




How to Create Object Storage in Dell APEX Data Storage Services (DSS)
Wed, 19 Jan 2022 21:18:36 -0000
|Read Time: 0 minutes
As of the December 2021 release of APEX DSS, Dell now supports creating object storage! APEX File Services provides multi-protocol data access and includes support for the S3 (Simple Storage Service) Object protocol.
During activation of APEX File deployments (or subsequently, in response to a Service Request), Dell Services will enable the specific data access protocols (SMB, NFS, and S3) as requested by the customer.
Object capabilities are a good fit for file users who are leveraging complex application designs that demand File and Object access to the same data, thus expanding file storage to include cloud-native workloads without the need to make a data set copy.
Here is a walkthrough of how to create S3 object storage in APEX DSS:
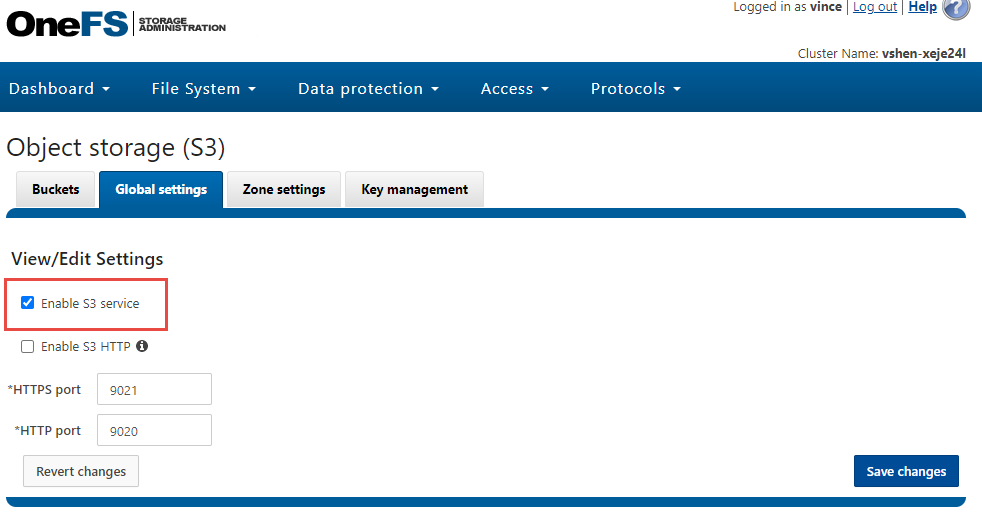
- Launch the OneFS web UI. Make sure the S3 object service is enabled by clicking Protocols > Object storage (S3) > Global settings:
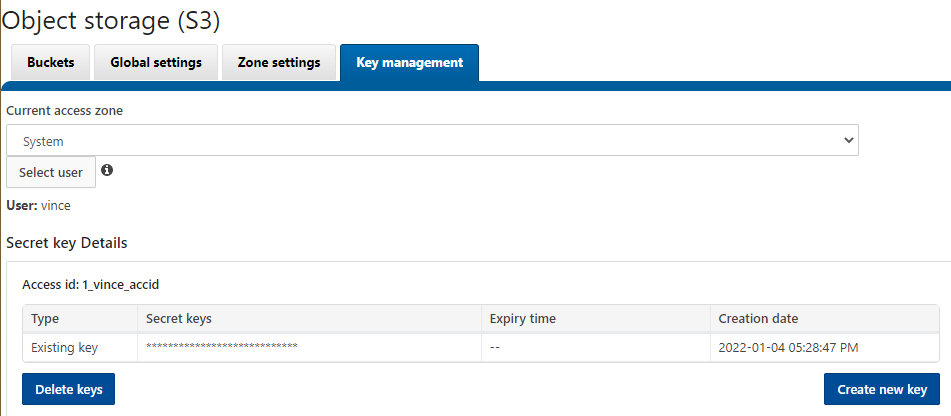
2. Create the secret key for the end-user. In this case, I will create the key for the user vince. Under the Key management tab in the Object storage (S3) panel, click Select user. Select the user vince and click the button Create a key. Note the Access id and the corresponding secret key for future use. In my case they are:
Access id: 1_vince_accid
Secret key: yHVUjcEJR1u1wq3glGJleAqXyVh6
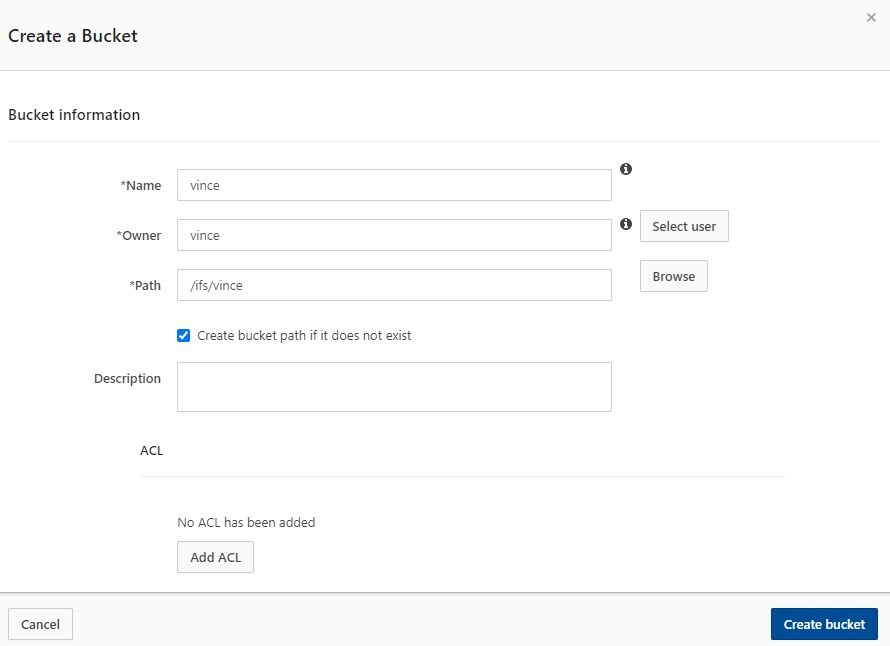
3. To create the S3 bucket, select the Buckets tab under the Object storage (S3) panel. Click the button Create bucket. In my example, I will create a bucket using the following parameters:
Bucket name: vince
Owner: vince
Path: /ifs/vince
4. Test your S3 object storage. You can use any S3 client tools for this purpose. In my case, I am using CloudBerry Explorer to set up the connection:
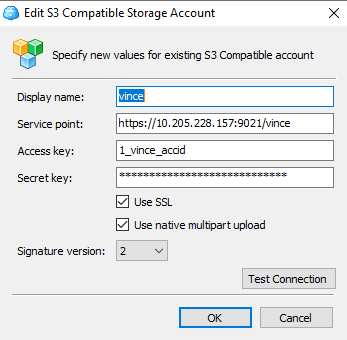
Note: by default, it will use an SSL certificate to encrypt the connection. The default port for HTTPS is 9021 which you can configure in the OneFS web UI under Global settings.
Conclusion
Using APEX DSS, you can easily deploy your S3 object storage in minutes. With this capability, clients can access APEX DSS file-based data as objects efficiently. OneFS S3 in APEX DSS is designed as a first-class protocol including features for bucket and object operations, security implementation, and management interface.
In our next blog, we will go through the colocation feature in APEX DSS for file.
Author: Vincent Shen
Related Blog Posts

Alert in IIQ 5.0.0 – Part I
Wed, 13 Dec 2023 17:40:06 -0000
|Read Time: 0 minutes
Alert is a new feature introduced with the release of IIQ 5.0.0. It provides the capability and flexibility to configure alerts based on the KPI threshold.
This blog will walk you through the following aspects of this feature:
- Introduction to Alert
- How to configure alerts using Alert
Let’s get started:
Introduction
IIQ 5.0.0 can send email alerts based on your defined KPI and threshold. The supported KPIs are listed in the following table:
KPI Name | Description | Scope |
Protocol Latency SMB | Average latency within last 10 minutes required for the various operations for the SMB protocol | Across all nodes and clients per cluster. |
Protocol Latency NFS | Average latency within last 10 minutes required for the various operations for the NFS protocol. | Across all nodes and clients per cluster. |
Active Clients NFS | The current number of active clients using NFS. The client is active when it is transmitting or receiving data. | Across all nodes per cluster. |
Active Clients SMB 1 | The current number of active clients using SMB 1. The client is active when it is transmitting or receiving data. | Across all nodes per cluster. |
Active Clients SMB 2 | The current number of active clients using SMB 2. The client is active when it is transmitting or receiving data. | Across all nodes per cluster. |
Connected Clients NFS | The current number of connected clients using NFS. The client is connected when it has an open TCP connection to the cluster. It can transmit or receive data or it can be in an idle state. | Across all nodes per cluster. |
Connected Clients SMB | The current number of connected clients using SMB. The client is connected when it has an open TCP connection to the cluster. It can transmit or receive data or it can be in an idle state. | Across all nodes per cluster. |
Pending Disk Operation Count | The average pending disk operation count within the last 10 minutes. It is the number of I/O operations that are pending at the file system level and waiting to be issued to an individual drive. | Across all disks per cluster. |
CPU Usage | The average usage of CPU cores including the physical cores and hyperthreaded core within last 10 minutes. | Across all nodes per cluster. |
Cluster Capacity | The current used capacity for the cluster. | N/A |
Nodepool Capacity | The current used capacity for the node pool in a cluster. | N/A |
Drive Capacity | The current used capacity for a drive in a cluster. | N/A |
Node Capacity | The current used capacity for a node in a cluster. | N/A |
Network Throughput Equivalency | Checks whether the network throughput for each node within the last 10 minutes is within the specified threshold percentage of the average network throughput of all nodes in the node pool for the same time. | Across all nodes per node pool. |
Each KPI requires a threshold and a severity level, together forming an alert rule. You can customize the alert rules to align with specific business use cases.

Here is an example of an alert rule:
If CPU usage (KPI) is greater than or equal to 96% (threshold), a critical alert (severity) will be triggered.
The supported severities are:
- Emergency
- Critical
- Warning
- Information
You can combine multiple alert rules into a single alert policy for easy management purposes.
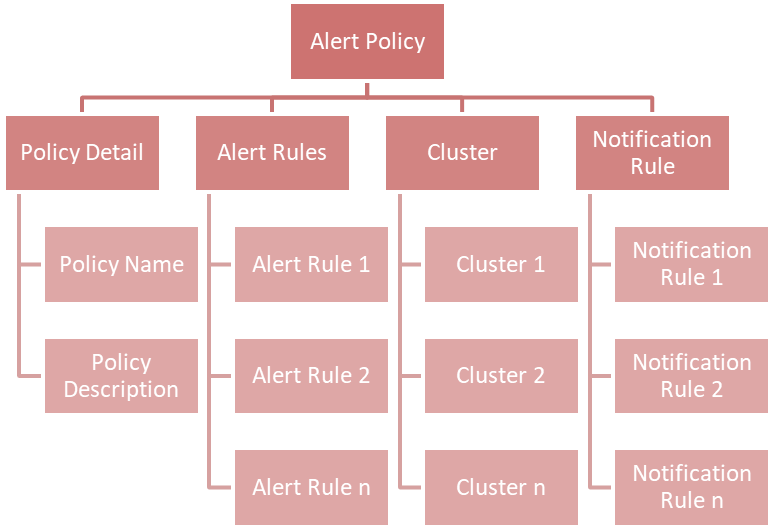
If you take a look at the chart above, you will find a new concept called Notification Rule. This is used to define the recipients' Email address and from what severity they will receive an Email:
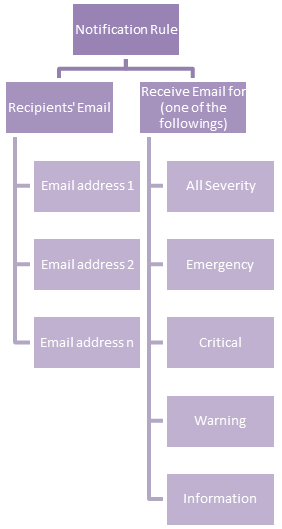
An example of a notification rule is like this: for user A (user_a@lled.com) and user B (user_b@lled.com), they both will receive Email alerts from all severity.
If you combine the above two examples and put them into the view of alert policy, you will get:
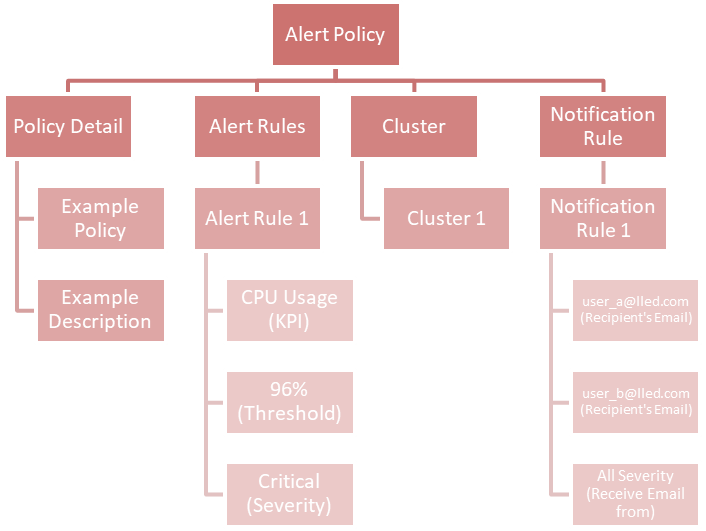
At this point, you should understand the big picture of the alert feature in IIQ 5.0.0. In my next post, I will walk you through the details of how to configure it.

How to Size Disk Capacity When Cluster Has Data Reduction Enabled
Mon, 08 Jan 2024 18:22:11 -0000
|Read Time: 0 minutes
When sizing a storage solution for OneFS, two major aspects need to be considered – capacity and performance. In this blog, we will talk about how to calculate the raw capacity in each node in the AWS cloud environment.
Consider a customer who wants to have 30TB of data capacity on APEX File Storage on AWS. The data reduction ratio is 1.6, and the cluster contains 6 nodes. How much capacity is needed for each node of the cluster?
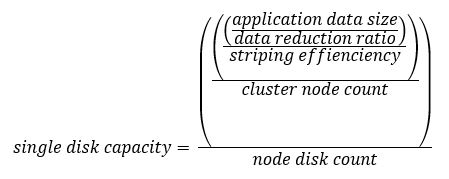
1. The usable capacity is calculated by dividing the application data size by the data reduction ratio: 30TB/1.6 = 18.75TB
2. OneFS in the AWS environment uses +2n as the default protection level. The +2n protection level striping pattern of 6 nodes is 4+2. The raw capacity necessary can be calculated by dividing the usable capacity by the striping pattern for the number of nodes involved: 18.75TB/66% = 28.41TB
3. Single disk capacity is then calculated by dividing the total raw capacity by the number of nodes involved: 28.41TB/6 nodes = 4.735TB
4. When each node contains 10 disks, each disk’s raw capacity should be 474GB.
OK, let's take a look at the formula of this calculation:
For reference, the striping patterns of 4, 5, and 6 nodes are listed as follows:
* 4 nodes: 2+2 (50%)
* 5 nodes: 3+2 (60%)
* 6 nodes: 4+2 (66%)
Now, knowing the logical data capacity, you can calculate the appropriate amount of capacity of each single EBS volume in the cluster.
Author: Yunlong Zhang