




Direct from Development - Acceleration over Ethernet for Dell EMC PowerEdge MX7000

Summary
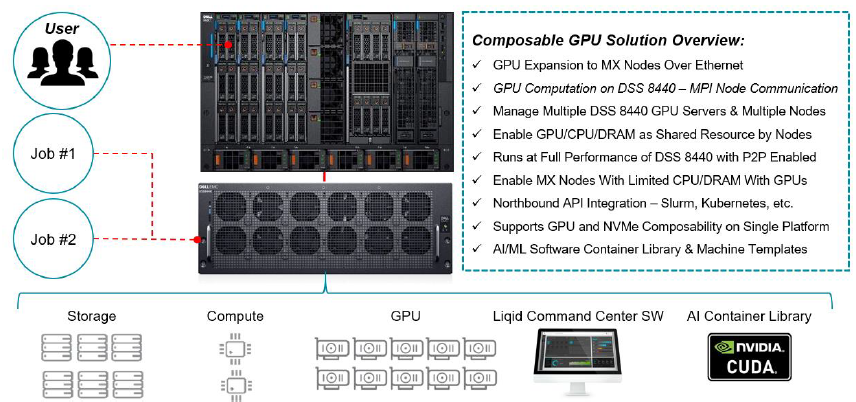
Many of today’s demanding applications require GPU resources. This reference architecture incorporates GPUs to the PowerEdge MX infrastructure, utilizing the PowerEdge MX Scalable Fabric, Dell EMC DSS 8440 GPU Server and Liqid Command Center Software.
Request a remote demo of this reference architecture or a quote from Dell Technologies Design Solutions Experts at the Design Solutions Portal
Background
Emerging workloads, like AI represent a powerfully uneven series of compute processes, such as data-heavy ingest and GPU-heavy data training. When coupled with the fact that these workloads can demand even more resources over time, it becomes clear this complex new paradigm demands a new type of IT infrastructure.
Dell EMC PowerEdge MX7000 modular chassis simplifies the deployment and management of today’s challenging workloads by allowing IT to dynamically assign, move and scale shared pools of compute, storage and networking. It provides IT the ability to deliver fast results, not spend time managing and reconfiguring infrastructure to meet ever-changing needs. Composable GPU Infrastructure from Liqid powered by Dell Technologies expands the promise of software-defined composability for today’s AI-driven compute environments and high value applications.
GPU Acceleration for MX7000
For unique workloads like AI that require accelerated computing, the addition of GPU acceleration within the MX7000 is paramount. With Liqid, supported GPUs can be quickly added to any new or existing MX7000 compute sled, delivering the resources needed to effectively handle each step of the AI workflow including data ingest, cleaning/tagging, training, and inference. Spin-up new bare-metal servers with the exact number of GPUs required, and add or remove dynamically as needed, via Liqid software.

Essential PowerEdge Components and Ethernet Cabling

Liqid Command Center Software
The first step in the GPU expansion process, is to install up to 16x HHHL or 10x FHFL GPUs into a Dell EMC DSS 8440 server. As noted in the table 1, this solution supports several GPU device options. The next step is to connect the DSS 8440 to Fabric A on the MX7000 via 100GbE.
Liqid Command Center software resides on the fabric and will discover the GPU devices in the DS8440 and enable them for utilization by the MX7000 compute nodes. The users can distribute GPU-centric jobs from any compute sled on the MX7000 to GPUs located within the DSS 8440.

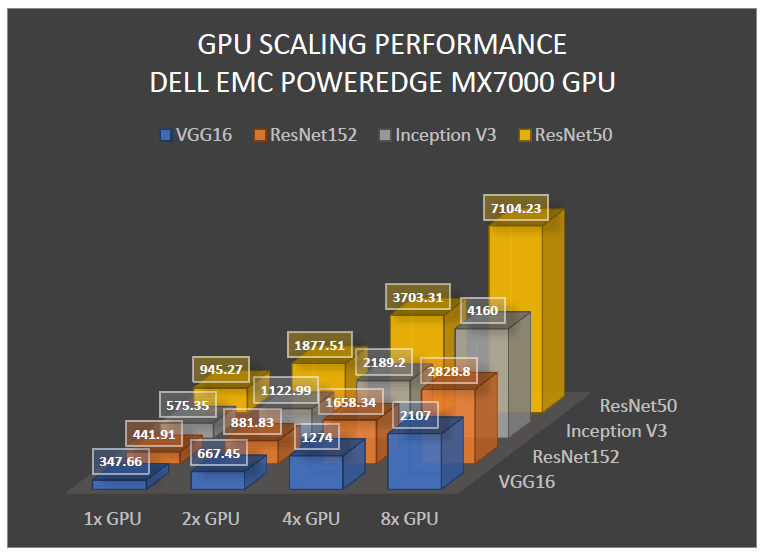
Accelerator Performance
To effectively demonstrate the performance of GPU accelerated MX7000 compute sleds, we tested it against DSS 8440 server with local GPUs and measured minimal to no overhead. The deep learning benchmark tests were run on the following networks: ResNet-50, ResNet-152, Inception V3, VGG-16. The DS8440 was outfitted with 8x NVDIA Tesla RTX8000 GPUs. The results clearly demonstrate that GPU enabled MX7000 delivers unrestricted performance on various industry standard benchmarks, using accelerator optimized Dell PowerEdge infrastructure.


In Conclusion
GPU expansion for the MX7000 unlocks the ability to handle the most demanding compute workloads for both new and existing AI and HPC deployments. Liqid Command Center on Dell EMC PowerEdge Servers accelerates applications by dynamically composing GPU resources directly to workloads without a power cycle on the compute sled.
Related Blog Posts

Reference Architecture: Acceleration over PCIe for Dell EMC PowerEdge MX7000
Thu, 12 Nov 2020 19:31:58 -0000
|Read Time: 0 minutes
Summary
Many of today's demanding applications require GPU resources. Our reference architecture incorporates GPUs to the PowerEdge MX infrastructure, utilizing the PowerEdge MX Scalable Fabric, Dell EMC DSS 8440 GPU Server, and Liqid Command Center Software. Request a remote demo of this reference architecture or a quote from Dell Technologies Design Solutions Experts at the Design Solutions Portal.
Background
The Dell EMC PowerEdge MX7000 Modular Chassis simplifies the deployment and management of today’s most challenging workloads by allowing IT administrators to dynamically assign, move and scale shared pools of compute, storage and networking resources. It provides IT administrators the ability to deliver fast results, eliminating managing and reconfiguring infrastructure to meet ever-changing needs of their end users. The addition of PCIe infrastructure to this managed pool of resources using Liqid technology designed on Dell EMC MX7000 expands the promise of software-defined composability for today’s AI-driven compute environments and high-value applications.
GPU Acceleration for PowerEdge MX7000
For workloads like AI that require parallel accelerated computing, the addition of GPU acceleration within the PowerEdge MX7000 is paramount. With Liqid technology and management software, GPUs of any form factor can be quickly added to any new or existing MX compute sled via the management interface, quickly delivering the resources needed to manage each step of the machine learning workflow including data ingest, cleansing, training, and inferencing. Spin-up new bare-metal servers with the exact number of accelerators required and then dynamically add or remove them as workload needs change.
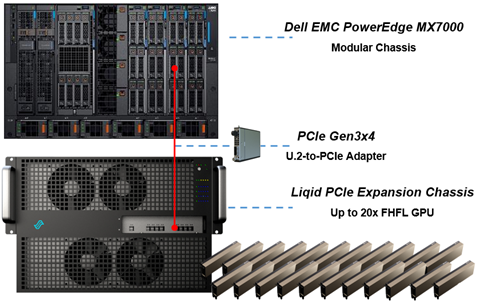 Figure 1 Essential PowerEdge Expansion Components
Figure 1 Essential PowerEdge Expansion Components
GPU Expansion Over PCIe | |
Compute Sleds | Up to 8 x Compute Sleds per Chassis |
GPU Chassis | PCIe Expansion Chassis |
Interconnect | PCIe Gen3x4 Per Compute Sled |
GPU Expansion | 20x GPU (FHFL) |
GPU Supported | V100, A100, RTX, T4, Others |
OS Supported | Linux, Windows, VMWare and Others |
Devices Supported | GPU, FPGA, and NVMe Storage |
Form Factor | 14U Total = MX7000 (7U) + PCIe Expansion Chassis (7U) |
 Figure 2
Figure 2
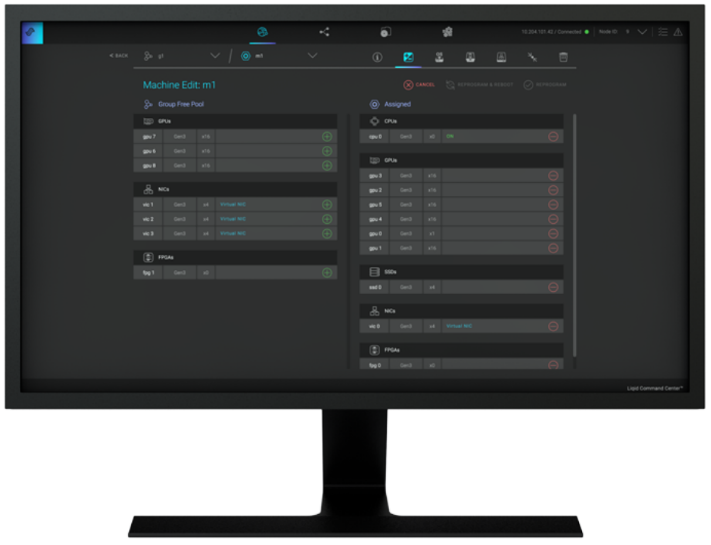 Figure 3 Liqid Command Center
Figure 3 Liqid Command Center
Implementing GPU Expansion for MX
Figure 3 Liqid Command Center
GPUs are installed into the PCIe expansion chassis. Next, U.2 to four PCIe Gen3 adapters are added to each compute sled that requires GPU acceleration, and then they are connected to the expansion chassis (Figure 1). Liqid Command Center software enables discovery of all GPUs, making them ready to be added to the server over native PCIe. FPGA and NVMe storage can also be added to compute nodes in tandem. This PCIe expansion chassis & software are available from the Dell Design Solutions team.
Software Defined Composability
Once PCIe devices are connected to the MX7000, Liqid Command Center software enables the dynamic allocation of GPUs to MX compute sleds at the bare metal. Any amount of resources can be added to the compute sleds, via Liqid Command Center (GUI) or RESTful API, in any ratio (GPU hot-plug supported). To the operating system, the GPUs are presented as local resources direct connected to the MX compute sled over PCIe (Figure 3). All operating systems are supported including Linux, Windows, and VMware. As workload needs change, add or remove resources on the fly, via software including NVMe SSD and FPGA (Table 1).
Enabling GPU Peer-2-Peer Capability
A key feature included with the PCIe expansion solution for PowerEdge MX7000 is the ability for RDMA Peer-2-Peer between GPU devices. Direct RDMA transfers have a massive impact on both throughput and latency for the highest performing GPU-centric applications. Up to 10x improvement in performance has been achieved with RDMA Peer-2-Peer enabled. Below is the overview of how PCIe Peer-2-Peer functions (Figure 4).
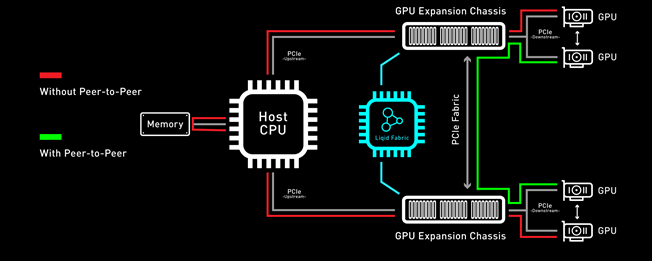 Figure 4 PCIe Peer-2-Peer
Figure 4 PCIe Peer-2-Peer
Bypassing the x86 processor and enabling direct RDMA communication between GPUs, realizes a dramatic improvement in bandwidth and in addition a reduction in latency is also realized. This chart outlines the performance expected for GPUs that are composed to a single node with GPU RDMA Peer-2-Peer enabled (Table 2).
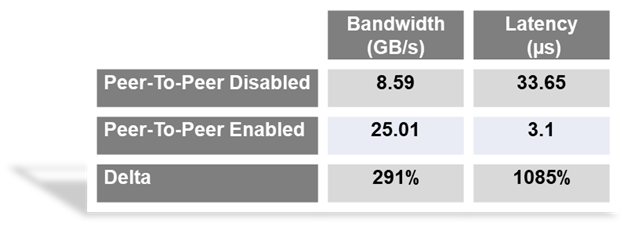
Application Level Performance
RDMA Peer-2-Peer is a key feature in GPU scaling for Artificial Intelligence, specifically machine learning based applications. Figure 5 outlines performance data measured on mainstream AI/ML applications on the MX7000 with GPU expansion over PCIe. It further demonstrates the performance scaling from 1-GPU to 8-GPU for a single MX740c compute sled. High scaling efficiency is observed for ResNet152, VGG16, Inception V3, and ResNet50 on MX7000 with composable PCIe GPUs measured with Peer-2-Peer enabled. These results indicate a near-linear growth pattern. and with the current capabilities of the Liqid PCIe 7U expansion sled one can allocate up to 20 GPUs to an application running on a single node.
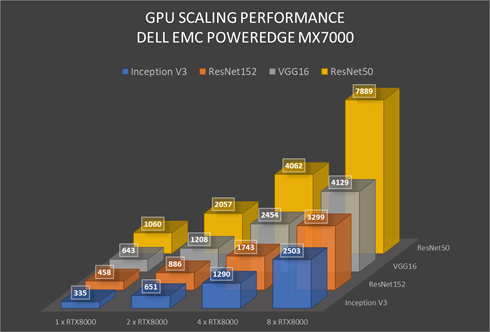 Figure 5 GPU Performance Scaling Comparison: MX7000 Leverages RTX8000 in PCIe expansion chassis measured with P2P Enabled
Figure 5 GPU Performance Scaling Comparison: MX7000 Leverages RTX8000 in PCIe expansion chassis measured with P2P Enabled
Conclusion
Liqid PCIe expansion for the Dell EMC PowerEdge MX7000 unlocks the ability to manage the most demanding workloads in which accelerators are required for both new and existing deployments. Liqid collaborated with Dell Technologies Design Solutions to accelerate applications by through the addition of GPUs to the Dell EMC MX compute sleds over PCIe.
Learn More | See a Demo | Get a Quote
This reference architecture is available as part of the Dell Technologies Design Solutions.

Dell Technologies PowerEdge MX 100 GbE solution with external Fabric Switching Engine
Mon, 26 Jun 2023 20:31:38 -0000
|Read Time: 0 minutes
The Dell PowerEdge MX platform is advancing its position as the leading high-performance data center infrastructure by introducing a 100 GbE networking solution. This evolved networking architecture not only provides the benefit of 100 GbE speed but also increases the number of MX7000 chassis within a Scalable Fabric. The 100 GbE networking solution brings a new type of architecture, starting with an external Fabric Switching Engine (FSE).
PowerEdge MX 100 GbE solution design example
The diagram shows only one connection on each MX8116n for simplicity. See the port-mapping section in the networking deployment guide here.
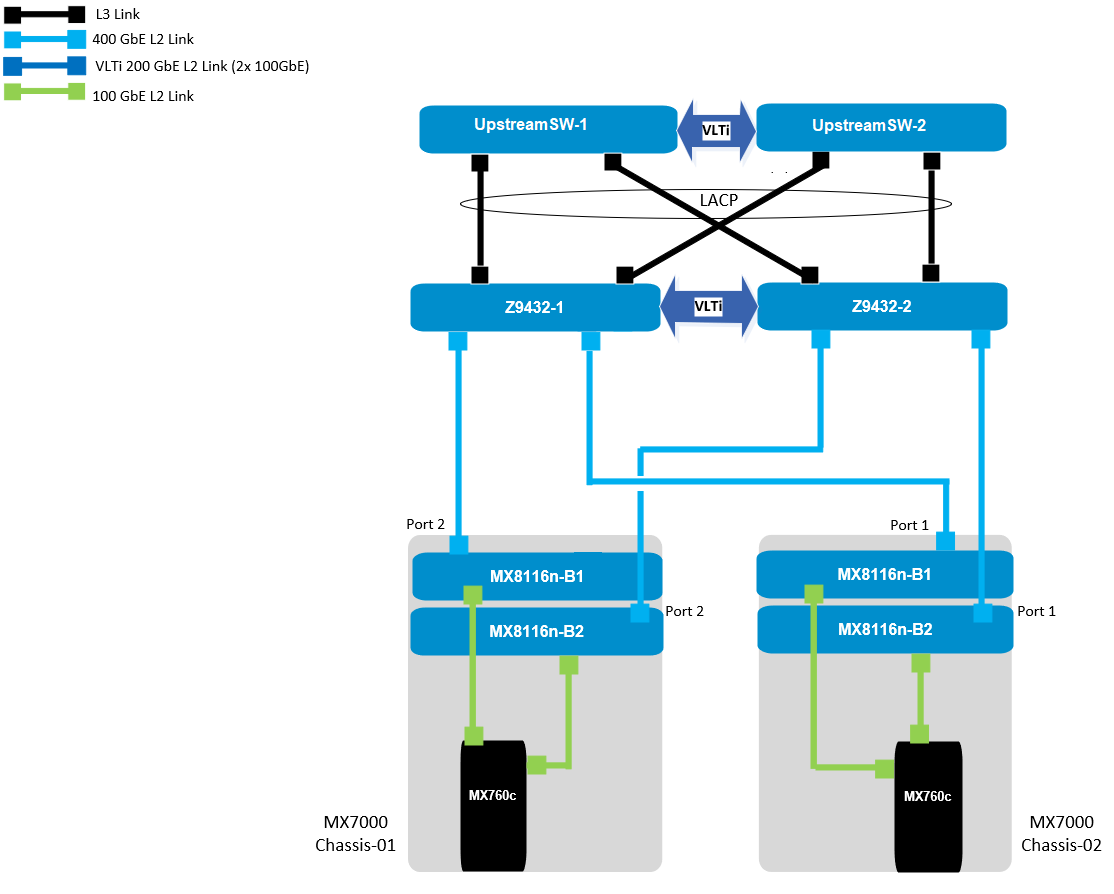
Figure 1. 100 GbE solution example topology
Components for 100 GbE networking solution
The key hardware components for 100 GbE operation within the MX Platform are described below with a minimal description.
Dell Networking MX8116n Fabric Expander Module
The MX8116n FEM includes two QSFP56-DD interfaces, with each interface providing up to 4x 100Gbps connections to the chassis, 8x 100 GbE internal server-facing ports for 100 GbE NICs, and 16x 25 GbE for 25 GbE NICs.
The MX7000 chassis supports up to four MX8116n FEMs in Fabric A and Fabric B.
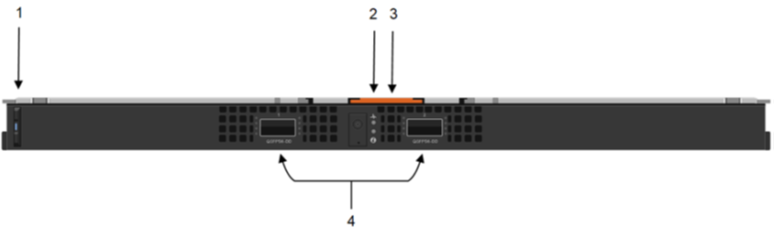
Figure 2. MX8116n FEM
The following MX8116n FEM components are labeled in the preceding figure:
- Express service tag
- Power and indicator LEDs
- Module insertion and removal latch
- Two QSFP56-DD fabric expander ports
Dell PowerEdge MX760c compute sled
- The MX760c is ideal for dense virtualization environments and can serve as a foundation for collaborative workloads.
- Businesses can install up to eight MX760c sleds in a single MX7000 chassis and combine them with compute sleds from different generations.
- Single or dual CPU (up to 56 cores per processor/socket with four x UPI @ 24 GT/s) and 32x DIMM slots DDR5 with eight memory channels.
- 8x E3.S NVMe (Gen5 x4) or 6 x 2.5" SAS/SATA SSDs or 6 x NVMe (Gen4) SSDs and iDRAC9 with lifecycle controller.
Note: The 100 GbE Dual Port Mezzanine card is also available on the MX750c.

Figure 3. Dell PowerEdge MX760c sled with eight E3.s SSD drives
Dell PowerSwitch Z9432F-ON external Fabric Switching Engine
The Z9432F-ON provides state-of-the-art, high-density 100/400 GbE ports, and a broad range of functionality to meet the growing demands of modern data center environments. Compact and offers an industry-leading density of 32 ports of 400 GbE in QSFP56-DD, 128 ports of 100, or up to 144 ports of 10/25/50 (through breakout) in a 1RU design. Up to 25.6 Tbps non-blocking (full duplex), switching fabric delivers line-rate performance under full load.L2 multipath support using Virtual Link Trunking (VLT) and Routed VLT support. Scalable L2 and L3 Ethernet switching with QoS and a full complement of standards-based IPv4 and IPv6 features, including OSPF and BGP routing support.

Figure 4. Dell PowerSwitch Z9432F-ON
Note: Mixed dual port 100 GbE and quad port 25 GbE mezzanine cards connecting to the same MX8116n are not a supported configuration.
100 GbE deployment options
There are four deployment options for the 100 GbE solution, and every option requires servers with a dual port 100 GbE mezzanine card. You can install the mezzanine card in either mezzanine slot A, B, or both. When you use the Broadcom 575 KR dual port 100 GbE mezzanine card, you should set the Z9432F-ON port-group to unrestricted mode and configure the port mode for 100g-4x.
PowerSwitch CLI example:
port-group 1/1/1
profile unrestricted
port 1/1/1 mode Eth 100g-4x
port 1/1/2 mode Eth 100g-4x
Note: The 100 GbE solution deployment, 14 maximum numbers of chassis are supported in single fabric, and 7 maximum numbers of chassis are supported in dual fabric using the same pair of FSE solution.
Single fabric
In a single fabric deployment, two MX8116n can be installed either in Fabric A or Fabric B, and the corresponding slot of the sled in slot-A or slot-B can have the 100 GbE mezzanine card installed.
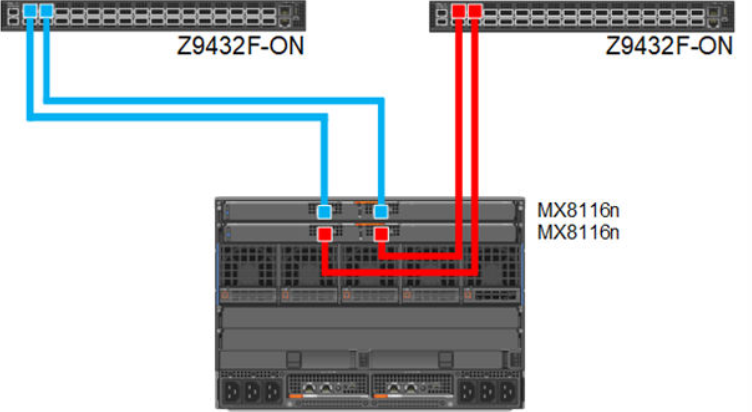
Figure 5. 100 GbE Single Fabric
Dual fabric combined fabrics
In this option, four MX8116n (2x in Fabric A and 2x in Fabric B) can be installed and combined to connect Z9432F-ON external FSE.
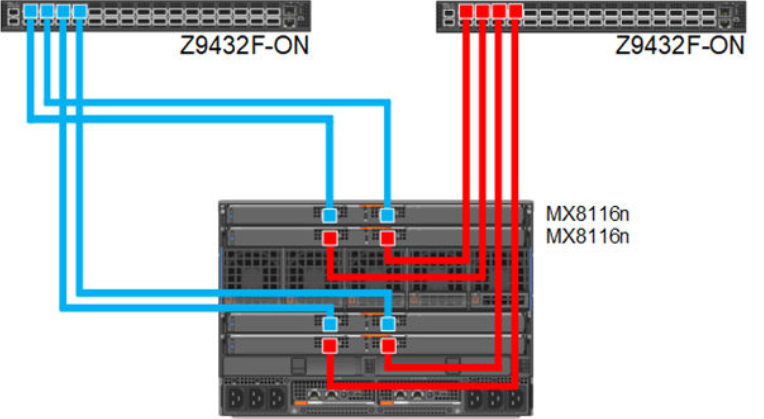
Figure 6. 100 GbE Dual Fabric combined Fabrics
Dual fabric separate fabrics
In this option four, MX8116n (2x in Fabric A and 2x in Fabric B) can be installed and connected to two different networks. In this case, the MX760c server module has two mezzanine cards, with each card connected to a separate network.
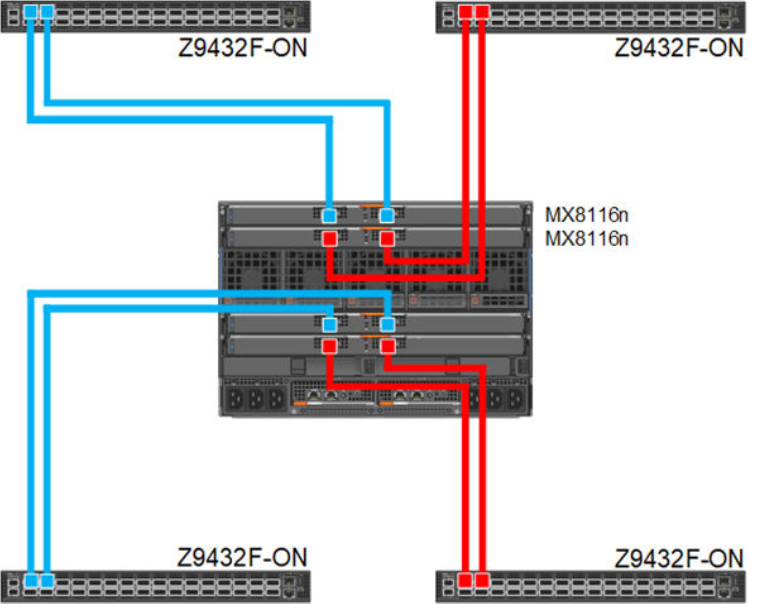
Figure 7. 100 GbE Dual Fabric separate Fabrics
Dual fabric, single MX8116n in each fabric, separate fabrics
In this option two, MX8116n (1x in Fabric A and 1x in Fabric B) can be installed and connected to two different networks. In this case, the MX760c server module has two mezzanine cards, each connected to a separate network.
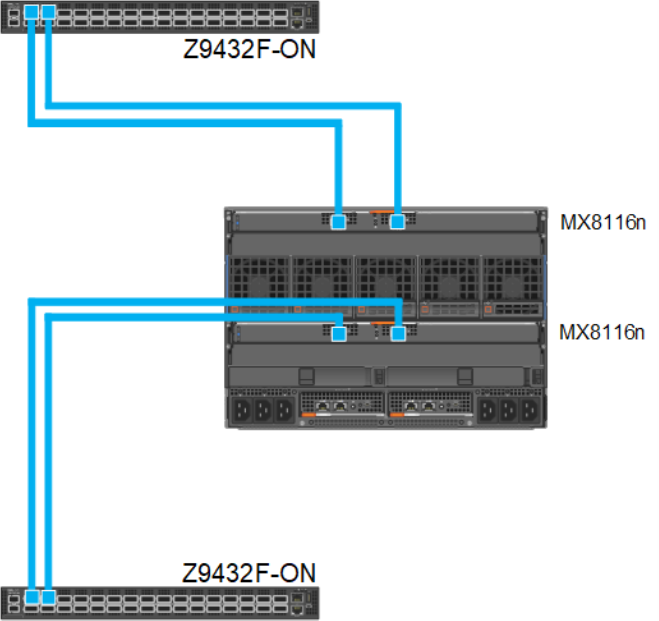
Figure 8. 100 GbE Dual Fabric single FEM in separate Fabrics
References
Dell PowerEdge Networking Deployment Guide
A chapter about 100 GbE solution with external Fabric Switching Engine