




Performance study of a VMware vSphere 7 virtualized HPC cluster
Mon, 28 Mar 2022 16:35:13 -0000
|Read Time: 0 minutes
High Performance Computing (HPC) involves processing complex scientific and engineering problems at a high speed across a cluster of compute nodes. Performance is one of the most important features of HPC. While most HPC applications are run on bare metal servers, there has been a growing interest to run HPC applications in virtual environments. In addition to providing resiliency and redundancy for the virtual nodes, virtualization offers the flexibility to quickly instantiate a secure virtual HPC cluster.
Most people tend to run their HPC workloads on dedicated hardware, which is often composed of server compute nodes that are interconnected by high-speed networks to maximize their performance. Alternatively, virtualization abstracts the underlying hardware and adds a software layer that emulates this hardware. With this in mind, the engineers at the Dell Technologies HPC & AI Innovation Lab and VMware conducted a performance study to compare the performance of running and scaling HPC workloads on dedicated bare metal nodes to a vSphere 7-based virtualized infrastructure. The team also tuned the physical and virtual infrastructure to achieve optimal virtual performance and share these findings and recommendations.
Performance test details
Our team evaluated tightly coupled HPC applications or message passing interface (MPI) based workloads and observed promising results. These applications consist of parallel processes (MPI ranks) that leverage multiple cores and are architected to scale computation to multiple compute servers (or VMs) to solve the complex mathematical model or scientific simulation in a timely manner. Examples of tightly coupled HPC workloads include computational fluid dynamics (CFD) used to model airflow in automotive and airplane designs, weather research and forecasting models for predicting the weather, and reservoir simulation code for oil discovery.
To evaluate the performance of these tightly coupled HPC applications, we built 16-node HPC cluster using Dell PowerEdge R640 vSAN Ready nodes. Dell Power Edge R640 is a 1U dual socket server with Intel® Xeon® Scalable processors. The same cluster was configured as both a bare metal HPC cluster and as a virtual cluster running VMware vSphere.
Figure 1 shows a representative network topology of this cluster. The cluster was connected to two separate physical networks. We used the following components for this cluster:
- Dell PowerSwitch Z9332 switch connecting NVIDIA® Connect®-X6 100 GbE adapters to provide a low latency high bandwidth 100 GbE RDMA-based HPC network for the MPI-based HPC workload
- a separate pair of Dell PowerSwitch S5248 25 GbE based top of rack (ToR) switches for hypervisor management, VM access and VMware vSAN networks for the virtual cluster
The VM switches provided redundancy and were connected by a virtual link trucking interconnect (VLTi). A VMware vSAN cluster was created to host the VMDKs for the virtual machines. To maximize CPU utilization RDMA, we also leveraged support for vSAN. This provides direct memory access between the nodes participating in the vSAN cluster without involving the operating system or the CPU. RDMA offers low latency, high throughput, and high IOPs that are more difficult to achieve with traditional TCP-based networks. It also enables the HPC workloads to consume more CPU for their work without impacting the vSAN performance.
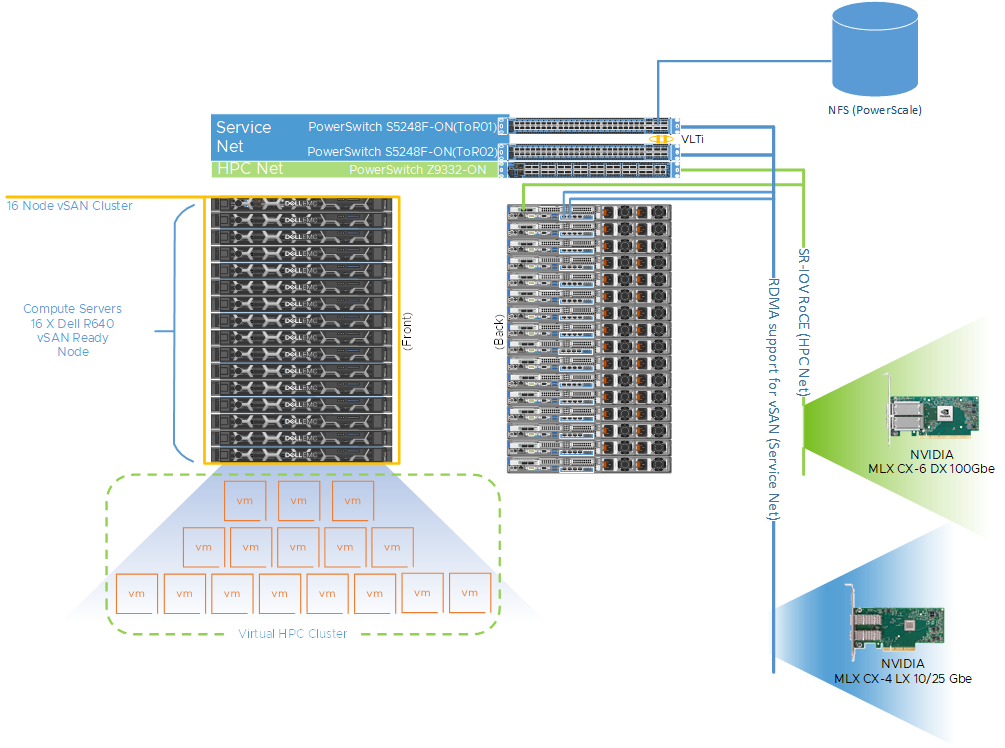
Figure 1: A 16-Node HPC cluster test bed
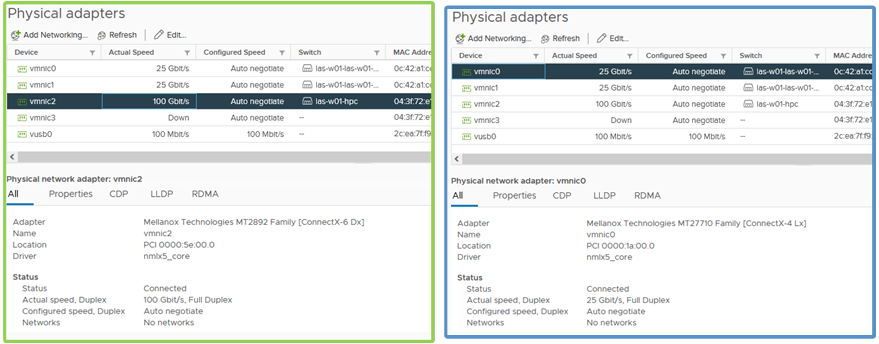
Figure 2: Physical adapter configuration for HPC network and service network
Table 1 describes the configuration details of the physical nodes and the network connectivity. For the virtual cluster, a single VM per node was provisioned for a total of 16 VMs or virtual compute nodes. Each VM was configured with 44 vCPU and 144 GB of memory, and the VM CPU and memory reservation were enabled and we set the VM latency sensitivity to high. Figure 1 also provides an example of how the hosts are cabled to each fabric. One port from each host is connected to the NVIDIA Mellanox ConnectX-6 adapter and to the Dell PowerSwitch Z9332 for the HPC network fabric. For the service network fabric, two ports are connected from the NVIDIA Mellanox ConnectX-4 adapter to the Dell PowerSwitch S5248 ToR switches.
Table 1: Configuration details for the bare metal and virtual clusters
Environment | Bare Metal | Virtual |
Server | PowerEdge R640 vSAN Ready Node | |
Processor | 2 x Intel Xeon 2nd Generation 6240R | |
Cores | All 48 cores used | 44 vCPU used |
Memory | 12 x 16GB @3200 MT/s | 144 GB reserved for the VM |
Operating System | CentOS 8.3 | Host OS: VMware vSphere 7.0u2 |
HPC Network NIC | 100 GbE NVIDIA Mellanox Connect-X6 | |
Service Network NIC | 10/25 GbE NVIDIA Mellanox Connect-X4 | |
HPC Network Switch | Dell PowerSwitch Z9332F-ON | |
Service Network Switch | Dell PowerSwitch S5248F-ON | |
Table 2 shows a range of different HPC applications across multiple vertical domains along with the benchmark datasets that were used for the performance comparison.
Table 2: Application and Benchmark Details
Application | Vertical Domain | Benchmark Dataset |
OpenFOAM | Manufacturing - Computational Fluid Dynamics (CFD) | |
Weather Research and Forecasting (WRF) | Weather and Environment | |
Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) | Molecular Dynamics | |
GROMACS | Life Sciences – Molecular Dynamics | HECBioSim Benchmarks – 3M Atoms |
Nanoscale Molecular Dynamics (NAMD) | Life Sciences – Molecular Dynamics | STMV – 1.06M Atoms |
Performance Results
Figures 3 through 7 show the performance, scalability, and difference in performance for five representative HPC applications in the CFD, weather, and science domains. Each of the applications was run to scale from 1 node through 16 nodes on a bare metal and a virtual cluster. All five applications demonstrate efficient speedup when computation is scaled out to multiple systems. The relative speedup for the application is plotted (the baseline is application performance on a bare metal single node).
The results indicate that MPI application performance running in a virtualized infrastructure (with proper tuning and following best practices for latency-sensitive applications in a virtual environment) is close to performance in a bare metal infrastructure. The single node performance delta ranges from no difference for WRF to a maximum of 8 percent difference observed with LAMMPS. Similarly, as the nodes are scaled, the performance observed on the virtual nodes is comparable to that on the bare-metal infrastructure with the largest delta being 10% when running LAMMPS on 16 nodes.
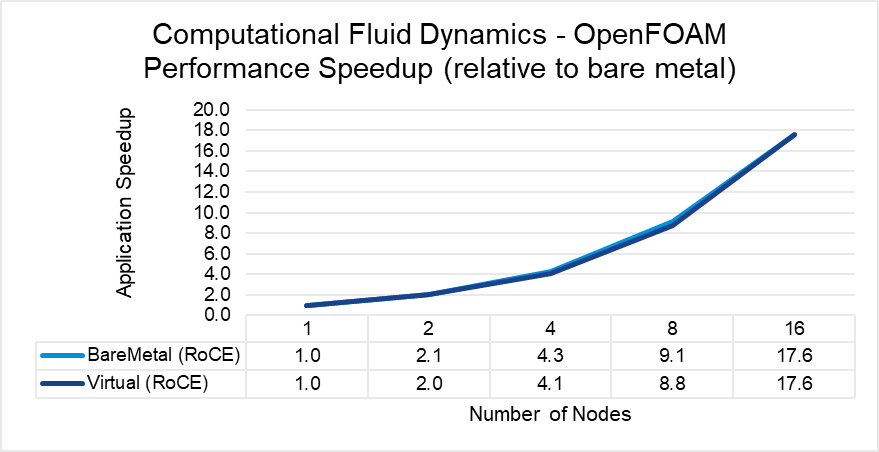
Figure 3: OpenFOAM performance comparison between virtual and bare-metal systems
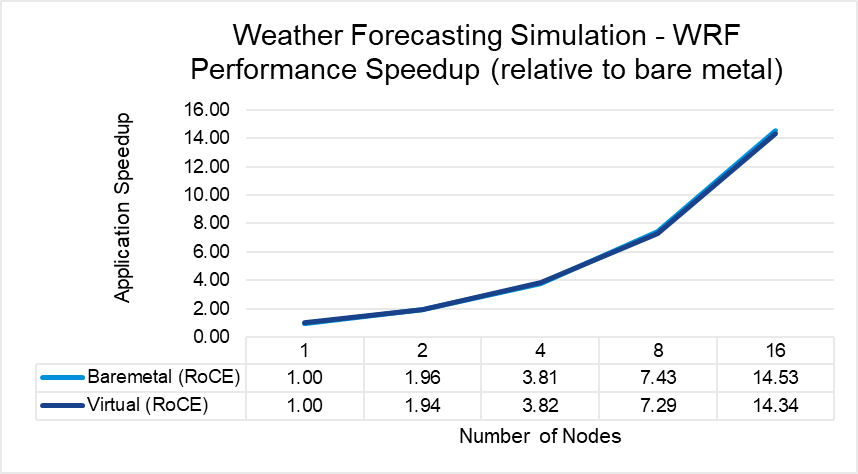
Figure 4: WRF performance comparison between virtual and bare-metal systems
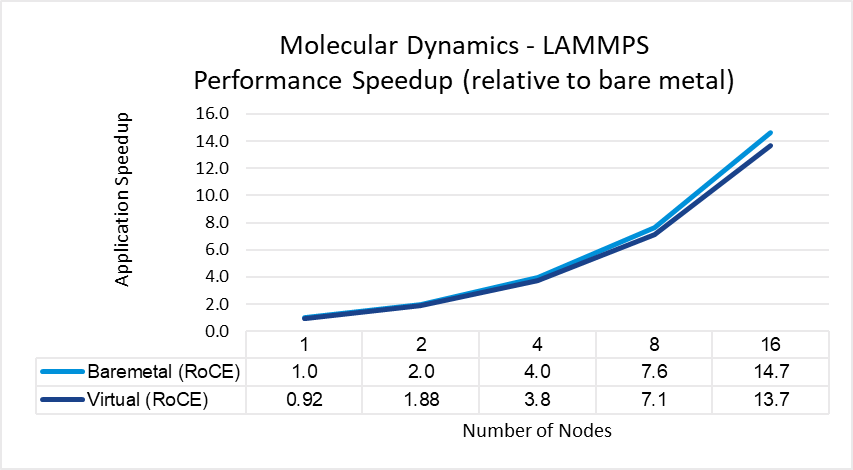
Figure 5: LAMMPS performance comparison between virtual and bare-metal systems
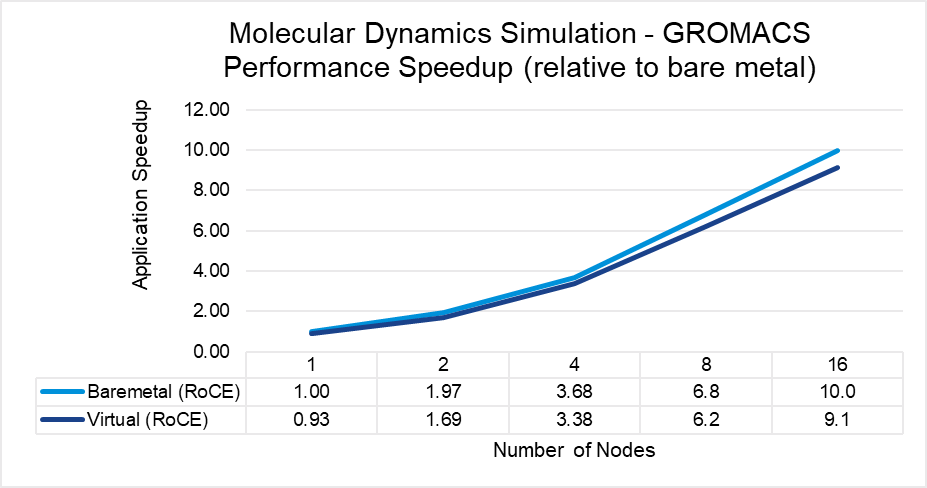
Figure 6: GROMACS performance comparison between virtual and bare-metal systems
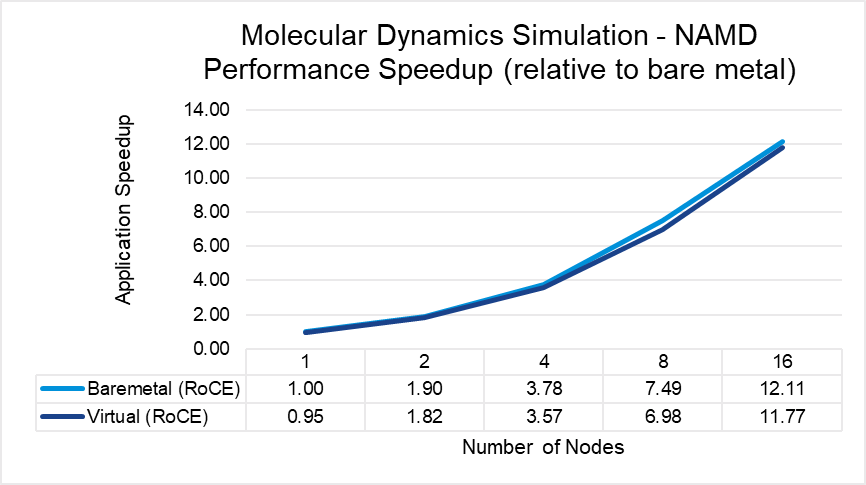
Figure 7: NAMD performance comparison between virtual and bare-metal systems
Tuning for Optimal Performance
One of the key elements of achieving a viable virtualized HPC solution is the tuning best practices that allow for optimal performance. We found a significant improvement was achieved after some minor tweaks were made from the out-of-box configuration. These improvements are a critical ingredient to ensuring customers can and will achieve results that enable not only the implementation of a virtual HPC environment, but also the adoption of a more cloud-ready eco-system that provides operational efficiencies and multi-workload support.
Table 3 outlines the parameters that we found to work best for MPI applications. Given the nature of MPI for parallel communication and its heavy reliance on a low-latency network, we suggest the implementation of the VM Latency Sensitivity setting available in vSphere 7.0. This setting allows users to optimize the scheduling delay for latency sensitive applications by 1) giving exclusive access to physical resources to reduce resource contention, 2) by-passing virtualization layers that are not providing value for these workloads, and 3) tuning virtualization layers to reduce any unnecessary overhead. We have also outlined the additional physical host and hypervisor tunings that complete these best practices below.
Table 3: Recommended performance turnings for tightly coupled HPC workloads
Settings | Value |
Physical Server |
|
BIOS Power Profile | Performance per watt (OS) |
BIOS Hyper-threading | On |
BIOS Node Interleaving | Off |
BIOS SR-IOV | On |
Hypervisor |
|
ESXi Power Policy | High Performance |
Virtual Machine |
|
VM Latency Sensitivity | High |
VM CPU Reservation | Enabled |
VM Memory Reservation | Enabled |
VM Sizing | Maximum VM size with CPU/memory reservation |
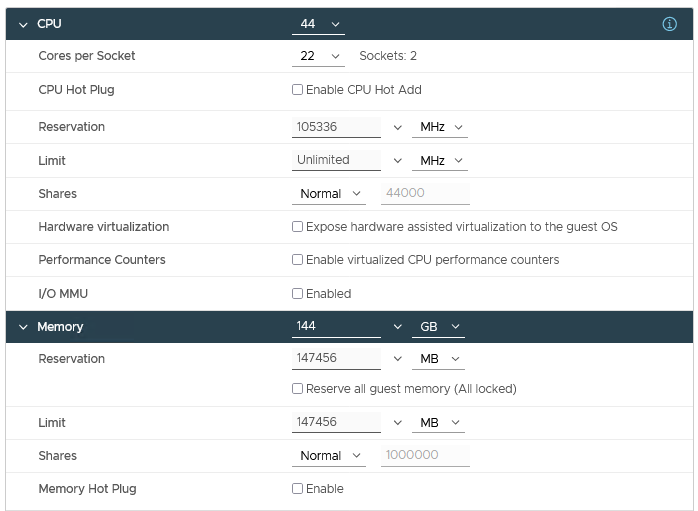
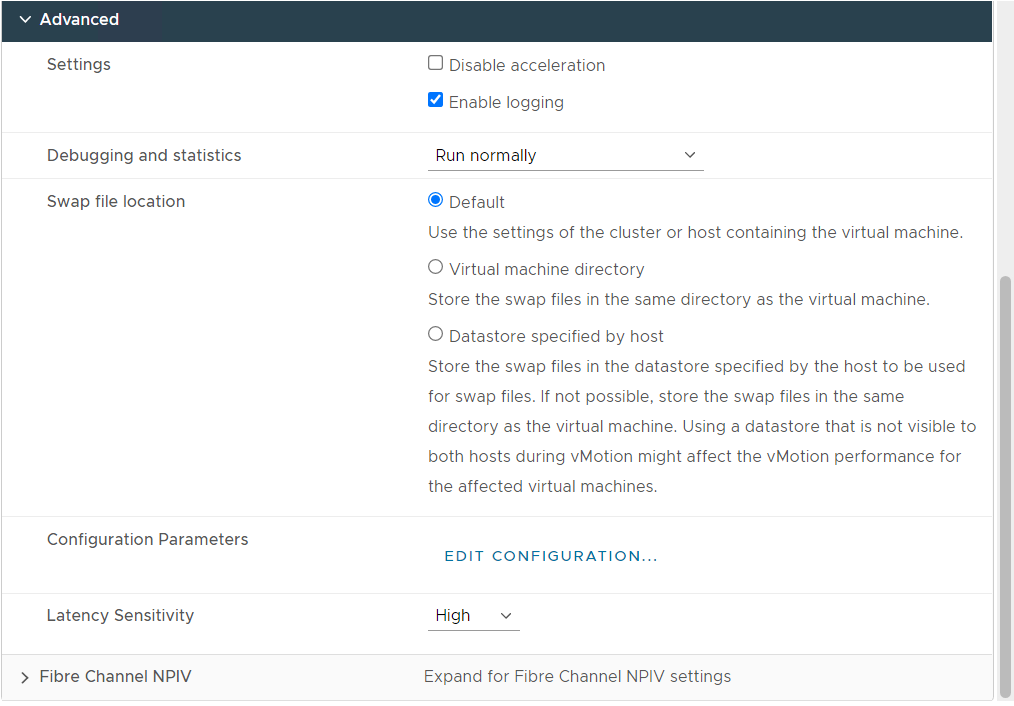
Figure 8: Virtual Machine Configuration with the recommended tuning settings
Figure 8 shows a snapshot of the recommended tuning settings as applied to the virtual machine used as the virtual nodes on the HPC cluster.
Conclusion
Achieving optimal performance is a key consideration for running an HPC application. While most HPC applications enjoy the performance benefits offered by a dedicated bare metal hardware, our results indicate that with appropriate tuning the performance gap between virtual and bare metal nodes has narrowed, making it feasible to run certain HPC applications in a virtualized environment. We also observed that these tested HPC applications demonstrate efficient speedups when computation is scaled out to multiple virtual nodes.
Additional resources
To learn more about our previous and ongoing work at the Dell Technologies HPC & AI Innovation Lab, see the High Performance Computing overview and the Dell Technologies Info Hub blog page for HPC solutions.
Acknowledgements
The authors thank Martin Hilgeman from Dell Technologies, Ramesh Radhakrishnan and Michael Cui from VMware, and Martin Feyereisen for their contribution in the study.
Related Blog Posts

Performance Evaluation of HPC Applications on a Dell PowerEdge R650-based VMware Virtualized Cluster
Wed, 08 Feb 2023 14:45:39 -0000
|Read Time: 0 minutes
Overview
High Performance Computing (HPC) solves complex computational problems by doing parallel computations on multiple computers and performing research activities through computer modeling and simulations. Traditionally, HPC is deployed on bare-metal hardware, but due to advancements in virtualization technologies, it is now possible to run HPC workloads in virtualized environments. Virtualization in HPC provides more flexibility, improves resource utilization, and enables support for multiple tenants on the same infrastructure.
However, virtualization is an additional layer in the software stack and is often construed as impacting performance. This blog explains a performance study conducted by the Dell Technologies HPC and AI Innovation Lab in partnership with VMware. The study compares bare-metal and virtualized environments on multiple HPC workloads with Intel® Xeon® Scalable third-generation processor-based systems. Both the bare-metal and virtualized environments were deployed on the Dell HPC on Demand solution.
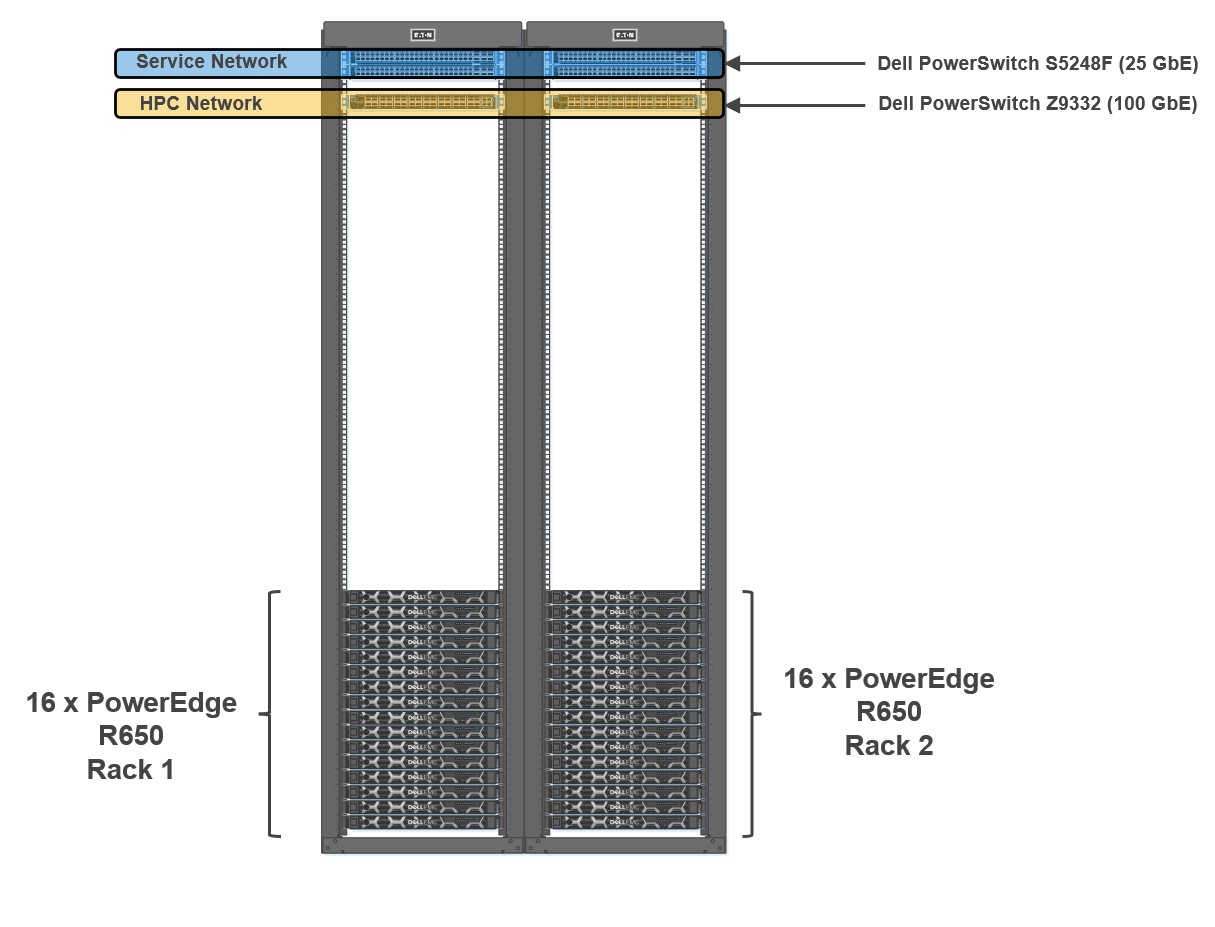
Figure 1: Cluster Architecture
To evaluate the performance of HPC applications and workloads, we built a 32-node HPC cluster using Dell PowerEdge R650 as compute nodes. Dell Power Edge R650 is a 1U dual socket server with Intel® Xeon® Scalable third-generation processors. The cluster was configured to use both bare-metal and virtual compute nodes (running VMware vSphere 7). Both bare-metal and virtualized nodes were attached to the same head node.
Figure 1 shows a representative network topology of this cluster. The cluster was connected to two separate physical networks. The compute nodes were spread across two sets of racks, and the cluster consisted of the following two networks:
- HPC Network: Dell PowerSwitch Z9332 switch connecting NVIDIA® Connect®-X6 100 GbE adapters to provide a low latency high bandwidth 100 GbE RDMA-based HPC network for the MPI-based HPC workload
- Services Network: A separate pair of Dell PowerSwitch S5248F-ON 25 GbE based top of rack (ToR) switches for hypervisor
The Virtual Machine (VM) configuration details for optimal performance settings were captured in an earlier blog. In addition to the settings noted in the previous blog, some additional BIOS tuning options such as Snoop Hold Off, SubNumaCluster (SNC) and LLC Prefetch settings were also tested. Snoop Hold Off (set to 2 K cycles), and SNC, helped performance across most of the tested applications and microbenchmarks for both the bare-metal and virtual nodes. Enabling SNC in the server BIOS and not configuring SNC correctly in the VM might result in performance degradation.
Bare-metal and virtualized HPC system configuration
Table 1 shows the system environment details used for the study.
Table 1: System configuration details for the bare-metal and virtual clusters
Machine function | Component |
Platform | PowerEdge R650 server |
Processor | Two Intel® Xeon® third Generation 6348 (28 cores @ 2.6 GHz) |
Number of cores | Bare-Metal: 56 cores Virtual: 52 vCPUs (four cores reserved for ESXi) |
Memory | Sixteen 32 GB DDR4 DIMMS @3200 MT/s Bare-Metal: All 512 GB used Virtual: 440 GB reserved for the VM
|
HPC Network NIC | 100 GbE NVIDIA Mellanox Connect-X6 |
Service Network NIC | 10/25 GbE NVIDIA Mellanox Connect-X5 |
HPC Network Switch | Dell PowerSwitch Z9332 with OS 10.5.2.3 |
Service Network Switch | Dell PowerSwitch S5248F-ON |
Operating system | Rocky Linux release 8.5 (Green Obsidian) |
Kernel | 4.18.0-348.12.2.el8_5.x86_64 |
Software – MPI | IntelMPI 2021.5.0 |
Software – Compilers | Intel OneAPI 2022.1.1 |
Software – OFED | OFED 5.4.3 (Mellanox FW 22.32.20.04) |
BIOS version | 1.5.5 (for both bare-metal and virtual nodes) |
Application and benchmark details
The following chart outlines the set of HPC applications used for this study from different domains like Computational Fluid Dynamics (CFD), Weather, and Life Sciences. Different benchmark datasets were used for each of the applications as detailed in Table 2.
Table 2: Application and benchmark dataset details
Application | Vertical Domain | Benchmark Dataset |
Weather and Environment | Conus 2.5KM, Maria 3KM | |
Manufacturing - Computational Fluid Dynamics (CFD) | ||
Life Sciences – Molecular Dynamics | ||
Molecular Dynamics | EAM metallic Solid Benchmark (1M, 3M and 8M Atoms) HECBIOSIM – 3M Atoms |
Performance results
All the application results shown here were run on both bare-metal and virtual environments using the same binary compiled with Intel Compiler and run with Intel MPI. Multiple runs were done to ensure consistency in the performance. Basic synthetic benchmarks like High Performance Linpack (HPL), Stream, and OSU MPI Benchmarks were run to ensure that the cluster was operating efficiently before running the HPC application benchmarks. For the study, all the benchmarks were run in a consistent, optimized, and stable environment across both the bare-metal and virtual compute nodes.
Intel® Xeon® Scalable third-generation processors (Ice Lake 6348) have 56 cores. Four cores were reserved for the virtualization hypervisor (ESXi) providing the remaining 52 cores to run benchmarks. All the results shown here consist of 56 core runs on bare-metal vs 52 core runs on virtual nodes.
To ensure better scaling and performance, multiple combinations of threads and MPI ranks were tried based on applications. The best results are used to show the relative speedup between both the bare-metal and virtual systems.
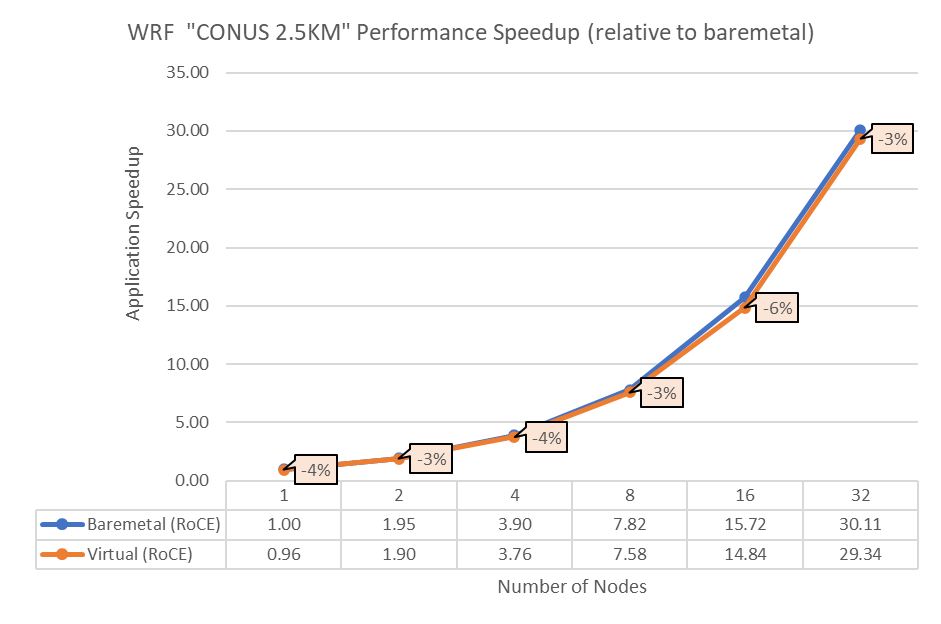
Figure 2: Performance comparison between bare-metal and virtual nodes for WRF
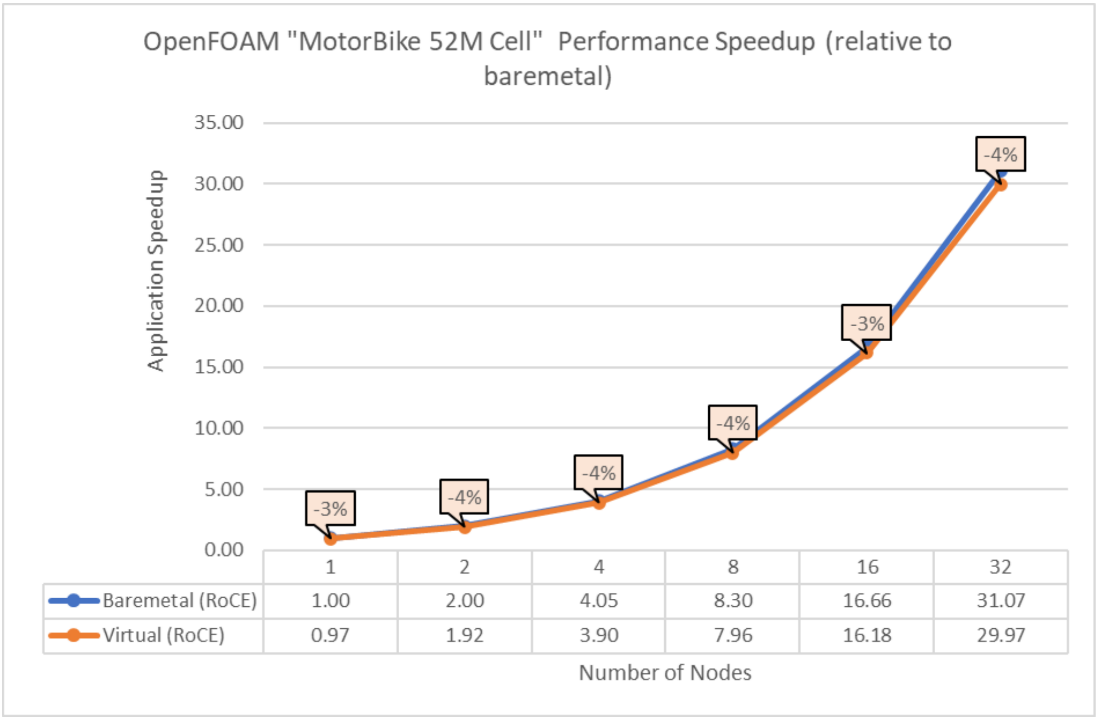
Figure 3: Performance comparison between bare-metal and virtual nodes for OpenFOAM
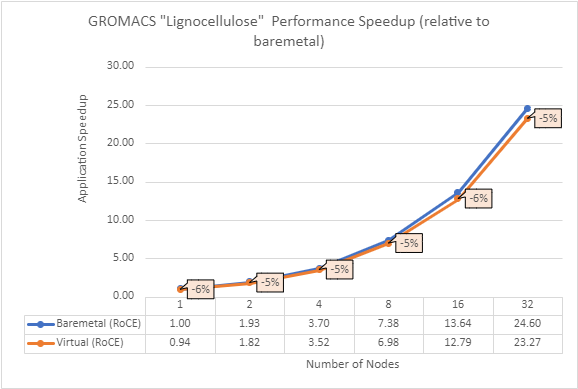
Figure 4: Performance comparison between bare-metal and virtual nodes for GROMACS
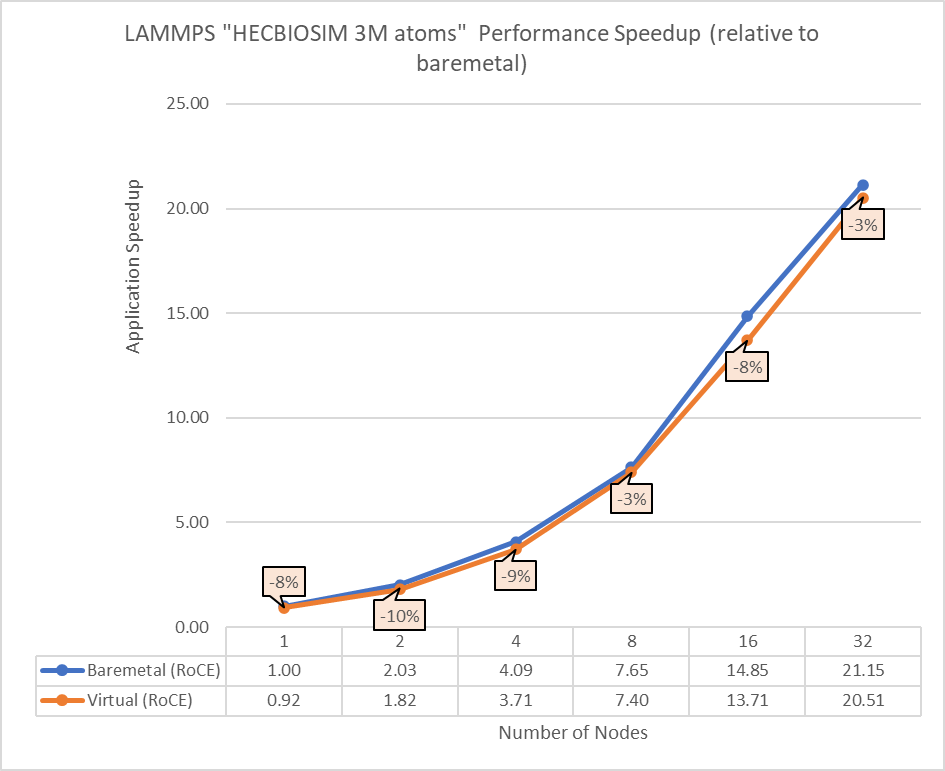
Figure 5: Performance comparison between bare-metal and virtual nodes for LAMMPS
The above results indicate that all the MPI applications running in a virtualized environment are close in performance to the bare-metal environment if proper tuning and optimizations are used. The performance delta, running from a single node up to 32 nodes, is within the 10% range for all the applications. This delta shows no major impact on scaling.
Concurrency test
In a virtualized multitenant HPC environment, the expectation is for multiple tenants to be running multiple concurrent instances of the same or different applications. To simulate this configuration, a concurrency test was conducted by making multiple copies of the same workload and running them in parallel. This test checks whether any performance degradation appears in comparison with the baseline run result. To do some meaningful concurrency tests, we expanded the virtual cluster to 48 nodes by converting 16 nodes of bare-metal to virtual. For the concurrency tests, the baseline is made with an 8-node run while no other workload was running across the 48-node virtual cluster. After that, six copies of the same workload were allowed to run simultaneously across the virtual cluster. Then the results are compared and depicted for all the applications.
The concurrency was tested in two ways. In the first test, all eight nodes running a single copy were placed in the same rack. In the second test, the nodes running a single job were spread across two racks to see if any performance difference was observed due to additional communication over the network.
Figures 6 to 13 capture the results of the concurrency test. As seen from the results there was no degradation observed in the performance.
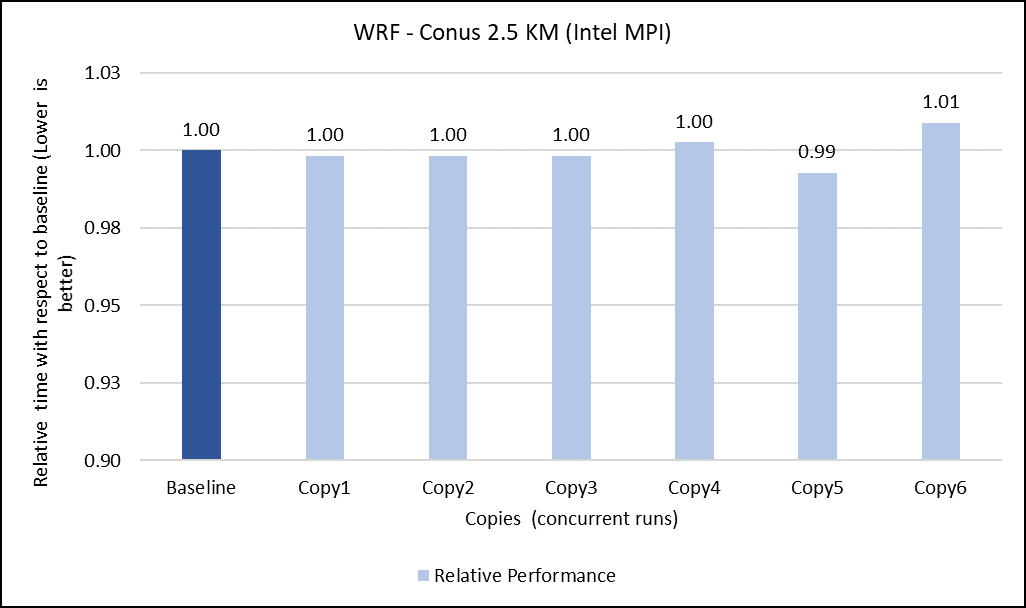
Figure 6: Concurrency Test 1 for WRF
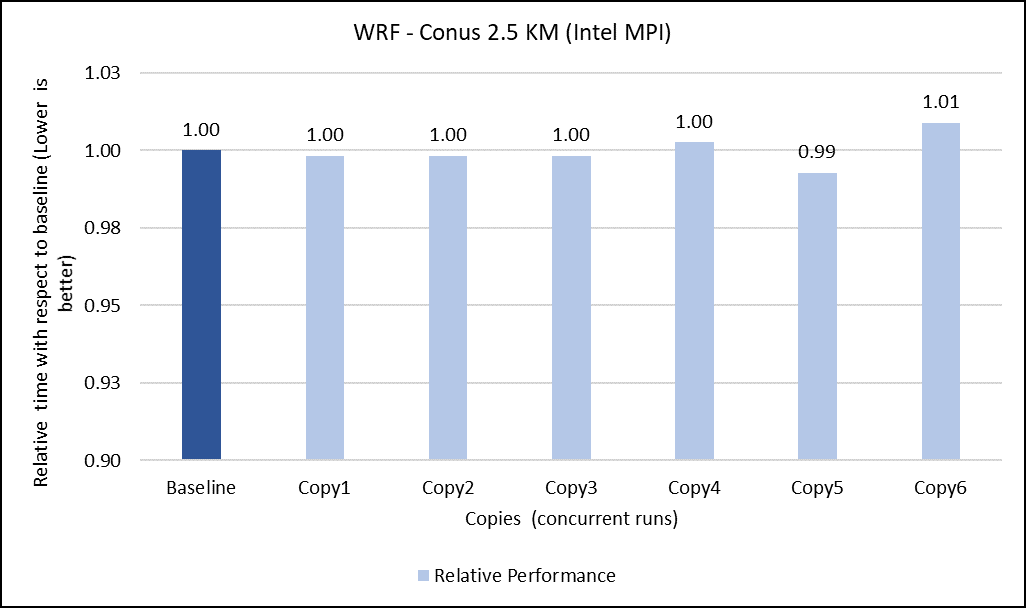
Figure 7: Concurrency Test 2 for WRF
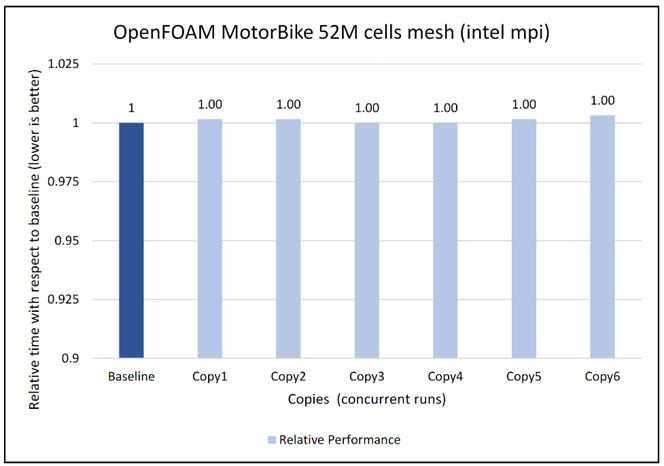
Figure 8: Concurrency Test 1 for Open FOAM
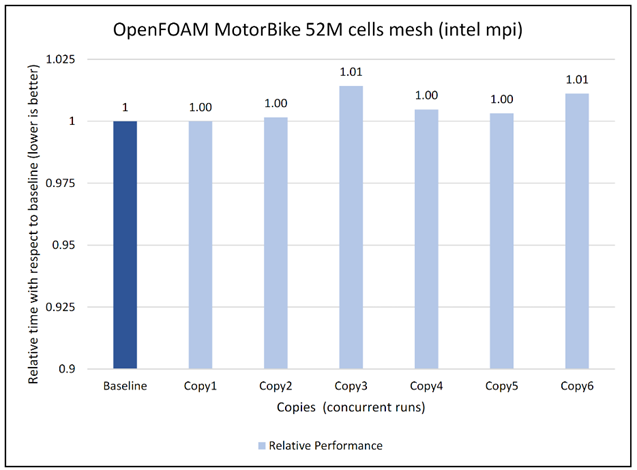
Figure 9: Concurrency Test 2 for Open FOAM
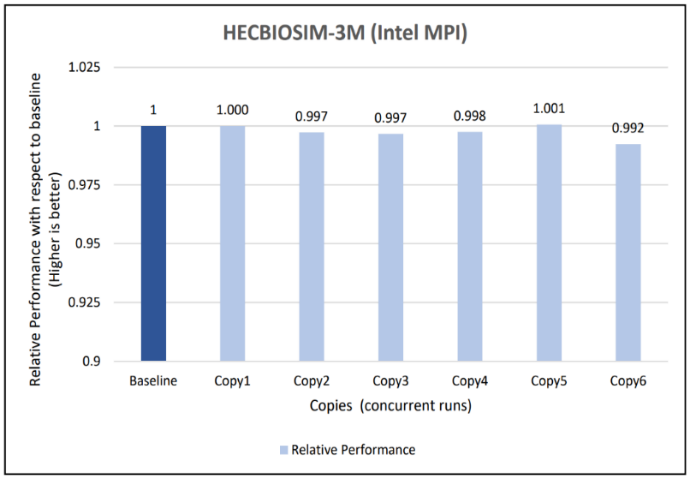
Figure 10: Concurrency Test 1 for GROMACS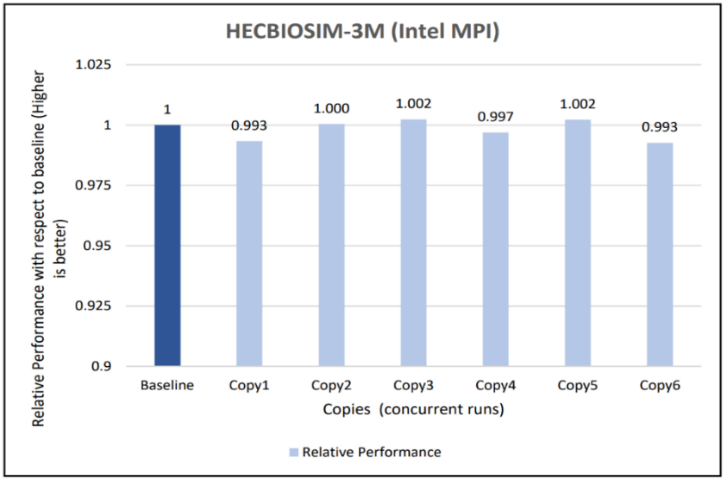
Figure 11: Concurrency Test 2 for GROMACS
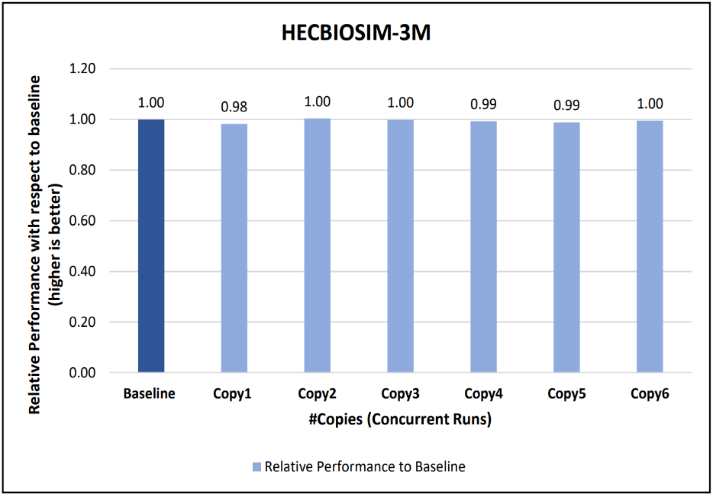
Figure 12: Concurrency Test 1 for LAMMPS 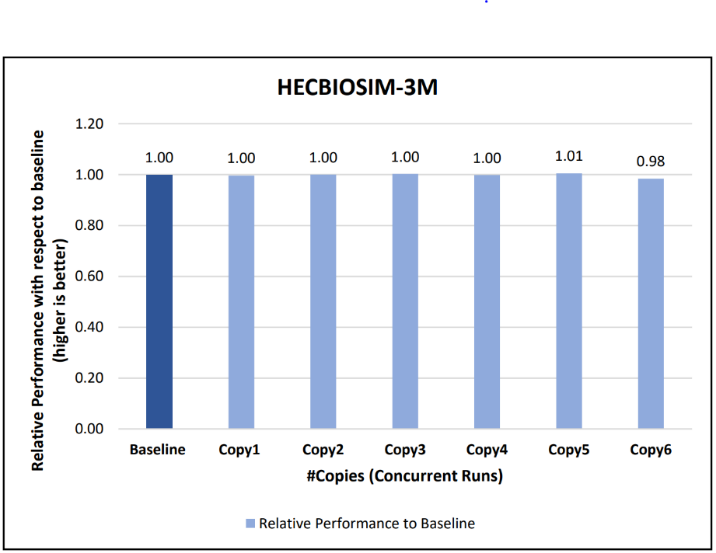
Figure 13: Concurrency Test 2 for LAMMPS
Another set of concurrency tests was conducted by running different applications (WRF, GROMACS, and Open FOAM) simultaneously in the virtual environment. In this test, two eight-node copies of each application run concurrently across the virtual cluster to determine if any performance variation occurs while running multiple parallel applications in the virtual nodes. There is no performance degradation observed in this scenario also, when compared to the individual application baseline run with no other workload running on the cluster.
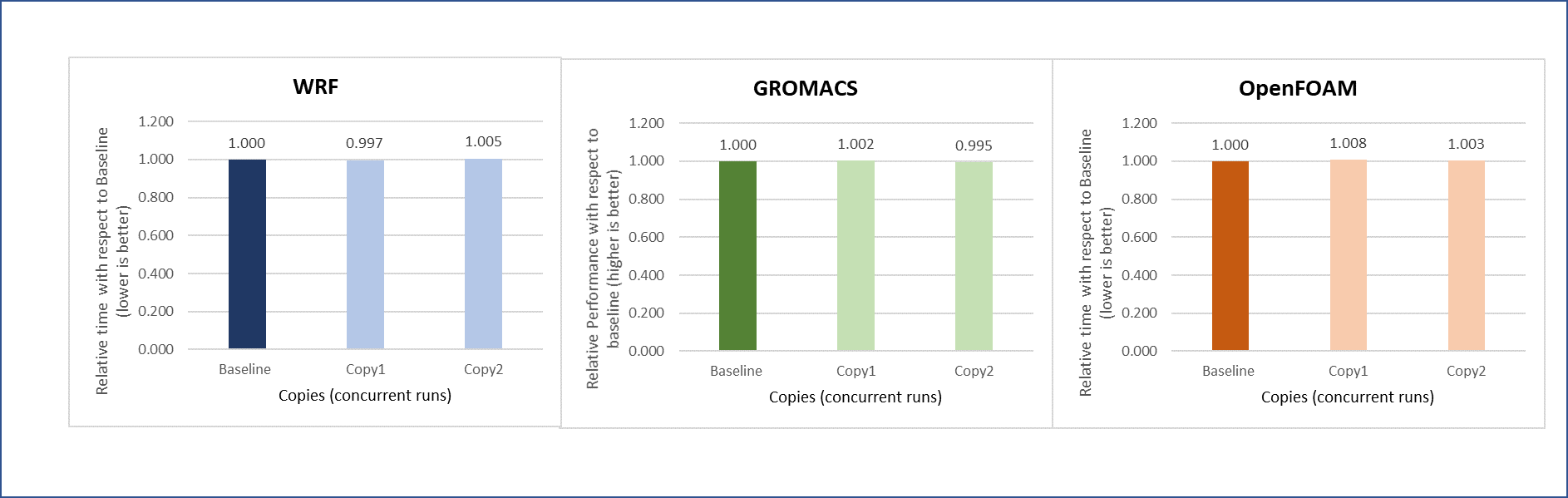
Figure 14: Concurrency test with multiple applications running in parallel
Intel Select Solution certification
In addition to the benchmark testing, this system has been certified as an Intel® Select Solution for Simulation and Modeling. Intel Select Solutions are workload-optimized configurations that Intel benchmark-tests and verifies for performance and reliability. These solutions can be deployed easily on premises and in the cloud, providing predictability and scalability.
All Intel Select Solutions are a tailored combination of Intel data center compute, memory, storage, and network technologies that deliver predictable, trusted, and compelling performance. Each solution offers assurance that the workload will work as expected, if not better. These solutions can save individual businesses from investing the resources that might otherwise be used to evaluate, select, and purchase the hardware components to gain that assurance themselves.
The Dell HPC On Demand solution is one of a select group of prevalidated, tested solutions that combine third-generation Intel® Xeon® Scalable processors and other Intel technologies into a proven architecture. These certified solutions can reduce the time and cost of building an HPC cluster, lowering hardware costs by taking advantage of a single system for both simulation and modeling workloads.
Conclusion
Running an HPC application necessitates careful consideration for achieving optimal performance. The main objective of the current study is to use appropriate tuning to bridge the performance gap between bare-metal and virtual systems. With the right settings on the tested HPC applications (see Overview), the performance difference between virtual and bare-metal nodes for the 32 node tests is less than 10%. It is therefore possible to successfully run different HPC workloads in a virtualized environment to leverage benefits of virtualization features. The concurrency testing helped to demonstrate that running multiple applications simultaneously in the virtual nodes does not degrade performance.
Resources
To learn more about our previous work on HPC virtualization on Cascade Lake, see the Performance study of a VMware vSphere 7 virtualized HPC cluster.
Acknowledgments
The authors thank Savitha Pareek from Dell Technologies, Yuankun Fu from VMware, Steven Pritchett, and Jonathan Sommers from R Systems for their contribution in the study.

AI and Model Development Performance
Thu, 31 Aug 2023 20:47:58 -0000
|Read Time: 0 minutes
There has been a tremendous surge of information about artificial intelligence (AI), and generative AI (GenAI) has taken center stage as a key use case. Companies are looking to learn more about how to build architectures to successfully run AI infrastructures. In most cases, creating a GenAI solution involves fine-tuning a pretrained foundational model and deploying it as an inference service. Dell recently published a design guide – Generative AI in the Enterprise – Inferencing, that provides an outline of the overall process.
All AI projects should start with understanding the business objectives and key performance indicators. Planning, data prep, and training make up the other phases of the cycle. At the core of the development are the systems that drive these phases – servers, GPUs, storage, and networking infrastructures. Dell is well equipped to deliver everything an enterprise needs to build, develop, and maintain analytic models that serve business needs.
GPUs and accelerators have become common practice within AI infrastructures. They pull in data and training/fine-tune models within the computational capabilities of the GPU. As GPUs have evolved, their ability to handle larger models and parallel development cycles has evolved. This has left a lot of us wondering - how do we build an architecture that will support the model development that my business needs? It helps to understand a few parameters.
Defining business objectives and use cases will help shape your architecture requirements.
- The size and location of the training data set
- Model size in number of parameters and type of model being trained/fine-tuned
- Training parallelism and time to complete the training/fine-tuning.
Answering these questions helps determine how many GPUs are needed to train/fine-tune the model. Consider two main factors in GPU sizing. First is the amount of GPU memory needed to store model parameters and optimizer state. Second is the number of floating-point operations (FLOPs) needed to execute the model. Both generally scale with model size. Large models often exceed the resources of a single GPU and require spreading a single model over multiple GPUs.
Estimating the number of GPUs needed to train/fine-tune the model helps determine the server technologies to choose. When sizing servers, it’s important to balance the right GPU density and interconnect, power consumption, PCI bus technology, external port capacity, memory, and CPU. Dell PowerEdge servers include a variety of options for GPU types and density. PowerEdge XE Servers can host up to 8 NVIDIA H100 GPUs in a single server GenAI on PowerEdge XE9680, as well as the latest technologies, including NVLink, NVIDIA GPUDirect, PCIe 5.0, and NVMe disks. PowerEdge mainstream servers range from two to four GPU configurations, offering a variety of GPUs from different manufacturers. PowerEdge servers provide outstanding performance for all phases of model development. Visit Dell.com for more on PowerEdge Servers.
Now that we understand how many GPUs are needed and the servers to host them, it’s time to tackle storage. At a minimum, the storage should have capacity to host the training data set, the checkpoints during the model training, and any other data that relates to the pruning/preparing phase. The storage also needs to deliver the data at a rate the GPUs request it. The rate of delivery is multiplied by model parallelism, or the number of models being trained in parallel, and subsequently the number of GPUs requesting the data simultaneously (concurrently). Ideally, every GPU is running at 90% or better to maximize our investment, and a storage system that supports high concurrency is suited for these types of workloads.
Tools such as FIO or its cousin GDSIO (used to understand speeds and feeds of the storage system) are great for gaining hero numbers or theoretical maximums for reads/writes, but they are not representative of performance requirements for the AI development cycles. Data prep and stage shows up on the storage as random R/W, while during the training/fine-tuning phase, the GPUs are concurrently streaming reads from the storage system. Checkpoints throughout training are handled as writes back to the storage. These different points during the AI lifecycle require storage that can successfully handle these workloads at the scale determined by our model calculations and parallel development cycles.
Data scientists at Dell take great effort in understanding how different model development affects server and storage requirements. For example, language models like BERT and GPT have little effect on storage performance and resources, whereas image sequencing and DLRM models have significant or show worst case storage performance and resource demand. For this, the Dell storage teams focus testing and benchmarking on AI Deep Learning workflows based on popular image models like ResNet with real GPUs to understand the performance requirements needed to deliver data to the GPU during model training. The following image shows an architecture designed with Dell PowerEdge servers and networking with PowerScale scale-out storage.
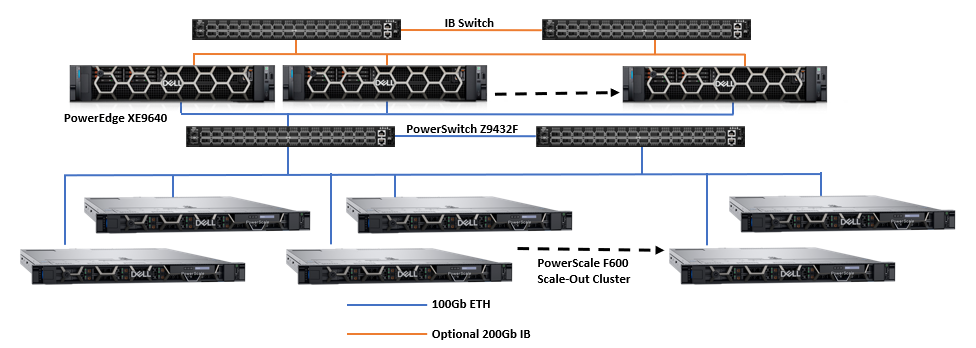
Dell PowerScale scale-out file storage is especially suited for these workloads. Each node in a PowerScale cluster delivers equivalent performance as the cluster and workloads scale. The following images show how PowerScale performance scales linearly as GPUs are increased, while the performance of each individual GPU remains constant. The scale-out architecture of PowerScale file storage easily supports AI workflows from small to large.
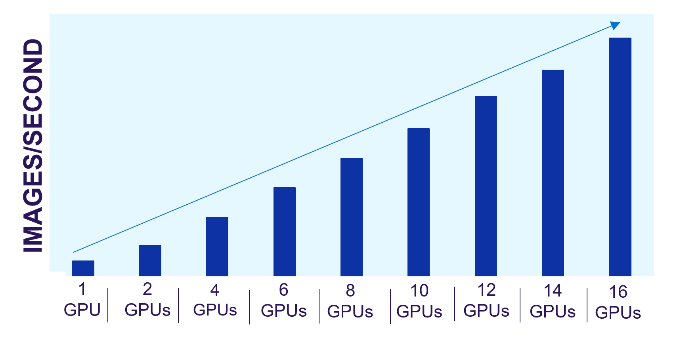
Figure 1. PowerScale linear performance
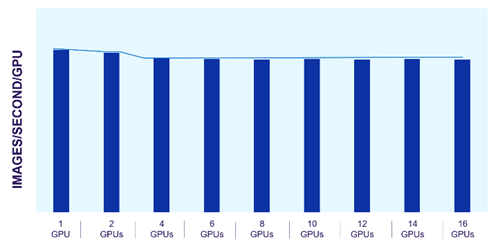
Figure 2. Consistent GPU performance with scale
The predictability of PowerScale allows us to estimate the storage resources needed for model training and fine-tuning. We can easily scale these architectures based on the model type and size along with the number and type of GPUs required.
Architecting for small and large AI workloads is challenging and takes planning. Understanding performance needs and how the components in the architecture will perform as the AI workload demand scales is critical.
Author: Darren Miller