




SQL Server in containers: Dell EMC CSI plug-in—It's about manageability!
Mon, 03 Jul 2023 15:55:47 -0000
|Read Time: 0 minutes
A picture can be worth a thousand words, however, not every slide in a presentation is self-explanatory and sometimes even the speaker notes don’t provide enough real estate to cover the full meaning of the content. That happened to me recently with this slide in a technical presentation that I created:
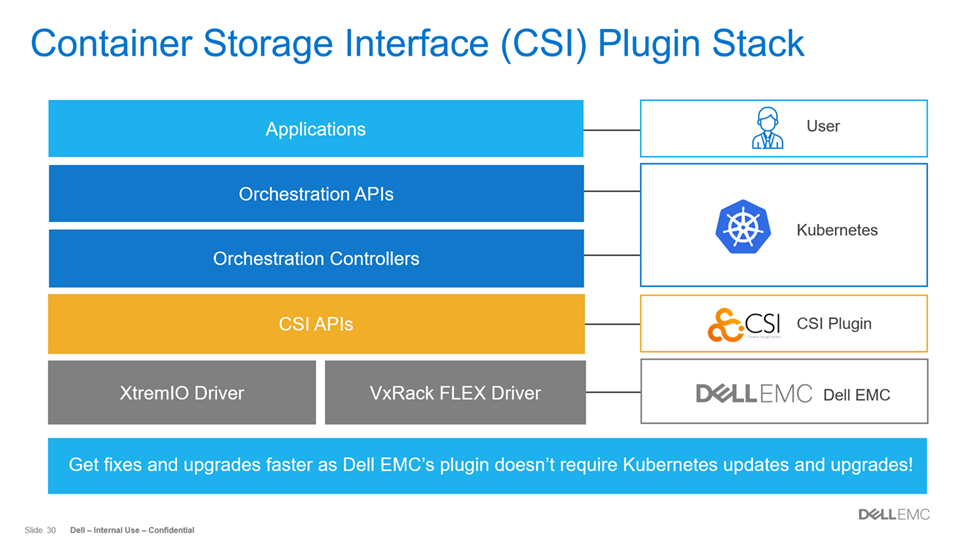
The unanswered question was what does this sentence mean? - “Get fixes and upgrades faster as Dell EMC’s plug-in doesn’t require Kubernetes updates and upgrades!” I wrote this blog give more background and details about that statement. Before we can get to that, let’s discuss the value that the CSI plug-in has for customers using XtremIO X2 and VxRack FLEX. The CSI is a standard used by Dell EMC and other storage providers to provide an interface for container orchestration systems to expose storage services to containers. Thus, the CSI plug-in enables orchestration between containers and storage via Kubernetes. Other orchestration systems such as Mesos, Docker, and Cloud Foundry also use the same CSI specification for managing containers and storage together.
The CSI plug-in has another advantage for both orchestration systems (like Kubernetes) and the storage providers. For example, Kubernetes development can progress independently without requiring storage vendors to check code into the core Kubernetes repository. Similarly, the storage vendors update the CSI plug-in only when required and not with every update or upgrade of Kubernetes. Overall there is less complexity for both Kubernetes developers and storage vendors because the CSI plug-in simplifies the integration between the orchestration and storage layers. Thus, the CSI plug-in enables faster fixes and upgrades by Dell EMC to work with Kubernetes. I hope that answers the question from above. You can also take a look at this Kubernetes blog that goes into greater detail: Introducing Container Storage Interface (CSI) Alpha for Kubernetes.
We also recently wrote a white paper about SQL Server Containers that provides an overview of how the XtremIO X2 features available with our CSI plug-in can be used with SQL Server 2019 Linux containers .With the CSI plug-in, the Kubernetes administrator can:
- Dynamically provision and decommission volumes
- Attach and detach volumes from a host node
- Mount and unmount a volume from a host node
The Kubernetes administrator can even use the XtremIO X2 snapshot capabilities to provision a copy of the SQL Server. It’s these capabilities that really make automation and orchestration of SQL Server containers easier and faster. Want to learn more? The SQL Server Containers white paper is the right starting place because it takes you through the technology and shows how the XtremIO X2 CSI plug-in with Kubernetes and Docker can address traditional challenges.
Please rate this blog and provide us with ideas for future solutions. Thanks!
Related Blog Posts

New Dell EMC Ready Solution powers SQL Server, the complete performance platform
Mon, 03 Aug 2020 16:09:44 -0000
|Read Time: 0 minutes
Working on the new Dell EMC Ready Solution for SQL Server was like going from 0 to 60 mph in under 3 seconds. The exhilaration of being pushed into the seat as the road roars past in a blur is absolute fun. That’s what the combination of Dell EMC PowerEdge R840 servers and the new Dell EMC XtremIO X2 storage array did for us in our recent tests.
The classic challenge with most database infrastructures is diminishing performance over time. To use an analogy, it’s like gradually increasing the load a supercar must pull until its 0-to-60 time just isn’t impressive anymore. In the case of databases, the load is input/output operations per second (IOPS). As IOPS increase, response times can slow and database performance suffers. What is interesting is how this performance problem happens over time. As more databases are gradually added to an infrastructure, response times slow by a fraction at a time. These incremental hits on performance can condition application users to accept slower performance—until one day someone says, “Performance was good two years ago but today it’s slow.”
When reading about supercars, we usually learn about their 0-to-60 mph time and their top speed. While the top speed is interesting, how many supercars have you seen race by at 200+ mph? Top speeds apply to databases too. Perhaps you have read a third-party study that devoted a massive hardware infrastructure to one database, thereby showing big performance numbers. If only we had the budget to do that for all our databases, right? Top speeds are fun, but scalability is more realistic as most infrastructures will be required to support multiple databases.
Dell EMC Labs took the performance scalability approach in testing the new SQL Server architecture. Our goals were aggressive: Run 8 virtualized databases per server for a total of 16 databases running in parallel, with a focus on generating significant load while maintaining fast response times. To make the scalability tests more interesting, 8 virtualized databases used Windows Server Datacenter on one server and the other 8 databases used Red Hat Enterprise Linux on another server. Figure 1 shows the two PowerEdge R840 servers and the 8-to-1 consolidation ratio (on each server) achieved in the tests.

Figure 1: PowerEdge R840 servers
Quest Benchmark Factory was used to create the same TPC-E OLTP workload across all 16 virtualized databases. On the storage side, XtremIO X2 was used to accelerate all database I/O. The XtremIO X2 configuration included two X-Brick modules, each with 36 flash drives for a total of 72. According to the XtremIO X2 specification sheet, a 72-drive configuration can achieve 220,000 IOPS at .5 milliseconds (ms) of latency with a mixture of 70 percent reads and 30 percent writes using 8K blocks. Figure 2 shows the two X-Brick configuration of the X2 array with some of key features that make the all-flash system ideal for SQL Server databases.
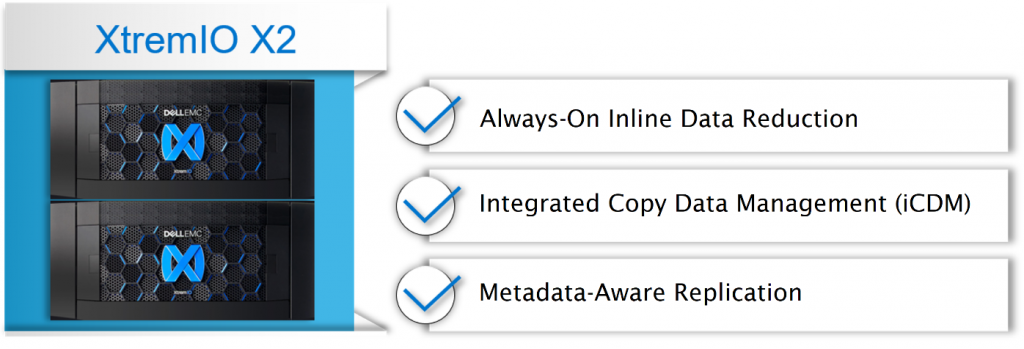
Figure 2: XtremIO X2
Before we review the performance findings, let’s talk about IOPS and latency. IOPS is a measure that defines the load on a storage system. This measurement has greater context if we understand the maximum recommended IOPS for a storage system for a specific configuration. For example, 16 databases running in parallel don’t represent a significant load if they are only generating 20,000 IOPS. However, if the same databases generated 200,000 IOPS, as they did on the XtremIO X2 array that we used in our tests, then that’s a significant workload. Thus, IOPS are important in understanding the load on a storage system.
Response time and latency are used interchangeably in this blog and refer to the amount of time used to respond to a request to read or write data. Latency is our 0-to-60 metric that tells us how fast the storage system responds to a request. Just like with supercars, the lower the time, the faster the car and the storage system. Our goal was to determine if average read and write latencies remained under .5 ms.
Looking at IOPS and latency together brings us to our overall test objective. Can this SQL Server solution remain fast (low latency) under a heavy IOPS load? To answer this question is to understand if the database solution can scale. Scalability is the capability of the database infrastructure to handle increased workload with minimal impact to performance. The greater the scalability of the database solution, the more workload it can support and the greater return on investment it provides to customers. So, for our tests to be meaningful we must show a significant load; otherwise, the database system has not been challenged in terms of scalability.
We broke the achievable IOPS barrier of 220,000 IOPS by more than 55,000 IOPS! In large part, the PowerEdge R840 servers enabled the SQL Server databases to really push the OLTP workload to the XtremIO X2 array. We were able to simulate overloading the system by placing a load that is greater than recommended. In one respect we were impressed that XtremIO X2 supported more than 275,000 IOPS, but then we were concerned that there might have been a trade-off with performance.
The average latency for all physical reads and writes was under .5 ms. So not only did the SQL Server solution generate a large database workload, the XtremIO X2 storage system maintained consistently fast latencies throughout the tests. The test results show that this database solution was designed for performance scalability: The system maintained performance under a large workload across 16 databases. Figure 3 summarizes the test findings.
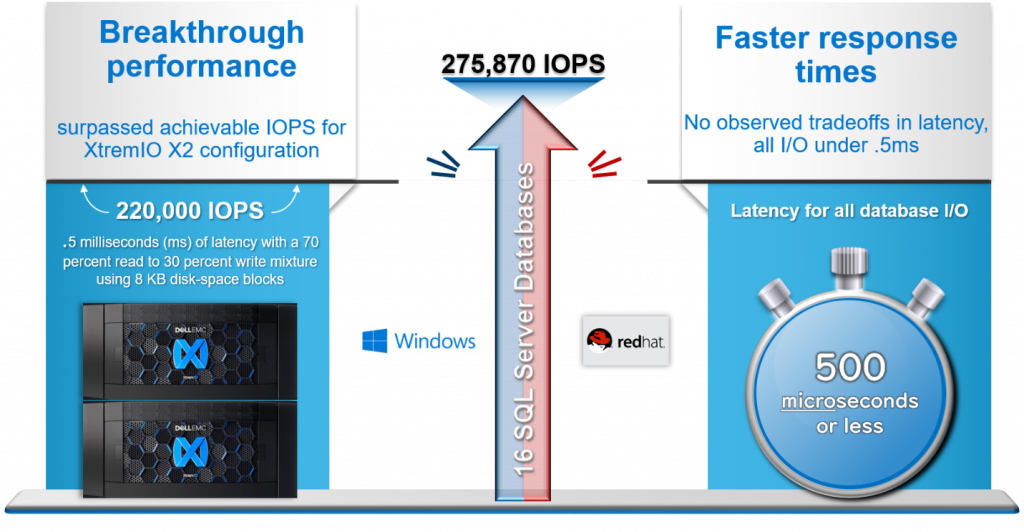
Figure 3: Summary of test findings
The capability to scale without having to invest in more infrastructure provides greater value to customers. Would I recommend pushing the new SQL Server solution past its limits like Dell EMC Labs did in testing for scalability? No. Running database tests involves achieving a steady state of performance that is uncharacteristic of real-world production databases. Production databases have peak processing times that must be planned for so that the business does not experience any performance issues. Dell EMC has SQL Server experts that can design the Ready Solution for different workloads. In my opinion, one of the key strengths of this solution is that each physical component can be sized to address database requirements. For example, the number of servers might need to be increased, but no additional investment is necessary on XtremIO X2, thus, saving the business money.
If I were to address just one other topic, I would pick the space savings achieved with a 1 TB SQL Server database. In figure 4, test results show a 3.52-to-1 data reduction ratio, which translates to a 71.5 percent space savings for a 1 TB database on the XtremIO X2 array. Always-on inline data reduction saves space by writing only unique blocks and then compressing those blocks to storage. The value of inline data reduction is the resulting ability to consolidate more databases to the XtremIO X2 array.
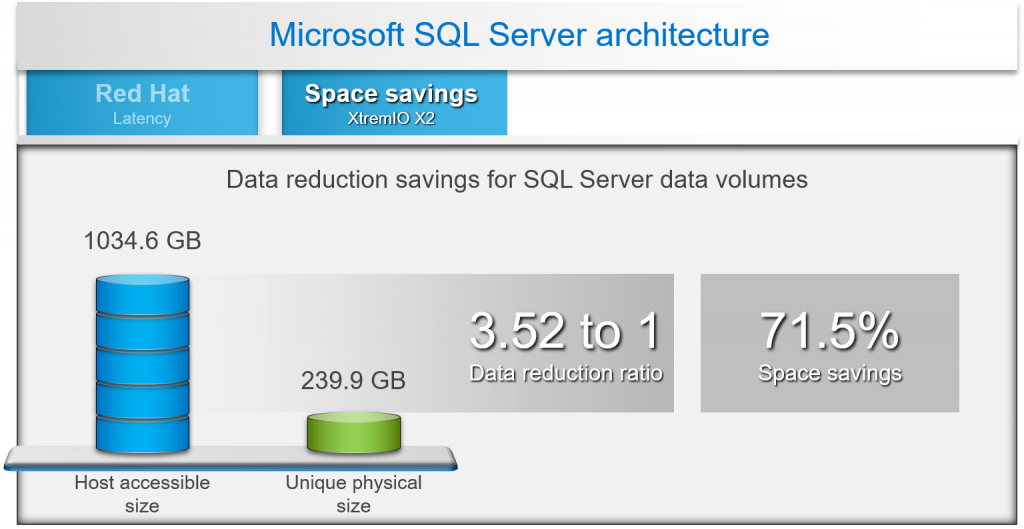
Figure 4: XtremIO X2 inline data reduction
Are you interested in learning how SQL Server performed on Windows Server Datacenter edition and Red Hat Enterprise Linux Server? I recommend reading the design guide for Dell EMC XtremIO X2 with PowerEdge R840 servers. The validation and use case section of that guide takes the reader through all the performance findings. Or schedule a meeting with your local Microsoft expert at Dell EMC to explore the solution.
Why Ready Solutions for Microsoft SQL?
The Ready Solutions for Microsoft SQL Server team at Dell EMC is a group of SQL Server experts who are passionate about building database solutions. All of our solutions are fully integrated, validated, and tested. Figure 5 shows how we approach developing database solutions. Many of us have been on the customer or consulting side of the business, and these priorities reflect our passion to develop specialized database solutions that are faster and more reliable.
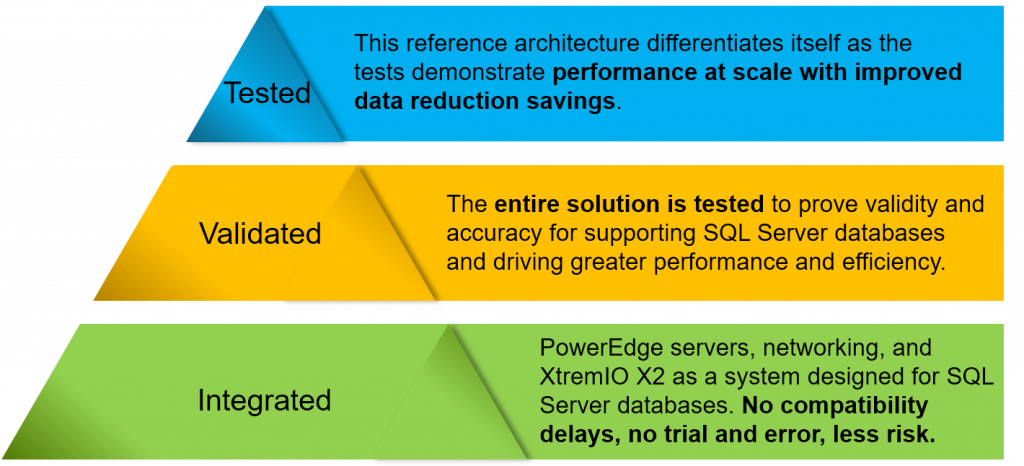
Figure 5: Our database solutions development approach
I hope you enjoyed this blog. If you have any questions, please contact me.
Additional Resources:
- Microsoft SQL Server Info Hub—A list of recent Dell EMC solutions for SQL Server
- Dell EMC Ready Solutions for Microsoft SQL—A good resource for all Dell EMC solutions for SQL Server

Time to Rethink your SQL Backup Strategy – Part 2

Wed, 10 May 2023 15:17:38 -0000
|Read Time: 0 minutes
A while back, I wrote a blog about changes to backup/restore functionality in SQL Server 2022: SQL Server 2022 – Time to Rethink your Backup and Recovery Strategy. Now, more exciting features are here in PowerStoreOS 3.5 that provide additional options and enhanced flexibility for protecting, migrating, and recovering SQL Server workloads on PowerStore.
Secure your snapshots
Backup copies provide zero value if they have been compromised when you need them the most. Snapshot removal could happen accidentally or intentionally as part of a malicious attack. PowerStoreOS 3.5 introduces a new feature, secure snapshot, to ensure that snapshots can't be deleted prior to their expiration date. This feature is a simple checkbox on a snapshot or protection policy that protects snapshots until they expire and can't be turned off. This ensures that your critical data will be available when you need it. Secure snapshot can be enabled on new or existing snapshots. Here’s an example of the secure snapshot option on an existing snapshot.
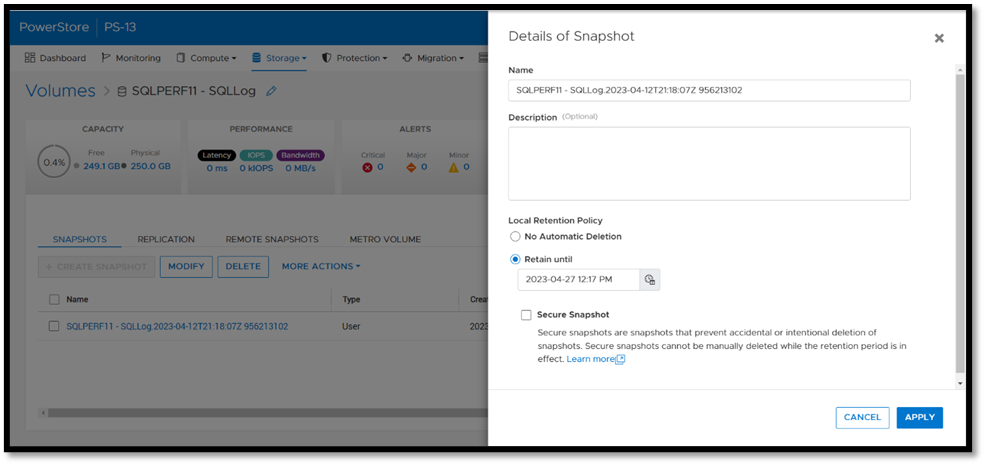
Once this option is selected, a warning is displayed stating that the snapshot can’t be deleted until the retention period expires. To make the snapshot secure, ensure that the Secure Snapshot checkbox is selected and click Apply.
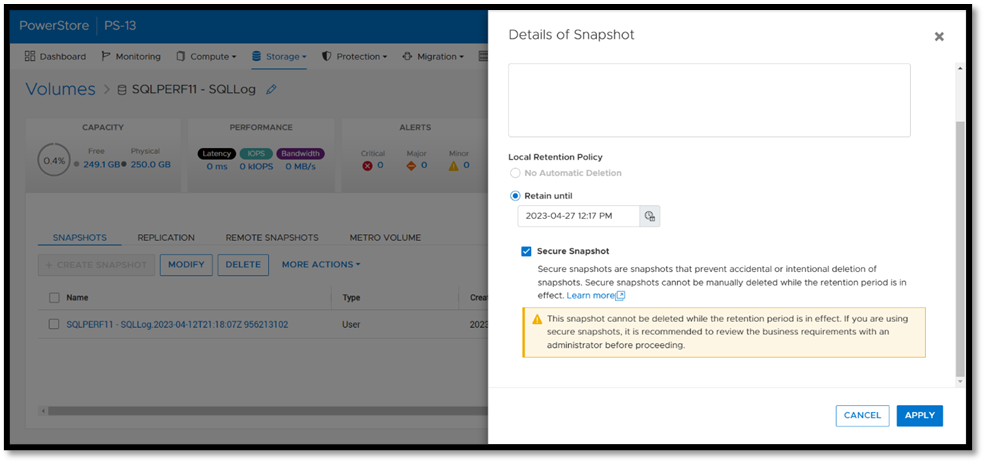
Secure snapshot can be applied to individual snapshots of volumes or volume groups. The secure snapshot option can also be enabled on one or more snapshot rules in a protection policy to ensure that snapshots taken as part of the protection policy have secure snapshot applied.
Since existing snapshots can be marked as secure, this option can be used on snapshots taken outside of PowerStore Manager or even snapshots taken with other utilities such as AppSync. Consider enabling this option on your critical snapshots to ensure that they are available when you need them!
There's no such thing as too many backups!
If you're responsible for managing and protecting SQL Server databases, you quickly learn that it's valuable to have many different backups and in various formats, for various reasons. It could be for disaster recovery, migration, reporting, troubleshooting, resetting dev/test environments, or any combination of these. Perhaps you’re trying to mitigate the risk of failure of a single platform, method, or tool. Each scenario and workflow has different requirements. PowerStoreOS 3.5 introduces direct integration with Dell PowerProtect DD series appliances, including PowerProtect DDVE which is the virtual edition for both on-premises and cloud deployments. This provides an agentless way to take crash consistent, off-array backups directly from PowerStore and send them to PowerProtect DD.
To enable PowerStore remote backup, you need to connect the PowerProtect DD appliance to your PowerStore system as a remote system.
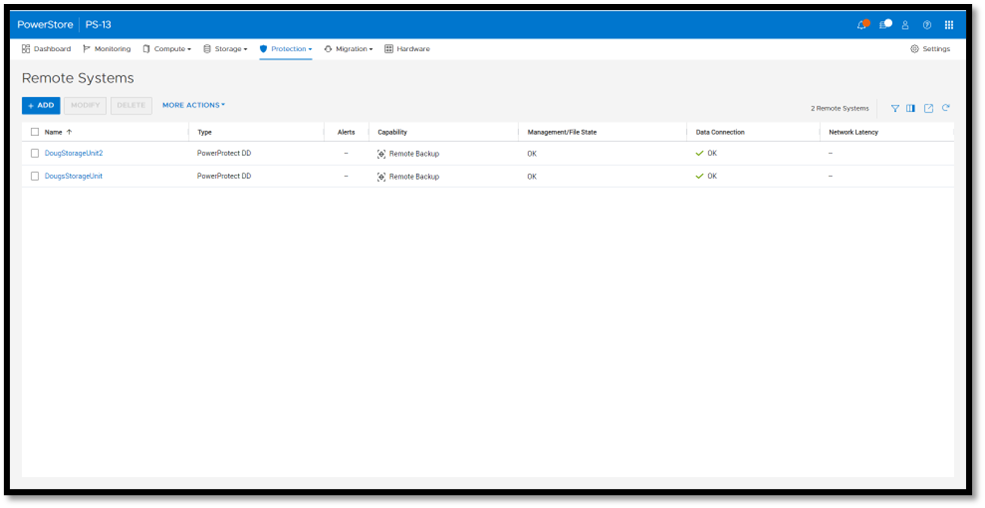
Next, you add a remote backup rule to a new or existing protection policy for the volume or volume group you want to protect, providing the destination, schedule, and retention.
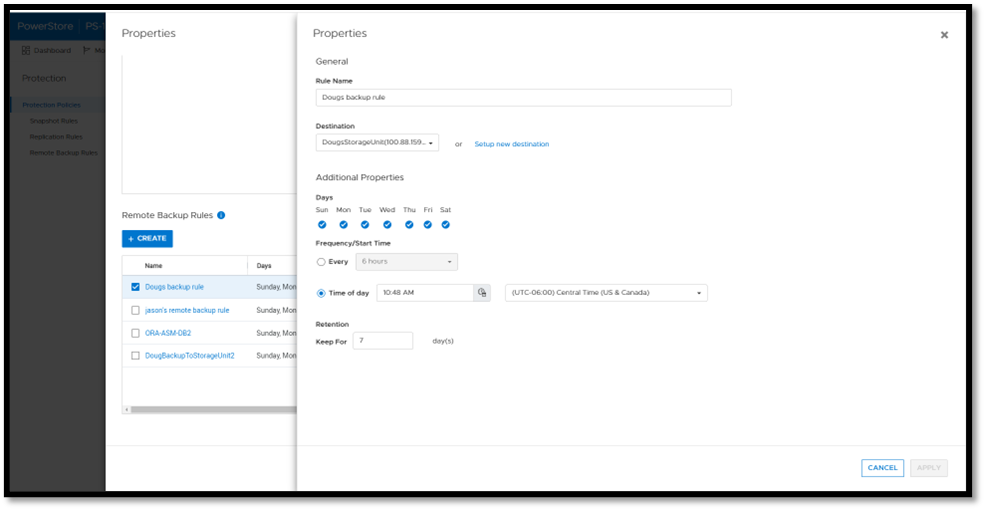
Once a protection policy is created with remote backup rules and assigned to a PowerStore volume or volume group, a backup session will appear.
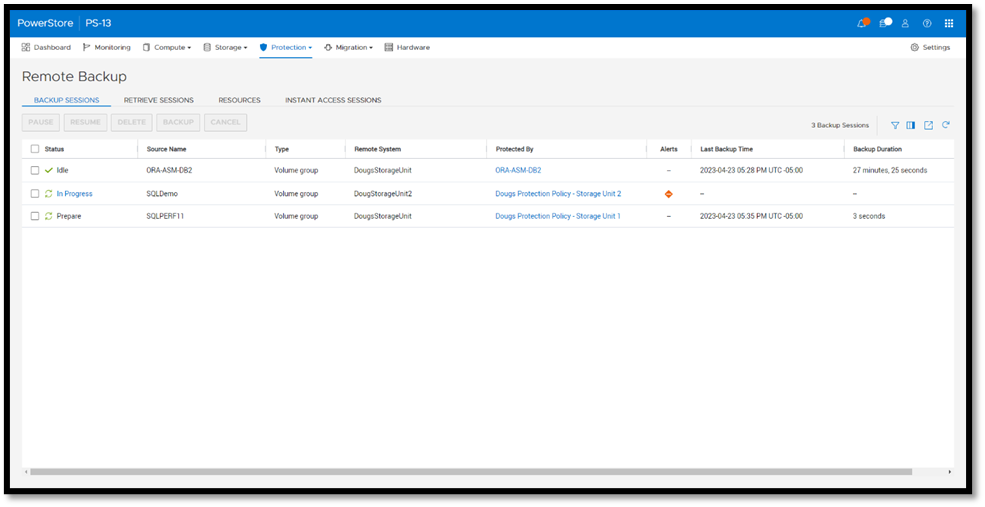
Under Backup Sessions, you can see the status of all the sessions or select one to back up immediately, and click Backup.
Once a remote backup is taken, it will appear under the Volume or Volume Group Protection tab as a remote snapshot.
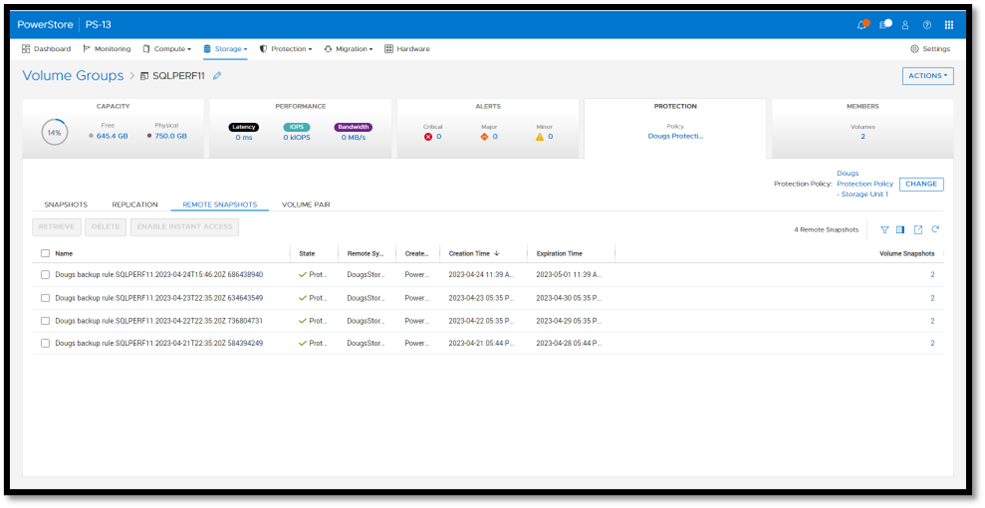
From here, you can retrieve it and work with it as a normal snapshot on PowerStore or enable Instant Access whereby the contents can be accessed by a host directly from PowerProtect DD. You can even retrieve remote snapshots from other PowerStore clusters!
This is yet another powerful tool included with PowerStoreOS 3.5 to enhance data protection and data mobility workflows.
For more information on this feature and other new PowerStore features and capabilities, be sure to check out all the latest information on the Dell PowerStore InfoHub page.
Author: Doug Bernhardt
Sr. Principal Engineering Technologist
https://www.linkedin.com/in/doug-bernhardt-data/