




Metered Usage for Azure Stack Infrastructure
Thu, 20 Aug 2020 20:50:56 -0000
|Read Time: 0 minutes
Metered Usage for Azure Stack Infrastructure
When it comes to building modern applications and adopting a cloud operating model, Azure Stack is an extension of Azure. While the primary focus is the ability to develop and run Azure services in a Hybrid Environment, Microsoft has also brought the Azure economic model to Azure Stack with usage-based billing. At Dell EMC, our goal is to complete that experience by providing a metered usage consumption offering for the Dell EMC Cloud on Microsoft Azure Stack. Now with the recent introduction of Flex on Demand from Dell Financial Services (DFS), you have the option to pay for your Azure Stack Infrastructure based on the usage data from your Azure Stack Usage API Endpoint.
Capacity Planning and Flex capacity
An important consideration for many of our Hybrid Cloud customers is the ability to scale applications and services rapidly. This could apply to the ability to accommodate bursty workloads as well as scenarios where you see rapid growth yet keep some buffer capacity to cushion the impact of that growth. Our goal at Dell EMC is to provide you with the business model that accommodates both options softening the impact of time related to capacity planning.

Usage based billing consistent with Cloud Economics
Most of target personas for Hybrid cloud are focused on the application developer or the IT operator. As Hybrid Cloud adoption grows, a company’s finance, accounting along with procurement stakeholders are realizing the benefits of cloud economics. Eliminating the need to manage un-planned capital expenses, while benefiting from procurement of equipment as a service enables you to simplify accounting, free up cash flow and make procurement of new services more streamlined.
With Flex on Demand from DFS, consistent with Azure, your infrastructure charges are tied to usage and aligns with the OPEX type consumption models that customers desire. You pay Dell EMC for the services you consume plus a pre-negotiated fixed cost monthly. This covers the usage costs associated with the Hardware, Lifecycle Management SW and Maintenance while you continue to pay your subscription costs to Microsoft for the Azure Services running on Azure Stack.

Meters consistent with Azure
While metered service is a key tenet of Cloud computing, picking the right resources and meters is equally important. In discussing options with our customers, the consistency with Azure and the Cost transparency were highlighted as key goals. In keeping with the notion that Azure Stack is an extension of Azure, we applied a similar approach to the usage measurements and billing of the Azure Stack Infrastructure.
To do this, we extract and report back the per-subscription resources leveraging the usage API endpoints from Azure Stack Provider Resource API. Consistent with Azure Stack, we measure the VM Hours and capture the VM Type. From this data, we compute the resource consumption. Based on the Scale Unit Type (Balanced/All Flash), we then assign a rate and a bill is generated.
Whether you are looking for a financial model consistent with Azure or looking to keep some buffer capacity to accommodate growth, working with Dell Financial Services, we are delighted to bring this Measured Service capability to the full stack and in a way completing the final piece of the Hybrid cloud puzzle. For more information you can go to Flex On Demand from DFS.
Related Blog Posts

Azure Stack with PowerScale
Mon, 17 Aug 2020 18:44:45 -0000
|Read Time: 0 minutes
Dell EMC Integrated System for Microsoft Azure Stack Hub has been at the forefront in bringing Azure to customer datacenters, enabling customers to operate their own region of Azure in a secure environment that addresses their data sovereignty and performance needs.
As data growth explodes at the edge, many of our customers are looking to process PB scale data in the context of file, image/video processing, analytics, simulation, and learning. With Azure Stack Hub, built on hyperconverged infrastructure (HCI), the need for external storage to handle this growth in data was critical. Additionally, for applications that use file storage with CIFS/NFS today, Azure files storage service is currently not supported.
As we set out to identify the right storage subsystem that met our customers’ needs (with performance, multi-tenancy, multi-petabyte scale-out storage, and advanced data management features), we did not have to look far. Dell Technologies has a large product portfolio that enables us not only to integrate with other infrastructures but to innovate in other areas to deliver the Azure consistent experience our customers expect.
With newly announced Azure Stack Hub integration with Dell EMC PowerScale, customers can run their Azure IaaS and PaaS on-premises while connecting to data that is generated and stored locally. In the context of Azure consistency, depending on your application needs, there are two ways to consume this storage.
- Azure Consistent Storage (ACS): Applications that are using Azure Block Blob storage
- Integrated NAS (File Storage): NFS and CIFS
Here are some highlights about the choices and differences:
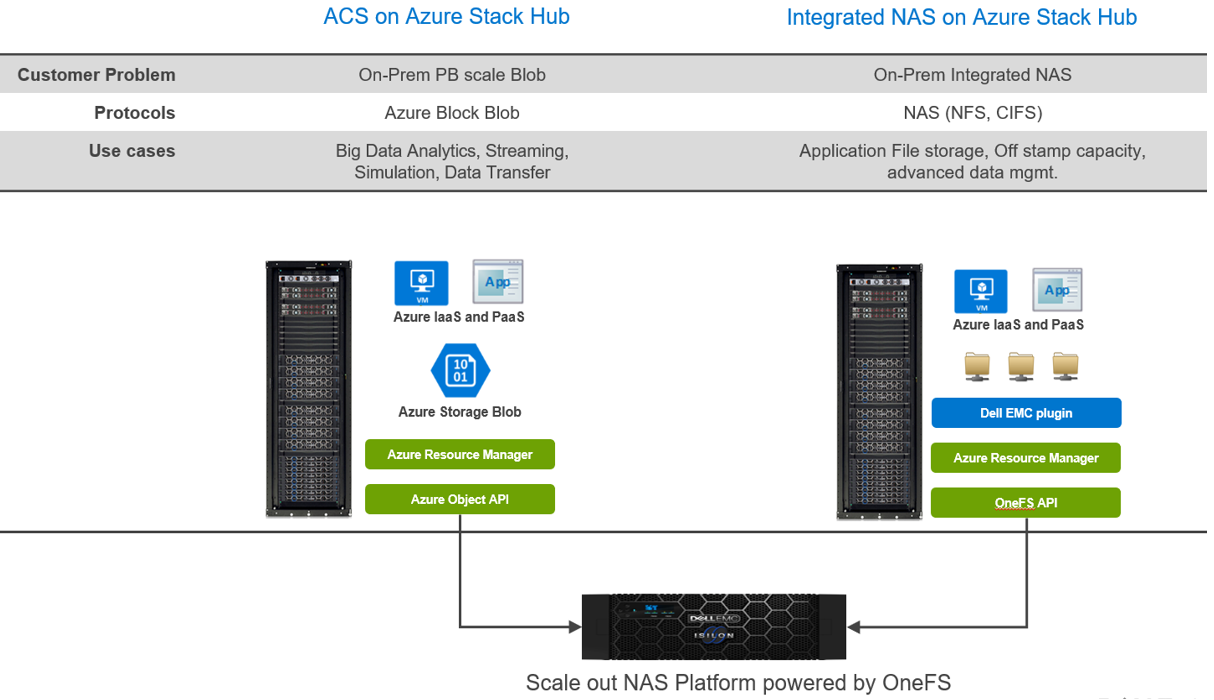
Regardless of your protocol of choice, you have two personas engaged:
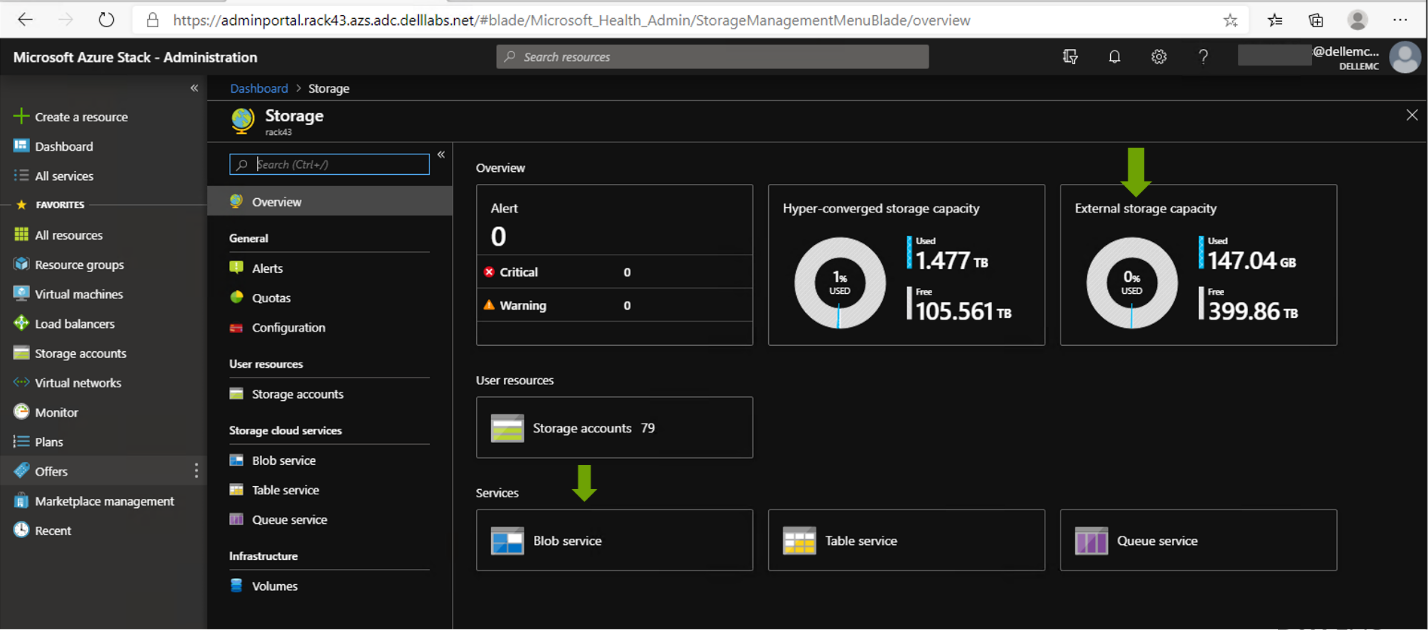
- The Azure Stack Hub Cloud administrator (screen below) is responsible for creating offers, quotas, and plans to offer the underlying storage, via subscriptions, to Azure tenants.
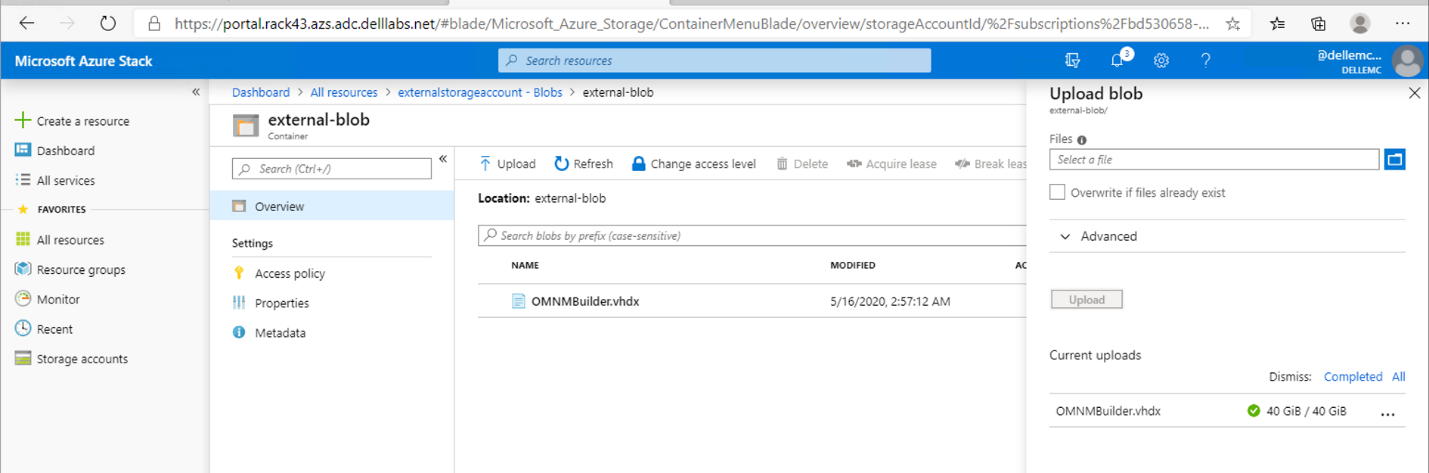
- The Azure Stack tenant can consume storage and be metered and billed consistent with other Azure Services. All of this, without having to manage anything in PowerScale.
With this strategy, our customers can tap into external PB storage to consume Azure Block Blob or Files via CIFS/NFS while maintaining the Azure consistent experience. Additionally, for customers looking to keep their applications in the public cloud while maintaining their data on-premises, Dell Technologies Cloud PowerScale extends OneFS running on-prem to Azure.
To read more about it, see this solution brief:
Dell Technologies Cloud PowerScale: Microsoft Azure
With the work Dell Technologies has been doing with Azure and Azure Stack Hub, your data is secure and compliant. You also have the choice to run your application in Azure or Azure Stack Hub and connect to your on-prem data without sacrificing bandwidth or latency.

A Best Practice for Enhancing Your Dell PowerVault Storage Investment with Dell Metro Node
Thu, 28 Sep 2023 19:37:34 -0000
|Read Time: 0 minutes
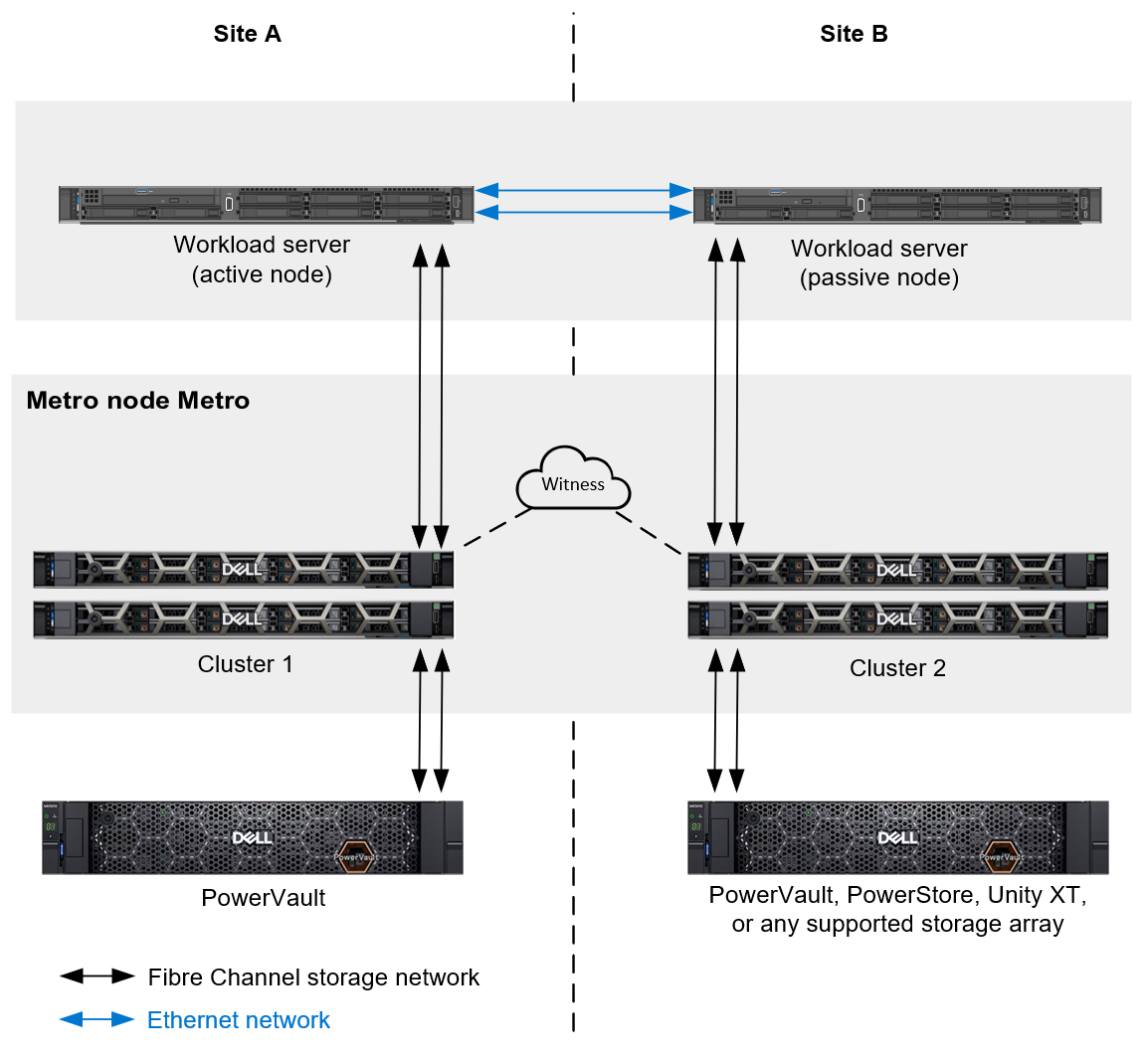
Dell PowerVault ME5 storage provides industry-leading features, capacity, and performance, at entry-level prices. But did you know that the Dell Technologies storage portfolio also offers an easy-to-use, cost-effective way to enhance the business continuity configuration of your PowerVault investment? It’s done with Dell metro node.
All organizations – large and small – need to make business continuity a high priority to protect their data and ensure uptime. With metro node, your PowerVault environment can take advantage of enterprise-class features, such as:
- Synchronous replication
- Automatic DR failover with a decision time objective (DTO) of zero
- Seamless data mobility to other Dell PowerVault or Dell PowerStore storage appliances
- Nondisruptive tech upgrades and refreshes
To learn more, check out this new whitepaper: Dell PowerVault and Metro Node with Microsoft.
Conclusion
If you are already using PowerVault storage or are considering PowerVault, explore the power of metro node features and see where metro node can enhance and extend the resiliency of your PowerVault storage investment.
Resources
- Dell PowerVault Storage Info hub
- Dell PowerVault and Metro Node with Microsoft
- Dell Metro Node Product Guide
Author: Marty Glaser, Sr. Principal Engineer