
CPU-based AI inference
CPU-based AI inference
-
To measure the performance on different memory configurations for CPU-based AI inference workload types, we used the TensorFlow benchmark. TensorFlow is a benchmark with implementations of popular convolutional neural networks for large-scale image recognition (VGG-16, AlexNet, GoogLeNet, and ResNet-50) and various batch sizes (16, 32, 64, 256, and 512). It is designed to support workloads running on a single machine as well as workloads running in distributed mode across multiple hosts. The study looks at all subtests in TensorFlow.
We looked at the performance trend that each model shows for the different batch sizes to decide which of the 1-socket and 2-socket versions is suitable for a CPU-based AI inference type of workload. The following figures show the performance of convolutional models on different batch sizes in the balanced, 12-DIMMs-per-socket configuration with memory capacity of 64 GB per DIMM in PowerEdge 7625 and 7615 with 4th Gen AMD EPYC 9654 and 9654P processors:

Figure 9. Performance of convolutional models on different batch sizes in the balanced, 12-DIMMs-per-socket configuration with memory capacity of 64 GB per DIMM with default BIOS settings
The batch size can vary depending on several factors, including the specific application, available computational resources, and hardware constraints. Generally, larger batch sizes are preferred because they offer better parallelization and computational efficiency, but they also require more memory. As we can see in the line graphs, the 2-socket server (PowerEdge R7625) outperforms the 1-socket server (PowerEdge R7615) by up to 38 percent in the largest batch sizes.
For inference tasks, the performance unit is typically measured as the number of inferences (predictions) made per second. It represents how many predictions the model can generate in a given time frame. Again, a higher value indicates better performance, meaning the model can perform more predictions per second. In our model, the unit is images per second.
We look at the performance, performance per watt, and cost effectiveness results of AlexNet on a batch size of 256 for the 2-socket PowerEdge R7625 to make our recommendations. The following figures show the performance, energy efficiency, and performance per dollar for the tested configurations:
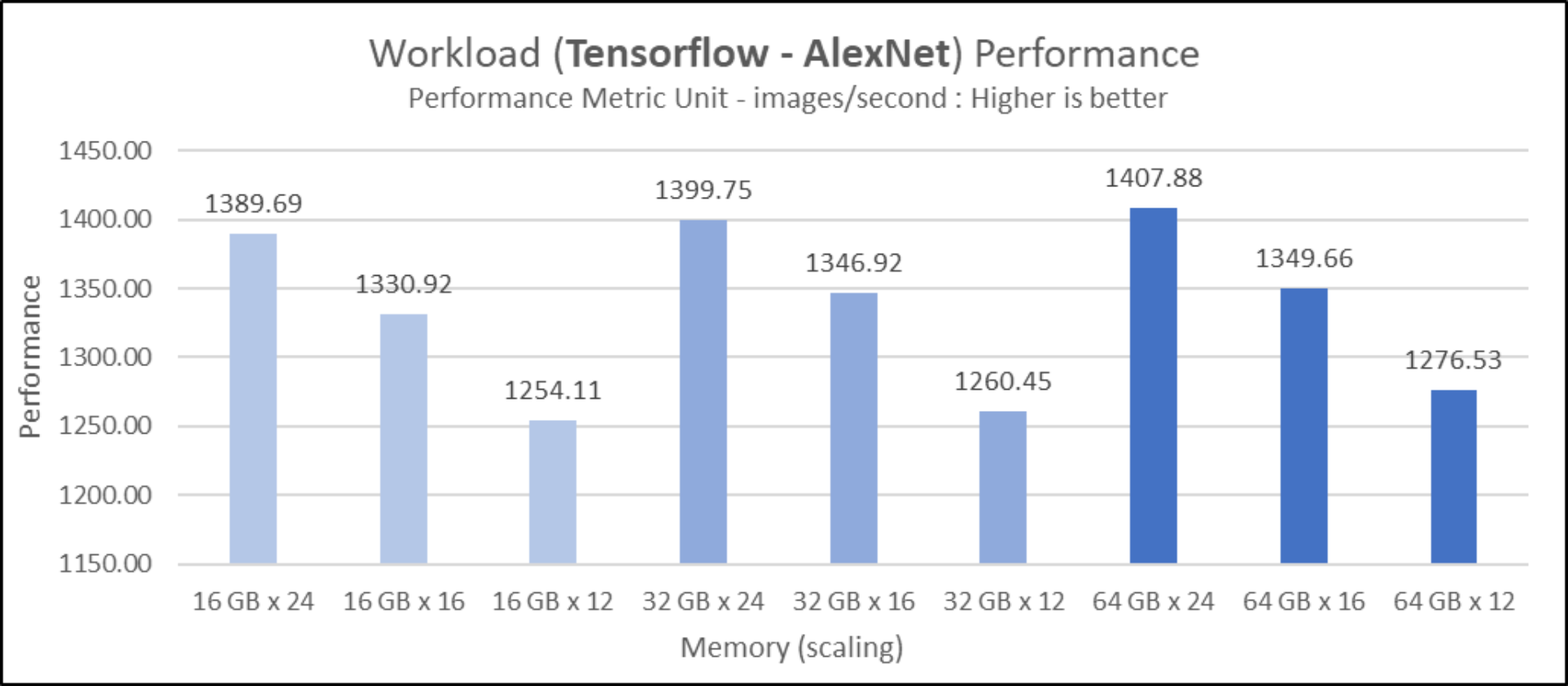 Figure 10. Performance trend for AlexNet on batch size of 256 with different DIMM configurations and memory capacity for 4th Gen AMD EPYC 9654 processor-based PowerEdge R7625 with default BIOS settings
Figure 10. Performance trend for AlexNet on batch size of 256 with different DIMM configurations and memory capacity for 4th Gen AMD EPYC 9654 processor-based PowerEdge R7625 with default BIOS settings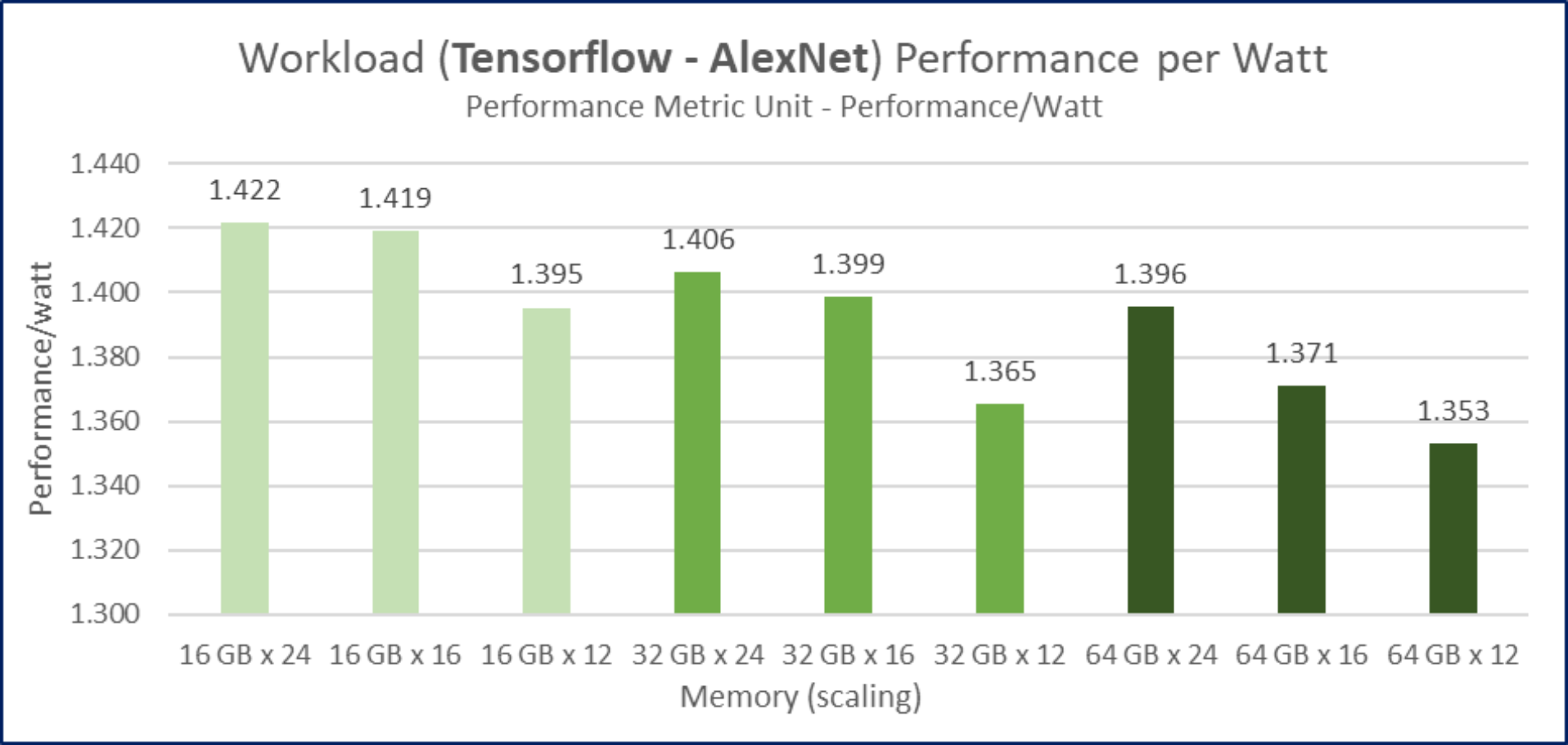 Figure 11. Performance per watt trend for TensorFlow – AlexNet on batch size of 256 with different DIMM configurations and memory capacity for 4th Gen AMD EPYC 9654 processor-based PowerEdge R7625 with default BIOS settings
Figure 11. Performance per watt trend for TensorFlow – AlexNet on batch size of 256 with different DIMM configurations and memory capacity for 4th Gen AMD EPYC 9654 processor-based PowerEdge R7625 with default BIOS settings
Figure 12. Performance per $1,000 trend for TensorFlow – AlexNet with batch size of 256 with different DIMM configurations and memory capacity for 4th Gen AMD EPYC 9654 processor-based PowerEdge R7625 with default BIOS settingsBalanced configurations showed the best performance. The balanced configuration with 64 GB DIMMs has the best performance in our testing. The balanced configuration with 16 GB DIMMs is the most energy efficient, and we find the configuration with the most value for money is the 8-DIMMs-per-socket, nearly balanced configuration with 16 GB DIMMs.
We infer from the performance results that CPU-based AI inference workloads are bandwidth-bound. Based on test results, we recommend PowerEdge R7625 featuring AMD EPYC 9654 in the 16 GB balanced configuration. It provides the best performance per watt and provides cost savings of more than 50 percent for a marginal drop in performance over 64 GB DIMMs in the balanced configuration.