




Next-Generation Dell PowerEdge XR5610 Machine Learning Performance
Download PDFFri, 03 Mar 2023 20:01:50 -0000
|Read Time: 0 minutes
Summary
Dell Technologies has recently announced the launch of next-generation Dell PowerEdge servers that deliver advanced performance and energy-efficient design.
This Direct from Development Tech Note describes the new capabilities you can expect from the next generation of PowerEdge servers. It discusses the test and results for machine learning (ML) performance of the PowerEdge XR5610 using the industry-standard MLPerf Inference v2.1 benchmarking suite. The XR5610 has target workloads in networking and communication, enterprise edge, military, and defense—all key workloads requiring AI/ML inferencing capabilities at the edge.
The 1U single-socket XR5610 is an edge-optimized short-depth rugged 1U server powered by 4th Generation Intel® Xeon® Scalable processors with the MCC SKU stack. It includes the latest generation of technologies, with slots up to 8x DDR5 and two PCIe Gen5x16 card slots, and is capable of 46 percent faster image classification (reduced latency) workload as compared to the previous-generation PowerEdge XR12.
PowerEdge XR5610—Designed for the edge
Edge computing, in essence, brings compute power close to the source of the data. As Internet of Things (IoT) endpoints and other devices generate more and more time-sensitive data, edge computing becomes increasingly important. Machine learning (ML) and artificial intelligence (AI) applications are particularly suitable for edge computing deployments. The environmental conditions for edge computing are typically vastly different than those at centralized data centers. Edge computing sites, at best, might consist of little more than a telecommunications closet with minimal or no HVAC.
Dell PowerEdge XR5610 is a rugged, short-depth (400 mm class) 1U server for the edge, designed for deployment in locations constrained by space or environmental challenges. It is well suited to operate at high temperatures ranging from –5°C to 55°C (23°F to 131°F) and designed to excel with telecom vRAN workloads, military and defense deployments, and retail AI including video monitoring, IoT device aggregation, and PoS analytics.

Figure 1. Dell PowerEdge XR5610 – 1U
The emerging technology of edge intelligence
According to a recent Forrester report, “Edge intelligence, a top 10 emerging technology in 2022, helps capture data, embed inferencing, and connect insight in a real-time network of application, device, and communication ecosystems.”

Figure 2. Forrester report excerpt, reprinted with permission
MLPerf Inference workload summary
MLPerf Inference is a multifaceted benchmark framework, measuring four different workload types and three processing scenarios. The workloads are image classification, object detection, medical imaging, speech-to-text, and natural language processing (BERT). The processing scenarios, as outlined in the following table, are single stream, multistream, and offline.
Table 1. MLPerf Inference benchmark scenarios
Scenario | Performance metric | Use case |
Single stream | 90th latency percentile | Search results. Waits until the query is made and returns the search results. Example: Google voice search |
Multistream | 99th latency percentile | Multicamera monitoring and quick decisions. Acts more like a CCTV backend system that processes multiple real-time streams and identifies suspicious behaviors. Example: Self-driving car that merges all multiple camera inputs and makes drive decisions in real time |
Offline | Measured throughput | Batch processing, also known as offline processing. Example: Google Photos service that identifies pictures, tags people, and generates an album with specific people and locations or events offline |
The MLPerf suite for inferencing includes the following benchmarks:
Table 2. MLPerf suite for inferencing benchmarks
Area | Task | Model | Dataset | QSL size | Quality |
Vision | Image classification | Resnet50-v1.5 | ImageNet (224x224) | 1024 | 99% of FP32 (76.46%) |
Vision | Object detection | Retinanet | OpenImages (800x800) | 64 | 99% of FP32 (0.3755 mAP) |
Vision | Medical image segmentation | 3D UNET | KiTS 2019 | 42 | 99% of FP32 and 99.9% of FP32 (0.86330 mean DICE score) |
Speech | Speech-to-text | RNNT | Librispeech dev-clean (samples < 15 seconds) | 2513 | 99% of FP32 (1 – WER, where WER=7.452253714852645%) |
Language | Language processing | BERT | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% of FP32 (f1_score=90.874%) |
MLPerf Inference performance
The following table outlines the key specifications of the PowerEdge XR5610 that was used for the MLPerf Inference test suite.
Table 3. Dell PowerEdge XR5610 key specifications for MLPerf Inference test suite
Component | Specifications |
CPU | 4th Gen Intel Xeon Scalable processors MCC SKU |
Operating system | CentOS 8.2.2004 |
Memory | 256 GB |
GPU | NVIDIA A2 |
GPU count | 1 |
Networking | 1x ConnectX-5 IB EDR 100 Gbps |
Software stack |
|
Storage | NVMe SSD 1.8 TB |
Table 4 shows the specifications of the NVIDIA GPUs that were used in the benchmark tests.
Table 4. NVIDIA GPUs tested
GPU model | GPU memory | Maximum power consumption | Form factor | 2-way bridge | Recommended workloads |
PCIe adapter form factor | |||||
A2 | 16 GB GDDR6 | 60 W | SW, HHHL, or FHHL | Not applicable | AI inferencing, edge, VDI |
The edge server offloads the image processing to the GPU, and, just as servers have different price/performance levels to suit different requirements, so do GPUs. XR5610 supports up to 2x SW GPUs, as did the previous-generation XR11.
XR5610 was tested with the NVIDIA A2 GPU for the entire range of MLPerf workloads on the offline scenario. The following figure shows the results of the testing.
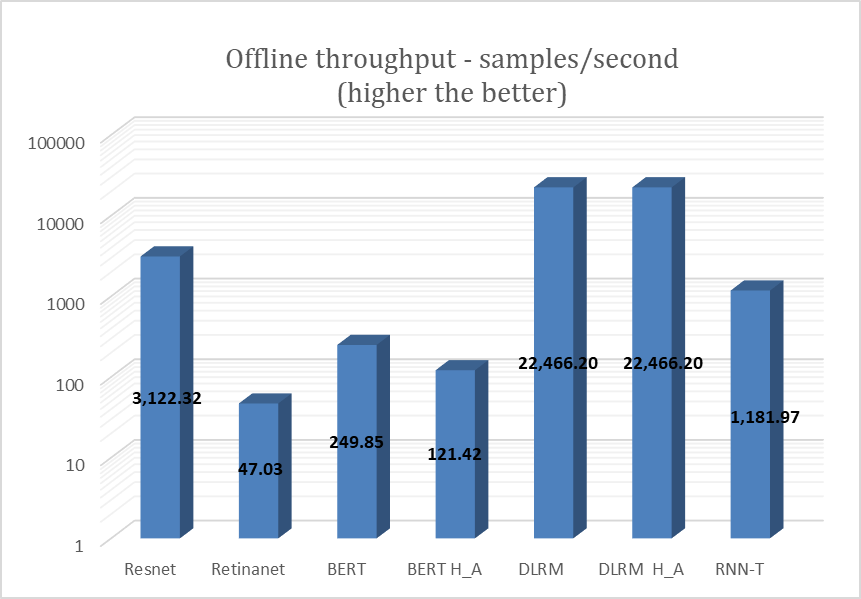
Figure 3. NVIDIA A2 GPU test results for MLPerf offline scenario
XR5610 also was tested with the NVIDIA A2 GPU for the entire range of MLPerf workloads on the single stream scenario. The following figure shows the results of that testing.
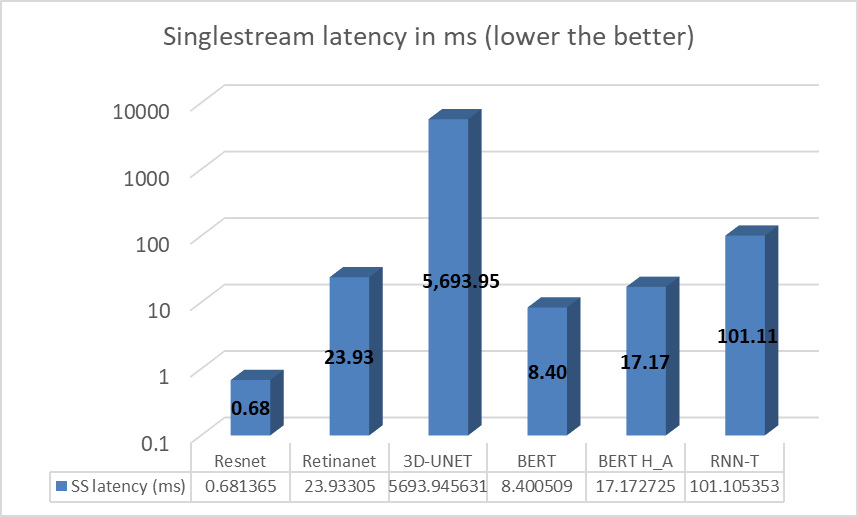
Figure 4. NVIDIA A2 GPU test results for MLPerf single stream scenario
In some tasks/workloads, the XR5610 showed improvement over previous generations, resulting from the integration of new technologies such as PCIe Gen 5.
Image classification
The PowerEdge XR5610 delivered 46 percent better image classification latency compared to the prior-generation PowerEdge server, as shown in the following figure.
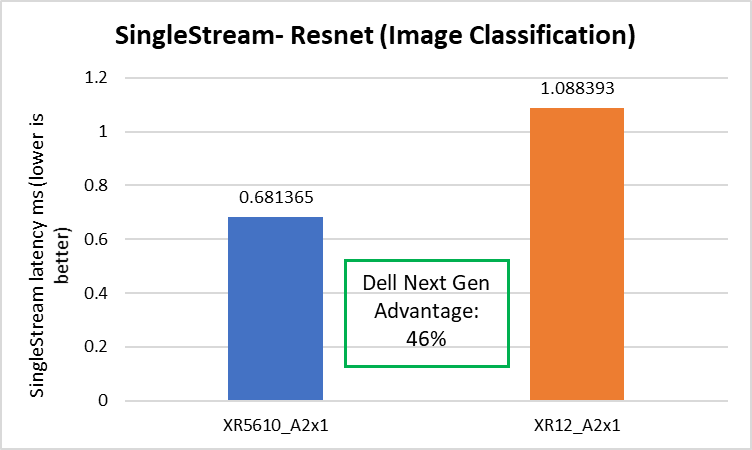
Figure 5. Image classification latencies: XR5610 and prior-generation PowerEdge server
Speech to text
The Dell XR5610 delivered 15 percent better speech-to-text throughput compared to the prior-generation PowerEdge server, as shown in the following figure.
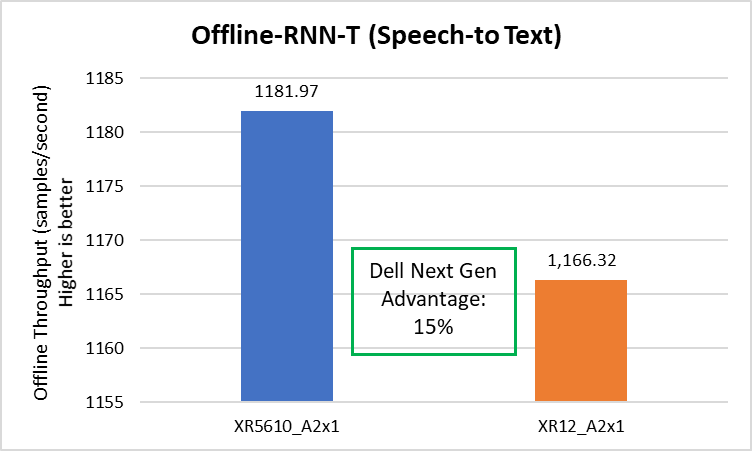
Figure 6. Speech to text latencies: XR5610 and prior-generation PowerEdge server
Conclusion
The PowerEdge XR portfolio continues to provide a streamlined approach for various edge and telecom deployment options based on different use cases. It provides a solution to the challenge of a small form factor at the edge with industry-standard rugged certifications (NEBS), providing a compact solution for scalability and for flexibility in a temperature range of –5°C to +55°C.
References
Notes:
- Based on testing conducted in Dell Cloud and Emerging Technology lab in January 2023. Results to be submitted to MLPerf in Q2, FY24.
- Unverified MLPerf v2.1 Inference. Result not verified by MLCommons Association. MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Related Documents

Multi-Instance GPU on the Edge
Fri, 03 Mar 2023 19:57:25 -0000
|Read Time: 0 minutes
Summary
Dell has recently announced the launch of Next-generation Dell PowerEdge servers that deliver advanced performance and energy efficient design.
This Direct from Development (DfD) tech note describes the new capabilities you can expect from the next-generation Dell PowerEdge servers powered by Intel 4th Gen Intel® Xeon® Scalable processors MCC SKU stack. This document covers the test and results for ML performance benchmarking for the offline scenario on Dell’s next generation PowerEdge XR 7620 using Multi-Instance GPU technology. XR7620 has target workloads in manufacturing, retail, defense, and telecom - all key workloads requiring AI/ML inferencing capabilities at the edge. Dell continues to provide scalability and flexibility with its latest short-depth XR servers portfolio, integrated with the latest technologies such as 4th Gen Intel CPU, PCIe Gen5, DDR5, NVMe drives, and GPU slots, along with compliance testing for NEBS and MIL-STD.
MIG overview
Multi-Instance GPU (MIG) expands the performance and value of NVIDIA H100, A100, and A30 Tensor Core GPUs. MIG can partition the GPU into as many as seven instances, each fully isolated with its own high-bandwidth memory, cache, and compute cores. This gives administrators the ability to support every workload, from the smallest to the largest, with guaranteed quality of service (QoS) and extending the reach of accelerated computing resources to every user.
Without MIG, different jobs running on the same GPU, such as different AI inference requests, compete for the same resources. A job-consuming larger memory bandwidth starves others, resulting in several jobs missing their latency targets. With MIG, jobs run simultaneously on different instances, each with dedicated resources for compute, memory, and memory bandwidth, resulting in a predictable performance with QoS and maximum GPU utilization.

Figure 1. Seven different instances with MIG
MIG at the edge
Dell defines edge computing as technology that brings compute, storage, and networking closer to the source where data is created. This enables faster processing of data, and consequently, quicker decision making and faster insights. For edge use cases such as running an edge server on a factory floor or in a retail store, requires multiple applications to run simultaneously. One solution to solve this problem can be to add a piece of hardware for each application, but this solution is not scalable or sustainable in the long run. Thus, deploying multiple applications on the same piece of hardware is an option but it can cause much higher latency for different applications.
With multiple applications running on the same device, the device time-slices the applications in a queue so that applications are run sequentially as opposed to concurrently. There is always a delay in results while the device switches from processing data for one application to another.
MIG is an innovative technology to use in such use cases for the edge, where power, cost, and space are important constraints. AI inferencing applications such as computer vision and image detection need to run instantaneously and continuously to avoid any serious consequences due to lack of safety.
Jobs running simultaneously with different resources result in predictable performance with quality of service and maximum GPU utilization. This makes MIG an essential addition to every edge deployment.
MIG can be used in a multitenant environment. It is different from virtual GPU technology because MIG is hardware based, which makes edge computing even more secure.
Provision and configure instances as needed
A GPU can be partitioned into different-sized MIG instances. For example, in an NVIDIA A100 40GB, an administrator could create two instances with 20 gigabytes (GB) of memory each, three instances with 10GB each, or seven instances with 5GB each, or a combination of these.
MIG instances can also be dynamically reconfigured, enabling administrators to shift GPU resources in response to changing user and business demands. For example, seven MIG instances can be used during the day for low-throughput inference and reconfigured to one large MIG instance at night for deep learning training.
System Config for Next Generation Dell PowerEdge XR Server MIG Testing
Table 1. System architecture
MLPerf system | Edge |
Operating System | CentOS 8.2.2004 |
CPU | 4th Gen Intel Xeon Scalable processors MCC SKU |
Memory | 512GB |
GPU | NVIDIA A100 |
GPU Count | 1 |
Networking | 1x ConnectX-5 IB EDR 100Gb/Sec |
Software Stack | TensorRT 8.4.2 CUDA 11.6 cuDNN 8.4.1 Driver 510.73.08 DALI 0.31.0 |
Table 2. MLPerf scenario used in this test and MIG specs
Scenario | Performance metric | Example use cases | |
Offline | Measured throughput | Batch processing aka Offline processing. Google photos identifies pictures, tags, and people and generates an album with specific people and locations/events offline. | |
MIG Specifications | A100 | ||
Instance types | 7x 10GB 3x 20GB 2x 40GB 1x 80GB | ||
GPU profiling and monitoring | Only one instance at a time | ||
Secure Tenants | 1x | ||
Media decoders | Limited options | ||
Table 3. High accuracy benchmarks and their degree of precision
| BERT | BERT H_A | DLRM | DLRM H_A | 3D-Unet | 3D-Unet H_A |
Precision | int8 | fp16 | int8 | int8 | int8 | int8 |
DLRM H_A and 3D-Unet H_A is the same as DLRM and 3D-unet respectively. They were able to reach the target accuracy with int8 precision.
Performance results
This section provides MIG performance results for various scenarios, showing that when divided into seven instances, each instance can provide equal performance without any loss in throughput.
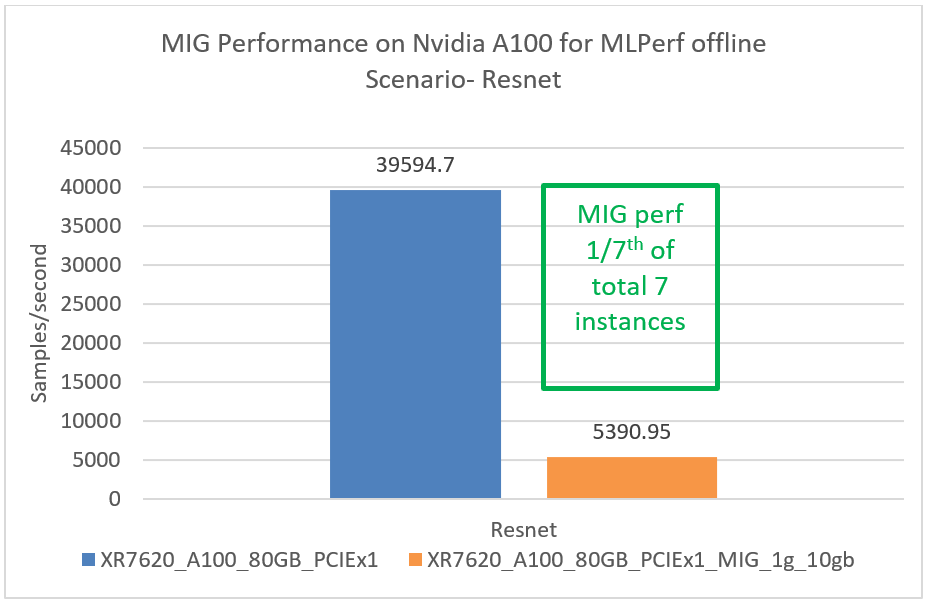
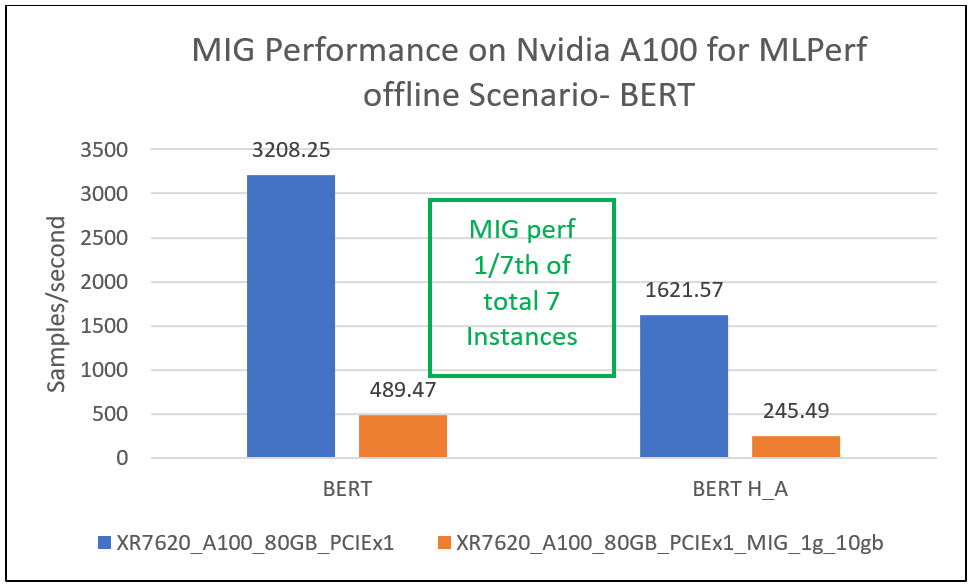
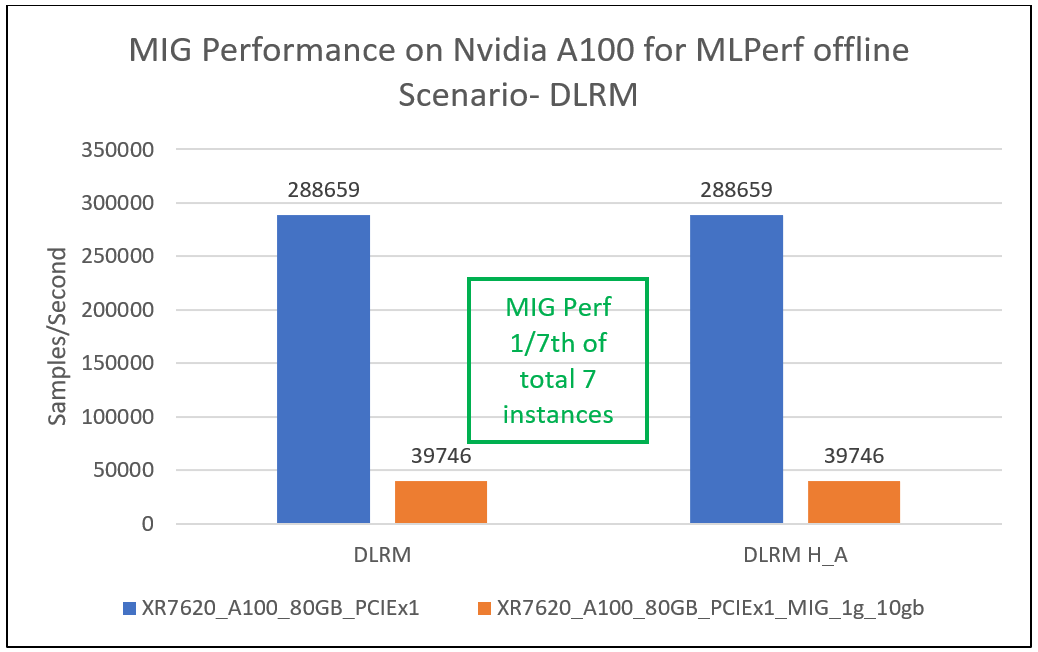
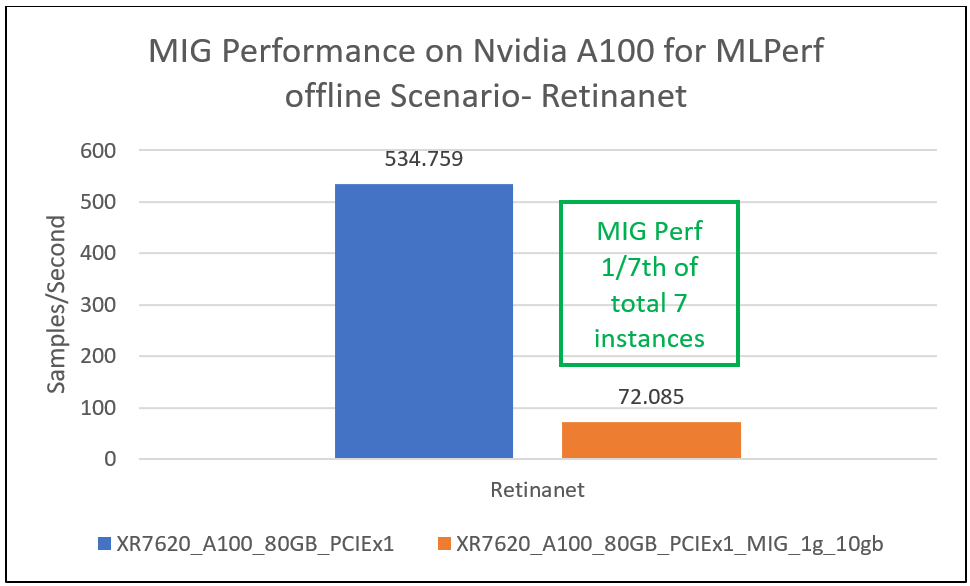
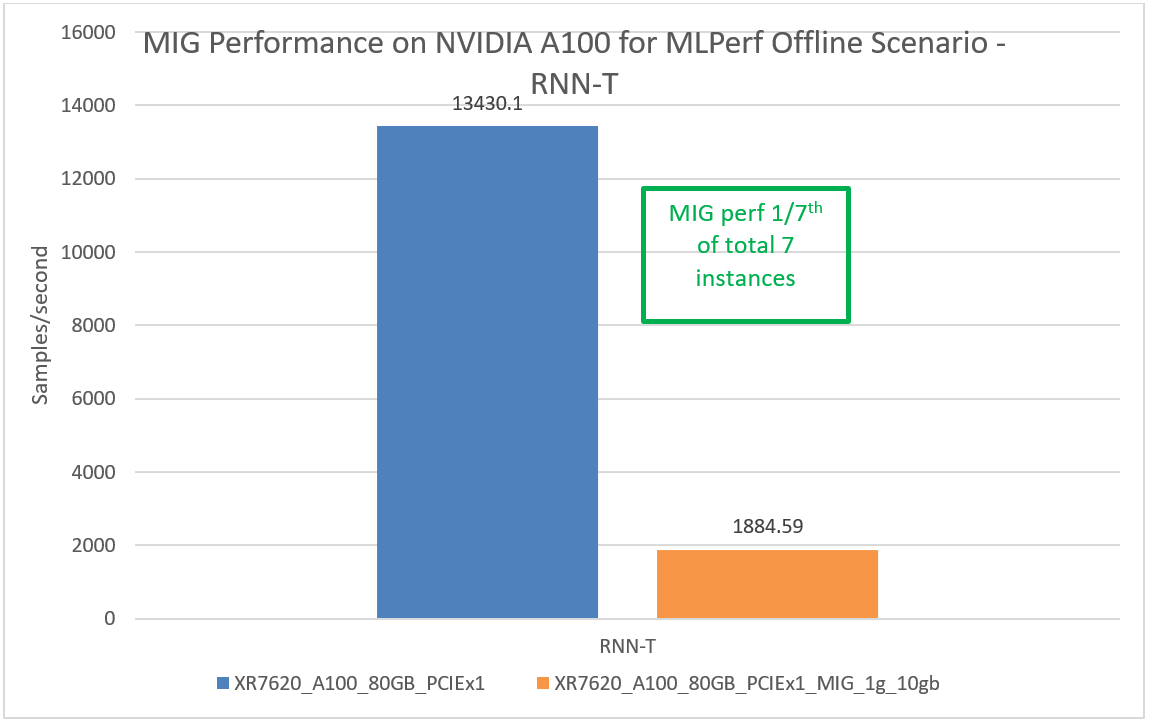
Conclusion
Dell XR portfolio continues to provide a streamlined approach for various edge and telecom deployment options based on different use cases. It provides a solution to the challenge of small form factors at the edge with industry-standard rugged certifications (NEBS) that provide a compact solution for scalability, and flexibility in a temperature range of -5 to +55°C. The MIG capability for MLPerf workloads provides real-life scenarios for showcasing AI/Ml inferencing on multiple instances for edge use cases. Based on the results in this document, Dell servers continue to provide a complete solution.
References
- https://www.nvidia.com/en-us/technologies/multi-instance-gpu
- Running Multiple Applications on the Same Edge Devices | NVIDIA Technical Blog
- MLPerf Inference Benchmark
Notes:
- Based on testing conducted in Dell Cloud and Emerging Technology lab in January 2023. Results to be submitted to MLPerf in Q2, FY24.
- Unverified MLPerf v2.1 Inference. Results not verified by MLCommons Association. MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.

Next Generation Dell PowerEdge XR7620 Server Machine Learning (ML) Performance
Fri, 03 Mar 2023 19:57:26 -0000
|Read Time: 0 minutes
Summary
Dell Technologies has recently announced the launch of next-generation Dell PowerEdge servers that deliver advanced performance and energy efficient design.
This Direct from Development (DfD) tech note describes the new capabilities you can expect from the next-generation Dell PowerEdge servers powered by Intel 4th Gen Intel® Xeon® Scalable processors MCC SKU stack. This document covers the test and results for ML performance of Dell’s next generation PowerEdge XR 7620 using the industry standard MLPerf Inference v2.1 benchmarking suite. XR7620 has target workloads in manufacturing, retail, defense, and telecom - all key workloads requiring AI/ML inferencing capabilities at the edge.
With up to 2x300W accelerator cards for GPUs to handle your most demanding edge workloads, XR7620 provides a 45% faster image classification workload as compared to the previous generation Dell XR 12 server with just one 300W GPU accelerator for the ML/AI scenarios at the enterprise edge. The combination of low latency and high processing power allows for faster and more efficient analysis of data, enabling organizations to make real-time decisions for more opportunities.
Edge computing
Edge computing, in a nutshell, brings computing power close to the source of the data. As the Internet of Things (IoT) endpoints and other devices generate more and more time-sensitive data, edge computing becomes increasingly important. Machine Learning (ML) and Artificial Intelligence (AI) applications are particularly suitable for edge computing deployments. The environmental conditions for edge computing are typically vastly different than those at centralized data centers. Edge computing sites might, at best, consist of little more than a telecommunications closet with minimal or no HVAC. Rugged, purpose-built, compact, and accelerated edge servers are therefore ideal for such deployments. The Dell PowerEdge XR7620 server checks all of those boxes. It is a high-performance, high-capacity server for the most demanding workloads, certified to operate in rugged, dusty environments ranging from -5C to 55C (23F to 131F), all within a short-depth 450mm (from ear-to-rack) form factor.
MLPerf Inference workload summary
MLPerf is a multi-faceted benchmark suite that benchmarks different workload types and different processing scenarios. There are five workloads and three processing scenarios. The workloads are:
- Image classification
- Object detection
- Medical image segmentation
- Speech-to-text
- Language processing
The scenarios are single-stream (SS), multi-stream (MS), and Offline.
The tasks are self-explanatory and are listed in the following table below, along with the dataset used, the ML model used, and descriptions. The single-stream tests reported results at the 90th percentile; multi-stream tests reported results at the 99th percentile.
Table 1. MLPerf Inference benchmark scenarios
Scenario | Performance metric | Example use cases |
Single-stream | 90% percentile latency | Google voice search: Waits until the query is asked and returns the search results. |
Offline | Measured throughput | Batch processing aka Offline processing. Google photos identifies pictures, tags people, and generates an album with specific people and locations/events Offline. |
Multi-stream | 99% percentile latency | Example 1: Multicamera monitoring and quick decisions. MultiStream is more like a CCTV backend system that processes multiple real-time streams on identifying suspicious behaviors. Example 2: Self driving cameras merge all multiple camera inputs and make drive decisions in real time. |
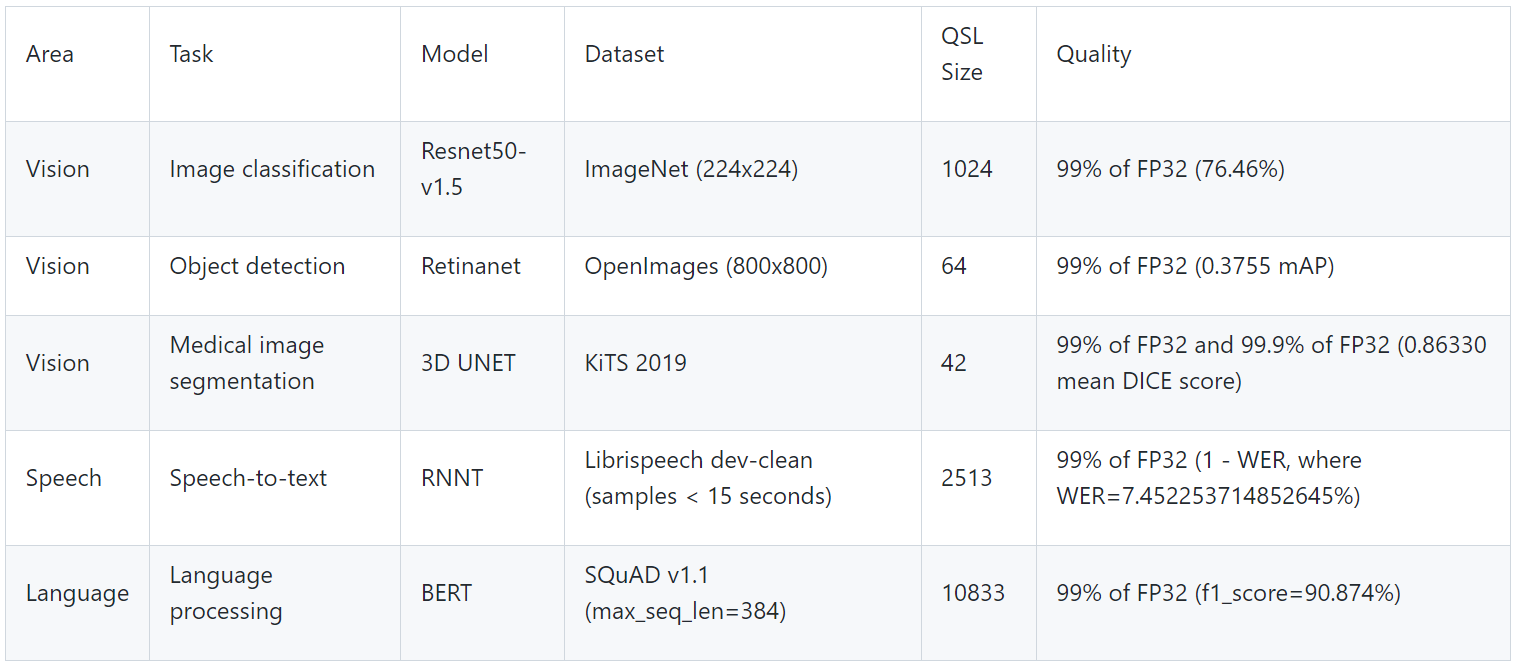
Table 2. MLPerf EdgeSuite for inferencing benchmarks
Industry reports about the future of edge computing
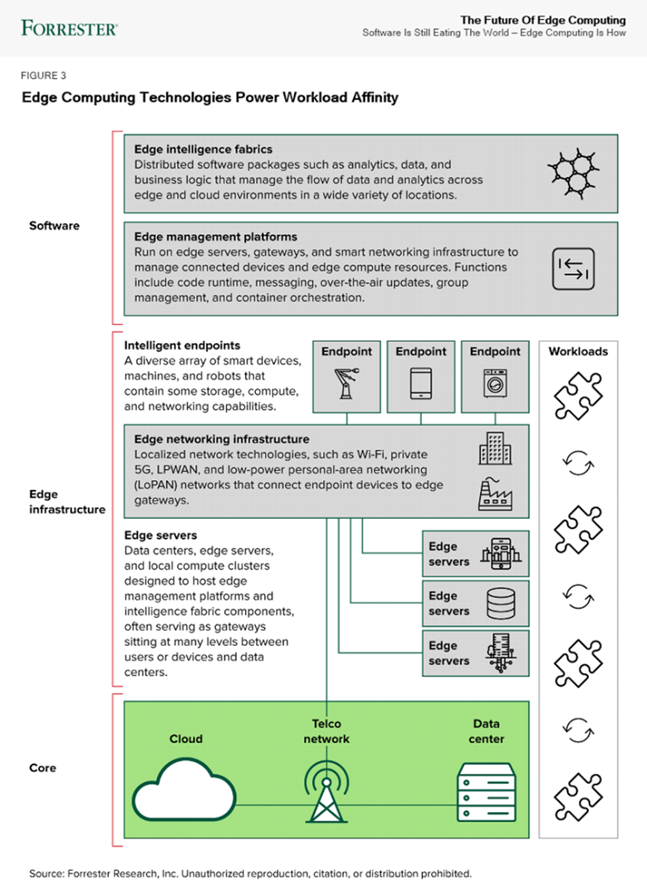
According to Forrester’s report (“Five technology elements make workload affinity possible across the four business scenarios”), most systems today are designed to run software in a single place. This creates performance limitations as conditions change, such as when more sensors are installed in a factory, as more people gather for an event, or as cameras receive more video feed. Workload affinity is the concept of using distributed applications to deploy software automatically where it runs best: in a data center, in the cloud, or across a growing set of connected assets. Innovative AI/ML, analytics, IoT, and container solutions enable new applications, deployment options, and software design strategies. In the future, systems will choose where to run software across a spectrum of possible locations, depending on the needs of the moment.
ML/AI inference performance
Table 3. Dell PowerEdge XR7620 key specifications
MLPerf system suite type | Edge |
Operating System | CentOS 8.2.2004 |
CPU | 4th Gen Intel® Xeon® Scalable processors MCC SKU |
Memory | 512GB |
GPU | NVIDIA A2 |
GPU Count | 1 |
Networking | 1x ConnectX-5 IB EDR 100Gb/Sec |
Software Stack | TensorRT 8.4.2 CUDA 11.6 cuDNN 8.4.1 Driver 510.73.08 DALI 0.31.0 |

Figure 1. Dell PowerEdge XR7620: 2U 2S
Table 4. NVIDIA GPUs Tested:
Brand | GPU | GPU memory | Max power consumption | Form factor | 2-way bridge | Recommended workloads |
PCIe Adapter Form Factor | ||||||
NVIDIA | A2 | 16 GB GDDR6 | 60W | SW, HHHL or FHHL | n/a | AI Inferencing, Edge, VDI |
NVIDIA | A30 | 24 GB HBM2 | 165W | DW, FHFL | Y | AI Inferencing, AI Training |
NVIDIA | A100 | 80 GB HBM2e | 300W | DW, FHFL | Y, Y | AI Training, HPC, AI Inferencing |
The edge server offloads the image processing to the GPU. And just as servers have different price/performance levels to suit different requirements, so do GPUs. XR7620 supports up to 2xDW 300W GPUs or 4xSW 150W GPUs, part of the constantly evolving scalability and flexibility offered by the Dell PowerEdge server portfolio. In comparison, the previous gen XR11 could support up to 2xSW GPUs.
Edge server vs data center server comparison[1]
When testing with NVIDIA A100 GPU for the Offline scenario, the Dell XR7620 delivered a performance with less than 1% difference, as compared to the prior generation Dell PowerEdge rack server. The XR7620 edge server with a depth of 430mm is capable of providing similar performance for an AI inferencing scenario as a rack server. See Figure 2.
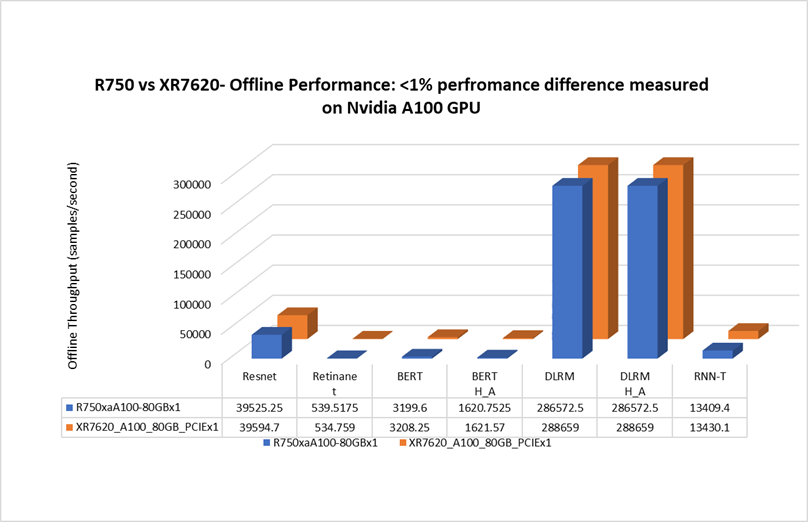
Figure 2. Rack vs edge server MLPerf Offline performance
XR7620 performance with NVIDIA A2 GPU
XR7620 was also tested with NVIDIA A2 GPU for the entire range of MLPerf workloads in the Offline scenario. For the results, see Figure 3.
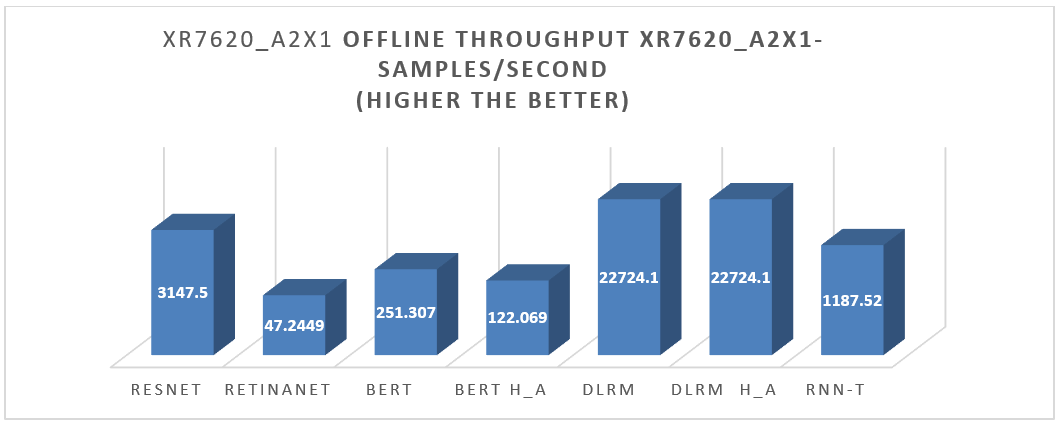
Figure 3. XR7620 Offline performance results
XR7620 was also tested with NVIDIA A2 GPU for the entire range of MLPerf workloads in the Single Stream scenario. See Figure 4.
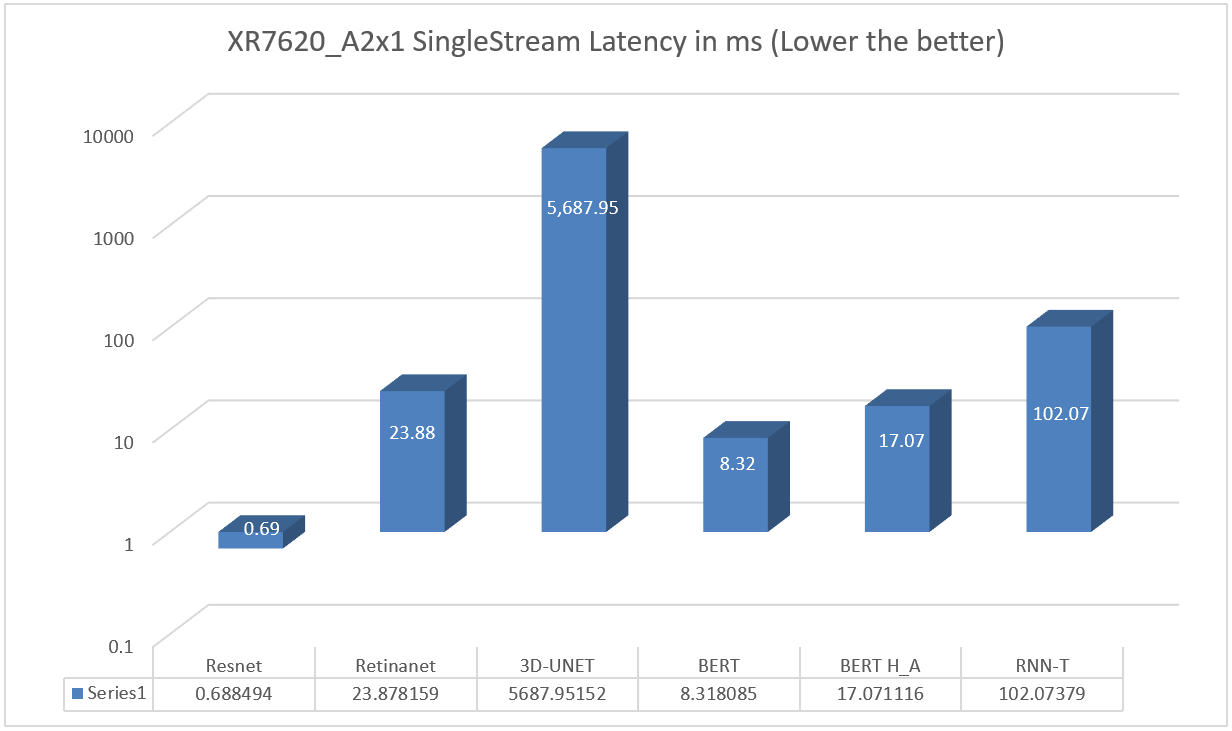
Figure 4. XR7620 Single Stream Performance results
XR7620 was also tested with NVIDIA A30 GPU for the entire range of MLPerf workloads in the Offline Scenario. See Figure 5.
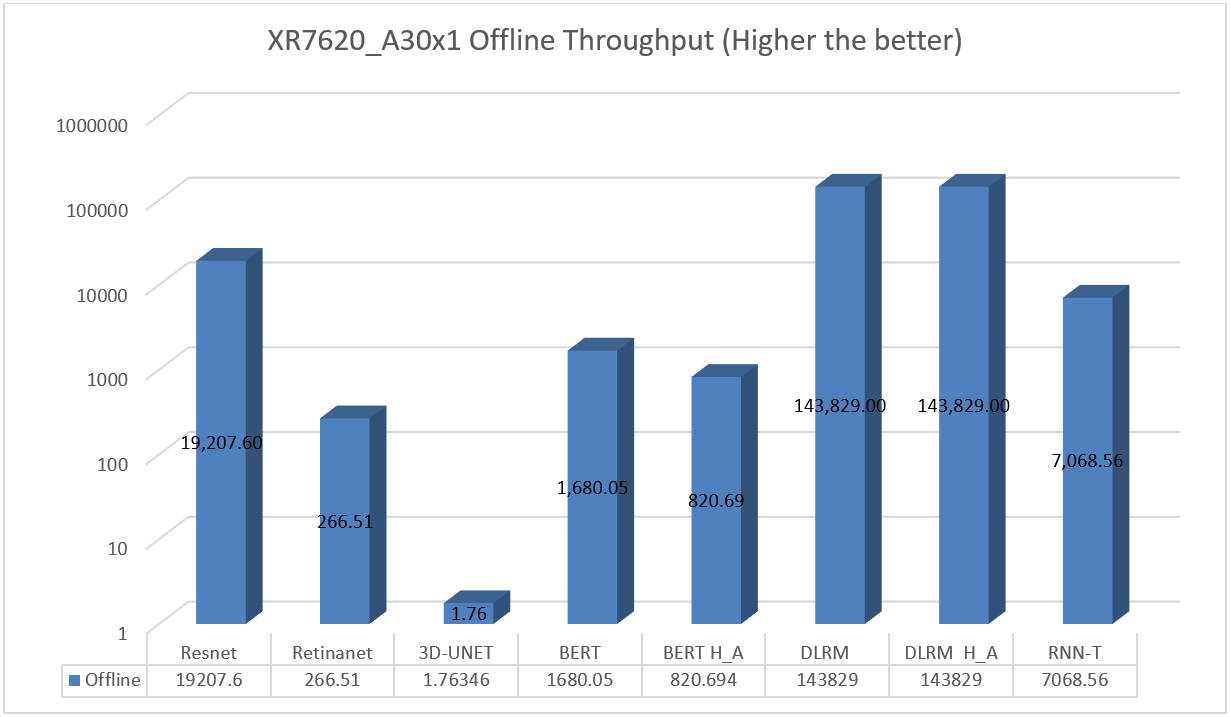
Figure 5. XR7620 Offline Performance results on A30 GPU
XR7620 was also tested with NVIDIA A30 GPU for the entire range of MLPerf workloads in the Single Scenario. See Figure 6.
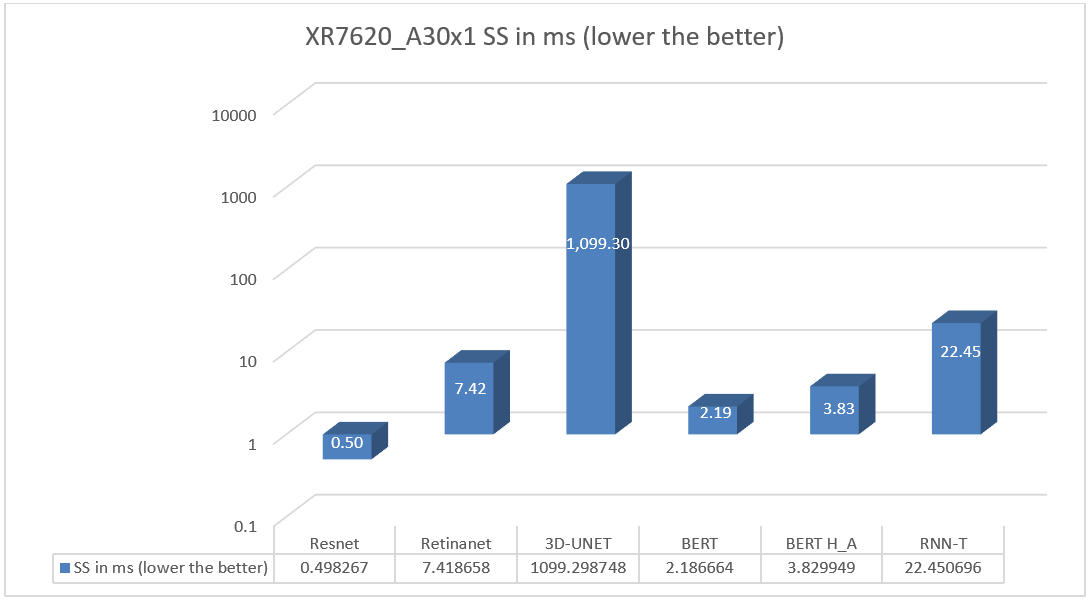
Figure 6. XR7620 SS Performance results on A30 GPU
In some scenarios, next generation Dell PowerEdge servers showed improvement over previous generations, due to the integration of the latest technologies such as PCIe Gen 5.
Speech to text
The Dell XR7620 delivered better throughput by 16%, as compared to the prior generation Dell server. See Figure 7
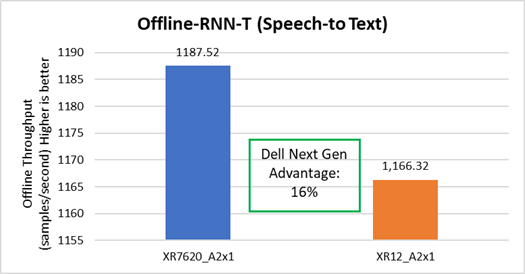
Figure 7. Offline Speech to Text performance improvement on XR7620
Image Classification
The Dell XR7620 delivered better latency by 45%, as compared to the prior generation Dell server. See Figure 8.
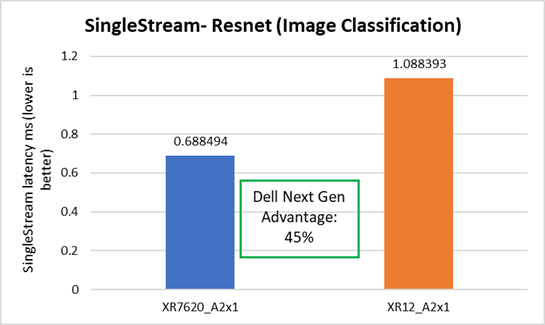
Figure 8. SS Image Classification performance improvement on XR7620
Conclusion
The Dell XR portfolio continues to provide a streamlined approach for various edge and telecom deployment options based on various use cases. It provides a solution to the challenge of small form factors at the edge with industry-standard rugged certifications (NEBS), with a compact solution for scalability and flexibility in a temperature range of -5 to +55°C. The MLPerf results provide a real-life scenario on edge inferencing for servers on AI inferencing. Based on the results in this document, Dell servers continue to provide a complete solution.
References
Notes:
- Based on testing conducted in Dell Cloud and Emerging Technology lab, January 2023. Results to be submitted to MLPerf in Q2,FY24.
- Unverified MLPerf v2.1 Inference. Results not verified by MLCommons Association. MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
[1] Based on testing conducted in Dell Cloud and Emerging Technology lab, January 2023.