




Inferencing at the Edge

Inferencing Defined
Inferencing, in the context of artificial intelligence (AI) and machine learning (ML), refers to the process of classifying or making predictions based on the input information. It involves using existing knowledge or learned knowledge to arrive at new insights or interpretations.
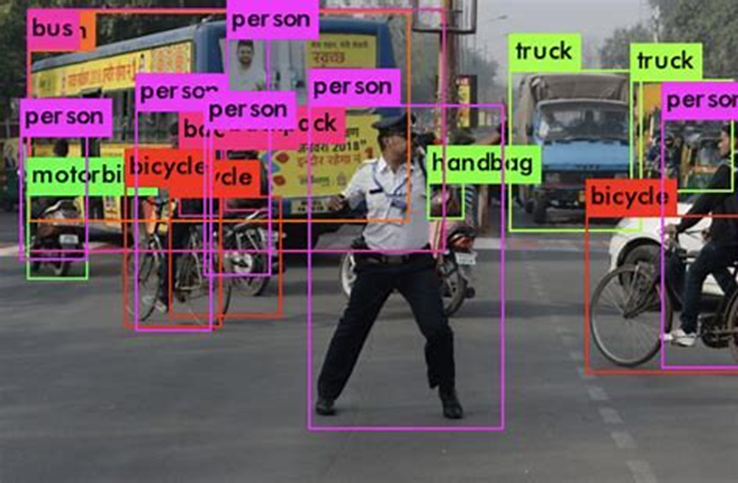 Figure 1. Inferencing use case – real-time image classification
Figure 1. Inferencing use case – real-time image classification
The Need for Edge Inferencing
Data growth driven by data-intensive applications and ubiquitous sensors to enable real-time insight is growing three times faster than traditional methods that require network access. This drives data processing at the edge to keep up with the pace and reduce cloud cost and latency. S&P Global Market Intelligence estimates that by 2027, 62 percent of enterprises data will be processed at the edge.
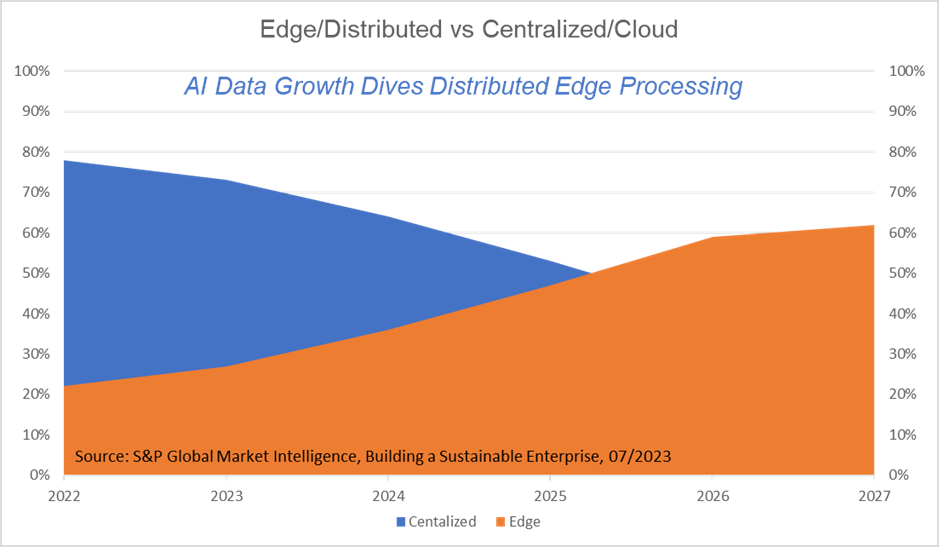 Figure 2. Data growth driven by sensors, apps, and real-time insights driving AI computation to the edge
Figure 2. Data growth driven by sensors, apps, and real-time insights driving AI computation to the edge
How Does Inferencing Work?
Inferencing is a crucial aspect of various AI applications, including natural language processing, computer vision, graph processes, and robotics.
The process of inferencing typically involves the following steps:
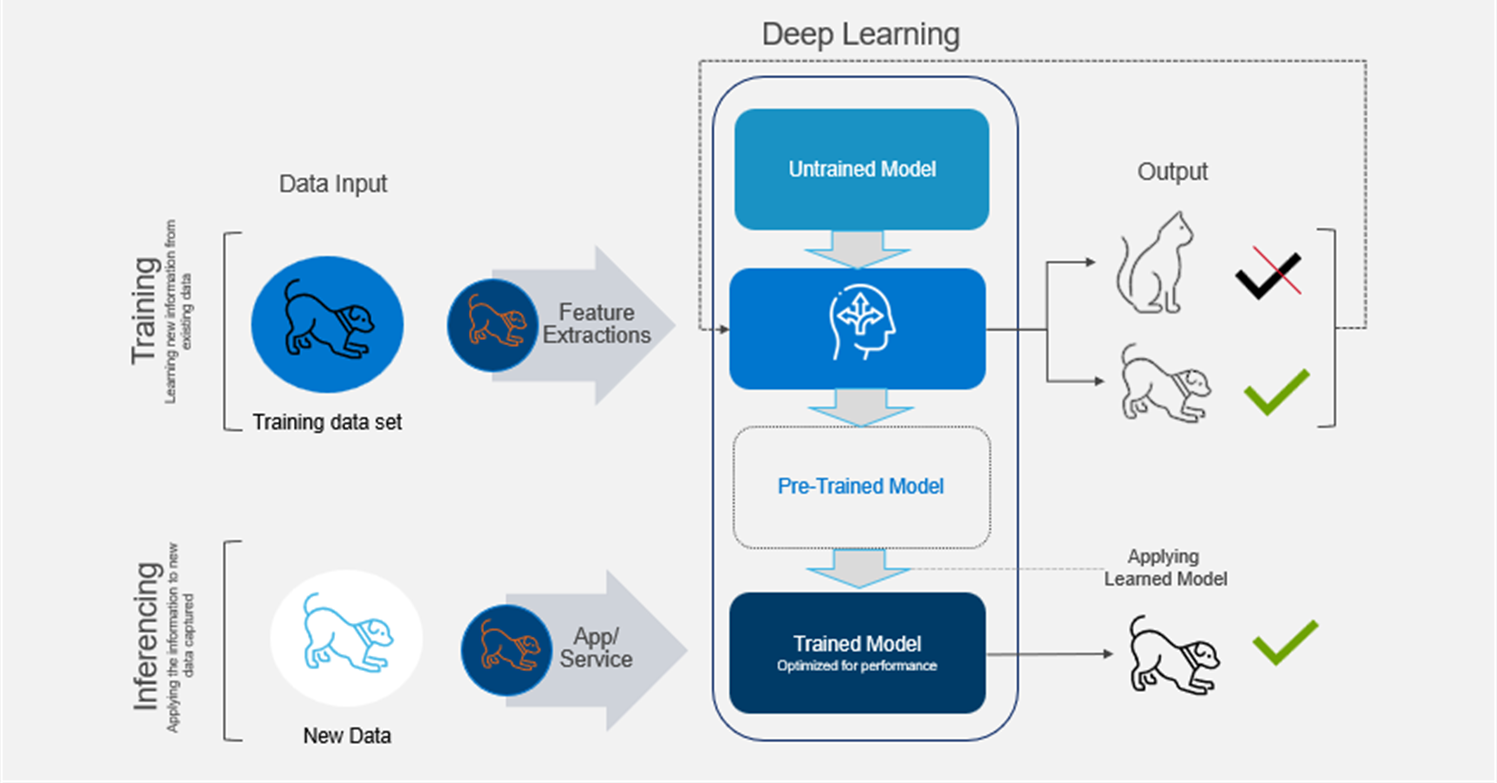 Figure 3. From training to inferencing
Figure 3. From training to inferencing
- Data input—The AI model receives input data, which could be text, images, audio, or any other form of structured or unstructured data.
- Feature extraction—For complex data like images or audio, the AI model may need to extract relevant features from the input data to represent it in a suitable format for processing.
- Pre-trained model—In many cases, AI models are pre-trained on large datasets using techniques like supervised learning or unsupervised learning. During this phase, the model learns patterns and relationships in the data.
- Applying learned knowledge—When new data is presented to the model for inferencing, it applies the knowledge it gained during the training phase to make predictions and classifications or generate responses.
- Output—The model produces an output based on its understanding of the input data.
Edge Inferencing
Inference at the edge is a technique that enables data-gathering from devices to provide actionable intelligence using AI techniques rather than relying solely on cloud-based servers or data centers. It involves installing an edge server with an integrated AI accelerator (or a dedicated AI gateway device) close to the source of data, which results in much faster response time. This technique improves performance by reducing the time from input data to inference insight, and reduces the dependency on network connectivity, ultimately improving the business bottom line. Inference at the edge also improves security as the large dataset does not have to be transferred to the cloud. For more information, see Edge Inferencing is Getting Serious Thanks to New Hardware, What is AI Inference at the Edge?, and Edge Inference Concept Use Case Architecture.
In short, inferencing is the process of an AI model using what it has learned to give us useful answers quickly. This can happen at the edge or on a personal device which maintains privacy and shortens response time.
Challenges
Computational challenges
AI inferencing can be challenging because edge systems may not always have sufficient resources. To be more specific, here are some of the key challenges with edge inferencing:
- Limited computational resources—Edge devices often have less processing power and memory compared to cloud servers. This may limit the complexity and size of AI models that can be deployed at the edge.
- Model optimization—AI models may need to be optimized and compressed to run efficiently on resource-constrained edge devices while maintaining acceptable accuracy.
- Model updates—Updating AI models at the edge can be more challenging than in a centralized cloud environment, as devices might be distributed across various locations and may have varying configurations.
Operational challenges
Handling a deep learning process involves continuous data pipeline management and infrastructure management. This leads to the following question:
- How do I manage the acquisition to the edge platform of the models, how do I stage the model, and how do I update the model?
- Do I have sufficient computational and network resources for the AI inference to execute properly?
- How do I manage the drift and security (privacy protection and adversarial attack) of the model?
- How do I manage the inference pipelines, insight pipelines, and datasets associated with the models?
Edge Inferencing by Example
To illustrate how inferencing works, we use TensorFlow as our deep learning framework.
TensorFlow is an open-source deep learning framework developed by the Google Brain team. It is widely used for building and training ML models, especially those based on neural networks.
The following example illustrates how to create a deep learning model in TensorFlow. The model takes a set of images and classifies them into separate categories, for example, sea, forest, or building.
We can create an optimized version of that TensorFlow Lite model with post-training quantization. The edge inferencing works using TensorFlow-Lite as the underlying framework and Google Edge Tensor Processing Uni (TPU) as the edge device.
This process involves the following steps:
- Create the model.
- Train the model.
- Save the model.
- Apply post-training quantization.
- Convert the model to TensorFlow Lite.
- Compile the TensorFlow Lite model using edge TPU compiler for Edge TPU devices like Coral Dev board (Google development platform that includes the Edge TPU) to TPU USB Accelerator (this allows users to add Edge TPU capabilities to existing hardware by simply plugging in the USB device).
- Deploy the model at the edge to make inferences.
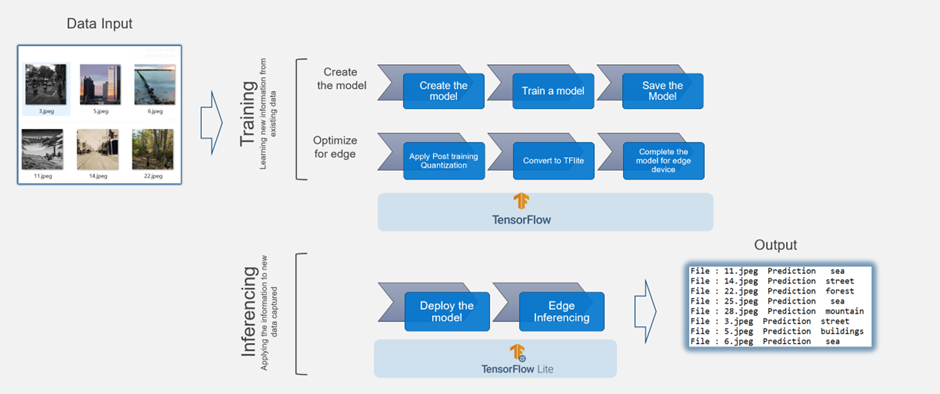 Figure 4. Image inferencing example using TensorFlow and TensorFlow Lite
Figure 4. Image inferencing example using TensorFlow and TensorFlow Lite
You can read the full example in this post: Step by Step Guide to Make Inferences from a Deep Learning at the Edge | by Renu Khandelwal | Towards AI
Conclusion
Inferencing is like a magic show, where AI models surprise us with their clever responses. It's used in many exciting areas like talking to virtual assistants, recognizing objects in pictures, and making smart decisions in various applications.
Edge inferencing allows us to bring the AI processing closer to the source of the data and thus gain the following benefits:
- Reduced latency—By performing inferencing locally on the edge device, the time required to send data to a centralized server and receive a response is significantly reduced. This is especially important in real-time applications where low latency is crucial, such as autonomous vehicles/systems, industrial automation, and augmented reality.
- Bandwidth optimization—Edge inferencing reduces the amount of data that needs to be transmitted to the cloud, which helps optimize bandwidth usage. This is particularly beneficial in scenarios where network connectivity might be limited or costly.
- Privacy and security—For certain applications, such as those involving sensitive data or privacy concerns, performing inferencing at the edge can help keep the data localized and minimize the risk of data breaches or unauthorized access.
- Offline capability—Edge inferencing allows AI models to work even when there is no internet connection available. This is advantageous for applications that need to function in remote or offline environments.
References
What is AI Inference at the Edge? | Insights | Steatite (steatite-embedded.co.uk)