




Part III | How to Run Llama-2 via Hugging Face Models on AMD ROCm™ with Dell PowerEdge™?
Thu, 09 Nov 2023 23:21:47 -0000
|Read Time: 0 minutes
 PowerEdge R7615
PowerEdge R7615
 AMD Instinct MI210 Accelerator
AMD Instinct MI210 Accelerator
In our second blog, we provided a step-by-step guide on how to get models running on AMD ROCm™, set up TensorFlow and PyTorch, and deploying GPT-2. In this guide, we are now exploring how to set up a leading large language model (LLM) Llama-2 using Hugging Face.
Dell™ PowerEdge™ offers a rich portfolio of AMD ROCm™ solutions, including Dell™ PowerEdge™ R7615, R7625, and R760xa servers.
| We implemented the following Dell™ PowerEdge™ system configurations
Operating system: Ubuntu 22.04.3 LTS
Kernel version: 5.15.0-86-generic
Docker Version: Docker version 24.0.6, build ed223bc
ROCm version: 5.7
Server: Dell PowerEdge R7615
CPU: AMD EPYC™ 9354P 32-Core Processor
GPU: AMD Instinct™ MI210

| Step-by-Step Guide
1. First, Install AMD ROCm™ driver, libraries, and tools. Follow the detailed installation instructions for your Linux based platform.
To ensure these installations are successful, check the GPU info using `rocm-smi`.
2. Next, we will select code snippets from Hugging Face. Hugging Face offers the most comprehensive set of developer tools for leading AI models. We will select GPT2 code snippets for both TensorFlow and PyTorch. Follow the steps in blog 2 (link) to start the ROCm PyTorch docker container.
Follow the steps in Blog II to start the AMD ROCm™ PyTorch docker container.
| Running a chatbot with Llama2-7B-chat model and Gradio ChatInterface:
The Llama-2-7b-chat model from Hugging Face is a large language model developed by Facebook AI and Meta, designed for text generation tasks. It is a part of the Llama2 series, featuring an impressive 6.74 billion parameters, and is primarily used for creating AI chatbots and generating human-like text.
Gradio ChatInterface is Gradio's high-level abstraction for creating chatbot UIs and allows you to create a web-based demo around the Llama2-7B- chat model in a few lines of code.
Install Prerequisites:
Python pip3 install transformers sentencepiece accelerate gradio protobuf |
Request access token:
Request access to Llama-2 7B Chat Model: Llama-2-7B-Chat-HF
Log in to Hugging Face CLI and enter your access token when prompted:
Unset huggingface-cli login |
Perform Python code:
Python import time import torch from transformers import LlamaForCausalLM, LlamaTokenizer import gradio as gr model_name = "meta-llama/Llama-2-7b-chat-hf" torch_dtype = torch.bfloat16 max_new_tokens = 500 # Initialize and load tokenizer, model tokenizer = LlamaTokenizer.from_pretrained(model_name, device_map="auto") model = LlamaForCausalLM.from_pretrained(model_name, torch_dtype=torch_dtype, device_map="auto") def chat(message, history): input_text = message # Encode the input text using tokenizer encoded_input = tokenizer.encode(input_text, return_tensors='pt') encoded_input = encoded_input.to('cuda') # Inference start_time = time.time() outputs = model.generate(encoded_input, max_new_tokens=max_new_tokens) end_time = time.time() generated_text = tokenizer.decode( outputs[0], skip_special_tokens=True )
# Calculate number of tokens generated num_tokens = len(outputs[0].detach().cpu().numpy().flatten()) inference_time = end_time - start_time token_per_sec = num_tokens / inference_time print(f"Inference latency: {inference_time} sec") print(f"Token per sec: {token_per_sec}") return(generated_text)
# Launch gradio based chatinterface demo = gr.ChatInterface(fn=chat, title="Llama2 chatbot") demo.launch() |
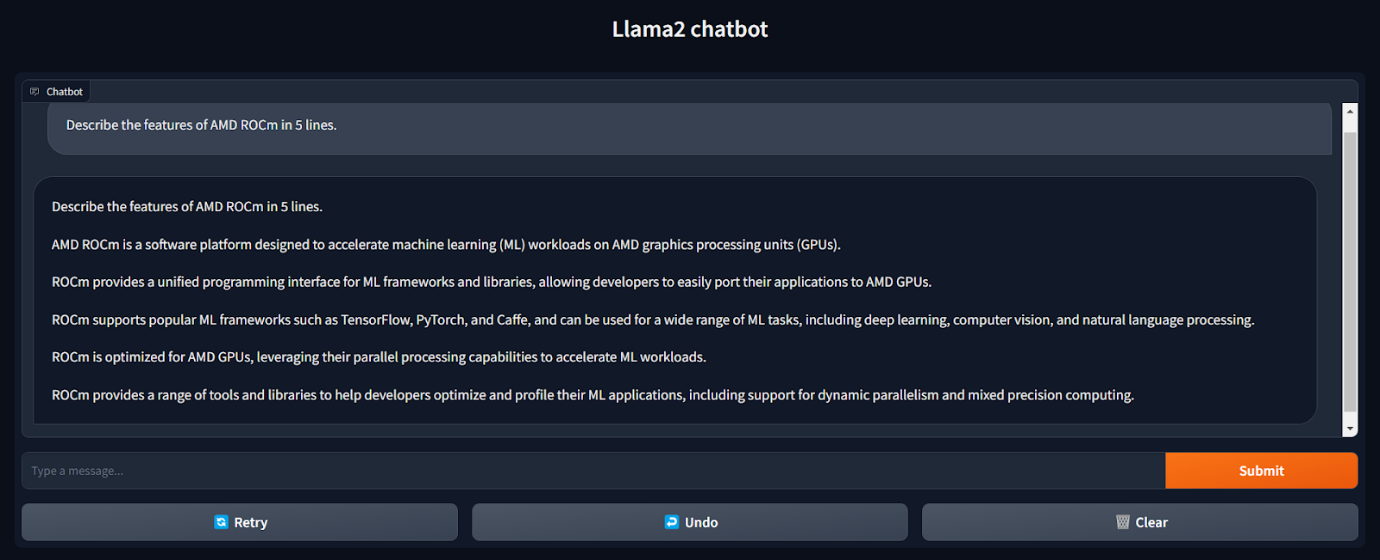
| Here is the output conversation on the chatbot with prompt and results
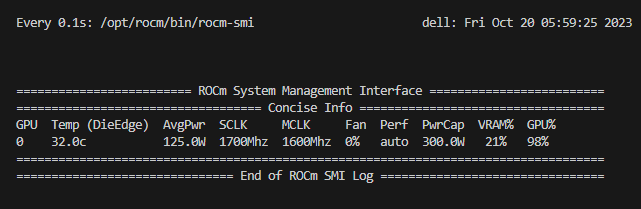
| Here is a view of AMD GPU utilization with rocm-smi
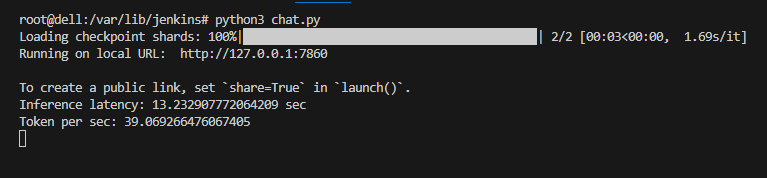
As you can see, using Hugging Face integration with AMD ROCm™, we can now deploy the leading large language models, in this case, Llama-2. Furthermore, the performance of the AMD Instinct™ MI210 meets our target performance threshold for inference of LLMs at <100 millisecond per token.
| “Scalers AI was thrilled to see the robust ecosystem emerging around ROCm that provides us with critical choice and exceeds our target <100 millisecond per user latency target on 7B parameter leading large language models!”
- Chetan Gadil, CTO, Scalers AI
In our next blog, we explore the performance of AMD ROCm™ and how we can accelerate AI research progress across industries with AMD ROCm™.
| Authors
Steen Graham, CEO of Scalers AI
Delmar Hernandez, Dell PowerEdge Technical Marketing
Mohan Rokkam, Dell PowerEdge Technical Marketing