




SQL Server deployments–Have you tried this?
Tue, 27 Sep 2022 19:11:24 -0000
|Read Time: 0 minutes
SQL Server databases are critical components of most business operations and initiatives. As these systems become more intelligent and complex, maintaining optimal SQL Server database performance and uptime can pose significant challenges to IT—and often have severe implications for the business.
What is SQL Server best practice?
Best practices for SQL Server database solution provide a comprehensive set of recommendations for both the physical infrastructure and the software stack. This set of recommendations is derived from many testing hours and expertise from the Dell Server team, Dell Storage team, and the Dell Solutions and Engineering SQL Server specialists.
Why use SQL Server best practice?
Business-critical applications require an optimized infrastructure to run smoothly and efficiently. An optimized infrastructure allows applications to run smoothly and prevents performance risks, such as system sluggishness that could affect system resources and application response time. Such unexpected outcomes can often result in revenue loss, customer dissatisfaction, and damage to brand reputation.
The mission around best practices
Dell’s mission is to ensure that its customers have a robust and high-performance database infrastructure solution by providing best practices for SQL Server 2019 running on PowerEdge R750xs servers and PowerStore T model storage including the new PowerStore 3.0. These best practices aim to offer time savings for our customers by reducing the complex work required to optimize their databases. To enhance the value of best practices, we identify which configuration changes produce the greatest results and categorize them as follows:
Day 1 through Day 3: Most enterprises implement changes based on the delivery cycle:
- Day 1: Indicates configuration changes that are part of provisioning a database. The business has defined these best practices as an essential part of delivering a database.
- Day 2: Indicates configuration changes that are applied after the database has been delivered to the customer. These best practices address optimization steps to further improve system performance.
- Day 3: Indicates configuration changes that provide small incremental improvements in the database performance.
Highly, moderately, and fine-tuning recommendations: Customers want to understand the impact of the best practices and these terms are used to indicate the value of each best practice.
- Highly recommended: Indicates best practices that provided the greatest performance in our tests.
- Moderately recommended: Indicates best practices that provide modest performance improvements, but which are not as substantial as the highly recommended best practices.
- Fine-tuning: Indicates best practices that provide small incremental improvements in database performance.
Best practices test methodology for Intel-based PowerEdge and PowerStore deployments
Within each layer of the infrastructure, the team sequentially tested each component and documented the results. For example, within the storage layer, the goal was to show how optimizing the number of volumes for SQL User DB Data area volumes improve performance of a SQL Server database.
The expectation was that performance would sequentially improve. Using this methodology, an overall optimal SQL Server database solution would be achieved during the last test.
The physical architecture consists of:
- 2 x PowerEdge R750xs servers
- 1 x PowerStore T model array
Table 1 and Table 2 show the server configuration and the PowerStore T model configuration.
Table 1. Server configuration
Processors | 2 x Intel® Xeon® Gold 6338 32 core CPU @2.00GHz |
Memory | 16 x 64 GB 3200MT/s memory, total of 1 TB |
Network Adapters | Embedded NIC: 1 x Broadcom BCM5720 1 GbE DP Ethernet Integrated NIC1: 1 x Broadcom Adv. Dual port 25 Gb Ethernet NIC slot 5: 1 x Mellanox ConnectX-5-EN 25 GbE Dual port |
HBA | 2 x Emulex LP35002 32 Gb Dual Port Fibre Channel |
Table 2. PowerStore 5000T configuration details
Processors | 2 x Intel® Xeon® Gold 6130 CPU @ 2.10 GHz per Node
|
Cache size | 4 x 8.5 GB NVMe NVRAM |
Drives | 21 x 1.92 TB NVMe SSD |
Total usable capacity | 28.3 TB |
Front-end I/O modules | 2 x Four-Port 32 Gb FC |
The software layer consists of:
- VMware ESXi 7.0.3
- Red Hat Enterprise Linux 8.5
- SQL Server 2019 CU 16-15.0.4223.1
There are several combinations possible for the software architecture. For this testing, SQL Server 2019, Red Hat Enterprise Linux 8.5, and VMware vSphere 7.0.3 were selected to have a design that applies to many database customers use today.
Benchmark tool
HammerDB is a leading benchmarking tool that is used with databases like Oracle, MySQL, Microsoft SQL Server, and others. Dell’s engineering team used HammerDB to generate an Online Transaction Processing (OLTP) workload to simulate enterprise applications. To compare the benchmark results between the baseline configuration and the best practice configuration, there must be a significant load on the SQL Server Database infrastructure to ensure that the system was sufficiently taxed. This method of testing guarantees that the infrastructure resources are optimized after applying best practices. Table 3 shows the HammerDB workload configuration.
Table 3. HammerDB workload configuration
Setting name | Value |
Total transactions per user | 1,000,000 |
Number of warehouses | 5,000 |
Number of virtual users | 80 |
Minutes of ramp up time | 10 |
Minutes of test duration | 50 |
Use all warehouses | Yes |
User delay (ms) | 500 |
Repeat delay (ms) | 500 |
Iterations | 1 |
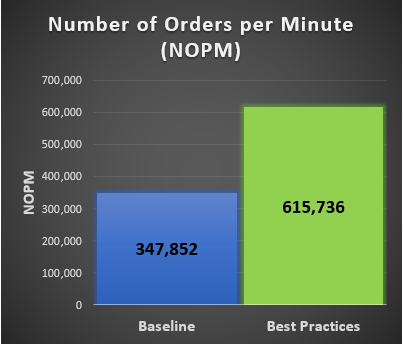
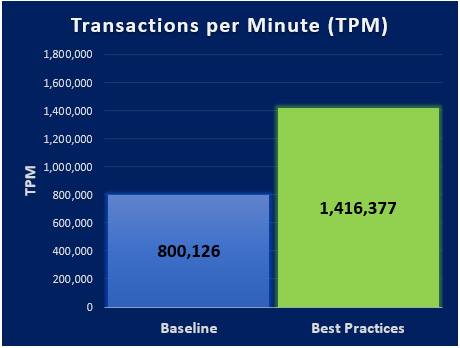
New Order per Minute (NOPM) and Transaction per Minute (TPM) provide metrics to interpret the HammerDB results. These metrics are from the TPC-C benchmark and indicate the result of a test. During our best practice validation, we compared those metrics against the baseline configuration to ensure that there was an increase in performance.
Findings
After performing various test cases between the baseline configuration and the best practice configuration, our results showed an improvement over the baseline configuration. The following graphs are derived from the database virtual machines configuration in the following table.
Note: Every database workload and system is different, which means actual results of these best practices may vary from system to system.
Table 4. vCPU and memory allocation
Resource Reservation | Baseline configuration per virtual machine | Number of SQL Server database virtual machines | Total |
vCPU | 10 cores | 6 | 60 cores |
Memory | 112 GB | 6 | 672 GB |
Related Blog Posts

When Performance Testing Your Storage, Avoid Zeros!

Tue, 20 Feb 2024 17:37:42 -0000
|Read Time: 0 minutes
Storage benchmarking
Occasionally, Dell Technologies customers will want to run their own storage performance tests to ensure that their storage can meet the demands of their workload. Dell Technologies partners like Microsoft publish guidance on how to use benchmarking tools such as Diskspd to test various workloads. When running these tools on intelligent storage appliances like those offered by Dell Technologies, don’t forget to watch for how your test files are populated!
The first step in using performance benchmark tools is creating one or more test files for use when testing. The benchmark tool will then write and read data to and from these files, taking measurements to assess performance. An important detail that is often overlooked is how the test files are populated with data. If the files are not populated correctly, it can lead to misleading results and inaccurate conclusions.
We’ll use Diskspd as an example, however please note that most tools have the same default behavior. By default, when you run a Diskspd test, you need to specify several parameters, such as a test file location and size, IO block size, read/write ratio, queue depth, and so on.
If we open a test file created with default parameters and examine it with a hexadecimal editor, this is what it looks like:
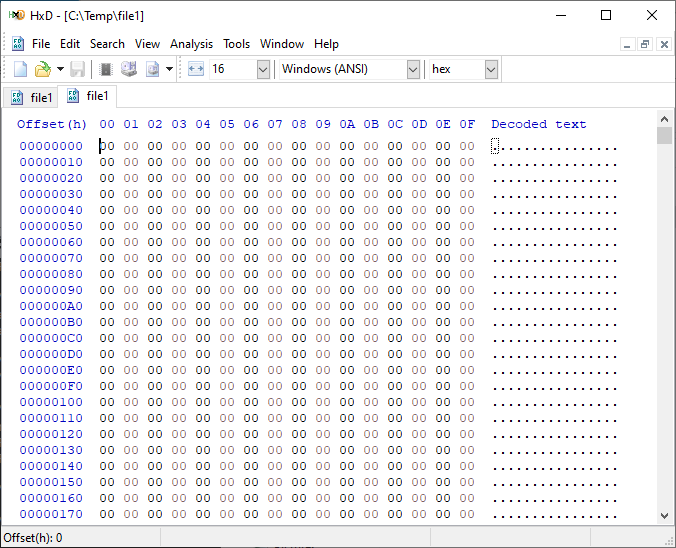
It is filled with nothing, 0x00 throughout the entire file – all “zeros”!
OK, so what is the problem?
When storage benchmarking tools create test files, they all use synthetic data for testing. This is fine when performing IO to a storage device with no “intelligence” built in because it will perform unaltered IO directly to the storage without the data content mattering. In the past, storage devices were simple and would read and write data as commanded, so the data content was irrelevant.
However, intelligent storage appliances such as those offered by Dell Technologies look at data differently. These products are built for efficiency and performance. Compression, deduplication, zero detection, and other optimizations may be used for space savings and performance. Since an empty file would obviously compress and deduplicate well, most of this IO will not access the disks in the same manner that a file of actual data would. It is also possible that other components in the data path would behave differently than normal when repeatedly presented with an identical piece of data.
It is safe to assume that these optimizations likely exist on data being stored in the cloud as well. Many cloud providers use intelligent storage appliances or have developed proprietary software to optimize storage.
The bottom line is that your test is likely inaccurate and may not represent your storage performance under more realistic conditions. While no synthetic test can reproduce a real workload 100%, you should try to make it as realistic as possible.
Mitigations
Some tools can initialize the test files with random data. Diskspd, for example, has parameters that can be added to create a buffer of random data to be used to write to the files or specify a source file of data. Regardless of the method used, you should inspect the test files to make sure that at a minimum, random data is being used. Zero-filled files and repeating patterns should be avoided.
Random data also may not achieve the expected behavior when compression and deduplication capabilities are used. More advanced testing tools such as vdbench can use target compression and deduplication capabilities independently.
Tips
Here are a few more tips when benchmarking storage performance to try to make it as realistic as possible:
- Use datasets of comparable size to real data workloads. Smaller datasets may fit entirely in the cache and skew results.
- Use IO sizes and read/write ratios that match your workload. If you are unsure of what your workload looks like, your Dell Technologies representative can assist you.
- Test with “multiples”. Intelligent storage assumes multiple files, volumes, and hosts. At a minimum, use multiple files and volumes. When testing larger block sizes, you may need to use multiple hosts and multiple host bus adapters to generate enough IO to test the full bandwidth capabilities of the storage.
- Start with a light load and scale up. Begin with one file, one worker thread, and a queue depth of one. In general, modern storage is designed for concurrency. Some amount of concurrency will be required to fully use storage system resources. As you scale up, observe the behavior. Pay attention to the measured latency. At some point as you scale the test, latency will start to increase rapidly.
- Excessive latency indicates a bottleneck. Once latencies are excessive, you have encountered a bottleneck somewhere. “Excessive” is a relative term when it comes to storage latency and is determined by your workload and business needs. Only scale the test to the point where the measured latency is within your acceptable range or above. Further increasing the test load will result in diminishing returns.
- Make sure the entire test environment can drive the wanted performance. The storage network and host configuration must be capable of desired performance levels and configured properly.
- Beware of outdated guidance. There are still articles online that are over a decade old that reference testing methods and best practices that were developed when storage was based on spinning disks. Those assumptions may be inaccurate on the latest storage devices and storage network protocols.
Summary
Storage performance benchmarking can be interesting and provide useful data points. That said, what is most important is how the storage supports actual business workloads and—most importantly—your unique workload. As such, there is no true substitute for testing with your actual workload.
Selecting the proper storage fit for your environment can be challenging, and Dell Technologies has the expertise to help. Leveraging tools like CloudIQ and LiveOptics, Dell Technologies can help you analyze your storage performance, explain storage metrics, and make recommendations to increase storage efficiency.
Author: Doug Bernhardt, Sr. Principal Engineering Technologist | LinkedIn

PowerStore validation with Microsoft Azure Arc-enabled data services updated to 1.25.0
Mon, 12 Feb 2024 20:04:34 -0000
|Read Time: 0 minutes
Microsoft Azure Arc-enabled data services allow you to run Azure data services on-premises, at the edge, or in the cloud. Arc-enabled data services align with Dell Technologies’ vision, by allowing you to run traditional SQL Server workloads on Kubernetes, on your infrastructure of choice. For details about a solution offering that combines PowerStore and Microsoft Azure Arc-enabled data services, see the white paper Dell PowerStore with Azure Arc-enabled Data Services.
Dell Technologies works closely with partners such as Microsoft to ensure the best possible customer experience. We are happy to announce that Dell PowerStore has been revalidated with the latest version of Azure Arc-enabled data services, 1.25.0.
Deploy with confidence
One of the deployment requirements for Azure Arc-enabled data services is that you must deploy on one of the validated solutions. At Dell Technologies, we understand that customers want to deploy solutions that have been fully vetted and tested. Key partners such as Microsoft understand this too, which is why they have created a validation program to ensure that the complete solution will work as intended.
By working through this process with Microsoft, Dell Technologies can confidently say that we have deployed and tested a full end-to-end solution and validated that it passes all tests.
The validation process
Microsoft haspublished tests for their continuous integration/continuous delivery (CI/CD) pipeline that partners and customers to run. For Microsoft to support an Arc-enabled data services solution, it must pass these tests. At a high level, these tests perform the following:
- Connect to an Azure subscription provided by Microsoft.
- Deploy the components for Arc-enabled data services, including SQL Managed Instance, using both direct and indirect connect modes.
- Validate Kubernetes (K8s), hosts, storage, container storage interface (CSI), and networking.
- Run Sonobuoy tests ranging from simple smoke tests to complex high-availability scenarios and chaos tests.
- Upload results to Microsoft for analysis.
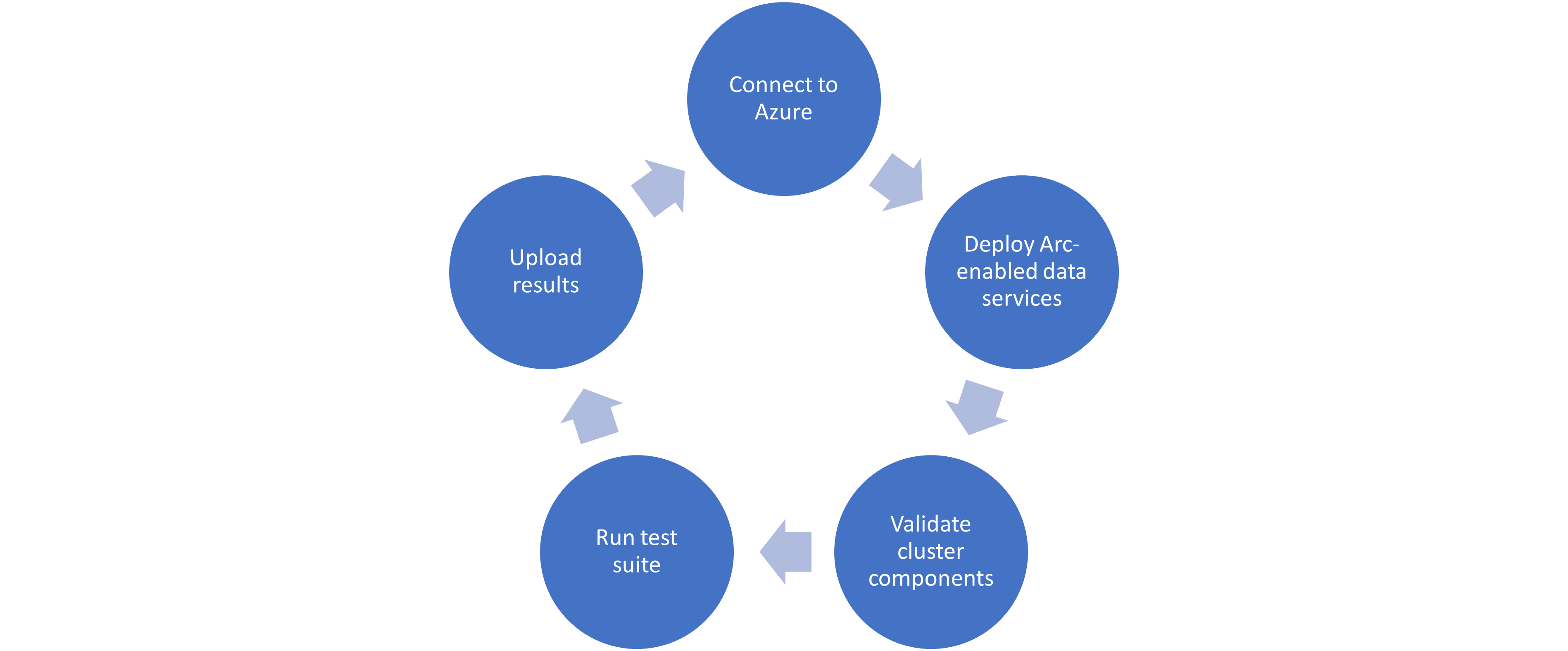
When Microsoft accepts the results, they add the new or updated solution to their list of validated solutions. At that point, the solution is officially supported. This process is repeated as needed as new component versions are introduced. Complete details about the validation testing and links to the GitHub repositories are available here.
More to come
Stay tuned for more additions and updates from Dell Technologies to the list of validated solutions for Azure Arc-enabled data services. Dell Technologies is leading the way on hybrid solutions, proven by our work with partners such as Microsoft on these validation efforts. Reach out to your Dell Technologies representative for more information about these solutions and validations.
Author: Doug Bernhardt
Sr. Principal Engineering Technologist