




Mowing the DbaaS Weeds Without --Force

With the release of a recent paper that I had the pleasure to co-author, Building a Hybrid Database-as-a-Service Platform with Azure Stack HCI, I wanted to continue to author some additional interesting perspectives, and dive deep into the DbaaS technical weeds.
That recent paper was a refresh of a previous paper that we wrote roughly 16 months ago. That time frame is an eternity for technology changes. It was time to refresh with tech updates and some lessons learned.
The detail in the paper describes an end-to-end Database as a Service solution with Dell and Microsoft product offerings. The entire SysOps, DevOps, and DataOps teams will appreciate the detail in the paper. DbaaS actually realized.
One topic that was very interesting to me was our analysis and resource tuning of Kubernetes workloads. With K8s (what the cool kids say), we have the option to configure our pods with a very tightly defined resource allocation, both requested and limits, for both CPU and memory.
A little test harness history
First, a little history from previous papers with my V1 test harness. I first started working through an automated test harness constructed by using the HammerDB CLI, T-SQL, PowerShell, and even some batch files. Yeah, batch files… I am that old. The HammerDB side of the harness required a sizable virtual machine with regard to CPU and memory—along with the overhead and maintenance of a full-blown Windows OS, which itself requires a decent amount of resource to properly function. Let’s just say this was not the optimal way to go about end-to-end testing, especially with micro-services as an integral part of the harness.
Our previous test harness architecture is represented by this diagram:
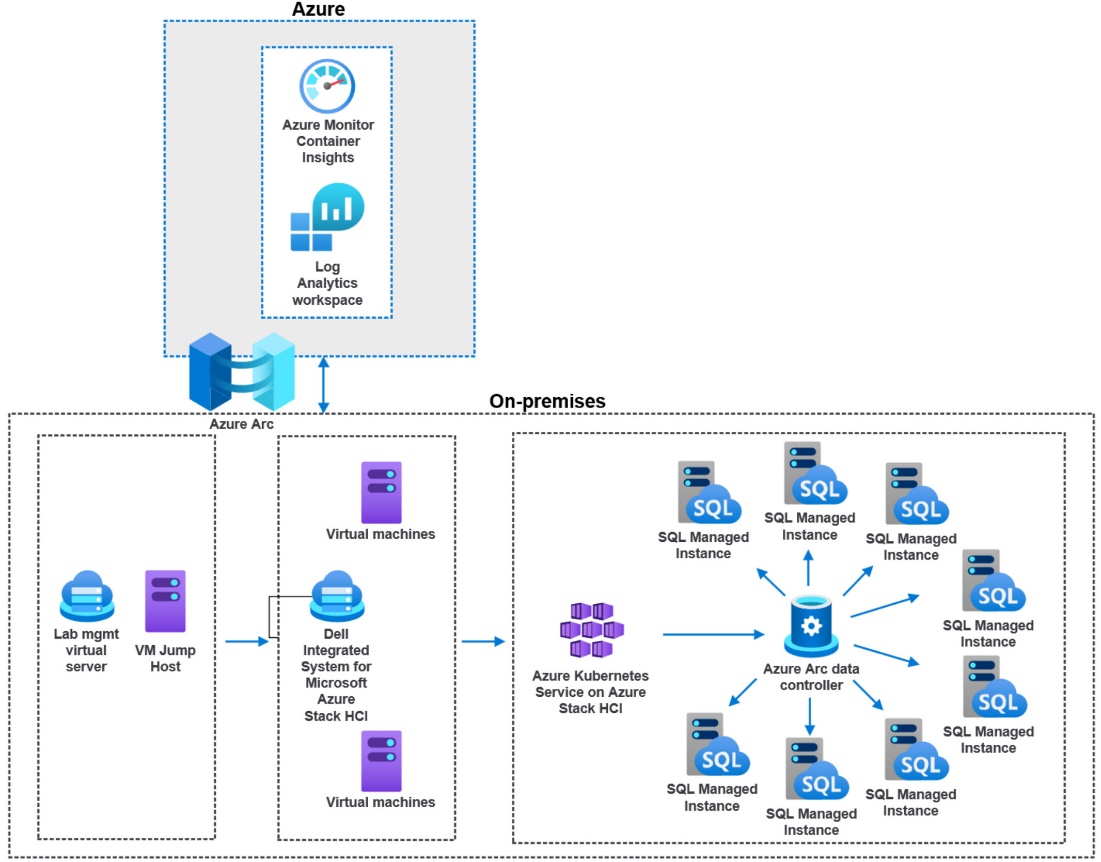
The better answer would be to use micro-services for everything. We were ready and up for the task. This is where I burned some quality cycles with another awesome Dell teammate to move the test harness into a V2 configuration. We decided to use HammerDB within a containerized deployment.
Each HammerDB in a container would map to a separate SQL MI (referenced in the image below). I quickly saw some very timely configuration opportunities where I could dive into resource consolidation. Both the application and the database layers were deployed into their own Kubernetes namespaces. This allowed us a much better way to provide fine-grained resource reporting analysis.
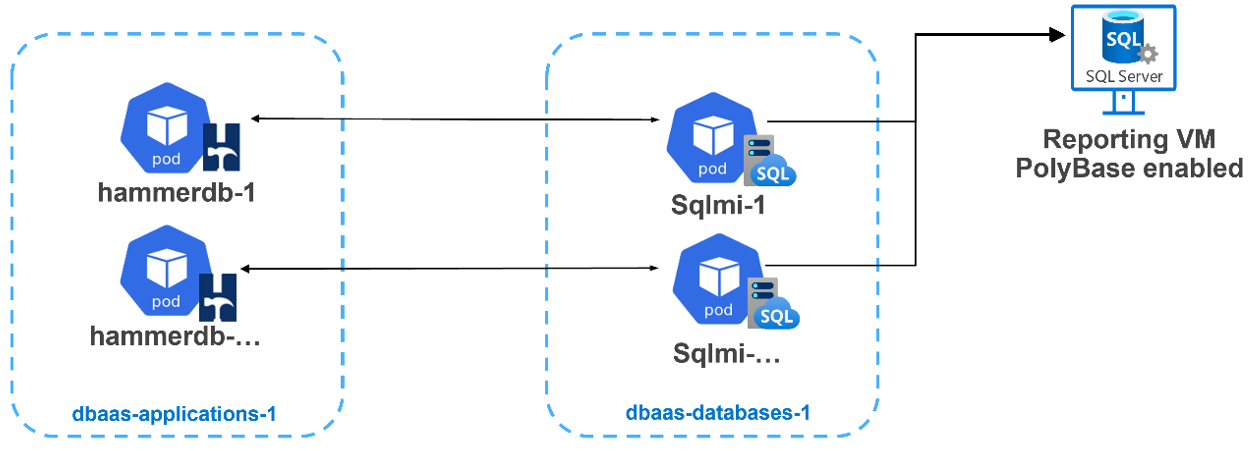
There is a section within our paper regarding the testing we worked through, comparing Kubernetes requests and limits for CPU and memory. For an Azure Arc-enabled SQL managed instance, defining these attributes is required and there are minimums as defined by Microsoft here. But where do you start? How do we size a pod? There are a few pieces of the puzzle to consider:
- What is the resource allocation of each Kubernetes worker node (virtual or physical)— CPU and memory totals?
- How many of these worker nodes exist? Can we scale? Should we use anti-affinity rules? (Not that it is better to let the scheduler sort it out.)
- Kubernetes does have its own overhead. A conservative resource allocation would allow for at least 20 percent overhead for each worker node.
For DbaaS CPU, how do we define our requests and limits?
We know a SQL managed instance is billed on CPU resource limits and not CPU resource requests. This consumption billing leaves us with an interesting paradigm. With any modern architecture, we want to maximize our investment with a very dense, but still performant, SQL Server workload environment. We need to strike a balance.
With microservices, we can finally achieve real consolidation for workloads.
Real… Consolidation...
What do we know about the Kubernetes scheduler around CPU?
- A request for a pod is a guaranteed baseline for the pod. When a pod is initially scheduled and deployed, the request attribute is used.
- Setting a CPU request is a solid best practice when using Kubernetes. This setting does help the scheduler allocate pods efficiently.
- The limit is the hard “limit” that that pod can consume. The CPU limit only affects how the spare CPU is distributed. This is good for a dense and highly consolidated SQL MI deployment.
- With Kubernetes, CPU represents compute processing time that is measured in cores. The minimum is 1m. My HammerDB pod YAML references 500m, or half a core.
- With a CPU limit, you are defining a period and a quota.
- CPU is a compressible resource, and it can be stretched. It can also be throttled if processes request too much.
Let go of the over-provisioning demons
It is time to let go of our physical and virtual machine sizing constructs, where most SQL Server deployments are vastly over-provisioned. I have analyzed and recommended better paths forward for over-provisioned machines for years.
- For SQL Server, do we always consume the limit, or max CPU, 100 percent of the time? I doubt it. Our workloads almost always go up and down—consuming CPU cycles, then pulling back and waiting for more work.
- For workload placement, the scheduler—by the transitive property—therein defines our efficiency and consolidation automatically. However, as mentioned, we do need to reference a CPU limit because it is required.
- There is a great deal of Kubernetes CPU sizing guidance to not use limits; however, for a database workload, this is a good thing, not to mention a requirement and good fundamental database best practice.
- Monitor your workloads with real production-like work to derive the average CPU utilization. If CPU consumption percentages remain low, throttle back the CPU requests and limits.
- Make sure that your requests are accurate for SQL Server. We should not over-provision resource “just because” we may need them.
- Start with half the CPU you had allocated for the same SQL Server running in a virtual machine, then monitor. If still over-provisioned, decrease by half again.
Kubernetes also exists in part to terminate pods that are no longer needed or no longer consuming resources. In fact, I had to fake out the HammerDB container with a “keep-alive” within my YAML file to make sure that the pod remained active long enough to be called upon to run a workload. Notice the command:sleep attribute in this YAML file:
apiVersion: v1 kind: Pod metadata: name: <hammerpod> namespace: <hammernamespace> spec: containers: - name: <hammerpod> image: dbaasregistry/hammerdb:latest command: - "sleep" - "7200" resources: requests: memory: "500M" cpu: "500m" limits: memory: "500M" cpu: "500m" imagePullPolicy: IfNotPresent
Proving out the new architecture
Our new fully deployed architecture is depicted below, with a separation of applications, in this case HammerDB from SQL Server, deployed into separate namespaces. This allows for tighter resource utilization, reporting, and tuning.
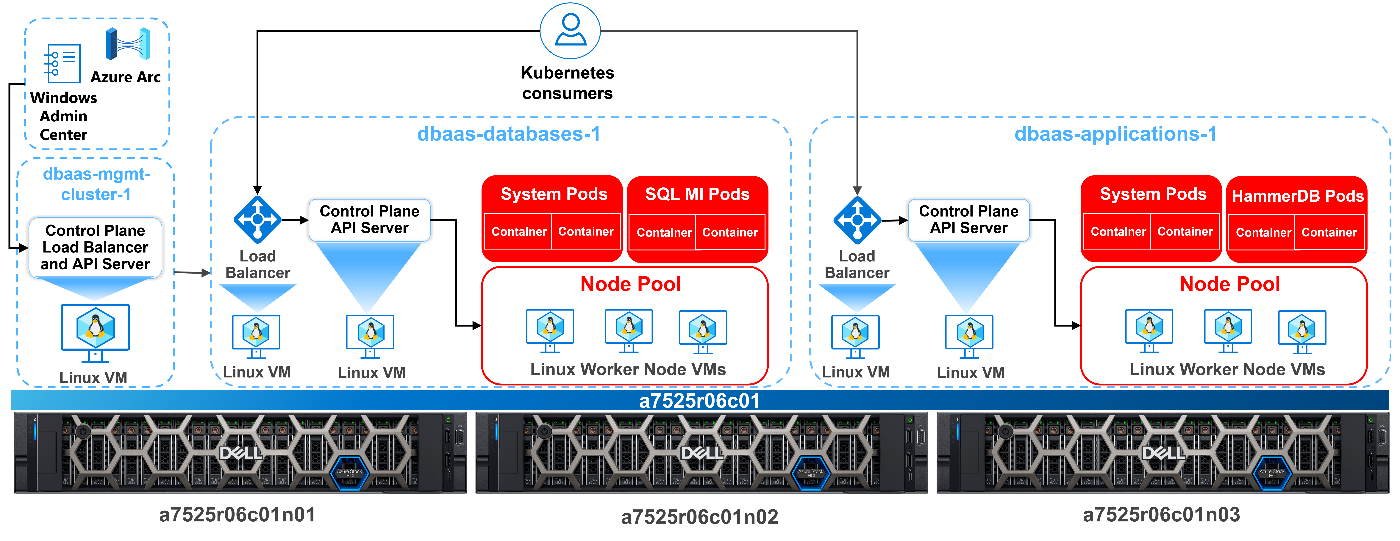
It's also important to note that setting appropriate resources and limits is just one aspect of optimizing your Azure Arc-enabled data services deployment. You should also consider other factors, such as storage configuration, network configuration, and workload characteristics, to ensure that your microservice architecture runs smoothly and efficiently.
Scheduled CPU lessons learned
The tests we conducted and described in the paper gave me some enlightenment regarding proper database microservice sizing. Considering our dense SQL MI workload, we again wanted to maximize the amount of SQL instances we could deploy and keep performance at an acceptable level. I also was very mindful of our consumption-based billing based on CPU limit. For all my tests, I did keep memory as a constant, as it is a finite resource for Kubernetes.
What I found is that performance was identical, and it was even better in some cases when:
- I set CPU requested to half the limit, letting the Kubernetes scheduler do what it is best at—managing resources.
- I monitored the tests and watched resource consumption, tightening up allocation where I could.
My conclusion is this: It is time to let go and not burn my own thinking analysis on trying to outsmart the scheduler. I have better squirrels to go chase and rabbit holes to dive into. 😊
Embrace the IT polyglot mindset
To properly engage and place the best practice stake in the ground, I needed to continue to embrace my polyglot persona. Use all the tools while containerizing all the things! I wrote about this previously here.
I was presenting on the topic of Azure Arc-enabled data services at a recent conference. I have a conversation slide that has a substantial list of tools that I use in my test engineering life. The question was asked, “Do you think all GUI will go away and scripting will again become the norm?” I explained that I think that all tools have their place, depending on the problem or deployment you are working through. For me, scripting is vital for repeatable testing success. You can’t check-in a point-and-click deployment.
There are many GUI tools for Linux and Kubernetes and others. They all have their place, especially when managing very large environments. I do also believe that honing your script skills first is best. Then you understand and appreciate the GUI.
Being an IT polyglot means that you have a broad understanding of various technologies and how they can be used to solve different problems. It also means that you can communicate effectively with developers and other stakeholders, from tin to “C-level” who may have expertise in different areas.
For most everything I do with Azure Arc, I first turn to command line tools, CLI or kubectl to name a few. I love the fact that I can script, check in my work, or feed into a GitOps pipe, and forget about it. It always works on my machine. 😉
To continue developing your skills as an IT polyglot, it's important to stay up to date with the latest industry trends and technologies. This can be done by attending conferences, reading industry blogs and publications, participating in online communities, and experimenting with new tools and platforms. As I have stated in other blogs… #NeverStopLearning
Author: Robert F. Sonders
Technical Staff – Engineering Technologist
Multicloud Storage Software
@RobertSonders | |
robert.sonders@dell.com | |
Blog | https://www.dell.com/en-us/blog/authors/robert-f-sonders/ |
Location | Scottsdale AZ, USA (GMT-7) |
Related Blog Posts

Why Canonicalization Should Be a Core Component of Your SQL Server Modernization (Part 2)
Wed, 12 Apr 2023 16:01:55 -0000
|Read Time: 0 minutes
In Part 1 of this blog series, I introduced the Canonical Model, a fairly recent addition to the Services catalog. Canonicalization will become the north star where all newly created work is deployed to and managed, and it’s simplified approach also allows for vertical integration and solutioning an ecosystem when it comes to the design work of a SQL Server modernization effort. The stack is where the “services” run—starting with bare-metal, all the way to the application, with seven layers up the stack.
In this blog, I’ll dive further into the detail and operational considerations for the 7 layers of the fully supported stack and use by way of example the product that makes my socks roll up and down: a SQL Server Big Data Cluster. The SQL BDC is absolutely not the only “application” your IT team would address. This conversation is used for any “top of stack application” solutions. One example is Persistent Storage – for databases running in a container. We need to solution for the very top (SQL Server) and the very bottom (Dell Technologies Infrastructure). And, many optional permutation layers.
First, a Word About Kubernetes
One of my good friends at Microsoft, Buck Woody, never fails to mention a particular truth in his deep-dive training sessions for Kubernetes. He says, “If your storage is not built on a strong foundation, Kubernetes will fall apart.” He’s absolutely correct.
Kubernetes or “K8s” is an open-source container-orchestration system for automating deployment, scaling, and management of containerized applications and is the catalyst in the creation of many new business ventures, startups, and open-source projects. A Kubernetes cluster consists of the components that represent the control plane and includes a set of machines called nodes.
To get a good handle on Kubernetes, give Global Discipline Lead Daniel Murray’s blog a read, “Preparing to Conduct Your Kubernetes Orchestra in Tune with Your Goals.”
The 7 Layers of Integration Up the Stack
 Let’s look at the vertical integration one layer at a time. This process and solution conversation is very fluid at the start. Facts, IT desires, best practice considerations, IT maturity, is currently all on the table. For me, at this stage, there is zero product conversation. For my data professionals, this is where we get on a white board (or virtual white board) and answer these questions:
Let’s look at the vertical integration one layer at a time. This process and solution conversation is very fluid at the start. Facts, IT desires, best practice considerations, IT maturity, is currently all on the table. For me, at this stage, there is zero product conversation. For my data professionals, this is where we get on a white board (or virtual white board) and answer these questions:
- Any data?
- Anywhere?
- Any way?
Answers here will help drive our layer conversations.
From tin to application, we have:
Layer 1
The foundation of any solid design of the stack starts with Dell Technologies Solutions for SQL Server. Dell Technologies infrastructure is best positioned to drive consistency up and down the stack and its supplemented by the company’s subject matter experts who work with you to make optimal decisions concerning compute, storage, and back up.

The requisites and hardware components of Layer 1 are:
- Memory, storage class memory (PMEM), and a consideration for later—maybe a bunch of all-flash storage. Suggested equipment: PowerEdge.
- Storage and CI component. Considerations here included use cases that will drive decisions to be made later within the layers. Encryption and compression in the mix? Repurposing? HA/DR conversations are also potentially spawned here. Suggested hardware: PowerOne, PowerStore, PowerFlex. Other considerations – structured or unstructured? Block? File? Object? Yes to all! Suggested hardware: PowerScale, ECS
- Hard to argue the huge importance of a solid backup and recovery plan. Suggested hardware: PowerProtect Data Management portfolio.
- Dell Networking. How are we going to “wire up”—Converged or Hyper-converged, or up the stack of virtualization, containerization and orchestration? How are all those aaS’es going to communicate? These questions concern the stack relationship integration and a key component to getting right.
Note: All of Layer 1 should consist of Dell Technologies products with deployment and support services. Full stop.
Layer 2
Now that we’ve laid our foundation from Dell Technologies, we can pivot to other Dell ecosystem solution sets as our journey continues, up the stack. Let’s keep going.
Considerations for Layer 2 are:

- Are we sticking with physical tin (bare-metal)?
- Should we apply a virtualization consolidationfactor here? ESXi, Hyper-V, KVM? Virtualization is “optional” at this point. Again, the answers are fluid right now and it’s okay to say, “it depends.” We’ll get there!
- Do we want to move to open-source in terms of a fully supported stack? Do we want the comfort of a supported model? IMO, I like a fully supported model although it comes at a cost. Implementing consolidation economics, however, like I mentioned above with virtualization and containerization, equals doing more with less.
Note: Layer 2 is optional (dependent upon future layers) and would be fully supported by either Dell Technologies, VMware or Microsoft and services provided by Dell Technologies Services or VMware Professional Services.
Layer 3
Choices in Layer 3 help drive decision or maturity curve comfort level all the way back to Layer 1. Additionally, at this juncture, we’ll also start talking about subsequent layers and thinking about the orchestration of Containers with Kubernetes.

Considerations and some of the purpose-built solutions for Layer 3 include:
- Software-defined everything such as Dell Technologies PowerFlex (formally VxFlex).
- Network and storage such as The Dell Technologies VMware Family – vSAN and the Microsoft Azure Family on-premises servers – Edge, Azure Stack Hub, Azure Stack HCI.
As we are walking through the journey to a containerized database world, at this level, is where we also need to start thinking about the CSI (Container Storage Interface) driver and where it will be supported.
Note: Layer 3 is optional (dependent upon future layers) and would be fully supported by either Dell Technologies, VMware or Microsoft and services provided by Dell Technologies Services or VMware Professional Services.
Layer 4
Ah, we’ve climbed up four rungs on the ladder and arrived at the Operating System where things get really interesting! (Remember the days when OS was tin and an OS?)

Considerations for Layer 4 are:
- Windows Server. Available in a few different forms—Desktop experience, Core, Nano.
- Linux OS. Many choices including RedHat, Ubuntu, SUSE, just to name a few.
Note: Do you want to continue the supported stack path? If so, Microsoft and RedHat are the answers here in terms of where you’ll reach for “phone-a-friend” support.
Option: We could absolutely stop at this point and deploy our application stack. Perfectly fine to do this. It is a proven methodology.
Layer 5
Container technology – the ability to isolate one process from another – dates back to 1979. How is it that I didn’t pick this technology when I was 9 years old?  Now, the age of containers is finally upon us. It cannot be ignored. It should not be ignored. If you have read my previous blogs, especially “The New DBA Role – Time to Get your aaS in Order,” you are already embracing SQL Server on containers. Yes!
Now, the age of containers is finally upon us. It cannot be ignored. It should not be ignored. If you have read my previous blogs, especially “The New DBA Role – Time to Get your aaS in Order,” you are already embracing SQL Server on containers. Yes!


Considerations and options for Layer 5, the “Container Control plane” are:
- VMware VCF 4.
- RedHat OpenShift (with our target of a SQL 2019 BDC, we need 4.3+).
- AKS (Azure Kubernetes Service) – on-premises with Azure Stack Hub.
- Vanilla Kubernetes (The original Trunk/Master).
Note: Containers are absolutely optional here. However, certain options, in these layers, that will provide the runway for containers in the future. Virtualization of data and containerization of data can live on the same platform! Even if you are not ready currently. It would be good to setup for success now. Ready to start with containers, within hours, if needed.
Layer 6
The Container Orchestration plane. We all know about Virtualization sprawl. Now, we have container sprawl! Where are all these containers running? What cloud are they running? Which Hypervisor? It’s best to now manage through a single pane of glass—understanding and managing “all the things.”
 Considerations for Layer 6 are:
Considerations for Layer 6 are:
Note: As of this blog publish date Azure Arc is not yet GA, it’s still in preview. No time like the present to start learning Arc’s in’s and out’s! Sign up for the public preview.
Layer 7
Finally, we have reached the application layer in our SQL Server Modernization. We can now install SQL Server, or any ancillary service offering in the SQL Server ecosystem. But hold on! There are a couple options to consider: Would you like your SQL services to be managed and “Always Current?” For me, the answer would be yes. And remember, we are talking about on-premises data here.

Considerations for Layer 7:
- The application for this conversation is SQL Server 2019.
- The appropriate decisions in building you stack will lead you to Azure Arc Data Services (currently in Preview), SQL Server and Kubernetes is a requirement here.
Note: With Dell Technologies solutions, you can deploy at your rate, as long as your infrastructure is solid. Dell Technologies Services has services to move/consolidate and/or upgrade old versions of SQL Server to SQL Server 2019.
The Fully Supported Stack
In terms of considering all the choices and dependencies made at each layer of building and integrating the 7 layers up the stack, there is a fully supported stack available that includes services and products from:
- Dell Technologies
- VMware
- RedHat
- Microsoft
Also, there are absolutely many open-source choices that your teams can make along the way. Perfectly acceptable to do. In the end, it comes down to who wants to support what, and when.
Dell Technologies Is Here to Help You Succeed
There are deep integration points for the fully supported stack. I can speak for all permutations representing the four companies listed above. In my role at Dell Technologies, I engage with senior leadership, product owners, engineers, evangelists, professional services teams, data scientists—you name it. We all collaborate and discuss what is best for you, the client. When you engage with Dell Technologies for the complete solution experience, we have a fierce drive to make sure you are satisfied, both in the near and long term. Find out more about our products and services for Microsoft SQL Server.
I invite you to take a moment to connect with a Dell Technologies Service Expert today and begin moving forward to your fully-support stack / SQL Server Modernization.
Why Canonicalization Should Be a Core Component of Your SQL Server Modernization (Part 1)
Tue, 23 Mar 2021 13:00:57 -0000
|Read Time: 0 minutes
The Canonical Model, Defined
A canonical model is a design pattern used to communicate between different data formats; a data model which is a superset of all the others (“canonical”) and creates a translator module or layer to/from which all existing modules exchange data with other modules [1]. It’s a form of enterprise application integration that reduces the number of data translations, streamlines maintenance and cost, standardizes on agreed data definitions associated with integrating business systems, and drives consistency in providing common data naming, definition and values with a generalized data framework.
SQL Server Modernization
I’ve always been a data fanatic and forever hold a special fondness for SQL Server. As of late, my many clients have asked me: “How do we embark on era of data management for the SQL Server stack?”
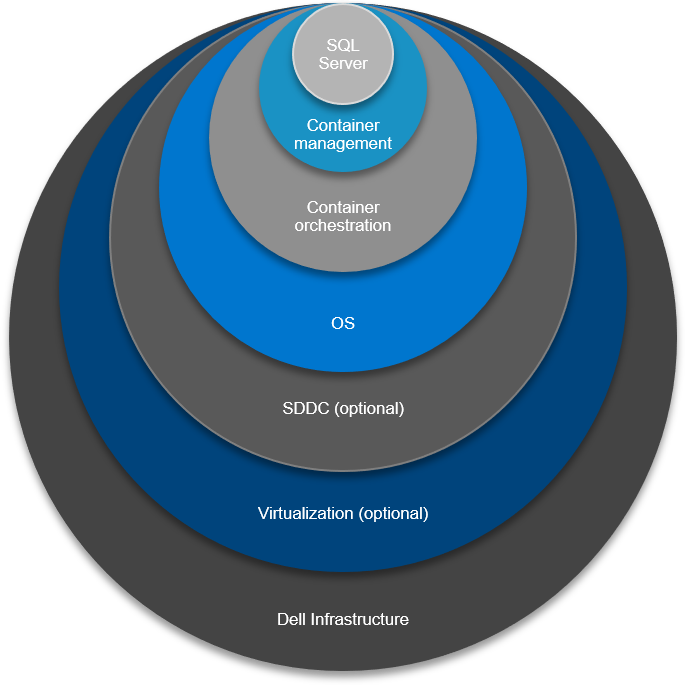
Canonicalization, in fact, is very much applicable to the design work of a SQL Server modernization effort. It’s simplified approach allows for vertical integration and solutioning an entire SQL Server ecosystem. The stack is where the “Services” run—starting with bare-metal, all the way to the application, with seven integrated layers up the stack.
The 7 Layers of Integration Up the Stack
The foundation of any solid design of the stack starts with . Dell Technologies is best positioned to drive consistency up and down the stack and its supplemented by the company’s subject matter infrastructure and services experts who work with you to make the best decisions concerning compute, storage, and back up.
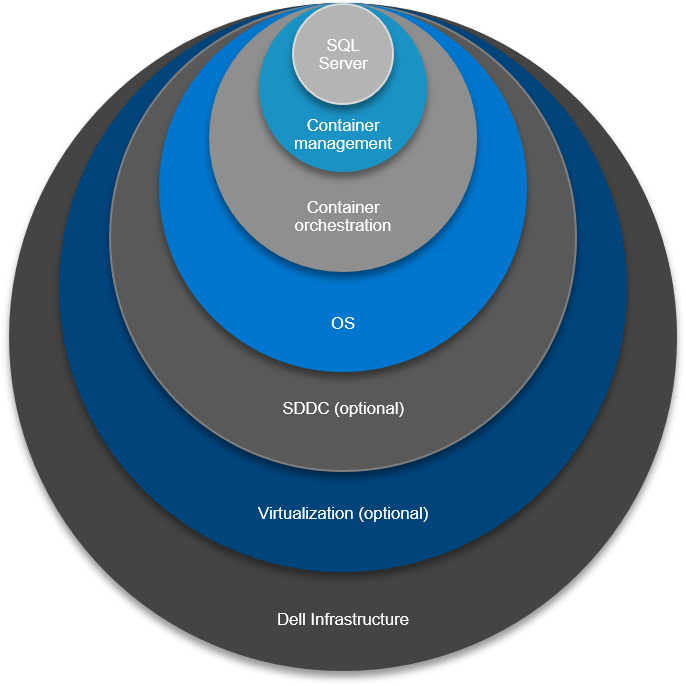
Let’s take a look at the vertical integration one layer at a time. From tin to application, we have:
- Infrastructure from Dell Technologies
- Virtualization (optional)
- Software defined – everything
- An operating system
- Container control plane
- Container orchestration plane
- Application
There are so many dimensions to choose from as we work up this layer cake of both hardware and software-defined and, of course, applications. Think: Dell, VMware, RedHat, Microsoft. With the progress of software, evolving at an ever-increasing rate and eating up the world, there is additional complexity. It’s critical you understand how all the pieces of the puzzle work and which pieces work well together, giving consideration of the integration points you may already have in your ecosystem.
Determining the Most Reliable and Fully Supported Solution
With all this complexity, which architecture do you choose to become properly solutioned? How many XaaS would you like to automate? I hope you answer is – All of them! At what point would you like the control plane, or control planes? Think of a control plane as the where your team’s manage from, deploy to, hook your DevOps tooling to. To put it a different way, would you like your teams innovating or maintaining?
As your control plane insertion point moves up towards the application, the automation below increases, as does the complexity. One example here is the Azure Resource Manager, or ARM. There are ways to connect any infrastructure in your on-premises data centers, driving consistent management. We also want all the role-based access control (RBAC) in place – especially for our data stores we are managing. One example, which we will talk about in Part 2, is Azure Arc.
This is the main reason for this blog, understanding the choices and tradeoff of cost versus complexity, or automated complexity. Many products deliver this automation, out of the box. “Pay no attention to the man behind the curtain!”
One of my good friends at Dell Technologies, Stephen McMaster an Engineering Technologist at Dell, describes these considerations as the Plinko Ball, a choose your own adventure type of scenario. This analogy is spot on!
With all the choices of dimensions, we must distill down to the most efficient approach. I like to understand both the current IT tool set and the maturity journey of the organization, before I tackle making the proper recommendation for a solid solution set and fully supported stack.
Dell Technologies Is Here to Help You Succeed
Is “keeping the lights on” preventing your team from innovating?
Dell Technologies Services can complement your team! As your company’s trusted advisor, my team members share deep expertise for Microsoft products and services and we’re best positioned to help you build your stack from tin to application. Why wait? Contact a Dell Technologies Services Expert today to get started.
Stay tuned for Part 2 of this blog series where we’ll dive further into the detail and operational considerations of the 7 layers of the fully supported stack.