




Dell ObjectScale Data Path Overview Part I
Wed, 10 Jan 2024 16:13:45 -0000
|Read Time: 0 minutes
Dell ObjectScale is the next evolution of object storage from Dell Technologies. ObjectScale is scale-out, high-performance containerized object storage built for the toughest applications and workloads, from generative AI to analytics and more. ObjectScale features a containerized architecture built on the principles of microservices to promote resiliency and flexibility. It is a branch of Dell ECS’s codebase and has been re-platformed to utilize the native orchestration capabilities of Kubernetes—scheduling, load-balancing, self-healing, resource optimization, and so on.
This blog will focus solely on the data path of ObjectScale. Please refer to the ObjectScale overview and architecture documentation to learn more about ObjectScale.
Before we introduce the data path, let’s first review chunks, metadata, and B+ tree . If you are already familiar with these concepts, please refer to the Dell ObjectScale Data Path Overview Part II, which will introduce data protection and dataflow.
Chunks
A chunk is a logical container that ObjectScale uses to store all types of data, including object data, custom client provided metadata, and system metadata. Chunks contain 128 MB of data consisting of one or more objects, as shown in the following figure.
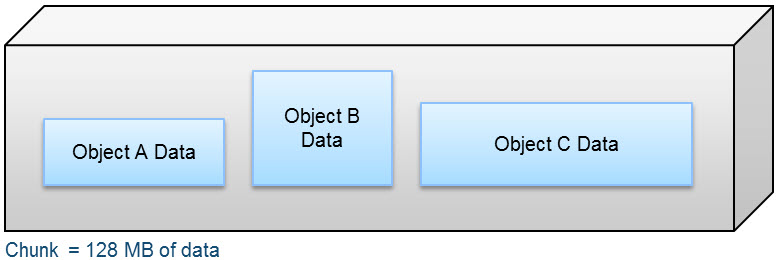
Figure 1. Composition of a chunk
An object created within ObjectScale includes writing data and metadata. Metadata encompasses journal chunks and btree chunks. Data chunks have either inline coding or triple mirror plus in-place erasure coding protection depending on the size of the object data, and the btree or journal chunks which store the metadata have triple mirror protection. For more information, please refer to the Dell ObjectScale Data Path Overview Part II.
Metadata
Metadata provides information about one or more aspects of the data, including system metadata like owner, creation date, size, and custom metadata. An example of customer metadata could be client=Dell, event=DellWorld, and ID=123.
Both system metadata and custom metadata are stored in B+ tree and journal chunks.
Data management
ObjectScale maintains the metadata that tracks data locations and transaction history in logical tables and journals.
The tables hold key-value pairs to store information relating to the objects. A hash function is used to do fast lookups of values associated with a key. These key-value pairs are stored in a B+ tree for fast indexing of data locations. In addition, to further enhance query performance of these logical tables, ObjectScale implements a two-level log-structured merge (LSM) tree. Thus, there are two tree-like structures in which a smaller tree is in memory (memory table) and the main B+ tree resides on disk. A lookup of key-value pairs first queries the memory table, and if the value is not memory, it looks in the main B+ tree on disk.
Transaction history is recorded in journal logs which are written to disks. The journals track the index transactions not yet committed to the B+ tree. After the transaction is logged into a journal, the memory table is updated. After a set period of time or when the table in memory becomes full, the table is merged, sorted, or dumped to the B+ tree on disk. A checkpoint is then recorded in the journal.
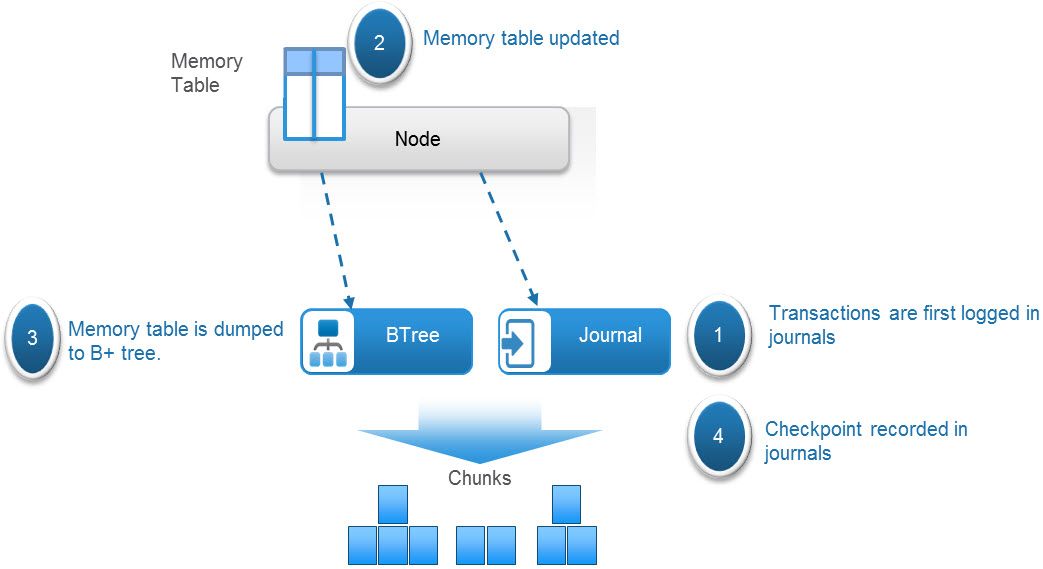
Figure 2. Metadata management process in ObjectScale
ObjectScale uses several different tables, which can get quite large. To optimize the performance of table lookups, each table is divided into partitions that are distributed across the nodes. The node where the partition is written then becomes the owner or authority of that partition or section of the table.
One such table is a chunk table, which tracks the physical location of chunk fragments and replica copies on disk. The following table shows a sample of a partition of the chunk table. Each chunk identifies its physical location by listing the disk within the node, the file within the disk, the offset within that file, and the length of the data. Chunk ID C1 is erasure coded, and chunk ID C2 is triple mirrored, as shown in table 1.
Table 1. Sample chunk table partition
Chunk ID | Chunk location |
C1 | Node1:Disk1:File1:offset1:length Node2:Disk1:File1:offset1:length Node3:Disk1:File1:offset1:length Node4:Disk1:File1:offset1:length Node5:Disk1:File1:offset1:length Node6:Disk1:File1:offset1:length Node7:Disk1:File1:offset1:length Node8:Disk1:File1:offset1:length Node1:Disk2:File1:offset1:length Node2:Disk2:File1:offset1:length Node3:Disk2:File1:offset1:length Node4:Disk2:File1:offset1:length Node5:Disk2:File1:offset1:length Node6:Disk2:File1:offset1:length Node7:Disk2:File1:offset1:length Node8:Disk2:File1:offset1:length |
C2 | Node1:Disk3:File1:offset1:length Node2:Disk3:File1:offset1:length Node3:Disk3:File1:offset1:length |
Another example is an object table, which is used for object name to chunk mapping. The following table shows an example of a partition of an object table that lists the chunk or chunks and shows where an object resides in the chunk or chunks.
Table 2. Sample object table
Object name | Chunk ID |
ImgA | C1:offset:length |
FileA | C4:offset:length C6:offset:length |
A service called Atlas, which runs on all nodes, maintains the mapping of table partition owners. The following table shows an example of a portion of an atlas mapping table.
Table 3. Sample Atlas mapping table
Table ID | Table partition owner |
Table 0 P1 | Node 1 |
Table 0 P2 | Node 2 |
We will cover ObjectScale data protection and workflow in the Dell ObjectScale Data Path Overview Part II.
Resources
The following Dell Technologies documentation provides additional information related to this blog. Access to these documents depends on an individual’s login credentials. For access to a document, contact a Dell Technologies representative.
Author: Jarvis Zhu