




Big Solutions on Dell EMC VxRail with SQL 2019 Big Data Cluster
Mon, 17 Aug 2020 18:31:31 -0000
|Read Time: 0 minutes
The amount of data and different formats organizations must manage, ingest, and analyze has been the driving force behind Microsoft SQL 2019 Big Data Clusters (BDC). SQL Server 2019 BDC demonstrates the deployment of scalable clusters of SQL Server, Spark, and containerized HDFS (Hadoop Distributed File System) running on Kubernetes.
 We recently deployed and tested SQL Server 2019 BDC on Dell EMC VxRail hyperconverged infrastructure to demonstrate how VxRail delivers the performance, scalability, and flexibility needed to bring these multiple workloads together.
We recently deployed and tested SQL Server 2019 BDC on Dell EMC VxRail hyperconverged infrastructure to demonstrate how VxRail delivers the performance, scalability, and flexibility needed to bring these multiple workloads together.
The Dell EMC VxRail platform was selected for its ability to incorporate compute, storage, virtualization, and management in one platform offering. The key feature of the VxRail HCI is the integration of vSphere, vSAN, and VxRail HCI System Software for an efficient and reliable deployment and operations experience. The use of VxRail with SQL Server 2019 BDC makes it easy to unite relational data with big data.
The testing demonstrates the advantages of using VxRail with SQL Server 2019 BDC for analytic application development. This also demonstrates how Docker, Kubernetes, and the vSphere Container Storage Interface (CSI) driver accelerate the application development life cycle when they are used with VxRail. The lab environment for development and testing used four VxRail E560F nodes supported by the vSphere CSI driver. With this solution, developers can provision SQL Server BDC in containerized environments without the complexities of traditional methods for installing databases and provisioning storage.
Our white paper, Microsoft SQL Server 2019 Big Data Cluster on Dell EMC VxRail shows the power of implementing SQL Server 2019 BDC technologies on VxRail. Integrating SQL Server 2019 RDBMS, SQL Server BDC, MongoDB, and Oracle RDBMS helps to create a unified data analytics application. Using VxRail enhances the ability of SQL Server 2019 to scale out storage and compute clusters while embracing the virtualization techniques from VMware. This SQL Server 2019 BDC solution also benefits from the simplicity of a complete yet flexible validated Dell EMC VxRail with Kubernetes management and storage integration.
The solution demonstrates the combined value of the following technologies:
- VxRail E560F – All-flash performance
- Large tables stored on a scaled-out HDFS storage cluster that is hosted by BDC
- Smaller related data tables that are hosted on SQL Server, MongoDB, and Oracle databases
- Distributed queries that are enabled by the PolyBase capability in SQL Server 2019 to process Transact-SQL queries that access external data in SQL Server, Oracle, Teradata, and MongoDB.
- Red Hat Enterprise Linux
Big Data Cluster Services
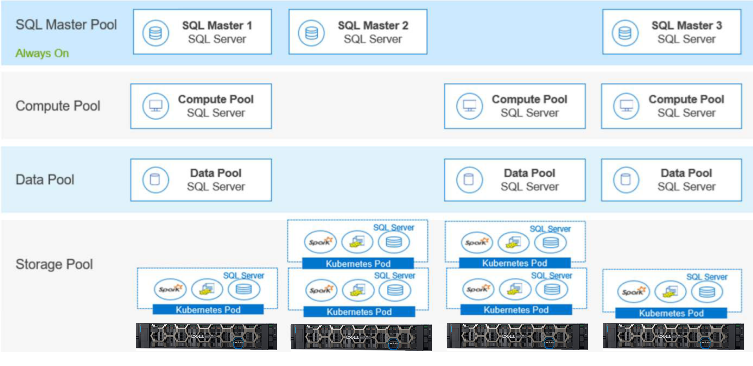
This diagram shows how the pools are built. It provides details of the benefits for Kubernetes features for container orchestration at scale, including:
- Autoscaling, replication, and recovery of containers
- Intracontainer communication, such as IP sharing
- A single entity—a pod—for creating and managing multiple containers
- A container resource usage and performance analysis agent, cAdvisor
- Network pluggable architecture
- Load balancing
- Health check service
This white paper, Microsoft SQL Server 2019 Big Data Cluster on Dell EMC VxRail, addresses big data storage, the tools for handling big data, and the details around testing with TPC-H. When we tested data virtualization with PolyBase, the queries were successful, running without error and returning the results that joined all four data sources.
Because data virtualization does not involve physically copying and moving the data (so that the data is available to business users in real-time), BDC simplifies and centralizes access to and analysis of the organization’s data sphere. It enables IT to manage the solution by consolidating big data and data virtualization on one platform with a proven set of tools.
Success starts with the right foundation:
SQL Server 2019 BDC is a compelling new way to utilize SQL Server to bring high-value relational data and high-volume big data together on a unified, scalable data platform. All of this can be deployed with VxRail, enabling enterprises to experience the power of PolyBase to virtualize their data stores, create data lakes, and create scalable data marts in a unified, secure environment without needing to implement slow and costly Extract, Transform, and Load (ETL) pipelines. This makes data-driven applications and analysis more responsive and productive. SQL Server 2019 BDC and Dell EMC VxRail provide a complete unified data platform to deliver intelligent applications that can help make any organization more successful.
Read the full paper to learn more about how Dell EMC VxRail with SQL 2019 Big Data Clusters can:
- Bring high-value relational data and high-volume big data together on a single, scalable platform.
- Incorporates intelligent features and gets insights from more of your data—including data stored beyond SQL Server in Hadoop, Oracle, Teradata, and MongoDB.
- Supports and enhances your database management and data-driven apps with advanced analytics using Hadoop and Spark.
Additional VxRail & SQL resources:
Microsoft SQL Server 2019 Big Data Cluster on Dell EMC VxRail
Microsoft SQL Server on VMware Cloud Foundation on Dell EMC VxRail
Key Benefits of Running Microsoft SQL Server on Dell EMC hyperconverged infrastructure (HCI) - Whitepaper
Key benefits of running Microsoft SQL Server on Dell EMC Hyperconverged Infrastructure (HCI) - Infographic
Architecting Microsoft SQL Server on VMware vSphere
Author: Vic Dery, Senior Principal Engineer, VxRail Technical Marketing
Related Blog Posts

Dell Technologies partners with Microsoft and Red Hat running SQL Server Big Data Clusters on OpenShift

Wed, 19 Aug 2020 22:32:11 -0000
|Read Time: 0 minutes
Introduced with Microsoft SQL Server 2019, SQL Server Big Data Clusters allow customers to deploy scalable clusters of SQL Server, Spark, and HDFS containers running on Kubernetes. Complete info on Big Data Clusters can be found in the Microsoft documentation. Many Dell Technologies customers are using Red Hat OpenShift Container Platform as their Kubernetes platform of choice and with this and many other solutions we are leading the way on OpenShift applications.
In Cumulative Update 5 (CU5) of Microsoft SQL Server 2019 Big Data Clusters (BDC), OpenShift 4.3+ is supported as a platform for Big Data Clusters. This has been a highly anticipated launch as customers not only realize the power of BDC and OpenShift but also look for the support of Dell Technologies, Microsoft, and Red Hat to run mission-critical workloads. Dell Technologies has been working with Microsoft and Red Hat to develop architecture guidance and best practices for deploying and running BDC on OpenShift.
For this effort we utilized the Databricks’ TPC-DS Spark SQL kit to populate a dataset and run a workload on the OpenShift 4.3 BDC cluster to test the various architecture components of the solution. The TPC-DS benchmark is a popular database benchmark used to evaluate performance in decision support and Big Data environments.
Based on our testing we were able to achieve linear scale of our workload while fully exercising our OpenShift cluster consisting of 12 Dell EMC R640 PowerEdge Servers and a single Dell EMC Unity 880F storage array.
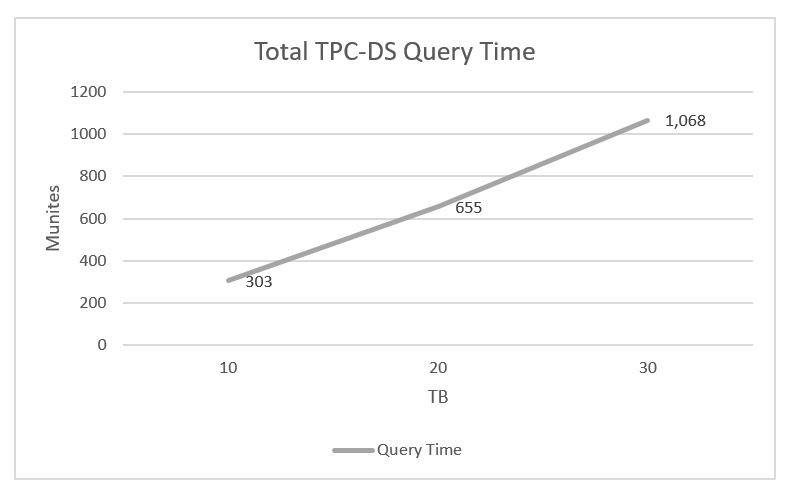
Total time of all queries run for 10,20,and 30TB datasets
As a result of this testing, a fully detailed OpenShift reference architecture and a best practices paper for running Big Data Clusters on Dell EMC Unity storage are under way and will be published soon. More information on Dell Technologies solutions for OpenShift can be found on our OpenShift Info Hub. Additional information on Dell Technologies for SQL Server can be found on our Microsoft SQL webpage.

Manage and analyze humongous amounts of data with SQL Server 2019 Big Data Cluster
Wed, 19 Aug 2020 22:07:59 -0000
|Read Time: 0 minutes
A collection of facts and statistics for reference or analysis is called data, and, in a way, the term “big data” is a large sum of data. The big data concept has been around for many years, and the volume of data is growing like never, which is why data is a hugely valued asset in this connected world. Effective big data management enables an organization to locate valuable information with ease, regardless of how large or unstructured the data is. The data is collected from various sources including system logs, social media sites, and call detail records.
The four V's associated with big data are Volume, Variety, Velocity, and Veracity:
- Volume is about the size—how much data you have.
- Variety means that the data is very different—that you have very different types of data structures.
- Velocity is about the speed of how fast the data is getting to you.
- Veracity, the final V, is a difficult one. The issue with big data is that it is very unreliable.
SQL Server Big Data Clusters make it easy to manage this complex assortment of data.
You can use SQL Server 2019 to create a secure, hybrid, machine learning architecture starting with preparing data, training a machine learning model, operationalizing your model, and using it for scoring. SQL Server Big Data Clusters make it easy to unite high-value relational data with high-volume big data.
Big Data Clusters bring together multiple instances of SQL Server with Spark and HDFS, making it much easier to unite relational and big data and use them in reports, predictive models, applications, and AI.
In addition, using PolyBase, you can connect to many different external data sources such as MongoDB, Oracle, Teradata, SAP HANA, and more. Hence, SQL Server 2019 Big Data Cluster is a scalable, performant, and maintainable SQL platform, data warehouse, data lake, and data science platform that doesn’t require compromising between cloud and on-premises. Components include:
Controller | The controller provides management and security for the cluster. It contains the control service, the configuration store, and other cluster-level services such as Kibana, Grafana, and Elastic Search. |
Compute pool | The compute pool provides computational resources to the cluster. It contains nodes running SQL Server on Linux pods. The pods in the compute pool are divided into SQL compute instances for specific processing tasks. |
Data pool | The data pool is used for data persistence and caching. The data pool consists of one or more pods running SQL Server on Linux. It is used to ingest data from SQL queries or Spark jobs. SQL Server Big Data Cluster data marts are persisted in the data pool. |
Storage pool | The storage pool consists of storage pool pods comprising SQL Server on Linux, Spark, and HDFS. All the storage nodes in a SQL Server Big Data Cluster are members of an HDFS cluster. |
Following is the reference architecture of SQL Server 2019 on Big Data Cluster:
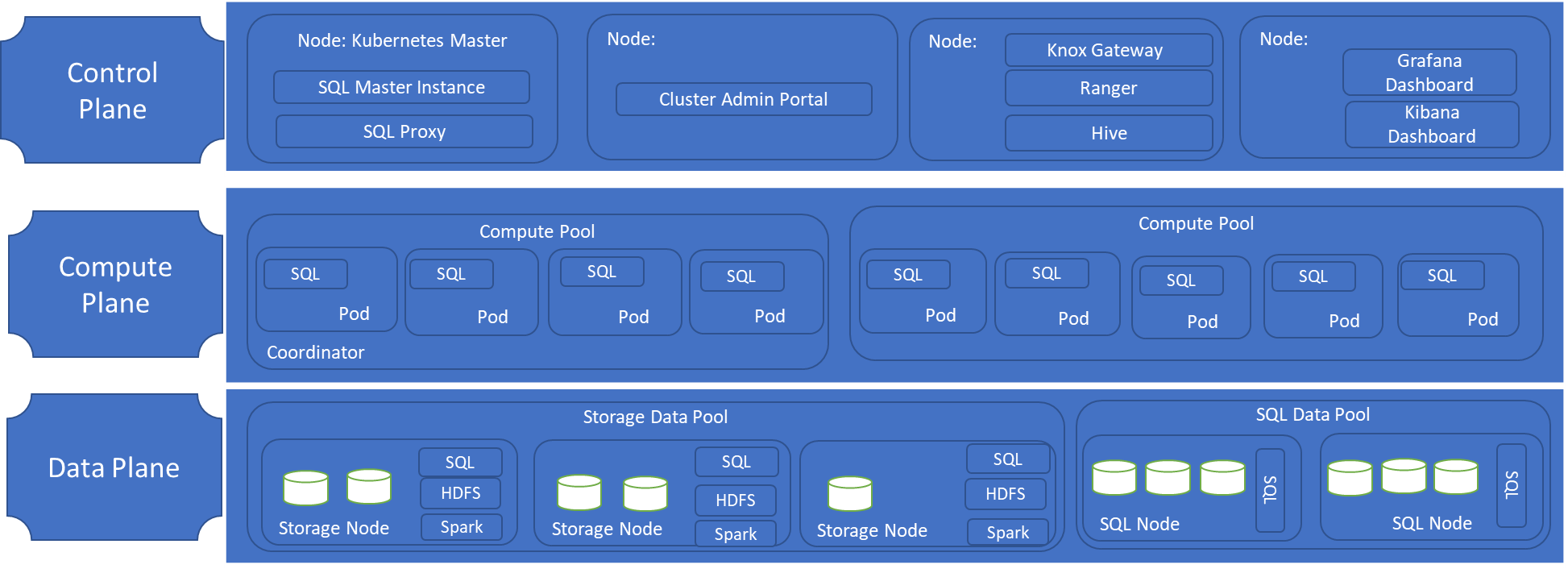
Big data analysis
Data analytics is the science of examining raw data to uncover underlying information. The primary goal is to ensure that the resulting information is of high data quality and accessible for business intelligence as well as big data analytics applications. Big Data Clusters make machine learning easier and more accurate by handling the four Vs of big data:
The impact of the Vs on analytics | How a Big Data Cluster helps | |
Volume | The greater the volume of data processed by a machine learning algorithm, the more accurate the predictions will be. | Increases the data volume available for AI by capturing data in scalable, inexpensive big data storage in HDFS and by integrating data from multiple sources using PolyBase connectors. |
Variety | The greater the variety of different sources of data, the more accurate the predictions will be. | Increases the number of varieties of data available for AI by integrating multiple data sources through the PolyBase connectors. |
Velocity | Real-time predictions depend on up to-date data flowing quickly through the data processing pipelines. | Increases the velocity of data to enable AI by using elastic compute and caching to speed up queries. |
Veracity | Accurate machine learning depends on the quality of the data going into the model training. | Increases the veracity of data available for AI by sharing data without copying or moving data, which introduces data latency and data quality issues. SQL Server and Spark can both read and write into the same data files in HDFS. |
Cluster management
Azure Data Studio is the tool that data engineers, data scientists, and DBAs use to manage databases and write queries. Cluster admins use the admin portal, which runs as a pod inside the same namespace as a whole cluster and provides information such as status of all pods and overall storage capacity.
Azure Data Studio is a cross-platform management tool for Microsoft databases. It’s like SQL Server Management Studio on top of the popular VS Code editor engine, a rich T-SQL editor with IntelliSense and plug-in support. Currently, it’s the easiest way to connect to the different SQL Server 2019 endpoints (SQL, HDFS, and Spark). To do so, you need to install Data Studio and the SQL Server 2019 extension.
If you have a Kubernetes infrastructure, you can deploy this with a single server cluster in single command and have a cluster in about 30 minutes.
If you want to install SQL Server 2019 Big Data Cluster on your on-premises Kubernetes cluster, you can find an official deployment guide for Big Data Clusters on Minikube in Microsoft docs.
Conclusion
Planning is everything and good planning will get a lot of problems out of the way, especially if you are thinking about streaming data and real-time analytics.
When it comes to technology, organizations have many different types of big data management solutions to choose from. Dell Technologies solutions for SQL Server help organizations achieve some of the key benefits of SQL Server 2019 Big Data Clusters:
- Insights to everyone: Access to management services, an admin portal, and integrated security in Azure Data Studio, which makes it easy to manage and create a unified development and administration experience for big data and SQL Server users
- Enriched data: Data using advanced analytics and artificial intelligence that’s built into the platform
- Overall data intelligence:
- Unified access to all data with unparalleled performance
- Easily and securely manage data (big/small)
- Build intelligent apps and AI with all data
- Management of any data, any size, anywhere: Simplified management and analysis through unified deployment, governance, and tooling
- Easy deployment and management of using Kubernetes-based big data solution built in to SQL Server
To make better decisions and to gain insights from data, large, small, and medium-size enterprises use big data analysis. For information about how the SQL solutions team at Dell help customers store, analyze, and protect data with Microsoft SQL Server 2019 on Big Data Cluster technologies, see the following links:
https://www.delltechnologies.com/en-us/big-data/solutions.htm#dropdown0=0
https://infohub.delltechnologies.com/t/sql-server/