




Azure Stack HCI Stretch Clustering: because automatic disaster recovery matters
If history has taught us anything, it’s that disasters are always around the corner and tend to appear in any shape or form when they’re least expected.
To overcome these circumstances, we need the appropriate tools and technologies that can guarantee resuming operations back to normal in a secure, automatic, and timely manner.
Traditional disaster recovery (DR) processes are often complex and require a significant infrastructure investment. They are also labor intensive and prone to human error.
Since December 2020, the situation has changed. Thanks to the new release of Microsoft Azure Stack HCI, version 20H2, we can leverage the new Azure Stack HCI stretched cluster feature on Dell EMC Integrated System for Microsoft Azure Stack HCI (Azure Stack HCI).
The integrated system is based on our flexible AX nodes family as the foundation, and combines Dell Technologies full stack life cycle management with the Microsoft Azure Stack HCI operating system.
It is important to note that this technology is only available for the integrated system offering under the certified Azure Stack HCI catalog.
Azure Stack HCI stretch clustering provides an easy and automatic solution (no human interaction if desired) that assures transparent failovers of disaster-impacted production workloads to a safe secondary site.
It can also be leveraged to perform planned operations (such as entire site migration, or disaster avoidance) that, until now, required labor intensive and error prone human effort for execution.
Stretch clustering is one type of Storage Replica configuration. It allows customers to split a single cluster between two locations—rooms, buildings, cities, or regions. It provides synchronous or asynchronous replication of Storage Spaces Direct volumes to provide automatic VM failover if a site disaster occurs.
There are two different topologies:
- Active-Passive: All the applications and workloads run on the primary (preferred) site while the infrastructure at the secondary site remains idle until a failover occurs.
- Active-Active: There are active applications in both sites at any given time and replication occurs bidirectionally from either site. This setup tends to be a more efficient use of an organization’s investment in infrastructure because resources in both sites are being used.
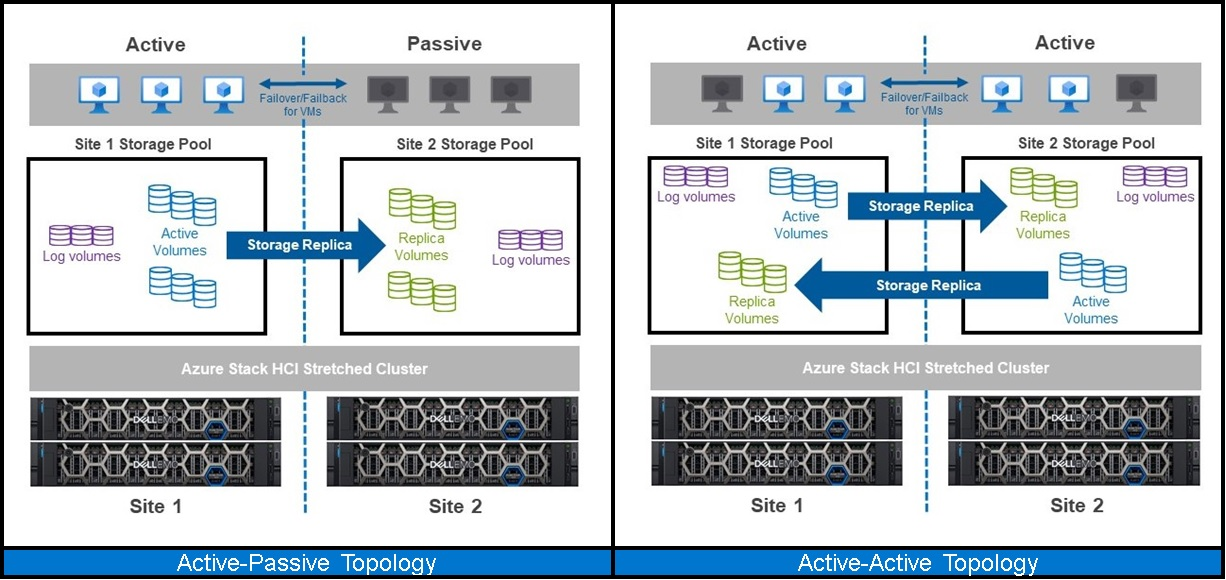
Azure Stack HCI stretch clustering topologies: Active-Passive and Active-Active
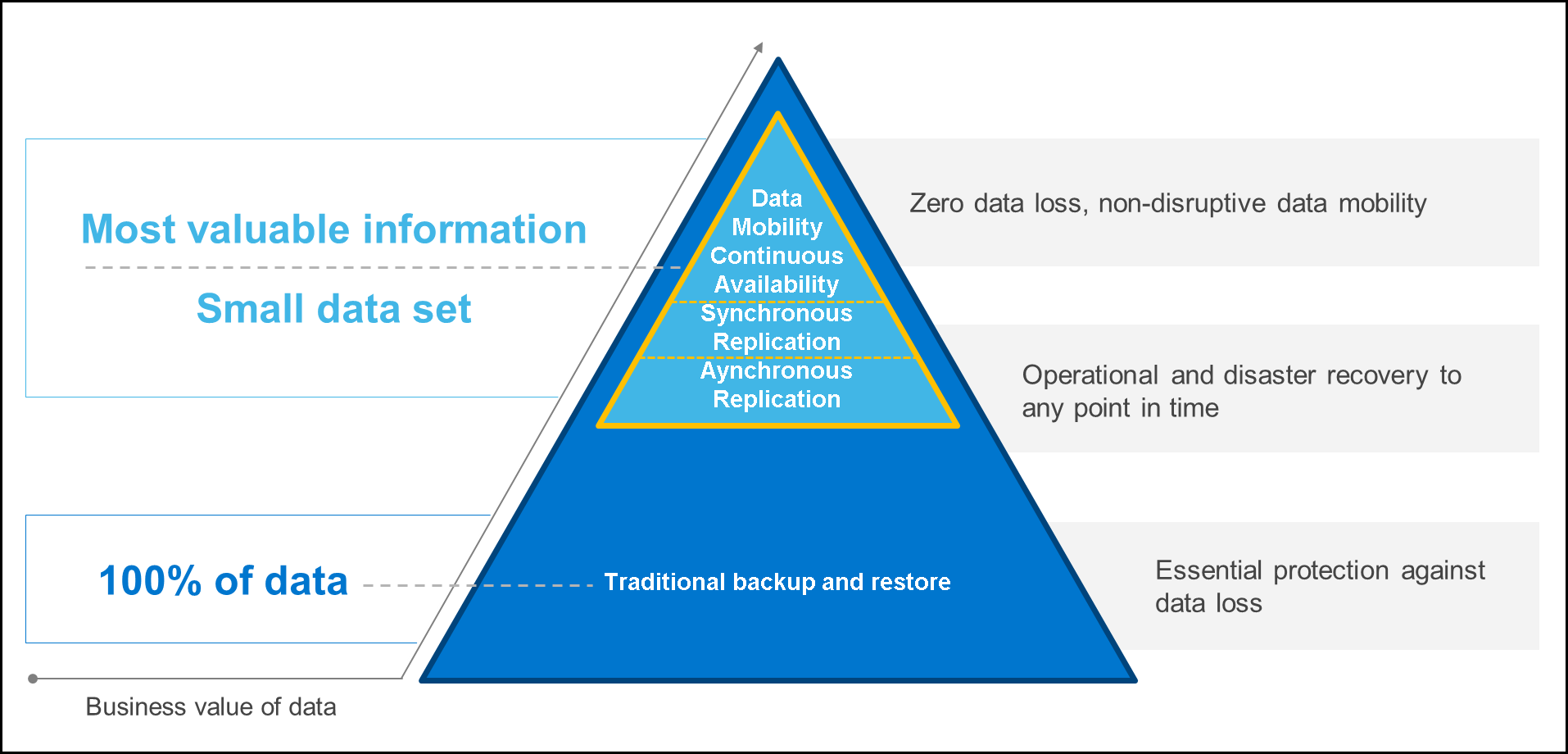
To be truly cost-effective, the best data protection strategies incorporate a combination of different technologies (deduplicated backup, archive, data replication, business continuity, and workload mobility) to deliver the right level of data protection for each business application.
The following diagram highlights the fact that just a reduced data set holds the most valuable information. This is the sweet spot for stretch clustering.
For a real-life experience, our Dell Technologies experts put Azure Stack HCI stretched clustering to the test in the following lab setup:
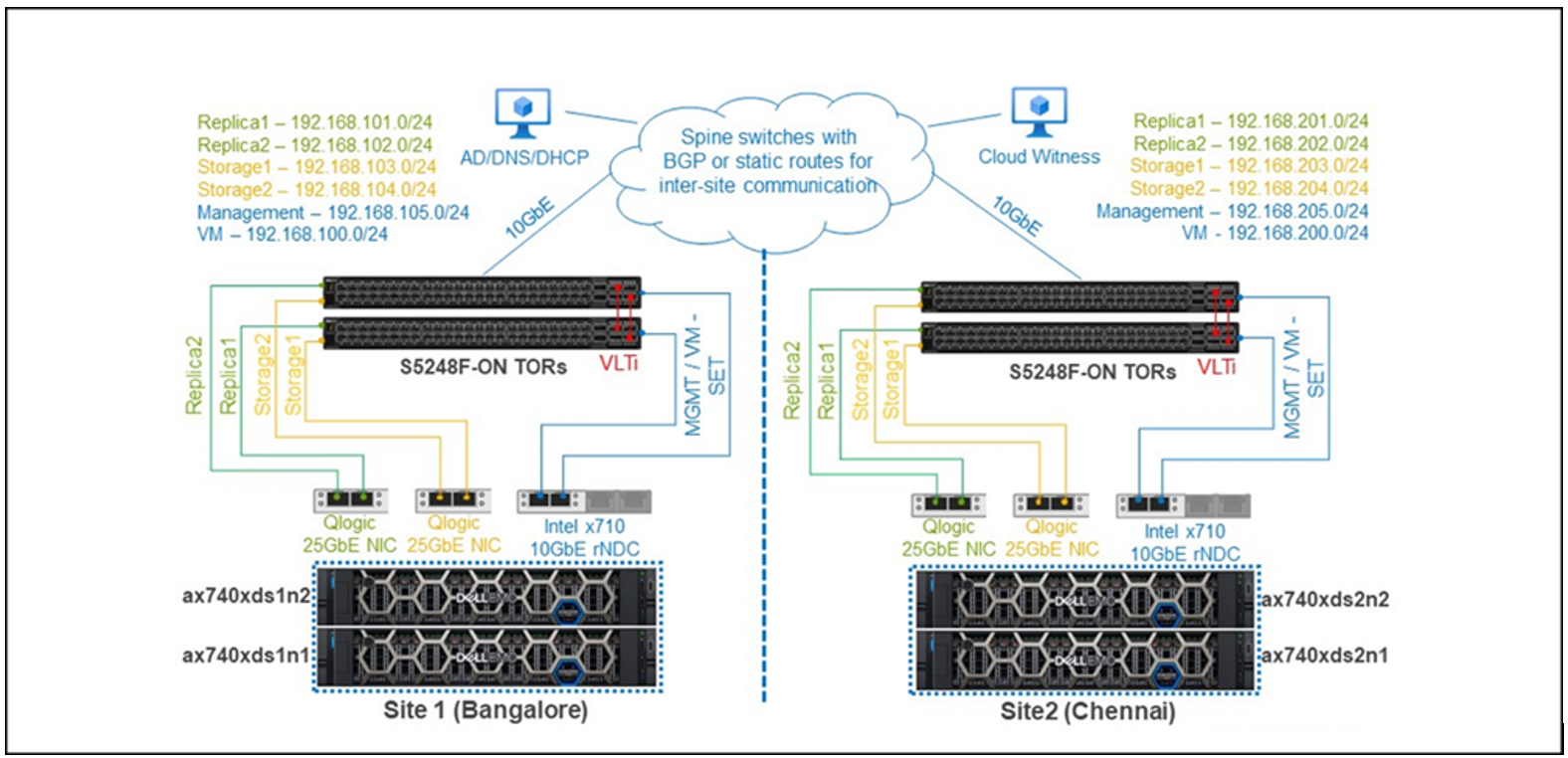
Test lab cluster network topology
Note these key considerations regarding the lab network architecture:
- The Storage Replica, management, and VM networks in each site were unique Layer 3 subnets. In Active Directory, we configured two sites—Bangalore (Site 1) and Chennai (Site 2)—based on these IP subnets so that the correct sites appeared in Failover Cluster Manager on configuration of the stretched cluster. No additional manual configuration of the cluster fault domains was required.
- Average latency between the two sites was less than 5 milliseconds, required for synchronous replication.
- Cluster nodes could reach a file share witness within the 200-millisecond maximum roundtrip latency requirement.
- The subnets in both sites could reach Active Directory, DNS, and DHCP servers.
- Software-defined networking (SDN) on a multisite cluster is not currently supported and was not used for this testing.
For all the details, see this white paper: Adding Flexibility to DR Plans with Stretch Clustering for Azure Stack HCI.
In this blog though, I only want to focus on summarizing the results we obtained in our labs for the following four scenarios:
- Scenario 1: Unplanned node failure
- Scenario 2: Unplanned site failure
- Scenario 3: Planned failover
- Scenario 4: Life cycle management
Scenario | Event | Simulated failure or maintenance event | Stretched Cluster expected response | Stretched Cluster actual response |
1 | Unplanned node failure | Node 1 in Site 1 power-down | Impacted VMs should failover to another local node | In around 5 minutes, all 10 VMs in Node 1 Site 1 fully restarted in Node 2 Site 1.
This is expected behavior since Site 1 has been configured as preferred site; otherwise, the active volume could have been moved to Site 2, and the VMs would have been restarted on a cluster node in Site 2. |
2 | Outage in Site 1 | Simultaneous power-down of Nodes 1 and 2 in site 1 | Impacted VMs should failover to nodes on the secondary site | In 25 minutes, all VMs were restarted, and the included web application was fully responsive.
The volumes owned by the nodes in Site 2 remained online throughout this failure scenario.
The replica volumes remained offline until Site 1 was restored to full health. Once Site 1 was back online, synchronous replication began again from the source volumes in Site 2 to their destination replica partners in Site 1. |
3 | Planned failover | Switch Direction operation on a volume from Windows Admin Center | Selected VMs and workloads should transparently move to secondary site | Within 0 to 3 mins, the application hosted by the affected VMs was reachable without service interruption (time depends on whether IP reassignment is required).
First, the owner node for the volumes changed to Node 2 in Site 2, and owner node for the replica volumes changed to Node 2 in Site 1. No service interruption. At this time, the test VM was running in Site 1, but its virtual disk that resided on the volume was running in Site 2. Performance problems can result because I/O is traversing the replication links across sites. After approximately 10 minutes, a Live Migration of the test VM would occur automatically (if not manually initiated earlier) so that the VM would be on the same node as its virtual disk. |
4 | Lifecycle management | Update all nodes in the cluster by using Single-click Full Stack Cluster Aware Updating (CAU) in Windows Admin Center | Stretched cluster and CAU should work seamlessly together to provide full stack cluster update without service interruption and local only workload mobility for the Live Migrated VMs | The total process of applying the operating system and firmware updates to the stretched cluster took approximately 3 hours, and the process had no application impact.
Each node was drained, and its VMs were live migrated to the other node in the same site. The intersite links between Site 1 and Site 2 were never used during update operations. In addition, the process required only a single reboot per node. This behavior was consistent throughout the update of all the nodes in the stretched cluster. |
To sum up, Azure Stack HCI Stretch Clustering has been shown to work as expected under difficult circumstances. It can easily be leveraged to cover a wide range of data protection scenarios, such as:
- restoring your organization's IT within minutes after an unplanned event
- transparently moving running workloads between sites to avoid incoming disasters or other planned operations
- automatically failing over VMs and workloads of individual failed nodes
This technology may make the difference for businesses to automatically stand up after disaster strikes, a total game changer in the automatic disaster recovery landscape.
Thank you for your time reading this blog and don’t forget to check out the full white paper!!!
Related Blog Posts

Dell Hybrid Management: Azure Policies for HCI Compliance and Remediation
Mon, 30 May 2022 17:05:47 -0000
|Read Time: 0 minutes
Dell Hybrid Management: Azure Policies for HCI Compliance and Remediation
Companies that take an “Azure hybrid first” strategy are making a wise and future-proof decision by consolidating the advantages of both worlds—public and private—into a single entity.
Sounds like the perfect plan, but a key consideration for these environments to work together seamlessly is true hybrid configuration consistency.
A major challenge in the past was having the same level of configuration rules concurrently in Azure and on-premises. This required different tools and a lot of costly manual interventions (subject to human error) that resulted, usually, in potential risks caused by configuration drift.
But those days are over.
We are happy to introduce Dell HCI Configuration Profile (HCP) Policies for Azure, a revolutionary and crucial differentiator for Azure hybrid configuration compliance.
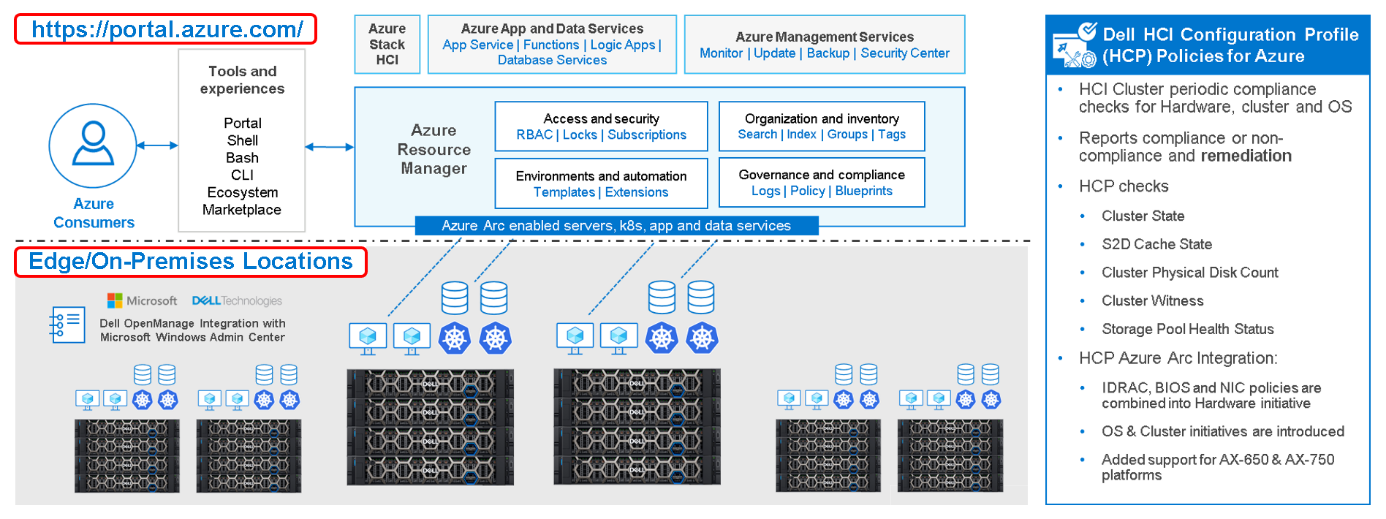
Figure 1: Dell Hybrid Management with Windows Admin Center (local) and Azure/Azure Arc (public)
So, what is it? How does it work? What value does it provide?
Dell HCP Policies for Azure is our latest development for Dell OpenManage Integration with Windows Admin Center (OMIMSWAC). With it, we can now integrate Dell HCP policy definitions into Azure Policy. Dell HCP is the specification that captures the best practices and recommended configurations for Azure Stack HCI and Windows-based HCI solutions from Dell to achieve better resiliency and performance with Dell HCI solutions.
The HCP Policies feature functions at the cluster level and is supported for clusters that are running Azure Stack HCI OS (21H2) and pre-enabled for Windows Server 2022 clusters.
IT admins can manage Azure Stack HCI environments through two different approaches:
- At-scale through the Azure portal using the Azure Arc portfolio of technologies
- Locally on-premises using Windows Admin Center
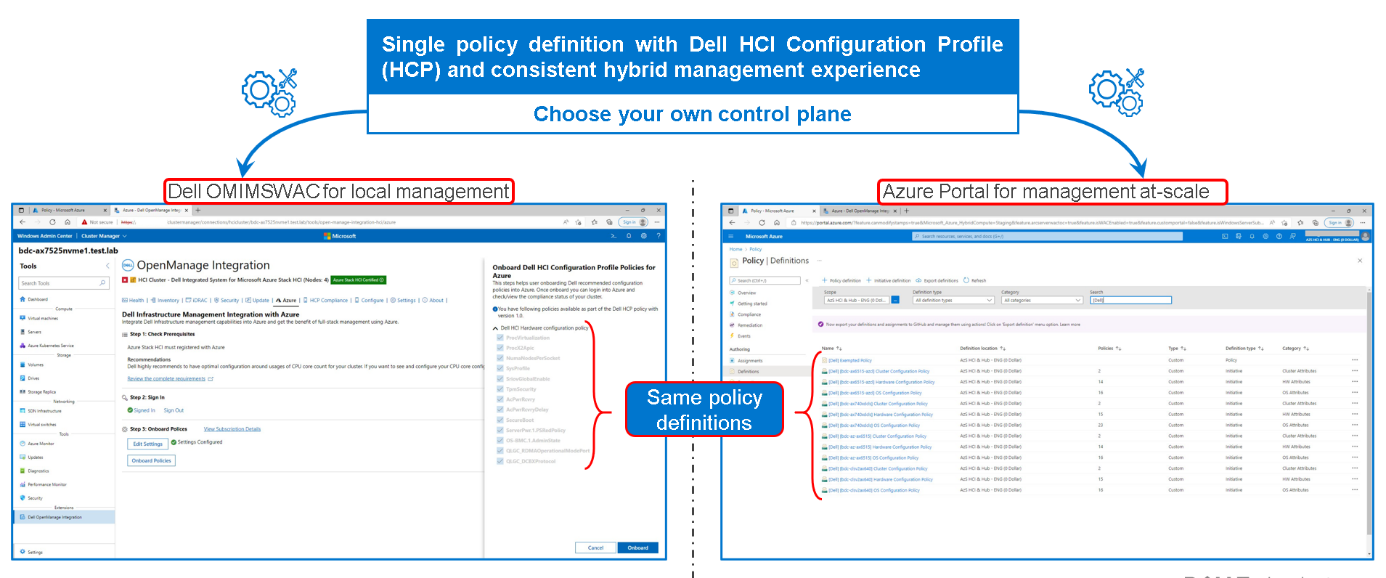
Figure 2: Dell HCP Policies for Azure - onboarding Dell HCI Configuration Profile
By using a single Dell HCP policy definition, both options provide a seamless and consistent management experience.
Running Check Compliance automatically compares the recommended rules packaged together in the Dell HCP policy definitions with the settings on the running integrated system. These rules include configurations that address the hardware, cluster symmetry, cluster operations, and security.

Figure 3: Dell HCP Policies for Azure - HCP policy compliance
Dell HCP Policy Summary provides the compliance status of four policy categories:
- Dell Infrastructure Lock Policy - Indicates enhanced security compliance to protect against unintentional changes to infrastructure
- Dell Hardware Configuration Policy - Indicates compliance with Dell recommended BIOS, iDRAC, firmware, and driver settings that improve cluster resiliency and performance
- Dell Hardware Symmetry Policy - Indicates compliance with integrated-system validated components on the support matrix and best practices recommended by Dell and Microsoft
- Dell OS Configuration Policy - Indicates compliance with Dell recommended operating system and cluster configurations
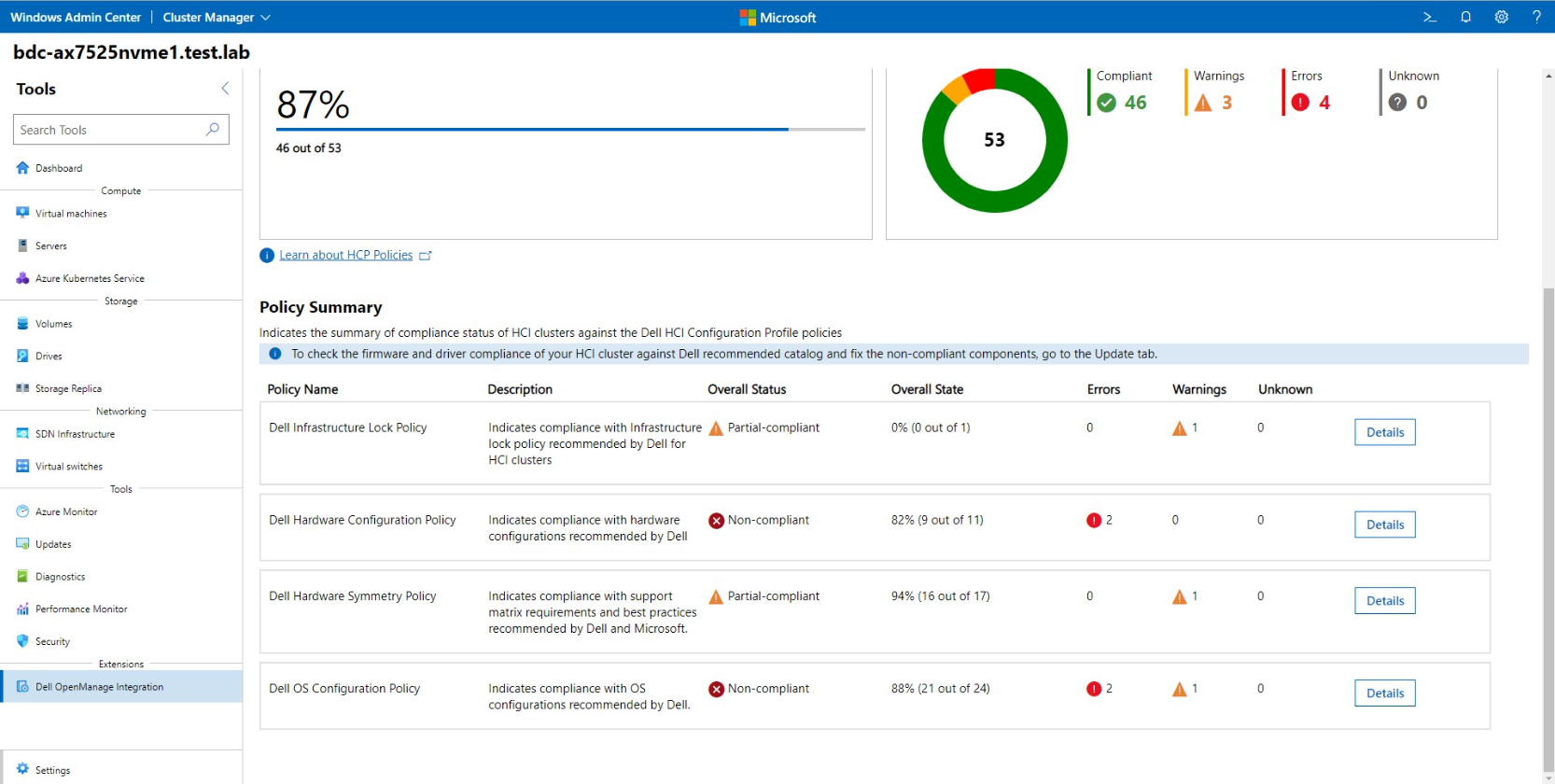
Figure 4: Dell HCP Policies for Azure - HCP Policy Summary
To re-align non-compliant policies with the best practices validated by Dell Engineering, our Dell HCP policy remediation integration with WAC (unique at the moment) helps to fix any non-compliant errors. Simply click “Fix Compliance.”

Figure 5: Dell HCP Policies for Azure - HCP policy remediation
Some fixes may require manual intervention; others can be corrected in a fully automated manner using the Cluster-Aware Updating framework.
Conclusion
The “Azure hybrid first” strategy is real today. You can use Dell HCP Policies for Azure, which provides a single-policy definition with Dell HCI Configuration Profile and a consistent hybrid management experience, whether you use Dell OMIMSWAC for local management or Azure Portal for management at-scale.
With Dell HCP Policies for Azure, policy compliance and remediation are fully covered for Azure and Azure Stack HCI hybrid environments.
You can see Dell HCP Policies for Azure in action at the interactive Dell Demo Center.
Thanks for reading!
Author: Ignacio Borrero, Dell Senior Principal Engineer CI & HCI, Technical Marketing
Twitter: @virtualpeli

Azure Stack HCI automated and consistent protection through Secured-core and Infrastructure lock
Mon, 21 Feb 2022 17:45:58 -0000
|Read Time: 0 minutes
Global damages related to cybercrime were predicted to reach USD 6 trillion in 2021! This staggering number highlights the very real security threat faced not only by big companies, but also for small and medium businesses across all industries.
Cyber attacks are becoming more sophisticated every day and the attack surface is constantly increasing, now even including the firmware and BIOS on servers.

Figure 1: Cybercrime figures for 2021
However, this isn’t all bad news, as there are now two new technologies (and some secret sauce) that we can leverage to proactively defend against unauthorized access and attacks to our Azure Stack HCI environments, namely:
- Secured-core Server
- Infrastructure lock
Let’s briefly discuss each of them.
Secured-core is a set of Microsoft security features that leverage the latest security advances in Intel and AMD hardware. It is based on the following three pillars:
- Hardware root-of-trust: requires TPM 2.0 v3, verifies for validly signed firmware at boot times to prevent tamper attacks
- Firmware protection: uses Dynamic Root of Trust of Measurement (DRTM) technology to isolate the firmware and limit the impact of vulnerabilities
- Virtualization-based security (VBS): in conjunction with hypervisor-based code integrity (HVCI), VBS provides granular isolation of privileged parts of the OS (like the kernel) to prevent attacks and exfiltration of data
Infrastructure lock provides robust protection against unauthorized access to resources and data by preventing unintended changes to both hardware configuration and firmware updates.
When the infrastructure is locked, any attempt to change the system configuration is blocked and an error message is displayed.
Now that we understand what these technologies provide, one might have a few more questions, such as:
- How do I install these technologies?
- Is it easy to deploy and configure?
- Does it require a lot of human manual (and perhaps error prone) interaction?
In short, deploying these technologies is not an easy task unless you have the right set of tools in place.
This is when you’ll need the “secret sauce”— which is the Dell OpenManage Integration with Microsoft Windows Admin Center (OMIMSWAC) on top of our certified Dell Cyber-resilient Architecture, as illustrated in the following figure:
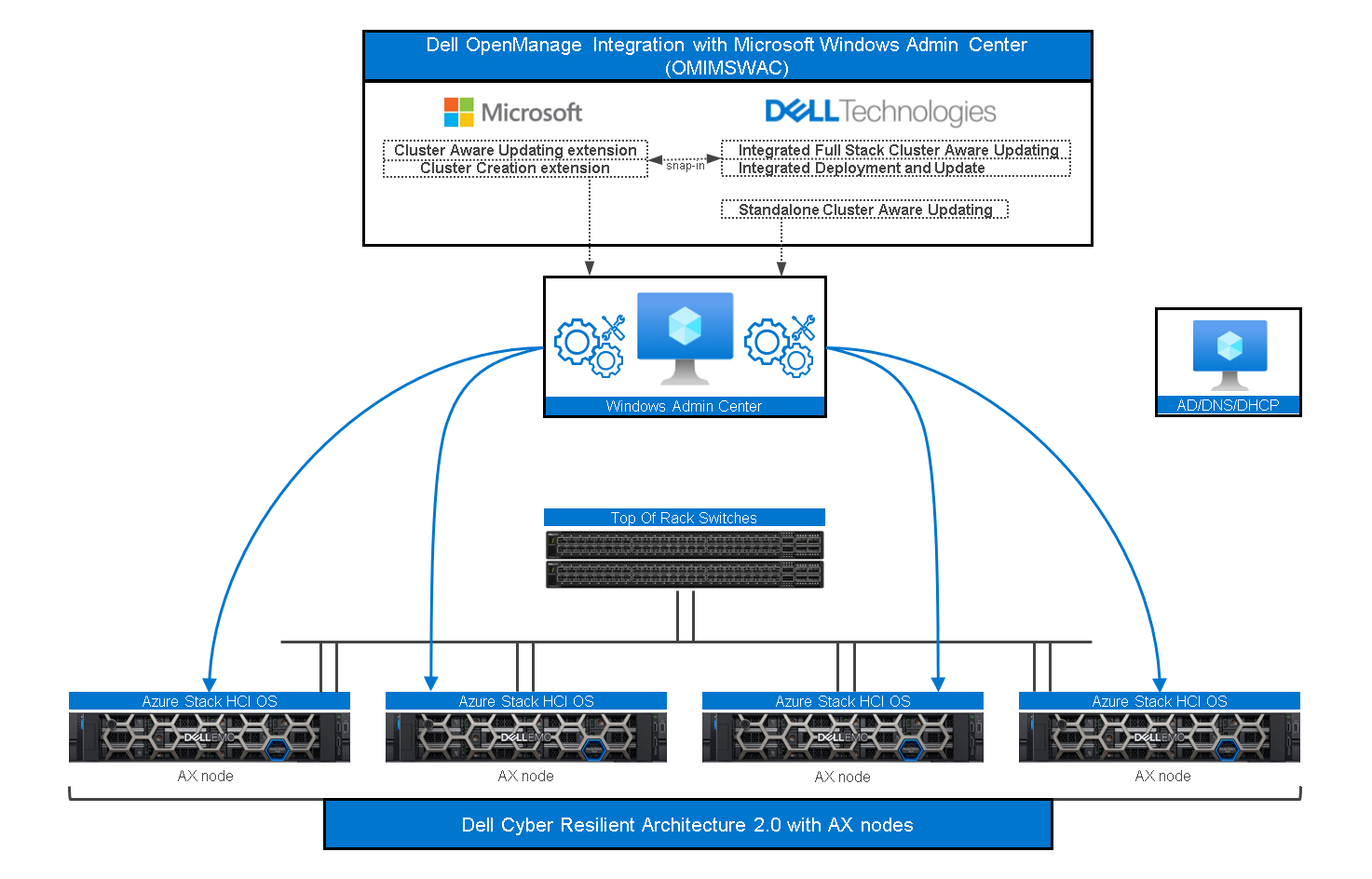
Figure 2: OMIMSWAC and Dell Cyber-resilient Architecture with AX Nodes
As a quick reminder, Windows Admin Center (WAC) is Microsoft’s single pane of glass for all Windows management related tasks.
Dell OMIMSWAC extensions make WAC even better by providing additional controls and management possibilities for certain features, such as Secured-core and Infrastructure lock.
Dell Cyber Resilient Architecture 2.0 safeguards customer’s data and intellectual property with a robust, layered approach.
Since a picture is worth a thousand words, the next section will show you what WAC extensions look like and how easy and intuitive they are to play with.
Dell OMIMSWAC Secured-core
The following figure shows our Secured-core snap-in integration inside the WAC security blade and workflow.
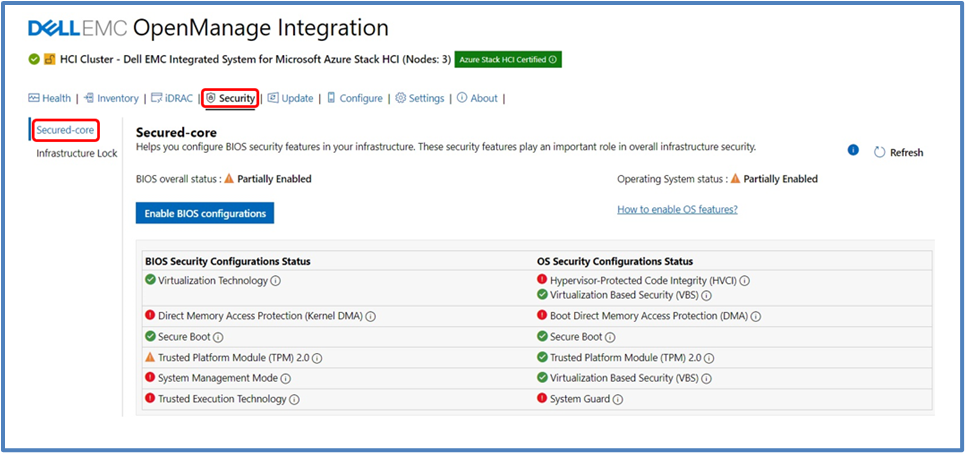
Figure 3: OMIMSWAC Secured-core view
The OS Security Configuration Status and the BIOS Security Configuration Status are displayed. The BIOS Security Configuration Status is where we can set the Secured-core required BIOS settings for the entire cluster.
OS Secured-core settings are visible but cannot be altered using OMIMSWAC (you would directly use WAC for it). You can also view and manage BIOS settings for each node individually.
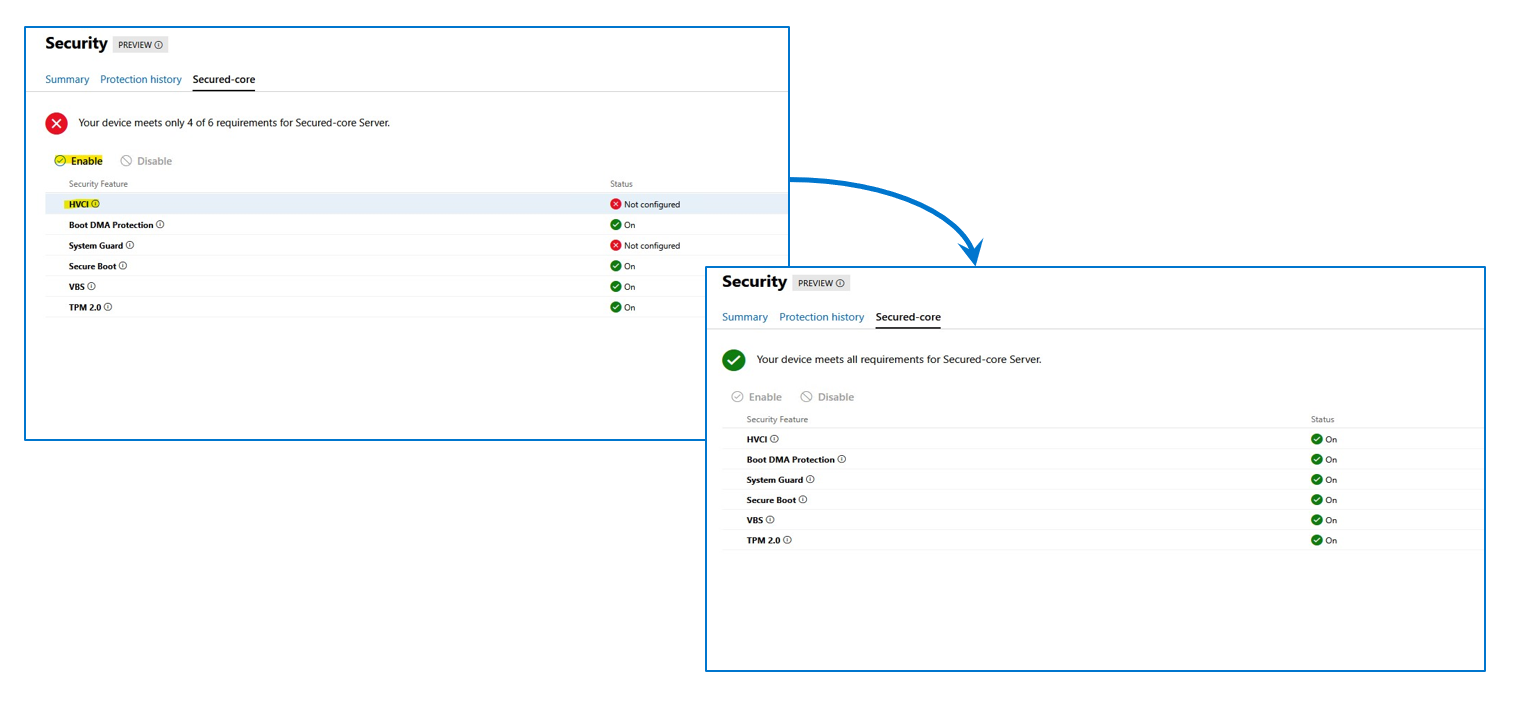
Figure 4: OMIMSWAC Secured-core, node view
Prior to enabling Secured-core, the cluster nodes must be updated to Azure Stack HCI, version 21H2 (or newer). For AMD Servers, the DRTM boot driver (part of the AMD Chipset driver package) must be installed.
Dell OMIMSWAC Infrastructure lock
The following figure illustrates the Infrastructure lock snap-in integration inside the WAC security blade and workflow. Here we can enable or disable Infrastructure lock to prevent unintended changes to both hardware configuration and firmware updates.
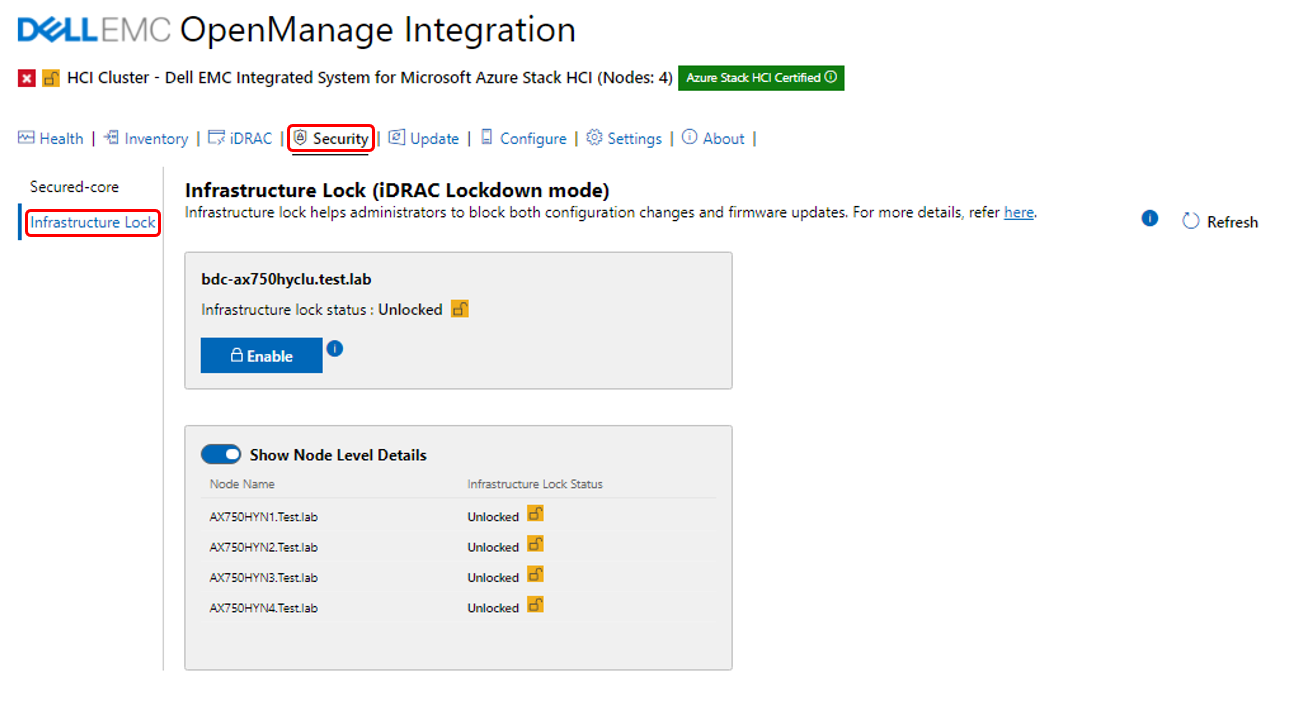
Figure 5: OMIMSWAC Infrastructure lock
Enabling Infrastructure lock also blocks the server or cluster firmware update process using OpenManage Integration extension tool. This means a compliance report will be generated if you are running a Cluster Aware Update (CAU) operation with Infrastructure lock enabled, which will block the cluster updates. If this occurs, you will have the option to temporarily disable Infrastructure lock and have it automatically re-enabled when the CAU is complete.
Conclusion
Dell understands the importance of the new security features introduced by Microsoft and has developed a programmatic approach, through OMIMSWAC and Dell’s Cyber-resilient Architecture, to consistently deliver and control these new features in each node and cluster. These features allow customers to always be secure and compliant on Azure Stack HCI environments.
Stay tuned for more updates (soon) on the compliance front, thank you for reading this far!
Author Information
Ignacio Borrero, Senior Principal Engineer, Technical Marketing
Twitter: @virtualpeli
References
2020 Verizon Data Breach Investigations Report
2019 Accenture Cost of Cybercrime Study
Global Ransomware Damage Costs Predicted To Reach $20 Billion (USD) By 2021
Cybercrime To Cost The World $10.5 Trillion Annually By 2025
The global cost of cybercrime per minute to reach $11.4 million by 2021