




Dell EMC PowerFlex and VMware Cloud Foundation for High Performance Applications

The world in 2020 has shown all industries that innovation is necessary to thrive in all conditions. VMware Cloud Foundation (VCF) hybrid cloud platform was crafted by innovators who realize the biggest asset our customers have is their information technology and the data that runs the business. The VCF offering takes the complexity out of operationalizing infrastructure to enable greater elasticity, growth, and simplification through improved automation. VCF enables options available using on-premises and multi-cloud deployments to address ever changing enterprise needs.
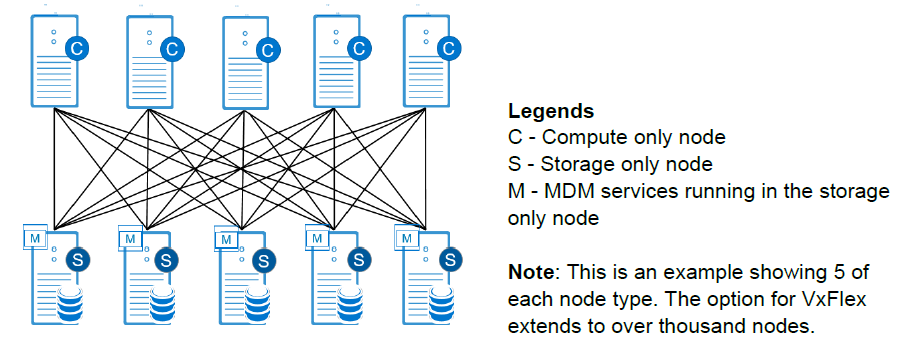
VMware included design factors that anticipated customers’ use of varying storage options in the flexibility of implementing VCF. VMware vSAN is the standard for VCF hyperconverged infrastructure (HCI) deployments and is directly integrated into vSphere and VCF. For those circumstances where workloads or customer resource usage require alternative storage methods, VMware built flexibility into the VCF storage offering. Just as we see a wide variety in desktop computing devices, one size doesn't fit all applies to the enterprise storage products as well. Dell Technologies’ PowerFlex (formerly VxFlex) provides a software-defined mechanism to add a combination of compute and storage with scale out flexibility. As customers look to software-defined operational constructs for agility, PowerFlex provides an adjustable means to add the right balance of storage resources while enabling non-disruptive additions without painful migrations as demands increase.
Joining the Dell Technologies Cloud family as a validated design, Dell EMC PowerFlex helps customers simplify their path to hybrid cloud by combining the power of Dell EMC infrastructure with VMware Cloud Foundation software as supplemental storage. As a high-performance, scale out, software-defined block storage product, PowerFlex provides a combination of storage and compute in a unified fabric that's well equipped to service particularly challenging workloads. The scalability of compute and/or storage in a modular architecture provides an asymmetrical (2-layer) option to add capacity to either compute or storage independently. PowerFlex makes it possible to transform from a traditional three-tier architecture to a modern data center without any trade-offs between performance, resilience or future expansion.
PowerFlex significantly reduces operational and infrastructure complexity, empowering organizations to move faster by delivering flexibility, elasticity, and simplicity with predictable performance and resiliency at scale for deployments. PowerFlex Manager is a key element of our engineered systems providing a full lifecycle administration experience for PowerFlex from day 0 through expansions and upgrades which is independent, but complementary to the full stack life cycle management available through VCF via SDDC Manager. A cornerstone value proposition of VCF is administering the lifecycle management of OS upgrades, vSphere updates, vRealize monitoring, automation and NSX administration. PowerFlex manager works in parallel with VCF to deliver a comprehensive lifecycle experience for the physical ingredients and for the PowerFlex software-define storage layer. PowerFlex also offers a vRealize Operations plug-in for a unified monitoring capability from VMware vRealize Suite which is included in most VCF editions. From a storage management perspective, PowerFlex utilizes a management system that complements VCF and VMware vSphere by working within the appropriate vCenter management constructs. PowerFlex Manager provides the administration of PowerFlex storage functions, while VCF and vCenter manages the allocation of LUNs to provisioned VMFS file systems to provide data stores for the provisioned workloads.

PowerFlex systems enables customers to scale from a small environment to enterprise scale with over a thousand nodes. In addition, it provides enterprise grade data protection, multi-tenant capabilities, and add-on enterprise features such as QoS, thin provisioning, compression and snapshots. PowerFlex systems deliver the performance and time-to-value required to meet the demands of the modern enterprise data center.
Does Supplemental Storage Mean Slow or Light Workload Use Cases?
PowerFlex provides a Dell Technologies validated design as a supplemental storage platform for VCF, unlocking the value of PowerFlex to be realized by customers within the VCF environment. By providing sub-millisecond latency, high IOPS and high throughput with linearity as nodes join the fabric, the result is a very predictable scaling profile that accelerates the VCF vision within the datacenter.
PowerFlex, as a part of VCF, can help solve for even the most demanding of applications. Using the supplemental capabilities to service workloads with the highest of efficiency provides a best of class performance experience. Some illustrative examples of demanding application workloads validated with PowerFlex, independent of VCF, include the following:
SAP HANA
SAP HANA certified for PowerFlex integrated rack in both 4-socket and 2-socket offerings (certification details). Highly efficient in hosting up to six production HANA instances per 4-socket server. Our capabilities outperform external competitors by hosting 2x the capacity. The Configuration and Deployment Best Practices for SAP HANA white paper provides details. While this white paper illustrates a single layer architecture, even better performance characteristics are achievable using the VCF aligned 2-layer architectural implementation of PowerFlex.
Oracle RAC & Microsoft SQL
Flexibility to run compute and storage on separate hardware results in significant reduction of database licensing cost.
- Oracle RAC Solution – Get over 1 Million IOPs with less than 1ms latency with Oracle 12c RAC database transactions in just six nodes delivering 33GB/sec throughput (5.6GB/sec per node).
- Oracle 19c RAC TPC-C achieving more than 10 Million TPMs in eight nodes.
- MS SQL 2019 Solution (white paper) or MS SQL 2019 Big Data Cluster with Kubernetes (white paper) delivering approximately 9 Million SQL Server transactions (TPMs) with less than 1ms latency using just five storage nodes.
SAS Analytics
Validated/certified by SAS for running SAS mixed analytics workloads (white paper) providing an average throughput of 210 MBs per core (40% greater than their recommended 150 MB/sec needed for certification).
Elastic Stack
The validated solution with Elastic provides customers with the required high-performance, scalable, block-based IO with flexible deployment options in multiple operating environments (Windows, Linux, Virtualized/Bare Metal). Elastic validated the efficiency of PowerFlex using only three compute and 4 storage nodes to deliver ~1 billion indexing events measured by Elastic’s Rally benchmarking tool.
EPIC
The validated PowerFlex solution for Epic delivers 6x9’s availability and high performance for critical the EPIC hyperspace workloads while simultaneously enabling hosting the VDI with the operational and analytical databases for a completely integrated infrastructure option.
Cassandra
For customers deploying Kubernetes container-based database deployments like Cassandra, PowerFlex provides 300,000 operations/second for 10 million operations (Read intensive operations) with avg read latency of 1ms on just eight nodes.
PowerFlex gives Dell Technologies the ability to help customers address diverse infrastructure needs. The implementation guide for using PowerFlex for supplemental storage provides the simple steps to provide complementary storage options for VCF deployments. For more information on the PowerFlex product family and workload solutions, please see the product page here.
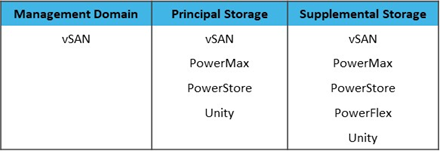
Other pre-tested Dell Technologies Storage products validated for VMware Cloud Foundation that provide the capabilities to independently scale storage and compute include the offerings below. You can find more details in the Dell Technologies Cloud Validated Designs document.
Related Blog Posts

Can I do that AI thing on Dell PowerFlex?

Thu, 20 Jul 2023 21:08:09 -0000
|Read Time: 0 minutes
The simple answer is Yes, you can do that AI thing with Dell PowerFlex. For those who might have been busy with other things, AI stands for Artificial Intelligence and is based on trained models that allow a computer to “think” in ways machines haven’t been able to do in the past. These trained models (neural networks) are essentially a long set of IF statements (layers) stacked on one another, and each IF has a ‘weight’. Once something has worked through a neural network, the weights provide a probability about the object. So, the AI system can be 95% sure that it’s looking at a bowl of soup or a major sporting event. That, at least, is my overly simplified description of how AI works. The term carries a lot of baggage as it’s been around for more than 70 years, and the definition has changed from time to time. (See The History of Artificial Intelligence.)
Most recently, AI has been made famous by large language models (LLMs) for conversational AI applications like ChatGPT. Though these applications have stoked fears that AI will take over the world and destroy humanity, that has yet to be seen. Computers still can do only what we humans tell them to do, even LLMs, and that means if something goes wrong, we their creators are ultimately to blame. (See ‘Godfather of AI’ leaves Google, warns of tech’s dangers.)
The reality is that most organizations aren’t building world destroying LLMs, they are building systems to ensure that every pizza made in their factory has exactly 12 slices of pepperoni evenly distributed on top of the pizza. Or maybe they are looking at loss prevention, or better traffic light timing, or they just want a better technical support phone menu. All of these are uses for AI and each one is constructed differently (they use different types of neural networks).
We won’t delve into these use cases in this blog because we need to start with the underlying infrastructure that makes all those ideas “AI possibilities.” We are going to start with the infrastructure and what many now consider a basic (by today’s standards) image classifier known as ResNet-50 v1.5. (See ResNet-50: The Basics and a Quick Tutorial.)
That’s also what the PowerFlex Solution Engineering team did in the validated design they recently published. This design details the use of ResNet-50 v1.5 in a VMware vSphere environment using NVIDIA AI Enterprise as part of PowerFlex environment. They started out with the basics of how a virtualized NVIDIA GPU works well in a PowerFlex environment. That’s what we’ll explore in this blog – getting started with AI workloads, and not how you build the next AI supercomputer (though you could do that with PowerFlex as well).
In this validated design, they use the NVIDIA A100 (PCIe) GPU and virtualized it in VMware vSphere as a virtual GPU or vGPU. With the infrastructure in place, they built Linux VMs that will contain the ResNet-50 v1.5 workload and vGPUs. Beyond just working with traditional vGPUs that many may be familiar with, they also worked with NVIDIA’s Multi-Instance GPU (MIG) technology.
NVIDIA’s MIG technology allows administrators to partition a GPU into a maximum of seven GPU instances. Being able to do this provides greater control of GPU resources, ensuring that large and small workloads get the appropriate amount of GPU resources they need without wasting any.
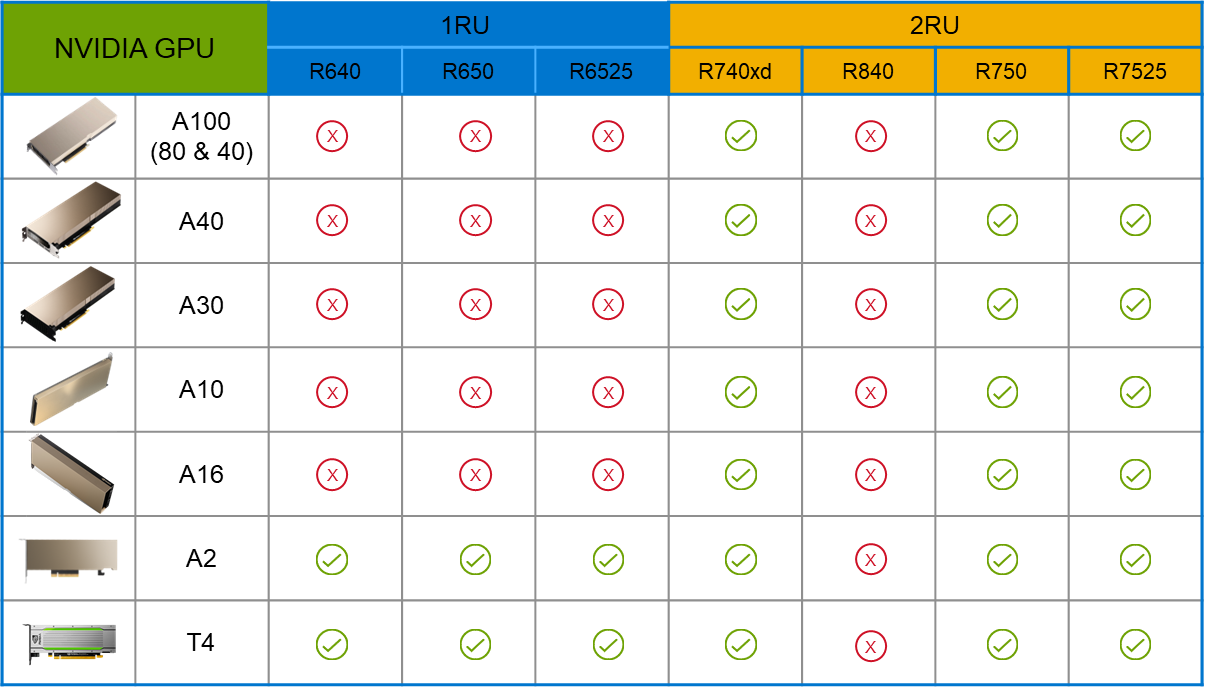
PowerFlex supports a large range of NVIDIA GPUs for workloads, from VDI (Virtual Desktops) to high end virtual compute workloads like AI. You can see this in the following diagram where there are solutions for “space constrained” and “edge” environments, all the way to GPUs used for large inferencing models. In the table below the diagram, you can see which GPUs are supported in each type of PowerFlex node. This provides a tremendous amount of flexibility depending on your workloads.

The validated design describes the steps to configure the architecture and provides detailed links to the NVIDIAand VMware documentation for configuring the vGPUs, and the licensing process for NVIDIA AI Enterprise.
These are key steps when building an AI environment. I know from my experience working with various organizations, and from teaching, that many are not used to working with vGPUs in Linux. This is slowly changing in the industry. If you haven’t spent a lot of time working with vGPUs in Linux, be sure to pay attention to the details provided in the guide. It is important and can make a big difference in your performance.
The following diagram shows the validated design’s logical architecture. At the top of the diagram, you can see four Ubuntu 22.04 Linux VMs with the NVIDIA vGPU driver loaded in them. They are running on PowerFlex hosts with VMware ESXi deployed. Each VM contains one NVIDIA A100 GPU configured for MIG operations. This configuration leverages a two-tier architecture where storage is provided by separate PowerFlex software defined storage (SDS) nodes.
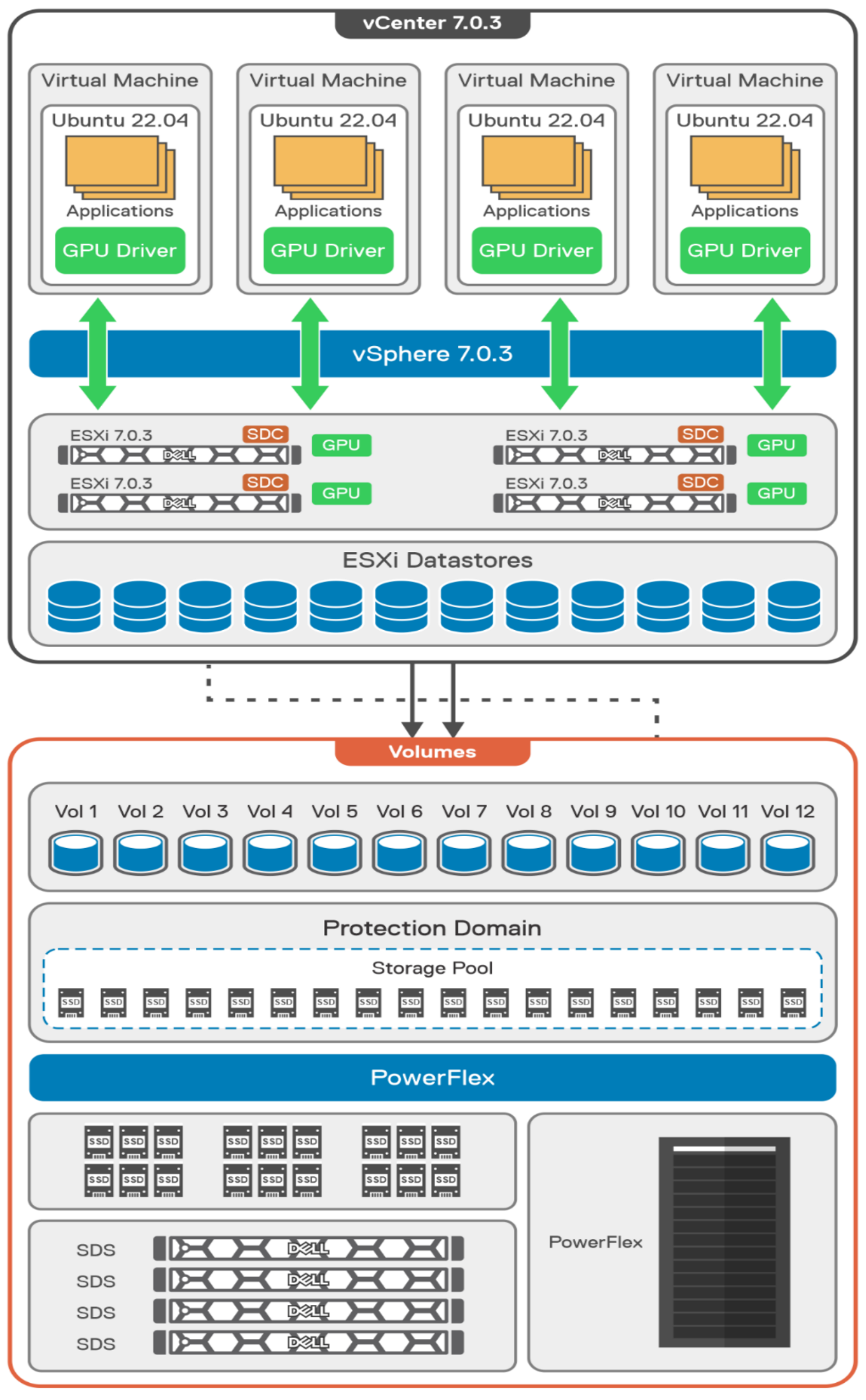
A design like this allows for independent scalability for your workloads. What I mean by this is during the training phase of a model, significant storage may be required for the training data, but once the model clears validation and goes into production, storage requirements may be drastically different. With PowerFlex you have the flexibility to deliver the storage capacity and performance you need at each stage.
This brings us to testing the environment. Again, for this paper, the engineering team validated it using ResNet-50 v1.5 using the ImageNet 1K data set. For this validation they enabled several ResNet-50 v1.5 TensorFlow features. These include Multi-GPU training with Horovod, NVIDIA DALI, and Automatic Mixed Precision (AMP). These help to enable various capabilities in the ResNet-50 v1.5 model that are present in the environment. The paper then describes how to set up and configure ResNet-50 v1.5, the features mentioned above, and details about downloading the ImageNet data.
At this stage they were able to train the ResNet-50 v1.5 deployment. The first iteration of training used the NVIDIA A100-7-40C vGPU profile. They then repeated testing with the A100-4-20C vGPU profile and the A100-3-20C vGPU profile. You might be wondering about the A100-2-10C vGPU profile and the A100-1-5C profile. Although those vGPU profiles are available, they are more suited for inferencing, so they were not tested.
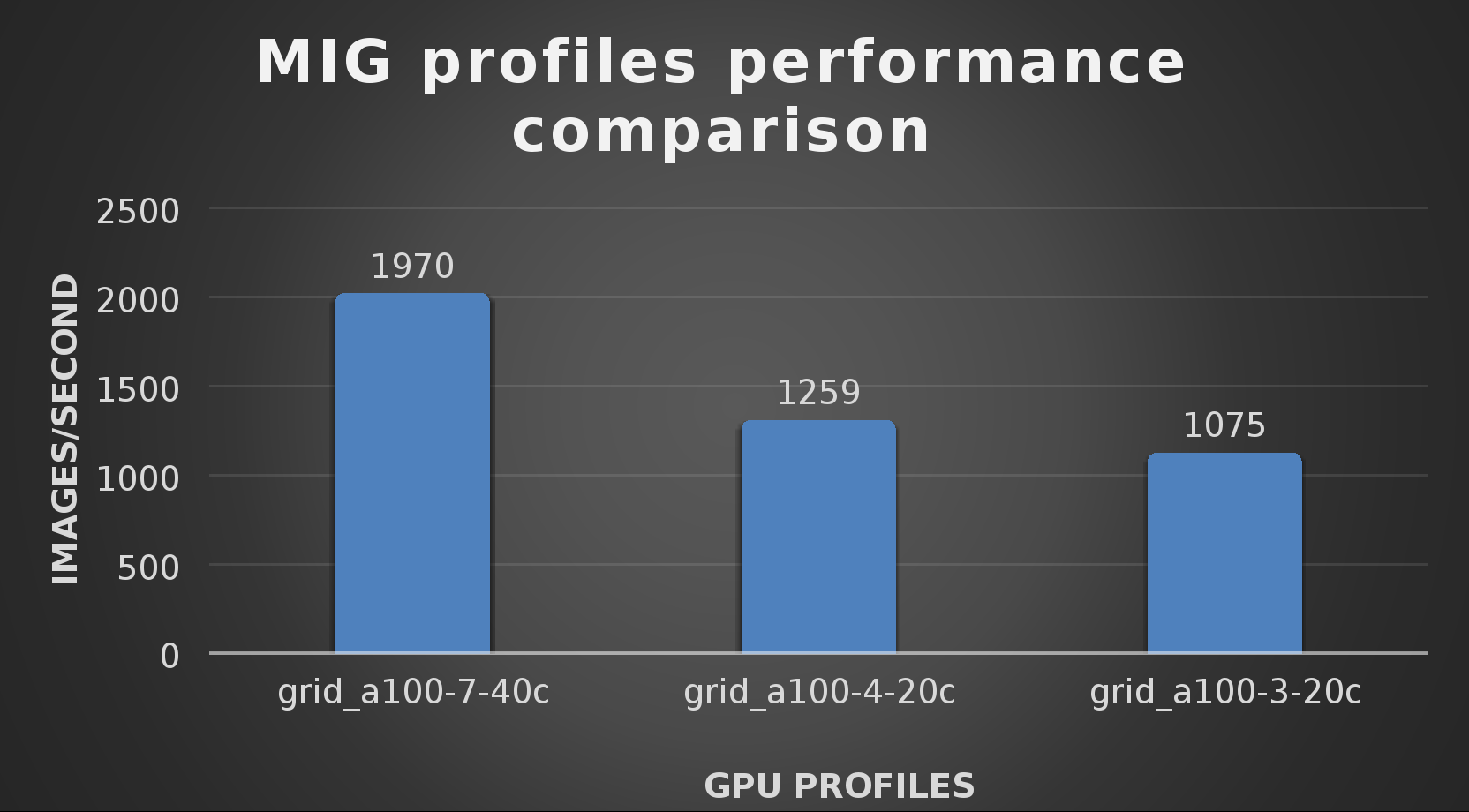
The results from validating the training workloads for each vGPU profile is shown in the following graph. The vGPUs were running near 98% capacity according to nvitop during each test. The CPU utilization was 14% and there was no bottle neck with the storage during the tests.
With the models trained, the guide then looks at how well inference runs on the MIG profiles. The following graph shows inferencing images per second of the various MIG profiles with ResNet-50 v1.5.
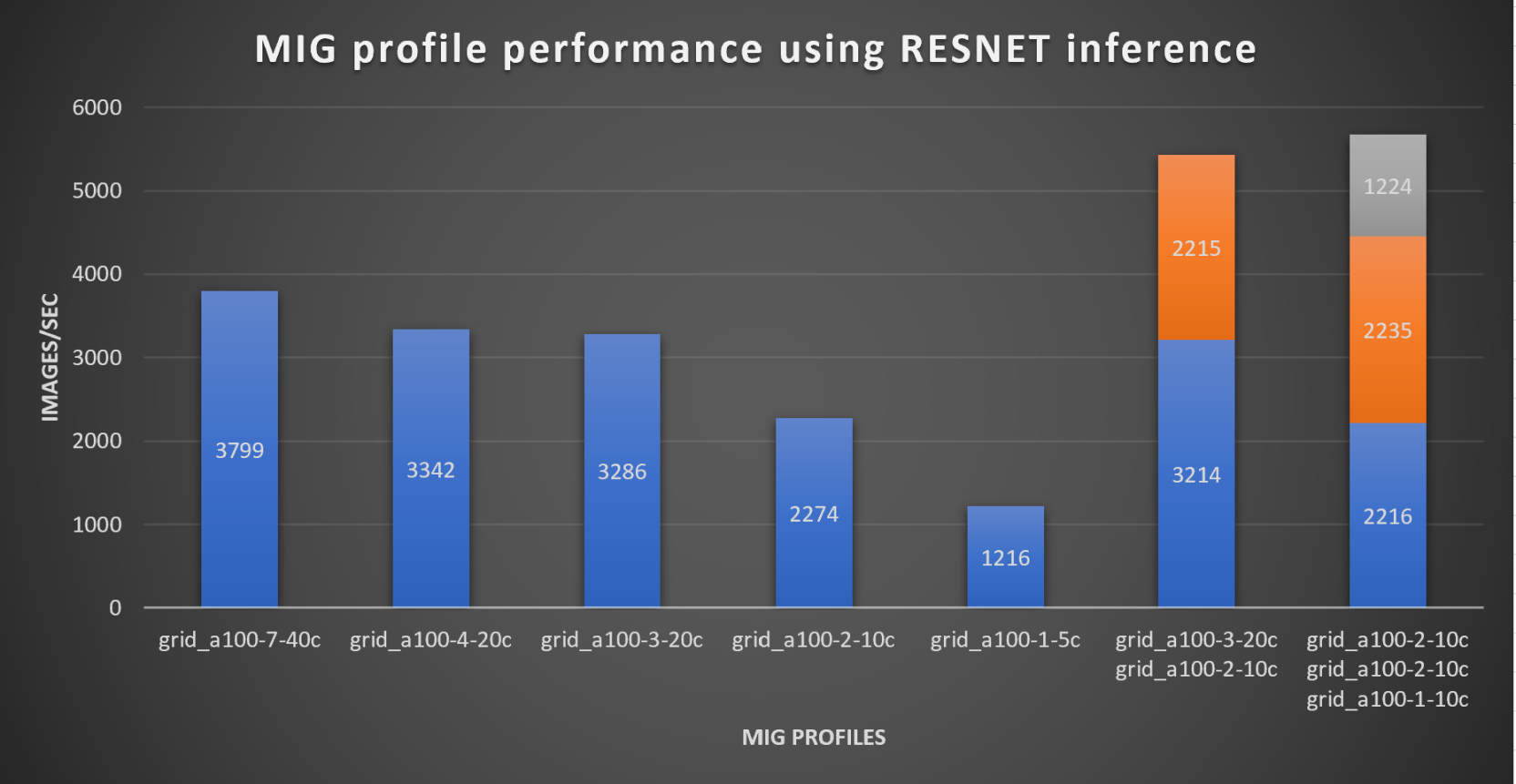
It’s worth noting that the last two columns show the inferencing running across multiple VMs, on the same ESXi host, that are leveraging MIG profiles. This also shows that GPU resources are partitioned with MIG and that resources can be precisely controlled, allowing multiple types of jobs to run on the same GPU without impacting other running jobs.
This opens the opportunity for organizations to align consumption of vGPU resources in virtual environments. Said a different way, it allows IT to provide “show back” of infrastructure usage in the organization. So if a department only needs an inferencing vGPU profile, that’s what they get, no more, no less.
It’s also worth noting that the results from the vGPU utilization were at 88% and CPU utilization was 11% during the inference testing.
These validations show that a Dell PowerFlex environment can support the foundational components of modern-day AI. It also shows the value of NVIDIA’s MIG technology to organizations of all sizes: allowing them to gain operational efficiencies in the data center and enable access to AI.
Which again answers the question of this blog, can I do that AI thing on Dell PowerFlex… Yes you can run that AI thing! If you would like to find out more about how to run your AI thing on PowerFlex, be sure to reach out to your Dell representative.
Resources
- The History of Artificial Intelligence
- ‘Godfather of AI’ leaves Google, warns of tech’s dangers
- ResNet-50: The Basics and a Quick Tutorial
- Dell Validated Design for Virtual GPU with VMware and NVIDIA on PowerFlex
- NVIDIA NGC Catalog ResNet v1.5 for PyTorch
- NVIDIA AI Enterprise
- NVIDIA A100 (PCIe) GPU
- NVIDIA Virtual GPU Software Documentation
- NVIDIA A100-7-40C vGPU profile
- NVIDIA Multi-Instance GPU (MIG)
- NVIDIA Multi-Instance GPU User Guide
- Horovod
- ImageNet
- DALI
- Automatic Mixed Precision (AMP)
- nvitop
Author: Tony Foster
Sr. Principal Technical Marketing Engineer
Twitter: | |
LinkedIn: | |
Personal Blog: | |
Location: | The Land of Oz [-6 GMT] |

Performance Evaluation of HPC Applications on a Dell PowerEdge R650-based VMware Virtualized Cluster
Wed, 08 Feb 2023 14:45:39 -0000
|Read Time: 0 minutes
Overview
High Performance Computing (HPC) solves complex computational problems by doing parallel computations on multiple computers and performing research activities through computer modeling and simulations. Traditionally, HPC is deployed on bare-metal hardware, but due to advancements in virtualization technologies, it is now possible to run HPC workloads in virtualized environments. Virtualization in HPC provides more flexibility, improves resource utilization, and enables support for multiple tenants on the same infrastructure.
However, virtualization is an additional layer in the software stack and is often construed as impacting performance. This blog explains a performance study conducted by the Dell Technologies HPC and AI Innovation Lab in partnership with VMware. The study compares bare-metal and virtualized environments on multiple HPC workloads with Intel® Xeon® Scalable third-generation processor-based systems. Both the bare-metal and virtualized environments were deployed on the Dell HPC on Demand solution.
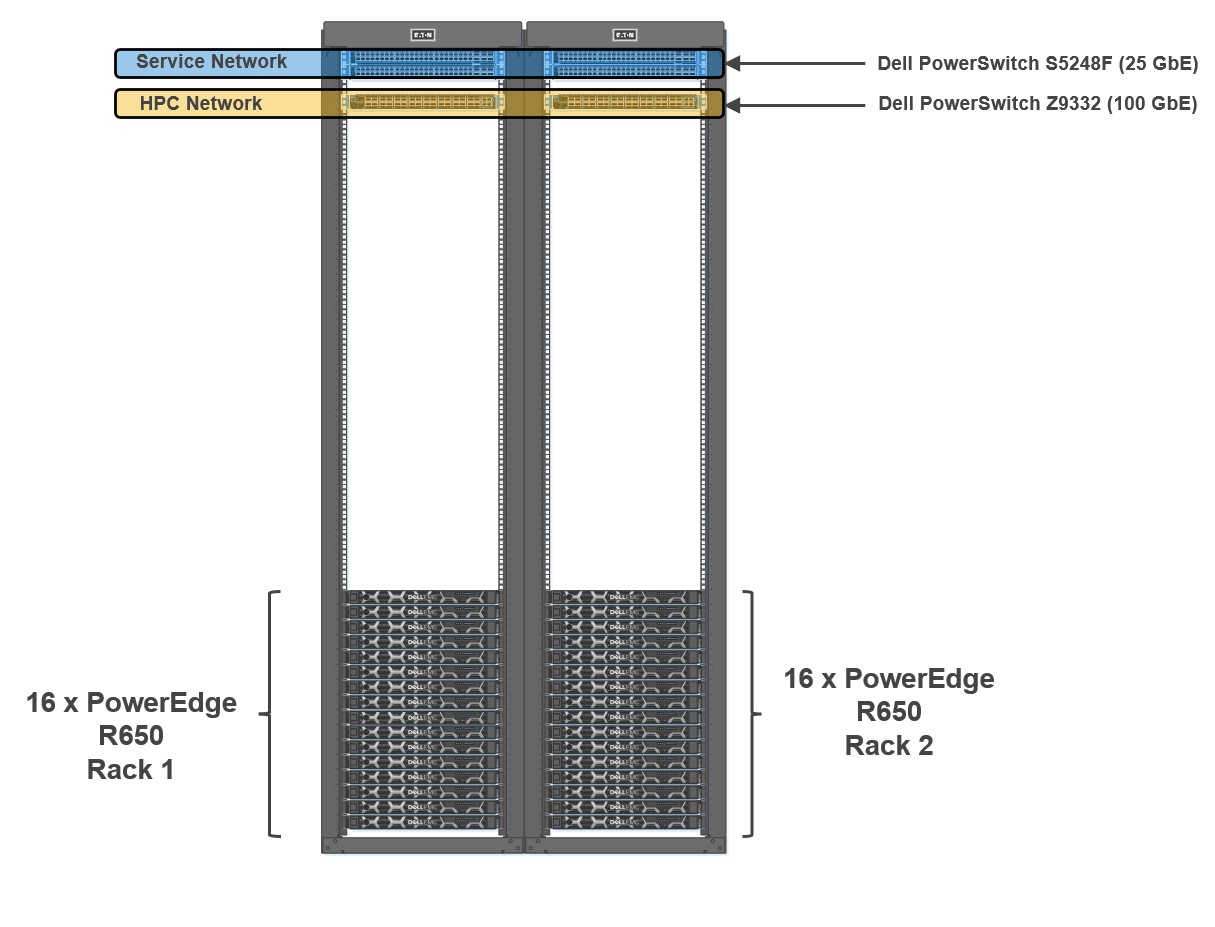
Figure 1: Cluster Architecture
To evaluate the performance of HPC applications and workloads, we built a 32-node HPC cluster using Dell PowerEdge R650 as compute nodes. Dell Power Edge R650 is a 1U dual socket server with Intel® Xeon® Scalable third-generation processors. The cluster was configured to use both bare-metal and virtual compute nodes (running VMware vSphere 7). Both bare-metal and virtualized nodes were attached to the same head node.
Figure 1 shows a representative network topology of this cluster. The cluster was connected to two separate physical networks. The compute nodes were spread across two sets of racks, and the cluster consisted of the following two networks:
- HPC Network: Dell PowerSwitch Z9332 switch connecting NVIDIA® Connect®-X6 100 GbE adapters to provide a low latency high bandwidth 100 GbE RDMA-based HPC network for the MPI-based HPC workload
- Services Network: A separate pair of Dell PowerSwitch S5248F-ON 25 GbE based top of rack (ToR) switches for hypervisor
The Virtual Machine (VM) configuration details for optimal performance settings were captured in an earlier blog. In addition to the settings noted in the previous blog, some additional BIOS tuning options such as Snoop Hold Off, SubNumaCluster (SNC) and LLC Prefetch settings were also tested. Snoop Hold Off (set to 2 K cycles), and SNC, helped performance across most of the tested applications and microbenchmarks for both the bare-metal and virtual nodes. Enabling SNC in the server BIOS and not configuring SNC correctly in the VM might result in performance degradation.
Bare-metal and virtualized HPC system configuration
Table 1 shows the system environment details used for the study.
Table 1: System configuration details for the bare-metal and virtual clusters
Machine function | Component |
Platform | PowerEdge R650 server |
Processor | Two Intel® Xeon® third Generation 6348 (28 cores @ 2.6 GHz) |
Number of cores | Bare-Metal: 56 cores Virtual: 52 vCPUs (four cores reserved for ESXi) |
Memory | Sixteen 32 GB DDR4 DIMMS @3200 MT/s Bare-Metal: All 512 GB used Virtual: 440 GB reserved for the VM
|
HPC Network NIC | 100 GbE NVIDIA Mellanox Connect-X6 |
Service Network NIC | 10/25 GbE NVIDIA Mellanox Connect-X5 |
HPC Network Switch | Dell PowerSwitch Z9332 with OS 10.5.2.3 |
Service Network Switch | Dell PowerSwitch S5248F-ON |
Operating system | Rocky Linux release 8.5 (Green Obsidian) |
Kernel | 4.18.0-348.12.2.el8_5.x86_64 |
Software – MPI | IntelMPI 2021.5.0 |
Software – Compilers | Intel OneAPI 2022.1.1 |
Software – OFED | OFED 5.4.3 (Mellanox FW 22.32.20.04) |
BIOS version | 1.5.5 (for both bare-metal and virtual nodes) |
Application and benchmark details
The following chart outlines the set of HPC applications used for this study from different domains like Computational Fluid Dynamics (CFD), Weather, and Life Sciences. Different benchmark datasets were used for each of the applications as detailed in Table 2.
Table 2: Application and benchmark dataset details
Application | Vertical Domain | Benchmark Dataset |
Weather and Environment | Conus 2.5KM, Maria 3KM | |
Manufacturing - Computational Fluid Dynamics (CFD) | ||
Life Sciences – Molecular Dynamics | ||
Molecular Dynamics | EAM metallic Solid Benchmark (1M, 3M and 8M Atoms) HECBIOSIM – 3M Atoms |
Performance results
All the application results shown here were run on both bare-metal and virtual environments using the same binary compiled with Intel Compiler and run with Intel MPI. Multiple runs were done to ensure consistency in the performance. Basic synthetic benchmarks like High Performance Linpack (HPL), Stream, and OSU MPI Benchmarks were run to ensure that the cluster was operating efficiently before running the HPC application benchmarks. For the study, all the benchmarks were run in a consistent, optimized, and stable environment across both the bare-metal and virtual compute nodes.
Intel® Xeon® Scalable third-generation processors (Ice Lake 6348) have 56 cores. Four cores were reserved for the virtualization hypervisor (ESXi) providing the remaining 52 cores to run benchmarks. All the results shown here consist of 56 core runs on bare-metal vs 52 core runs on virtual nodes.
To ensure better scaling and performance, multiple combinations of threads and MPI ranks were tried based on applications. The best results are used to show the relative speedup between both the bare-metal and virtual systems.
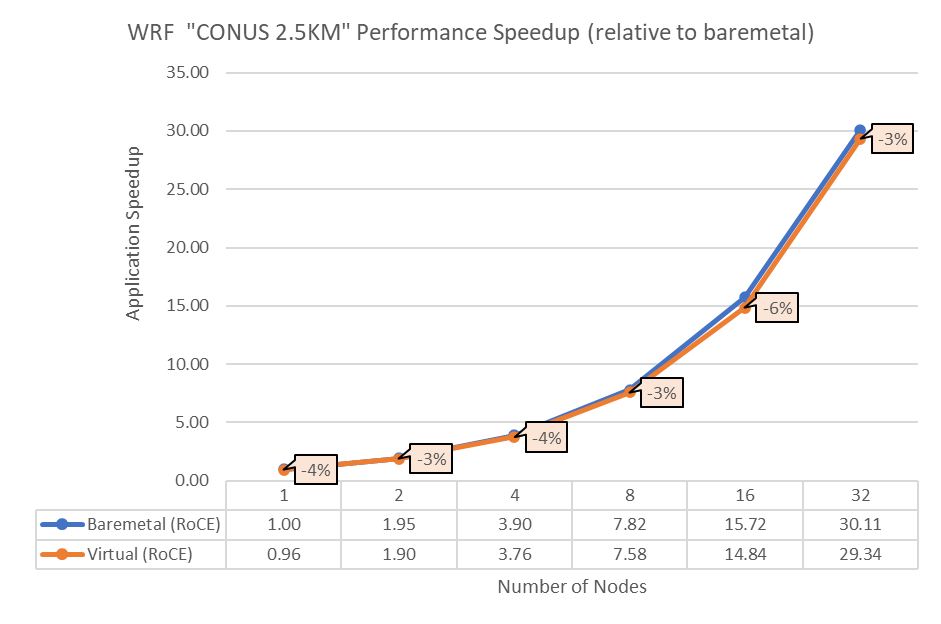
Figure 2: Performance comparison between bare-metal and virtual nodes for WRF
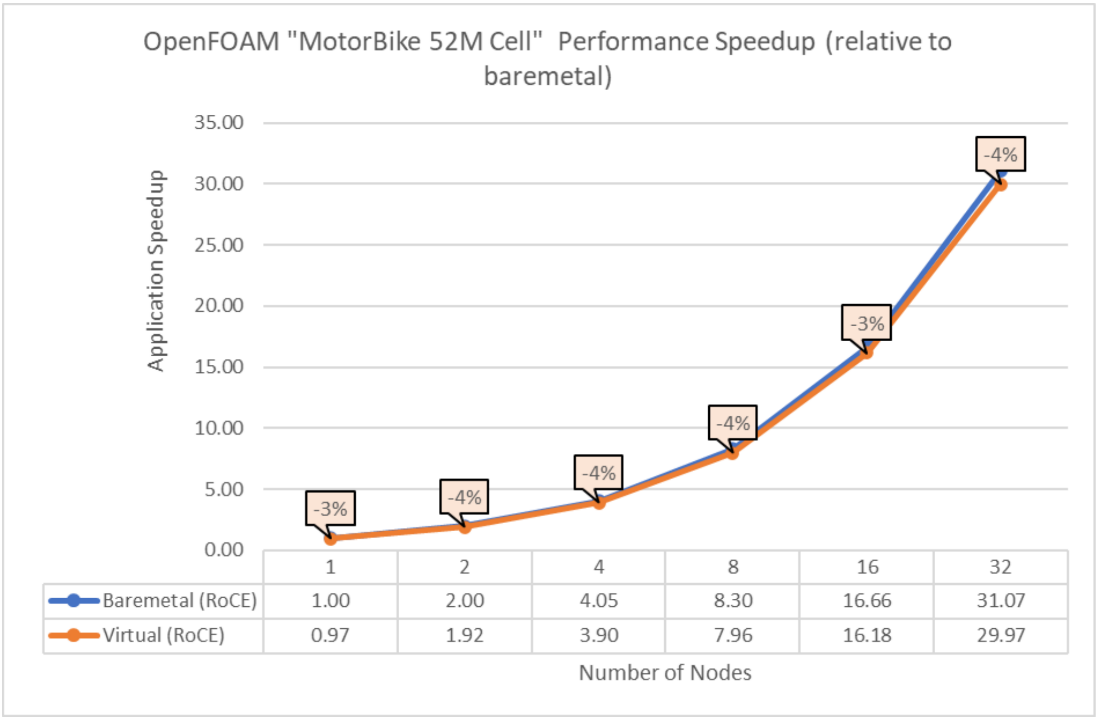
Figure 3: Performance comparison between bare-metal and virtual nodes for OpenFOAM
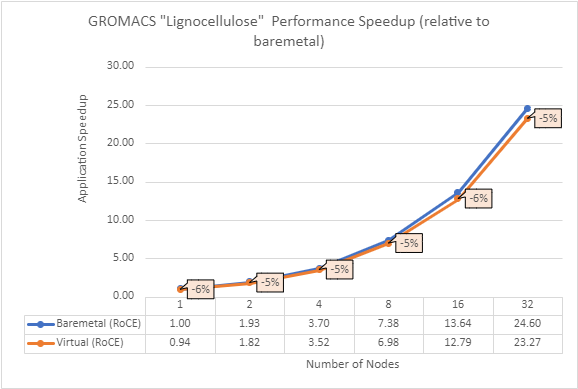
Figure 4: Performance comparison between bare-metal and virtual nodes for GROMACS
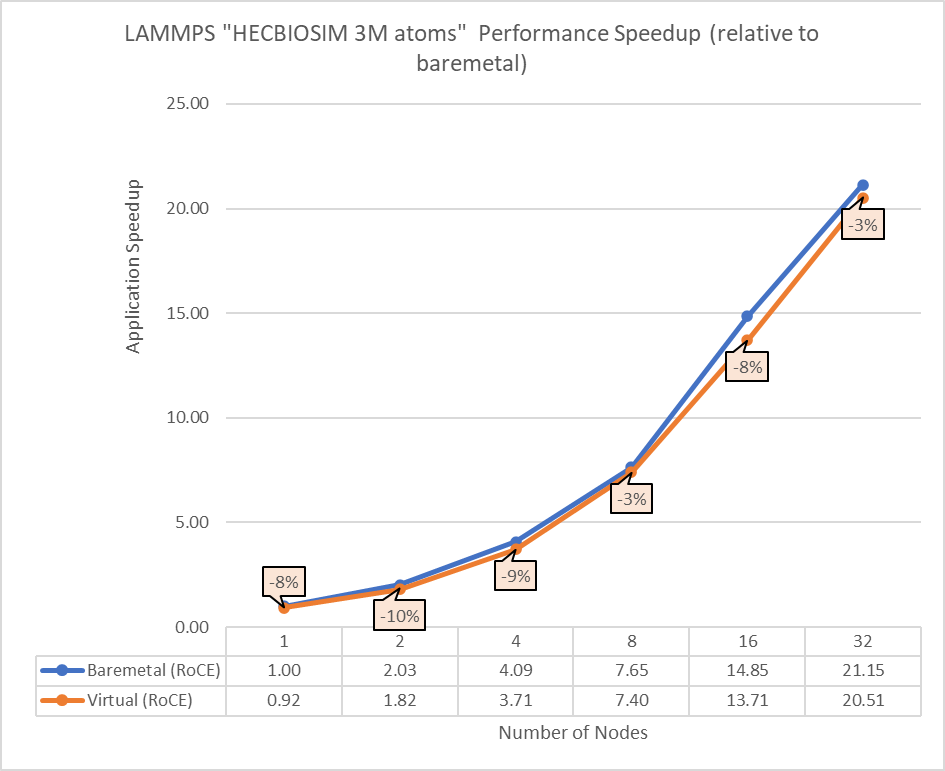
Figure 5: Performance comparison between bare-metal and virtual nodes for LAMMPS
The above results indicate that all the MPI applications running in a virtualized environment are close in performance to the bare-metal environment if proper tuning and optimizations are used. The performance delta, running from a single node up to 32 nodes, is within the 10% range for all the applications. This delta shows no major impact on scaling.
Concurrency test
In a virtualized multitenant HPC environment, the expectation is for multiple tenants to be running multiple concurrent instances of the same or different applications. To simulate this configuration, a concurrency test was conducted by making multiple copies of the same workload and running them in parallel. This test checks whether any performance degradation appears in comparison with the baseline run result. To do some meaningful concurrency tests, we expanded the virtual cluster to 48 nodes by converting 16 nodes of bare-metal to virtual. For the concurrency tests, the baseline is made with an 8-node run while no other workload was running across the 48-node virtual cluster. After that, six copies of the same workload were allowed to run simultaneously across the virtual cluster. Then the results are compared and depicted for all the applications.
The concurrency was tested in two ways. In the first test, all eight nodes running a single copy were placed in the same rack. In the second test, the nodes running a single job were spread across two racks to see if any performance difference was observed due to additional communication over the network.
Figures 6 to 13 capture the results of the concurrency test. As seen from the results there was no degradation observed in the performance.
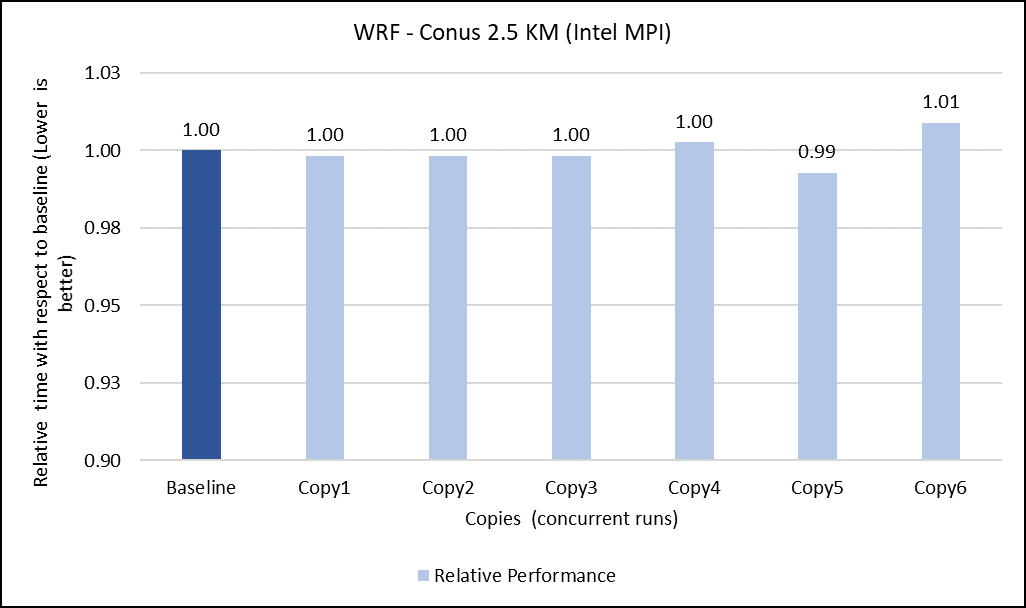
Figure 6: Concurrency Test 1 for WRF
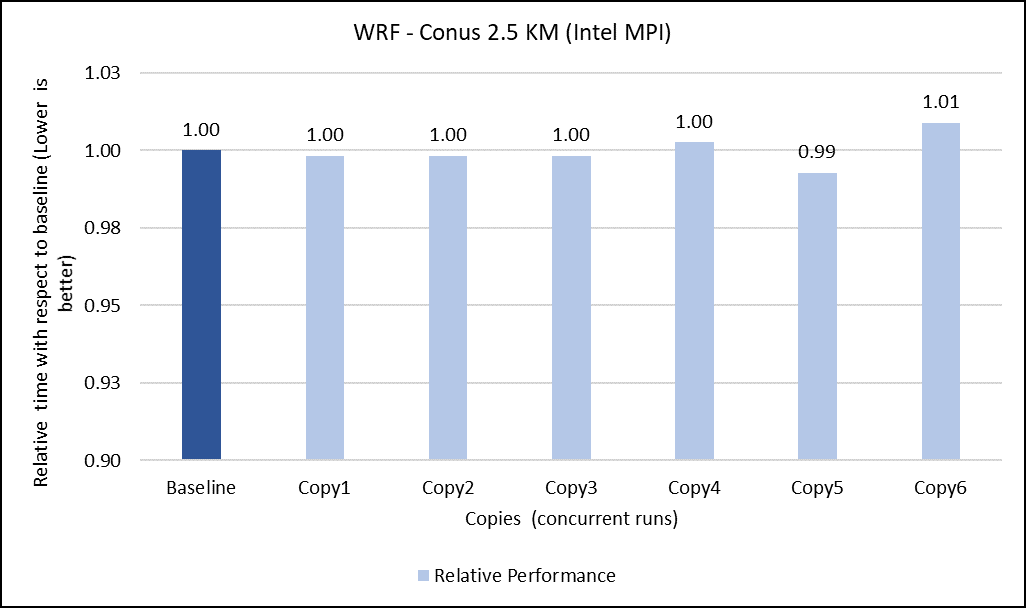
Figure 7: Concurrency Test 2 for WRF
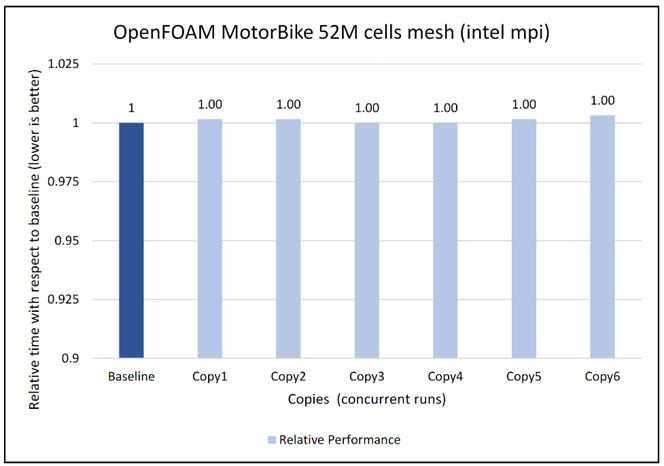
Figure 8: Concurrency Test 1 for Open FOAM
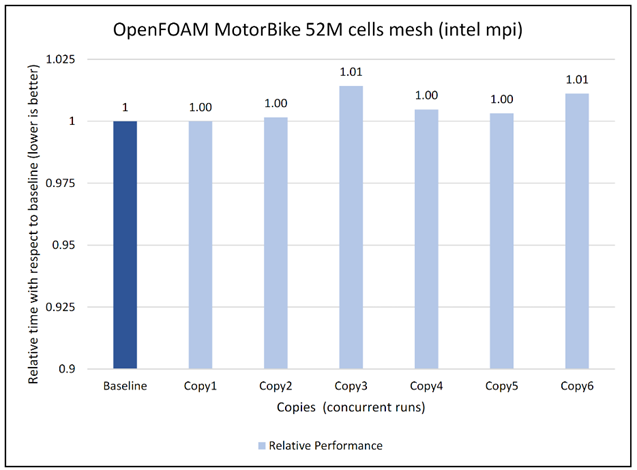
Figure 9: Concurrency Test 2 for Open FOAM
Figure 10: Concurrency Test 1 for GROMACS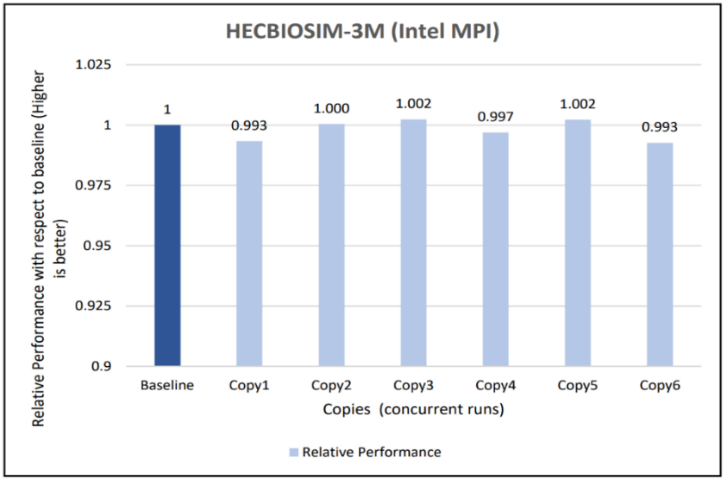
Figure 11: Concurrency Test 2 for GROMACS
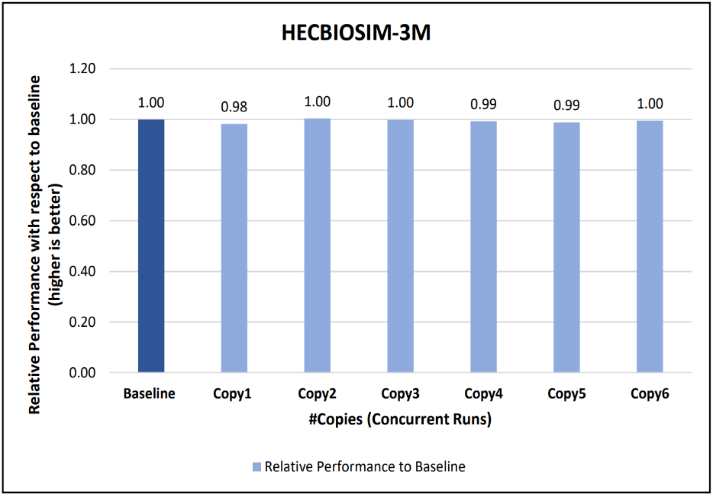
Figure 12: Concurrency Test 1 for LAMMPS 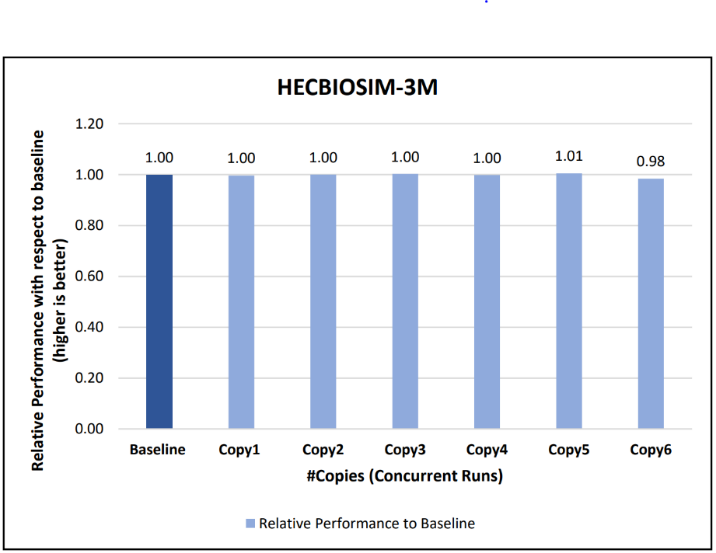
Figure 13: Concurrency Test 2 for LAMMPS
Another set of concurrency tests was conducted by running different applications (WRF, GROMACS, and Open FOAM) simultaneously in the virtual environment. In this test, two eight-node copies of each application run concurrently across the virtual cluster to determine if any performance variation occurs while running multiple parallel applications in the virtual nodes. There is no performance degradation observed in this scenario also, when compared to the individual application baseline run with no other workload running on the cluster.
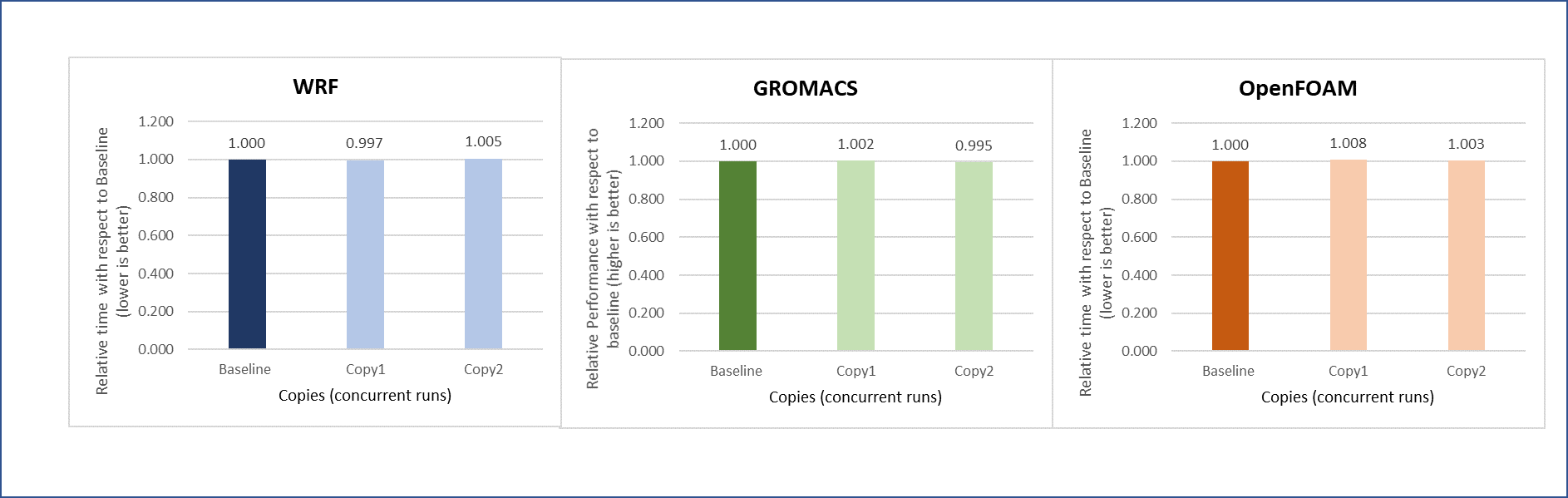
Figure 14: Concurrency test with multiple applications running in parallel
Intel Select Solution certification
In addition to the benchmark testing, this system has been certified as an Intel® Select Solution for Simulation and Modeling. Intel Select Solutions are workload-optimized configurations that Intel benchmark-tests and verifies for performance and reliability. These solutions can be deployed easily on premises and in the cloud, providing predictability and scalability.
All Intel Select Solutions are a tailored combination of Intel data center compute, memory, storage, and network technologies that deliver predictable, trusted, and compelling performance. Each solution offers assurance that the workload will work as expected, if not better. These solutions can save individual businesses from investing the resources that might otherwise be used to evaluate, select, and purchase the hardware components to gain that assurance themselves.
The Dell HPC On Demand solution is one of a select group of prevalidated, tested solutions that combine third-generation Intel® Xeon® Scalable processors and other Intel technologies into a proven architecture. These certified solutions can reduce the time and cost of building an HPC cluster, lowering hardware costs by taking advantage of a single system for both simulation and modeling workloads.
Conclusion
Running an HPC application necessitates careful consideration for achieving optimal performance. The main objective of the current study is to use appropriate tuning to bridge the performance gap between bare-metal and virtual systems. With the right settings on the tested HPC applications (see Overview), the performance difference between virtual and bare-metal nodes for the 32 node tests is less than 10%. It is therefore possible to successfully run different HPC workloads in a virtualized environment to leverage benefits of virtualization features. The concurrency testing helped to demonstrate that running multiple applications simultaneously in the virtual nodes does not degrade performance.
Resources
To learn more about our previous work on HPC virtualization on Cascade Lake, see the Performance study of a VMware vSphere 7 virtualized HPC cluster.
Acknowledgments
The authors thank Savitha Pareek from Dell Technologies, Yuankun Fu from VMware, Steven Pritchett, and Jonathan Sommers from R Systems for their contribution in the study.