



MLPerf™ Inference v2.0 Edge Workloads Powered by Dell PowerEdge Servers
Fri, 06 May 2022 19:54:11 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf Inference v2.0 benchmark suite. This blog examines the results of two specialty edge servers: the Dell PowerEdge XE2420 server with the NVIDIA T4 Tensor Core GPU and the Dell PowerEdge XR12 server with the NVIDIA A2 Tensor Core GPU.
Introduction
It is 6:00 am on a Saturday morning. You drag yourself out of bed, splash water on your face, brush your hair, and head to your dimly lit kitchen for a bite to eat before your morning run. Today, you have decided to explore a new part of the neighborhood because your dog’s nose needs new bushes to sniff. As you wait for your bagel to toast, you ask your voice assistant “what’s the weather like?” Within a couple of seconds, you know that you need to grab an extra layer because there is a slight chance of rain. Edge computing has saved your morning run.
Although this use case is covered in the MLPerf Mobile benchmarks, the data discussed in this blog is from the MLPerf Inference benchmark that has been run on Dell servers.
Edge computing is computing that takes place at the “edge of networks.” Edge of networks refers to where devices such as phones, tablets, laptops, smart speakers, and even industrial robots can access the rest of the network. In this case, smart speakers can perform speech-to-text recognition to offload processing that ordinarily must be accomplished in the cloud. This offloading not only improves response time but also decreases the amount of sensitive data that is sent and stored in the cloud. The scope for edge computing expands far beyond voice assistants with use cases including autonomous vehicles, 5G mobile computing, smart cities, security, and more.
The Dell PowerEdge XE2420 and PowerEdge XR 12 servers are designed for edge computing workloads. The design criteria is based on real life scenarios such as extreme heat, dust, and vibration from factory floors, for example. However, despite these servers not being physically located in a data center, server reliability and performance are not compromised.
PowerEdge XE2420 server
The PowerEdge XE2420 server is a specialty edge server that delivers high performance in harsh environments. This server is designed for demanding edge applications such as streaming analytics, manufacturing logistics, 5G cell processing, and other AI applications. It is a short-depth, dense, dual-socket, 2U server that can handle great environmental stress on its electrical and physical components. Also, this server is ideal for low-latency and large-storage edge applications because it supports 16x DDR4 RDIMM/LR-DIMM (12 DIMMs are balanced) up to 2993 MT/s. Importantly, this server can support the following GPU/Flash PCI card configurations:
- Up to 2 x PCIe x16, up to 300 W passive FHFL cards (for example, NVIDIA V100/s or NVIDIA RTX6000)
- Up to 4 x PCIe x8; 75 W passive (for example, NVIDIA T4 GPU)
- Up to 2 x FE1 storage expansion cards (up to 20 x M.2 drives on each)
The following figures show the PowerEdge XE2420 server (source):

Figure 1: Front view of the PowerEdge XE2420 server

Figure 2: Rear view of the PowerEdge XE2420 server
PowerEdge XR12 server
The PowerEdge XR12 server is part of a line of rugged servers that deliver high performance and reliability in extreme conditions. This server is a marine-compliant, single-socket 2U server that offers boosted services for the edge. It includes one CPU that has up to 36 x86 cores, support for accelerators, DDR4, PCIe 4.0, persistent memory and up to six drives. Also, the PowerEdge XR12 server offers 3rd Generation Intel Xeon Scalable Processors.
The following figures show the PowerEdge XR12 server (source):

Figure 3: Front view of the PowerEdge XR12 server

Figure 4: Rear view of the PowerEdge XR12 server
Performance discussion
The following figure shows the comparison of the ResNet 50 Offline performance of various server and GPU configurations, including:
- PowerEdge XE8545 server with the 80 GB A100 Multi-Instance GPU (MIG) with seven instances of the one compute instance of the 10gb memory profile
- PowerEdge XR12 server with the A2 GPU
- PowerEdge XE2420 server with the T4 and A30 GPU
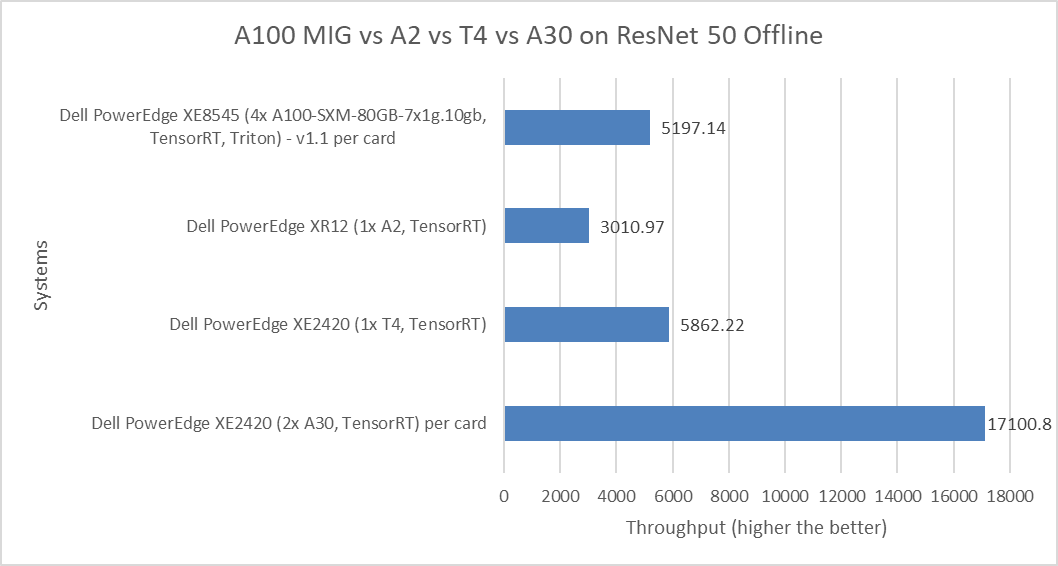
Figure 5: MLPerf Inference ResNet 50 Offline performance
ResNet 50 falls under the computer vision category of applications because it includes image classification, object detection, and object classification detection workloads.
The MIG numbers are per card and have been divided by 28 because of the four physical GPU cards in the systems multiplied by second instances of the MIG profile. The non-MIG numbers are also per card.
For the ResNet 50 benchmark, the PowerEdge XE2420 server with the T4 GPU showed more than double the performance of the PowerEdge XR12 server with the A2 GPU. The PowerEdge XE8545 server with the A100 MIG showed competitive performance when compared to the PowerEdge XE2420 server with the T4 GPU. The performance delta of 12.8 percent favors the PowerEdge XE2420 system. However, the PowerEdge XE2420 server with A30 GPU card takes the top spot in this comparison as it shows almost triple the performance over the PowerEdge XE2420 server with the T4 GPU.
The following figure shows a comparison of the SSD-ResNet 34 Offline performance of the PowerEdge XE8545 server with the A100 MIG and the PowerEdge XE2420 server with the A30 GPU.
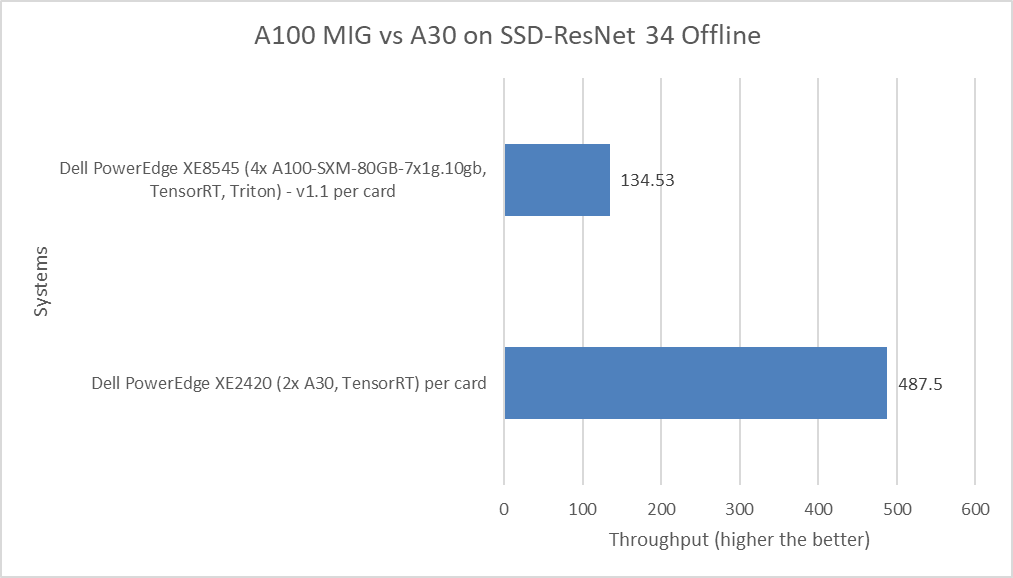
Figure 6: MLPerf Inference SSD-ResNet 34 Offline performance
The SSD-ResNet 34 model falls under the computer vision category because it performs object detection. The PowerEdge XE2420 server with the A30 GPU card performed more than three times better than the PowerEdge XE8545 server with the A100 MIG.
The following figure shows a comparison of the Recurrent Neural Network Transducers (RNNT) Offline performance of the PowerEdge XR12 server with the A2 GPU and the PowerEdge XE2420 server with the T4 GPU:
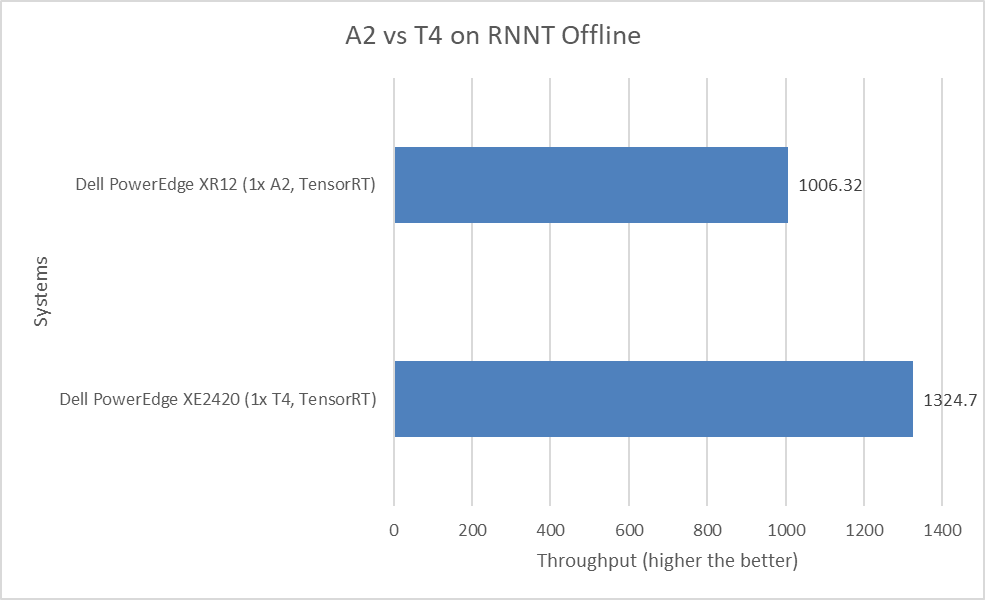
Figure 7: MLPerf Inference RNNT Offline performance
The RNNT model falls under the speech recognition category, which can be used for applications such as automatic closed captioning in YouTube videos and voice commands on smartphones. However, for speech recognition workloads, the PowerEdge XE2420 server with the T4 GPU and the PowerEdge XR12 server with the A2 GPU are closer in terms of performance. There is only a 32 percent performance delta.
The following figure shows a comparison of the BERT Offline performance of default and high accuracy runs of the PowerEdge XR12 server with the A2 GPU and the PowerEdge XE2420 server with the A30 GPU:
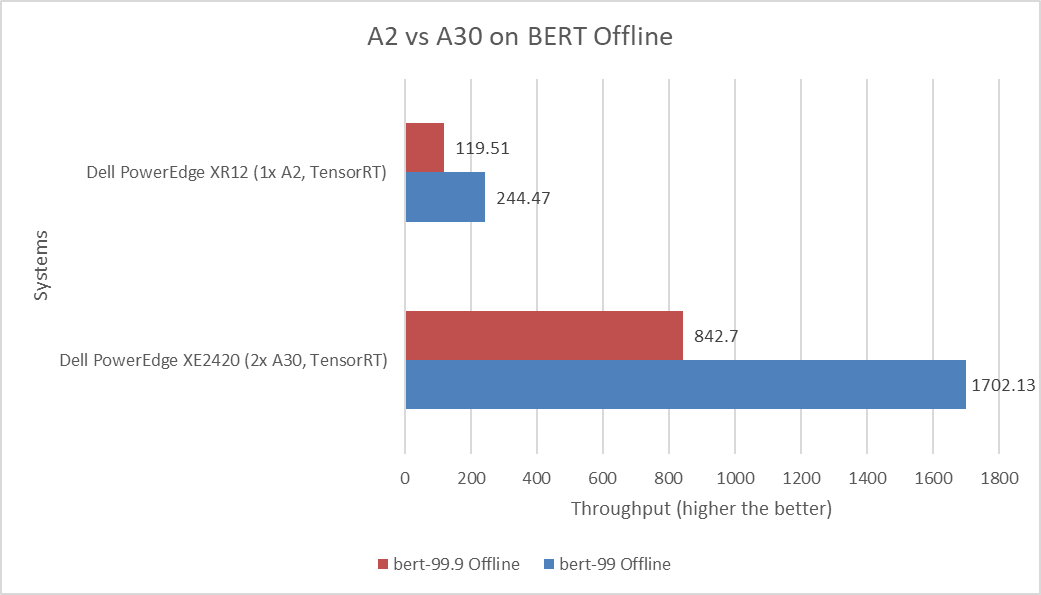
Figure 8: MLPerf Inference BERT Offline performance
BERT is a state-of-the-art, language-representational model for Natural Language Processing applications such as sentiment analysis. Although the PowerEdge XE2420 server with the A30 GPU shows significant performance gains, the PowerEdge XR12 server with the A2 GPU exceeds when considering achieved performance based on the money spent.
The following figure shows a comparison of the Deep Learning Recommendation Model (DLRM) Offline performance for the PowerEdge XE2420 server with the T4 GPU and the PowerEdge XR12 server with the A2 GPU:
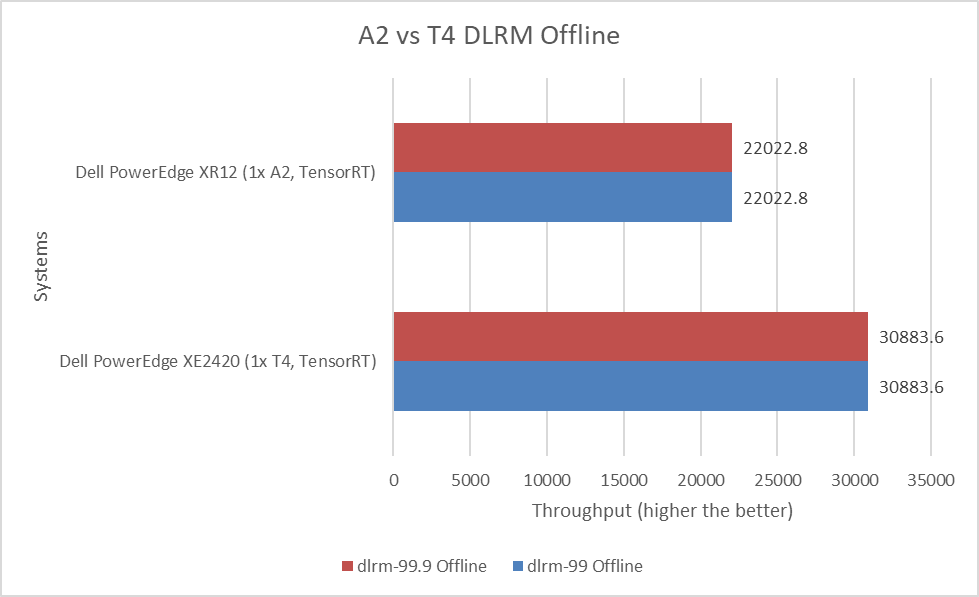
Figure 9: MLPerf Inference DLRM Offline performance
DLRM uses collaborative filtering and predicative analysis-based approaches to make recommendations, based on the dataset provided. Recommender systems are extremely important in search, online shopping, and online social networks. The performance of the PowerEdge XE2420 T4 in the offline mode was 40 percent better than the PowerEdge XR12 server with the A2 GPU.
Despite the higher performance from the PowerEdge XE2420 server with the T4 GPU, the PowerEdge XR12 server with the A2 GPU is an excellent option for edge-related workloads. The A2 GPU is designed for high performance at the edge and consumes less power than the T4 GPU for similar workloads. Also, the A2 GPU is the more cost-effective option.
Power Discussion
It is important to budget power consumption for the critical load in a data center. The critical load includes components such as servers, routers, storage devices, and security devices. For the MLPerf Inference v2.0 submission, Dell Technologies submitted power numbers for the PowerEdge XR12 server with the A2 GPU. Figures 8 through 11 showcase the performance and power results achieved on the PowerEdge XR12 system. The blue bars are the performance results, and the green bars are the system power results. For all power submissions with the A2 GPU, Dell Technologies took the Number One claim for performance per watt for the ResNet 50, RNNT, BERT, and DLRM benchmarks.
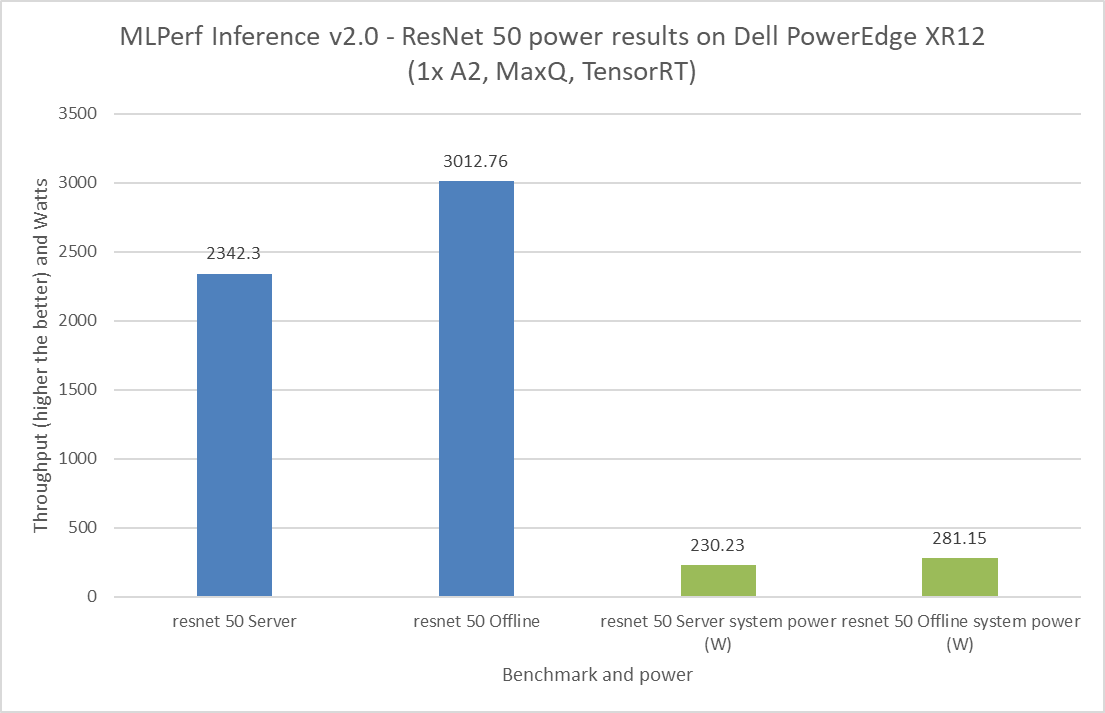
Figure 10: MLPerf Inference v2.0 ResNet 50 power results on the Dell PowerEdge XR12 server
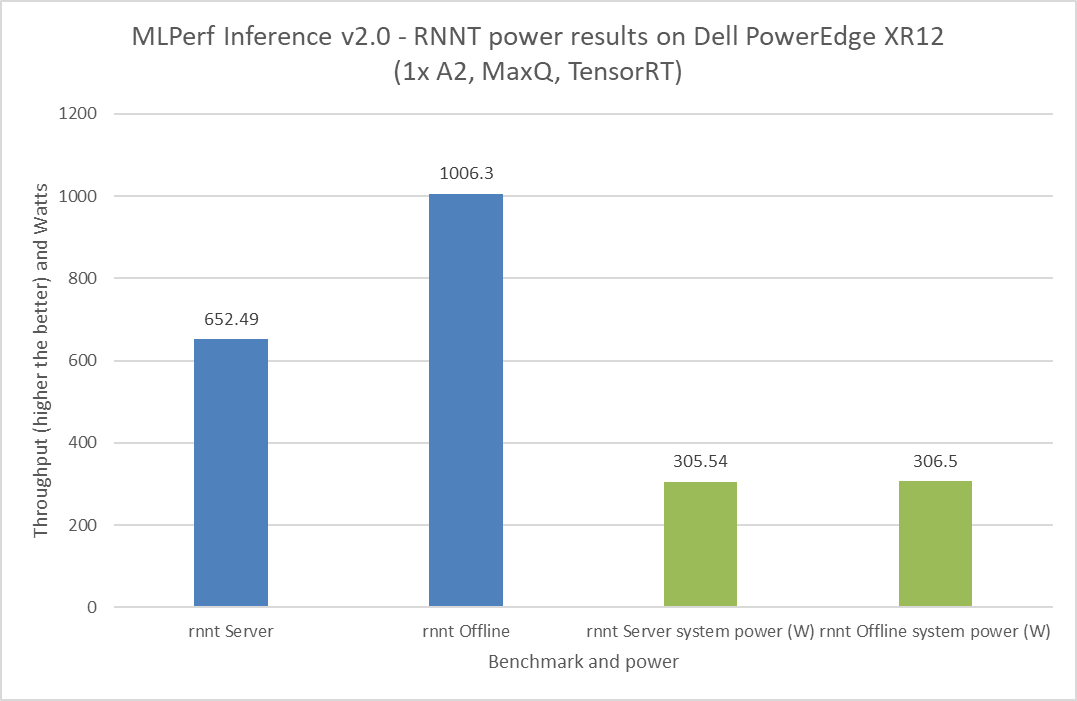
Figure 11: MLPerf Inference v2.0 RNNT power results on the Dell PowerEdge XR12 server
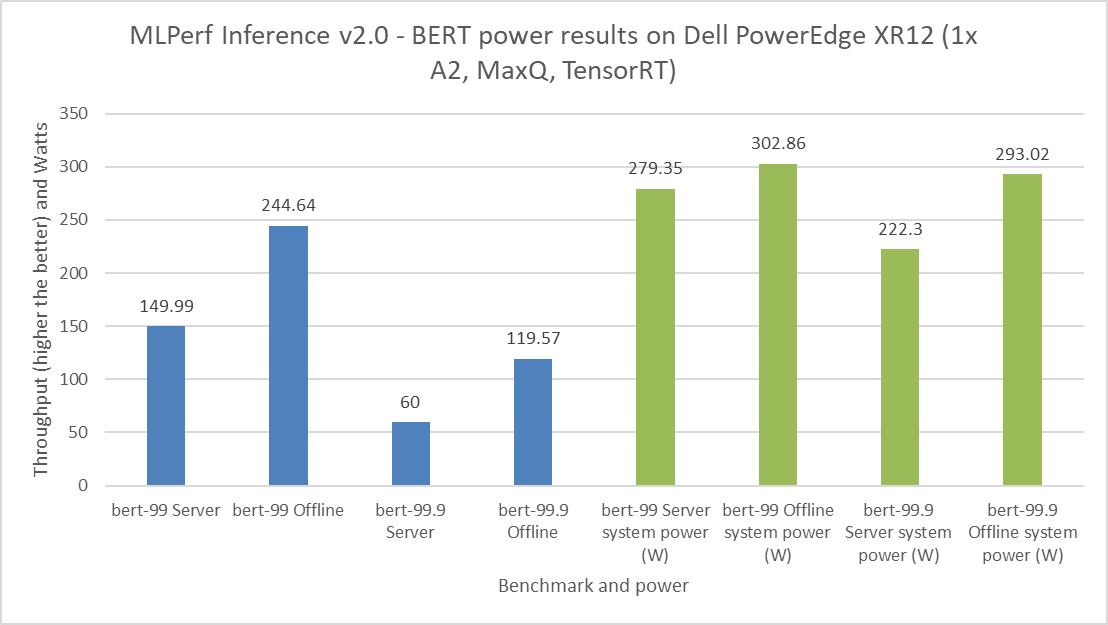
Figure 12: MLPerf Inference v2.0 BERT power results on the Dell PowerEdge XR12 server
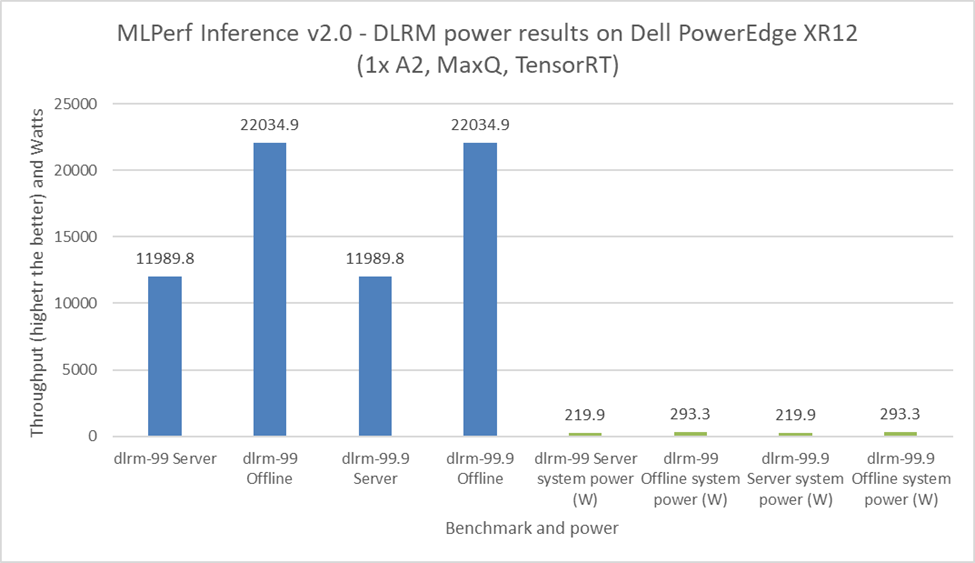 Figure 13: MLPerf Inference v2.0 DLRM power results on the Dell PowerEdge XR12 server
Figure 13: MLPerf Inference v2.0 DLRM power results on the Dell PowerEdge XR12 server
Note: During our submission to MLPerf Inference v2.0 including power numbers, the PowerEdge XR12 server was not tuned for optimal performance per watt score. These results reflect the performance-optimized power consumption numbers of the server.
Conclusion
This blog takes a closer look at Dell Technologies’ MLPerf Inference v2.0 edge-related submissions. Readers can compare performance results between the Dell PowerEdge XE2420 server with the T4 GPU and the Dell PowerEdge XR12 server with the A2 GPU with other systems with different accelerators. This comparison helps readers make informed decisions about ML workloads on the edge. Performance, power consumption, and cost are the important factors to consider when planning any ML workload. Both the PowerEdge XR12 and XE2420 servers are excellent choices for Deep Learning workloads on the edge.
Appendix
SUT configuration
The following table describes the System Under Test (SUT) configurations from MLPerf Inference v2.0 submissions:
Table 1: MLPerf Inference v2.0 system configuration of the PowerEdge XE2420 and XR12 servers
Platform | PowerEdge XE2420 1x T4, TensorRT | PowerEdge XR12 1x A2, TensorRT | PowerEdge XR12 1x A2, MaxQ, TensorRT | PowerEdge XE2420 2x A30, TensorRT |
MLPerf system ID | XE2420_T4x1_edge_TRT | XR12_edge_A2x1_TRT | XR12_A2x1_TRT_MaxQ | XE2420_A30x2_TRT |
Operating system | CentOS 8.2.2004 | Ubuntu 20.04.4 | ||
CPU | Intel Xeon Gold 6238 CPU @ 2.10 GHz | Intel Xeon Gold 6312U CPU @ 2.40 GHz | Intel Xeon Gold 6252N CPU @ 2.30 GHz | |
Memory | 256 GB | 1 TB | ||
GPU | NVIDIA T4 | NVIDIA A2 | NVIDIA A30 | |
GPU form factor | PCIe | |||
GPU count | 1 | 2 | ||
Software stack | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.47.03 DALI 0.31.0 | |||
Table 2: MLPerf Inference v1.1 system configuration of the PowerEdge XE8545 server
Platform | PowerEdge XE8545 4x A100-SXM-80GB-7x1g.10gb, TensorRT, Triton |
MLPerf system ID | XE8545_A100-SXM-80GB-MIG_28x1g.10gb_TRT_Triton |
Operating system | Ubuntu 20.04.2 |
CPU | AMD EPYC 7763 |
Memory | 1 TB |
GPU | NVIDIA A100-SXM-80GB (7x1g.10gb MIG) |
GPU form factor | SXM |
GPU count | 4 |
Software stack | TensorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 Driver 470.57.02 DALI 0.31.0 |
Related Blog Posts
Unveiling the Power of the PowerEdge XE9680 Server on the GPT-J Model from MLPerf™ Inference
Tue, 16 Jan 2024 18:30:32 -0000
|Read Time: 0 minutes
Abstract
For the first time, the latest release of the MLPerf™ inference v3.1 benchmark includes the GPT-J model to represent large language model (LLM) performance on different systems. As a key player in the MLPerf consortium since version 0.7, Dell Technologies is back with exciting updates about the recent submission for the GPT-J model in MLPerf Inference v3.1. In this blog, we break down what these new numbers mean and present the improvements that Dell Technologies achieved with the Dell PowerEdge XE9680 server.
MLPerf inference v3.1
MLPerf inference is a standardized test for machine learning (ML) systems, allowing users to compare performance across different types of computer hardware. The test helps determine how well models, such as GPT-J, perform on various machines. Previous blogs provide a detailed MLPerf inference introduction. For in-depth details, see Introduction to MLPerf inference v1.0 Performance with Dell Servers. For step-by-step instructions for running the benchmark, see Running the MLPerf inference v1.0 Benchmark on Dell Systems. Inference version v3.1 is the seventh inference submission in which Dell Technologies has participated. The submission shows the latest system performance for different deep learning (DL) tasks and models.
Dell PowerEdge XE9680 server
The PowerEdge XE9680 server is Dell’s latest two-socket, 6U air-cooled rack server that is designed for training and inference for the most demanding ML and DL large models.

Figure 1. Dell PowerEdge XE9680 server
Key system features include:
- Two 4th Gen Intel Xeon Scalable Processors
- Up to 32 DDR5 DIMM slots
- Eight NVIDIA HGX H100 SXM 80 GB GPUs
- Up to 10 PCIe Gen5 slots to support the latest Gen5 PCIe devices and networking, enabling flexible networking design
- Up to eight U.2 SAS4/SATA SSDs (with fPERC12)/ NVMe drives (PSB direct) or up to 16 E3.S NVMe drives (PSB direct)
- A design to train and inference the most demanding ML and DL large models and run compute-intensive HPC workloads
The following figure shows a single NVIDIA H100 SXM GPU:

Figure 2. NVIDIA H100 SXM GPU
GPT-J model for inference
Language models take tokens as input and predict the probability of the next token or tokens. This method is widely used for essay generation, code development, language translation, summarization, and even understanding genetic sequences. The GPT-J model in MLPerf inference v3.1 has 6 B parameters and performs text summarization tasks on the CNN-DailyMail dataset. The model has 28 transformer layers, and a sequence length of 2048 tokens.
Performance updates
The official MLPerf inference v3.1 results for all Dell systems are published on https://mlcommons.org/benchmarks/inference-datacenter/. The PowerEdge XE9680 system ID is ID 3.1-0069.
After submitting the GPT-J model, we applied the latest firmware updates to the PowerEdge XE9680 server. The following figure shows that performance improved as a result:
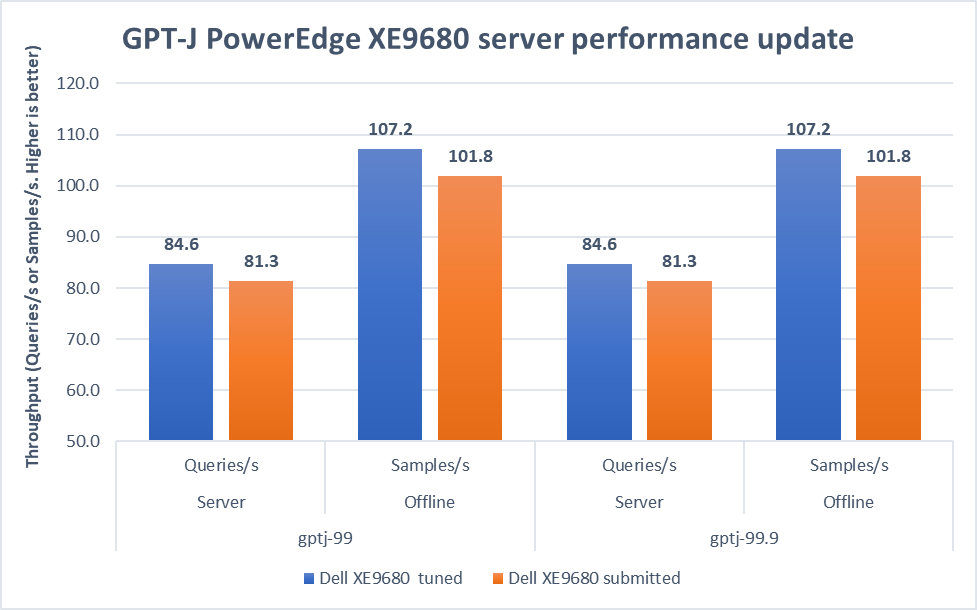
Figure 3. Improvement of the PowerEdge XE9680 server on GPT-J Datacenter 99 and 99.9, Server and Offline scenarios [1]
In both 99 and 99.9 Server scenarios, the performance increased from 81.3 to an impressive 84.6. This 4.1 percent difference showcases the server's capability under randomly fed inquires in the MLPerf-defined latency restriction. In the Offline scenarios, the performance saw a notable 5.3 percent boost from 101.8 to 107.2. These results mean that the server is even more efficient and capable of handling batch-based LLM workloads.
Note: For PowerEdge XE9680 server configuration details, see https://github.com/mlcommons/inference_results_v3.1/blob/main/closed/Dell/systems/XE9680_H100_SXM_80GBx8_TRT.json
Conclusion
This blog focuses on the updates of the GPT-J model in the v3.1 submission, continuing the journey of Dell’s experience with MLPerf inference. We highlighted the improvements made to the PowerEdge XE9680 server, showing Dell's commitment to pushing the limits of ML benchmarks. As technology evolves, Dell Technologies remains a leader, constantly innovating and delivering standout results.
[1] Unverified MLPerf® v3.1 Inference Closed GPT-J. Result not verified by MLCommons Association.
The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
Choosing a PowerEdge Server and NVIDIA GPUs for AI Inference at the Edge

Fri, 05 May 2023 16:38:19 -0000
|Read Time: 0 minutes
Dell Technologies submitted several benchmark results for the latest MLCommonsTM Inference v3.0 benchmark suite. An objective was to provide information to help customers choose a favorable server and GPU combination for their workload. This blog reviews the Edge benchmark results and provides information about how to determine the best server and GPU configuration for different types of ML applications.
Results overview
For computer vision workloads, which are widely used in security systems, industrial applications, and even in self-driven cars, ResNet and RetinaNet results were submitted. ResNet is an image classification task and RetinaNet is an object detection task. The following figures show that for intensive processing, the NVIDIA A30 GPU, which is a double-wide card, provides the best performance with almost two times more images per second than the NVIDIA L4 GPU. However, the NVIDIA L4 GPU is a single-wide card that requires only 43 percent of the energy consumption of the NVIDIA A30 GPU, considering nominal Thermal Design Power (TDP) of each GPU. This low-energy consumption provides a great advantage for applications that need lower power consumption or in environments that are more challenging to cool. The NVIDIA L4 GPU is the replacement for the best-selling NVIDIA T4 GPU, and provides twice the performance with the same form factor. Therefore, we see that this card is the best option for most Edge AI workloads.
Conversely, the NVIDIA A2 GPU exhibits the most economical price (compared to the NVIDIA A30 GPU's price), power consumption (TDP), and performance levels among all available options in the market. Therefore, if the application is compatible with this GPU, it has the potential to deliver the lowest total cost of ownership (TCO).
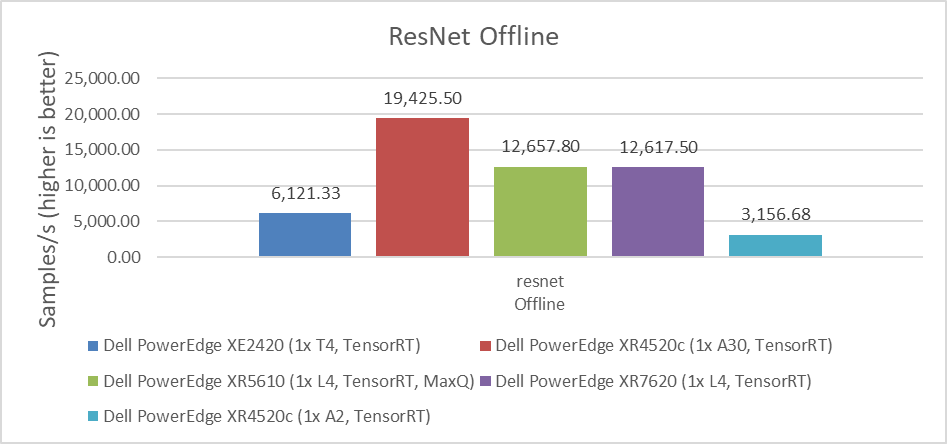
Figure 1: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the ResNet Offline benchmark
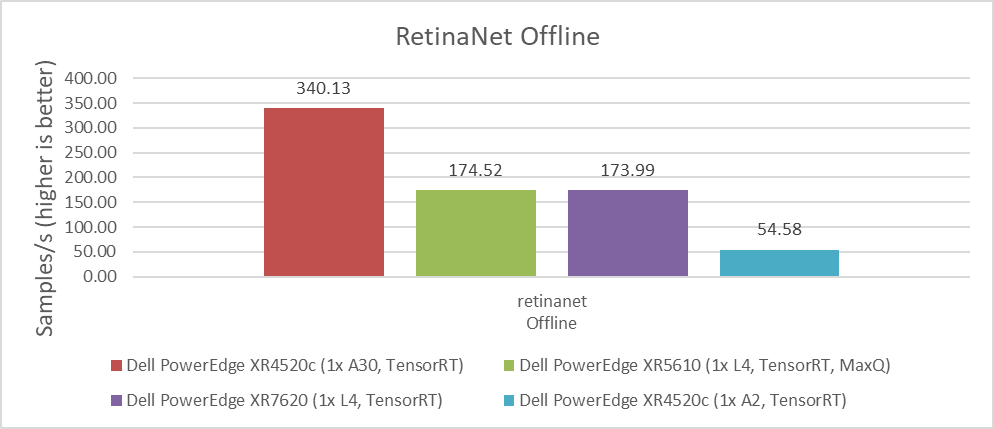
Figure 2: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the RetinaNet Offline benchmark
The 3D-UNet benchmark is the other computer vision image-related benchmark. It uses medical images for volumetric segmentation. We saw the same results for default accuracy and high accuracy. Moreover, the NVIDIA A30 GPU delivered significantly better performance over the NVIDIA L4 GPU. However, the same comparison between energy consumption, space, and cooling capacity discussed previously applies when considering which GPU to use for each application and use case.
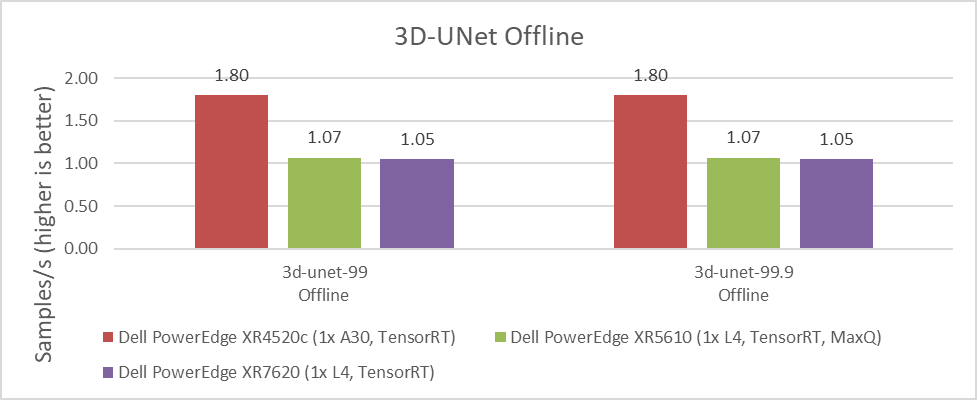
Figure 3: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the 3D-UNet Offline benchmark
Another important benchmark is for BERT, which is a Natural Language Processing model that performs tasks such as question answering and text summarization. We observed similar performance differences between the NVIDIA A30, L4, T4, and A2 GPUs. The higher the value, the better.
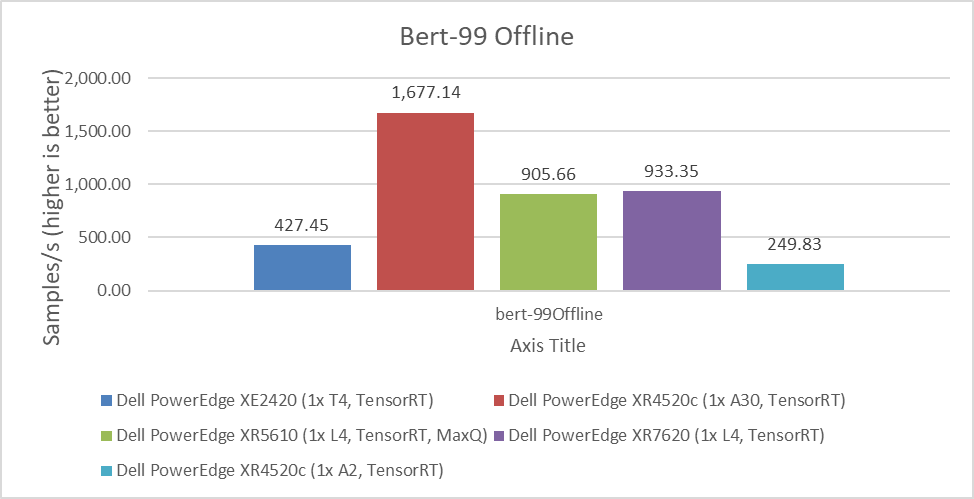
Figure 4: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the BERT Offline benchmark
MLPerf benchmarks also include latency results, which are the time that systems take to process requests. For some use cases, this processing time can be more critical than the number of requests that can be processed per second. For example, if it takes several seconds to respond to a conversational algorithm or an object detection query that needs a real-time response, this time can be particularly impactful on the experience of the user or application.
As shown in the following figures, the NVIDIA A30 and NVIDIA L4 GPUs have similar latency results. Depending on the workload, the results can vary due to which GPU provides the lowest latency. For customers planning to replace the NVIDIA T4 GPU or seeking a better response time for their applications, the NVIDIA L4 GPU is an excellent option. The NVIDIA A2 GPU can also be used for applications that require low latency because it performed better than the NVIDIA T4 GPU in single stream workloads. The lower the value, the better.
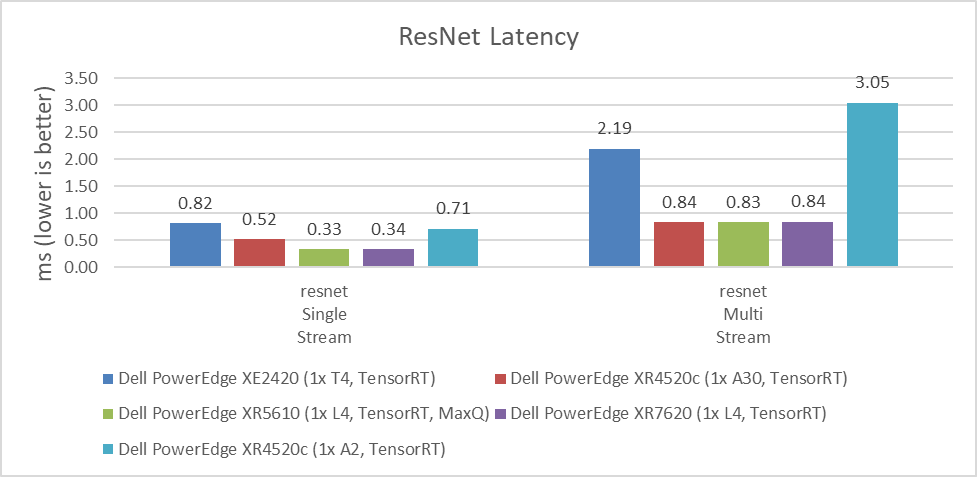
Figure 4: Latency comparison of NVIDIA A30, L4, T4, and A2 GPUs for the ResNet single-stream and multistream benchmark
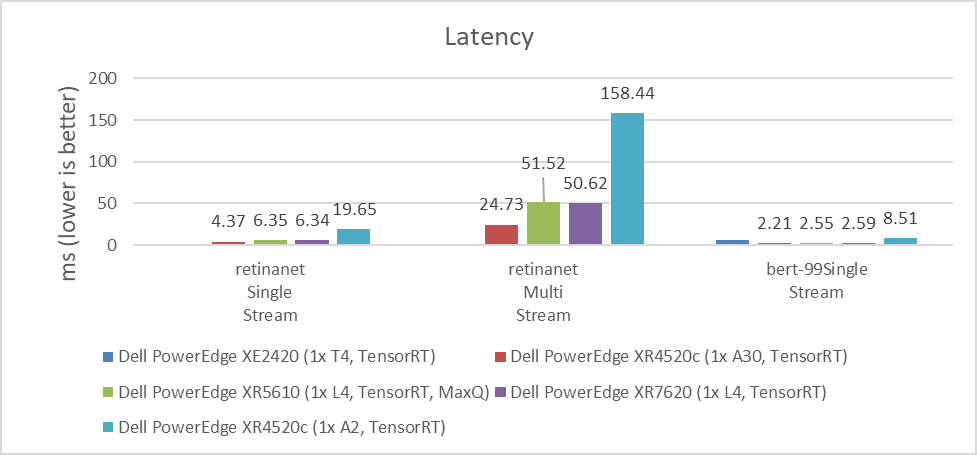
Figure 5: Latency comparison of NVIDIA A30, L4, T4, and A2 GPUs for the RetinaNet single-stream and multistream benchmark and the BERT single-stream benchmark
Dell Technologies submitted to various benchmarks to help understand which configuration is the most environmentally friendly as the data center’s carbon footprint is a concern today. This concern is relevant because some edge locations have power and cooling limitations. Therefore, it is important to understand performance compared to power consumption.
The following figure affirms that the NVIDIA L4 GPU has equal or better performance per watt compared to the NVIDIA A2 GPU, even with higher power consumption. For Throughput and Perf/watt values, higher is better; for Power(watt) values, lower is better.
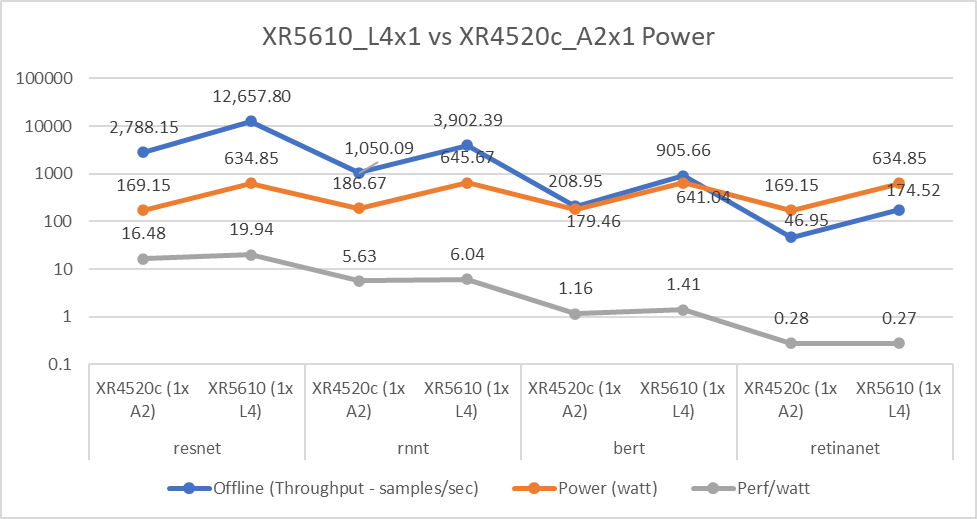
Figure 6: NVIDIA L4 and A2 GPU power consumption comparison
Conclusion
With measured workload benchmarks on MLPerf Inference 3.0, we can conclude that all NVIDIA GPUs tested for Edge workloads have characteristics that address several use cases. Customers must evaluate size, performance, latency, power consumption, and price. When choosing which GPU to use and depending on the requirements of the application, one of the evaluated GPUs will provide a better result for the final use case.
Another important conclusion is that the NVIDIA L4 GPU can be considered as an exceptional upgrade for customers and applications running on NVIDIA T4 GPUs. The migration to this new GPU can help consolidate the amount of equipment, reduce the power consumption, and reduce the TCO; one NVIDIA L4 GPU can provide twice the performance of the NVIDIA T4 GPU for some workloads.
Dell Technologies demonstrates on this benchmark the broad Dell portfolio that provides the infrastructure for any type of customer requirement.
The following blogs provide analyses of other MLPerfTM benchmark results:
- Dell Servers Excel in MLPerf™ Inference 3.0 Performance
- Dell Technologies’ NVIDIA H100 SXM GPU submission to MLPerf™ Inference 3.0
- Empowering Enterprises with Generative AI: How Does MLPerf™ Help Support
- Comparison of Top Accelerators from Dell Technologies’ MLPerf™
References
For more information about Dell Power Edge servers, go to the following links:
- Dell’s PowerEdge XR7620 for Telecom/Edge Compute
- Dell’s PowerEdge XR5610 for Telecom/Edge Compute
- PowerEdge XR4520c Compute Sled specification sheet
- PowerEdge XE2420 Spec Sheet
For more information about NVIDIA GPUs, go to the following links:
MLCommonsTM Inference v3.0 results presented in this document are based on following system IDs:
| ID | Submitter | Availability | System |
|---|---|---|---|
2.1-0005 | Dell Technologies | Available | Dell PowerEdge XE2420 (1x T4, TensorRT) |
2.1-0017 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A2, TensorRT) |
2.1-0018 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A30, TensorRT) |
2.1-0019 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A2, MaxQ, TensorRT) |
2.1-0125 | Dell Technologies | Preview | Dell PowerEdge XR5610 (1x L4, TensorRT, MaxQ) |
2.1-0126 | Dell Technologies | Preview | Dell PowerEdge XR7620 (1x L4, TensorRT) |
Table 1: MLPerfTM system IDs