




Reference Architecture: Acceleration over PCIe for Dell EMC PowerEdge MX7000

Summary
Many of today's demanding applications require GPU resources. Our reference architecture incorporates GPUs to the PowerEdge MX infrastructure, utilizing the PowerEdge MX Scalable Fabric, Dell EMC DSS 8440 GPU Server, and Liqid Command Center Software. Request a remote demo of this reference architecture or a quote from Dell Technologies Design Solutions Experts at the Design Solutions Portal.
Background
The Dell EMC PowerEdge MX7000 Modular Chassis simplifies the deployment and management of today’s most challenging workloads by allowing IT administrators to dynamically assign, move and scale shared pools of compute, storage and networking resources. It provides IT administrators the ability to deliver fast results, eliminating managing and reconfiguring infrastructure to meet ever-changing needs of their end users. The addition of PCIe infrastructure to this managed pool of resources using Liqid technology designed on Dell EMC MX7000 expands the promise of software-defined composability for today’s AI-driven compute environments and high-value applications.
GPU Acceleration for PowerEdge MX7000
For workloads like AI that require parallel accelerated computing, the addition of GPU acceleration within the PowerEdge MX7000 is paramount. With Liqid technology and management software, GPUs of any form factor can be quickly added to any new or existing MX compute sled via the management interface, quickly delivering the resources needed to manage each step of the machine learning workflow including data ingest, cleansing, training, and inferencing. Spin-up new bare-metal servers with the exact number of accelerators required and then dynamically add or remove them as workload needs change.
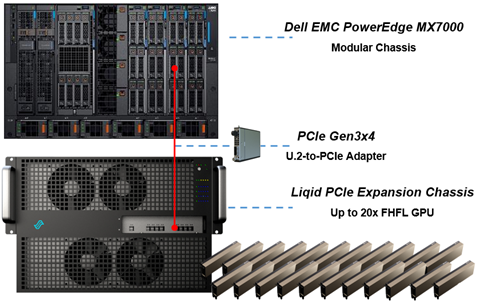 Figure 1 Essential PowerEdge Expansion Components
Figure 1 Essential PowerEdge Expansion Components
GPU Expansion Over PCIe | |
Compute Sleds | Up to 8 x Compute Sleds per Chassis |
GPU Chassis | PCIe Expansion Chassis |
Interconnect | PCIe Gen3x4 Per Compute Sled |
GPU Expansion | 20x GPU (FHFL) |
GPU Supported | V100, A100, RTX, T4, Others |
OS Supported | Linux, Windows, VMWare and Others |
Devices Supported | GPU, FPGA, and NVMe Storage |
Form Factor | 14U Total = MX7000 (7U) + PCIe Expansion Chassis (7U) |
 Figure 2
Figure 2
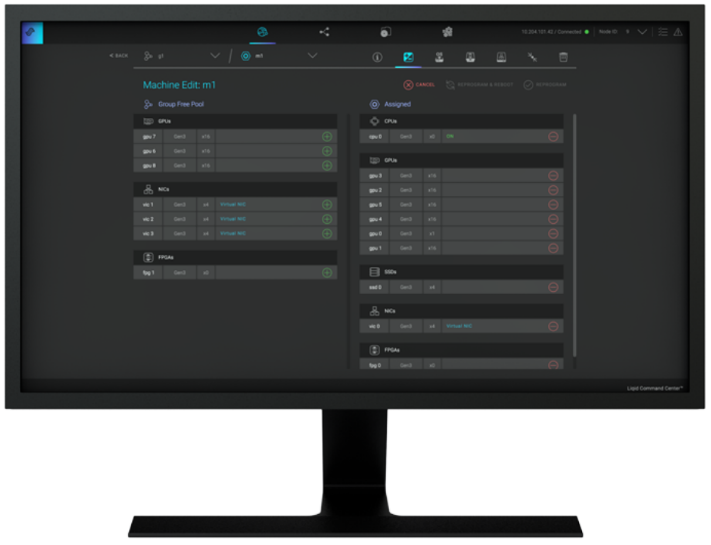 Figure 3 Liqid Command Center
Figure 3 Liqid Command Center
Implementing GPU Expansion for MX
Figure 3 Liqid Command Center
GPUs are installed into the PCIe expansion chassis. Next, U.2 to four PCIe Gen3 adapters are added to each compute sled that requires GPU acceleration, and then they are connected to the expansion chassis (Figure 1). Liqid Command Center software enables discovery of all GPUs, making them ready to be added to the server over native PCIe. FPGA and NVMe storage can also be added to compute nodes in tandem. This PCIe expansion chassis & software are available from the Dell Design Solutions team.
Software Defined Composability
Once PCIe devices are connected to the MX7000, Liqid Command Center software enables the dynamic allocation of GPUs to MX compute sleds at the bare metal. Any amount of resources can be added to the compute sleds, via Liqid Command Center (GUI) or RESTful API, in any ratio (GPU hot-plug supported). To the operating system, the GPUs are presented as local resources direct connected to the MX compute sled over PCIe (Figure 3). All operating systems are supported including Linux, Windows, and VMware. As workload needs change, add or remove resources on the fly, via software including NVMe SSD and FPGA (Table 1).
Enabling GPU Peer-2-Peer Capability
A key feature included with the PCIe expansion solution for PowerEdge MX7000 is the ability for RDMA Peer-2-Peer between GPU devices. Direct RDMA transfers have a massive impact on both throughput and latency for the highest performing GPU-centric applications. Up to 10x improvement in performance has been achieved with RDMA Peer-2-Peer enabled. Below is the overview of how PCIe Peer-2-Peer functions (Figure 4).
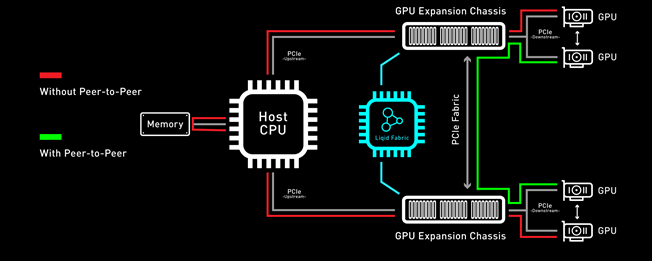 Figure 4 PCIe Peer-2-Peer
Figure 4 PCIe Peer-2-Peer
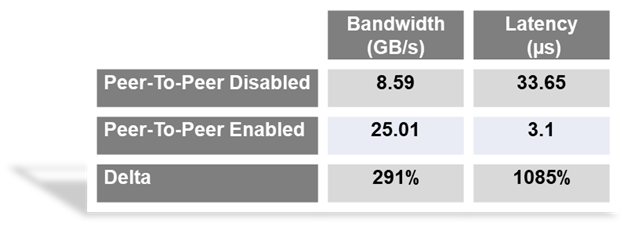
Bypassing the x86 processor and enabling direct RDMA communication between GPUs, realizes a dramatic improvement in bandwidth and in addition a reduction in latency is also realized. This chart outlines the performance expected for GPUs that are composed to a single node with GPU RDMA Peer-2-Peer enabled (Table 2).
Application Level Performance
RDMA Peer-2-Peer is a key feature in GPU scaling for Artificial Intelligence, specifically machine learning based applications. Figure 5 outlines performance data measured on mainstream AI/ML applications on the MX7000 with GPU expansion over PCIe. It further demonstrates the performance scaling from 1-GPU to 8-GPU for a single MX740c compute sled. High scaling efficiency is observed for ResNet152, VGG16, Inception V3, and ResNet50 on MX7000 with composable PCIe GPUs measured with Peer-2-Peer enabled. These results indicate a near-linear growth pattern. and with the current capabilities of the Liqid PCIe 7U expansion sled one can allocate up to 20 GPUs to an application running on a single node.
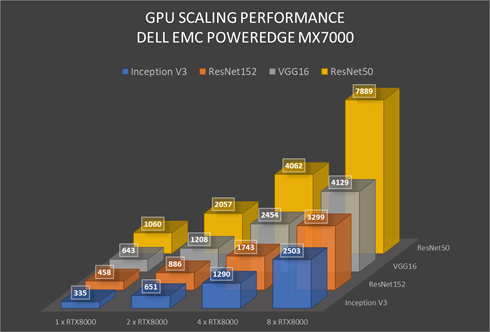 Figure 5 GPU Performance Scaling Comparison: MX7000 Leverages RTX8000 in PCIe expansion chassis measured with P2P Enabled
Figure 5 GPU Performance Scaling Comparison: MX7000 Leverages RTX8000 in PCIe expansion chassis measured with P2P Enabled
Conclusion
Liqid PCIe expansion for the Dell EMC PowerEdge MX7000 unlocks the ability to manage the most demanding workloads in which accelerators are required for both new and existing deployments. Liqid collaborated with Dell Technologies Design Solutions to accelerate applications by through the addition of GPUs to the Dell EMC MX compute sleds over PCIe.
Learn More | See a Demo | Get a Quote
This reference architecture is available as part of the Dell Technologies Design Solutions.
Related Blog Posts
Unveiling the Power of the PowerEdge XE9680 Server on the GPT-J Model from MLPerf™ Inference
Tue, 16 Jan 2024 18:30:32 -0000
|Read Time: 0 minutes
Abstract
For the first time, the latest release of the MLPerf™ inference v3.1 benchmark includes the GPT-J model to represent large language model (LLM) performance on different systems. As a key player in the MLPerf consortium since version 0.7, Dell Technologies is back with exciting updates about the recent submission for the GPT-J model in MLPerf Inference v3.1. In this blog, we break down what these new numbers mean and present the improvements that Dell Technologies achieved with the Dell PowerEdge XE9680 server.
MLPerf inference v3.1
MLPerf inference is a standardized test for machine learning (ML) systems, allowing users to compare performance across different types of computer hardware. The test helps determine how well models, such as GPT-J, perform on various machines. Previous blogs provide a detailed MLPerf inference introduction. For in-depth details, see Introduction to MLPerf inference v1.0 Performance with Dell Servers. For step-by-step instructions for running the benchmark, see Running the MLPerf inference v1.0 Benchmark on Dell Systems. Inference version v3.1 is the seventh inference submission in which Dell Technologies has participated. The submission shows the latest system performance for different deep learning (DL) tasks and models.
Dell PowerEdge XE9680 server
The PowerEdge XE9680 server is Dell’s latest two-socket, 6U air-cooled rack server that is designed for training and inference for the most demanding ML and DL large models.

Figure 1. Dell PowerEdge XE9680 server
Key system features include:
- Two 4th Gen Intel Xeon Scalable Processors
- Up to 32 DDR5 DIMM slots
- Eight NVIDIA HGX H100 SXM 80 GB GPUs
- Up to 10 PCIe Gen5 slots to support the latest Gen5 PCIe devices and networking, enabling flexible networking design
- Up to eight U.2 SAS4/SATA SSDs (with fPERC12)/ NVMe drives (PSB direct) or up to 16 E3.S NVMe drives (PSB direct)
- A design to train and inference the most demanding ML and DL large models and run compute-intensive HPC workloads
The following figure shows a single NVIDIA H100 SXM GPU:

Figure 2. NVIDIA H100 SXM GPU
GPT-J model for inference
Language models take tokens as input and predict the probability of the next token or tokens. This method is widely used for essay generation, code development, language translation, summarization, and even understanding genetic sequences. The GPT-J model in MLPerf inference v3.1 has 6 B parameters and performs text summarization tasks on the CNN-DailyMail dataset. The model has 28 transformer layers, and a sequence length of 2048 tokens.
Performance updates
The official MLPerf inference v3.1 results for all Dell systems are published on https://mlcommons.org/benchmarks/inference-datacenter/. The PowerEdge XE9680 system ID is ID 3.1-0069.
After submitting the GPT-J model, we applied the latest firmware updates to the PowerEdge XE9680 server. The following figure shows that performance improved as a result:
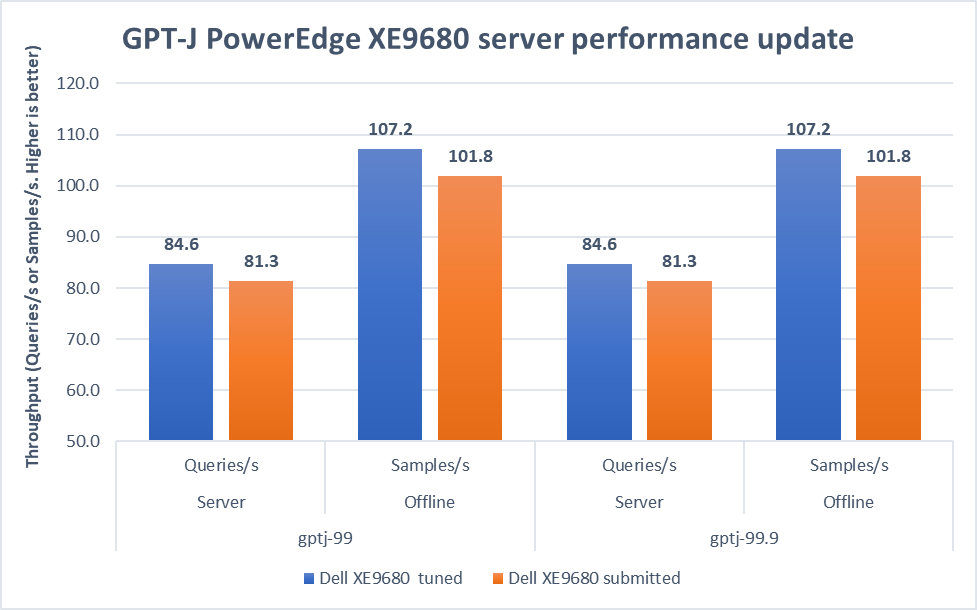
Figure 3. Improvement of the PowerEdge XE9680 server on GPT-J Datacenter 99 and 99.9, Server and Offline scenarios [1]
In both 99 and 99.9 Server scenarios, the performance increased from 81.3 to an impressive 84.6. This 4.1 percent difference showcases the server's capability under randomly fed inquires in the MLPerf-defined latency restriction. In the Offline scenarios, the performance saw a notable 5.3 percent boost from 101.8 to 107.2. These results mean that the server is even more efficient and capable of handling batch-based LLM workloads.
Note: For PowerEdge XE9680 server configuration details, see https://github.com/mlcommons/inference_results_v3.1/blob/main/closed/Dell/systems/XE9680_H100_SXM_80GBx8_TRT.json
Conclusion
This blog focuses on the updates of the GPT-J model in the v3.1 submission, continuing the journey of Dell’s experience with MLPerf inference. We highlighted the improvements made to the PowerEdge XE9680 server, showing Dell's commitment to pushing the limits of ML benchmarks. As technology evolves, Dell Technologies remains a leader, constantly innovating and delivering standout results.
[1] Unverified MLPerf® v3.1 Inference Closed GPT-J. Result not verified by MLCommons Association.
The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.

Can I do that AI thing on Dell PowerFlex?

Thu, 20 Jul 2023 21:08:09 -0000
|Read Time: 0 minutes
The simple answer is Yes, you can do that AI thing with Dell PowerFlex. For those who might have been busy with other things, AI stands for Artificial Intelligence and is based on trained models that allow a computer to “think” in ways machines haven’t been able to do in the past. These trained models (neural networks) are essentially a long set of IF statements (layers) stacked on one another, and each IF has a ‘weight’. Once something has worked through a neural network, the weights provide a probability about the object. So, the AI system can be 95% sure that it’s looking at a bowl of soup or a major sporting event. That, at least, is my overly simplified description of how AI works. The term carries a lot of baggage as it’s been around for more than 70 years, and the definition has changed from time to time. (See The History of Artificial Intelligence.)
Most recently, AI has been made famous by large language models (LLMs) for conversational AI applications like ChatGPT. Though these applications have stoked fears that AI will take over the world and destroy humanity, that has yet to be seen. Computers still can do only what we humans tell them to do, even LLMs, and that means if something goes wrong, we their creators are ultimately to blame. (See ‘Godfather of AI’ leaves Google, warns of tech’s dangers.)
The reality is that most organizations aren’t building world destroying LLMs, they are building systems to ensure that every pizza made in their factory has exactly 12 slices of pepperoni evenly distributed on top of the pizza. Or maybe they are looking at loss prevention, or better traffic light timing, or they just want a better technical support phone menu. All of these are uses for AI and each one is constructed differently (they use different types of neural networks).
We won’t delve into these use cases in this blog because we need to start with the underlying infrastructure that makes all those ideas “AI possibilities.” We are going to start with the infrastructure and what many now consider a basic (by today’s standards) image classifier known as ResNet-50 v1.5. (See ResNet-50: The Basics and a Quick Tutorial.)
That’s also what the PowerFlex Solution Engineering team did in the validated design they recently published. This design details the use of ResNet-50 v1.5 in a VMware vSphere environment using NVIDIA AI Enterprise as part of PowerFlex environment. They started out with the basics of how a virtualized NVIDIA GPU works well in a PowerFlex environment. That’s what we’ll explore in this blog – getting started with AI workloads, and not how you build the next AI supercomputer (though you could do that with PowerFlex as well).
In this validated design, they use the NVIDIA A100 (PCIe) GPU and virtualized it in VMware vSphere as a virtual GPU or vGPU. With the infrastructure in place, they built Linux VMs that will contain the ResNet-50 v1.5 workload and vGPUs. Beyond just working with traditional vGPUs that many may be familiar with, they also worked with NVIDIA’s Multi-Instance GPU (MIG) technology.
NVIDIA’s MIG technology allows administrators to partition a GPU into a maximum of seven GPU instances. Being able to do this provides greater control of GPU resources, ensuring that large and small workloads get the appropriate amount of GPU resources they need without wasting any.
PowerFlex supports a large range of NVIDIA GPUs for workloads, from VDI (Virtual Desktops) to high end virtual compute workloads like AI. You can see this in the following diagram where there are solutions for “space constrained” and “edge” environments, all the way to GPUs used for large inferencing models. In the table below the diagram, you can see which GPUs are supported in each type of PowerFlex node. This provides a tremendous amount of flexibility depending on your workloads.

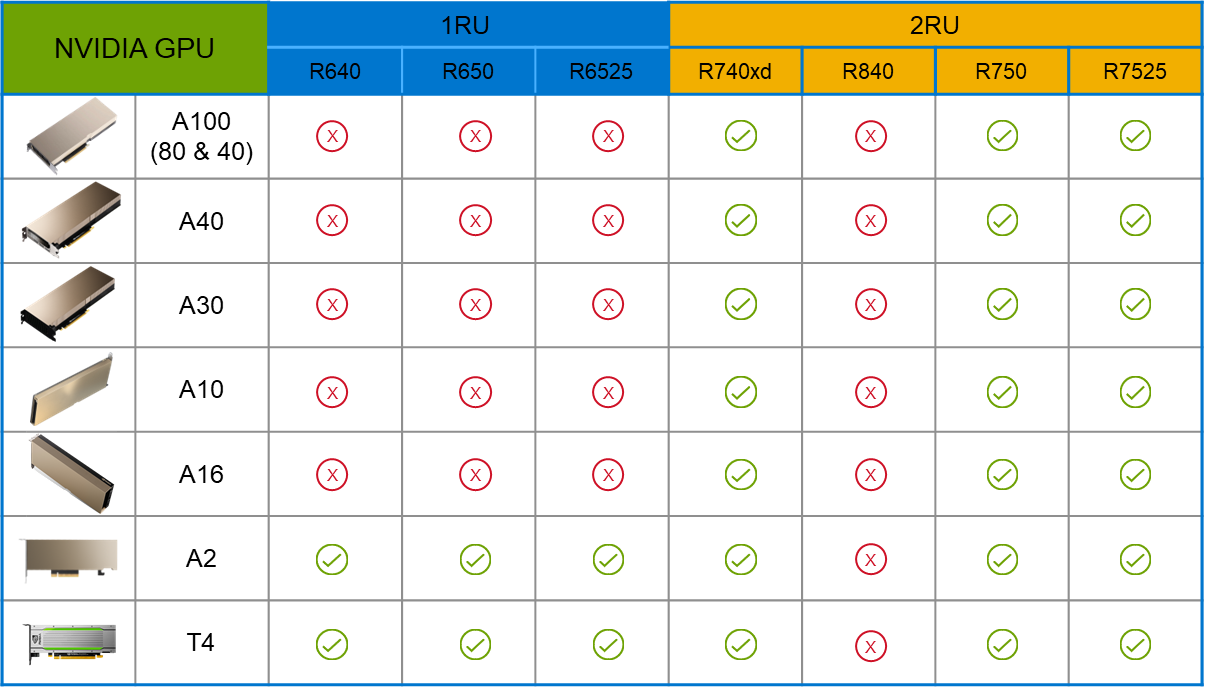
The validated design describes the steps to configure the architecture and provides detailed links to the NVIDIAand VMware documentation for configuring the vGPUs, and the licensing process for NVIDIA AI Enterprise.
These are key steps when building an AI environment. I know from my experience working with various organizations, and from teaching, that many are not used to working with vGPUs in Linux. This is slowly changing in the industry. If you haven’t spent a lot of time working with vGPUs in Linux, be sure to pay attention to the details provided in the guide. It is important and can make a big difference in your performance.
The following diagram shows the validated design’s logical architecture. At the top of the diagram, you can see four Ubuntu 22.04 Linux VMs with the NVIDIA vGPU driver loaded in them. They are running on PowerFlex hosts with VMware ESXi deployed. Each VM contains one NVIDIA A100 GPU configured for MIG operations. This configuration leverages a two-tier architecture where storage is provided by separate PowerFlex software defined storage (SDS) nodes.
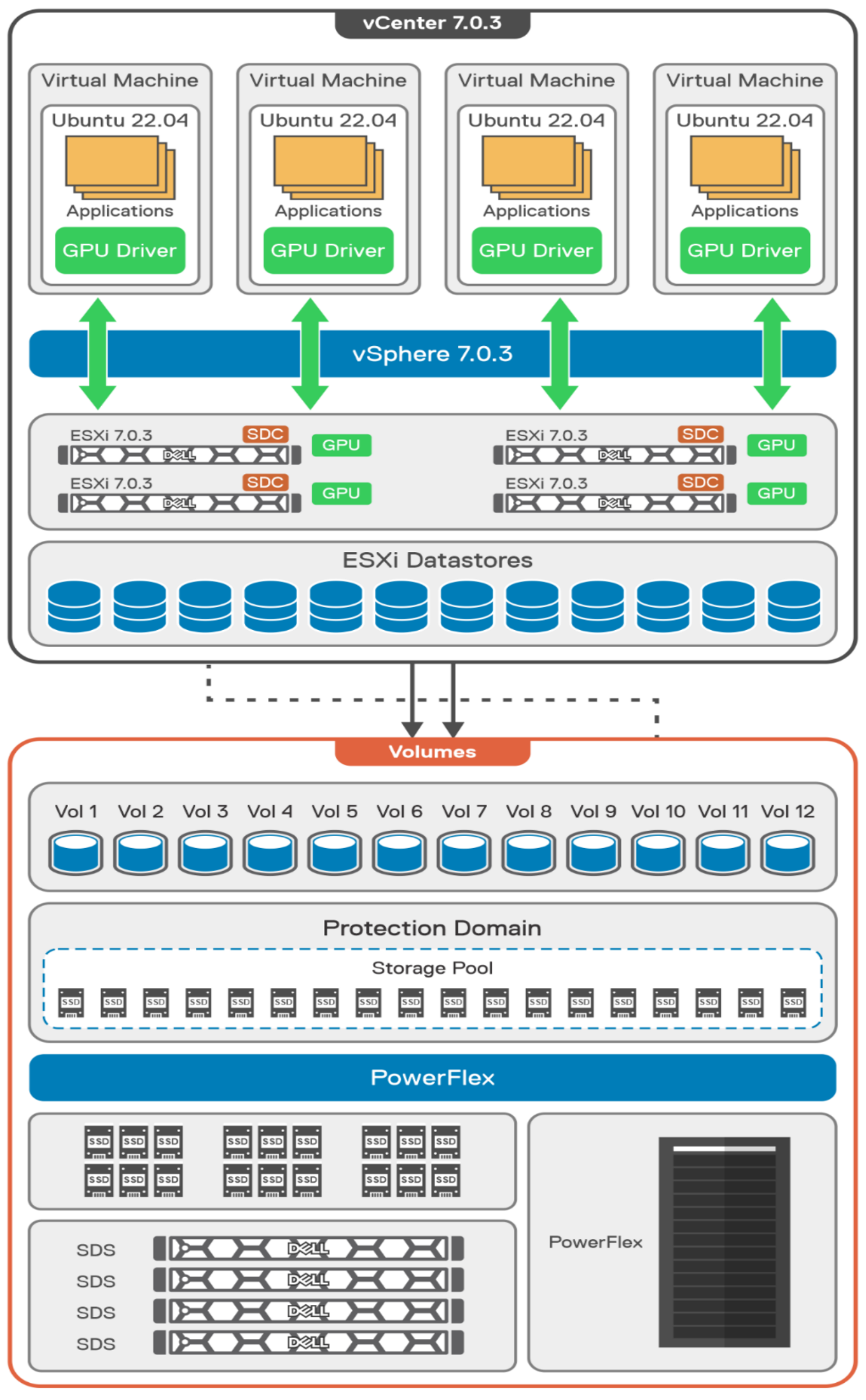
A design like this allows for independent scalability for your workloads. What I mean by this is during the training phase of a model, significant storage may be required for the training data, but once the model clears validation and goes into production, storage requirements may be drastically different. With PowerFlex you have the flexibility to deliver the storage capacity and performance you need at each stage.
This brings us to testing the environment. Again, for this paper, the engineering team validated it using ResNet-50 v1.5 using the ImageNet 1K data set. For this validation they enabled several ResNet-50 v1.5 TensorFlow features. These include Multi-GPU training with Horovod, NVIDIA DALI, and Automatic Mixed Precision (AMP). These help to enable various capabilities in the ResNet-50 v1.5 model that are present in the environment. The paper then describes how to set up and configure ResNet-50 v1.5, the features mentioned above, and details about downloading the ImageNet data.
At this stage they were able to train the ResNet-50 v1.5 deployment. The first iteration of training used the NVIDIA A100-7-40C vGPU profile. They then repeated testing with the A100-4-20C vGPU profile and the A100-3-20C vGPU profile. You might be wondering about the A100-2-10C vGPU profile and the A100-1-5C profile. Although those vGPU profiles are available, they are more suited for inferencing, so they were not tested.
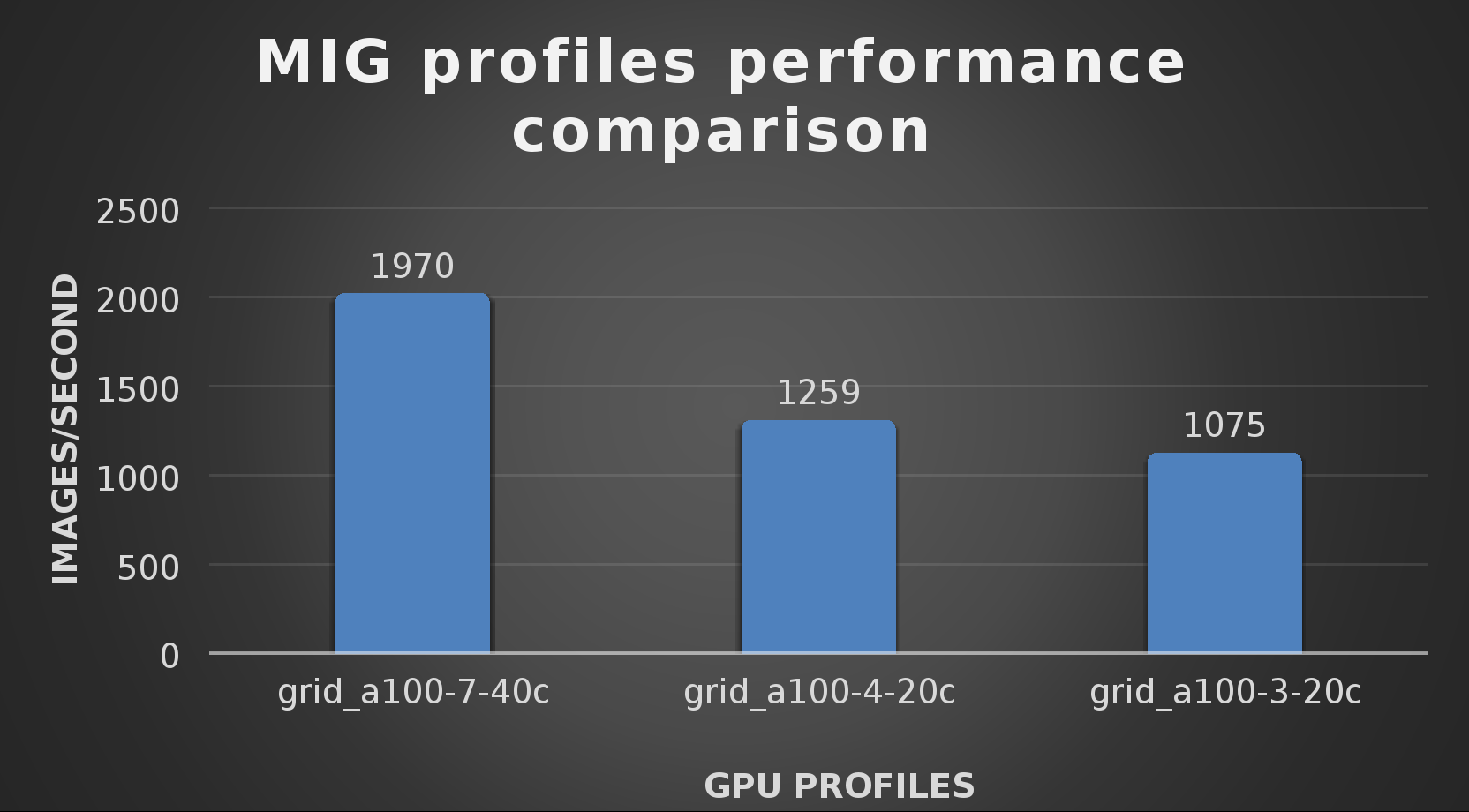
The results from validating the training workloads for each vGPU profile is shown in the following graph. The vGPUs were running near 98% capacity according to nvitop during each test. The CPU utilization was 14% and there was no bottle neck with the storage during the tests.
With the models trained, the guide then looks at how well inference runs on the MIG profiles. The following graph shows inferencing images per second of the various MIG profiles with ResNet-50 v1.5.
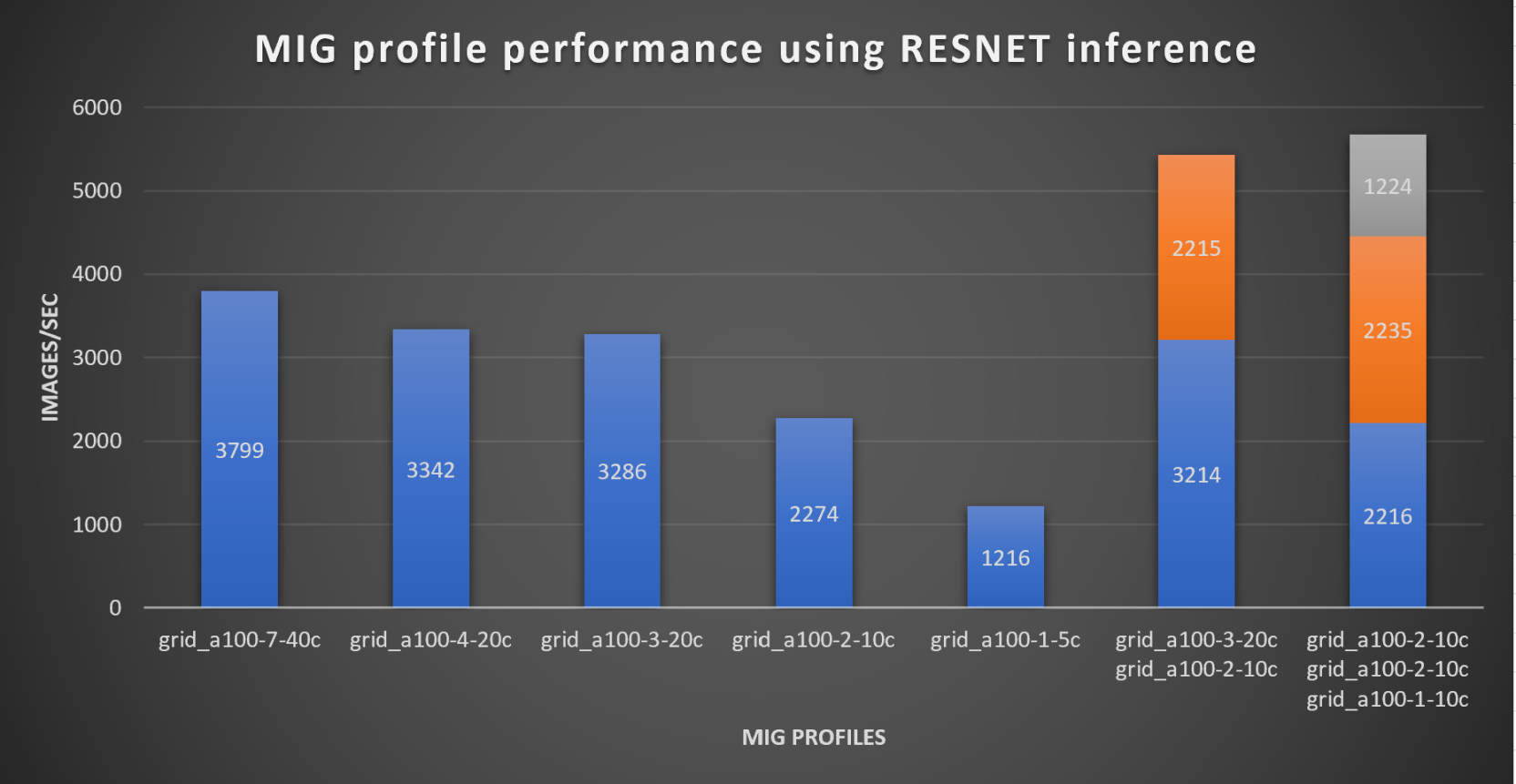
It’s worth noting that the last two columns show the inferencing running across multiple VMs, on the same ESXi host, that are leveraging MIG profiles. This also shows that GPU resources are partitioned with MIG and that resources can be precisely controlled, allowing multiple types of jobs to run on the same GPU without impacting other running jobs.
This opens the opportunity for organizations to align consumption of vGPU resources in virtual environments. Said a different way, it allows IT to provide “show back” of infrastructure usage in the organization. So if a department only needs an inferencing vGPU profile, that’s what they get, no more, no less.
It’s also worth noting that the results from the vGPU utilization were at 88% and CPU utilization was 11% during the inference testing.
These validations show that a Dell PowerFlex environment can support the foundational components of modern-day AI. It also shows the value of NVIDIA’s MIG technology to organizations of all sizes: allowing them to gain operational efficiencies in the data center and enable access to AI.
Which again answers the question of this blog, can I do that AI thing on Dell PowerFlex… Yes you can run that AI thing! If you would like to find out more about how to run your AI thing on PowerFlex, be sure to reach out to your Dell representative.
Resources
- The History of Artificial Intelligence
- ‘Godfather of AI’ leaves Google, warns of tech’s dangers
- ResNet-50: The Basics and a Quick Tutorial
- Dell Validated Design for Virtual GPU with VMware and NVIDIA on PowerFlex
- NVIDIA NGC Catalog ResNet v1.5 for PyTorch
- NVIDIA AI Enterprise
- NVIDIA A100 (PCIe) GPU
- NVIDIA Virtual GPU Software Documentation
- NVIDIA A100-7-40C vGPU profile
- NVIDIA Multi-Instance GPU (MIG)
- NVIDIA Multi-Instance GPU User Guide
- Horovod
- ImageNet
- DALI
- Automatic Mixed Precision (AMP)
- nvitop
Author: Tony Foster
Sr. Principal Technical Marketing Engineer
Twitter: | |
LinkedIn: | |
Personal Blog: | |
Location: | The Land of Oz [-6 GMT] |