




OneFS Protocol Auditing

Related Blog Posts

PowerScale Gen6 Chassis Hardware Resilience
Thu, 13 Jan 2022 16:48:24 -0000
|Read Time: 0 minutes
In this article, we’ll take a quick look at the OneFS journal and boot drive mirroring functionality in PowerScale chassis-based hardware:
PowerScale Gen6 platforms, such as the new H700/7000 and A300/3000, stores the local filesystem journal and its mirror in the DRAM of the battery backed compute node blade. Each 4RU Gen 6 chassis houses four nodes. These nodes comprise a ‘compute node blade’ (CPU, memory, NICs), plus drive containers, or sleds, for each.
A node’s file system journal is protected against sudden power loss or hardware failure by OneFS journal vault functionality – otherwise known as ‘powerfail memory persistence’ (PMP). PMP automatically stores the both the local journal and journal mirror on a separate flash drive across both nodes in a node pair:
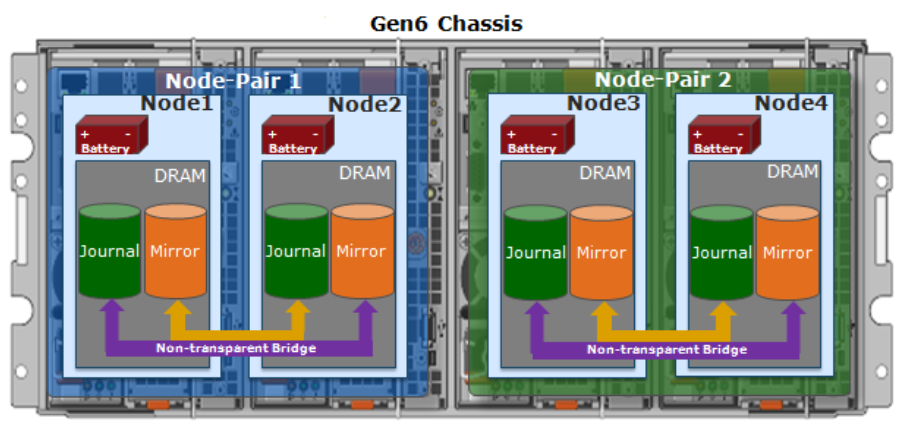
This journal de-staging process is known as ‘vaulting’, during which the journal is protected by a dedicated battery in each node until it’s safely written from DRAM to SSD on both nodes in a node-pair. With PMP, constant power isn’t required to protect the journal in a degraded state since the journal is saved to M.2 flash and mirrored on the partner node.
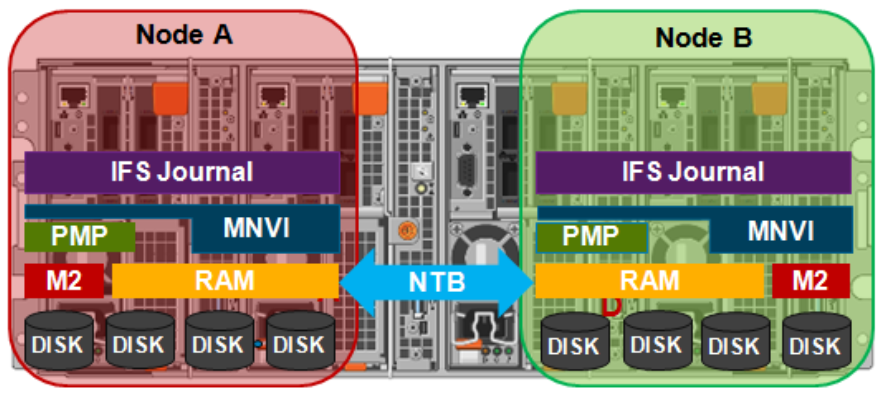
So, the mirrored journal is comprised of both hardware and software components, including the following constituent parts:
Journal Hardware Components
- System DRAM
- 2 Vault Flash
- Battery Backup Unit (BBU)
- Non-Transparent Bridge (NTB) PCIe link to partner node
- Clean copy on disk
Journal Software Components
- Power-fail Memory Persistence (PMP)
- Mirrored Non-volatile Interface (MNVI)
- IFS Journal + Node State Block (NSB)
- Utilities
Asynchronous DRAM Refresh (ADR) preserves RAM contents when the operating system is not running. ADR is important for preserving RAM journal contents across reboots, and it does not require any software coordination to do so.
The journal vault feature encompasses the hardware, firmware, and operating system support that ensure the journal’s contents are preserved across power failure. The mechanism is similar to the NVRAM controller on previous generation nodes but does not use a dedicated PCI card.
On power failure, the PMP vaulting functionality is responsible for copying both the local journal and the local copy of the partner node’s journal to persistent flash. On restoration of power, PMP is responsible for restoring the contents of both journals from flash to RAM and notifying the operating system.
A single dedicated flash device is attached via M.2 slot on the motherboard of the node’s compute module, residing under the battery backup unit (BBU) pack. To be serviced, the entire compute module must be removed.

If the M.2 flash needs to be replaced for any reason, it will be properly partitioned and the PMP structure will be created as part of arming the node for vaulting.
The battery backup unit (BBU), when fully charged, provides enough power to vault both the local and partner journal during a power failure event.

A single battery is utilized in the BBU, which also supports back-to-back vaulting.
On the software side, the journal’s Power-fail Memory Persistence (PMP) provides an equivalent to the NVRAM controller‘s vault/restore capabilities to preserve Journal. The PMP partition on the M.2 flash drive provides an interface between the OS and firmware.
If a node boots and its primary journal is found to be invalid for whatever reason, it has three paths for recourse:
- Recover journal from its M.2 vault.
- Recover journal from its disk backup copy.
- Recover journal from its partner node’s mirrored copy.

A single battery is utilized in the BBU, which also supports back-to-back vaulting.
On the software side, the journal’s Power-fail Memory Persistence (PMP) provides an equivalent to the NVRAM controller‘s vault/restore capabilities to preserve Journal. The PMP partition on the M.2 flash drive provides an interface between the OS and firmware.
If a node boots and its primary journal is found to be invalid for whatever reason, it has three paths for recourse:
- Recover journal from its M.2 vault.
- Recover journal from its disk backup copy.
- Recover journal from its partner node’s mirrored copy.
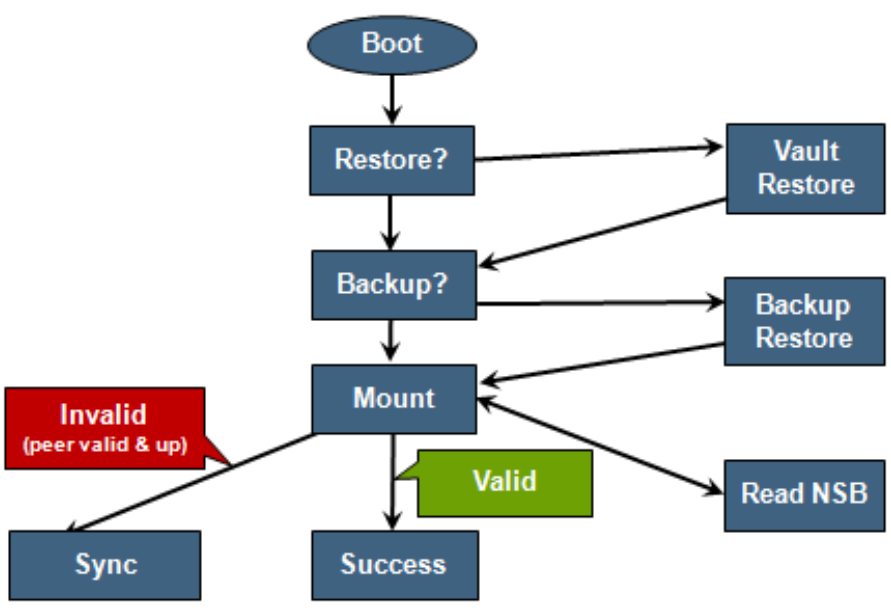
The mirrored journal must guard against rolling back to a stale copy of the journal on reboot. This necessitates storing information about the state of journal copies outside the journal. As such, the Node State Block (NSB) is a persistent disk block that stores local and remote journal status (clean/dirty, valid/invalid, etc), as well as other non-journal information. NSB stores this node status outside the journal itself and ensures that a node does not revert to a stale copy of the journal upon reboot.
Here’s the detail of an individual node’s compute module:
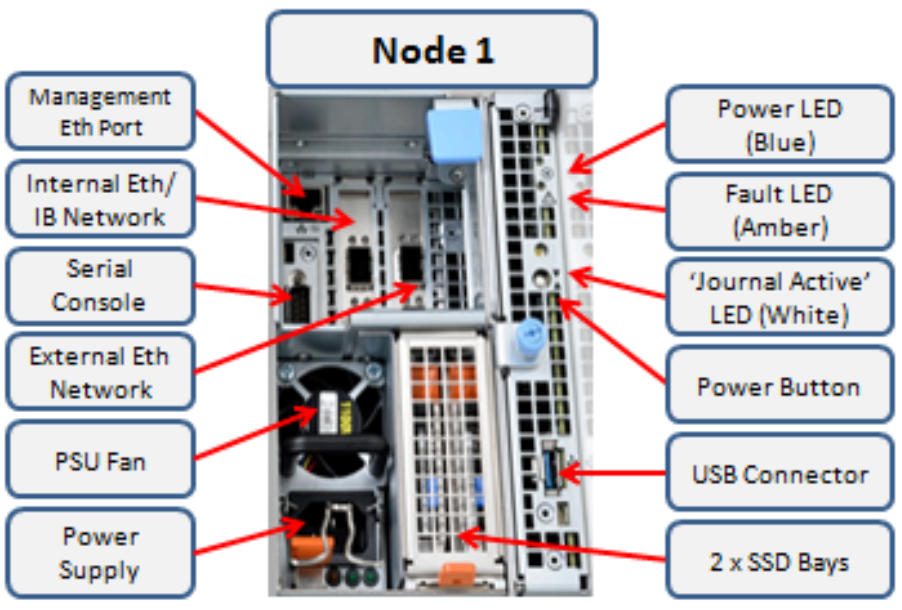
Of particular note is the ‘journal active’ LED, which is displayed as a white hand icon.

When this white hand icon is illuminated, it indicates that the mirrored journal is actively vaulting, and it is not safe to remove the node!
There is also a blue ‘power’ LED, and a yellow ‘fault’ LED per node. If the blue LED is off, the node may still be in standby mode, in which case it may still be possible to pull debug information from the baseboard management controller (BMC).
The flashing yellow ‘fault’ LED has several state indication frequencies:
Blink Speed | Blink Frequency | Indicator |
Fast blink | ¼ Hz | BIOS |
Medium blink | 1 Hz | Extended POST |
Slow blink | 4 Hz | Booting OS |
Off | Off | OS running |
The mirrored non-volatile interface (MNVI) sits below /ifs and above RAM and the NTB, provides the abstraction of a reliable memory device to the /ifs journal. MNVI is responsible for synchronizing journal contents to peer node RAM, at the direction of the journal, and persisting writes to both systems while in a paired state. It upcalls into the journal on NTB link events and notifies the journal of operation completion (mirror sync, block IO, etc.).
For example, when rebooting after a power outage, a node automatically loads the MNVI. It then establishes a link with its partner node and synchronizes its journal mirror across the PCIe Non-Transparent Bridge (NTB).
Prior to mounting /ifs, OneFS locates a valid copy of the journal from one of the following locations in order of preference:
Order | Journal Location | Description |
1st | Local disk | A local copy that has been backed up to disk |
2nd | Local vault | A local copy of the journal restored from Vault into DRAM |
3rd | Partner node | A mirror copy of the journal from the partner node |
If the node was shut down properly, it will boot using a local disk copy of the journal. The journal will be restored into DRAM and /ifs will mount. On the other hand, if the node suffered a power disruption the journal will be restored into DRAM from the M.2 vault flash instead (the PMP copies the journal into the M.2 vault during a power failure).
In the event that OneFS is unable to locate a valid journal on either the hard drives or M.2 flash on a node, it will retrieve a mirrored copy of the journal from its partner node over the NTB. This is referred to as ‘Sync-back’.
Note: Sync-back state only occurs when attempting to mount /ifs.
On booting, if a node detects that its journal mirror on the partner node is out of sync (invalid), but the local journal is clean, /ifs will continue to mount. Subsequent writes are then copied to the remote journal in a process known as ‘sync-forward’.
Here’s a list of the primary journal states:
Journal State | Description |
Sync-forward | State in which writes to a journal are mirrored to the partner node. |
Sync-back | Journal is copied back from the partner node. Only occurs when attempting to mount /ifs. |
Vaulting | Storing a copy of the journal on M.2 flash during power failure. Vaulting is performed by PMP. |
During normal operation, writes to the primary journal and its mirror are managed by the MNVI device module, which writes through local memory to the partner node’s journal via the NTB. If the NTB is unavailable for an extended period, write operations can still be completed successfully on each node. For example, if the NTB link goes down in the middle of a write operation, the local journal write operation will complete. Read operations are processed from local memory.
Additional journal protection for Gen 6 nodes is provided by OneFS powerfail memory persistence (PMP) functionality, which guards against PCI bus errors that can cause the NTB to fail. If an error is detected, the CPU requests a ‘persistent reset’, during which the memory state is protected and node rebooted. When back up again, the journal is marked as intact and no further repair action is needed.
If a node loses power, the hardware notifies the BMC, initiating a memory persistent shutdown. At this point the node is running on battery power. The node is forced to reboot and load the PMP module, which preserves its local journal and its partner’s mirrored journal by storing them on M.2 flash. The PMP module then disables the battery and powers itself off.
Once power is back on and the node restarted, the PMP module first restores the journal before attempting to mount /ifs. Once done, the node then continues through system boot, validating the journal, setting sync-forward or sync-back states, etc.
During boot, isi_checkjournal and isi_testjournal will invoke isi_pmp. If the M.2 vault devices are unformatted, isi_pmp will format the devices.
On clean shutdown, isi_save_journal stashes a backup copy of the /dev/mnv0 device on the root filesystem, just as it does for the NVRAM journals in previous generations of hardware.
If a mirrored journal issue is suspected, or notified via cluster alerts, the best place to start troubleshooting is to take a look at the node’s log events. The journal logs to /var/log/messages, with entries tagged as ‘journal_mirror’.
The following new CELOG events have also been added in OneFS 8.1 for cluster alerting about mirrored journal issues:
CELOG Event | Description |
HW_GEN6_NTB_LINK_OUTAGE | Non-transparent bridge (NTP) PCIe link is unavailable |
FILESYS_JOURNAL_VERIFY_FAILURE | No valid journal copy found on node |
Another reliability optimization for the Gen6 platform is boot mirroring. Gen6 does not use dedicated bootflash devices, as with previous generation nodes. Instead, OneFS boot and other OS partitions are stored on a node’s data drives. These OS partitions are always mirrored (except for crash dump partitions). The two mirrors protect against disk sled removal. Since each drive in a disk sled belongs to a separate disk pool, both elements of a mirror cannot live on the same sled.
The boot and other OS partitions are 8GB and reserved at the beginning of each data drive for boot mirrors. OneFS automatically rebalances these mirrors in anticipation of, and in response to, service events. Mirror rebalancing is triggered by drive events such as suspend, softfail and hard loss.
The following command will confirm that boot mirroring is working as intended:
# isi_mirrorctl verify
When it comes to smartfailing nodes, here are a couple of other things to be aware of with mirror journal and the Gen6 platform:
- When you smartfail a node in a node pair, you do not have to smartfail its partner node.
- A node will still run indefinitely with its partner missing. However, this significantly increases the window of risk since there’s no journal mirror to rely on (in addition to lack of redundant power supply, etc).
- If you do smartfail a single node in a pair, the journal is still protected by the vault and powerfail memory persistence.
Author: Nick Trimbee

OneFS Path-based File Pool Policies
Thu, 13 Jan 2022 16:30:42 -0000
|Read Time: 0 minutes
As we saw in a previous article, when data is written to the cluster, SmartPools determines which pool to write to based on either path or on any other criteria.
If a file matches a file pool policy which is based on any other criteria besides path name, SmartPools will write that file to the Node Pool with the most available capacity.
However, if a file matches a file pool policy based on directory path, that file will be written into the Node Pool dictated by the File Pool policy immediately.

If the file matches a file pool policy that places it on a different Node Pool than the highest capacity Node Pool, it will be moved when the next scheduled SmartPools job runs.
If a filepool policy applies to a directory, any new files written to it will automatically inherit the settings from the parent directory. Typically, there is not much variance between the directory and the new file. So, assuming the settings are correct, the file is written straight to the desired pool or tier, with the appropriate protection, etc. This applies to access protocols like NFS and SMB, as well as copy commands like ‘cp’ issued directly from the OneFS command line interface (CLI). However, if the file settings differ from the parent directory, the SmartPools job will correct them and restripe the file. This will happen when the job next runs, rather than at the time of file creation.
However, simply moving a file into the directory (via the UNIX CLI commands such as cp, mv, etc.) will not occur until a SmartPools, SetProtectPlus, Multiscan, or Autobalance job runs to completion. Since these jobs can each perform a re-layout of data, this is when the files will be re-assigned to the desired pool. The file movement can be verified by running the following command from the OneFS CLI:
# isi get -dD <dir>
So the key is whether you’re doing a copy (that is, a new write) or not. As long as you’re doing writes and the parent directory of the destination has the appropriate file pool policy applied, you should get the behavior you want.
One thing to note: If the actual operation that is desired is really a move rather than a copy, it may be faster to change the file pool policy and then do a recursive “isi filepool apply –recurse” on the affected files.
There’s negligible difference between using an NFS or SMB client versus performing the copy on-cluster via the OneFS CLI. As mentioned above, using isi filepool apply will be slightly quicker than a straight copy and delete, since the copy is parallelized above the filesystem layer.
A file pool policy may be crafted which dictates that anything written to path /ifs/path1 is automatically moved directly to the Archive tier. This can easily be configured from the OneFS WebUI by navigating to File System > Storage Pools > File Pool Policies:
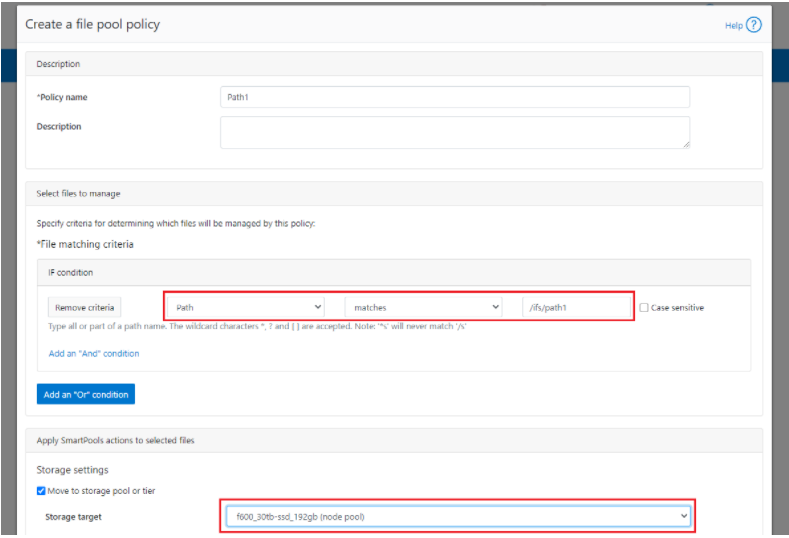
In the example above, a path based policy is created such that data written to /ifs/path1 will automatically be placed on the cluster’s F600 node pool.
For file Pool Policies that dictate placement of data based on its path, data typically lands on the correct node pool or tier without a SmartPools job running. File Pool Policies that dictate placement of data on other attributes besides path name get written to Disk Pool with the highest available capacity and then moved, if necessary, to match a File Pool policy, when the next SmartPools job runs. This ensures that write performance is not sacrificed for initial data placement.
Any data not covered by a File Pool policy is moved to a tier that can be selected as a default for exactly this purpose. If no Disk Pool has been selected for this purpose, SmartPools will default to the Node Pool with the most available capacity.
Be aware that, when reconfiguring an existing path-based filepool policy to target a different nodepool or tier, the change will not immediately take effect for the new incoming data. The directory where new files will be created must be updated first and there are a several options available to address this:
- Running the SmartPools job will achieve this. However, this can take a significant amount of time, as the job may entail restriping or migrating a large quantity of file data.
- Invoking the ’isi filepool apply <path>’ command on a single directory in question will do it very rapidly. This option is ideal for a single, or small number, of ‘incoming’ data directories.
- To update all directories in a given subtree, but not affect the files’ actual data layouts, use:
# isi filepool apply --dont-restripe --recurse /ifs/path1- OneFS also contains the SmartPoolsTree job engine job specifically for this purpose. This can be invoked as follows:
# isi job start SmartPoolsTree --directory-only --path /ifs/path
For example, a cluster has both an F600 pool and an A2000 pool. A directory (/ifs/path1) is created and a file (file1.txt) written to it:
# mkdir /ifs/path1 # cd !$; touch file1.txt
As we can see, this file is written to the default A2000 pool:
# isi get -DD /ifs/path1/file1.txt | grep -i pool * Disk pools: policy any pool group ID -> data target a2000_200tb_800gb-ssd_16gb:97(97), metadata target a2000_200tb_800gb-ssd_16gb:97(97)
Next, a path-based file pool policy is created such that files written to /ifs/test1 are automatically directed to the cluster’s F600 tier:
# isi filepool policies create test2 --begin-filter --path=/ifs/test1 --and --data-storage-target f600_30tb-ssd_192gb --end-filter
# isi filepool policies list Name Description CloudPools State ------------------------------------ Path1 No access ------------------------------------ Total: 1
# isi filepool policies view Path1 Name: Path1 Description: CloudPools State: No access CloudPools Details: Policy has no CloudPools actions Apply Order: 1 File Matching Pattern: Path == path1 (begins with) Set Requested Protection: - Data Access Pattern: - Enable Coalescer: - Enable Packing: - Data Storage Target: f600_30tb-ssd_192gb Data SSD Strategy: metadata Snapshot Storage Target: - Snapshot SSD Strategy: - Cloud Pool: - Cloud Compression Enabled: - Cloud Encryption Enabled: - Cloud Data Retention: - Cloud Incremental Backup Retention: - Cloud Full Backup Retention: - Cloud Accessibility: - Cloud Read Ahead: - Cloud Cache Expiration: - Cloud Writeback Frequency: - ID: Path1
The ‘isi filepool apply’ command is run on /ifs/path1 in order to activate the path-based file policy:
# isi filepool apply /ifs/path1
A file (file-new1.txt) is then created under /ifs/path1:
# touch /ifs/path1/file-new1.txt
An inspection shows that this file is written to the F600 pool, as expected per the Path1 file pool policy:
# isi get -DD /ifs/path1/file-new1.txt | grep -i pool * Disk pools: policy f600_30tb-ssd_192gb(9) -> data target f600_30tb-ssd_192gb:10(10), metadata target f600_30tb-ssd_192gb:10(10)
The legacy file (/ifs/path1/file1.txt) is still on the A2000 pool, despite the path-based policy. However, this policy can be enacted on pre-existing data by running the following:
# isi filepool apply --dont-restripe --recurse /ifs/path1
Now, the legacy files are also housed on the F600 pool, and any new writes to the /ifs/path1 directory will also be written to the F600s:
# isi get -DD file1.txt | grep -i pool * Disk pools: policy f600_30tb-ssd_192gb(9) -> data target a2000_200tb_800gb-ssd_16gb:97(97), metadata target a2000_200tb_800gb-ssd_16gb:97(97)
Author: Nick Trimbee