




Real-Time Streaming Solutions Beyond Data Ingestion
Thu, 17 Dec 2020 03:05:00 -0000
|Read Time: 0 minutes
So, it has been all about data—data at rest, data in-flight, IoT data, and so forth. Let’s touch base on the traditional data processing approaches and look at their synergy with modern database technologies. Users’ model-based inquiries manifest to a data entity that is created upon initiation of the request payloads. Traditional database and business applications have been the lone actors that collaborated to provide implementations of such data models. They interact in processing of the users’ inquiries and persisting the results in static data stores for further updates. The business continuity is measured by a degree of such activities among business applications consuming data from these shared data stores. Of course, with a lower degree of such activities, there exists a high potential for the business to be at idle states of operations caused by waiting for more data acquisitions.
The above paradigm is inherently set to potentially miss a great opportunity to maintain a higher degree of business continuity. To fill these gaps, a shift in the static data store paradigm is necessary. The new massive ingested data processing requirements mandate the implementation of processing models that continuously generate insight from any “data in-flight,” mostly in real time. To overcome storage access performance bottlenecks, persisting the interim computed results in a permanent data store is expected to be kept at a minimal level.
This blog addresses these modern data processing models from a real-time streaming ingestion and processing perspective. In addition, it discusses Dell Technologies’ offerings of such models in detail.
Customers have an option of building their own solutions based on the open source projects for adopting real-time streaming analytics technologies. The mix and match of such components to implement real-time data ingestion and processing infrastructures is cumbersome. It requires a variety of costly skills to stabilize such infrastructures in production environments. Dell Technologies offers validated reference architectures to meet target KPIs on storage and compute capacities to simplify these implementations. The following sections provide high-level information about real-time data streaming and popular platforms to implement these solutions. This blog focuses particularly on two Ready Architecture solutions from Dell—Streaming Data Platform (formerly known as Nautilus) and a Real-Time Streaming reference architecture based on Confluent’s Kafka ingestion platform—and provides a comparative analysis of the platforms.
Real-time data streaming
The topic of real-time data streaming goes far beyond ingesting data in real time. Many publications clearly describe the compelling objectives behind a system that ingests millions of data events in real time. An article from Jay Kreps, one of the co-creators of open source Apache Kafka, provides a comprehensive and in-depth overview of ingesting real-time streaming data. This blog focuses on both ingestion and the processing side of the real-time streaming analytics platforms.
Real-time streaming analytics platforms
A comprehensive end-to-end big data analytics platform demands must-have features that:
- Simplify the data ingestion layer
- Integrate seamlessly with other components in the big data ecosystem
- Provide programming model APIs for developing insight-analytics applications
- Provide plug-and-play hooks to expose the processed data to visualization and business intelligence layers
Over the past many years, demand for real-time ingestion features have created motivations for implementing several streaming analytics engines, each with a unique targeted architecture. Streaming analytics engines provide capabilities ranging from micro-batching the streamed data during processing to a near-real-time performance to a true-real-time processing behavior. The ingested datatype may range from a byte-stream event to a complex event format. Examples of such data size ingestion engines are Dell Technologies supported Pravega and open source Apache 2.0 Kafka that can be seamlessly integrated with open source big data analytics engines such as Samza, Spark, Flink, and Storm, to name a few. Proprietary implementations of similar technologies are offered by a variety of vendors. A short list of these products includes Striim, WSO2 Complex Event processor, IBM Streams, SAP Event Stream Processor, and TIBCO Event Processing.
Real-time streaming analytics solutions: A Dell Technologies strategy
Dell Technologies offer customers two solutions to implement their real-time streaming infrastructure. One solution is built on Apache Kafka as the ingestion layer and Kafka Stream Processing as the default streaming data processing engine. The second solution is built on open source Pravega as the ingestion layer and Flink as the default real-time streaming data processing engine. But how are these solutions being used in response to customers’ requirements? Let’s review possible integration patterns where Dell Technologies real-time streaming offerings facilitate data ingestion and partial preprocessing layers for implementing these patterns.
Real-time streaming and big data processing patterns
Customers implement real-time streaming in different ways to meet their specific requirements. This implies that there may exist many ways of integrating a real-time streaming solution, with the remaining components in the customer’s infrastructure ecosystem. Figure 1 depicts a minimal big data integration pattern that customers may implement by mixing and matching a variety of existing streaming, storage, compute, and business analytics technologies.
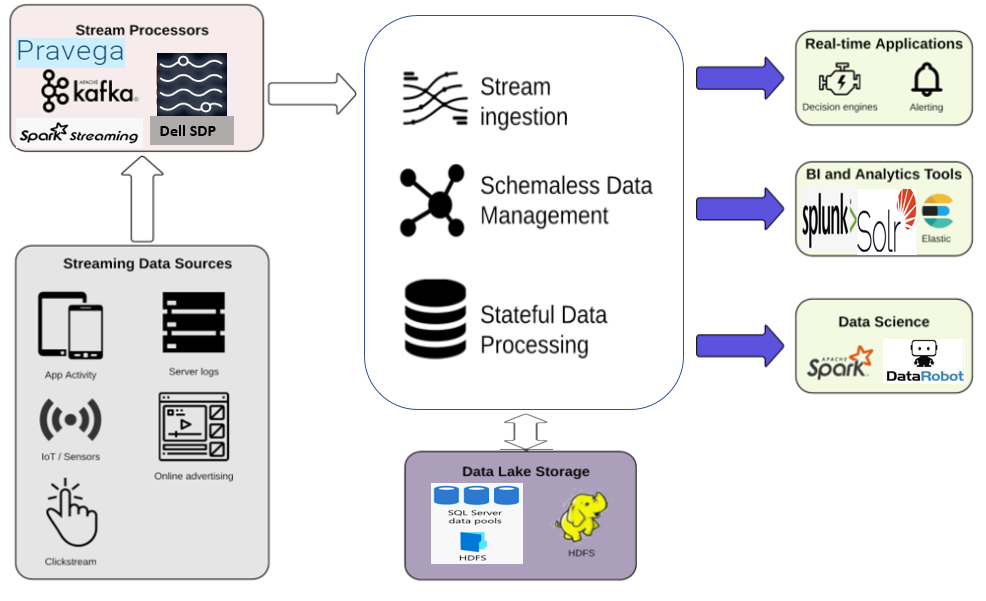
Figure 1: A modern big data integration pattern for processing real-time ingested data
There are several options to implement the Stream Processors layer, including the following two offerings from Dell Technologies.
Dell EMC–Confluent Ready Architecture for Real-Time Data Streaming
The core component of this solution is Apache Kafka, which also delivers Kafka Stream Processing in the same package. Confluent provides and supports the Apache Kafka distribution along with Confluent Enterprise-Ready Platform with advanced capabilities to improve Kafka. Additional community and commercial platform features enable:
- Accelerated application development and connectivity
- Event transformations through stream processing
- Simplified enterprise operations at scale and adherence to stringent architectural requirements
Dell Technologies provides infrastructure for implementing stream processing deployment architectures using one of two Kafka distributions from Confluent—Standard Cluster Architecture or Large Cluster Architecture. Both cluster architectures may be implemented as either the streaming branch of a Lambda Architecture or as the single process flow engine in a Kappa Architecture. For a description of the difference between the two architectures, see this blog. For more details about the product, see Dell Real-Time Big Data Streaming Ready Architecture documentation.
- Standard Cluster Architecture: This architecture consists of two Dell EMC PowerEdge R640 servers to provide resources for Confluent’s Control Center, three R640 servers to host Kafka Brokers, and two R640 servers to provide compute and storage resources for Confluent’s higher-level KSQL APIs leveraging the Apache Kafka Stream Processing engine. The Kafka Broker nodes also host the Kafka Zookeeper and the Kafka Rebalancer applications. Figure 2 depicts the Standard Cluster Architecture.
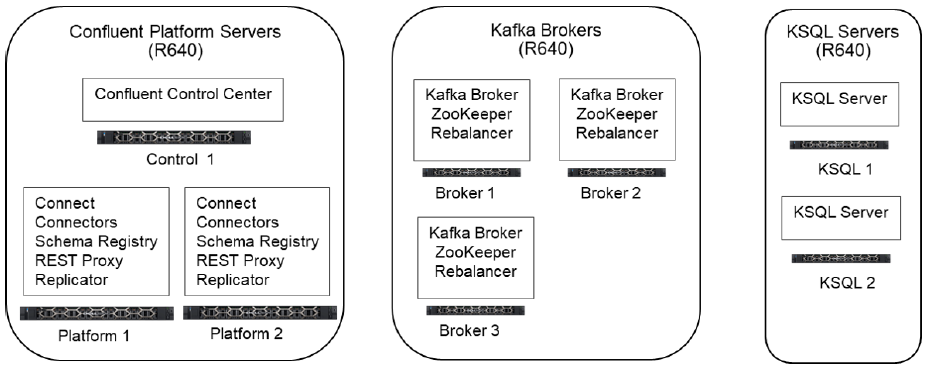
Figure 2: Standard Dell Real-Time Streaming Big Data Cluster Architecture
- Large Cluster Architecture: This architecture consists of two PowerEdge R640 servers to provide resources for Confluent’s Control Center, a configurable number of R640 servers for scalability to host Kafka Brokers, and a configurable number of R640 servers to provide compute and storage resources for Confluent’s KSQL APIs to the implementation of the Apache Kafka Stream Processing engine. The Kafka Broker nodes also host the Kafka Zookeeper and the Kafka Rebalancer applications. Figure 3 depicts the Standard Cluster Architecture.
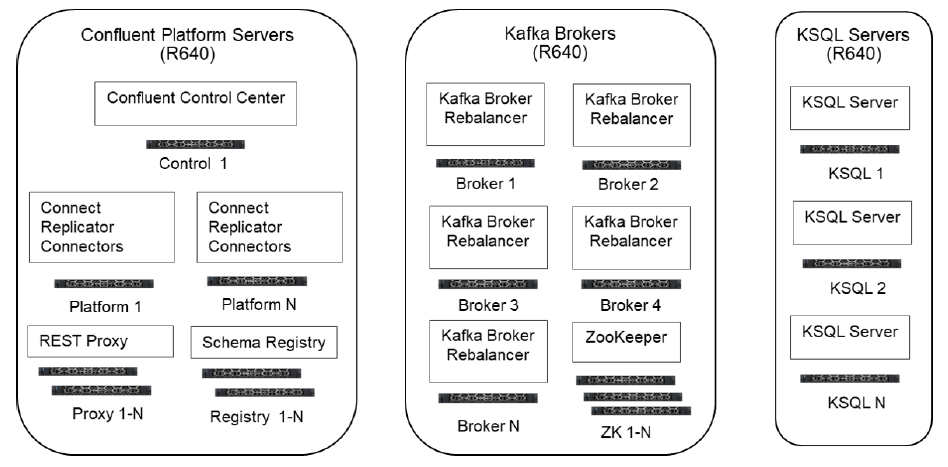
Figure 3: Large Scalable Dell Real-Time Streaming Big Data Cluster Architecture
Dell EMC Streaming Data Platform (SDP)
SDP is an elastically scalable platform for ingesting, storing, and analyzing continuously streaming data in real time. The platform can concurrently process both real-time and collected historical data in the same application. The core components of SDP are open source Pravega for ingestion, Long Term Storage, Apache Flink for compute, open source Kubernetes, and a Dell Technologies proprietary software known as Management Platform. Figure 4 shows the SDP architecture and its software stack components.
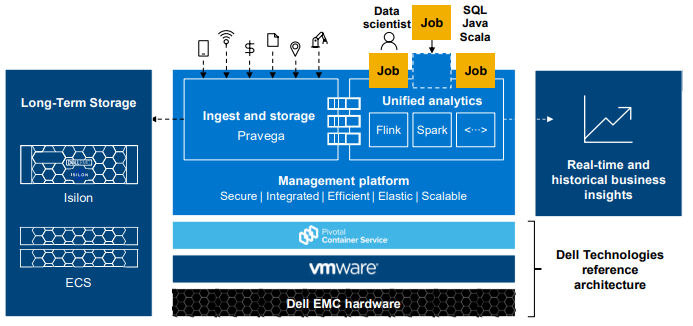
Figure 4: Streaming Data Platform Architecture Overview
- Open source Pravega provides the ingestion and storage artifacts by implementing streams built from heterogeneous datatypes and storing them as appended “segments.” The classes of Unstructured, Structured, and Semi-Structured data may range from a small number of bytes emitted by IoT devices, to clickstreams generated from the users while they surf websites, to business applications’ intermediate transaction results, to virtually any size complex events. Briefly, SDP offers two options for Pravega’s persistent Long Term Storage: Dell EMC Isilon and Dell EMC ECS S3. These storage options are mutually exclusive—that is, both cannot be used in the same SDP instance. Currently, upgrading from one to another is yet to be supported. For details on Pravega and its role in providing storage for SDP streams using Isilon or ECS S3, refer to this Pravega webinar.
- Apache Flink is SDP’s default event processing engine. It consumes ingested streamed data from Pravega’s storage layer and processes it in an instance of a previously implemented data pipeline application. The pipeline application invokes Flink DataStream APIs and processes continuous unbounded streams of data in real time. Alternatives to Flink analytics engines, such as Apache Spark, are also available. To unify multiple analytics engines’ APIs and to prevent writing multiple versions of the same data pipeline application, an attempt is underway to add Apache Beam APIs to SDP to allow the implementation of one Flink data pipeline application that can run on multiple underlying engines on demand.
Comparative analysis: Dell EMC real-time streaming solutions
Both Dell EMC real-time streaming solutions address the same problem and ultimately provide the same solution for it. However, in addition to using different technology implementations, each tends to be a better fit for certain streaming workloads. The best starting point for selecting one over the other is with an understanding of the exactions of the target use case and workload.
In most situations, users know what they want for a real-time ingestion solution—typically an open-source solution that is popular in the industry. Kafka is demanded by customers in most of these situations. Additional characteristics, such as the mechanisms for receiving and storing events and for processing, are secondary. Most of our customer conversations are about a reliable ingestion layer that can guarantee delivery of the customer’s business events to the consuming applications. Further detailed expectations are focused on no loss of events, simple yet long-term storage capacity, and, in most cases, a well-defined process integration method for implementing their initial preprocessing tasks such as filtering, cleansing, and any transformation-like Extract Transform Load (ETL). The purpose of preprocessing is to offload nonbusiness-logic-related work from the target analytics engine—i.e., Spark, Flink, Kafka Stream Processing—resulting in better overall end-to-end real-time performance.
Kafka and Pravega in a nutshell
Kafka is essentially a messaging vehicle to decouple the sender of the event from the application that processes it for gaining business insight. By default, Kafka uses the local disk for temporarily persisting the incoming data. However, the longer-term storage for the ingested data is implemented in what’s known as Kafka Broker Servers. When an event is received, it is broadcast to the interested applications known as subscribers. An application may subscribe to more than one event-type-group, also known as a topic. By default, Kafka stores and replicates events of a topic in partitions configured in Kafka Brokers. The replicas of an event may be distributed among several Brokers to prevent data loss and guarantee recovery in case of a failover. A Broker cluster may be constructed and configured on several Dell EMC PowerEdge R640 servers. To avoid Brokers’ storage and compute capacity limitations, the Brokers’ cluster may be extended through the addition of more Brokers to the cluster topology. This is a horizontally scalable characteristic of Kafka architecture. By design, the de facto analytics engine provided in an open source Kafka stack is known as Kafka Stream Processing. It is customary to use Kafka Stream Processing as a preprocessing engine and then route the results as real-time streaming artifacts to an actual business logic implementing analytics engine such as Flink or Spark Streaming. Confluent wraps the Kafka Stream Processing implementation in an abstract process layer known as KSQL APIs. It makes it extremely simple to run SQL like statements to process events in the core Kafka Stream Processing engine instead of complex third-generation languages such as Java or C++, or scripting languages such as Python.
Unlike Kafka’s messaging protocol and events persisting partitions, Pravega implements a storage protocol and starts to temporarily persist events as appended streams. As time goes by, and the events age, they become long-term data entities. Therefore, unlike Kafka, the Pravega architecture does not require separate long-term storage. Eventually, the historical data is available in the same storage. Pravega, in Dell’s current SDP architecture, routes previously appended streams to Flink, which provides a data pipeline to implement the actual business logic. When it comes to scalability, Pravega uses Isilon or ECS S3 as extended and/or archiving storage.
Although both SDP and Kafka act as a vehicle between the event sender and the event processor, they implement this transport differently. By design, Kafka implements the pub/sub pattern. It basically broadcasts the event to all interested applications at the same time. Pravega makes specific events available directly to a specific application by implementing a point-to-point pattern. Both Kafka and Pravega claim guaranteed delivery. However, the point-to-point approach supports a more rigid underlying transport.
Conclusion
Dell Technologies offers two real-time streaming solutions, and it is not a simple task to promote one over the other. Ideally, every customer problem requires an initial analysis on the data source, data format, data size, expected data ingestion frequency, guaranteed delivery requirements, integration requirements, transactional rollback requirements (if applicable), storage requirements, transformation requirements, and data structural complexity. Aggregated results from such analysis may help us suggest a specific solution.
Dell works with customers to collect as much detailed information as possible about the customer’s streaming use cases. Kafka Stream Processing has an impressive feature that offloads the transformation portion of the analytics of a pipeline engine such as Flink or Spark to its Kafka Stream Processing engine. This could be a great advantage. Meanwhile SDP requires extra scripting efforts outside of the Flink configuration space to provide the same logically equivalent capability. On the other hand, SDP simplifies storage complexities through Pravega native streams-per-segments architecture, while Kafka core storage logic pertains to a messaging layer that requires a dedicated file system. Customers that have IoT device data use cases are concerned with ingestion high frequency rate (number of events per second). Soon, we can use this parameter and provide some benchmarking results of a comparative analysis of ingestion frequency rate performed on our SDP and Confluent Real-Time Streaming solutions.
Acknowledgments
I owe an enormous debt of gratitude to my colleagues Mike Pittaro and Mike King of Dell Technologies. They shared their valuable time to discuss the nuances of the text, guided me to clarify concepts, and made specific recommendations to deliver cohesive content.
Author: Amir Bahmanyari, Advisory Engineer, Dell Technologies Data-Centric Workload & Solutions. Amir joined Dell Technologies Big Data Analytics team in late 2017. He works with Dell Technologies customers to build their Big Data solutions. Amir has a special interest in the field of Artificial Intelligence. He has been active in Artificial and Evolutionary Intelligence work since late 1980’s when he was a Ph.D. candidate student at Wayne State University, Detroit, MI. Amir implemented multiple AI/Computer Vision related solutions for Motion Detection & Analysis. His special interest in biological and evolutionary intelligence algorithms lead to innovate a neuron model that mimics the data processing behavior in protein structures of Cytoskeletal fibers. Prior to Dell, Amir worked for several startups in the Silicon Valley and as a Big Data Analytics Platform Architect at Walmart Stores, Inc.
Related Blog Posts

Navigating the modern data landscape: the need for an all-in-one solution

Mon, 18 Mar 2024 19:56:59 -0000
|Read Time: 0 minutes
There are two revolutions brewing inside every enterprise. We are all very familiar with the first one - the frenzied rush to expand an organization's AI capabilities, which leads to an exponential growth in data creation, a rise in availability of high-performance computing systems with multi-threaded GPUs, and the rapid advancement of AI models. The situation creates a perfect storm that is reshaping the way enterprises operate. Then, there is a second revolution that makes the first one a reality – the ability to harness this awesome power and gain a competitive advantage to drive innovation. Enterprises are racing towards a modern data architecture that seeks to bring order to their chaotic data environment.
The Need For An All-In-One Solution
Data platforms are constantly evolving, despite a plethora of options such as data lakes, data warehouses, cloud data warehouses and even cloud data lakehouses, enterprise are still struggling. This is because the choices available today are suboptimal.
Cloud native solutions offer simplicity and scalability, but migrating all data to the cloud can be a daunting task and can end up being significantly more expensive over the long term. Moreover, concerns about the loss of control over proprietary data, particularly in the realm of AI, is a major cause for concern, as well. On the other hand, traditional on-premises solutions require significantly more expertise and resources to build and maintain. Many organizations simply lack the skills and capabilities needed to construct a robust data platform in-house.
A customer once told me – “We’ve heard from so many vendors but ultimately there is no easy button for us.”
When Dell Technologies set out to build that easy button, we started with what enterprises needed most: infrastructure, software, and services all seamlessly integrated. We created a tailor-made solution with right-sized compute and a highly performant query engine that is pre-integrated and pre-optimized to perfectly streamline IT operations. We incorporated built-in enterprise-grade security that also can seamlessly integrate with 3rd party security tools. To enable rapid support, we staffed a bench of experts, offering end-to-end maintenance and deployment services. We also knew the solution needed to be future proof – not only anticipating future innovations but also accommodating the diverse needs of users today. To support this idea, we made the choice to use open data formats, which means an organization’s data is no longer locked-in to a proprietary format or vendor. To make the transition easier, the solution makes use of built-in enterprise-ready connectors that ensures business continuity. Ultimately, our goal was to deliver an experience that is easy to install, easy to use, easy to manage, easy to scale, and easy to future-proof.
Dell Data Lakehouse’s Core Capabilities
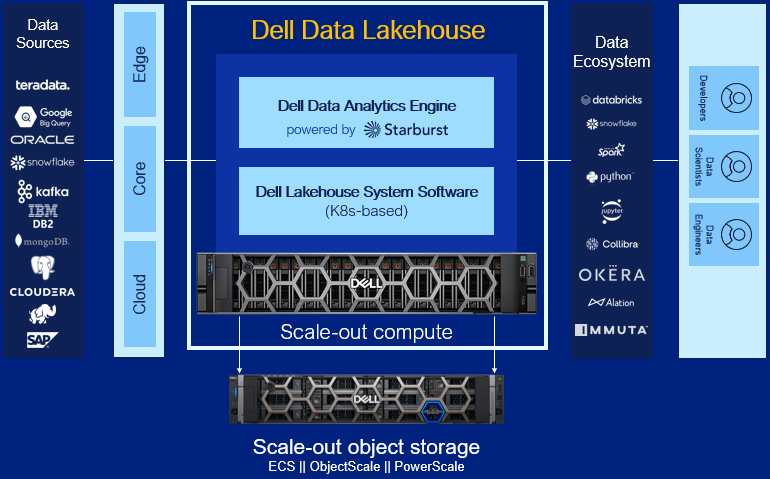
Let’s dig into each component of the solution.
- Data Analytics Engine, powered by Starburst: A high performance distributed SQL query engine, built on top of Starburst, based on Trino, which can run fast analytic queries against data lakes, lakehouses and distributed data sources at internet-scale. It integrates global security with fine-grained access controls, supports ad-hoc and long-running ELT workloads and is a gateway to building high quality data products and power AI and Analytics workloads. Dell’s Data Analytics Engine also includes exclusive features that help dramatically improve performance when querying data lakes. Stay tuned for more info!
- Data Lakehouse System Software: This new system software is the central nervous system of the Dell Data Lakehouse. It simplifies lifecycle management of the entire stack, drives down IT OpEx with pre-built automation and integrated user management, provides visibility into the cluster health and ensures high availability, enables easy upgrades and patches and lets admins control all aspects of the cluster from one convenient control center. Based on Kubernetes, it’s what converts a data lakehouse into an easy button for enterprises of all sizes.
- Scale-out Lakehouse Compute: Purpose-built Dell Compute and Networking hardware perfectly matched for compute-intensive data lakehouse workloads come pre-integrated into the solution. Independently scale from storage by seamlessly adding more compute as needs grow.
- Scale-out Object Storage: Dell ECS, ObjectScale and PowerScale deliver cyber-secure, multi-protocol, resilient and scale-out storage for storing and processing massive amounts of data. Native support for Delta Lake and Iceberg ensures read / write consistency within and across sites for handling concurrent, atomic transactions.
- Dell Services: Accelerate AI outcomes with help at every stage from trusted experts. Align a winning strategy, validate data sets, quickly implement your data platform and maintain secure, optimized operations.
- ProSupport: Comprehensive, enterprise-class support on the entire Dell Data Lakehouse stack from hardware to software delivered by highly trained experts around the clock and around the globe.
- ProDeploy: Expert delivery and configuration assure that you are getting the most from the Dell Data Lakehouse on day one. With 35 years of experience building best-in-class deployment practices and tools, backed by elite professionals, we can deploy 3x faster1 than in-house administrators.
- Advisory Services Subscription for Data Analytics Engine: Receive a pro-active, dedicated expert to maximize value of your Dell Data Analytics Engine environment, guiding your team through design and rollout of new use cases to optimize and scale your environment.
- Accelerator Services for Dell Data Lakehouse: Fast track ROI with guided implementation of the Dell Data Lakehouse platform to accelerate AI and data analytics.
Learn More
With the combination of these capabilities, Dell continues to innovate alongside our customers to help them exceed their goals in the face of data challenges. We aim to allow our customers to take advantage of the revolution brewing that is AI and this rapid change in the market to harness the power of their data and gain a competitive advantage and drive innovation. Enterprises are racing towards a modern data architecture – it's critical they don’t get stuck at the starting line.
For detailed information on this exciting product, refer to our technical guide. For other information, visit Dell.com/datamanagement.
Source
1 Based on a May 2023 Principled Technologies study “Using Dell ProDeploy Plus Infrastructure can improve deployment times for Dell Technology”
Graph DB Use Cases – Put a Tiger in Your Tank
Mon, 06 Feb 2023 18:44:06 -0000
|Read Time: 0 minutes
In the NoSQL Database Taxonomy there are four basic categories:
- Key Value
- Wide Column
- Document
- Graph
Although Graph is arguably the smallest category by several measures it is the richest when it comes to use cases. Here is a sampling of what I’ve seen to date:
- Fraud detection
- Feature store for ML/DL
- C360 – yeah you can do that one in most any db.
- As an overlay to an ERP application allowing the addition of new attributes without changing the underlying data model or code. For select objects the keys (primary & alternate) with select attributes populate the graph. The regular APIs are wrapped to check for new attributes in the graph. If none then the call is passed thru. For new attributes there would be a post processing module that makes sense of it and takes additional actions based on the content.
- One could use this same technique for many homegrown applications.
- As an integrated database for multiple disparate, hetereogenous data store integration. I solutioned this conceptually for a large bank that had data in the likes of Snowflake, Oracle, MySQL, Hadoop and Teradata. The key to success here is not dragging all the data into the graph but merely keys, select attributes
- Recommendation engines
- Configuration management
- Network management
- Transportation problems
- MDM
- Threat detection
- Bad guy databases
- Social networking
- Supply chain
- Telecom
- Call management
- Entity resolution
We’re closely partnered with Tiger Graph and can cover the above use cases and many more.
If you’d like to hear more and work on solutions to your problem please do drop me an email at Mike.King2@Dell.com