




Dell EMC vSAN Ready Nodes: Taking VDI and AI Beyond “Good Enough”

Some people have speculated that 2020 was “the year of VDI” while others say that it will never be the “year of VDI.” However, there is one certainty. In 2020 and part of 2021, organizations worldwide consumed a large amount of virtual desktop infrastructure (VDI). Some of these deployments went extremely well while other deployments were just “good enough.”
If you are a VDI enthusiast like me, there was much to learn from all that happened over the last 24 months. An interesting observation is that test VDI environments turned into production environments overnight. Also, people discovered that the capacity of clouds is not limitless. My favorite observation is the discovery by many IT professionals that GPUs can change the VDI experience from “good enough” to enjoyable, especially when coupled with an outstanding environment powered by Dell Technologies with VMware vSphere and VMware Horizon.
In this blog, I will tell you about how exceptional VDI (and AI/ML) is when paired with powerful technology.
This blog does not address cloud workloads as it is a substantial topic. It would be difficult for me to provide the proper level of attention in this blog, so I will address only on premises deployments.
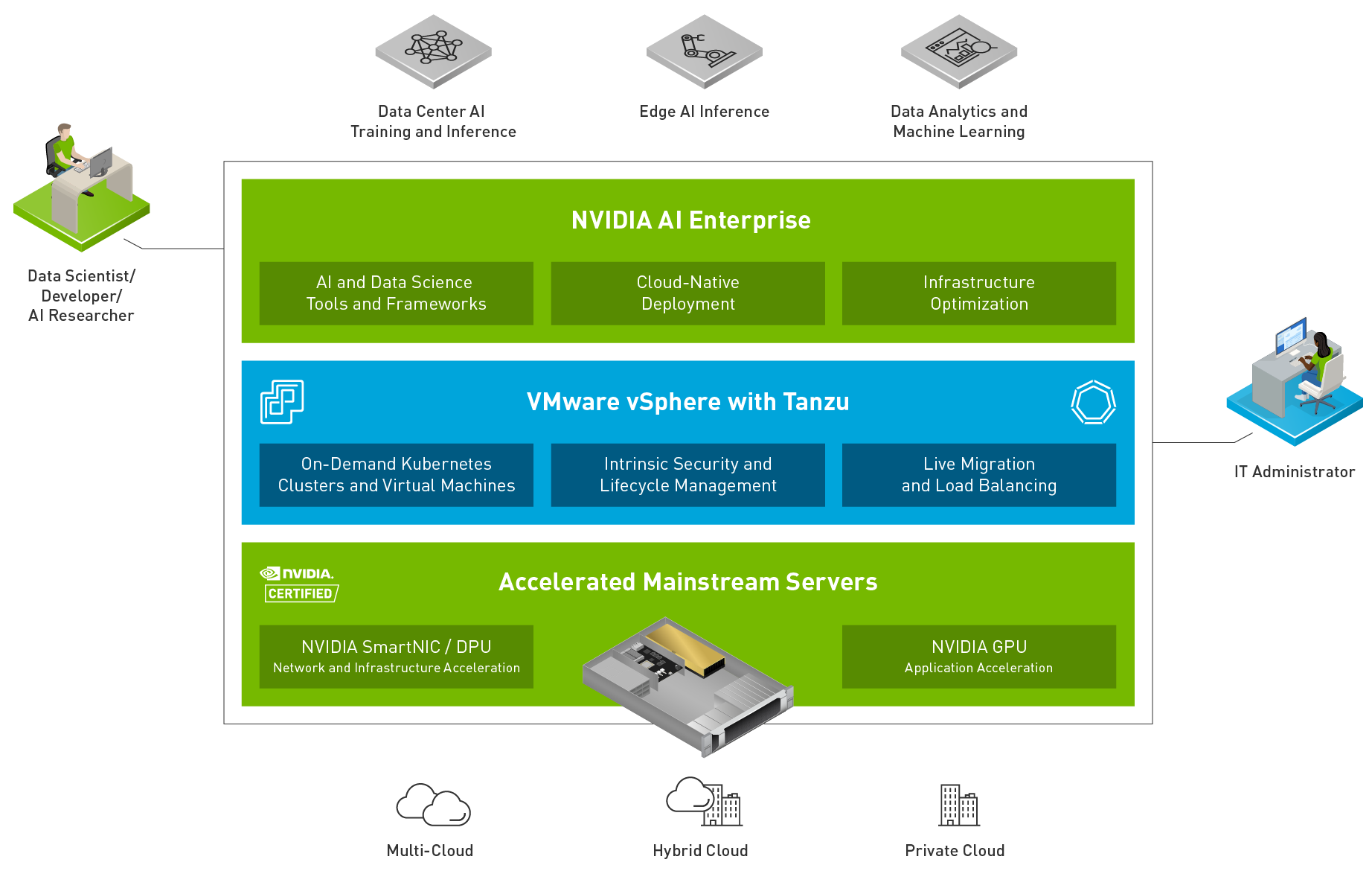
Many end users adopt hyperconverged infrastructure (HCI) in their data centers because it is easy to consume. One of the most popular HCIs is Dell EMC VxRail Hyperconverged Infrastructure. You can purchase nodes to match your needs. These needs range from the traditional data center workloads, to Tanzu clusters, to VDI with GPUs, and to AI. VxRail enables you to deliver whatever your end users need. Your end users might be developers working from home on a containers-based AI project and they need a development environment, VxRail can provide it with relative ease.
Some IT teams might want an HCI experience that is more customer managed but they still want a system that is straightforward to deploy, validate, and is easy to maintain. This scenario is where Dell EMC vSAN Ready Nodes come into play.

Dell EMC vSAN Ready Nodes provide comprehensive, flexible, and efficient solutions optimized for your workforce’s business goals with a large choice of options (more than 250 as of the September 29, 2021 vSAN Compatibility Guide) from tower to rack mount to blades. A surprising option is that you can purchase Dell EMC vSAN Ready Nodes with GPUs, making them a great platform for VDI and virtualized AI/ML workloads.
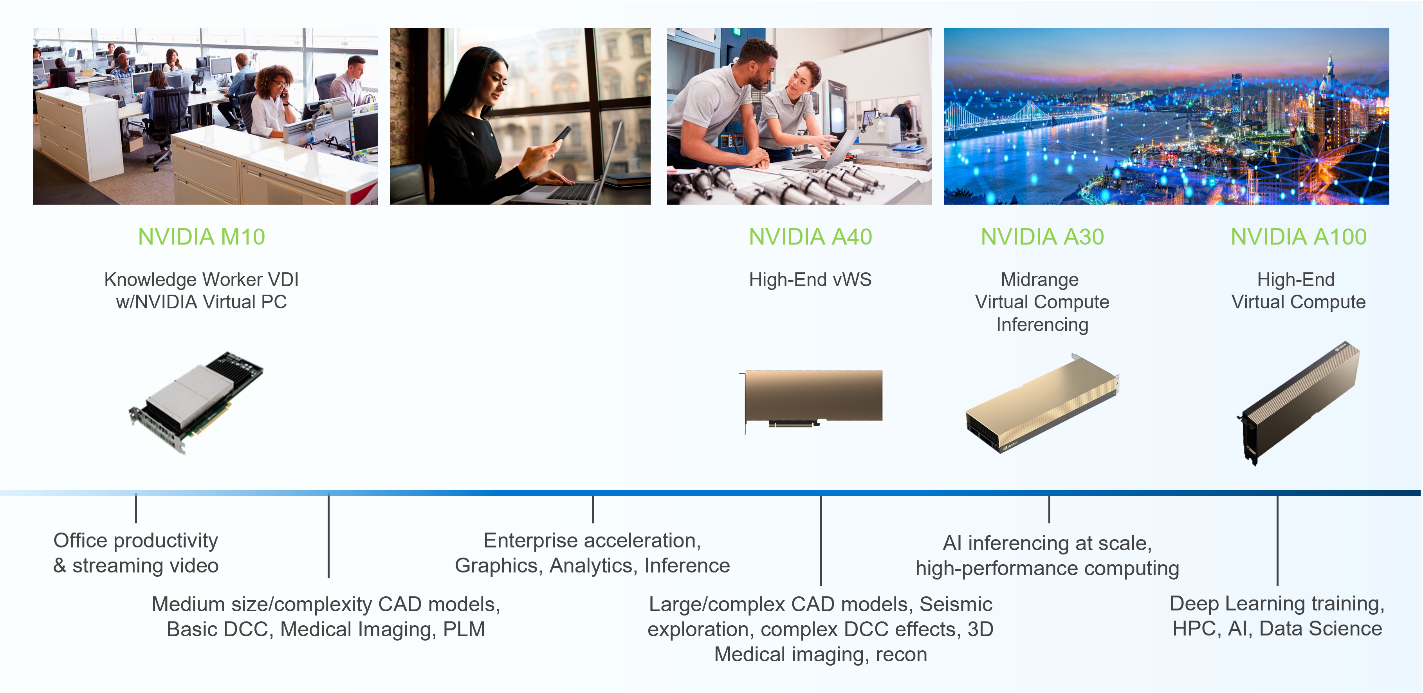
Dell EMC vSAN Ready Nodes supports many NVIDIA GPUs used for VDI and AI workloads, notably the NVIDIA M10 and A40 GPUs for VDI workloads and the NVIDIA A30 and A100 GPUs for AI workloads. There are other available GPUs depending on workload requirements, however, this blog focuses on the more common use cases.
For some time, the NVIDIA M10 GPU has been the GPU of choice for VDI-based knowledge workers who typically use applications such as Microsoft PowerPoint and YouTube. The M10 GPU provides a high density of users per card and can support multiple virtual GPU (vGPU) profiles per card. The multiple profiles result from having four GPU chips per PCI board. Each chip can run a unique vGPU profile, which means that you can have four vGPU profiles. That is, there are twice as many profiles than are provided by other NVIDIA GPUs. This scenario is well suited for organizations with a larger set of desktop profiles.
Combining this profile capacity with Dell EMC vSAN Ready Nodes, organizations can deliver various desktop options yet be based on a standardized platform. Organizations can let end users choose the system that suites them best and can optimize IT resources by aligning them to an end user’s needs.
Typically, power users need or want more graphics capabilities than knowledge workers. For example, power users working in CAD applications need larger vGPU profiles and other capabilities like NVIDIA’s Ray Tracing technology to render drawings. These power users’ VDI instances tend to be more suited to the NVIDIA A40 GPU and associated vGPU profiles. It allows power users who do more than create Microsoft PowerPoint presentations and watch YouTube videos to have the desktop experience they need to work effectively.
The ideal Dell EMC vSAN Ready Nodes platform for the A40 GPU is based on the Dell EMC PowerEdge R750 server. The PowerEdge R750 server provides the power and capacity for demanding workloads like healthcare imaging and natural resource exploration. These workloads also tend to take full advantage of other features built into NVIDIA GPUs like CUDA. CUDA is a parallel computing platform and programming model that uses GPUs. It is used in many high-end applications. Typically, CUDA is not used with traditional graphics workloads.
In this scenario, we start to see the blend between graphics and AI/ML workloads. Some VDI users not only render complex graphics sets, but also use the GPU for other computational outcomes, much like AI and ML do.
I really like that I can run AI/ML workloads in a virtual environment. It does not matter if you are an IT administrator or an AI/ML administrator. You can run AI and ML workloads in a virtual environment.
Many organizations have realized that the same benefits virtualization has brought to IT can also be realized in the AI/ML space. There are additional advantages, but those are best kept for another time.
For some organizations, IT is now responsible for AI/ML environments, whether delivering test/dev environments for programmers or delivering a complete AI training environment. For other IT groups, this responsibility falls to highly paid data scientists. And for some IT groups, the responsibility is a mix.
In this scenario, virtualization shines. IT administrators can do what they do best: deliver a powerful Dell EMC vSAN Ready Node infrastructure. Then, data scientists can spend their time building systems in a virtual environment consuming IT resources instead of racking and cabling a server.
Dell EMC vSAN Ready nodes are great for many AI/ML applications. They are easy to consume as a single unit of infrastructure. Both the NVIDIA A30 GPU and the A100 GPU are available so that organizations can quickly and easily assemble the ideal architecture for AI/ML workloads.
This ease of consumption is important for both IT and data scientists. It is unacceptable when IT consumers like data scientists must wait for the infrastructure they need to do their job. Time is money. Data scientists need environments quickly, which Dell EMC vSAN Ready Nodes can help provide. Dell EMC vSAN Ready Nodes deploy 130 percent faster with Dell EMC OpenManage Integration for VMware vCenter (OMIVV) (Based on Dell EMC internal competitive testing of PowerEdge and OMIVV compared to Cisco UCS manual operating system deployment.)
This speed extends beyond day 0 (deployment) to day 1+ operations. When using the vLCM and OMIVV, complete hypervisor and firmware updates to an eight-node PowerEdge cluster took under four minutes compared to a manual process, which took3.5 hours.(Principle Technologies report commissioned by Dell Technologies, New VMware vSphere 7.0 features reduced the time and complexity of routine update and hardware compliance tasks, July 2020.)
Dell EMC vSAN Ready Nodes ensures that you do not have to be an expert in hardware compatibility. With over 250 Dell EMC vSAN Ready Nodes available (as of the September 29, 2021 vSAN Compatibility Guide), you do not need to guess which drives will work or if a network adapter is compatible. You can then focus more on data and the results and less on building infrastructure.
These time-to-value considerations, especially for AI/ML workloads, are important. Being able to deliver workloads such as AI/ML or VDI quickly can have a significant impact on organizations, as has been evident in many organizations over the last two years. It has been amazing to see how fast organizations have adopted or expanded their VDI environments to accommodate everyone from knowledge workers to high-end power users wherever they need to consume IT resources.
Beyond “just expanding VDI” to more users, organizations have discovered that GPUs can improve the end-user experience and, in some cases, not only help but were required. For many, the NVIDIA M10 GPU helped users gain the wanted remote experience and move beyond “good enough.” For others who needed a more graphics-rich experience, the NVIDIA A40 GPU continues to be an ideal choice.
When GPUs are brought together as part of a Dell EMC vSAN Ready Node, organizations have the opportunity to deliver an expanded VDI and AI/ML experience to their users. To find out more about Dell EMC vSAN Ready Nodes, see Dell EMC vSAN Ready Nodes.
Author: Tony Foster Twitter: @wonder_nerd LinkedIn: https://linkedin.com/in/wondernerd
Related Blog Posts
Performance of the Dell PowerEdge R750xa Server for MLPerf™ Inference v2.0
Thu, 21 Apr 2022 18:20:33 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf Inference v2.0 benchmark suite. The results provide information about the performance of Dell servers. This blog takes a closer look at the Dell PowerEdge R750xa server and its performance for MLPerf Inference v1.1 and v2.0.
We compare the v1.1 results with the v2.0 results. We show the performance difference between the software stack versions. We also use the PowerEdge R750xa server to demonstrate that the v1.1 results from all systems can be referenced for planning an ML workload on systems that are not available for MLPerf Inference v2.0.
PowerEdge R750xa server
Built with state-of-the-art components, the PowerEdge R750xa server is ideal for artificial intelligence (AI), machine learning (ML), and deep learning (DL) workloads. The PowerEdge R750xa server is the GPU-optimized version of the PowerEdge R750 server. It supports accelerators as 4 x 300 W DW or 6 x 75 W SW. The GPUs are placed in the front of the PowerEdge R750xa server allowing for better airflow management. It has up to eight available PCIe Gen4 slots and supports up to eight NVMe SSDs.
The following figures show the PowerEdge R750xa server (source):

Figure 1: Front view of the PowerEdge R750xa server

Figure 2: Rear view of the PowerEdge R750xa server

Figure 3: Top view of the PowerEdge R750xa server
Configuration comparison
The following table describes the software stack configurations from the two rounds of submission for the closed data center division:
Table 1: MLPerf Inference v1.1 and v2.0 software stacks
NVIDIA component | v1.1 software stack | v2.0 software stack |
TensorRT | 8.0.2 | 8.4.0 |
CUDA | 11.3 | 11.6 |
cuDNN | 8.2.1 | 8.3.2 |
GPU driver | 470.42.01 | 510.39.01 |
DALI | 0.30.0 | 0.31.0 |
Triton | 21.07 | 22.01 |
Although the software has been updated across the two rounds of submission, performance is consistent, if not better, for the v2.0 submission. For MLPerf Inference v2.0, Triton performance results can be extrapolated from MLPerf Inference v1.1 except for the 3D U-Net benchmark, which is due to a v2.0 dataset change.
The following table describes the System Under Test (SUT) configurations from MLPerf Inference v1.1 and v2.0 of data center inference submissions:
Table 2: MLPerf Inference v1.1 and v2.0 system configuration of the PowerEdge R750xa server
Component | v1.1 system configuration | v2.0 system configuration |
Platform | R750xa 4x A100-PCIE-80GB, TensorRT | R750xa 4xA100 TensorRT |
MLPerf system ID | R750xa_A100-PCIE-80GBx4_TRT | R750xa_A100_PCIE_80GBx4_TRT |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
Memory | 1 TB | |
GPU | NVIDIA A100-PCIE-80GB | |
GPU form factor | PCIe | |
GPU count | 4 | |
Software stack | TensorRT 8.0.2 | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.39.01 DALI 0.31.0 |
In the v1.1 round of submission, Dell Technologies submitted four different configurations on the PowerEdge R750xa server. Although the GPU count of four was maintained, Dell Technologies submitted the 40 GB and the 80 GB versions of the NVIDIA A100 GPU. Additionally, Dell Technologies submitted Multi-Instance GPU (MIG) numbers using 28 instances of the one compute instance of the 10gb memory profile on the 80 GB A100 GPU. Furthermore, Dell Technologies submitted power numbers (MaxQ is a performance and power submission) for the 40 GB version of the A100 GPU and submitted with the Triton server on the 80 GB version of the A100 GPU. A discussion about the v1.1 submission by Dell Technologies can be found in this blog.
Performance comparison of the PowerEdge R70xa server for MLPerf Inference v2.0 and v1.1
ResNet 50
ReNet50 is a 50-layer deep convolution neural network that is made up of 48 convolution layers along with a single max pool and average pool layer. This model is used for computer vision applications including image classification, object detection, and object classification. For the ResNet 50 benchmark, the performance numbers from the v2.0 submission match and outperform in the server and offline scenarios respectively when compared to the v1.1 round of submission. As shown in the following figure, the v2.0 submission results are within 0.02 percent in the server scenario and outperform the previous round by 1 percent in the offline scenario:
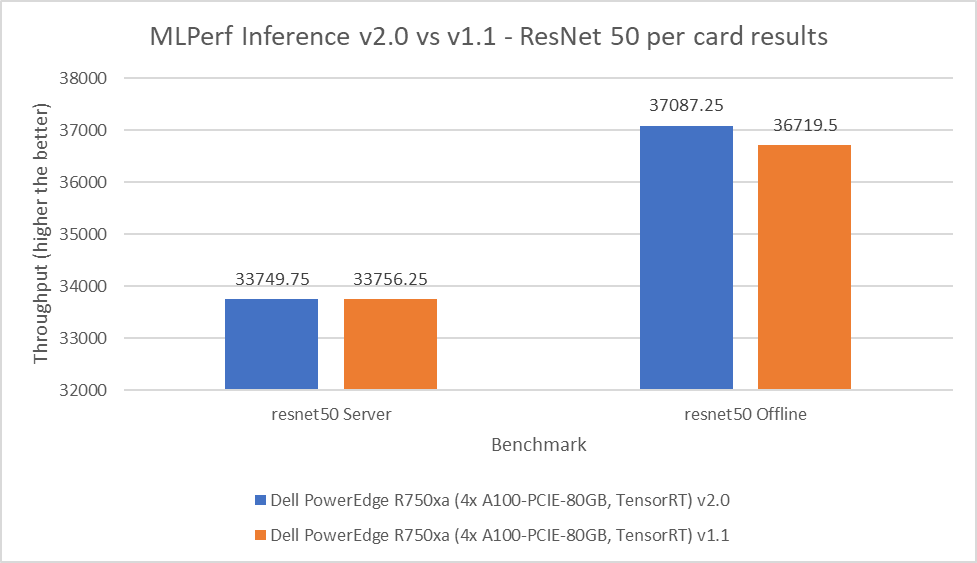
Figure 4: MLPerf Inference v2.0 compared to v1.1 ResNet 50 per card results on the PowerEdge R750xa server
BERT
Bidirectional Encoder Representation from Transformers (BERT) is a state-of-the-art language representational model for Natural Language Processing applications. This benchmark performs the SQuAD question answering task. The BERT benchmark consists of default and high accuracy modes for the offline and server scenarios. In the v2.0 round of submission, the PowerEdge R750xa server matched and slightly outperformed its performance from the previous round. In the default BERT server and offline scenarios, the extracted performance is within 0.06 and 2.33 percent respectively. In the high accuracy BERT server and offline scenarios, the extracted performance is within 0.14 and 1.25 percent respectively.
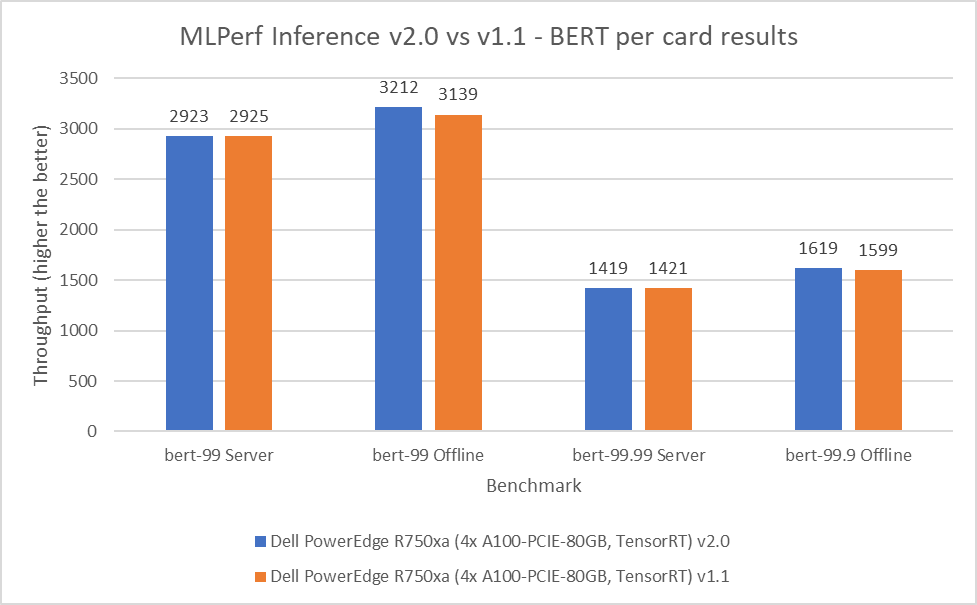
Figure 5: MLPerf Inference v2.0 compared to v1.1 BERT per card results on the PowerEdge R750xa server
SSD-ResNet 34
The SSD-ResNet 34 model falls under the computer vision category. This benchmark performs object detection. For the SSD-ResNet 34 benchmark, the results produced in the v2.0 round of submission are within 0.14 percent for the server scenario and show a 1 percent improvement in the offline scenario.
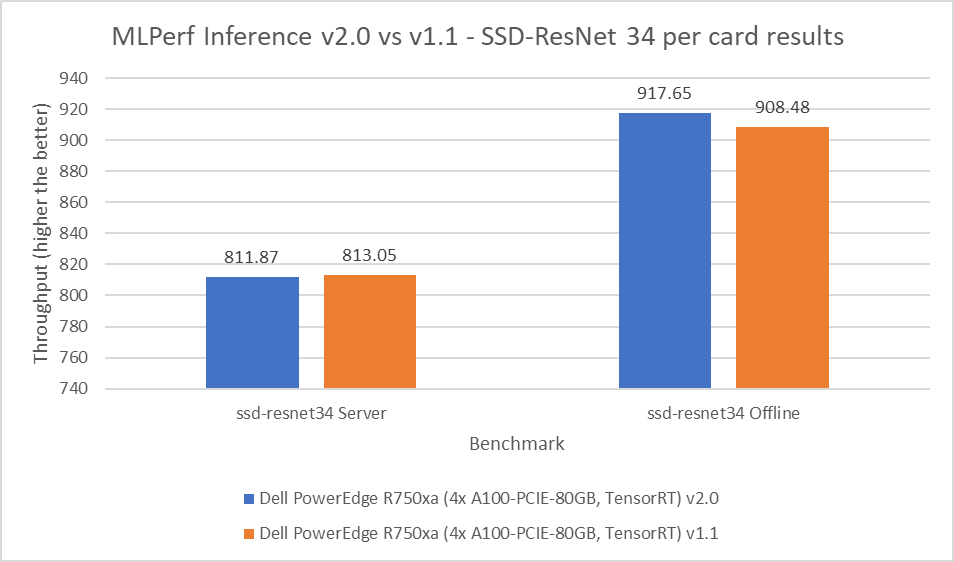
Figure 6: MLPerf Inference v2.0 compared to v1.1 SSD-ResNet 34 per card results on the PowerEdge R750xa server
DLRM
Deep Learning Recommendation Model (DLRM) is an effective benchmark for understanding workload requirements for building recommender systems. This model uses collaborative filtering and predicative analysis-based approaches to process large amounts of data. The DLRM benchmark consists of default and high accuracy modes, both containing the server and offline scenarios. For the server scenario in both the default and high accuracy modes, the v2.0 submissions results are within 0.003 percent. For the offline scenario across both modes, the PowerEdge R750xa server showed a 2.62 percent performance gain.
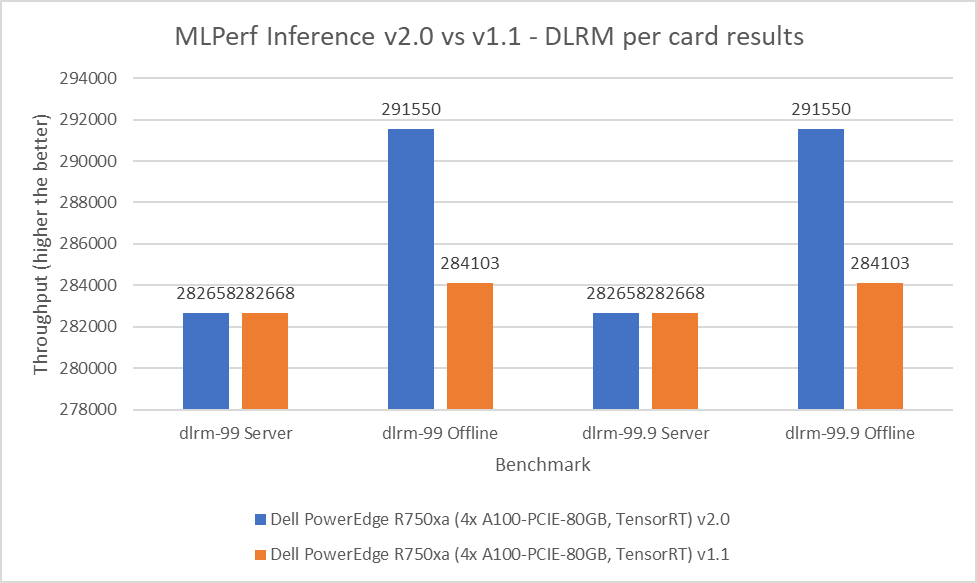
Figure 7: MLPerf Inference v2.0 compared to v1.1 DLRM per card results on the PowerEdge R750xa server
RNNT
The Recurrent Neural Network Transducers (RNNT) model falls under the speech recognition category. This benchmark accepts raw audio samples and produces the corresponding character transcription. For the RNNT benchmark, the PowerEdge R750xa server maintained similar performance behavior within 0.04 percent in the server mode and showing 1.46 percent performance gains in the offline mode.
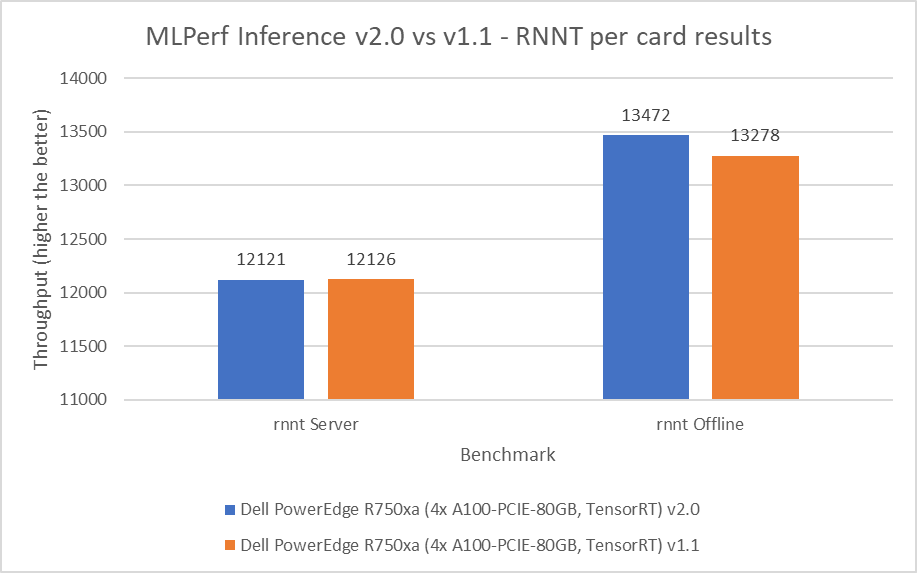
Figure 8: MLPerf Inference v2.0 compared to v1.1 RNNT per card results on the PowerEdge R750xa server
3D U-Net
The 3D U-Net performance numbers have changed in terms of scale and are not comparable in a bar graph because of a change to the dataset. The new dataset for this model is the Kitts 2019 Kidney Tumor Segmentation set. However, the PowerEdge R750xa server yielded Number One results among the PCIe form factor systems that were submitted. This model falls under the computer vision category, but it specifically deals with medical image data.
Results summary
Figure 1 through Figure 8 show the consistent performance of the PowerEdge R750xa server across both rounds of submission.
The following figure shows that in the offline scenarios for the benchmarks there is a small but noticeable performance improvement:
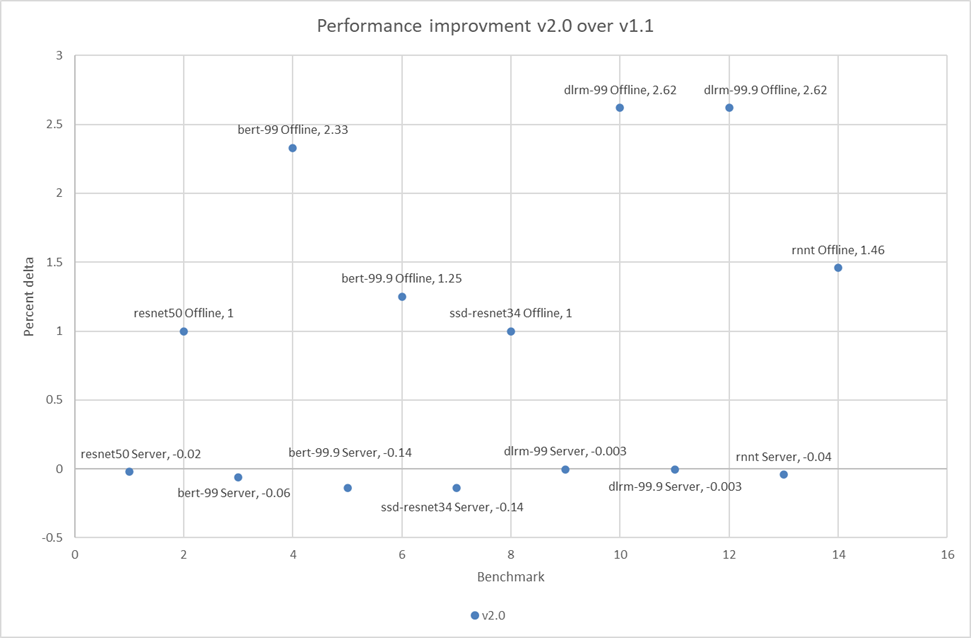
Figure 9: Performance improvement in percentage of the PowerEdge R750xa server across MLPerf Inference v2.0 and v1.1
The small percentage delta in the server scenarios can be a result of noise and are consistent with the previous round of submission.
Conclusion
This blog confirms the consistent performance of the Dell PowerEdge R750xa server across the MLPerf Inference v1.1 and MLPerf Inference v2.0 submissions. Because an identical system from round v1.1 performed at a consistent level for MLPerf Inference v2.0, we see that the software stack upgrades had minimal impact on performance. Therefore, the optimal results from the v1.1 round of submission can be used for making informed decisions about server performance for a specific ML workload. Because Dell Technologies submitted a diverse set of configurations in the v1.1 round of submission, customers can take advantage of many results.

New Frontiers—Dell EMC PowerEdge R750xa Server with NVIDIA A100 GPUs
Tue, 01 Jun 2021 20:18:04 -0000
|Read Time: 0 minutes
Dell Technologies has released the new PowerEdge R750xa server, a GPU workload-based platform that is designed to support artificial intelligence, machine learning, and high-performance computing solutions. The dual socket/2U platform supports 3rd Gen Intel Xeon processors (code named Ice Lake). It supports up to 40 cores per processor, has eight memory channels per CPU, and up to 32 DDR4 DIMMs at 3200 MT/s DIMM speed. This server can accommodate up to four double-width PCIe GPUs that are located in the front left and the front right of the server.
Compared with the previous generation PowerEdge C4140 and PowerEdge R740 GPU platform options, the new PowerEdge R750xa server supports larger storage capacity, provides more flexible GPU offerings, and improves the thermal requirement

Figure 1 PowerEdge R750xa server
The NVIDIA A100 GPUs are built on the NVIDIA Ampere architecture to enable double precision workloads. This blog evaluates the new PowerEdge R750xa server and compares its performance with the previous generation PowerEdge C4140 server.
The following table shows the specifications for the NVIDIA GPU that is discussed in this blog and compares the performance improvement from the previous generation.
Table 1 NVIDIA GPU specifications
PCIe | Improvement | ||
GPU name | A100 | V100 |
|
GPU architecture | Ampere | Volta | - |
GPU memory | 40 GB | 32 GB | 60% |
GPU memory bandwidth | 1555 GB/s | 900 GB/s | 73% |
Peak FP64 | 9.7 TFLOPS | 7 TFLOPS | 39% |
Peak FP64 Tensor Core | 19.5 TFLOPS | N/A | - |
Peak FP32 | 19.5 TFLOPS | 14 TFLOPS | 39% |
Peak FP32 Tensor Core | 156 TFLOPS 312 TFLOPS* | N/A | - |
Peak Mixed Precision FP16 ops/ FP32 Accumulate | 312 TFLOPS 624 TFLOPS* | 125 TFLOPS | 5x |
GPU base clock | 765 MHz | 1230 MHz | - |
Peak INT8 | 624 TOPS 1,248 TOPS* | N/A | - |
GPU Boost clock | 1410 MHz | 1380 MHz | 2.1% |
NVLink speed | 600 GB/s | N/A | - |
Maximum power consumption | 250 W | 250 W | No change |
Test bed and applications
This blog quantifies the performance improvement of the GPUs with the new PowerEdge GPU platform.
Using a single node PowerEdge R750xa server in the Dell HPC & AI Innovation Lab, we derived all results presented in this blog from this test bed. This section describes the test bed and the applications that were evaluated as part of the study. The following table provides test environment details:
Table 2 Server configuration
Component | Test Bed 1 | Test Bed 2 |
Server | Dell PowerEdge R750xa
| Dell PowerEdge C4140 configuration M |
Processor | Intel Xeon 8380 | Intel Xeon 6248 |
Memory | 32 x 16 GB @ 3200MT/s | 16 x 16 GB @ 2933MT/s |
Operating system | Red Hat Enterprise Linux 8.3 | Red Hat Enterprise Linux 8.3 |
GPU | 4 x NVIDIA A100-PCIe-40 GB GPU | 4 x NVIDIA V100-PCIe-32 GB GPU |
The following table provides information about the applications and benchmarks used:
Table 3 Benchmark and application details
Application | Domain | Version | Benchmark dataset |
High-Performance Linpack | Floating point compute-intensive system benchmark | xhpl_cuda-11.0-dyn_mkl-static_ompi-4.0.4_gcc4.8.5_7-23-20 | Problem size is more than 95% of GPU memory |
HPCG | Sparse matrix calculations | xhpcg-3.1_cuda_11_ompi-3.1 | 512 * 512 * 288
|
GROMACS | Molecular dynamics application | 2020 | Ligno Cellulose Water 1536 Water 3072 |
LAMMPS | Molecular dynamics application | 29 October 2020 release | Lennard Jones |
LAMMPS
Large-Scale Atomic/Molecular Massively Parallel simulator (LAMMPS) is distributed by Sandia National Labs and the US Department of Energy. LAMMPS is open-source code that has different accelerated models for performance on CPUs and GPUs. For our test, we compiled the binary using the KOKKOS package, which runs efficiently on GPUs.
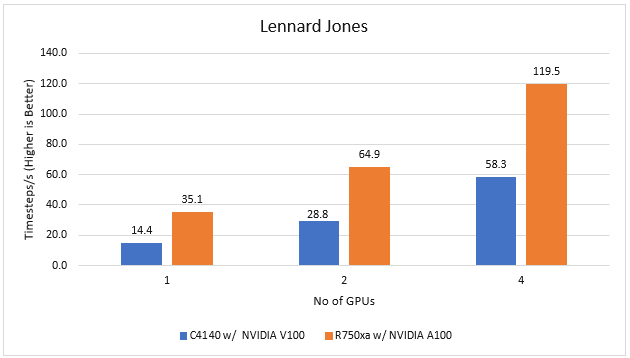
Figure 2 LAMMPS Performance on PowerEdge R750xa and PowerEdge C4140 servers
With the newer generation GPUs, this application improves 2.4 times compared to single GPU performance. The overall performance from a single server improved twice with the PowerEdge R750xa server and NVIDIA A100 GPUs.
GROMACS
GROMACS is a free and open-source parallel molecular dynamics package designed for simulations of biochemical molecules such as proteins, lipids, and nucleic acids. It is used by a wide variety of researchers, particularly for biomolecular and chemistry simulations. GROMACS supports all the usual algorithms expected from modern molecular dynamics implementation. It is open-source software with the latest versions available under the GNU Lesser General Public License (LGPL).
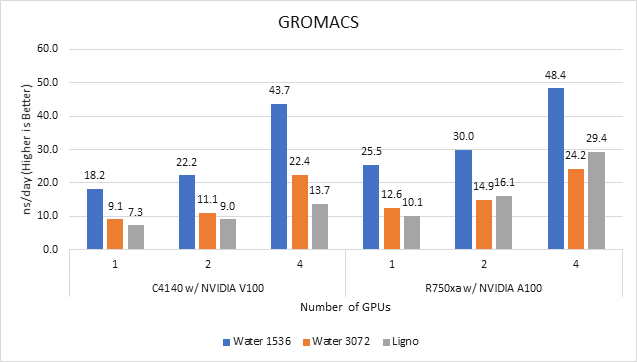
Figure 3 GROMACS performance on PowerEdge C4140 and r750xa servers
With the newer generation GPUs, this application improved approximately 1.5 times across the dataset compared to single GPU performance. The overall performance from a single server improved 1.5 times with a PowerEdge R750xa server and NVIDIA A100 GPUs.
High-Performance Linpack
High-Performance Linpack (HPL) needs no introduction in the HPC arena. It is a widely used standard benchmark tests in the industry.
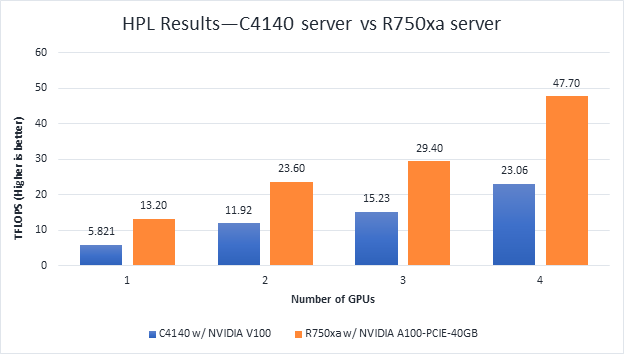
Figure 4 HPL Performance on the PowerEdge R750xa server with A100 GPU and PowerEdge C4140 server with V100 GPU
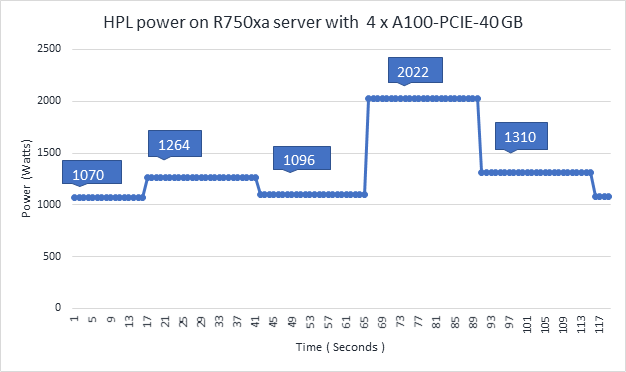
Figure 5 Power use of the HPL running on NVIDIA GPUs
From Figure 4 and Figure 5, the following results were observed:
- Performance—For GPU count, the NVIDIA A100 GPU demonstrates twice the performance of the NVIDIA V100 GPU. Higher memory size, double precision FLOPS, and a newer architecture contribute to the improvement for the NVIDIA A100 GPU.
- Scalability—The PowerEdge R750xa server with four NVIDIA A100-PCIe-40 GB GPUs delivers 3.6 times higher HPL performance compared to one NVIDIA A100-PCIE-40 GB GPU. The NVIDIA A100 GPUs scale well inside the PowerEdge R750xa server for the HPL benchmark.
- Higher Rpeak—The HPL code on NVIDIA A100 GPUs uses the new double-precision Tensor cores. The theoretical peak for each GPU is 19.5 TFlops, as opposed to 9.7 TFlops.
- Power—Figure 5 shows power consumption of a complete HPL run with the PowerEdge R750xa server using four A100-PCIe GPUs. This result was measured with iDRAC commands, and the peak power consumption was observed as 2022 Watts. Based on our previous observations, we know that the PowerEdge C4140 server consumes approximately 1800 W of power.
HPCG
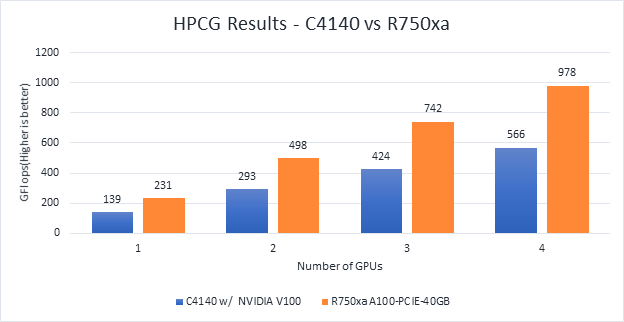
Figure 6 Scaling GPU performance data for HPCG Benchmark
As discussed in other blogs, high performance conjugate gradient (HPCG) is another standard benchmark to test data access patterns of sparse matrix calculations. From the graph, we see that the HPCG benchmark scales well with this benchmark resulting in 1.6 times performance improvement over the previous generation PowerEdge C4140 server with an NVIDIA V100 GPU.
The 72 percent improvement in memory bandwidth of the NVIDIA A100 GPU over the NVIDIA V100 GPU contributes to the performance improvement.
Conclusion
In this blog, we introduced the latest generation PowerEdge R750xa platform and discussed the performance improvement over the previous generation PowerEdge C4140 server. The PowerEdge R750xa server is a good option for customers looking for an Intel Xeon scalable CPU-based platform powered with NVIDIA GPUs.
With the newer generation PowerEdge R750xa server and NVIDIA A100 GPUs, the applications discussed in this blog show significant performance improvement.
Next steps
In future blogs, we plan to evaluate NVLINK bridge support, which is another important feature of the PowerEdge R750xa server and NVIDIA A100 GPUs.