




Dell ObjectScale on Red Hat OpenShift

Introduction
ObjectScale is a software-defined object storage offering from Dell Technologies. It is designed to deliver enterprise-grade, high-performance object storage in a Kubernetes-native environment.
ObjectScale has a layered architecture, with every function in the system built as an independent layer, making the functions horizontally scalable across all nodes and enabling high availability. The S3-compatible ObjectScale software forms the underlying cloud storage service, providing protection, geo-replication, and data access.
Red Hat® OpenShift® Container Platform is a Kubernetes distribution that provides production-oriented container and workload automation. Its declarative deployment approach, dynamic scaling, and self-healing capabilities make OpenShift a suitable platform to host ObjectScale.
The following diagram shows the ObjectScale topology:
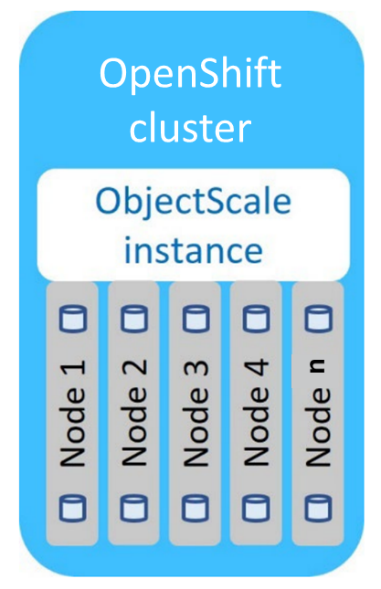 ObjectScale topology
ObjectScale topology
Deployment overview
The deployment of ObjectScale consists of three steps:
- Installing Bare Metal CSI drivers
- Installing the ObjectScale instance
- Creating ObjectStore
The bare-metal CSI drivers deployed as part of ObjectScale provide enhanced performance and serviceability. ObjectScale instance provides an easy-to-use web portal for its configuration and management. ObjectStores, user accounts, and buckets are some of the resources that are required to be created before the storage is ready to be consumed.
ObjectStores are independent storage systems with an individualized life cycle. One or more ObjectStores are deployed by each ObjectScale instance. ObjectStores are created, updated, and deleted independently from all other ObjectStores, and managed by the shared ObjectScale instance. Cluster resources such as storage, CPU, and RAM are defined for each ObjectStore based on workload demand inputs that are specified at ObjectStore creation. Resources that are reserved for an ObjectStore at creation may be adjusted at any time.
The minimum requirements for each OpenShift compute node are:
- 4 physical CPU cores
- 1 x 960 GB (or larger) unused SSD
- 128 GB RAM
- 200 GB of free space in /var/lib/kubelet
- 5 unused disks per node of identical storage class (minimum for a single object store), preferably the same size
Dell PowerEdge R750 and R7525 servers hosting the Red Hat OpenShift 4.8 are validated for ObjectScale deployment. The validated environment consisted of three compute nodes, each having 12 X 800 GB SSDs. The OpenShift NodePort service was used to access the ObjectScale UI.
Use cases
ObjectScale supports several modern and traditional use cases. Common use cases on OpenShift container platform are:
- ObjectScale for OpenShift internal image registry
- ObjectScale for OpenShift Quay
- ObjectScale for storing backups
- ObjectScale for building a data lake
- ObjectScale for Splunk SmartStore
Conclusion
The ease of deployment, scalability, fault tolerance, and security capabilities of OpenShift make it a preferred choice for hosting ObjectScale to fulfill object storage demands. ObjectStores running inside OpenShift, can be co-located and managed with the applications they support. This help reduce CapEx and deployment costs while improving time-to-market.
References
Authors
Indira Kannamedi (indira_kannamedi@dell.com)
Nitesh Mehra (nitesh_mehra@dell.com)
Related Blog Posts

Red Hat OpenShift - Windows compute nodes
Wed, 06 Dec 2023 10:35:35 -0000
|Read Time: 0 minutes
Red Hat OpenShift - Windows compute nodes
Red Hat® OpenShift® Container Platform is an industry-leading Kubernetes platform that enables a cloud-native development environment together with a cloud operations experience, giving you the ability to choose where you build, deploy, and run applications, all through a consistent interface. Powered by the open source-based OpenShift Kubernetes Engine, Red Hat OpenShift provides cluster management, platform services for managing workloads, application services for building cloud-native applications, and developer services for enhancing developer productivity.
Support for Windows containers
OpenShift Container Platform enables you to host and run Windows-based workloads on Windows compute nodes alongside the traditional Linux workloads that are hosted on Red Hat Enterprise Linux CoreOS (RHCOS) or Red Hat Enterprise Linux compute nodes. For more information, see Red Hat OpenShift support for Windows Containers.
As a prerequisite for installing Widows workloads, the Windows Machine Config Operator must be installed on a cluster that is configured with hybrid networking using OVN-Kubernetes. The operator configures Windows compute nodes and orchestrates the process of deploying and managing Windows workloads on a cluster.
Open Virtual Network (OVN) is the only supported networking configuration for installing Windows compute nodes. OpenShift Container Platform uses the OVN-Kubernetes network plug-in as its default network provider. You can configure the OpenShift Networking OVN-Kubernetes network plug-in to enable Linux and Windows nodes to host Linux and Windows workloads respectively. For more information, see About the OVN-Kubernetes network plugin.
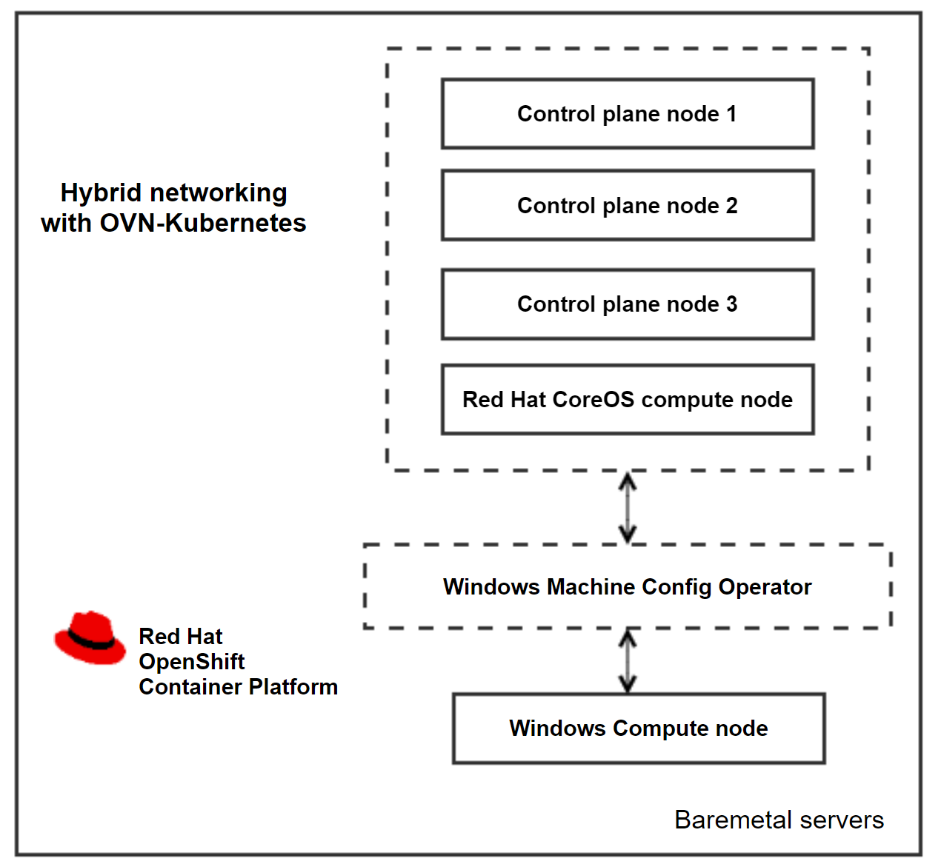 Cluster architecture and components
Cluster architecture and components
Adding a Windows node
You will need an already installed cluster, built using the IPI installation method or the Assisted Installer. For more information about deploying an OpenShift cluster on Dell bare-metal servers, see the Red Hat OpenShift Container Platform 4.12 on Dell Infrastructure Implementation Guide.
Create a custom manifest file to configure the Hybrid OVN-Kubernetes network during the cluster deployment by running the following commands:
cat cluster-network-03-config.yml
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
defaultNetwork:
ovnKubernetesConfig:
hybridOverlayConfig:
hybridClusterNetwork:
- cidr: 10.132.0.0/14
hostPrefix: 23
To add the server to the cluster as a worker node, you need bare-metal server with a Windows operating system. For the supported Windows versions, see Red Hat OpenShift 4.13 support for Windows Containers release notes.
- Open ports 22 and 10250 for SSH and for log collection on the Windows server.
- Create an administrator user. The administrator user’s private key is used in the secret as an authorized SSH key and to enable password-less authentication to the Windows server.
- Install the Windows Machine Config Operator on the cluster.
- In the openshift-windows-machine-config-operator namespace, create the secret from the administrator user’s private key.
- Describe the IPv4 or DNS address of the Windows instance and the administrator user in the configmap.
The WMCO operator scans for the secret created during boot, and creates another user data secret with the data that is required to interact with the Windows server using the SSH protocol. After the SSH connection is established, the operator starts processing the Windows servers that are listed in the configmap and begins to transfer files and configure the nodes. The CSRs that are generated are auto-approved, and the Windows instance is added to the cluster.
Environment overview
OpenShift Container platform is hosted on Dell PowerEdge R650 servers, enabling hybrid networking with OVN-Kubernetes. The Dell-validated environment consisted of three compute nodes. The validation team added a Windows instance to the cluster as a fourth node. The following table shows the cluster version information:
OpenShift cluster version | 4.13.21 |
Kubernetes version | 1.26.9 |
WCMO operator version | 8.1.0+0.1699557880.p |
Windows instance version | Windows server 2019 (Version 1809) |
References
Configuring hybrid networking - OVN-Kubernetes network plugin

NVIDIA AI Enterprise on Red Hat OpenShift
Wed, 15 Nov 2023 14:20:48 -0000
|Read Time: 0 minutes
NVIDIA AI Enterprise on Red Hat OpenShift
Red Hat OpenShift Container Platform is an enterprise-grade Kubernetes platform for deploying and managing secure and hardened Kubernetes clusters at scale. This Kubernetes distribution enables users to easily configure and use GPU resources to accelerate deep learning (DL) and machine learning (ML) workloads.
The NVIDIA H100 Tensor Core GPU, an integral part of the NVIDIA data center platform, is a high-performance GPU that is designed and optimized for AI workloads that are intended for data center and cloud-based applications. The GPU features major advances to accelerate AI, HPC, memory bandwidth, interconnect, and communication at data center scale. For more information, see NVIDIA H100 Tensor Core GPU.
NVIDIA AI Enterprise
NVIDIA AI Enterprise is an end-to-end, secure, cloud-native suite of AI software that enables organizations to solve new challenges while increasing operational efficiency. NVIDIA AI Enterprise accelerates the data science pipeline and streamlines development and deployment of production AI, including generative AI, computer vision, speech AI, and more. For more information, see NVIDIA AI Enterprise.
NVIDIA NGC catalog
The NVIDIA NGC catalog is a curated set of GPU-optimized software for AI, HPC, and Visualization. The NGC catalog simplifies building, customizing, and integrating GPU-optimized software into workflows on a variety of platforms, accelerating the time to solutions for users. The catalog includes containers, pre-trained models, Helm charts for Kubernetes deployments, and industry-specific AI toolkits. These toolkits consist of software development kits (SDKs) for NVDIA AI Enterprise that can be deployed on OpenShift Container Platform.
Prerequisites for installing NVIDIA AI Enterprise on OpenShift Container Platform
- An OpenShift cluster with a minimum of three nodes, at least one of which has an NVIDIA-supported GPU. For the list of supported GPUs, see the NVIDIA Product Support Matrix.
- A service instance for licenses. This blog briefly describes how to deploy a containerized DLS instance on OpenShift Container Platform that serves licenses to the clients.
NVIDIA license system
The NVIDIA license system is used to provide software licenses to licensed NVIDIA software products. The licenses are available from the NVIDIA Licensing Portal (access requires NVIDIA login credentials). The NVIDIA license system supports the following types of service instances: a Cloud License Service (CLS) instance that is hosted on the NVIDIA Licensing Portal, and a Delegated License Service (DLS) instance that is hosted on-premises at a location that is accessible from your private network, such as inside your data center.
A DLS instance is fully disconnected from the NVIDIA Licensing Portal. Licenses are downloaded from the portall and uploaded manually to the instance. The following figure depicts the flow:
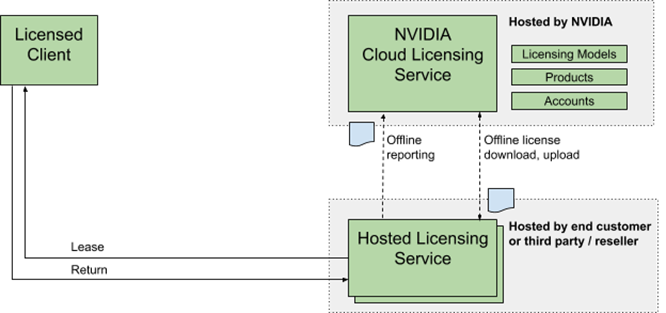 Figure 1. NVIDIA DLS instance license system workflow
Figure 1. NVIDIA DLS instance license system workflow
The following DLS software image types are available:
- A virtual appliance image to be installed in a virtual machine on a supported hypervisor.
- A containerized software image for bare-metal deployment on a supported container orchestration platform.
Setting up a DLS instance
1. Download the latest "NLS License Server (DLS) 2.1 for Container Platforms" software from the NVIDIA Licensing Portal.
2. To import DLS appliance and PostgreSQL, run the following commands:
podman load --input dls_appliance_2.1.0.tar.gz
podman load --input dls_pgsql_2.1.0.tar.gz
3. Upload the DLS appliance artifact and the PostgreSQL database artifact images to a private repository.
4. Edit the deployment files for the DLS appliance artifact, and then use the PostgreSQL database artifact to pull these artifacts from the private repository.
You must provide an IP address for DLS_PUBLIC_IP. Optionally, you can edit the DLS default ports in the nls-si-0-deployment.yaml and nls-si-0-service.yaml deployment files. If a registry secret is required to pull the images from the private repository, edit the deployment files for the DLS appliance and the PostgreSQL database to reference the secret.
5. Create a Postgres instance by running the following command:
oc create -f directory/postgres-nls-si-0-deployment.yaml
6. Fetch the IP address of the Postgres pod that you created in the previous step, and then set the DLS_DB_HOST environment variable in the nls-si-0-deployment.yaml file to the IP address of the postgres pod:
oc create -f directory/nls-si-0-deployment.yaml
7. Access the DLS instance at https://<worker-node-ip>:30001. Register the default admin user dls_admin with a new password during the first login.
8. Create a license server on the NVIDIA Licensing Portal, and then add the licenses for the products that you want to allot to this license server.  Figure 2. Adding a license to the DLS instance
Figure 2. Adding a license to the DLS instance
9. Register the on-premises DLS instance by uploading the DLS token file dls_instance_token_mm-dd-yyyy-hh-mm-ss.tok to the NVIDIA Licensing Portal. Bind the license server that you created in the preceding step to the registered service instance.
10. Download the license file license_mm-dd-yyyy-hh-mm-ss.bin from the license server on the portal and upload it to your on-premises DLS instance. The licenses on the server are made available to the DLS instance.
11. Generate the client configuration token file from the DLS instance. The client configuration token contains information about the service instance, license servers, and fulfillment conditions to be used to serve a license in response to a client request.
12. Copy the client configuration token to clients so that the service instance has the necessary information to serve licenses to clients.
Installing NVIDIA AI Enterprise on OpenShift
1. Install the Node Feature Discovery (NFD) operator.
Install the NFD operator from the embedded Red Hat OperatorHub. After the operator is installed, create an NFD API so that the NFD operator can label the cluster nodes that have GPUs.
2. Install the NVIDIA GPU operator.
Install the NVIDIA GPU operator from the embedded Red Hat OperatorHub. The GPU operator enables Kubernetes cluster engineers to manage GPU nodes just like CPU nodes in the cluster. The operator installs and manages the life cycle of software components so that GPU-accelerated applications can be run on Kubernetes. This operator is installed in the nvidia-gpu-operator namespace by default.
3. Create an NGC secret.
Create an image pull secret object n the nvidia-gpu-operator namespace. This object is for storing the NGC API key to authenticate your access to the NGC container registry. Generate the API key from the NGC catalog.
Use the following credentials for the NGC secret:
- Authentication type in the secret Image registry: the registry server address is nvcr.io/nvaie
- Username: $oauthtoken
- Password: the generated API key.
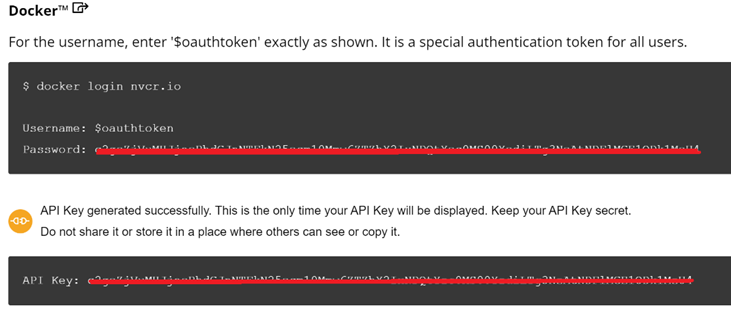 Figure 3. NGC secret
Figure 3. NGC secret
4. Create a ConfigMap with configuration data.
Create a configmap in the nvidia-gpu-operator namespace with the client configuration token as data.
kind: ConfigMap
apiVersion: v1
metadata:
name: licensing-config
data:
client_configuration_token.tok: >-
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiIwY2QxZ<...>
gridd.conf: '# empty file'
5. Create a Cluster Policy Custom Resource instance.
When you install the NVIDIA GPU operator in OpenShift Container Platform, a custom resource definition for a cluster policy is created. The policy configures the GPU stack that will be deployed, configuring the image names and repository, pod restrictions or credentials, and so on. When creating the cluster policy from the OpenShift web console, make the following customizations:
1. Enter the configmap containing the client configuration token that you created in the NVIDIA GPU/vGPU driver configuration file and enable the NLS.
2. Enable the deployment of the NVIDIA driver through the operator. The image repository is nvcr.io/nvaie.
3. Enter the NGC secret name in the driver configuration.
4. Specify the image name and NVIDIA vGPU driver version in the NVIDIA GPU/vGPU driver configuration section. Get this information from the NGC catalog, as shown in the following figure:
kind: ConfigMap
apiVersion: v1
metadata:
name: licensing-config
data:
client_configuration_token.tok: >-
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJqdGkiOiIwY2QxZ<...>
gridd.conf: '# empty file'
Figure 4. Configmap with Client configuration token
For a cluster on OpenShift Container Platform version 4.12, the NVIDIA GPU driver image is vgpu-guest-driver-3-1 and the version is 525.105.17. The GPU operator installs all the components that are required to set up the NVIDIA GPUs in the OpenShift cluster.
Validation
Environment overview: The Dell OpenShift validation team used Dell PowerEdge servers hosting Red Hat OpenShift Platform 4.12 to validate the NVIDIA AI Enterprise on OpenShift. The validated environment consisted of three compute nodes hosted on PowerEdge R760, R750 and R7525 servers and equipped respectively with NVIDIA GPU H100, A40, and A100. For more information about deploying an OpenShift cluster on Dell-powered bare metal servers, see the Red Hat OpenShift Container Platform 4.12 on Dell Infrastructure Implementation Guide.
A containerized DLS instance is present on the same OpenShift cluster with all the required licenses.
The team created a TensorFlow pod using the "tensorflow-3-1" image from the nvcr.io/nvaie repository by running the following commands:
apiVersion: v1
kind: Pod
metadata:
name: gpu
spec:
nodeSelector:
nvidia.com/gpu.product: NVIDIA-H100-PCIe
containers:
- image: nvcr.io/nvaie/tensorflow-3-1:23.03-tf1-nvaie-3.1-py3
name: tensorflow
command: ["/bin/sh","-c"]
resources:
limits:
nvidia.com/gpu: 1
requests:
nvidia.com/gpu: 1
restartPolicy: Never
The ResNet-50 convolutional neural network with FP32 and FP16 precision from inside the TensorFlow pod ran successfully.
To run the test, the team used the following commands:
cd /workspace/nvidia-examples/cnn
python resnet.py --layers 50 -b 64 -i 200 -u batch --precision fp16
python resnet.py --layers 50 -b 64 -i 300 -u batch --precision fp32
References
Red Hat OpenShift Container Platform 4.12 on Dell Infrastructure Implementation Guide
OpenShift on Bare Metal Deployment Guide
NVIDIA License System v3.2.0
NVIDIA User Guide
NVIDIA AI Enterprise with OpenShift