
Machine learning complexity
Machine learning complexity
-
Despite a rich set of ecosystem tools for data science and machine learning, there is still a big gap between its benefit and real business needs. There are a limited number of services that can effectively cover such system qualities as availability, release management, or even basic security. And that does not include IT operational aspects — integration with enterprise systems such as data warehouses, data lakes, user management systems, monitoring, and auditing.
In the last few years, we have witnessed a substantial technical leap in data processing (Apache Hadoop ecosystem, Apache Kafka, Apache Beam, etc.) and compute (Kubernetes, functions as a service, on-demand computation, etc.). However, when we look at the data science and machine learning domain, we need a solution beyond the data science engineer’s laptop and the “works on my machine” attitude.
Despite a recent plethora of new frameworks being introduced (TensorFlow, Caffe2, PyTorch) and the usage of accelerators and AI on CPUs, this ecosystem is lagging compared to the mature Hadoop ecosystem.
Therefore, when we look at a typical data science development lifecycle, we observe an inefficiency or bottleneck due to data science tasks being performed on non-performant infrastructure (such as the data scientist’s laptop):
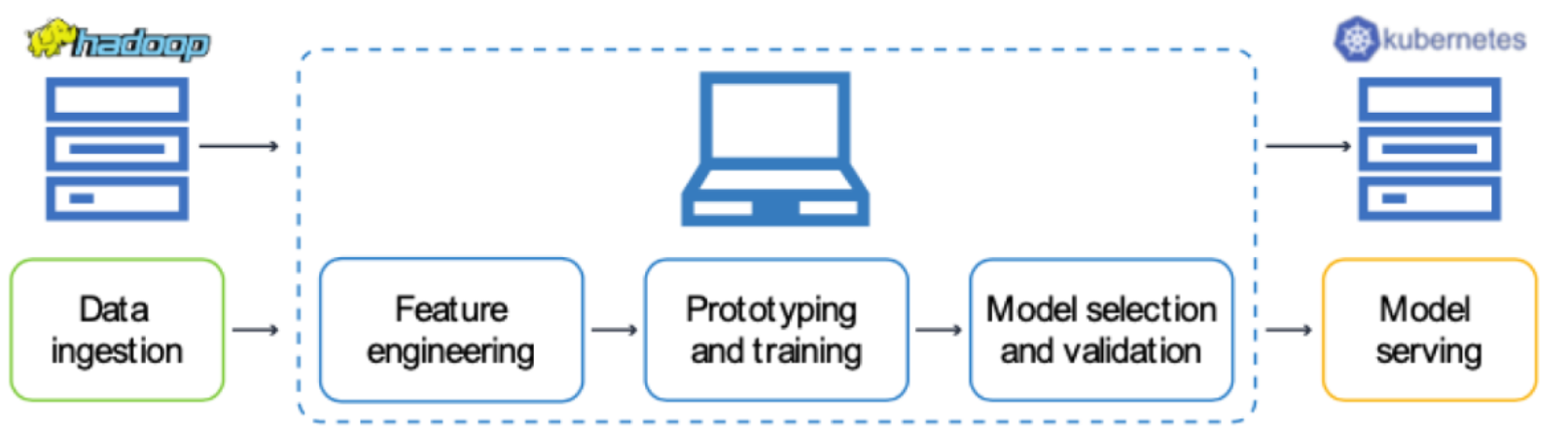
Glue code, pipeline jungles, and dead experimental code paths in addition to configuration debt are some reasons why the market doesn’t have a widely adapted product for machine learning and data science tasks beyond the engineer’s laptop and Jupyter Notebooks.