



Dell Technologies and Deloitte DataPaaS: Data Platform as a Service
Tue, 08 Dec 2020 17:45:44 -0000
|Read Time: 0 minutes
The Dell Technologies and Deloitte alliance combines Dell Technologies leading infrastructure software, and services with Deloitte’s ability to deliver solutions, to drive digital transformation for our mutual clients.
DataPaaS enables enterprise deployment and adoption of Deloitte best practice data analytics platforms for use cases such as Financial Services, Cyber Security, Business Analytics, IT Operations and IoT.
Why choose Dell Technologies and Deloitte
Best-in-class capabilities: The Dell Technologies and Deloitte alliance draws on strengths from each organization with the goal of providing best-in-class technology solutions to customers.
Strong track record of success: For years Dell Technologies and Deloitte have successfully worked together to help solve enterprise customers‘ most complex infrastructure, technology, cloud strategy, and business challenges.
Strategic approach: Successful engagements with a large, diverse group of customers have demonstrated the importance of taking a strategic approach to technology, solution design, integrations, and implementation.
Dell Technologies collaborates with Deloitte to deliver data analytics at scale, allowing customers to focus on outcomes, use cases and value
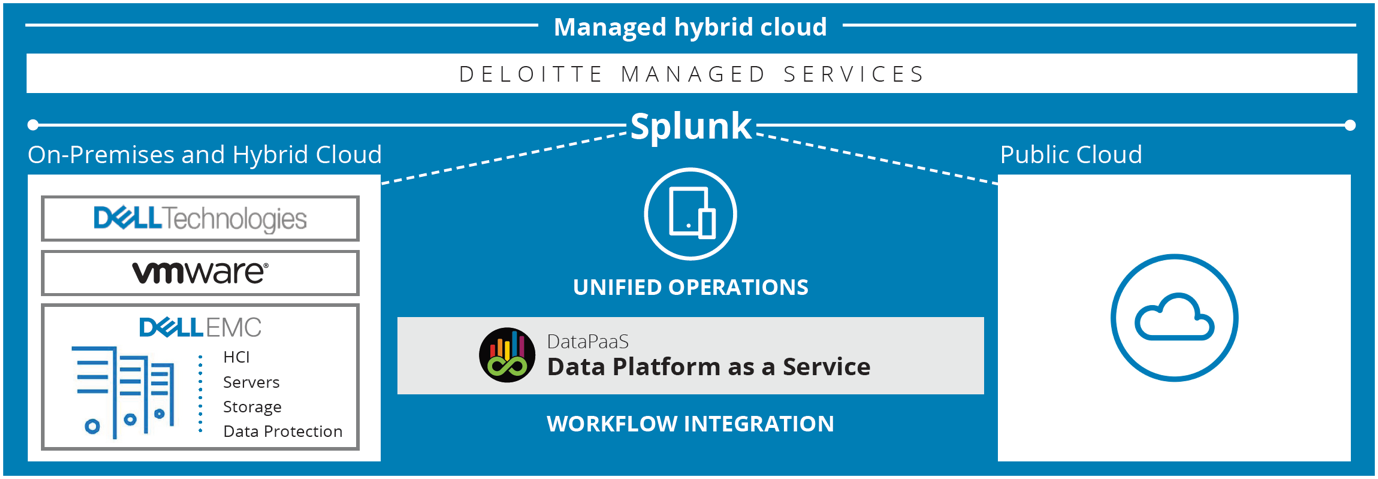
Keeping up with the demands of a growing data platform can be a real challenge. Getting data on-boarded quickly, deploying and scaling infrastructure, and managing users reporting and access demands becomes increasingly difficult. DataPaaS employs Deloitte’s best practise D8 Methodology to orchestrate the deployment, management and adoption of an organisation wide data platform.
- “Splunk as a Platform” enabling data reuse and analytics across the business
- On-premise, Cloud or Hybrid – route data to the most cost-effective option or depending on Information Governance policies
- DataPaaS delivers a catalog of use-cases that can be deployed in minutes…not days or weeks
- Free up and retain specialist resources - move from troubleshooting and management of the platform, to getting value out of the data in the platform
- True DevOps, using CICD, spin up and destroy full environments as needed
- Enforce and maintain consistent configuration, continuously synced enabling simple recovery
- Data Acquisition Channel for rapid and automated data onboarding and routing
- DataPaaS enables Data DevOps; 5x faster, at 50% of the cost with 100% control and 8x the return on investment
Find out more
- Dell Technologies and Deloitte DataPaaS Data Platform as a Service
- Dell technologies and Deloitte DataPaaS Pandemic Support for Government Crisis Management
- Dell Technologies and Deloitte DataPaaS Risk Management Analytics for Real-Time Decision Making
Contact us

Asia Pacific region
Stuart Hirst
Partner
Deloitte Risk Advisory Pty Ltd
shirst@deloitte.com.au
+612 487 471 729![]() @convergingdata
@convergingdata

United States region
Todd Wingler
Business Development Executive
Deloitte Risk and Financial Advisory
twingler@deloitte.com
+1 480 232-8540![]() @twingler
@twingler

EMEA region
Nicola Esposito
Partner
Deloitte Cyber
niesposito@deloitte.es
+34 918232431![]() @nicolaesposito
@nicolaesposito

Chris Belsey
ISV Strategy & Alliances, Global Alliances
Dell Technologies
chris.belsey@dell.com
+44 75 0088 0803![]() @chrisbelseyemc
@chrisbelseyemc

Byron Cheng
High Value Workloads Leader, Global Alliances
Dell Technologies
byron.cheng@dell.com
+1 949 241 6328![]() @byroncheng1
@byroncheng1
Related Blog Posts

Navigating the modern data landscape: the need for an all-in-one solution

Mon, 18 Mar 2024 19:56:59 -0000
|Read Time: 0 minutes
There are two revolutions brewing inside every enterprise. We are all very familiar with the first one - the frenzied rush to expand an organization's AI capabilities, which leads to an exponential growth in data creation, a rise in availability of high-performance computing systems with multi-threaded GPUs, and the rapid advancement of AI models. The situation creates a perfect storm that is reshaping the way enterprises operate. Then, there is a second revolution that makes the first one a reality – the ability to harness this awesome power and gain a competitive advantage to drive innovation. Enterprises are racing towards a modern data architecture that seeks to bring order to their chaotic data environment.
The Need For An All-In-One Solution
Data platforms are constantly evolving, despite a plethora of options such as data lakes, data warehouses, cloud data warehouses and even cloud data lakehouses, enterprise are still struggling. This is because the choices available today are suboptimal.
Cloud native solutions offer simplicity and scalability, but migrating all data to the cloud can be a daunting task and can end up being significantly more expensive over the long term. Moreover, concerns about the loss of control over proprietary data, particularly in the realm of AI, is a major cause for concern, as well. On the other hand, traditional on-premises solutions require significantly more expertise and resources to build and maintain. Many organizations simply lack the skills and capabilities needed to construct a robust data platform in-house.
A customer once told me – “We’ve heard from so many vendors but ultimately there is no easy button for us.”
When Dell Technologies set out to build that easy button, we started with what enterprises needed most: infrastructure, software, and services all seamlessly integrated. We created a tailor-made solution with right-sized compute and a highly performant query engine that is pre-integrated and pre-optimized to perfectly streamline IT operations. We incorporated built-in enterprise-grade security that also can seamlessly integrate with 3rd party security tools. To enable rapid support, we staffed a bench of experts, offering end-to-end maintenance and deployment services. We also knew the solution needed to be future proof – not only anticipating future innovations but also accommodating the diverse needs of users today. To support this idea, we made the choice to use open data formats, which means an organization’s data is no longer locked-in to a proprietary format or vendor. To make the transition easier, the solution makes use of built-in enterprise-ready connectors that ensures business continuity. Ultimately, our goal was to deliver an experience that is easy to install, easy to use, easy to manage, easy to scale, and easy to future-proof.
Dell Data Lakehouse’s Core Capabilities
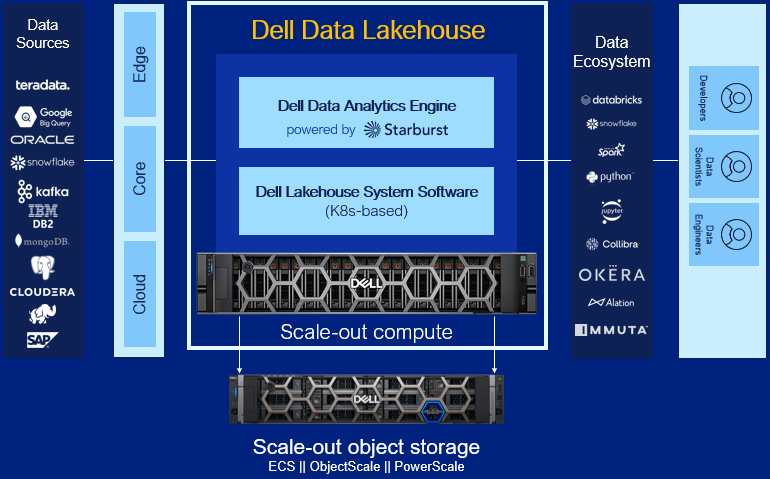
Let’s dig into each component of the solution.
- Data Analytics Engine, powered by Starburst: A high performance distributed SQL query engine, built on top of Starburst, based on Trino, which can run fast analytic queries against data lakes, lakehouses and distributed data sources at internet-scale. It integrates global security with fine-grained access controls, supports ad-hoc and long-running ELT workloads and is a gateway to building high quality data products and power AI and Analytics workloads. Dell’s Data Analytics Engine also includes exclusive features that help dramatically improve performance when querying data lakes. Stay tuned for more info!
- Data Lakehouse System Software: This new system software is the central nervous system of the Dell Data Lakehouse. It simplifies lifecycle management of the entire stack, drives down IT OpEx with pre-built automation and integrated user management, provides visibility into the cluster health and ensures high availability, enables easy upgrades and patches and lets admins control all aspects of the cluster from one convenient control center. Based on Kubernetes, it’s what converts a data lakehouse into an easy button for enterprises of all sizes.
- Scale-out Lakehouse Compute: Purpose-built Dell Compute and Networking hardware perfectly matched for compute-intensive data lakehouse workloads come pre-integrated into the solution. Independently scale from storage by seamlessly adding more compute as needs grow.
- Scale-out Object Storage: Dell ECS, ObjectScale and PowerScale deliver cyber-secure, multi-protocol, resilient and scale-out storage for storing and processing massive amounts of data. Native support for Delta Lake and Iceberg ensures read / write consistency within and across sites for handling concurrent, atomic transactions.
- Dell Services: Accelerate AI outcomes with help at every stage from trusted experts. Align a winning strategy, validate data sets, quickly implement your data platform and maintain secure, optimized operations.
- ProSupport: Comprehensive, enterprise-class support on the entire Dell Data Lakehouse stack from hardware to software delivered by highly trained experts around the clock and around the globe.
- ProDeploy: Expert delivery and configuration assure that you are getting the most from the Dell Data Lakehouse on day one. With 35 years of experience building best-in-class deployment practices and tools, backed by elite professionals, we can deploy 3x faster1 than in-house administrators.
- Advisory Services Subscription for Data Analytics Engine: Receive a pro-active, dedicated expert to maximize value of your Dell Data Analytics Engine environment, guiding your team through design and rollout of new use cases to optimize and scale your environment.
- Accelerator Services for Dell Data Lakehouse: Fast track ROI with guided implementation of the Dell Data Lakehouse platform to accelerate AI and data analytics.
Learn More
With the combination of these capabilities, Dell continues to innovate alongside our customers to help them exceed their goals in the face of data challenges. We aim to allow our customers to take advantage of the revolution brewing that is AI and this rapid change in the market to harness the power of their data and gain a competitive advantage and drive innovation. Enterprises are racing towards a modern data architecture – it's critical they don’t get stuck at the starting line.
For detailed information on this exciting product, refer to our technical guide. For other information, visit Dell.com/datamanagement.
Source
1 Based on a May 2023 Principled Technologies study “Using Dell ProDeploy Plus Infrastructure can improve deployment times for Dell Technology”

AI and Model Development Performance
Thu, 31 Aug 2023 20:47:58 -0000
|Read Time: 0 minutes
There has been a tremendous surge of information about artificial intelligence (AI), and generative AI (GenAI) has taken center stage as a key use case. Companies are looking to learn more about how to build architectures to successfully run AI infrastructures. In most cases, creating a GenAI solution involves fine-tuning a pretrained foundational model and deploying it as an inference service. Dell recently published a design guide – Generative AI in the Enterprise – Inferencing, that provides an outline of the overall process.
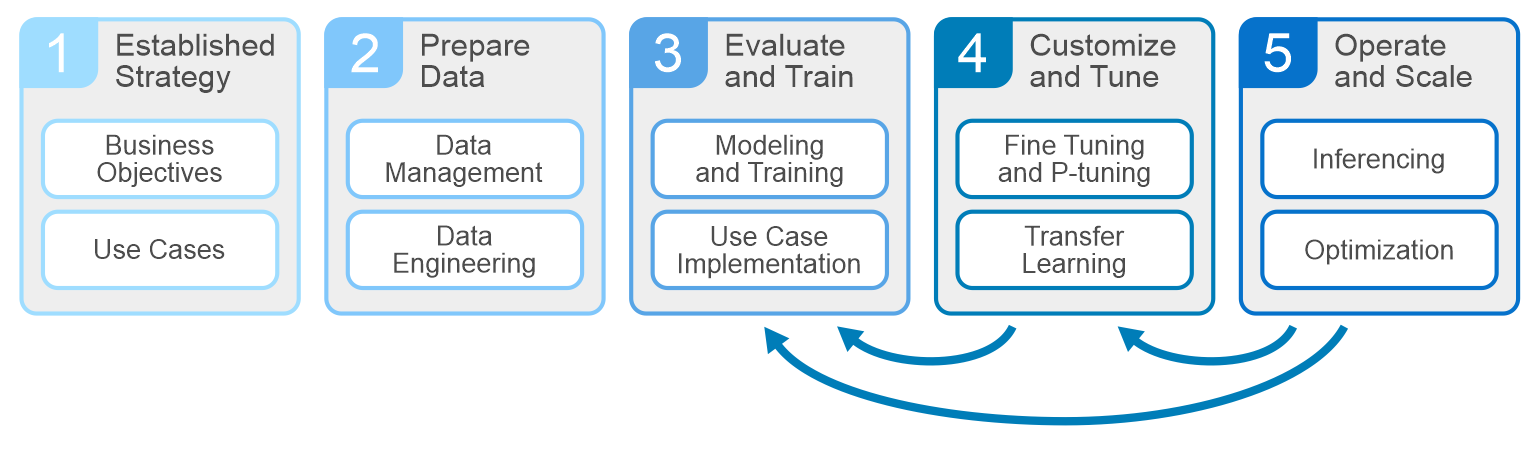
All AI projects should start with understanding the business objectives and key performance indicators. Planning, data prep, and training make up the other phases of the cycle. At the core of the development are the systems that drive these phases – servers, GPUs, storage, and networking infrastructures. Dell is well equipped to deliver everything an enterprise needs to build, develop, and maintain analytic models that serve business needs.
GPUs and accelerators have become common practice within AI infrastructures. They pull in data and training/fine-tune models within the computational capabilities of the GPU. As GPUs have evolved, their ability to handle larger models and parallel development cycles has evolved. This has left a lot of us wondering - how do we build an architecture that will support the model development that my business needs? It helps to understand a few parameters.
Defining business objectives and use cases will help shape your architecture requirements.
- The size and location of the training data set
- Model size in number of parameters and type of model being trained/fine-tuned
- Training parallelism and time to complete the training/fine-tuning.
Answering these questions helps determine how many GPUs are needed to train/fine-tune the model. Consider two main factors in GPU sizing. First is the amount of GPU memory needed to store model parameters and optimizer state. Second is the number of floating-point operations (FLOPs) needed to execute the model. Both generally scale with model size. Large models often exceed the resources of a single GPU and require spreading a single model over multiple GPUs.
Estimating the number of GPUs needed to train/fine-tune the model helps determine the server technologies to choose. When sizing servers, it’s important to balance the right GPU density and interconnect, power consumption, PCI bus technology, external port capacity, memory, and CPU. Dell PowerEdge servers include a variety of options for GPU types and density. PowerEdge XE Servers can host up to 8 NVIDIA H100 GPUs in a single server GenAI on PowerEdge XE9680, as well as the latest technologies, including NVLink, NVIDIA GPUDirect, PCIe 5.0, and NVMe disks. PowerEdge mainstream servers range from two to four GPU configurations, offering a variety of GPUs from different manufacturers. PowerEdge servers provide outstanding performance for all phases of model development. Visit Dell.com for more on PowerEdge Servers.
Now that we understand how many GPUs are needed and the servers to host them, it’s time to tackle storage. At a minimum, the storage should have capacity to host the training data set, the checkpoints during the model training, and any other data that relates to the pruning/preparing phase. The storage also needs to deliver the data at a rate the GPUs request it. The rate of delivery is multiplied by model parallelism, or the number of models being trained in parallel, and subsequently the number of GPUs requesting the data simultaneously (concurrently). Ideally, every GPU is running at 90% or better to maximize our investment, and a storage system that supports high concurrency is suited for these types of workloads.
Tools such as FIO or its cousin GDSIO (used to understand speeds and feeds of the storage system) are great for gaining hero numbers or theoretical maximums for reads/writes, but they are not representative of performance requirements for the AI development cycles. Data prep and stage shows up on the storage as random R/W, while during the training/fine-tuning phase, the GPUs are concurrently streaming reads from the storage system. Checkpoints throughout training are handled as writes back to the storage. These different points during the AI lifecycle require storage that can successfully handle these workloads at the scale determined by our model calculations and parallel development cycles.
Data scientists at Dell take great effort in understanding how different model development affects server and storage requirements. For example, language models like BERT and GPT have little effect on storage performance and resources, whereas image sequencing and DLRM models have significant or show worst case storage performance and resource demand. For this, the Dell storage teams focus testing and benchmarking on AI Deep Learning workflows based on popular image models like ResNet with real GPUs to understand the performance requirements needed to deliver data to the GPU during model training. The following image shows an architecture designed with Dell PowerEdge servers and networking with PowerScale scale-out storage.
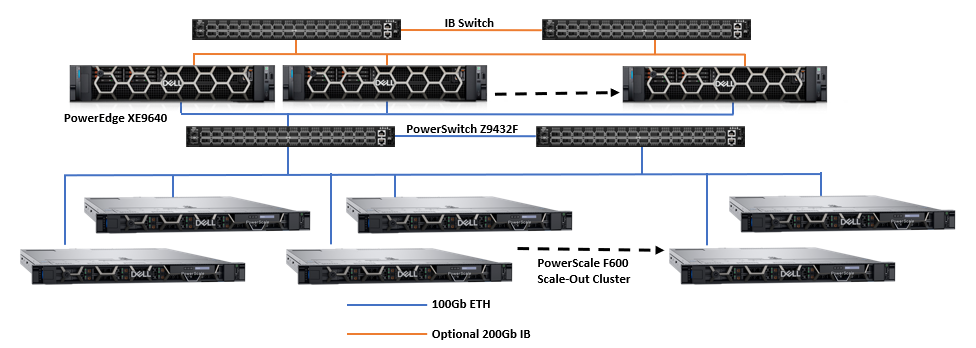
Dell PowerScale scale-out file storage is especially suited for these workloads. Each node in a PowerScale cluster delivers equivalent performance as the cluster and workloads scale. The following images show how PowerScale performance scales linearly as GPUs are increased, while the performance of each individual GPU remains constant. The scale-out architecture of PowerScale file storage easily supports AI workflows from small to large.
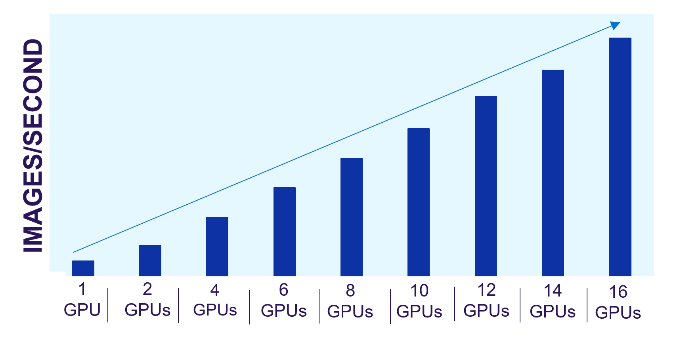
Figure 1. PowerScale linear performance
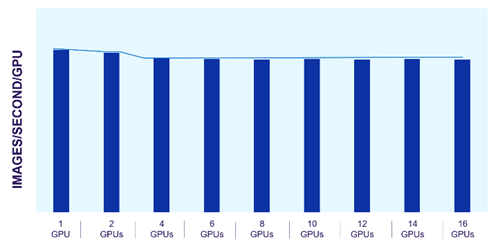
Figure 2. Consistent GPU performance with scale
The predictability of PowerScale allows us to estimate the storage resources needed for model training and fine-tuning. We can easily scale these architectures based on the model type and size along with the number and type of GPUs required.
Architecting for small and large AI workloads is challenging and takes planning. Understanding performance needs and how the components in the architecture will perform as the AI workload demand scales is critical.
Author: Darren Miller