
Test failover workflow in VMware SRM
Test failover workflow in VMware SRM
-
Test failover is a two-part process:
- Test—Initiates test failover, mounts replica devices and powers on (if configured) virtual machines according to the selected recovery plan.
- Cleanup—Powers down and removes test environment from recovery site, unmounts and deletes replica devices (if configured) and returns status to original pre-test state.
This section will first cover the replica modes then the general workflow of the test failover operation, regardless of replica mode. The subsequent sections will deal specifically with the configuration and execution of the different test failover modes.
SRA replica modes
In general, there are three ways to run a test failover with the SRDF SRA:
- Using the parameter <AutoTargetDevice>
- Using the EmcSrdfSraTestFailoverConfig.xml file
- Using the R2s
The first of these is the preferred method as it requires the least input from the user. Once the parameter is set, the SRA will create the necessary snapshots, linked devices, and present those devices to the recovery site. Upon cleanup the user can decide whether to delete the snapshot devices or retain them for future tests.
The second option requires that the user pre-creates the devices that the SRA will link to the snapshots. The XML file must be modified to show the relationship between the R2 devices and the pre-created devices. Customers who are unable to create new devices for the SRM test (e.g., cache limitations) or who already have available devices, might select this option.
The final option is to use the R2s directly, without a copy. This has the benefit of not requiring additional devices for the test. The SRA halts replication between the protection and recovery sites for the duration of the test and then during cleanup discards any changes made to the R2 and resynchronizes the R1 to the R2. This option is not a recommended option, however, because if the protection site is lost during the test, the recovery site cannot receive any changes from the R1 that occurred during the test. Furthermore, any changes made to the R2 during the test are now part of the recovered environment. Therefore, if this option is selected, Dell recommends taking a targetless SnapVX copy of the R2 before the testing commences. This will provide a viable backup if the R1 is lost and changes have already been made to the R2 during testing. Details on how this might be scripted can be found in the following section Targetless Gold Copies.
Requirements
Before a test failover can be executed the following requirements must be met:
- A recovery plan must be configured and associated with one or more protection groups.
- Inventory mappings should be configured so virtual machines can be properly recovered.
- A replica method for test failover, either TimeFinder or R2 recovery, must be chosen and configured. In the case of TimeFinder, device pairings (target devices to be replicas of the R2 devices) must be identified, or the global option AutoTargetDevice should be enabled. Specific requirements for this and how to configure these pairings is discussed in detail in the upcoming sections.
- If consistency protection is not enabled, the test failover operation will fail[30]. For example, if consistency has been disabled by the user or the RDF link is in “Transmit Idle” state, the adapter cannot perform a consistent split. The following error will appear in the EmcSrdfSra_<date>.log:
“Failed to create snapshots of replica devices. Failed to create snapshot of replica consistency group test_cg. SRA command 'testFailoverStart' failed for consistency group 'test_cg'. The devices don't have consistency enabled. Please check and enable consistency on the devices.”
Refer to the section, Consistency groups for more information on consistency.
- Device or composite groups must exist at each site. These may also be consistency groups depending on the environment.
- Test failover, by default, will fail when the involved RDF links are in the “Suspended” or “Split” state. The SRA global option, “TestFailoverForce” can be enabled to allow test failover in these situations. The SRDF SRA also supports test failover with TimeFinder if the protection site is unavailable (disconnected); however this is not supported if using the R2s directly for testing.
- If TestReplicaMaskingControl is enabled, ensure that the desired devices to be recovered during the test are configured within the masking control file on the recovery site SRM server.
Note: In Cascaded SRDF/Star or Cascaded SRDF/Non-Star environments that have been recovered to the Asynchronous target site, test failover, with or without TimeFinder is not supported. Only full recovery back to the original workload site is supported with the SRDF SRA.
Test
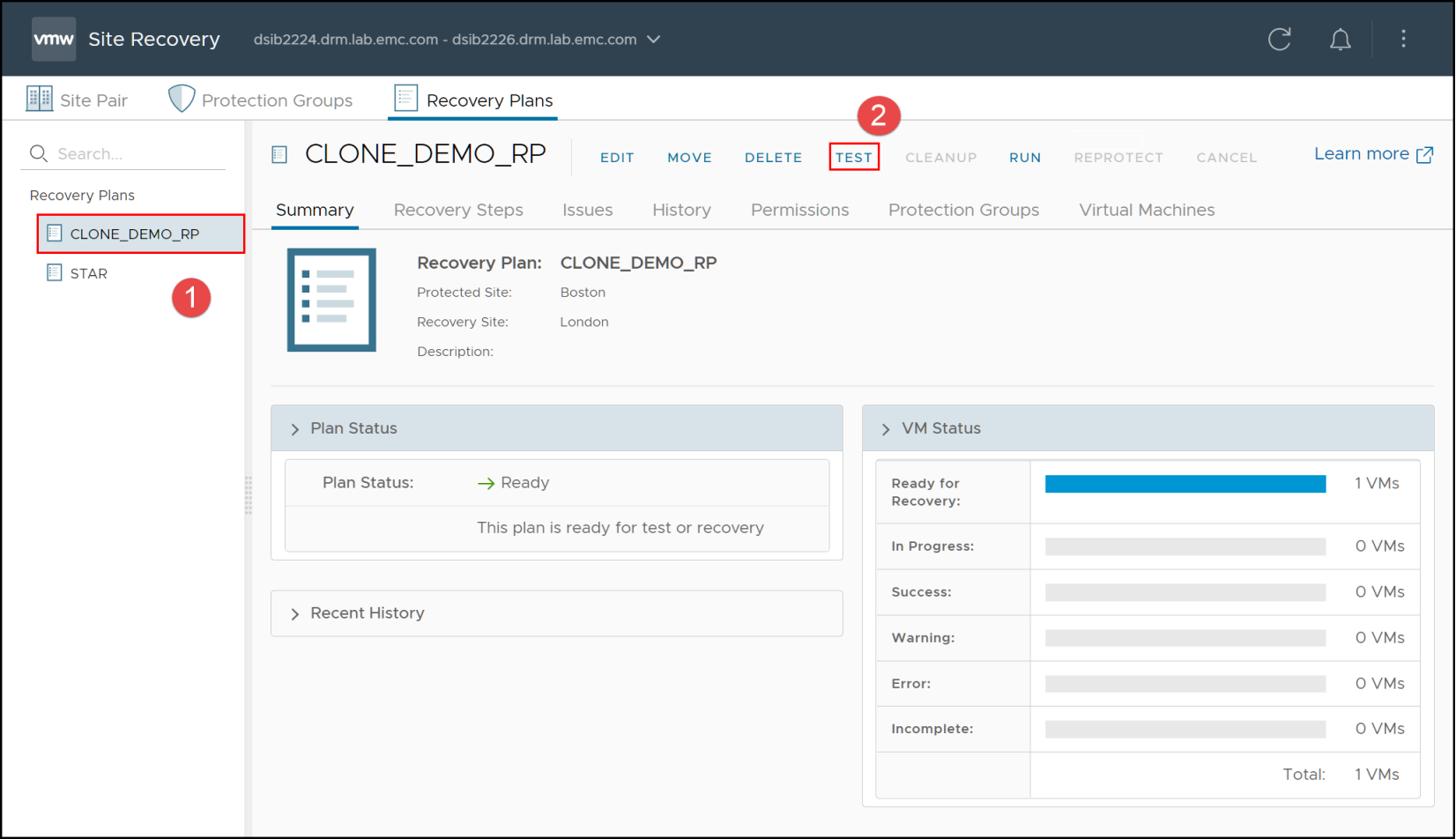
Once all required configurations are complete and the user is ready to perform a test failover operation the user must select the desired Recovery Plan and click on the Test link as shown in Figure 52.
Figure 52. Initiating a Recovery Plan test failover operation with SRM
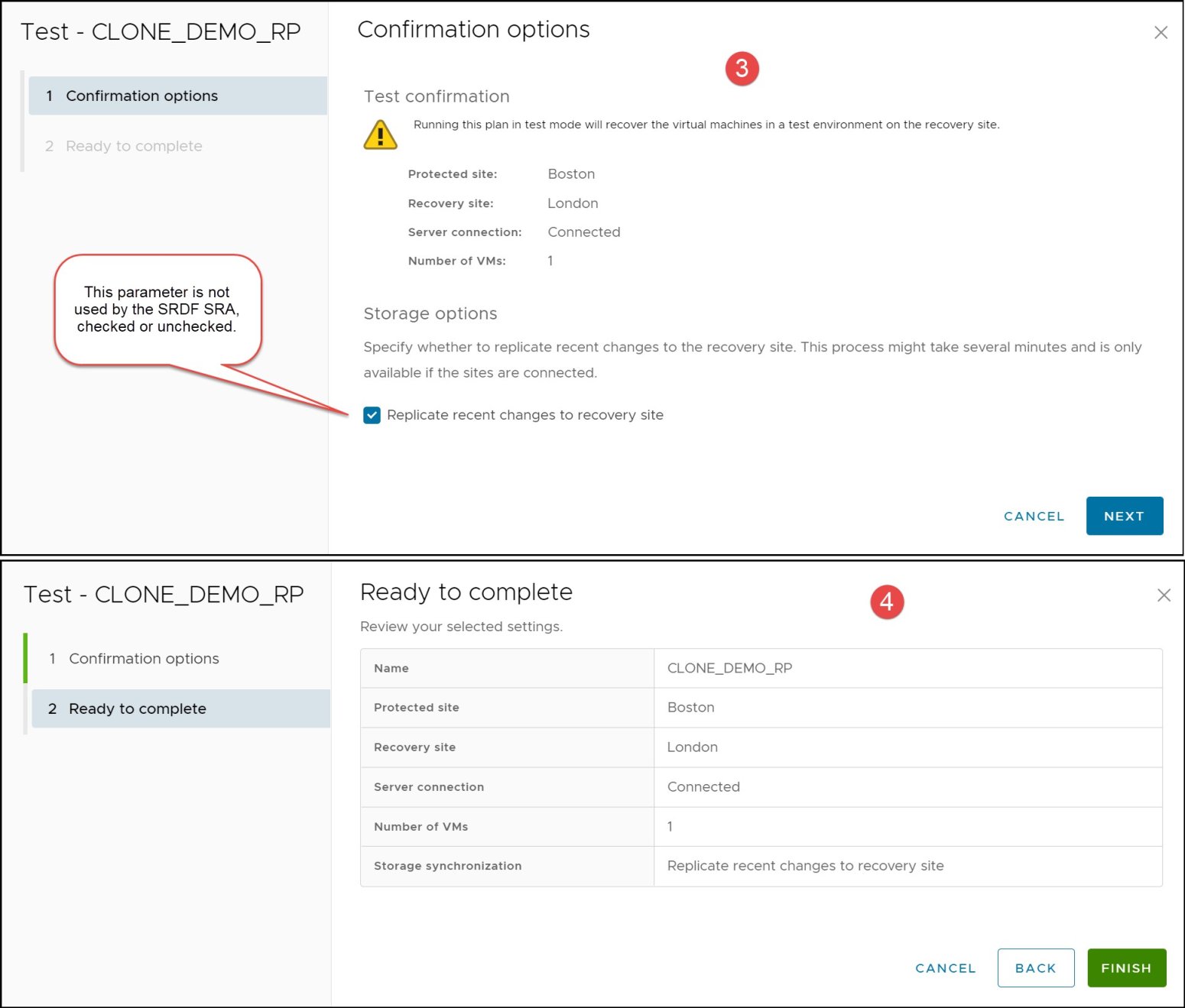
Once clicked, a short series of windows pop-up to confirm the test failover operation. There is a check-box offered in the first window called “Replicate Recent changes to recovery site”. This option, which enables or disables the “SyncOnce” operation, is present for all storage vendors. Though it may be relevant for other vendors and their respective replication technologies, it is ignored by the SRDF SRA, checked or unchecked. SRDF and consistency technology (as well as additional SRA requirements) make sure that an up-to-date and consistent copy is available on the R2 side. Steps 3 and 4 complete the wizard as seen in Figure 53.
Figure 53. Test failover confirmation wizard in SRM
At a high level, a recovery plan test involves the following:
- Creation of a “bubble” IP network[31] for the virtual machines to run in, so production networks are not interfered with.
- A temporary snapshot or clone of the R2/R21 device is created or the SRA splits the RDF relationship and read/write enables the R2/R21.
- [Optional] The replica TimeFinder device or R2/R21 device is added to a storage group and presented to the recovery site.
- The replica TimeFinder device or R2/R21 device is resignatured and mounted at the recovery site.
- Shadow VMs are unregistered and are replaced with the replica VMs.
- If the plan requests suspension of local virtual machines at the recovery site, they are suspended during the test.
- VMs are powered-on or left off according to the recovery plan.
- Finally, it is important to remember that no operations are disrupted at the protected site and that the replication of the VMAX/PowerMax devices containing the VMFS datastores is not affected or changed[32].
Once the user has confirmed the test failover operation can proceed, the Recovery Plan will be initiated in test mode. A completed test recovery can be seen in Figure 54. The test environment will remain operational until a Cleanup operation has been executed.
Figure 54. Completed Test Recovery Plan in SRM

Cleanup
Once a recovery plan has been tested the test environment can be discarded and reset through the use of the “Cleanup” operation offered by SRM. The Cleanup operation automatically reverts all changes incurred by the recovery plan test and allows for subsequent failover operations.
- The Cleanup operation performs the following operations:
- Power off and unregister test virtual machines
- Unmount and detach replica VMFS volumes or RDMs
- [Optional] Removes the replica(s) from the storage group in the recovery site masking view(s)
- [Optional] Free tracks from the replica devices
- [Optional] Delete the replica devices
- Replace recovered virtual machines with original placeholders (shadow VMs), preserving their identity and configuration information.
- Clean up replicated storage snapshots that were used by the recovered virtual machines during the test. Depending on the SRA options this can mean re-creating or terminating TimeFinder relationships or re-establishing SRDF replication.
Before resetting the environment after a test failover, ensure that the recovery plan worked as desired. Verify the success of any custom scripts, application functionality, networking, etc. Once all facets of the test have been verified by the involved stakeholders a Cleanup operation can be executed.
Note: After a test failover has been executed, an actual failover or another test failover cannot be run until a Cleanup operation has occurred. It is advisable to run a Cleanup operation as soon as the test environment is no longer needed to allow for any subsequent operations to be run without delay.
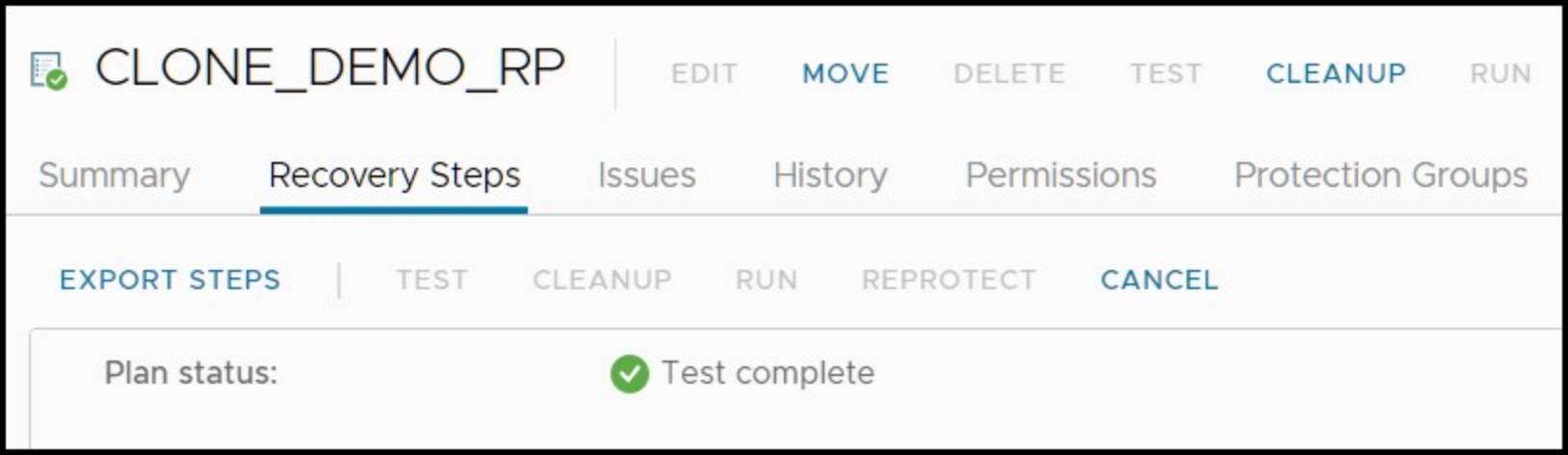
As can be seen in Figure 55, a Cleanup can only be run against a recovery plan if the recovery plan status is in “Test Complete”. Furthermore, even if a test failover was not entirely successful, a Cleanup operation will still need to be executed before another test failover can be attempted. The “Test Complete” status will be assigned to the Recovery Plan regardless of the level of success reached by the test failover.
Figure 55. Recovery plan in “Test Complete” status after successful test failover
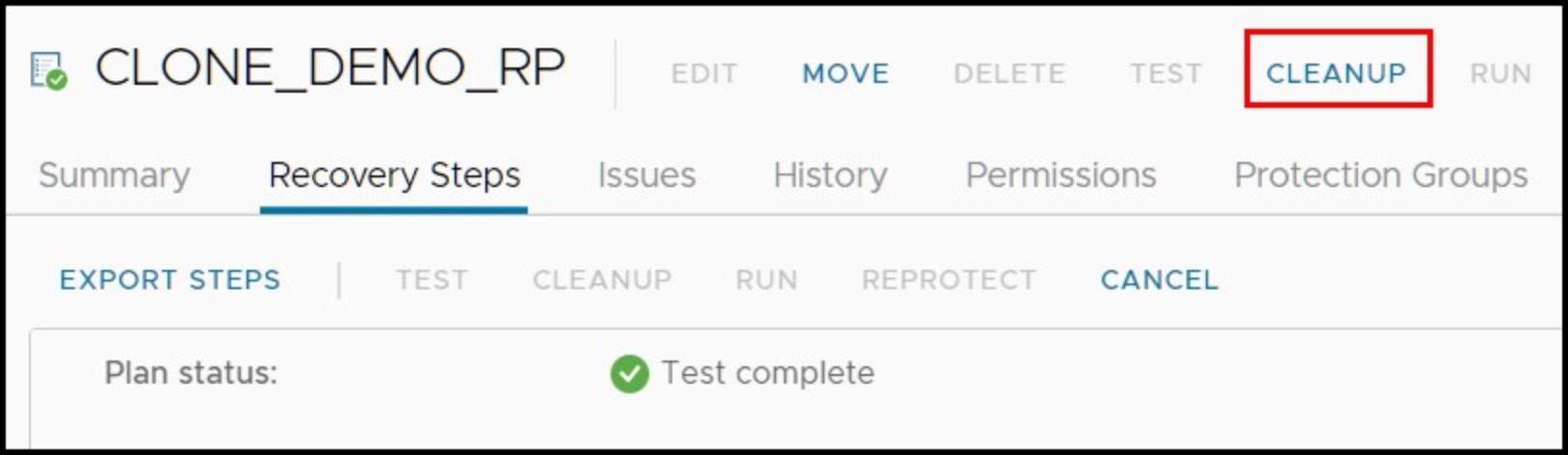
The Cleanup process is initiated, in a similar fashion to the test failover process, by clicking on the Cleanup link (broom) after selecting the appropriate Recovery Plan. This can be seen in Figure 56.
Figure 56. Initiating a Cleanup after a test recovery in SRM
The Cleanup link launches a similar set of windows that the original test operation brought up to confirm the reset activities that it will execute. The first attempt at running this Cleanup after a particular failover offers no configurable parameters and simply displays details for confirmation. This set of screens are shown in Figure 57.
Figure 57. Cleanup operation confirmation wizard in SRM
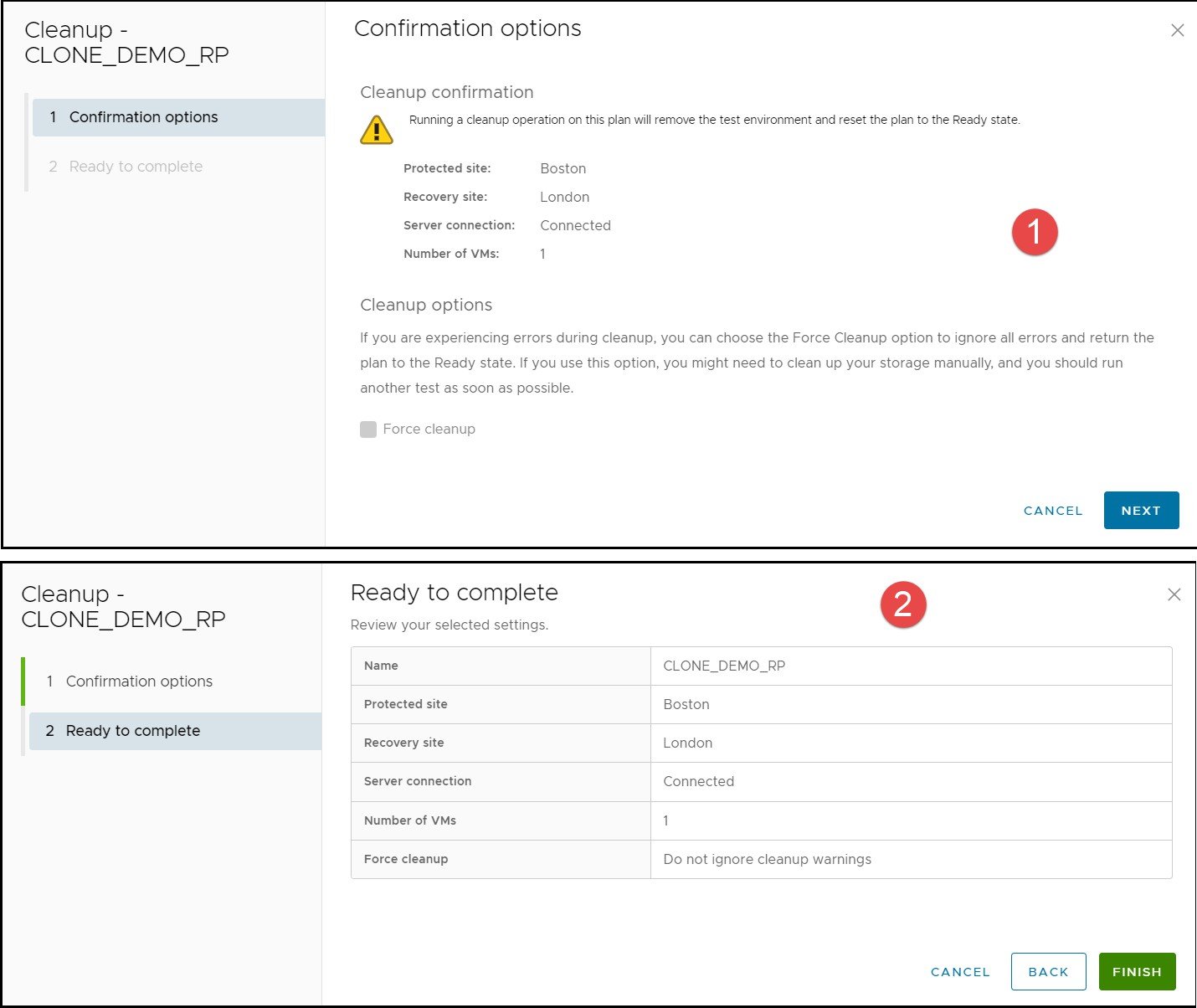
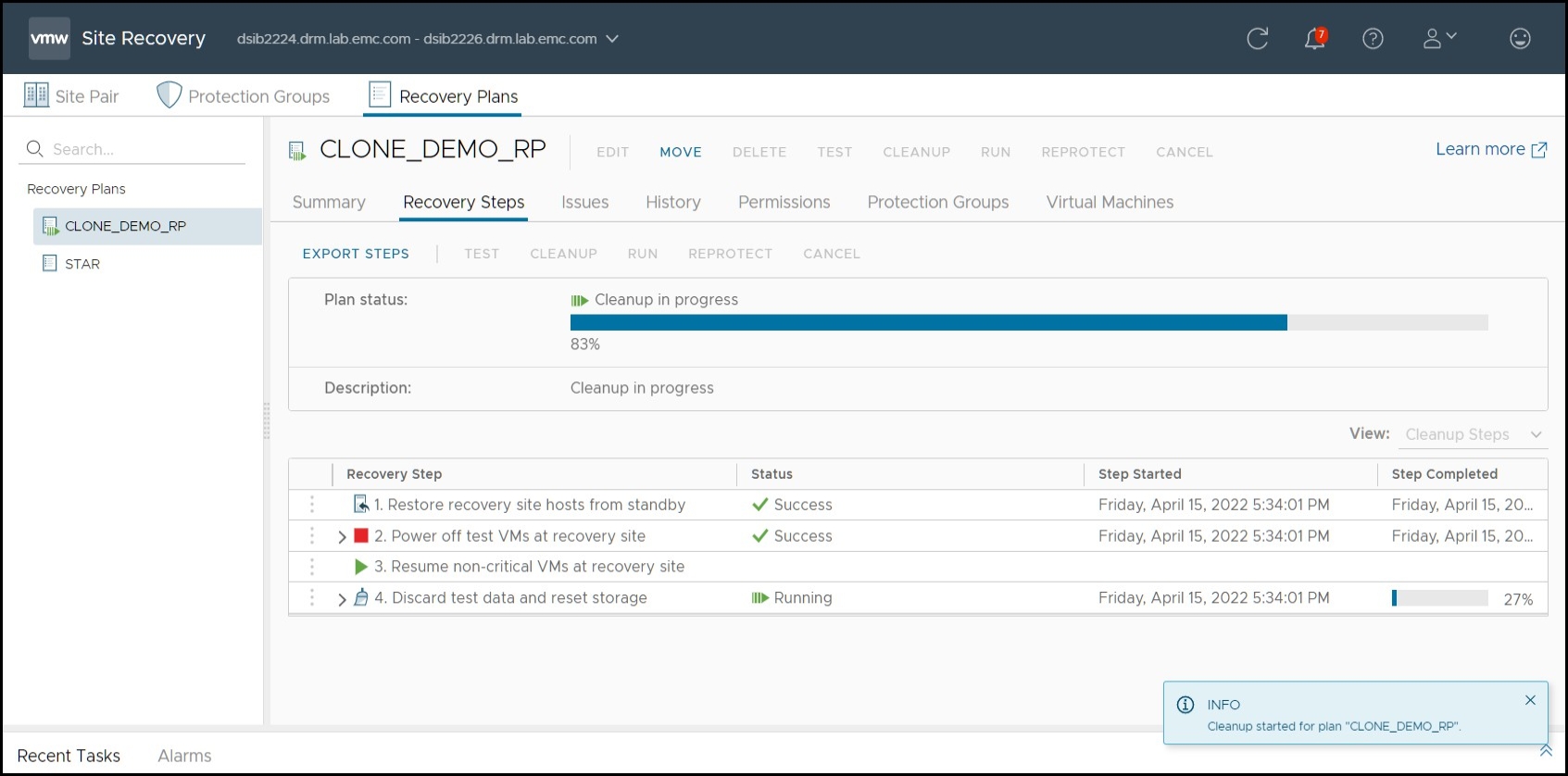
Figure 58 shows the steps taken by the Cleanup process itself.
Figure 58. Cleanup operation steps in SRM
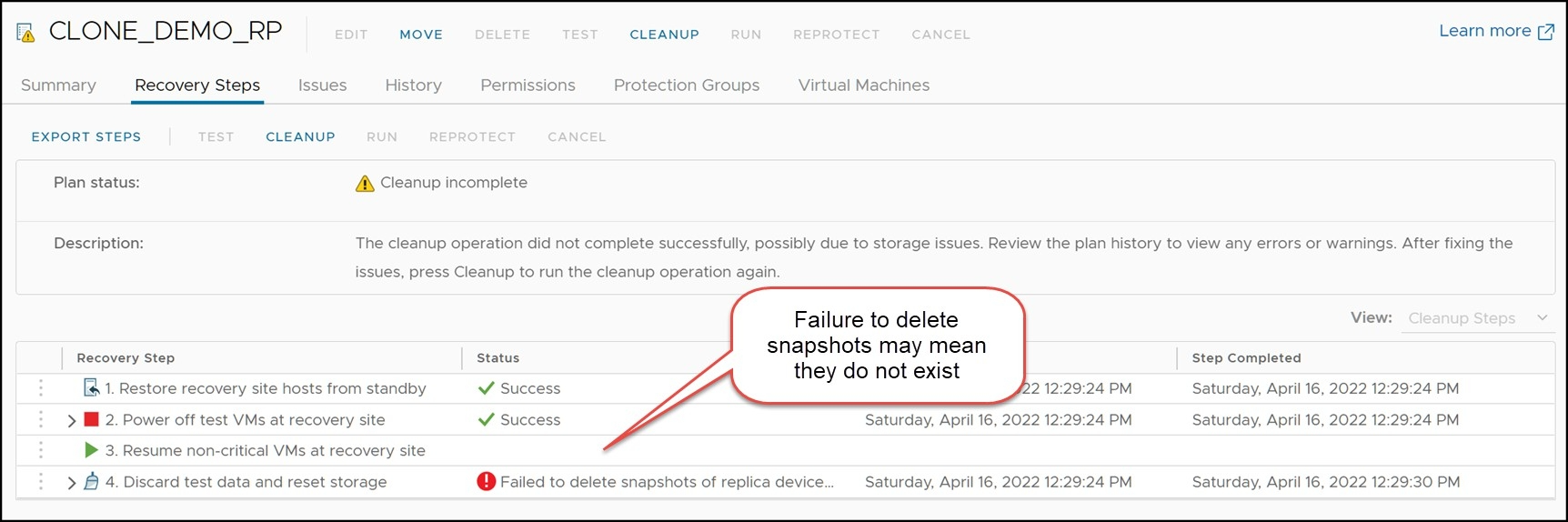
Due to a variety of reasons, the first attempt at a Cleanup operation may fail. Typical causes include:
- Test failover did not complete entirely successfully
- Storage replica creation failure
- Virtual machine inventory mappings incorrect
- Environment change after the test failover but before Cleanup
- Manual change to storage outside of SRA
- Significant protection group change
- VMware environment failure
- Manual change to VMware environment outside of SRM
Note: Errors reported in the SRM interface can often be very generic. Refer to the SRDF SRA log on the recovery site if the error indicates a failure is related to storage operations.
In cases such as these, the first Cleanup operation, which does not permit the use of force, will fail. This is due to the fact that on the first run the Cleanup operation does not tolerate any failures with any step of the Cleanup process. Therefore, if the Cleanup process encounters an error, it will immediately fail as in Figure 59
Figure 59. Initial SRM cleanup failure
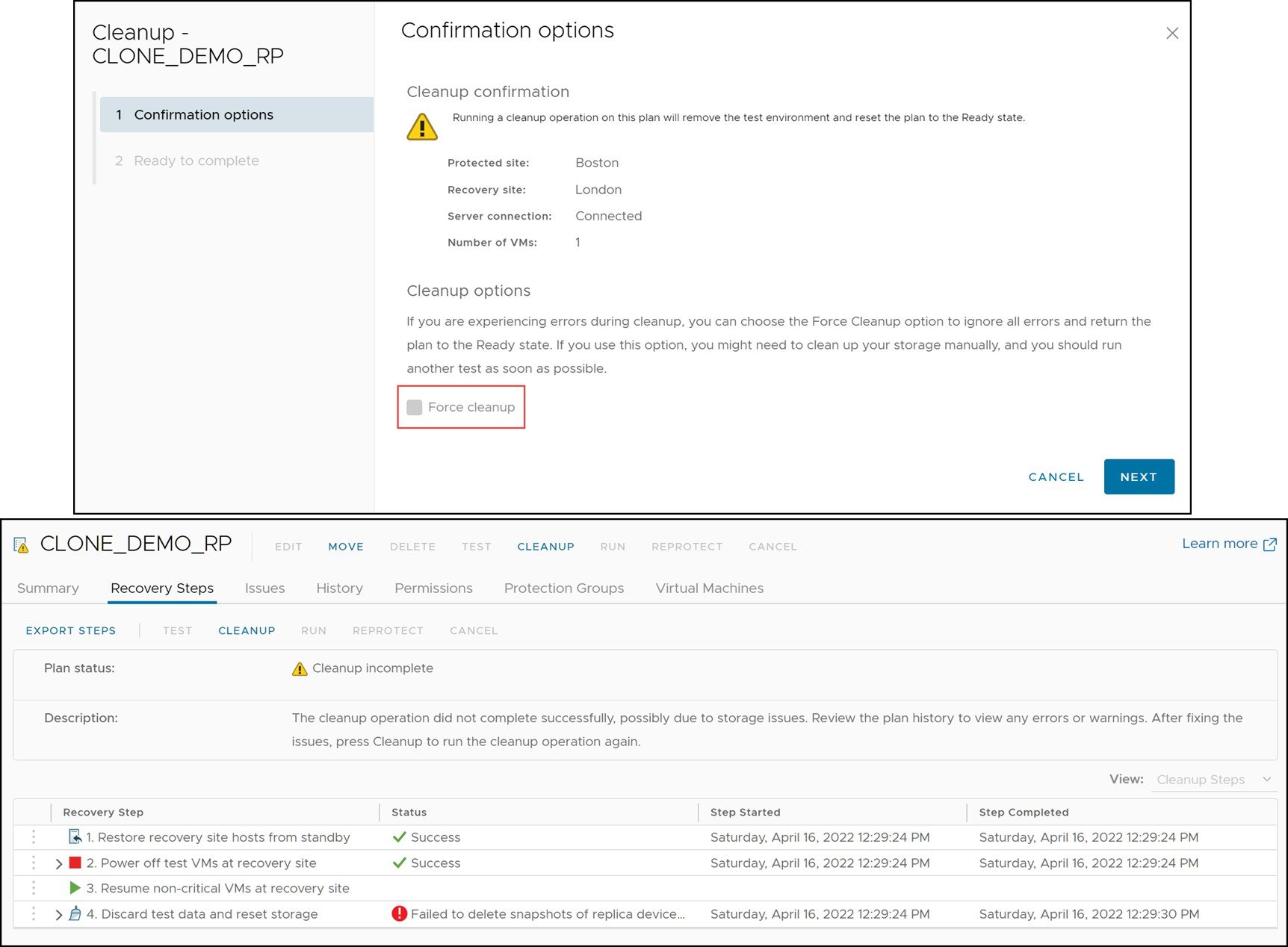
Once the Cleanup process has failed for the first time the ability to force the Cleanup becomes available. The Cleanup confirmation wizard, when run subsequent to a failure, will now offer a check-box to force the Cleanup as seen in Figure 60. This will alter the behavior of the Cleanup process to ride through any error encountered. Any operation it can complete successfully will be completed and, unlike before, any operation that encounters an error will be skipped.
Figure 60. Executing a Cleanup operation with the force option in SRM
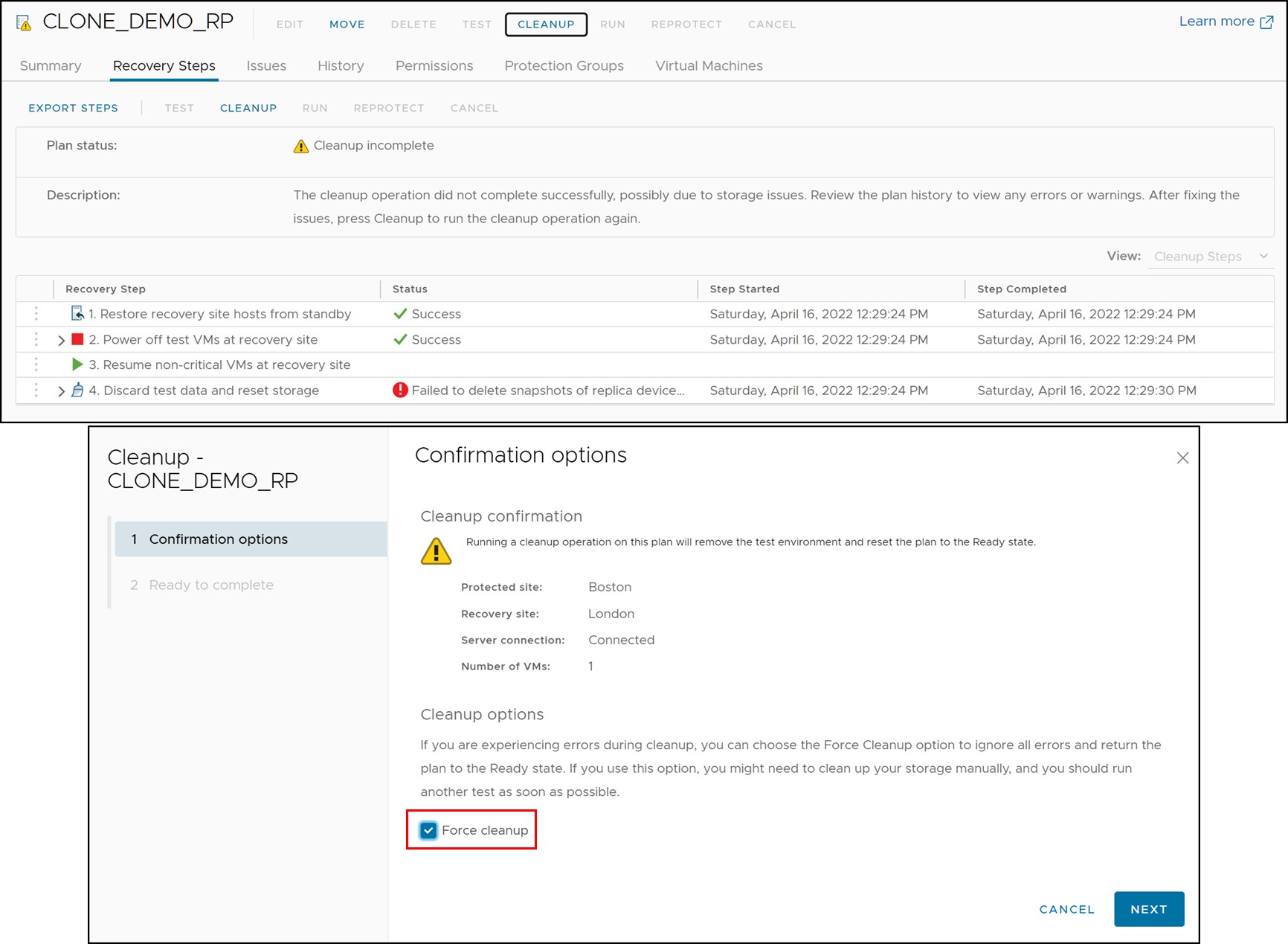
In general, it is not advisable to resort to the force Cleanup unless an actual failover operation needs to be run immediately and the time to troubleshoot any issues encountered in the Cleanup cannot be afforded. Otherwise, before using the force option, attempt to resolve any issues first and then retry a non-forced Cleanup again. If a force Cleanup is used in haste, it may require additional manual intervention afterwards because the SRA and SRM may not be able to recover and ready themselves for another test failover or failover without user intervention.
When a force Cleanup is run, as seen in Figure 61, users should refer to the logs to identify the exact errors encountered. If necessary, resolve these issues and attempt to execute another test failover as soon as possible to verify the environment is functioning correctly. A very common failure when running Cleanup with the SRDF SRA is the inability to remove snapshot devices. Frequently this is because they were never created due to issues with the XML configuration files. In such cases a Cleanup with force is perfectly acceptable.
Figure 61 Force Cleanup operation with failures in SRM
[30] Consistency does not need to be enabled on SRDF/S device groups limited to only one RDF group, but it is recommended. Also note that if the global option TestFailoverForce is enabled, the SRA will ignore the consistency state.
[31] If a special network is not created beforehand by the user, SRM will create one automatically. The problem with the SRM-created networks is that they will not allow virtual machines on different hosts to communicate as these networks are internal to each host and do not have external up-links. If inter-host communication is required, the user should create insulated networks across ESXi hosts and configure it for use in the recovery plan.
[32] With the exception of when the TestFailoverWithoutLocalSnapshots advanced option is enabled.