




Analytical Consulting Engine (ACE)
Mon, 17 Aug 2020 18:31:30 -0000
|Read Time: 0 minutes
VxRail plays its ACE, now generally available
November 2019
VxRail ACE (Analytical Consulting Engine), the new Artificial Intelligence infused component of the VxRail HCI System Software, was announced just a few months ago at Dell Technologies World and has been in global early access. Over 500 customers leveraged the early access program for ACE, allowing developers to collect feedback and implement enhancements prior to General Availability of the product. It is with great excitement that VxRail ACE is now generally available to all VxRail customers. By incorporating continuous innovation/continuous development (CIDC) utilizing the Pivotal Platform (also known as Pivotal Cloud Foundry) container-based framework, Dell EMC developers behind ACE have made rapid iterations to improve the offering; and customer demand has driven new features added to the roadmap. ACE is holding true to its design principles and commitment to deliver adaptive, frequent releases.

Figure 1 ACE Design Principles and Goals
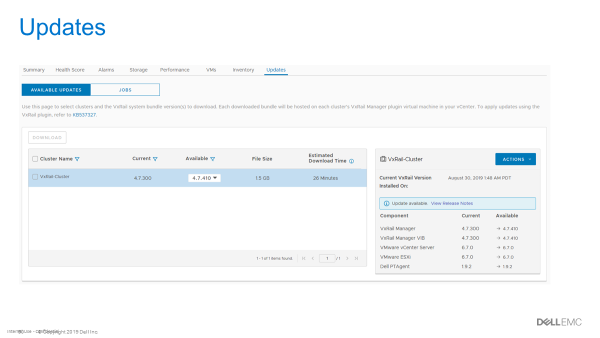
VxRail ACE is a centralized data collection and analytics platform that uses machine learning capabilities to perform capacity forecasting and self-optimization helping you keep your HCI stack operating at peak performance and ready for future workloads. In addition to some of the initial features available during early access, ACE now provides new functionality for intelligent upgrades of multiple clusters (see image below). You can now see the current software version of each cluster along with all available upgrade versions. ACE will allow you to select the desired version per each VxRail cluster. You can now manage at scale to standardize across all sites and clusters with the ability to customize by cluster. This becomes advantageous when some sites or clusters might need to remain at a specific version of VxRail software.
If you haven’t seen ACE in action yet, check out the additional links and videos below that showcase the features described in this post. For our 6,000+ VxRail customers, please visit our support site and Admin Guide to learn how to access ACE.
Christine Spartichino, Twitter - @cspartichino Linked In - linkedin.com/in/spartichino
For more information on VxRail, check out these great resources:
Related Blog Posts

Learn About the Latest VMware Cloud Foundation 5.1.1 on Dell VxRail 8.0.210 Release
Tue, 26 Mar 2024 18:47:52 -0000
|Read Time: 0 minutes
The latest VCF on VxRail release delivers GenAI-ready infrastructure, runs more demanding workloads, and is an excellent choice for supporting hardware tech refreshes and achieving higher consolidation ratios.
VMware Cloud Foundation 5.1.1 on VxRail 8.0.210 is a minor release from the perspective of versioning and new functionality but is significant in terms of support for the latest VxRail hardware platforms. This new release is based on the latest software bill of materials (BOM) featuring vSphere 8.0 U2b, vSAN 8.0 U2b, and NSX 4.1.2.3. Read on for more details…
VxRail hardware platform updates
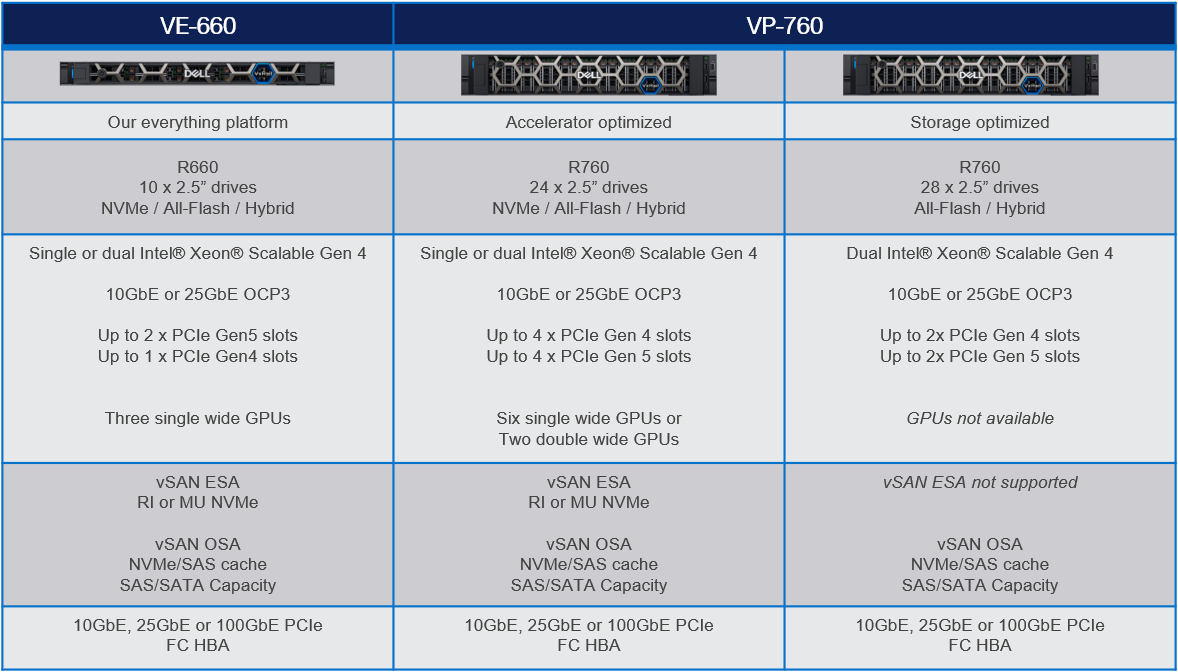
16th generation VxRail VE-660 and VP-760 hardware platform support
Cloud Foundation on VxRail customers can now benefit from the latest, more scalable, and robust 16th generation hardware platforms. This includes a full spectrum of hybrid, all-flash, and all NVMe options that have been qualified to run VxRail 8.0.210 software. This is fantastic news as these new hardware options bring many technical innovations, which my colleagues discussed in detail in previous blogs.
These new hardware platforms are based on Intel® 4th Generation Xeon® Scalable processors, which increase VxRail core density per socket to 56 (112 max per node). They also come with built-in Intel® AMX accelerators (Advanced Matrix Extensions) that support AI and HPC workloads without the need for additional drivers or hardware.
VxRail on the 16th generation hardware supports deployments with either vSAN Original Storage Architecture (OSA) or vSAN Express Storage Architecture (ESA). The VP-760 and VE-660 can take advantage of vSAN ESA’s single-tier storage architecture, which enables RAID-5 resiliency and capacity with RAID-1 performance.
This table summarizes the configurations of the newly added platforms:
To learn more about the VE-660 and VP-760 platforms, please check Mike Athanasiou’s VxRail’s Latest Hardware Evolution blog. To learn more about Intel® AMX capability set, make sure to check out the VxRail and Intel® AMX, Bringing AI Everywhere blog, authored by Una O’Herlihy.
VCF on VxRail LCM updates
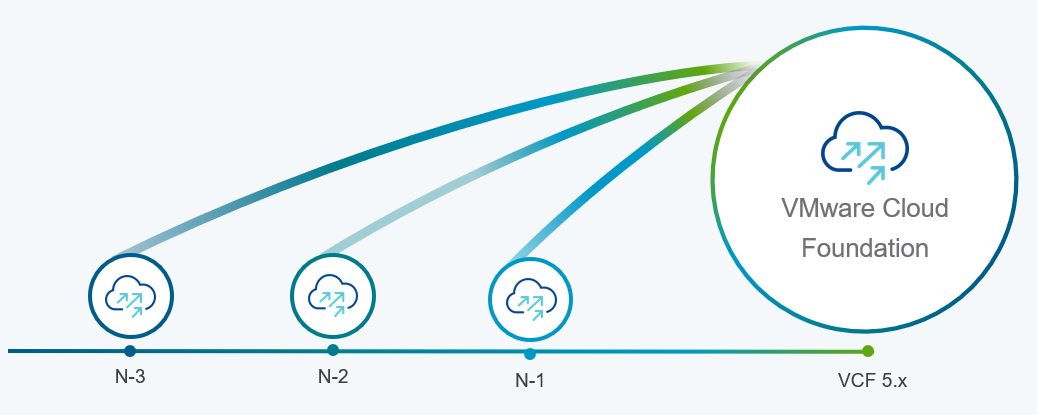
Support upgrades to VCF 5.1.1 from existing VCF 4.4.x and higher environments (N-3 upgrade support)
Customers who already upgraded to VCF 5.x are already familiar with the concept of the skip-level upgrade, which allows them to upgrade directly to the latest 5.x release without the need to perform upgrades to the interim versions. It significantly reduces the time required to perform the upgrade and enhances the overall upgrade experience. VCF 5.1.1 introduces so-called “N-3” upgrade support (as illustrated on the following diagram), which supports the skip-level upgrade for VCF 4.4.x. This means they can now perform a direct LCM upgrade operation from VCF 4.4.x, 4.5.x, 5.0.x, and 5.1.0 to VCF 5.1.1.
VCF licensing changes
Simplified licensing using a single solution license key
Starting with VCF 5.1.1, vCenter Server, ESXi, and TKG component licenses are now entered using a single “VCF Solution License” key. This helps to simplify the licensing by minimizing the number of individual component keys that require separate management. VMware NSX Networking, HCX, and VMware Aria Suite components are automatically entitled from the vCenter Server post-deployment. The single licensing key and existing keyed licenses will continue to work in parallel.
Removal of VCF+ cloud-connected subscriptions as a supported VCF licensing type
The other significant licensing change is the deprecation of VCF+ licensing, which the new subscription model has replaced.
Support for deploying or expanding VCF instances using Evaluation Mode
VMware Cloud Foundation 5.1.1 allows deploying a new VCF instance in evaluation mode without needing to enter license keys. An administrator has 60 days to enter licensing for the deployment, and SDDC Manager is fully functional at this time. The workflows for expanding a cluster, adding a new cluster, or creating a VI workload domain also provide an option to license later within a 60 day timeframe.
For more comprehensive information about changes in VCF licensing, please consult the VMware website.
Core VxRail enhancements
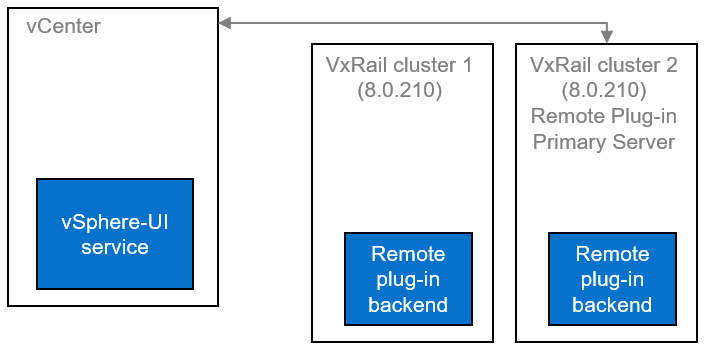
Support for remote vCenter plug-in
One of the notable enhancements in VxRail 8.0.210 is adopting the vSphere Client remote plugin architecture. It showcases adopting the latest vSphere architecture guidelines, as the local plug-ins are deprecated in vSphere 8.0 and won’t be supported in vSphere 9.0. The vSphere Client remote plug-in architecture allows plug-in functionality integration without running inside a vCenter Server. It’s a more robust architecture that separates vCenter Server from plug-ins and provides more security, flexibility, and scalability when choosing the programming frameworks and introducing new features. Starting with 8.0.210, a new VxRail Manager remote plug-in is deployed in the VxRail Manager Appliance.
LCM enhancements, including improved VxRail pre-checks and self-remediation of iDRAC issues.
VxRail 8.0.210 also comes with several small features based on Customer feedback that combine to improve the LCM experience's reliability. These include:
- VxRail Manager root disk space precheck prevents the upgrade errors related to lack of disk space (for rpm-based upgrades).
- Self-remediation of iDRAC issues during LCM upgrades provides a more reliable firmware upgrade experience. By clearing the iDRAC job queue and resetting the iDRAC, the process may recover from a firmware update failure.
Serviceability enhancements, including improved expansion pre-checks, external storage reporting, and improved troubleshooting capabilities.
Another group of features contributes to overall improved serviceability and visibility into the system:
- The UI now implements new errors and warnings for incompatible disks when the user tries to add an incompatible disk during the disk addition process (see the following figure)
- The improved hardware views report on storage capacity and utilization for dynamic nodes, improving the overall visibility for the external storage attached to dynamic nodes directly from the vSphere Client.
- VxRail cluster troubleshooting efficiency has improved thanks to better standardization of log format and event grooming for disk exhaustion.
- The improved node-add health checks reduce the risk of successfully adding a faulty or mismatched node to a VxRail cluster.
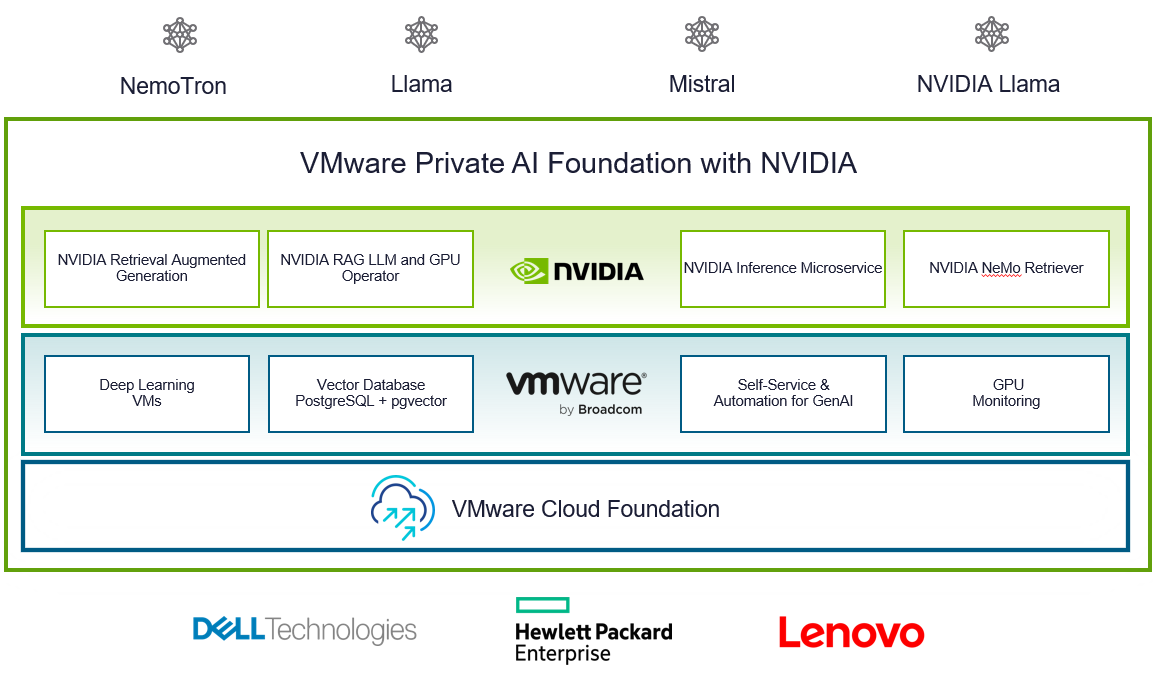
VMware Private AI Foundation with NVIDIA
With VCF 5.1.1, VMware introduces VMware Private AI Foundation with NVIDIA as Initial Access. Dell Technologies Engineering intends to validate this feature when it is generally available.
This solution aims to enable enterprise customers to adopt Generative AI capabilities more easily and securely by providing enterprises with a cost-effective, high-performance, and secure environment for delivering business value from Large Language Models (LLMs) using their private data.
Summary
The new VCF 5.1.1 on VxRail 8.0.210 release is an excellent option for customers looking for a hardware refresh, Gen AI-ready infrastructure to run more demanding workloads, or to achieve higher consolidation ratios. Additional enhancements introduced in the core VxRail functionality improve the overall LCM experience, serviceability, and visibility into the system.
Thank you for your time, and please check the additional resources if you like to learn more.
Resources
- VxRail’s Latest Hardware Evolution blog
- VxRail and Intel® AMX, Bringing AI Everywhere
- VxRail product page
- VxRail Infohub page
- VxRail Videos
- VMware Cloud Foundation on Dell VxRail Release Notes
- VCF on VxRail Interactive Demo
- VMware Product Lifecycle Matrix
Author: Karol Boguniewicz
Twitter: @cl0udguide

Learn About the Latest Major VxRail Software Release: VxRail 8.0.210
Fri, 15 Mar 2024 20:13:39 -0000
|Read Time: 0 minutes
It’s springtime, VxRail customers! VxRail 8.0.210 is our latest software release to bloom. Come see for yourself what makes this software release shine.
VxRail 8.0.210 provides support for VMware vSphere 8.0 Update 2b. All existing platforms that support VxRail 8.0 can upgrade to VxRail 8.0.210. This is also the first VxRail 8.0 software to support the hybrid and all-flash models of the VE-660 and VP-760 nodes based on Dell PowerEdge 16th Generation platforms that were released last summer and the edge-optimized VD-4000 platform that was released early last year.
Read on for a deep dive into the release content. For a more comprehensive rundown of the feature and enhancements in VxRail 8.0.210, see the release notes.
Support for VD-4000
The support for VD-4000 includes vSAN Original Storage Architecture (OSA) and vSAN Express Storage Architecture (ESA). VD-4000 was launched last year with VxRail 7.0 support with vSAN OSA. Support in VxRail 8.0.210 carries over all previously supported configurations for VD-4000 with vSAN OSA. What may intrigue you even more is that VxRail 8.0.210 is introducing first-time support for VD-4000 with vSAN ESA.
In the second half of last year, VMware reduced the hardware requirements to run vSAN ESA to extend its adoption of vSAN ESA into edge environments. This change enabled customers to consider running the latest vSAN technology in areas where constraints from price points and infrastructure resources were barriers to adoption. VxRail added support for the reduced hardware requirements shortly after for existing platforms that already supported vSAN ESA, including E660N, P670N, VE-660 (all-NVMe), and VP-760 (all-NVMe). With VD-4000, the VxRail portfolio now has an edge-optimized platform that can run vSAN ESA for environments that also may have space, energy consumption, and environmental constraints. To top that off, it’s the first VxRail platform to support a single-processor node to run vSAN ESA, further reducing the price point.
It is important to set performance expectations when running workload applications on the VD-4000 platform. While our performance testing on vSAN ESA showed stellar gains to the point where we made the argument to invest in 100GbE to maximize performance (check it out here), it is essential to understand that the VD-4000 platform is running with an Intel Xeon-D processor with reduced memory and bandwidth resources. In short, while a VD-4000 running vSAN ESA won’t be setting any performance records, it can be a great solution for your edge sites if you are looking to standardize on the latest vSAN technology and take advantage of vSAN ESA’s data services and erasure coding efficiencies.
Lifecycle management enhancements
VxRail 8.0.210 offers support for a few vLCM feature enhancements that came with vSphere 8.0 Update 2. In addition, the VxRail implementation of these enhancements further simplifies the user experience.
For vLCM-enabled VxRail clusters, we’ve made it easier to benefit from VMware ESXi Quick Boot. The VxRail Manager UI has been enhanced so that users can enable Quick Boot one time, and VxRail will maintain the setting whenever there is a Quick Boot-compatible cluster update. As a refresher for some folks not familiar with Quick Boot, it is an operating system-level reboot of the node that skips the hardware initialization. It can reduce the node reboot time by up to three minutes, providing significant time savings when updating large clusters. That said, any cluster update that involves firmware updates is not Quick Boot-compatible.
Using Quick Boot had been cumbersome in the past because it required several manual steps. To use Quick Boot for a cluster update, you would need to go to the vSphere Update Manager to enable the Quick Boot setting. Because the setting resets to Disabled after the reboot, this step had to be repeated for any Quick Boot-compatible cluster update. Now, the setting can be persisted to avoid manual intervention.
As shown in the following figure, the update advisor report now informs you whether a cluster update is Quick Boot-compatible so that the information is part of your update planning procedure. VxRail leverages the ESXi Quick Boot compatibility utility for this status check.
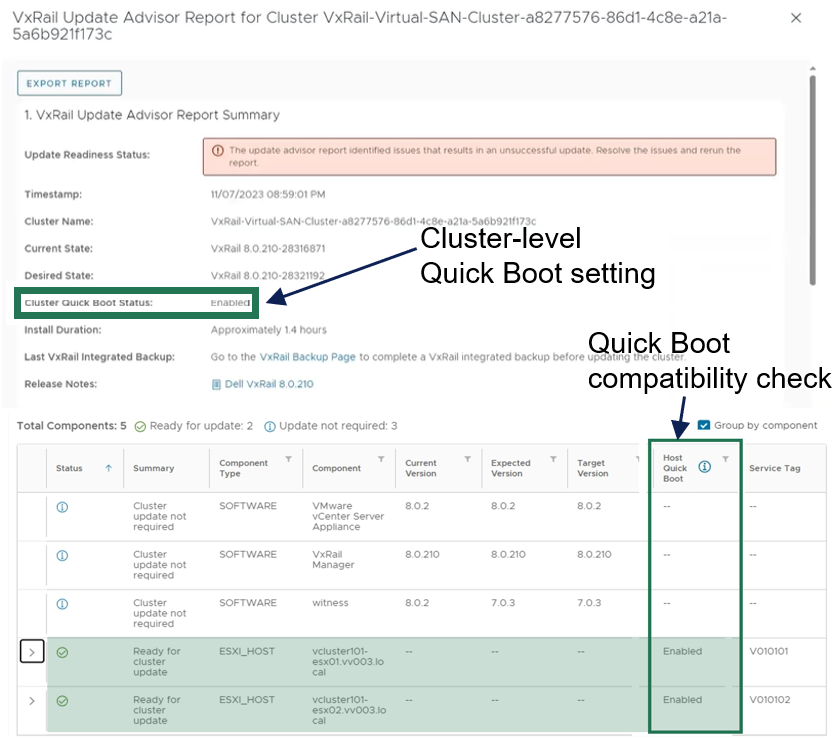
Figure 1. VxRail update advisor report highlighting Quick Boot information
Another new vLCM feature enhancement that VxRail supports is parallel remediation. This enhancement allows you to update multiple nodes at the same time, which can significantly cut down on the overall cluster update time. However, this feature enhancement only applies to VxRail dynamic nodes because vSAN clusters still need to be updated one at a time to adhere to storage policy settings.
This feature offers substantial benefits in reducing the maintenance window, and VxRail’s implementation of the feature offers additional protections over how it can be used on vSAN Ready Nodes. For example, enabling parallel remediation with vSAN Ready Nodes means that you would be responsible for managing when nodes go into and out of maintenance mode as well as ensuring application availability because vCenter will not check whether the nodes that you select will disrupt application uptime. The VxRail implementation adds safety checks that help mitigate potential pitfalls, ensuring a smoother parallel remediation process.
VxRail Manager manages when nodes enter and exit maintenance modes and provides the same level of error checking that it already performs on cluster updates. You have the option of letting VxRail Manager automatically set the maximum number of nodes that it will update concurrently, or you can input your own number. The number for the manual setting is capped at the total node count minus two to ensure that the VxRail Manager VM and vCenter Server VM can continue to run on separate nodes during the cluster update.
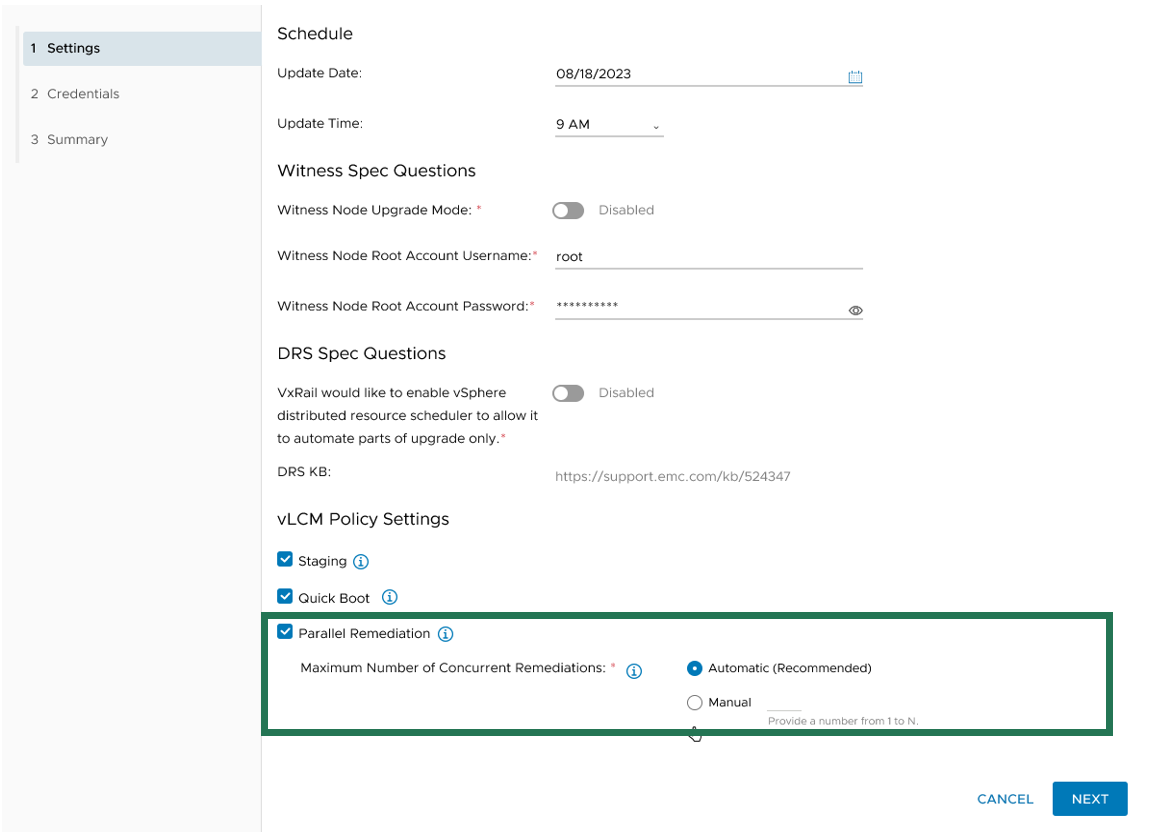
Figure 2. Options for setting the maximum number of concurrent node remediations
During the cluster update, VxRail Manager intelligently reduces the node count of concurrent updates if a node cannot enter maintenance mode or if the application workload cannot be migrated to another node to ensure availability. VxRail Manager will automatically defer that node to the next batch of node updates in the cluster update operation.
The last vLCM feature enhancement in VxRail 8.0.210 that I want to discuss is installation file pre-staging. The idea is to upload as many installation files for the node update as possible onto the node before it actually begins the update operation. Transfer times can be lengthy, so any reduction in the maintenance window would have a positive impact to the production environment.
To reap the maximum benefits of this feature, consider using the scheduling feature when setting up your cluster update. Initiating a cluster update with a future start time allows VxRail Manager the time to pre-stage the files onto the nodes before the update begins.
As you can see, the three vLCM feature enhancements can have varying levels of impact on your VxRail clusters. Automated Quick Boot enablement only benefits cluster updates that are Quick Boot-compatible, meaning there is not a firmware update included in the package. Parallel remediation only applies to VxRail dynamic node clusters. To maximize installation files pre-staging, you need to schedule cluster updates in advance.
That said, two commonalities across all three vLCM feature enhancements is that you must have your VxRail clusters running vLCM mode and that the VxRail implementation for these three feature enhancements makes them more secure and easy to use. As shown in the following figure, the Updates page on the VxRail Manager UI has been enhanced so that you can easily manage these vLCM features at the cluster level.
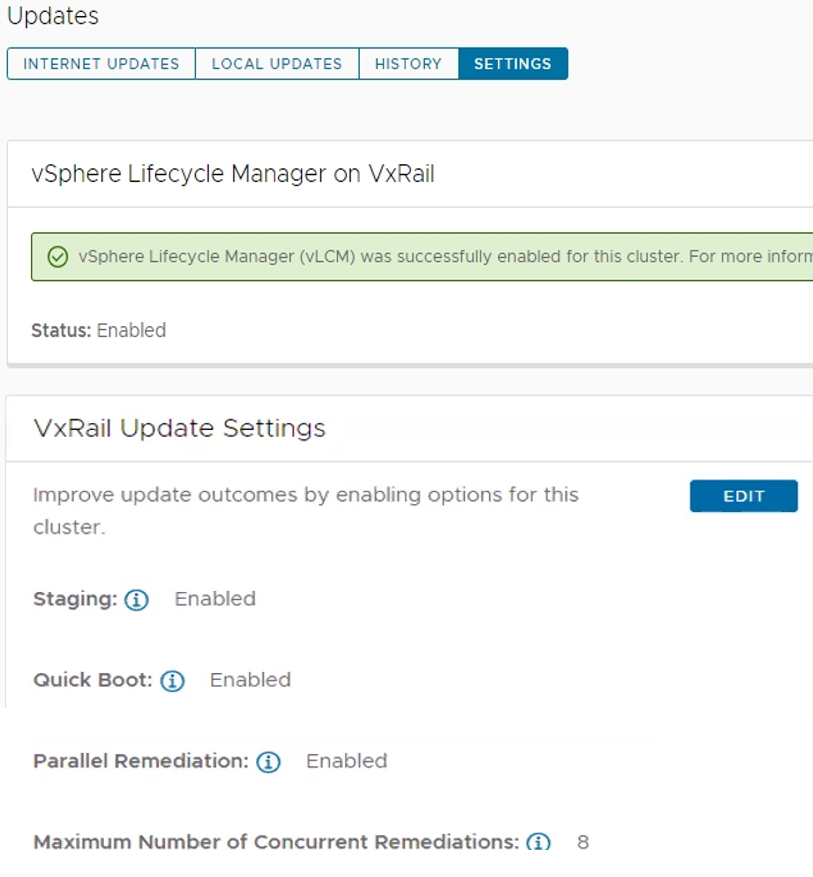
Figure 3. VxRail Update Settings for vLCM features
VxRail dynamic nodes
VxRail 8.0.210 also introduces an enhancement for dynamic node clusters with a VxRail-managed vCenter Server. In a recent VxRail software release, VxRail added an option for you to deploy a VxRail-managed vCenter Server with your dynamic node cluster as a Day 1 operation. The initial support was for Fiber-Channel attached storage. The parallel enhancement in this release adds support for dynamic node clusters using IP-attached storage for its primary datastore. That means iSCSI, NFS, and NVMe over TCP attached storage from PowerMax, VMAX, PowerStore, UnityXT, PowerFlex, and VMware vSAN cross-cluster capacity sharing is now supported. Just like before, you are still responsible for acquiring and applying your own vCenter Server license before the 60-day evaluation period expires.
Password management
Password management is one of the key areas of focus in this software release. To reduce the manual steps to modify the vCenter Server management and iDRAC root account passwords, the VxRail Manager UI has been enhanced to allow you to make the changes via a wizard-driven workflow instead of having to change the password on the vCenter Server or iDRAC themselves and then go onto VxRail Manager UI to provide the updated password. The enhancement simplifies the experience and reduces potential user errors.
To update the vCenter Server management credentials, there is a new Security page that replaces the Certificates page. As illustrated in the following figure, a Certificate tab for the certificates management and a Credentials tab to change the vCenter Server management password are now present.
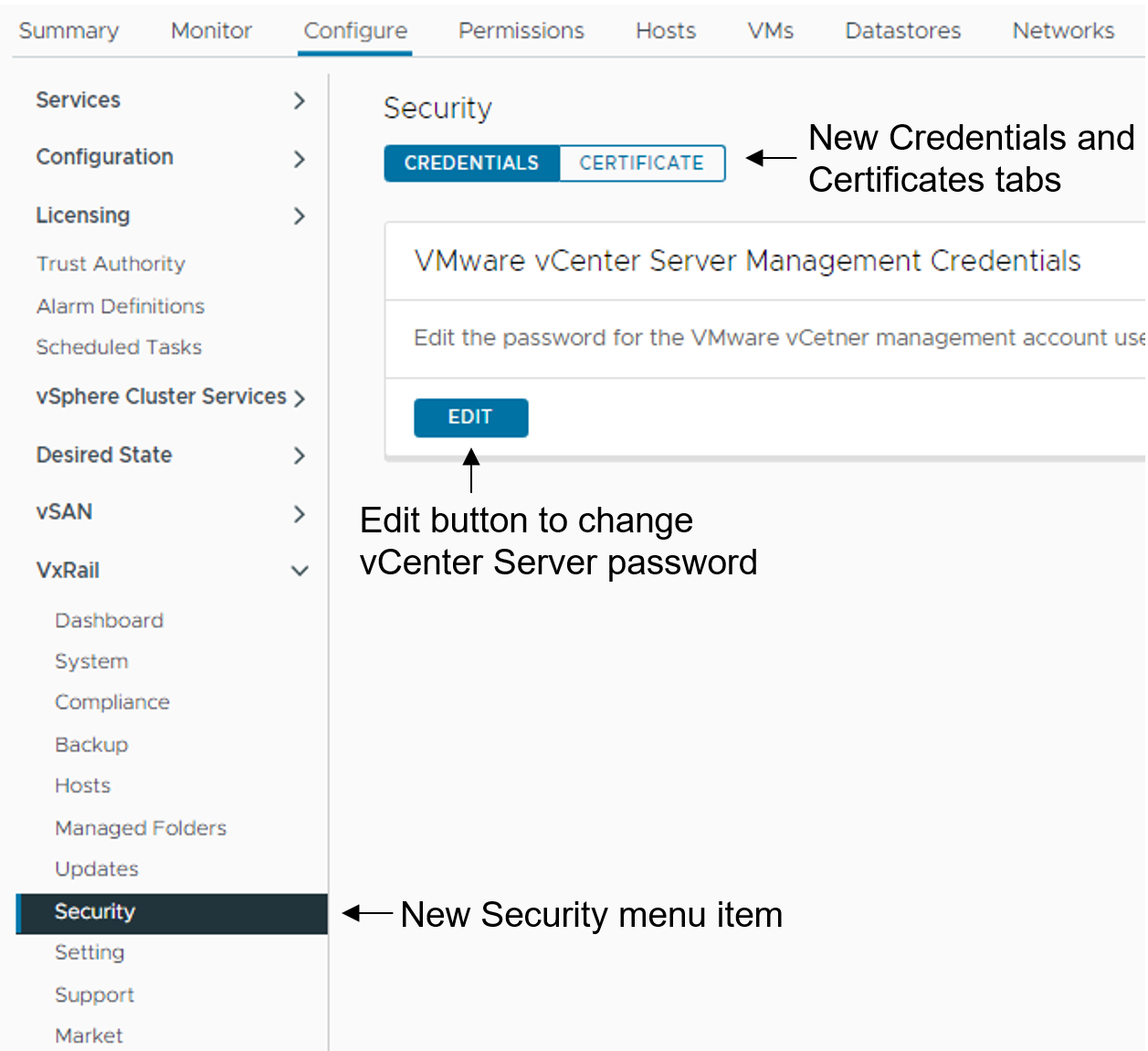
Figure 4. How to update the vCenter Server management credentials
To update the iDRAC root account password, there is a new iDRAC Configuration page where you can click the Edit button to launch a wizard to the change password.

Figure 5. How to update the iDRAC root password
Deployment Flexibility
Lastly, I want to touch on two features in deployment flexibility.
Over the past few years, the VxRail team has invested heavily in empowering you with the tools to recompose and rebuild the clusters on your own. One example is making our VxRail nodes customer-deployable with the VxRail Configuration Portal. Another is the node imaging tool.
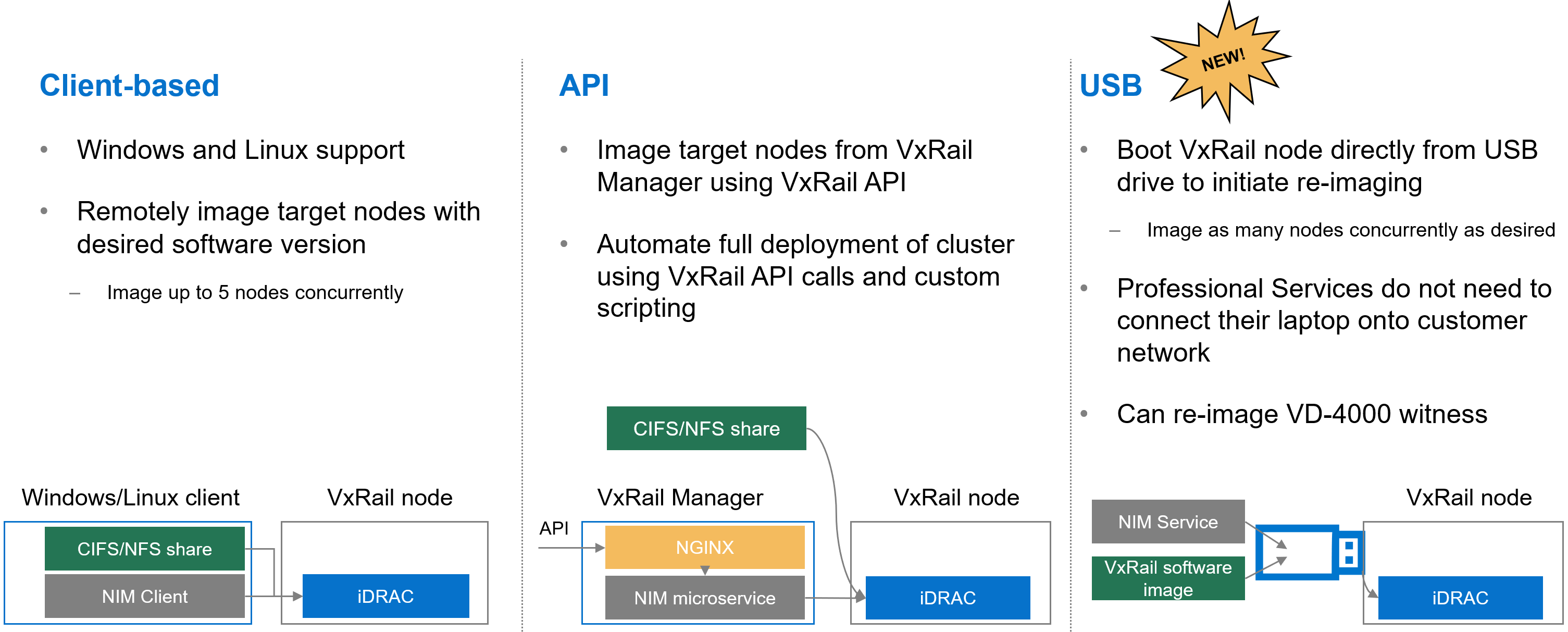
Figure 6. Different options to use the node image management tool
Initially, the node imaging tool was Windows client-based where the workstation has the VxRail software ISO image stored locally or on a share. By connecting the workstation onto the local network where the target nodes reside, the imaging tool can be used to connect to the iDRAC of the target node. Users can reimage up to 5 nodes on the local network concurrently. In a more recent VxRail release, we added Linux client support for the tool.
We’ve also refactored the tool into a microservice within the VxRail HCI System Software so that it can be used via VxRail API. This method added more flexibility so that you can automate the full deployment of your cluster by using VxRail API calls and custom scripting.
In VxRail 8.0.210, we are introducing the USB version of the tool. Here, the tool can be self-contained on a USB drive so that users can plug the USB drive into a node, boot from it, and initiate reimaging. This provides benefits in scenarios where the 5-node maximum for concurrent reimage jobs is an issue. With this option, users can scale reimage jobs by setting up more USB drives. The USB version of the tool now allows an option to reimage the embedded witness on the VD-4000.
The final feature for deployment flexibility is support for IPv6. Whether your environment is exhausting the IPv4 address pool or there are requirements in your organization to future-proof your networking with IPv6, you will be pleasantly surprised by the level of support that VxRail offers.
You can deploy IPv6 in a dual or single network stack. In a dual network stack, you can have IPv4 and IPv6 addresses for your management network. In a single network stack, the management network is only on the IPv6 network. Initial support is for VxRail clusters running vSAN OSA with 3 or more nodes. Other than that, the feature set is on par with what you see with IPv4. Select the network stack at cluster deployment.
Conclusion
VxRail 8.0.210 offers a plethora of new features and platform support such that there is something for everyone. As you digest the information about this release, know that updating your cluster to the latest VxRail software provides you with the best return on your investment from a security and capability standpoint. Backed by VxRail Continuously Validated States, you can update your cluster to the latest software with confidence. For more information about VxRail 8.0.210, please refer to the release notes. For more information about VxRail in general, visit the Dell Technologies website.
Author: Daniel Chiu, VxRail Technical Marketing
https://www.linkedin.com/in/daniel-chiu-8422287/