of the diverse results submitted on the Dell PowerEdge R750xa server with the NVIDIA H100 GPU to make an informed decision for their specific solution needs.