



Introduction to MLPerf™ Inference v1.1 with Dell EMC Servers
Fri, 24 Sep 2021 16:48:39 -0000
|Read Time: 0 minutes
Dell Technologies has participated in MLPerf submission for the past two years. The current submission is our fourth round to the MLPerf inference benchmarking suite.
This blog provides the latest MLPerf Inference v1.1 data center closed results on Dell EMC servers from our HPC & AI Innovation lab. The objective of this blog is to show optimal inference performance and performance/watt for the Dell EMC GPU servers (PowerEdge R750xa, DSS8440, and PowerEdge R7525). A blog about MLPerf Inference v1.0 performance can be found here. This blog also addresses the benchmarks rules, constraints, and submission categories. We recommend that you read it to become familiar with the MLPerf terminologies and rules.
Noteworthy results
Our noteworthy results include:
- The DSS8440 server (10 x A100-PCIE-80GB, TensorRT) yields Number One results across all the submitters for:
- BERT 99 Offline and Server
- BERT 99.9 Offline and Server
- RNN-T Offline and Server
- SSD-Resnet34 Offline and Server
- The R750xa server (4 x A100-PCIE-80GB, TensorRT) yields Number One results per PCIe accelerator for:
- 3D UNet Offline and 3D UNet 99.9 Offline
- Resnet50 Offline and Resnet50 Server
- BERT 99 Offline and BERT 99 Server
- BERT 99.9 Offline and BERT 99.9 Server
- DLRM 99 Offline and DLRM Server
- DLRM 99.9 Offline and DLRM 99.9 Server
- RNN-T Offline and RNN-T Server
- SSD-Resnet34 Offline and SSD-Resnet34 Server
- The R750xa server (4 x A100-PCIE-80GB, MIG) yields Number One results per PCIe accelerator MIG results for:
- Resnet50 Offline and Resnet50 Server
- BERT 99 Offline and BERT 99 Server
- BERT 99.9 Offline and BERT 99.9 Server
- SSD-Resnet34 Offline and SSD-Reset34 Server
- The R750xa server (4 x A100-PCIE-80GB, Triton) yields Number One results per PCIe accelerator Triton results for:
- 3D UNet Offline and 3D UNet 99.9 Offline
- Resnet50 Offline and Resnet50 Server
- BERT 99 Server
- BERT 99.9 Offline and BERT 99.9 Server
- DLRM 99 Offline and DLRM Server
- DLRM 99.9 Offline and DLRM 99.9 Server
To allow the like-to-like comparison of Dell Technologies results, we chose to test under the Datacenter closed division, as shown in this blog. Customers and partners can rely on our results, all of which MLCommonsTM has officially certified. Officially certified results are peer reviewed, have undergone compliance tests, and conform to the constraints enforced by MLCommons. If wanted, customers and partners can also reproduce our results. The blog that explains how to run MLPerf Inference v1.1 can be found here.
What is new?
The difference between MLPerf inference v1.1 and MLPerf inference v1.0 is that the Multistream scenario is deprecated. All other benchmarks and rules remain the same as for MLPerf inference v1.0.
For v1.1 submissions to MLCommons, over 1700 results were submitted. The number of submitters increased from 17 to 21.
Dell Technologies result submissions included new SUT configurations such as NVIDIA A100 Tensor Core 80GB GPU with 300 W TDP, A30, A100-MIG, and power results with NVIDIA-Certified R750xa servers.
MLPerf Inference 1.1 benchmark results
The following graphs include performance metrics for the Offline and Server scenarios. Overall, Dell Technologies results included approximately 200 performance results and 80 performance and power results. These results serve as a reference point to enable sizing deep learning clusters. The higher number of results in our submission helps further fine tune answers to specific questions that customers might have.
For the Offline scenario, the performance metric is Offline samples per second. For the Server scenario, the performance metric is queries per second (QPS). In general, the metrics represent throughput. A higher throughput is a better result. In the following graphs, the Y axis is an exponentially scaled axis representing the throughput and the X axis represents the SUTs and their corresponding models (described in the appendix).
Figures 1, 2, and 3 show the performance of different Dell EMC servers that were benchmarked for the different models. All these servers performed optimally and rendered high throughput. The backends included NVIDIA Triton, NVIDIA TensorRT on Offline and Server scenarios. Some of the results shown in figures 1 and 3 include MIG numbers.
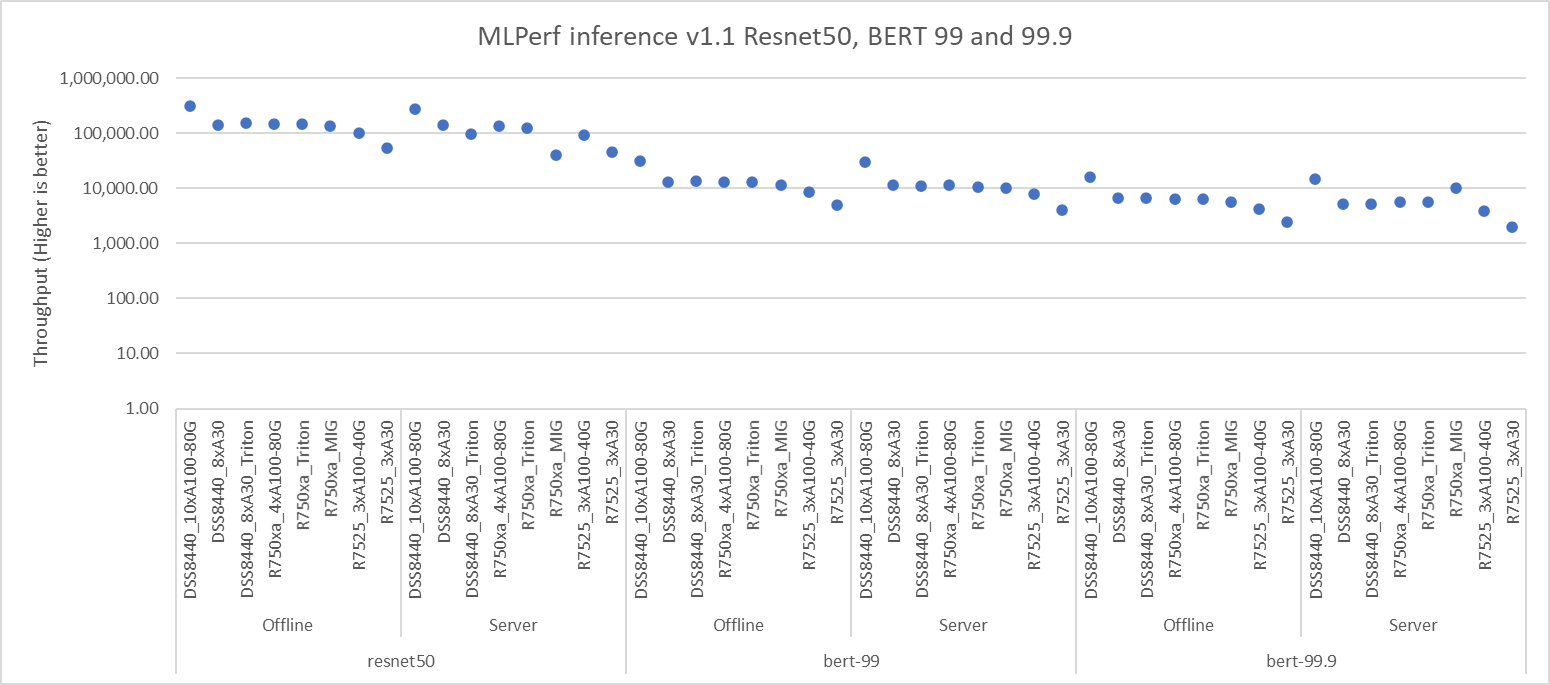
Figure 1: Resnet50, BERT default, and high accuracy results
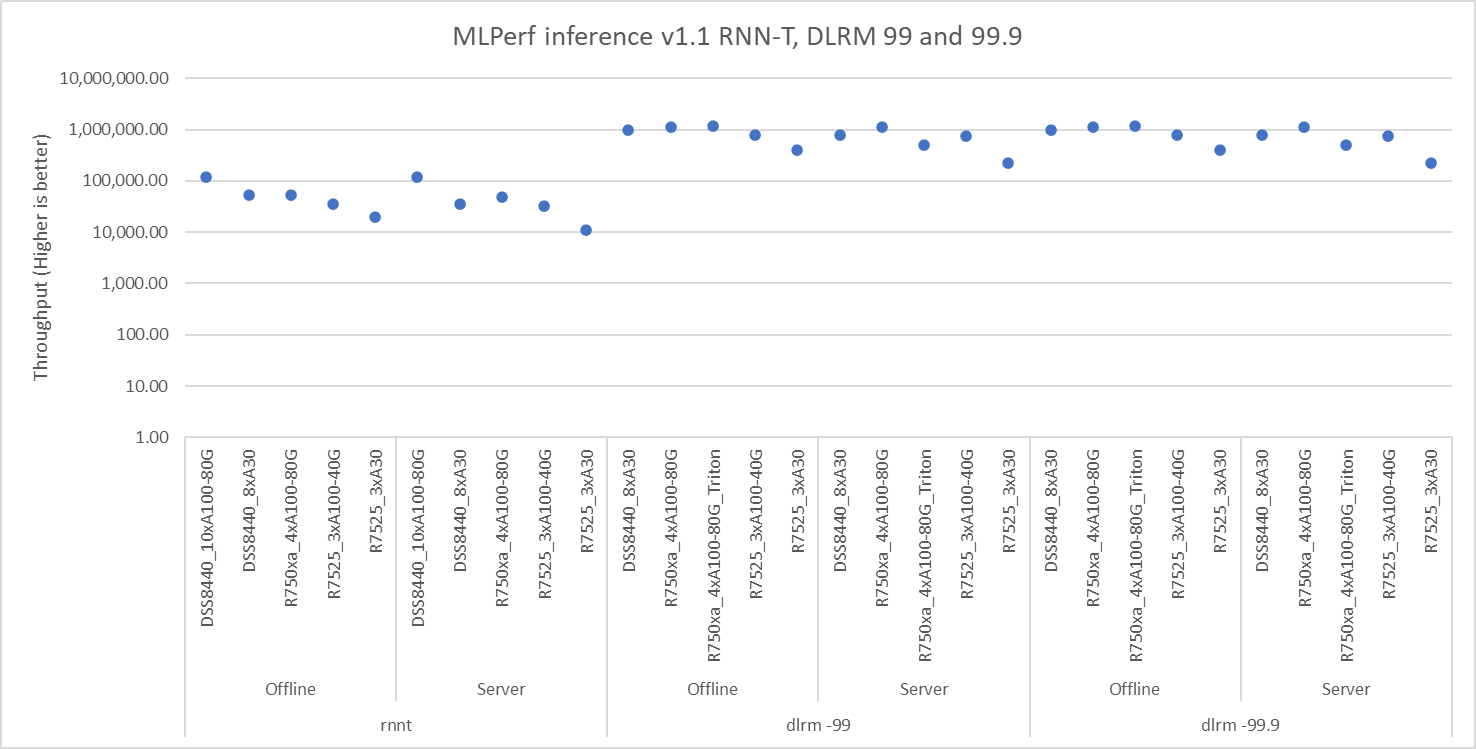
Figure 2: RNN-T, DLRM default, and high accuracy results
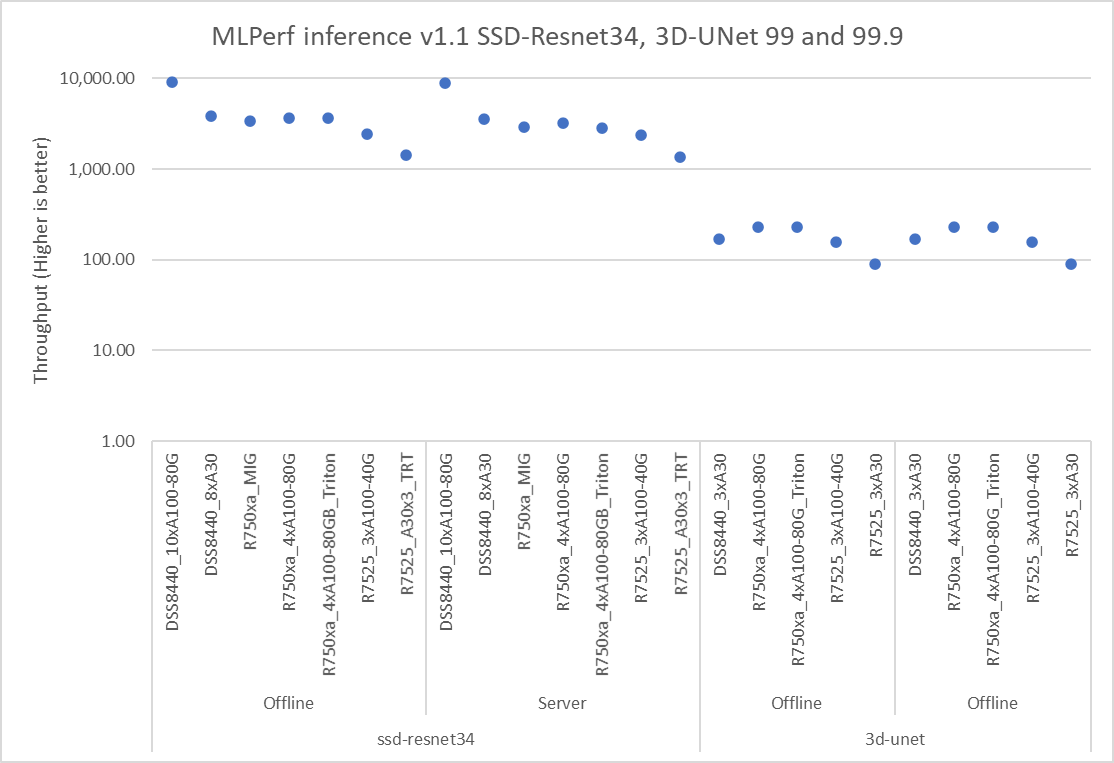
Figure 3: SSD-Resnet34, 3D-UNet default, and high accuracy results
Figure 4 shows the performance of the Dell EMC R750xa server that was benchmarked for the 3D-UNet, BERT 99, BERT 99.9, Resnet and SSD-Resnet34 models. The SUT provided high throughput while maintaining low power consumption. Higher throughputs were achieved with similar power usage for different models. These throughputs established our results in the optimal performance and optimal performance per watt category.
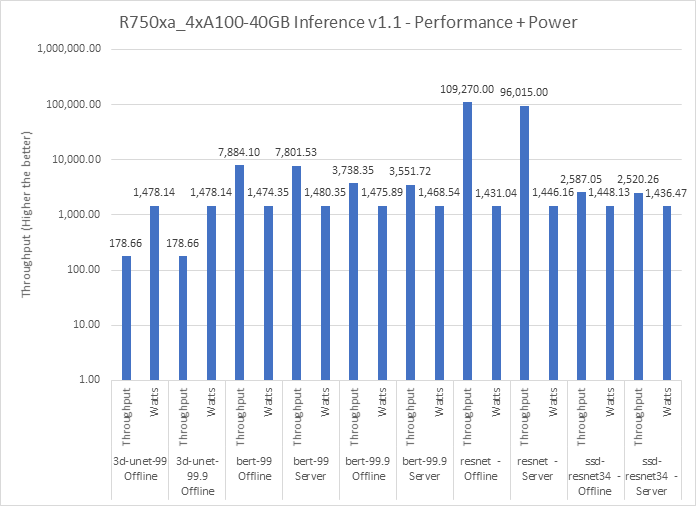
Figure 4: Performance and power submission with inference v1.1 with R750xa and 4 x NVIDIA A100–40G
Observations about results from Dell Technologies
All the preceding results are officially submitted to the MLCommonsTM consortium and verified. Submissions include performance and power-related numbers. Dell Technologies submissions include approximately 200 performance results and 80 performance and power results.
Different types of workload tasks such as image classification, object detection, medical image segmentation, speech to text, language processing, and recommendation were a part of these results, which were promising. These models met the quality-of-service targets as expected by the MLCommons consortium.
With different kinds of GPUs such as the NVIDIA A30 Tensor Core GPU, different NVIDIA A100 variants such as A100 40 GB PCIe and A100 80 GB PCIe, and different CPUs from AMD and Intel, Dell EMC servers performed with optimal performance and power results. Other Dell EMC SUT configuration results for the NVIDIA A40, RTX8000, and T4 GPUs can be found in the v1.0 results, which can be used for comparison with the v1.1 results.
The submission included results from different inference backends such as NVIDIA TensorRT, , and Multi-Instance GPU (MIG). The appendix includes a summary of the NVIDIA software stack.
All our systems are air-cooled. This feature allows data center administrators to perform minimal to no changes to accommodate these systems while delivering high throughput inference performance. Furthermore, Dell EMC servers offer high performance per watt more effectively without adding significant power constraints.
Conclusion
In this blog, we quantified the MLCommons inference v1.1 performance on different Dell EMC servers such as DSS8440 and PowerEdge R750xa and R7525 servers, producing many results. Customers can use these results to address the relative inference performance delivered by these servers. Dell EMC servers are powerful compute machines that deliver high throughput inference capabilities for customers inferencing requirements across different scenarios and workload types.
Next steps
In future blogs, we plan to describe:
- How to run MLPerf Inference v1.1
- The R750xa server as a platform for inference v1.1
- The DSS8440 server as a platform for inference v1.1
- Comparison of inference v1.0 performance with inference v1.1 performance
Appendix
NVIDIA software stack
NVIDIA Triton Inference Server is open-source software that aids the deployment of AI models at scale in production. It is an inferencing solution optimized for both CPUs and GPUs. Triton supports an HTTP/REST and GRPC protocol that allows remote clients to request inferencing for any model that the server manages. It adds support for multiple deep learning frameworks, enables high-performance inference, and is designed to consider IT, DevOps, and MLOps.
NVIDIA TensorRT is an SDK for high-performance, deep learning inference that includes an inference optimizer and runtime. It enables developers to import trained models from all major deep learning frameworks and optimizes them for deployment with the highest throughput and lowest latency, while preserving the accuracy of predictions. TensorRT-optimized applications perform up to 40 times faster on NVIDIA GPUs than CPU-only platforms during inference.
MIG can partition the A100 GPU into as many as seven instances, each fully isolated with their own high-bandwidth memory, cache, and compute cores. Administrators can support every workload, from the smallest to the largest, offering a right-sized GPU with guaranteed quality of service (QoS) for every job, optimizing utilization, and extending the reach of accelerated computing resources to every user.
SUT configurations
We selected servers with different types of NVIDIA GPUs as our SUT to conduct data center inference benchmarks. The following tables list the MLPerf system configurations for these servers.
Note: In the following tables, the main difference in the software stack is the use of NVIDIA Triton Inference Servers.
Table 3: MLPerf system configurations for Dell EMC DSS 8440 servers
| Platform | DSS8440_A100 | DSS8440_A30 | DSS8440_A30 |
| MLPerf System ID | DSS8440_A100-PCIE-80GBx10_TRT | DSS8440_A30x8_TRT | DSS8440_A30x8_TRT_Triton |
| Operating system | CentOS 8.2.2004 | ||
| CPU | Intel Xeon Gold 6248R CPU @ 3.00 GHz | Intel Xeon Gold 6248R | Intel Xeon Gold 6248R |
| Memory | 768 GB | 1 TB | |
| GPU | NVIDIA A100-PCIe-80GB | NVIDIA A30 | |
| GPU form factor | PCIe | ||
| GPU count | 10 | 8 | |
| Software stack | TensorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 | ||
| Triton 21.07 | |||
Table 4: MLPerf system configurations for PowerEdge servers
Platform | R750xa_A100 | R750xa_A100 | R750xa_A100 | R7525_A100 | R7525_A30 |
MLPerf System ID | R750xa_A100-PCIE-80GB-MIG_28x1g.10gb_TRT_Triton | R750xa_A100-PCIE-80GBx4_TRT | R750xa_A100-PCIE-80GBx4_TRT_Triton | R7525_A100-PCIE-40GBx3_TRT | R7525_A30x3_TRT |
Operating system | CentOS 8.2.2004
| ||||
CPU | Intel Xeon Gold 6338 | AMD EPYC 7502 32-Core Processor | AMD EPYC 7763 | ||
Memory | 1 TB | 512 GB | 1 TB | ||
GPU | NVIDIA A100-PCIE-80GB (7x1g.10gb MIG) | NVIDIA A100-PCIE-80GB
| NVIDIA A100-PCIE-40GB | NVIDIA A30 | |
GPU form factor | PCIe | ||||
GPU count | 4 | 3 | |||
Software stack | TensorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 | ||||
Triton 21.07 |
| Triton 21.07 |
| ||
Related Blog Posts
Inference Results Comparison of Dell Technologies Submissions for MLPerf™ v1.0 and MLPerf™ v1.1
Wed, 17 Nov 2021 20:43:29 -0000
|Read Time: 0 minutes
Abstract
The Dell Technologies HPC & AI Innovation Lab recently submitted results to the MLPerf Inference v1.1 benchmark suite. These results provide our customers with transparent information about the performance of Dell EMC servers. This blog highlights the enhancements between the MLPerf™ Inference v1.0 and MLPerf Inference v1.1 submissions from Dell Technologies. These enhancements include improved GPU performance and new software to extract performance. Also, this blog compares server and GPU configurations from the MLPerf Inference v1.0 and v1.1 submissions.
Configuration comparison
The MLPerf Inference submissions focus was on outperforming the expectations outlined by MLPerf. For an introduction to the MLPerf Inference v1.0 performance results, we recommend that you read this blog published by Dell Technologies.
The following table provides the software stack configurations from the two submissions for the closed division benchmarks:
Table 1: MLPerf Inference v1.0 and v1.1 software stacks
| v1.0 | v1.1 |
TensorRT | 7.2.3 | 8.0.2 |
CUDA | 11.1 | 11.3 |
cuDNN | 8.1.1 | 8.2.1 |
GPU driver | 460.32.03 | 470.42.01 |
DALI | 0.30.0 | 0.31.0 |
Triton |
| 21.07 |
The following table shows the Dell EMC servers used for the MLPerf Inference v1.0 and v1.1 submissions:
Table 2: Servers used for the MLPerf Inference v1.0 and v1.1 submissions
| v1.0 | v1.1 |
Server | Accelerator | Accelerator |
DSS 8440 | 10 x A100-PCIe-40GB 10 x A40 | 10 x NVIDIA A100-PCIE-80GB 8 x A30 (TensorRT) 8 x A30 (Triton) |
PowerEdge R7525 | 3 x Quadro RTX 8000 2 x A100-PCIe-40GB 3 x A100-PCIe-40GB | 3 x A100-PCIE-40GB 3 x A30 3 x GRID A100-40C |
PowerEdge R740 | 3 x NVIDIA A100-PCIe-40GB 4 x A100-PCIe-40GB |
|
PowerEdge R750 |
| ICX-6330(2S 28C) ICX-8352M(2S 32C) |
PowerEdge R750xa |
| 4 x A100-PCIE-40GB, MaxQ 4 x A100-PCIE-80GB-MIG-7x1g.10gb 4 x A100-PCIE-80GB (TensorRT) 4 x A100-PCIE-80GB (Triton) |
PowerEdge XE2420 | 4 x T4 | 2 x A10 |
PowerEdge XE8545 | 4 x A100-SXM-40GB 4 x A100-SXM-80GB | 4 x A100-SXM-80GB-7x1g.10gb 4 x A100-SXM-80GB (TensorRT) 4 x A100-SXM-80GB (Triton) |
PowerEdge XR12 |
| 2 x A10 |
Besides the upgrades in the software stack that are detailed in the preceding table and the results from the latest hardware, differences between the MLPerf Inference v1.0 and v1.1 submissions include:
- The Multistream scenario has been deprecated in MLPerf v1.1.
- The total number of submitters increased from 17 to 21.
- There were 1725 total submissions to MLCommons™ in v1.1.
MLPerf Inference v1.0 compared to MLPerf Inference v1.1
We compared the MLPerf v1.0 and v1.1 submissions by looking at results from an identical server and the same GPU configurations used in both rounds of submission. For both submissions, Dell Technologies submitted results for the Dell EMC PowerEdge XE8545 server configured with four A100 SXM 80 GB GPUs. The PowerEdge XE8545 servers used a combination of the latest AMD CPUs and powerful NVIDIA A100 Tensor Core GPUs. The PowerEdge XE8545 Spec Sheet provides additional details about the server.
The following figure shows nearly level performance across the two submissions, which allows for a fair comparison between the submissions. Also, it shows that we need to be aware of the software upgrades listed in Table 1, no matter how minimal.
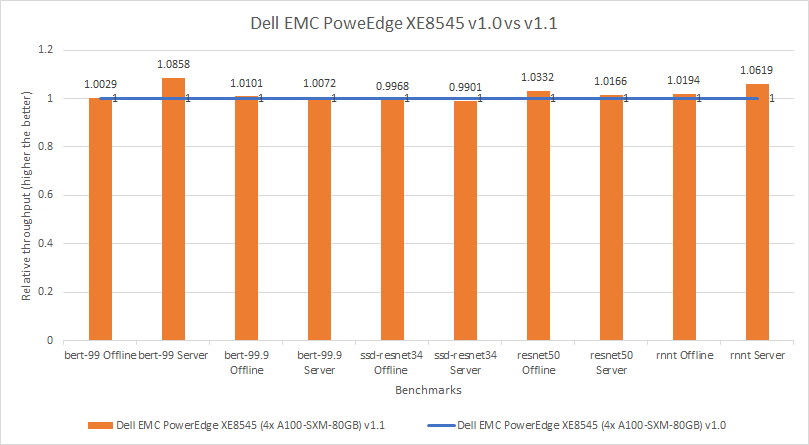
Figure 1: Relative performance comparison of PowerEdge XE8545 4 x A100 SXM 80 GB in MLPerf v1.0 and v1.1
Dell EMC systems improvements for MLPerf Inference v1.1
This section provides detailed comparisons of various GPUs across the MLPerf Inference v1.0 and v1.1 submissions to show an expansion of Dell EMC server and GPU configurations that are available.
A100 40 GB GPU compared with A100 80 GB GPU
Dell EMC DSS 8440 server
The Dell EMC DSS 8440 server delivers high performance at a lower cost compared to our competitors. By offering support for four, eight, or 10 GPUs, this server excels in processing capacity along with a flexible infrastructure. The DSS 8440 server delivers high performance for machine learning workloads. The DSS 8440 Spec Sheet provides more details about the server.
The following figure compares two DSS 8440 servers configured with NVIDIA A100 Tensor Core GPUs. For the v1.0 submission, the DSS 8440 server was configured with the A100 40 GB GPU (shown in blue). For the v1.1 submission, the DSS 8440 server was configured with the A100 80 GB GPU (shown in orange). Across the different models, the performance improvement was between three percent to 20 percent, favoring the system with the A100 80 GB GPU. The more than 10 percent performance improvement can be attributed to the frequency of each card; the A100 80 GB GPU is a 300W card whereas the A100 40 GB GPU is 250W card.
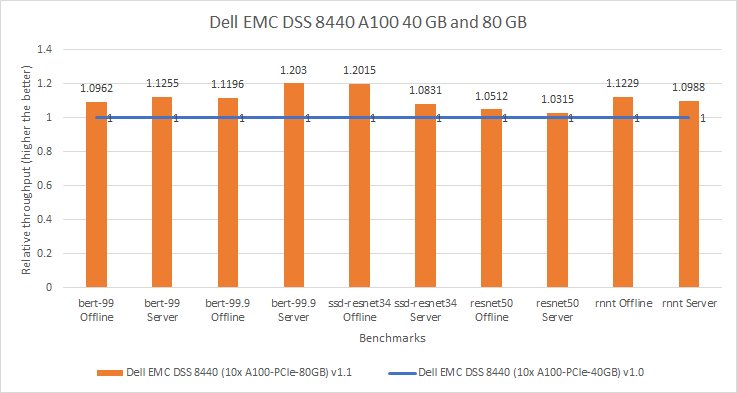
Figure 2: Relative performance comparison of DSS 8440 10 x A100 PCIe 40 GB and 80 GB in MLPerf v1.0 and v1.1
Dell EMC PowerEdge R750xa server
The PowerEdge R750xa server is ideal for Artificial Intelligence (AI)/Machine Learning (ML)/Deep Learning (DL) training and inferencing, high performance computing, and virtualization. See the Dell EMC PowerEdge R750xa Spec Sheet for more information about the server.
For this comparison, the server for both submissions was consistent. For the MLPerf v1.0 submission, the PowerEdge R750xa server was configured with four A100 40 GB GPUs. For the MLPerf v1.1 submission, the PowerEdge R750xa server was configured with four A100 80 GB GPUs. The following figure shows that for the MLPerf v1.1 submission, extra performance was extracted from the system. Across the various models, the MLPerf v1.1 results are seven percent to 22 percent better than the results from the MLPerf v1.0 submission. In the Resnet50 benchmark, the MLPerf v1.1 results are an impressive 15 and 19 percent better in the Offline and Server scenarios respectively.
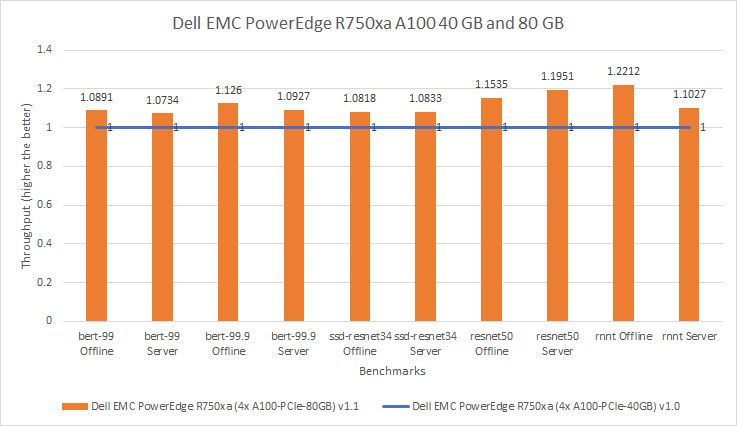
Figure 3: Relative performance of PowerEdge R750xa 4 x A100 40 GB GPU and 80 GB in MLPerf v1.0 and v1.1 respectively
Dell EMC PowerEdge XE8545 server
For the MLPerf v1.0 submission, the PowerEdge XE8545 server was configured with the A100 SXM4 40 GB GPU (shown in blue in figures 4 and 5) and the A100 SXM4 80 GB GPU (shown in orange in figures 4 and 5). For the MLPerf v1.1 submission, the PowerEdge XE 8545 server was configured with the A100 SXM4 80 GB GPU (shown in gray in figures 4 and 5). It was expected that for the MLPerf v1.0 submission, the A100 SXM4 80 GB GPU would outperform the A100 SXM4 40 GB GPU. Across the models in the MLPerf v1.1 submission, the A100 SXM4 80 GB GPU performed between negative one percent (a negative value indicates a performance deficit, noted for SSD ResNet34 in Figure 5) and eight percent better than the identical system in the MLPerf v1.0 submission. Interestingly, for the SSD Resnet-34 benchmark, the A100 GPU in the MLPerf v1.0 submission slightly outperformed the A100 GPU in the MLPerf v1.1 submission.
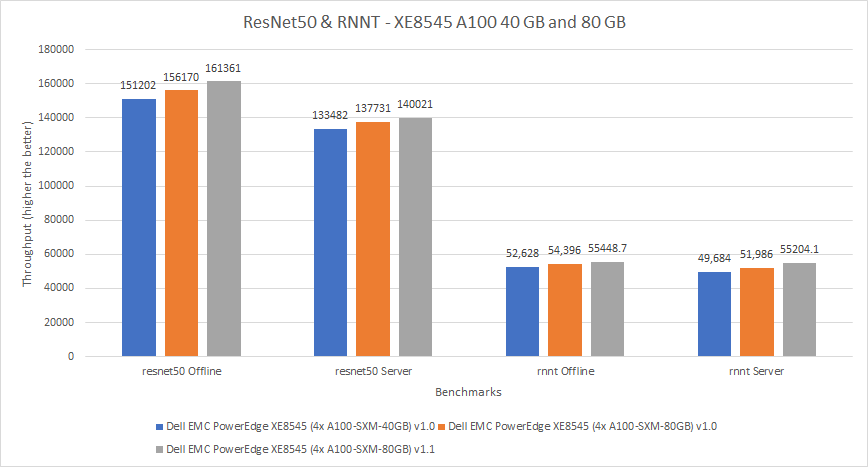
Figure 4: Performance of PowerEdge XE8545 4 x A100 40 GB and 80 GB in MLPerf v1.0 and 80 GB in MLPerf v1.1 for ResNet50 and RNNT
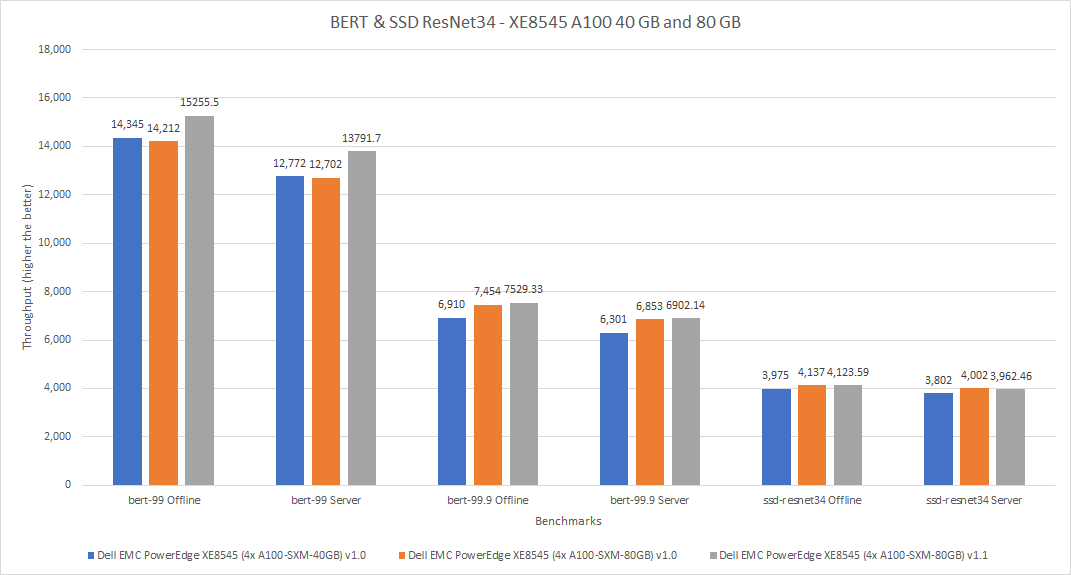
Figure 5: Performance of PowerEdge XE8545 4 x A100 40 GB and 80 GB in MLPerf v1.0 and 80 GB in MLPerf v1.1 for BERT and SSD ResNet34
NVIDIA A30 GPU compared with NVIDIA A40 GPU
This comparison considers the NVIDIA A40 and NVIDIA A30 Tensor Core GPU. For a fair comparison between the two GPUs, the DSS 8440 server configuration was consistent across the two submissions. For the MLPerf v1.0 submission, the DSS 8440 server was configured with ten A40 GPUs. For the MLPerf v1.1 submission, the server was configured with eight A30 GPUs. For a clear interpretation of the two GPUs, the results in Figure 6 are presented as the per card performance numbers, which means that the throughput results from the A40 GPU have been divided by ten and the results from the A30 GPU have been divided by eight.
The system configured with the A30 GPU performed 15 to 111 percent better than the A40 GPU across the various benchmarks. The A30 GPU is ideal for inference as it is configured with a High Bandwidth Memory (HBM2) and a higher GPU frequency. The A40 GPU is positioned more for Virtual Desktop Infrastructure (VDI) and other workloads.
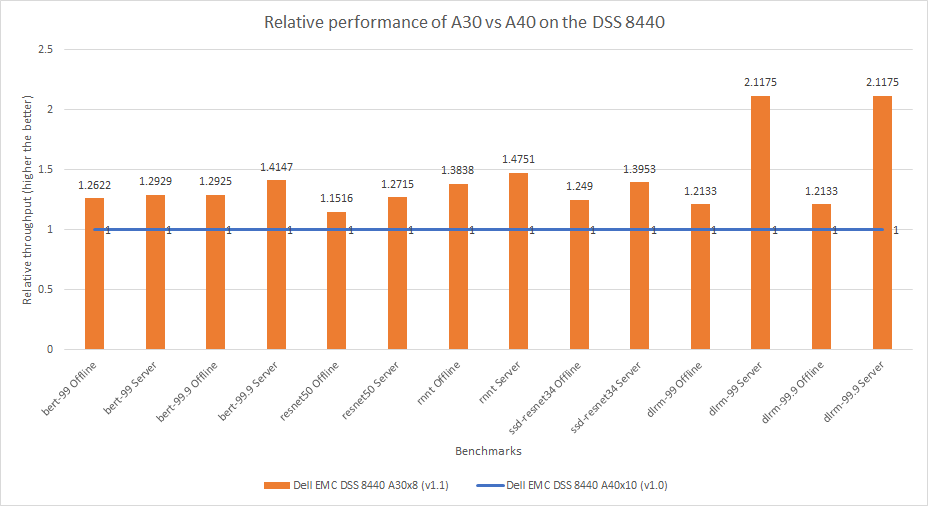
Figure 6: Per card relative performance comparison of the DSS 8440 server with A30 and A40 GPUs in MLPerf v1.0 and v1.1
Comparison of NVIDIA T4, A30, and A10 GPUs
This comparison considers three submissions on three different servers. The numbers are divided to display per card performance.
The Dell EMC PowerEdge XE2420 server is a specialty edge server that supports demanding applications at the edge, retail applications and analytics, manufacturing and logistics applications, and 5G cell processing. See the PowerEdge XE2420 Spec Sheet for more information. Our lab configured the system with four NVIDIA Tesla T4 GPUs that have been optimized for high utilization while also performing in an energy-efficient manner. The results from this system were published in the MLPerf Inference v1.0 Results.
The second server in this comparison is the DSS 8440 server, which was configured with eight NVIDIA A30 GPUs. The final server in this comparison is the PowerEdge XE2420 server, which was configured with two NVIDIA A10 GPUs.
The three cards in this comparison have different form factors; the A10 and A30 GPUs are larger than the T4 GPU. The following figure shows that the A30 GPU performed better than the other two GPUs. Across the various benchmarks, the A30 GPU performed between 204 and 360 percent better than the T4 GPU and between five percent and 57 percent better than the A10 GPU.
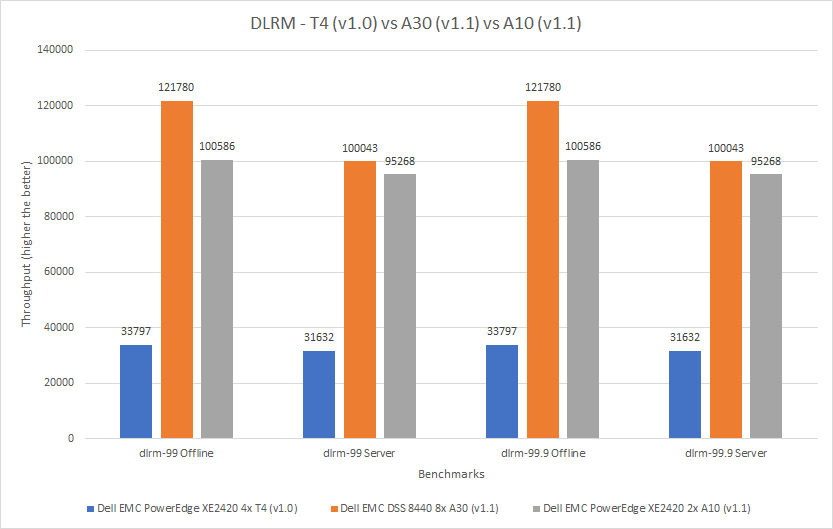
Figure 7: Comparison of T4, A30, and A10 GPUs for DLRM
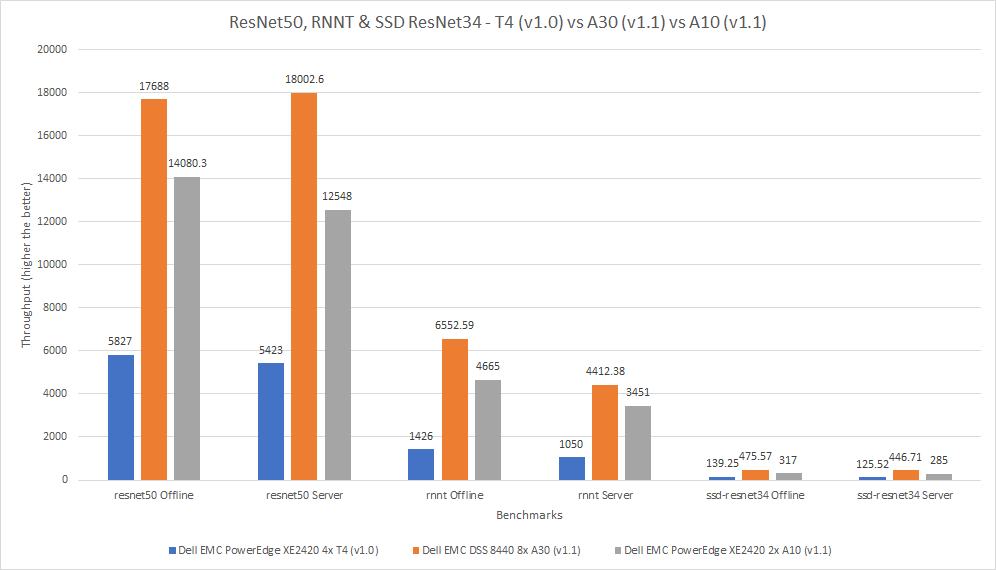
Figure 8: Comparison of T4, A40, and A10 GPUs for ResNet50, RNNT, and SSD ResNet34
Comparison of NVIDIA T4 GPU, A30 Multi-Instance GPU (MIG), and A100 MIG
This comparison also considers three submissions on three different servers. The results from the Resnet50 and SSD Resnet34 benchmarks have been divided to display per card performance.
The PowerEdge XE2420 server was configured with four NVIDIA Tesla T4 GPUs. The results for this system are from the MLPerf v1.0 submission. The PowerEdge R7525 server was configured with three NVIDIA A30 GPUs. MIG was enabled on all these GPUs with a profile of 1g6gb. We did not publish the A30 MIG results on the PowerEdge R7525 server to MLCommons, but the results are compliant.
The PowerEdge R750xa server was configured with four NVIDIA A100 80 GB GPUs, which support Multi-Instance GPU (MIG) and Peripheral Component Interconnect Express (PCIe). MIG is an enhancement for NVIDIA GPUs with the Ampere architecture that allows for seven secure partitions of GPU instances. This architecture is beneficial because it allows for increased parallelism. The results from this system were submitted in the MLPerf Inference v1.1 submission. There are different sizes of MIG slices. The configuration for the A30 and A100 GPUs used the smallest slice possible. For example, the A100 GPU was divided into seven slices and the A30 GPU into four slices.
The following figures show results across the MLPerf v1.0 and v1.1 submissions from Dell Technologies for ResNet50 and SSD ResNet34. Figure 9 shows per physical GPU results. For the ResNet50 Offline benchmark, the A30 GPU performed 232 percent better than the T4 GPU, while the A100 GPU performed 76 percent better than the A30 GPU. In the ResNet 50 Server mode, the A30 GPU outperformed the T4 GPU by 50 percent and the A100 GPU outperformed the A30 GPU by 23 percent. We observed a similar trend across the Offline and Server modes where the A100 GPU outperformed the A30 GPU, which outperformed the T4 GPU.
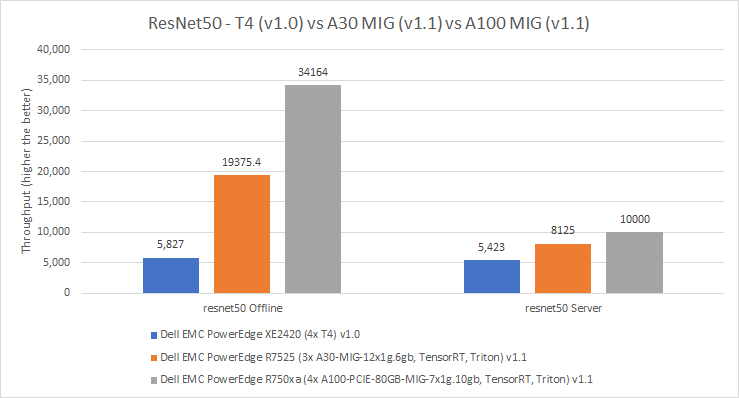
Figure 9: Per card performance of the T4 GPU, A30 MIG, and A100 MIG for ResNet50
In the SSD ResNet34 benchmark, we observed a similar trend where the performance of the A100 GPU was better than the performance of the A30 GPU, which performed better than the T4 GPU. In the Offline mode of the SSD ResNet34 benchmark, the A30 GPU performed 243 percent better than the T4 GPU, and the A100 GPU performed 77 percent better than the A30 GPU. In the Server mode, the A100 GPU outperformed the A30 GPU by 93 percent and the A30 GPU performed 198 percent better than the T4 GPU.
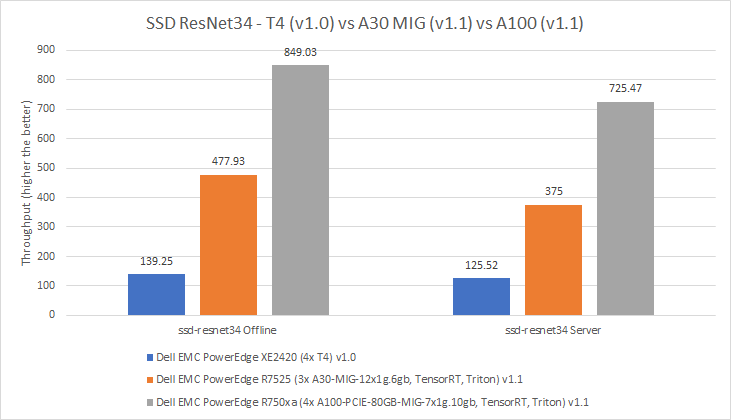
Figure 10: Per card performance of the T4 GPU, A30 MIG, and A100 MIG for SSD ResNet34
Conclusion
This blog has provided a brief introduction to MLPerf Inference benchmarking and a summary of the Dell Technologies submission from MLPerf Inference v1.0. Also, it highlighted the differences in the software stack between the MLPerf v1.0 and v1.1 submissions. This blog quantified results from various server and GPU configurations across the two rounds of MLPerf submissions and displayed noteworthy and relevant performance comparisons.
When comparing the A100 40 GB to the A100 80 GB GPUs on the Dell EMC DSS 8440 server, the latter exhibited an 11 percent increase in performance. On the Dell EMC PowerEdge R750xa server, the A100 PCIe 80 GB GPU performed 12 percent better than the A100 PCIe 40 GB GPU. The Dell EMC PowerEdge XE8545 server confirmed this result for the MLPerf v1.1 submission; the A100 SXM 80 GB GPU performed three percent better than an identical system from the MLPerf v1.0 submission.
The A30 and A40 GPU comparison showed that the former achieved a notable 42 percent performance improvement while maintaining the Dell EMC DSS 8440 server.
The comparison between the T4, A30, and A10 GPUs revealed that the A30 GPU performed significantly better than the T4 GPU and is considered a good upgrade for your ML workloads. The T4 GPU, A30 MIG, and A100 MIG were compared based on results from the ResNet50 and SSD-ResNet34 benchmarks.
MLPerf™ Inference v4.0 Performance on Dell PowerEdge R760xa and R7615 Servers with NVIDIA L40S GPUs
Fri, 05 Apr 2024 17:41:56 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf™ Inference v4.0 benchmark suite. This blog highlights Dell Technologies’ closed division submission made for the Dell PowerEdge R760xa, Dell PowerEdge R7615, and Dell PowerEdge R750xa servers with NVIDIA L40S and NVIDIA A100 GPUs.
Introduction
This blog provides relevant conclusions about the performance improvements that are achieved on the PowerEdge R760xa and R7615 servers with the NVIDIA L40S GPU compared to the PowerEdge R750xa server with the NVIDIA A100 GPU. In the following comparisons, we held the GPU constant across the PowerEdge R760xa and PowerEdge R7615 servers to show the excellent performance of the NVIDIA L40S GPU. Additionally, we also compared the PowerEdge R750xa server with the NVIDIA A100 GPU to its successor the PowerEdge R760xa server with the NVIDIA L40S GPU.
System Under Test configuration
The following table shows the System Under Test (SUT) configuration for the PowerEdge servers.
Table 1: SUT configuration of the Dell PowerEdge R750xa, R760xa, and R7615 servers for MLPerf Inference v4.0
Server | PowerEdge R750xa | PowerEdge R760xa | PowerEdge R7615 |
MLPerf Version | V4.0
| ||
GPU | NVIDIA A100 PCIe 80 GB | NVIDIA L40S
| |
Number of GPUs | 4 | 2 | |
MLPerf System ID | R750xa_A100_PCIe_80GBx4_TRT | R760xa_L40Sx4_TRT | R7615_L40Sx2_TRT
|
CPU | 2 x Intel Xeon Gold 6338 CPU @ 2.00GHz | 2 x Intel Xeon Platinum 8470Q | 1 x AMD EPYC 9354 32-Core Processor |
Memory | 512 GB | ||
Software Stack | TensorRT 9.3.0 CUDA 12.2 cuDNN 8.9.2 Driver 535.54.03 / 535.104.12 DALI 1.28.0 | ||
The following table lists the technical specifications of the NVIDIA L40S and NVIDIA A100 GPUs.
Table 2: Technical specifications of the NVIDIA A100 and NVIDIA L40S GPUs
Model | NVIDIA A100 | NVIDIA L40S | ||
Form factor | SXM4 | PCIe Gen4 | PCIe Gen4 | |
GPU architecture | Ampere | Ada Lovelace | ||
CUDA cores | 6912 | 18176 | ||
Memory size | 80 GB | 48 GB | ||
Memory type | HBM2e | HBM2e | ||
Base clock | 1275 MHz | 1065 MHz | 1110 MHz | |
Boost clock | 1410 MHz | 2520 MHz | ||
Memory clock | 1593 MHz | 1512 MHz | 2250 MHz | |
MIG support | Yes | No | ||
Peak memory bandwidth | 2039 GB/s | 1935 GB/s | 864 GB/s | |
Total board power | 500 W | 300 W | 350 W | |
Dell PowerEdge R760xa server
The PowerEdge R760xa server shines as an Artificial Intelligence (AI) workload server with its cutting-edge inferencing capabilities. This server represents the pinnacle of performance in the AI inferencing space with its processing prowess enabled by Intel Xeon Platinum processors and NVIDIA L40S GPUs. Coupled with NVIDIA TensorRT and CUDA 12.2, the PowerEdge R760xa server is positioned perfectly for any AI workload including, but not limited to, Large Language Models, computer vision, Natural Language Processing, robotics, and edge computing. Whether you are processing image recognition tasks, natural language understanding, or deep learning models, the PowerEdge R760xa server provides the computational muscle for reliable, precise, and fast results.

Figure 1: Front view of the Dell PowerEdge R760xa server

Figure 2: Top view of the Dell PowerEdge R760xa server
Dell PowerEdge R7615 server
The PowerEdge R7615 server stands out as an excellent choice for AI, machine learning (ML), and deep learning (DL) workloads due to its robust performance capabilities and optimized architecture. With its powerful processing capabilities including up to three NVIDIA L40S GPUs supported by TensorRT, this server can handle complex neural network inference and training tasks with ease. Powered by a single AMD EPYC processor, this server performs well for any demanding AI workloads.

Figure 3: Front view of the Dell PowerEdge R7615 server

Figure 4: Top view of the Dell PowerEdge R7615 server
Dell PowerEdge R750xa server
The PowerEdge R750xa server is a perfect blend of technological prowess and innovation. This server is equipped with Intel Xeon Gold processors and the latest NVIDIA GPUs. The PowerEdge R760xa server is designed for the most demanding AI, ML, and DL workloads as it is compatible with the latest NVIDIA TensorRT engine and CUDA version. With up to nine PCIe Gen4 slots and availability in a 1U or 2U configuration, the PowerEdge R750xa server is an excellent option for any demanding workload.

Figure 5: Front view of the Dell PowerEdge R750xa server

Figure 6: Top view of the Dell PowerEdge R750xa server
Performance results
Classical Deep Learning models performance
The following figure presents the results as a ratio of normalized numbers over the Dell PowerEdge R750xa server with four NVIDIA A100 GPUs. This result provides an easy-to-read comparison of three systems and several benchmarks.
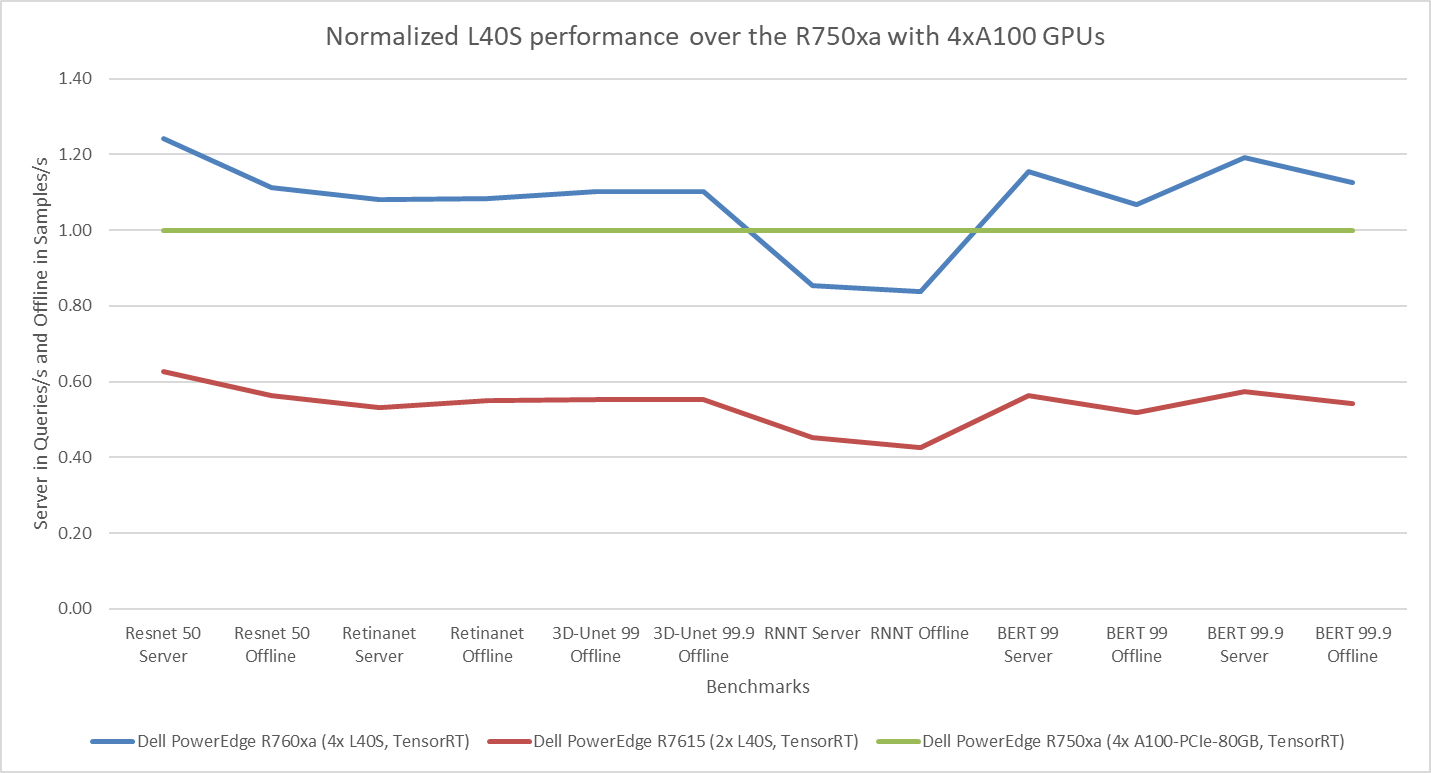
Figure 7: Normalized NVIDIA L40S GPU performance over the PowerEdge R750xa server with four A100 GPUs
The green trendline represents the performance of the Dell PowerEdge R750xa server with four NVIDIA A100 GPUs. With a score of 1.00 for each benchmark value, the results have been divided by themselves to serve as the baseline in green for this comparison. The blue trendline represents the performance of the PowerEdge R760xa server with four NVIDIA L40S GPUs that has been normalized by dividing each benchmark result by the corresponding score achieved by the PowerEdge R750xa server. In most cases, the performance achieved on the PowerEdge R760xa server outshines the results of the PowerEdge R750xa server with NVIDIA A100 GPUs, proving the expected improvements from the NVIDIA L40S GPU. The red trendline has also been normalized over the PowerEdge R750xa server and represents the performance of the PowerEdge R7615 server with two NVIDIA L40S GPUs. It is interesting that the red line almost mimics the blue line. This result suggests that the PowerEdge R7615 server, despite having half the compute resources, still performs comparably well in most cases, showing its efficiency.
Generative AI performance
The latest submission saw the introduction of the new Stable Diffusion XL benchmark. In the context of generative AI, stable diffusion is a text to image model that generates coherent image samples. This result is achieved gradually by refining and spreading out information throughout the generation process. Consider the example of dropping food coloring into a large bucket of water. Initially, only a small, concentrated portion of the water turns color, but gradually the coloring is evenly distributed in the bucket.
The following table shows the excellent performance of the PowerEdge R760xa server with the powerful NVIDIA L40S GPU for the GPT-J and Stable Diffusion XL benchmarks. The PowerEdge R760xa takes the top spot in GPT-J and Stable Diffusion XL when compared to other NVIDIA L40S results.
Table 3: Benchmark results for the PowerEdge R760xa server with the NVIDIA L40S GPU
Benchmark | Dell PowerEdge R760xa L40S result (Server in Queries/s and Offline in Samples/s) | Dell’s % gain to the next best non-Dell results (%) |
Stable Diffusion XL Server | 0.65 | 5.24 |
Stable Diffusion XL Offline | 0.67 | 2.28 |
GPT-J 99 Server | 12.75 | 4.33 |
GPT-J 99 Offline | 12.61 | 1.88 |
GPT-J 99.9 Server | 12.75 | 4.33 |
GPT-J 99.9 Offline | 12.61 | 1.88 |
Conclusion
The MLPerf Inference submissions elicit insightful like-to-like comparisons. This blog highlights the impressive performance of the NVIDIA L40S GPU in the Dell PowerEdge R760xa and PowerEdge R7615 servers. Both servers performed well when compared to the performance of the Dell PowerEdge R750xa server with the NVIDIA A100 GPU. The outstanding performance improvements in the NVIDIA L40S GPU coupled with the Dell PowerEdge server position Dell customers to succeed in AI workloads. With the advent of the GPT-J and Stable diffusion XL Models, the Dell PowerEdge server is well positioned to handle Generative AI workloads.