




Distributed Data Analytics Made Easy with Omnia
Thu, 20 Jul 2023 17:03:25 -0000
|Read Time: 0 minutes
Related Blog Posts

Navigating the modern data landscape: the need for an all-in-one solution

Mon, 18 Mar 2024 19:56:59 -0000
|Read Time: 0 minutes
There are two revolutions brewing inside every enterprise. We are all very familiar with the first one - the frenzied rush to expand an organization's AI capabilities, which leads to an exponential growth in data creation, a rise in availability of high-performance computing systems with multi-threaded GPUs, and the rapid advancement of AI models. The situation creates a perfect storm that is reshaping the way enterprises operate. Then, there is a second revolution that makes the first one a reality – the ability to harness this awesome power and gain a competitive advantage to drive innovation. Enterprises are racing towards a modern data architecture that seeks to bring order to their chaotic data environment.
The Need For An All-In-One Solution
Data platforms are constantly evolving, despite a plethora of options such as data lakes, data warehouses, cloud data warehouses and even cloud data lakehouses, enterprise are still struggling. This is because the choices available today are suboptimal.
Cloud native solutions offer simplicity and scalability, but migrating all data to the cloud can be a daunting task and can end up being significantly more expensive over the long term. Moreover, concerns about the loss of control over proprietary data, particularly in the realm of AI, is a major cause for concern, as well. On the other hand, traditional on-premises solutions require significantly more expertise and resources to build and maintain. Many organizations simply lack the skills and capabilities needed to construct a robust data platform in-house.
A customer once told me – “We’ve heard from so many vendors but ultimately there is no easy button for us.”
When Dell Technologies set out to build that easy button, we started with what enterprises needed most: infrastructure, software, and services all seamlessly integrated. We created a tailor-made solution with right-sized compute and a highly performant query engine that is pre-integrated and pre-optimized to perfectly streamline IT operations. We incorporated built-in enterprise-grade security that also can seamlessly integrate with 3rd party security tools. To enable rapid support, we staffed a bench of experts, offering end-to-end maintenance and deployment services. We also knew the solution needed to be future proof – not only anticipating future innovations but also accommodating the diverse needs of users today. To support this idea, we made the choice to use open data formats, which means an organization’s data is no longer locked-in to a proprietary format or vendor. To make the transition easier, the solution makes use of built-in enterprise-ready connectors that ensures business continuity. Ultimately, our goal was to deliver an experience that is easy to install, easy to use, easy to manage, easy to scale, and easy to future-proof.
Dell Data Lakehouse’s Core Capabilities
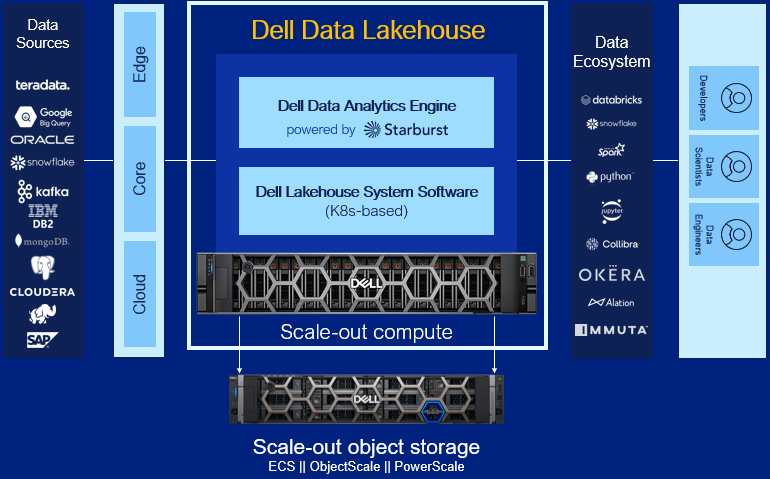
Let’s dig into each component of the solution.
- Data Analytics Engine, powered by Starburst: A high performance distributed SQL query engine, built on top of Starburst, based on Trino, which can run fast analytic queries against data lakes, lakehouses and distributed data sources at internet-scale. It integrates global security with fine-grained access controls, supports ad-hoc and long-running ELT workloads and is a gateway to building high quality data products and power AI and Analytics workloads. Dell’s Data Analytics Engine also includes exclusive features that help dramatically improve performance when querying data lakes. Stay tuned for more info!
- Data Lakehouse System Software: This new system software is the central nervous system of the Dell Data Lakehouse. It simplifies lifecycle management of the entire stack, drives down IT OpEx with pre-built automation and integrated user management, provides visibility into the cluster health and ensures high availability, enables easy upgrades and patches and lets admins control all aspects of the cluster from one convenient control center. Based on Kubernetes, it’s what converts a data lakehouse into an easy button for enterprises of all sizes.
- Scale-out Lakehouse Compute: Purpose-built Dell Compute and Networking hardware perfectly matched for compute-intensive data lakehouse workloads come pre-integrated into the solution. Independently scale from storage by seamlessly adding more compute as needs grow.
- Scale-out Object Storage: Dell ECS, ObjectScale and PowerScale deliver cyber-secure, multi-protocol, resilient and scale-out storage for storing and processing massive amounts of data. Native support for Delta Lake and Iceberg ensures read / write consistency within and across sites for handling concurrent, atomic transactions.
- Dell Services: Accelerate AI outcomes with help at every stage from trusted experts. Align a winning strategy, validate data sets, quickly implement your data platform and maintain secure, optimized operations.
- ProSupport: Comprehensive, enterprise-class support on the entire Dell Data Lakehouse stack from hardware to software delivered by highly trained experts around the clock and around the globe.
- ProDeploy: Expert delivery and configuration assure that you are getting the most from the Dell Data Lakehouse on day one. With 35 years of experience building best-in-class deployment practices and tools, backed by elite professionals, we can deploy 3x faster1 than in-house administrators.
- Advisory Services Subscription for Data Analytics Engine: Receive a pro-active, dedicated expert to maximize value of your Dell Data Analytics Engine environment, guiding your team through design and rollout of new use cases to optimize and scale your environment.
- Accelerator Services for Dell Data Lakehouse: Fast track ROI with guided implementation of the Dell Data Lakehouse platform to accelerate AI and data analytics.
Learn More
With the combination of these capabilities, Dell continues to innovate alongside our customers to help them exceed their goals in the face of data challenges. We aim to allow our customers to take advantage of the revolution brewing that is AI and this rapid change in the market to harness the power of their data and gain a competitive advantage and drive innovation. Enterprises are racing towards a modern data architecture – it's critical they don’t get stuck at the starting line.
For detailed information on this exciting product, refer to our technical guide. For other information, visit Dell.com/datamanagement.
Source
1 Based on a May 2023 Principled Technologies study “Using Dell ProDeploy Plus Infrastructure can improve deployment times for Dell Technology”

Inverse Design Meets Big Data: A Spark-Based Solution for Real-Time Anomaly Detection
Wed, 17 Jan 2024 18:27:32 -0000
|Read Time: 0 minutes
Inverse design is a process in which you start with a wanted outcome and performance goals. It works backward to find the system configuration and design parameters to achieve goals instead of the more traditional forward design, in which known parameters shape the design.
For accurate and timely identification of anomalies in big data streams from servers, it is important to configure an optimal combination of technologies. We first pick the autoencoder technique that shapes the multivariate analytics, then configure Kafka-Spark-Delta integration for dataflow, and finally select the data grouping at the source for the analytics to fire.
The iDRAC module in Dell PowerEdge servers gathers critical sideband data in its sensor bank. This data can be programmed for real-time streaming, but not every signal (data-chain) is relevant to online models that consume them. For example, if the goal is to find servers in the data center that are overheating, the internal residual battery charge in servers is not useful. Composable iDRAC data from PowerEdge servers is pooled in networked PowerScale storage. The most recent chunks of data are loaded onto memory for anomaly detection over random samples. Computed temporal fluctuations in anomaly strength complete the information synthesis from raw data. This disaggregated journey from logically grouped raw data to information using the Dell Data Lakehouse (DLH) network infrastructure specification (not shown here) triggers action in real-time. The following figure captures the architecture:
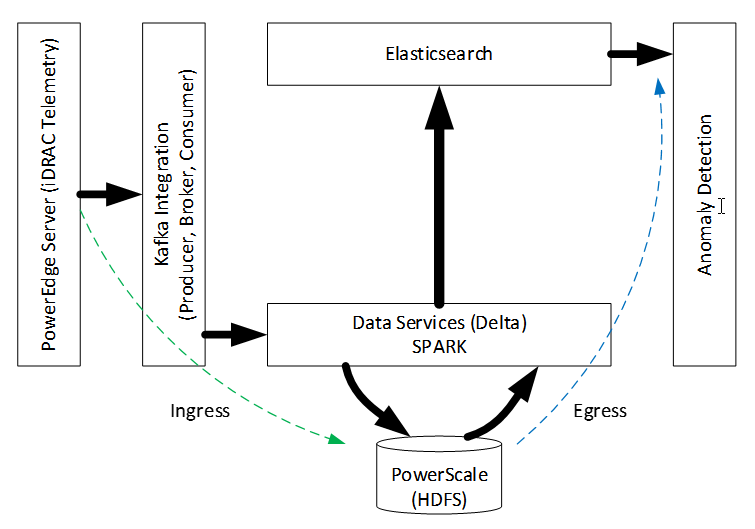
Figure 1. End-to-end architecture for streaming analytics
The pipeline has two in-order stages─ingress and egress. In the ingress stage, target model (for example, overheating) features influence data enablement, capture frequency, and streamer parameterization. Server iDRACs [1] write to the Kafka Pump (KP), which interprets native semantics for consumption by the multithreaded Kafka Consumer, as shown in the following figure:
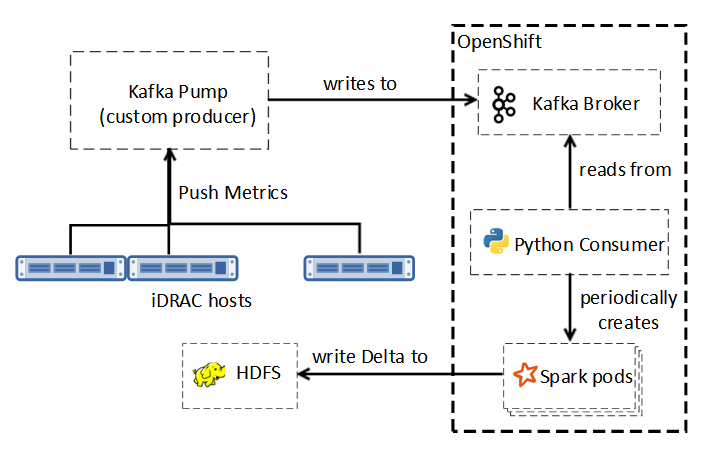
Figure 2. Kafka to Delta
The reader thread collects data from the configured input buffer while the writer thread periodically flushes this data by concatenating to the HDFS storage in Delta format, using Spark services for in-memory computing, scalability, and fault tolerance. Storage and data-management reliability, scalability, efficiency of HDFS and Delta Lake, coupled with the Spark and Kafka performance considerations influenced our choices.
In the egress stage of the pipeline, we apply anomaly strength analytics to the pretrained autoencoder [2] model. The use of NVIDIA A100 GPUs accelerated autoencoder training. Elasticsearch helped sift through random samples of the most recent server data bundle for anomaly identification. Aggregated Z-score error deviations over these samples helped characterize the precise multivariate anomaly strength (as shown in the following figure), extrapolation of which over a temporal window captured undesirable fluctuations. 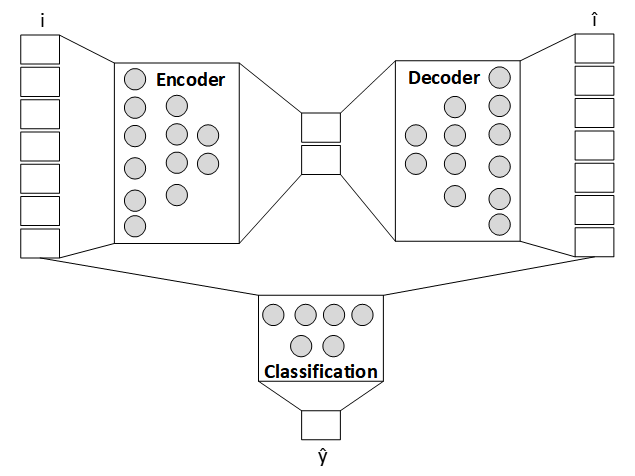
Figure 3. Anomaly analytics
We used Matplotlib to render, but you can alternatively manufacture on-demand events to drive corrections in the substrate. If generalized, this approach can continuously identify machine anomalies.
Conclusion
In this PoC, we combined several emerging technologies. We used Kafka for real-time data ingestion with Spark for reliable high-performance processing, HDFS with Delta Lake for storage, and advanced analytics for anomaly detection. We designed a Spark solution for real-time anomaly detection. By using autoencoders, supplemented with a strategy to quantify anomaly strength without requiring periodic drift compensation, we proved that modern data analytics integrates well on Dell DLH infrastructure. This infrastructure includes Red Hat OpenShift, Dell PowerScale storage, PowerEdge compute, and PowerSwitch network elements.
References:
[1] Telemetry Streaming with iDRAC9— Custom Reports Get Started
[2] D. Bank, N. Koenigstein, R. Giryes, “Autoencoders”, arXiv:2003.05991v2, April 2021.