
Run compute-heavy Hadoop big data workloads more quickly
Run compute-heavy Hadoop big data workloads more quickly
-
Big data workloads running on Hadoop framework can generate valuable insights that help organizations predict behaviors or outcomes. Decision-makers and their teams can use the insight to orchestrate transformative initiatives, such as targeted email campaigns that drive sales or customer feedback analysis that improves product quality. Current-generation PowerEdge R640 servers could allow business units and data analysts to work with large data sets more quickly than those in organizations that continue to run big data analysis workloads on previous-generation servers.
To see how the two solutions could handle real-world big data work, we ran three HiBench big data tests on them:
- Latent Dirichlet allocation (LDA): LDA is a technique to dynamically identify the topics discussed in a given document. It analyzes the words in a document, temporarily categorizes them, refines the topic of the document with the previously identified categories, and summarizes the document. A business could use LDA, for example, to organize customer reviews on a product or service.
- RandomForest (RF): Organizations can use random forests to make predictions by running multiple decision trees with slightly different weights and comparing the outcome between the trees to prevent overfitting—this can greatly increase the accuracy of a decision tree in classification and regression. For example, a bank or financial institution could use RF to make credit risk predictions.
- WordCount: This workload tallies the occurrence of each word in the data. The benchmark generates the random text from RandomTextWriter, which is a program that uses map/reduce to just run a distributed job with no interaction between tasks, and each task writes a large, unsorted random sequence of words. WordCount is “representative of another typical class of real-world MapReduce jobs - extracting a small amount of interesting data from large data set."2
The cluster of current-generation Dell EMC PowerEdge R640 servers powered by 2nd Generation Intel Xeon Scalable processors completed the three workloads more quickly than the previous-generation solution. The current-generation PowerEdge R640 servers ran the LDA workload with a throughput of more than 4 MB per second—more than double the throughput of the previous-generation solution. Processing more data per second could allow more of your business units to access and use the data. The chart below shows the throughput for both solutions in each test.
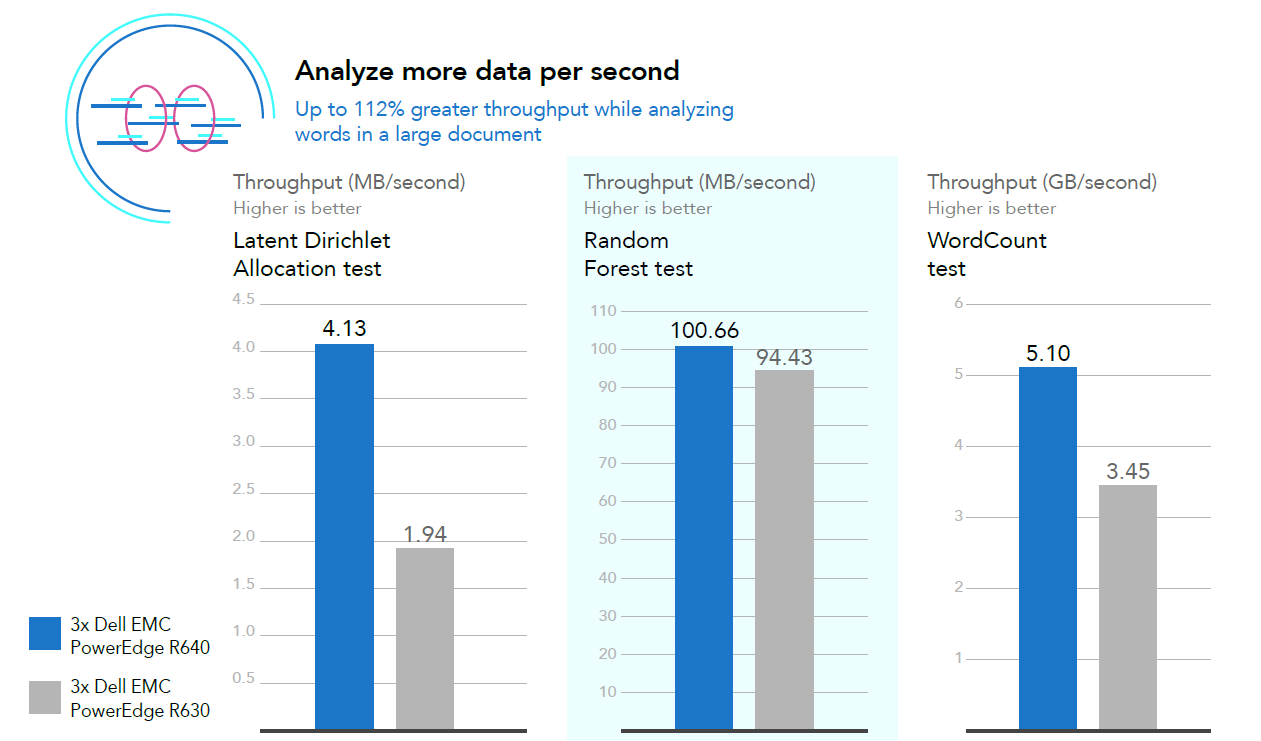
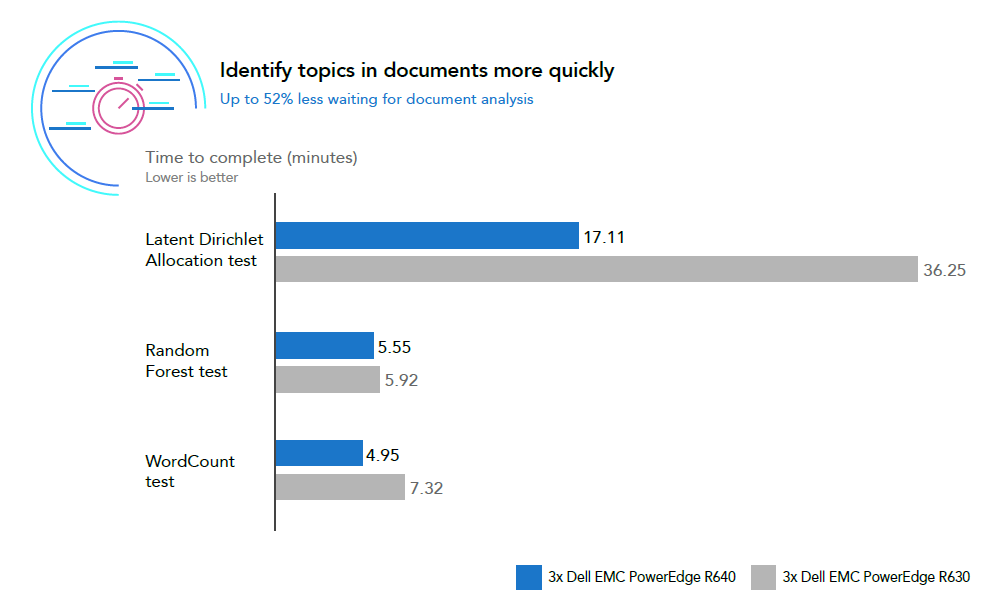
The current-generation Dell EMC PowerEdge R640 solution powered by 2nd Generation Intel Xeon Scalable processors needed just over 17 minutes to process 4.5 GB of data for the LDA test. Compared to the previous- generation solution, which needed 36 minutes, the solution completed the workload in less than half the time. Not only could you deliver analysis to decision makers more quickly with the PowerEdge R640, but you could use the extra time, for example, to re-run the LDA workload to ensure accuracy. The chart below shows the times to complete all three tests for both solutions.
About HiBench
Intel HiBench 7.1 is a big data benchmark suite for Apache Hadoop. Some tools in the suite are synthetic micro- benchmarks while others are real-world Hadoop applications. The output of the tools can demonstrate a solution’s processing speed, throughput, bandwidth, CPU utilization, data access patterns, and other metrics as they relate to processing big data workloads.
For more information on HiBench, visit https:// github.com/Intel- bigdata/HiBench.
2 "Intel-bigdata/HiBench,” accessed November 5, 2019, https://github.com/Intel-bigdata/HiBench.